 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What does BERT learn about prosody?
Apr 25, 2023
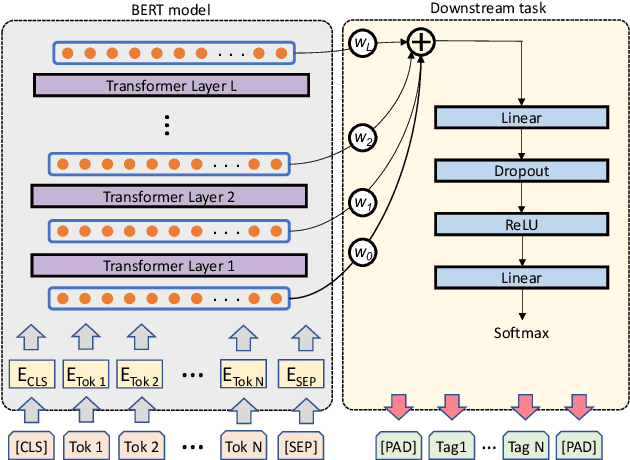
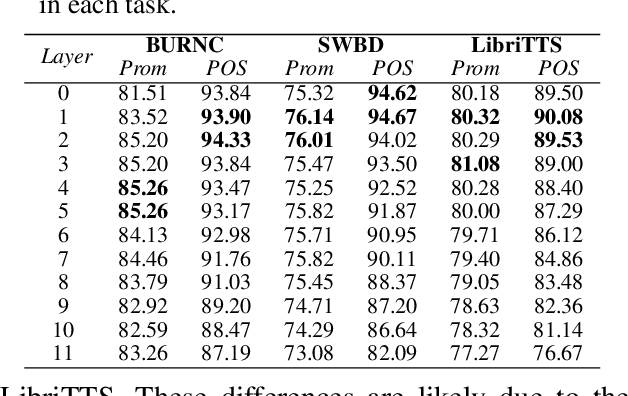
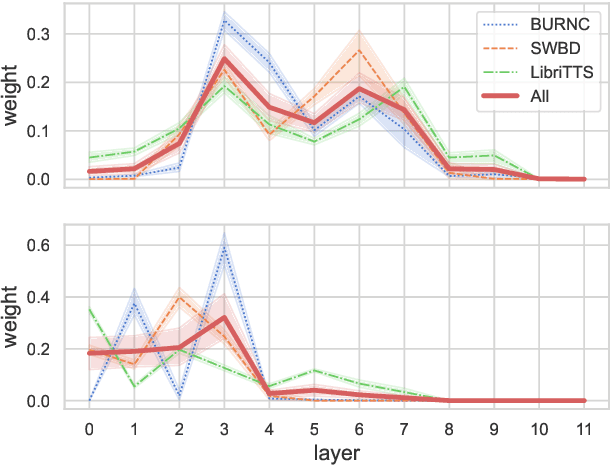

Language models have become nearly ubiquitous in natural language processing applications achieving state-of-the-art results in many tasks including prosody. As the model design does not define predetermined linguistic targets during training but rather aims at learning generalized representations of the language, analyzing and interpreting the representations that models implicitly capture is important in bridging the gap between interpretability and model performance. Several studies have explored the linguistic information that models capture providing some insights on their representational capacity. However, the current studies have not explored whether prosody is part of the structural information of the language that models learn. In this work, we perform a series of experiments on BERT probing the representations captured at different layers. Our results show that information about prosodic prominence spans across many layers but is mostly focused in middle layers suggesting that BERT relies mostly on syntactic and semantic information.
Convolutional Neural Networks Rarely Learn Shape for Semantic Segmentation
May 11, 2023

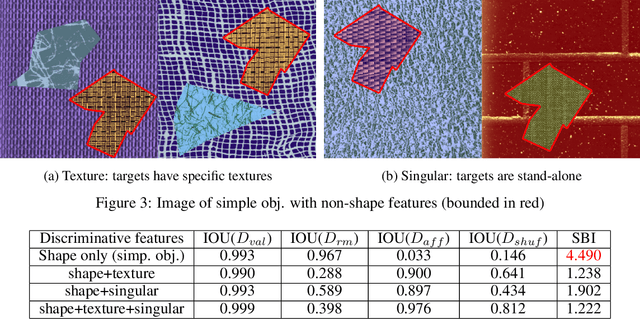
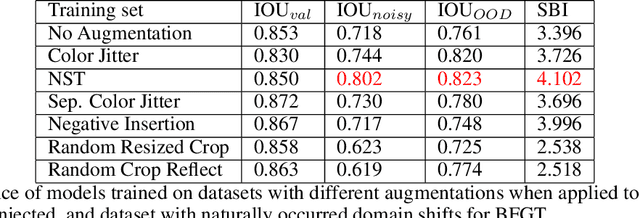
Shape learning, or the ability to leverage shape information, could be a desirable property of convolutional neural networks (CNNs) when target objects have specific shapes. While some research on the topic is emerging, there is no systematic study to conclusively determine whether and under what circumstances CNNs learn shape. Here, we present such a study in the context of segmentation networks where shapes are particularly important. We define shape and propose a new behavioral metric to measure the extent to which a CNN utilizes shape information. We then execute a set of experiments with synthetic and real-world data to progressively uncover under which circumstances CNNs learn shape and what can be done to encourage such behavior. We conclude that (i) CNNs do not learn shape in typical settings but rather rely on other features available to identify the objects of interest, (ii) CNNs can learn shape, but only if the shape is the only feature available to identify the object, (iii) sufficiently large receptive field size relative to the size of target objects is necessary for shape learning; (iv) a limited set of augmentations can encourage shape learning; (v) learning shape is indeed useful in the presence of out-of-distribution data.
Transformers for CT Reconstruction From Monoplanar and Biplanar Radiographs
May 11, 2023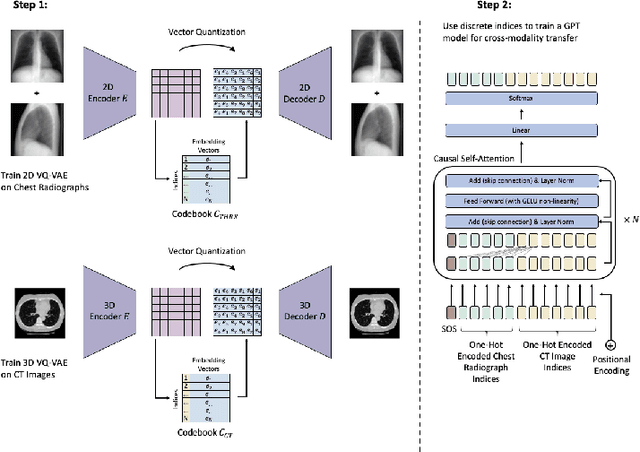
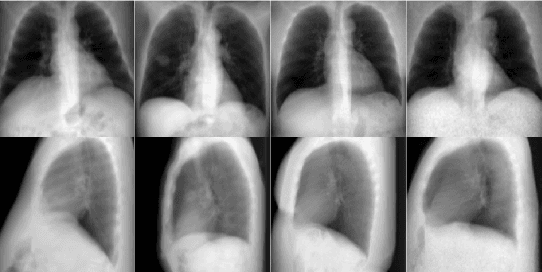
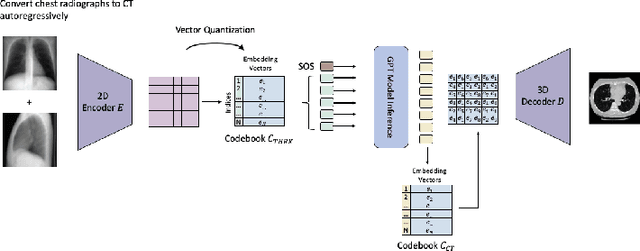
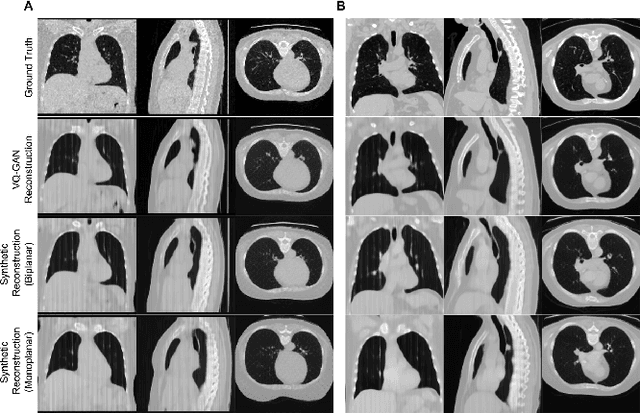
Computed Tomography (CT) scans provide detailed and accurate information of internal structures in the body. They are constructed by sending x-rays through the body from different directions and combining this information into a three-dimensional volume. Such volumes can then be used to diagnose a wide range of conditions and allow for volumetric measurements of organs. In this work, we tackle the problem of reconstructing CT images from biplanar x-rays only. X-rays are widely available and even if the CT reconstructed from these radiographs is not a replacement of a complete CT in the diagnostic setting, it might serve to spare the patients from radiation where a CT is only acquired for rough measurements such as determining organ size. We propose a novel method based on the transformer architecture, by framing the underlying task as a language translation problem. Radiographs and CT images are first embedded into latent quantized codebook vectors using two different autoencoder networks. We then train a GPT model, to reconstruct the codebook vectors of the CT image, conditioned on the codebook vectors of the x-rays and show that this approach leads to realistic looking images. To encourage further research in this direction, we make our code publicly available on GitHub: XXX.
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
May 22, 2023
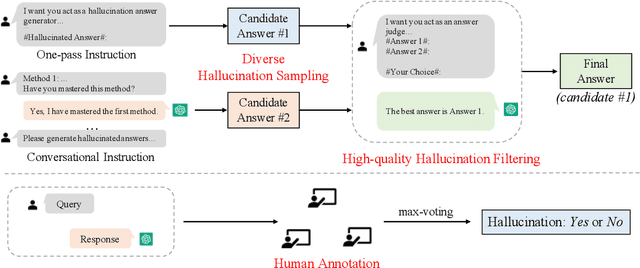

Large language models (LLMs), such as ChatGPT, are prone to generate hallucinations, \ie content that conflicts with the source or cannot be verified by the factual knowledge. To understand what types of content and to which extent LLMs are apt to hallucinate, we introduce the Hallucination Evaluation for Large Language Models (HaluEval) benchmark, a large collection of generated and human-annotated hallucinated samples for evaluating the performance of LLMs in recognizing hallucination. To generate these samples, we propose a ChatGPT-based two-step framework, \ie sampling-then-filtering. Besides, we also hire some human labelers to annotate the hallucinations in ChatGPT responses. The empirical results suggest that ChatGPT is likely to generate hallucinated content in specific topics by fabricating unverifiable information (\ie about $11.4\%$ user queries). Moreover, existing LLMs face great challenges in recognizing the hallucinations in texts. While, our experiments also prove that the hallucination recognition can be improved by providing external knowledge or adding reasoning steps. Our benchmark can be accessed at https://github.com/RUCAIBox/HaluEval.
DiffAVA: Personalized Text-to-Audio Generation with Visual Alignment
May 22, 2023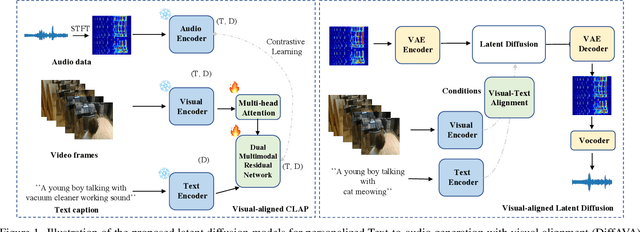


Text-to-audio (TTA) generation is a recent popular problem that aims to synthesize general audio given text descriptions. Previous methods utilized latent diffusion models to learn audio embedding in a latent space with text embedding as the condition. However, they ignored the synchronization between audio and visual content in the video, and tended to generate audio mismatching from video frames. In this work, we propose a novel and personalized text-to-sound generation approach with visual alignment based on latent diffusion models, namely DiffAVA, that can simply fine-tune lightweight visual-text alignment modules with frozen modality-specific encoders to update visual-aligned text embeddings as the condition. Specifically, our DiffAVA leverages a multi-head attention transformer to aggregate temporal information from video features, and a dual multi-modal residual network to fuse temporal visual representations with text embeddings. Then, a contrastive learning objective is applied to match visual-aligned text embeddings with audio features. Experimental results on the AudioCaps dataset demonstrate that the proposed DiffAVA can achieve competitive performance on visual-aligned text-to-audio generation.
Gloss-Free End-to-End Sign Language Translation
May 22, 2023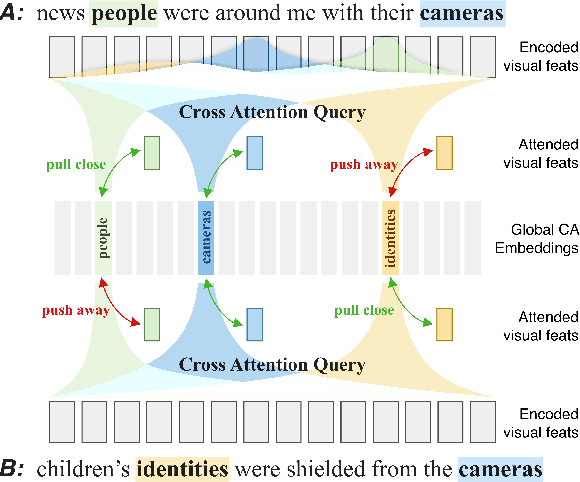

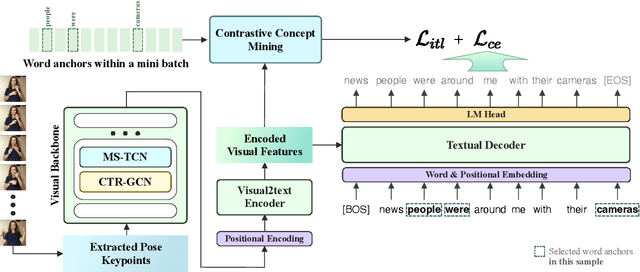

In this paper, we tackle the problem of sign language translation (SLT) without gloss annotations. Although intermediate representation like gloss has been proven effective, gloss annotations are hard to acquire, especially in large quantities. This limits the domain coverage of translation datasets, thus handicapping real-world applications. To mitigate this problem, we design the Gloss-Free End-to-end sign language translation framework (GloFE). Our method improves the performance of SLT in the gloss-free setting by exploiting the shared underlying semantics of signs and the corresponding spoken translation. Common concepts are extracted from the text and used as a weak form of intermediate representation. The global embedding of these concepts is used as a query for cross-attention to find the corresponding information within the learned visual features. In a contrastive manner, we encourage the similarity of query results between samples containing such concepts and decrease those that do not. We obtained state-of-the-art results on large-scale datasets, including OpenASL and How2Sign. The code and model will be available at https://github.com/HenryLittle/GloFE.
DeepJSCC-l++: Robust and Bandwidth-Adaptive Wireless Image Transmission
May 22, 2023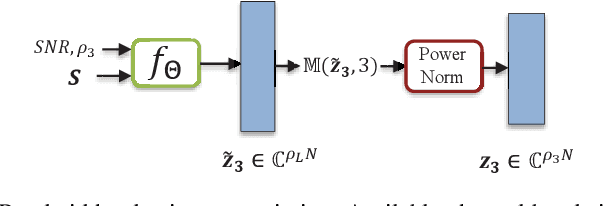
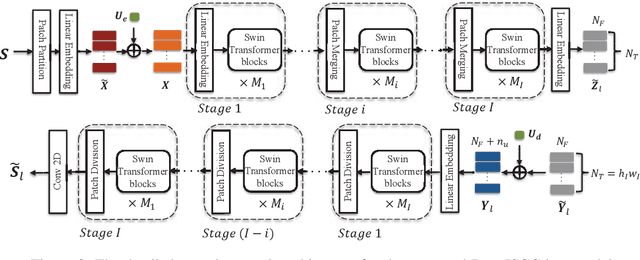
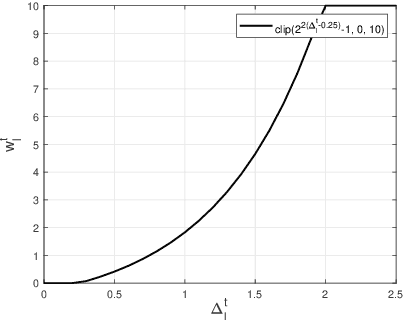
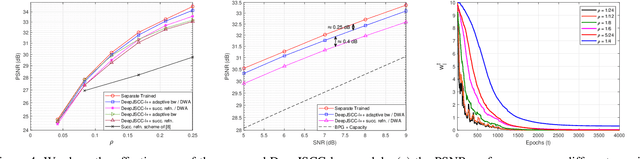
This paper presents a novel vision transformer (ViT) based deep joint source channel coding (DeepJSCC) scheme, dubbed DeepJSCC-l++, which can be adaptive to multiple target bandwidth ratios as well as different channel signal-to-noise ratios (SNRs) using a single model. To achieve this, we train the proposed DeepJSCC-l++ model with different bandwidth ratios and SNRs, which are fed to the model as side information. The reconstruction losses corresponding to different bandwidth ratios are calculated, and a new training methodology is proposed, which dynamically assigns different weights to the losses of different bandwidth ratios according to their individual reconstruction qualities. Shifted window (Swin) transformer, is adopted as the backbone for our DeepJSCC-l++ model. Through extensive simulations it is shown that the proposed DeepJSCC-l++ and successive refinement models can adapt to different bandwidth ratios and channel SNRs with marginal performance loss compared to the separately trained models. We also observe the proposed schemes can outperform the digital baseline, which concatenates the BPG compression with capacity-achieving channel code.
Accelerating Graph Neural Networks via Edge Pruning for Power Allocation in Wireless Networks
May 22, 2023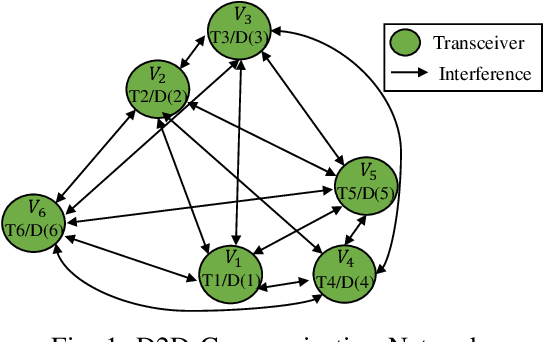
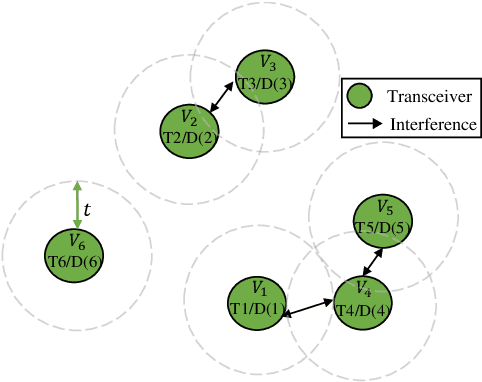
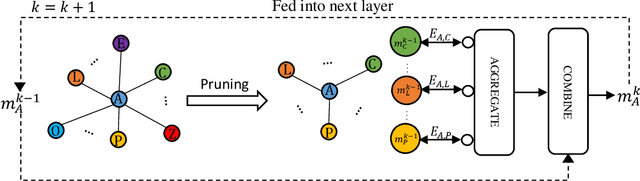
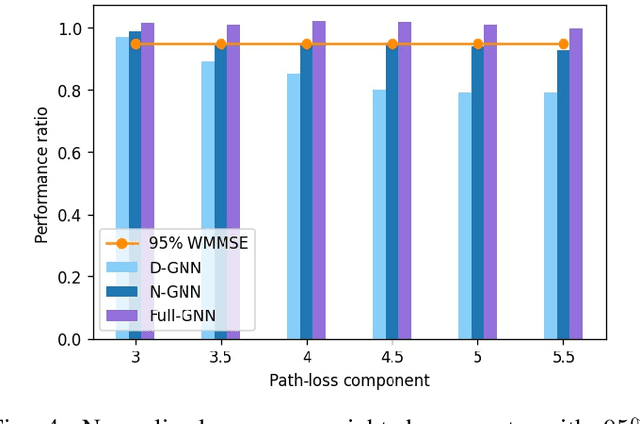
Neural Networks (GNNs) have recently emerged as a promising approach to tackling power allocation problems in wireless networks. Since unpaired transmitters and receivers are often spatially distant, the distanced-based threshold is proposed to reduce the computation time by excluding or including the channel state information in GNNs. In this paper, we are the first to introduce a neighbour-based threshold approach to GNNs to reduce the time complexity. Furthermore, we conduct a comprehensive analysis of both distance-based and neighbour-based thresholds and provide recommendations for selecting the appropriate value in different communication channel scenarios. We design the corresponding distance-based and neighbour-based Graph Neural Networks with the aim of allocating transmit powers to maximise the network throughput. Our results show that our proposed GNNs offer significant advantages in terms of reducing time complexity while preserving strong performance. Besides, we show that by choosing a suitable threshold, the time complexity is reduced from O(|V|^2) to O(|V|), where |V| is the total number of transceiver pairs.
Learning Emotion Representations from Verbal and Nonverbal Communication
May 22, 2023
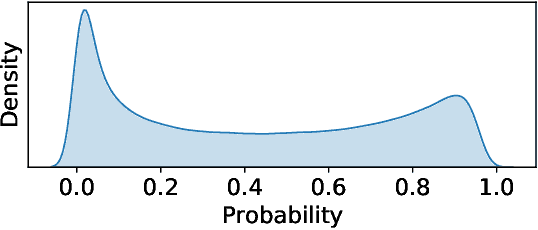
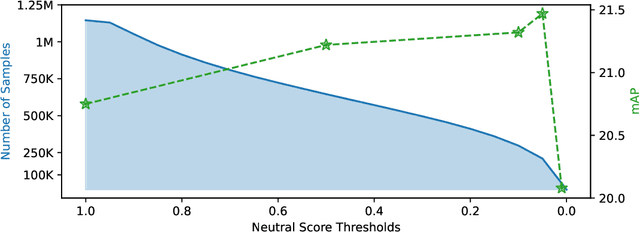
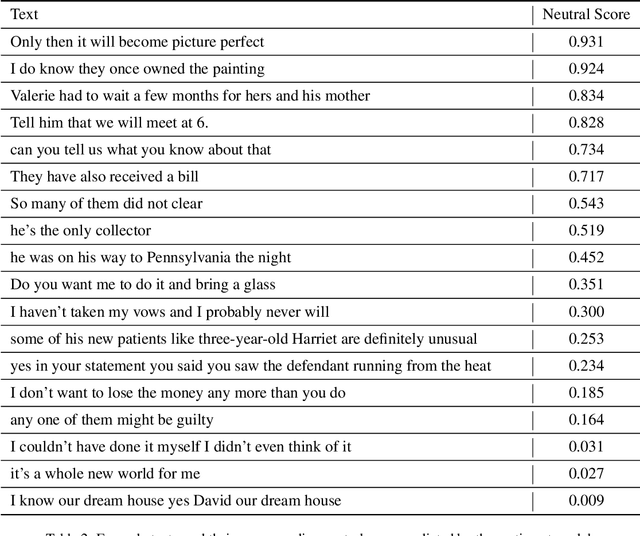
Emotion understanding is an essential but highly challenging component of artificial general intelligence. The absence of extensively annotated datasets has significantly impeded advancements in this field. We present EmotionCLIP, the first pre-training paradigm to extract visual emotion representations from verbal and nonverbal communication using only uncurated data. Compared to numerical labels or descriptions used in previous methods, communication naturally contains emotion information. Furthermore, acquiring emotion representations from communication is more congruent with the human learning process. We guide EmotionCLIP to attend to nonverbal emotion cues through subject-aware context encoding and verbal emotion cues using sentiment-guided contrastive learning. Extensive experiments validate the effectiveness and transferability of EmotionCLIP. Using merely linear-probe evaluation protocol, EmotionCLIP outperforms the state-of-the-art supervised visual emotion recognition methods and rivals many multimodal approaches across various benchmarks. We anticipate that the advent of EmotionCLIP will address the prevailing issue of data scarcity in emotion understanding, thereby fostering progress in related domains. The code and pre-trained models are available at https://github.com/Xeaver/EmotionCLIP.
Curriculum Modeling the Dependence among Targets with Multi-task Learning for Financial Marketing
Apr 25, 2023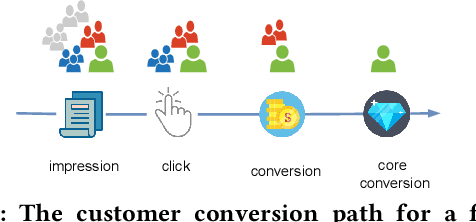
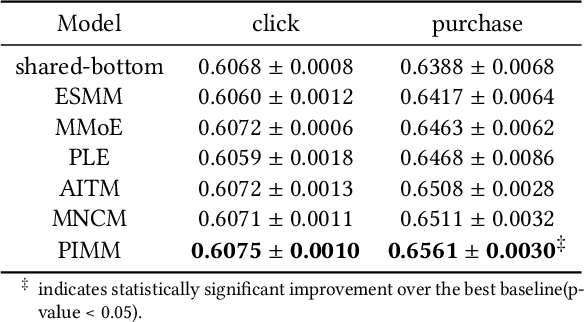
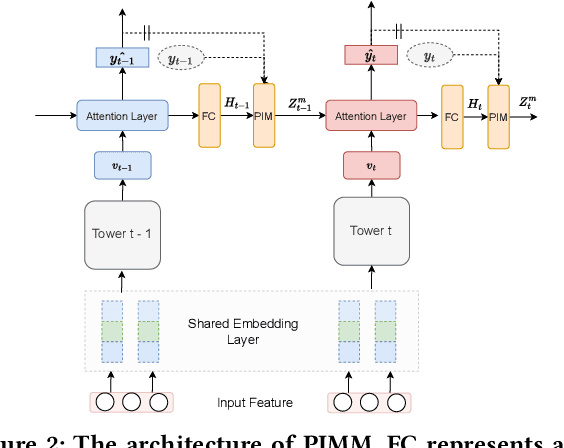
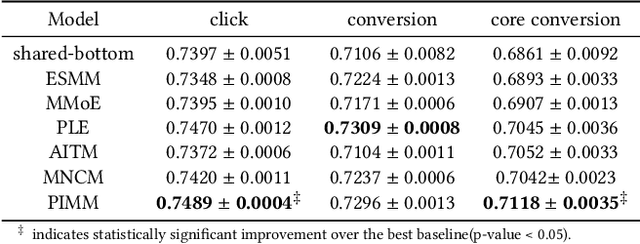
Multi-task learning for various real-world applications usually involves tasks with logical sequential dependence. For example, in online marketing, the cascade behavior pattern of $impression \rightarrow click \rightarrow conversion$ is usually modeled as multiple tasks in a multi-task manner, where the sequential dependence between tasks is simply connected with an explicitly defined function or implicitly transferred information in current works. These methods alleviate the data sparsity problem for long-path sequential tasks as the positive feedback becomes sparser along with the task sequence. However, the error accumulation and negative transfer will be a severe problem for downstream tasks. Especially, at the beginning stage of training, the optimization for parameters of former tasks is not converged yet, and thus the information transferred to downstream tasks is negative. In this paper, we propose a prior information merged model (\textbf{PIMM}), which explicitly models the logical dependence among tasks with a novel prior information merged (\textbf{PIM}) module for multiple sequential dependence task learning in a curriculum manner. Specifically, the PIM randomly selects the true label information or the prior task prediction with a soft sampling strategy to transfer to the downstream task during the training. Following an easy-to-difficult curriculum paradigm, we dynamically adjust the sampling probability to ensure that the downstream task will get the effective information along with the training. The offline experimental results on both public and product datasets verify that PIMM outperforms state-of-the-art baselines. Moreover, we deploy the PIMM in a large-scale FinTech platform, and the online experiments also demonstrate the effectiveness of PIMM.