 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Two Sides of One Coin: the Limits of Untuned SGD and the Power of Adaptive Methods
May 21, 2023
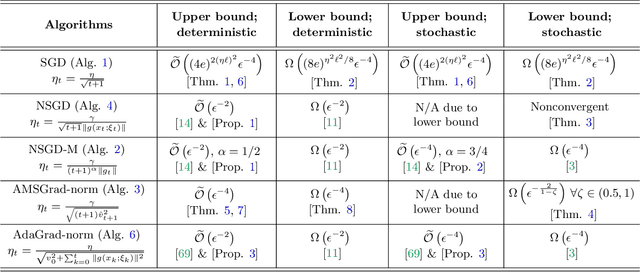
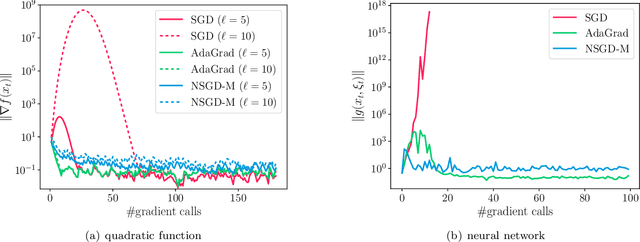
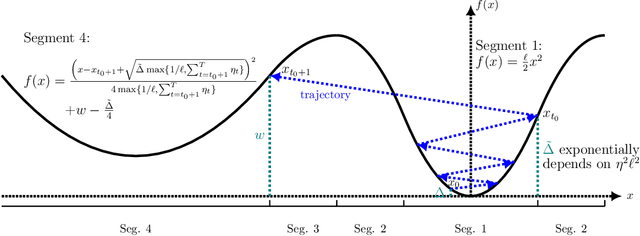
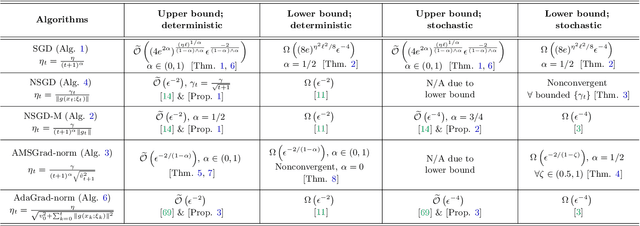
The classical analysis of Stochastic Gradient Descent (SGD) with polynomially decaying stepsize $\eta_t = \eta/\sqrt{t}$ relies on well-tuned $\eta$ depending on problem parameters such as Lipschitz smoothness constant, which is often unknown in practice. In this work, we prove that SGD with arbitrary $\eta > 0$, referred to as untuned SGD, still attains an order-optimal convergence rate $\widetilde{O}(T^{-1/4})$ in terms of gradient norm for minimizing smooth objectives. Unfortunately, it comes at the expense of a catastrophic exponential dependence on the smoothness constant, which we show is unavoidable for this scheme even in the noiseless setting. We then examine three families of adaptive methods $\unicode{x2013}$ Normalized SGD (NSGD), AMSGrad, and AdaGrad $\unicode{x2013}$ unveiling their power in preventing such exponential dependency in the absence of information about the smoothness parameter and boundedness of stochastic gradients. Our results provide theoretical justification for the advantage of adaptive methods over untuned SGD in alleviating the issue with large gradients.
PointSmile: Point Self-supervised Learning via Curriculum Mutual Information
Jan 30, 2023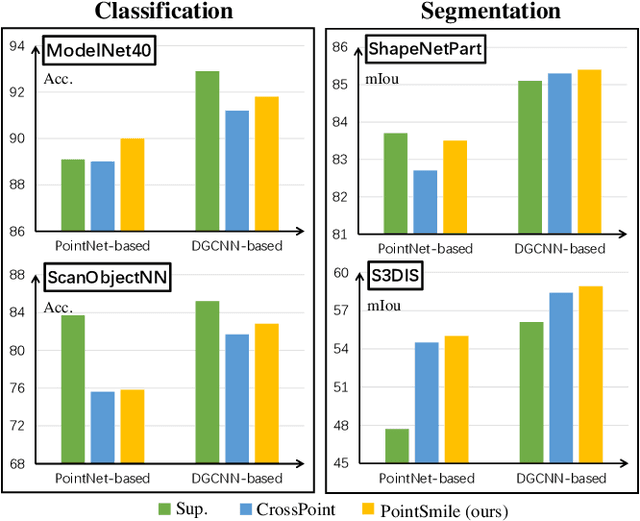
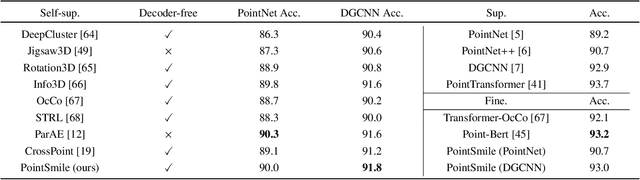
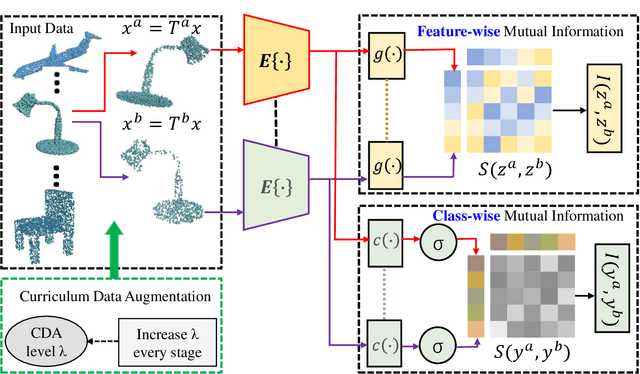
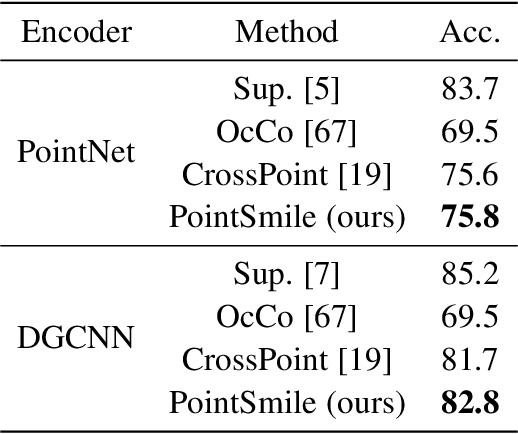
Self-supervised learning is attracting wide attention in point cloud processing. However, it is still not well-solved to gain discriminative and transferable features of point clouds for efficient training on downstream tasks, due to their natural sparsity and irregularity. We propose PointSmile, a reconstruction-free self-supervised learning paradigm by maximizing curriculum mutual information (CMI) across the replicas of point cloud objects. From the perspective of how-and-what-to-learn, PointSmile is designed to imitate human curriculum learning, i.e., starting with an easy curriculum and gradually increasing the difficulty of that curriculum. To solve "how-to-learn", we introduce curriculum data augmentation (CDA) of point clouds. CDA encourages PointSmile to learn from easy samples to hard ones, such that the latent space can be dynamically affected to create better embeddings. To solve "what-to-learn", we propose to maximize both feature- and class-wise CMI, for better extracting discriminative features of point clouds. Unlike most of existing methods, PointSmile does not require a pretext task, nor does it require cross-modal data to yield rich latent representations. We demonstrate the effectiveness and robustness of PointSmile in downstream tasks including object classification and segmentation. Extensive results show that our PointSmile outperforms existing self-supervised methods, and compares favorably with popular fully-supervised methods on various standard architectures.
Guided Focal Stack Refinement Network for Light Field Salient Object Detection
May 09, 2023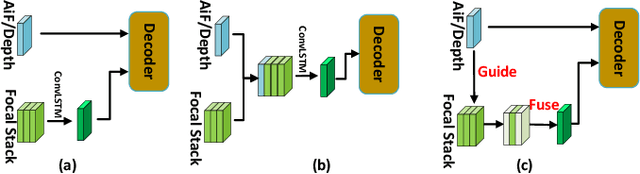
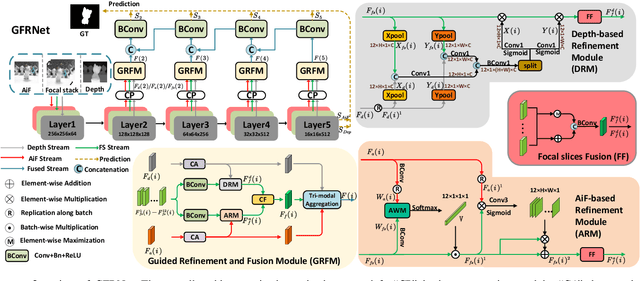
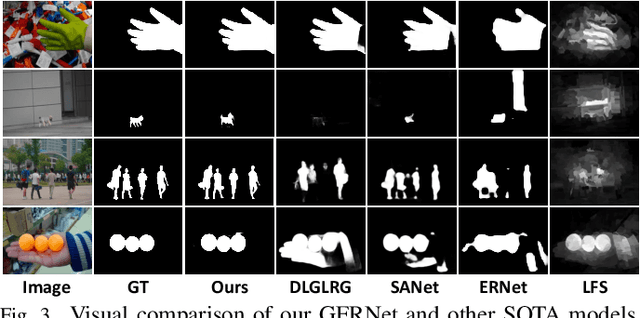
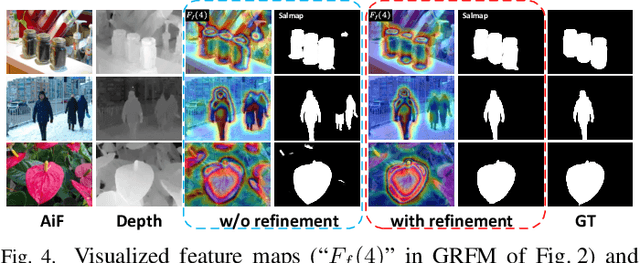
Light field salient object detection (SOD) is an emerging research direction attributed to the richness of light field data. However, most existing methods lack effective handling of focal stacks, therefore making the latter involved in a lot of interfering information and degrade the performance of SOD. To address this limitation, we propose to utilize multi-modal features to refine focal stacks in a guided manner, resulting in a novel guided focal stack refinement network called GFRNet. To this end, we propose a guided refinement and fusion module (GRFM) to refine focal stacks and aggregate multi-modal features. In GRFM, all-in-focus (AiF) and depth modalities are utilized to refine focal stacks separately, leading to two novel sub-modules for different modalities, namely AiF-based refinement module (ARM) and depth-based refinement module (DRM). Such refinement modules enhance structural and positional information of salient objects in focal stacks, and are able to improve SOD accuracy. Experimental results on four benchmark datasets demonstrate the superiority of our GFRNet model against 12 state-of-the-art models.
SRIL: Selective Regularization for Class-Incremental Learning
May 09, 2023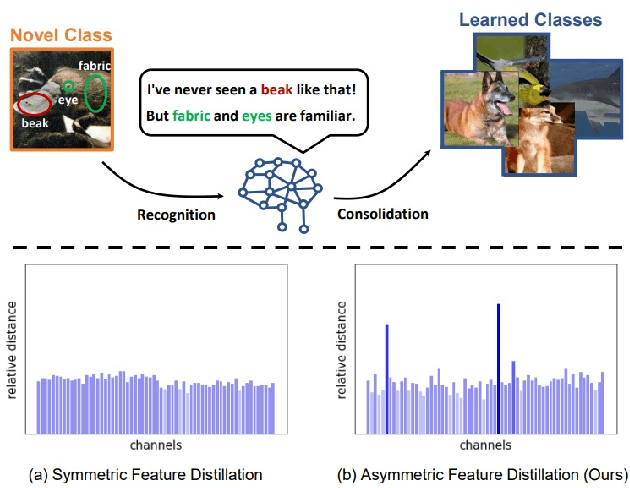
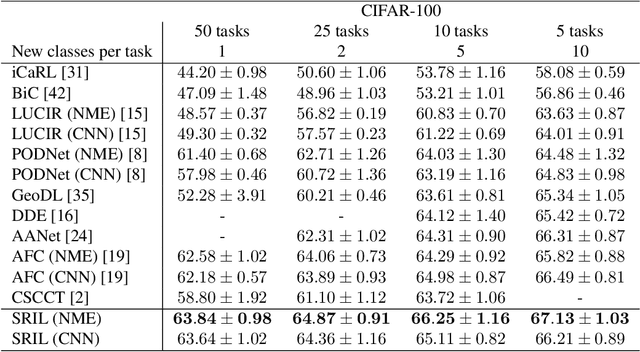
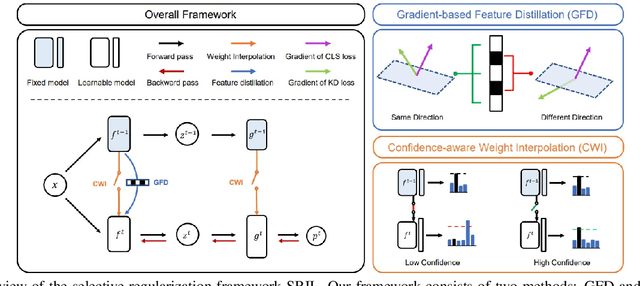
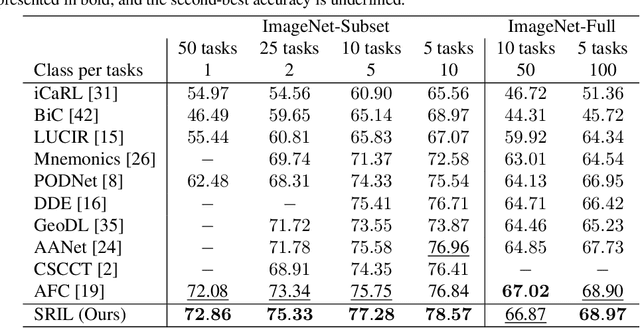
Human intelligence gradually accepts new information and accumulates knowledge throughout the lifespan. However, deep learning models suffer from a catastrophic forgetting phenomenon, where they forget previous knowledge when acquiring new information. Class-Incremental Learning aims to create an integrated model that balances plasticity and stability to overcome this challenge. In this paper, we propose a selective regularization method that accepts new knowledge while maintaining previous knowledge. We first introduce an asymmetric feature distillation method for old and new classes inspired by cognitive science, using the gradient of classification and knowledge distillation losses to determine whether to perform pattern completion or pattern separation. We also propose a method to selectively interpolate the weight of the previous model for a balance between stability and plasticity, and we adjust whether to transfer through model confidence to ensure the performance of the previous class and enable exploratory learning. We validate the effectiveness of the proposed method, which surpasses the performance of existing methods through extensive experimental protocols using CIFAR-100, ImageNet-Subset, and ImageNet-Full.
ACA-Net: Towards Lightweight Speaker Verification using Asymmetric Cross Attention
May 20, 2023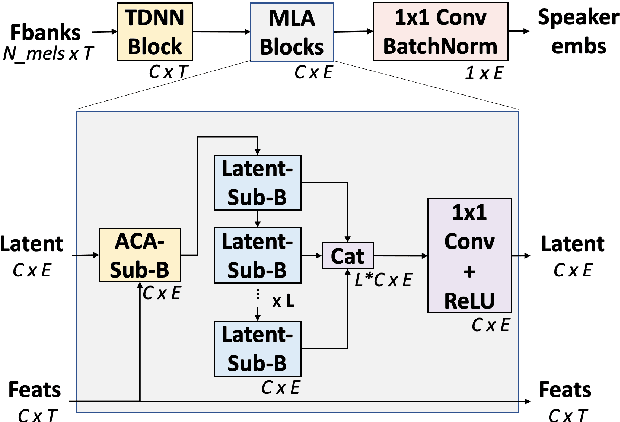
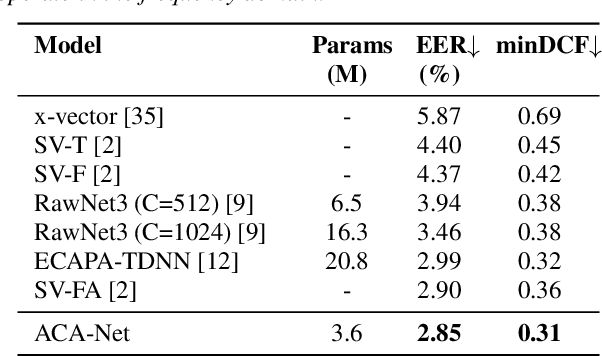
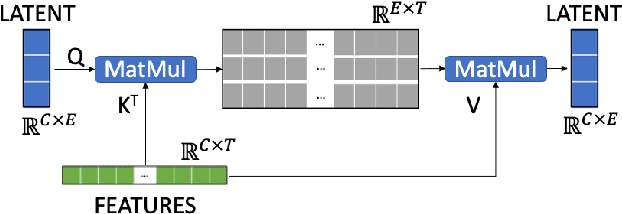
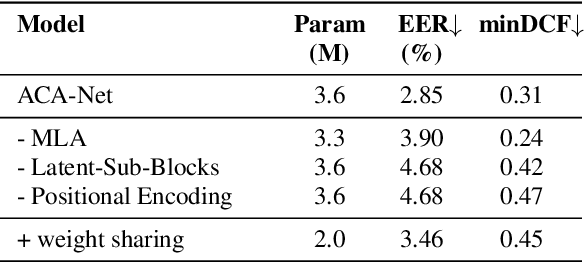
In this paper, we propose ACA-Net, a lightweight, global context-aware speaker embedding extractor for Speaker Verification (SV) that improves upon existing work by using Asymmetric Cross Attention (ACA) to replace temporal pooling. ACA is able to distill large, variable-length sequences into small, fixed-sized latents by attending a small query to large key and value matrices. In ACA-Net, we build a Multi-Layer Aggregation (MLA) block using ACA to generate fixed-sized identity vectors from variable-length inputs. Through global attention, ACA-Net acts as an efficient global feature extractor that adapts to temporal variability unlike existing SV models that apply a fixed function for pooling over the temporal dimension which may obscure information about the signal's non-stationary temporal variability. Our experiments on the WSJ0-1talker show ACA-Net outperforms a strong baseline by 5\% relative improvement in EER using only 1/5 of the parameters.
Chest X-ray Image Classification: A Causal Perspective
May 20, 2023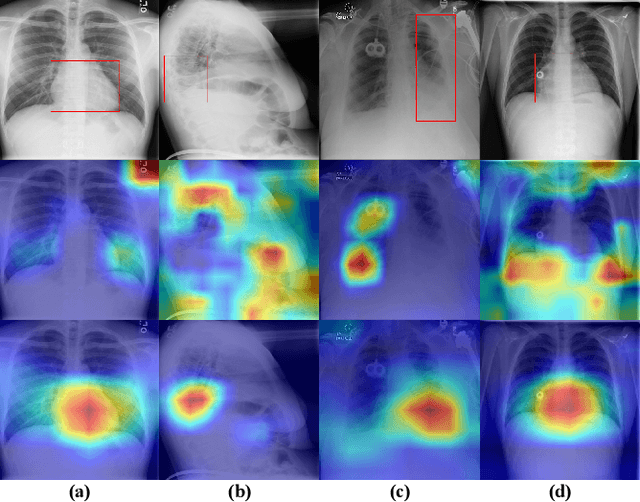
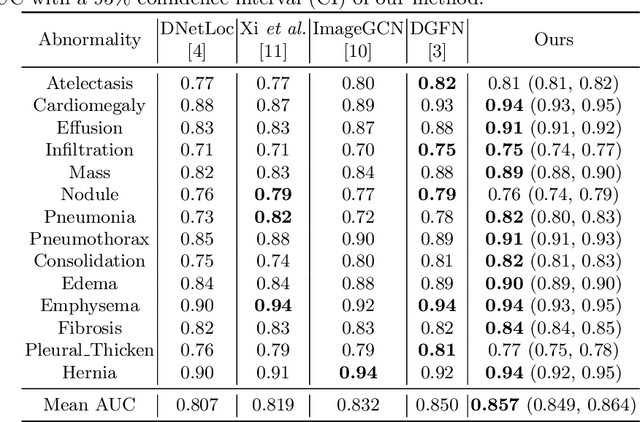
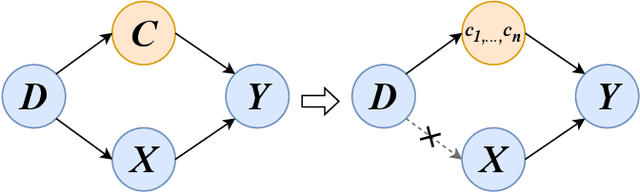
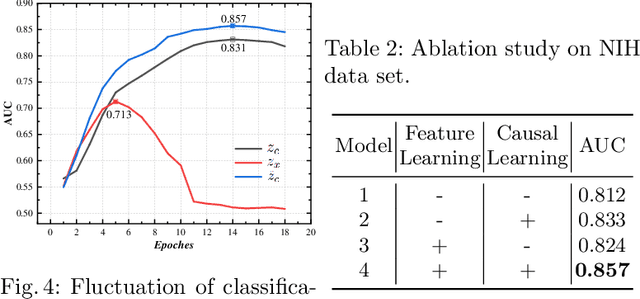
The chest X-ray (CXR) is one of the most common and easy-to-get medical tests used to diagnose common diseases of the chest. Recently, many deep learning-based methods have been proposed that are capable of effectively classifying CXRs. Even though these techniques have worked quite well, it is difficult to establish whether what these algorithms actually learn is the cause-and-effect link between diseases and their causes or just how to map labels to photos.In this paper, we propose a causal approach to address the CXR classification problem, which constructs a structural causal model (SCM) and uses the backdoor adjustment to select effective visual information for CXR classification. Specially, we design different probability optimization functions to eliminate the influence of confounders on the learning of real causality. Experimental results demonstrate that our proposed method outperforms the open-source NIH ChestX-ray14 in terms of classification performance.
Enhancing Indic Handwritten Text Recognition Using Global Semantic Information
Dec 15, 2022Handwritten Text Recognition (HTR) is more interesting and challenging than printed text due to uneven variations in the handwriting style of the writers, content, and time. HTR becomes more challenging for the Indic languages because of (i) multiple characters combined to form conjuncts which increase the number of characters of respective languages, and (ii) near to 100 unique basic Unicode characters in each Indic script. Recently, many recognition methods based on the encoder-decoder framework have been proposed to handle such problems. They still face many challenges, such as image blur and incomplete characters due to varying writing styles and ink density. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we enhance the performance of Indic handwritten text recognizers using global semantic information. We use a semantic module in an encoder-decoder framework for extracting global semantic information to recognize the Indic handwritten texts. The semantic information is used in both the encoder for supervision and the decoder for initialization. The semantic information is predicted from the word embedding of a pre-trained language model. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art results on handwritten texts of ten Indic languages.
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
May 22, 2023
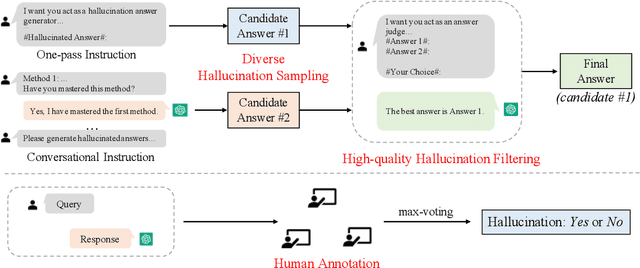

Large language models (LLMs), such as ChatGPT, are prone to generate hallucinations, \ie content that conflicts with the source or cannot be verified by the factual knowledge. To understand what types of content and to which extent LLMs are apt to hallucinate, we introduce the Hallucination Evaluation for Large Language Models (HaluEval) benchmark, a large collection of generated and human-annotated hallucinated samples for evaluating the performance of LLMs in recognizing hallucination. To generate these samples, we propose a ChatGPT-based two-step framework, \ie sampling-then-filtering. Besides, we also hire some human labelers to annotate the hallucinations in ChatGPT responses. The empirical results suggest that ChatGPT is likely to generate hallucinated content in specific topics by fabricating unverifiable information (\ie about $11.4\%$ user queries). Moreover, existing LLMs face great challenges in recognizing the hallucinations in texts. While, our experiments also prove that the hallucination recognition can be improved by providing external knowledge or adding reasoning steps. Our benchmark can be accessed at https://github.com/RUCAIBox/HaluEval.
DiffAVA: Personalized Text-to-Audio Generation with Visual Alignment
May 22, 2023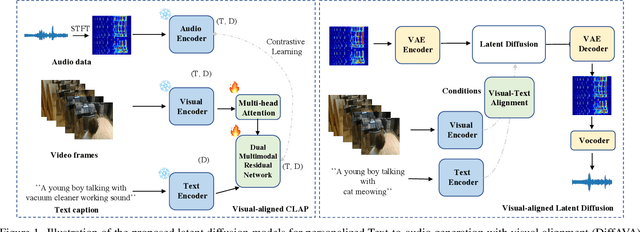


Text-to-audio (TTA) generation is a recent popular problem that aims to synthesize general audio given text descriptions. Previous methods utilized latent diffusion models to learn audio embedding in a latent space with text embedding as the condition. However, they ignored the synchronization between audio and visual content in the video, and tended to generate audio mismatching from video frames. In this work, we propose a novel and personalized text-to-sound generation approach with visual alignment based on latent diffusion models, namely DiffAVA, that can simply fine-tune lightweight visual-text alignment modules with frozen modality-specific encoders to update visual-aligned text embeddings as the condition. Specifically, our DiffAVA leverages a multi-head attention transformer to aggregate temporal information from video features, and a dual multi-modal residual network to fuse temporal visual representations with text embeddings. Then, a contrastive learning objective is applied to match visual-aligned text embeddings with audio features. Experimental results on the AudioCaps dataset demonstrate that the proposed DiffAVA can achieve competitive performance on visual-aligned text-to-audio generation.
Learning Emotion Representations from Verbal and Nonverbal Communication
May 22, 2023
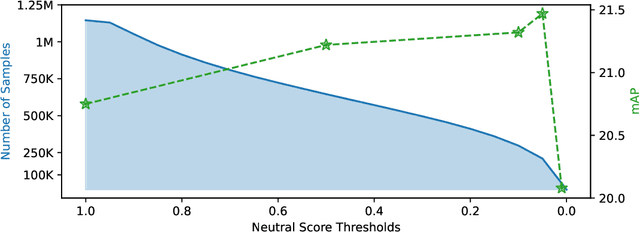
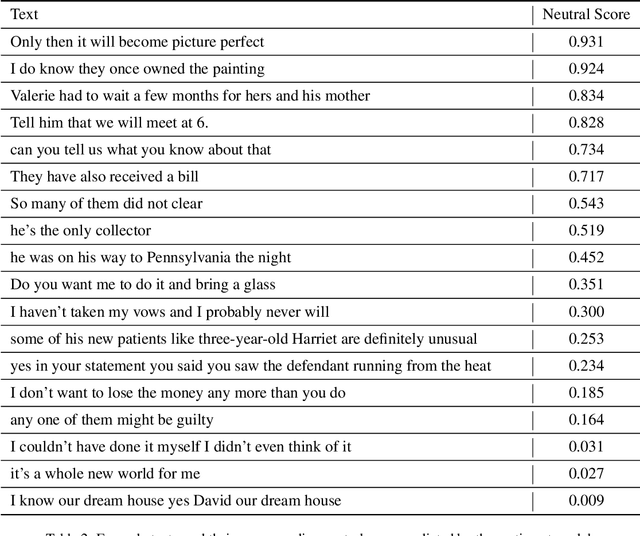
Emotion understanding is an essential but highly challenging component of artificial general intelligence. The absence of extensively annotated datasets has significantly impeded advancements in this field. We present EmotionCLIP, the first pre-training paradigm to extract visual emotion representations from verbal and nonverbal communication using only uncurated data. Compared to numerical labels or descriptions used in previous methods, communication naturally contains emotion information. Furthermore, acquiring emotion representations from communication is more congruent with the human learning process. We guide EmotionCLIP to attend to nonverbal emotion cues through subject-aware context encoding and verbal emotion cues using sentiment-guided contrastive learning. Extensive experiments validate the effectiveness and transferability of EmotionCLIP. Using merely linear-probe evaluation protocol, EmotionCLIP outperforms the state-of-the-art supervised visual emotion recognition methods and rivals many multimodal approaches across various benchmarks. We anticipate that the advent of EmotionCLIP will address the prevailing issue of data scarcity in emotion understanding, thereby fostering progress in related domains. The code and pre-trained models are available at https://github.com/Xeaver/EmotionCLIP.