 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Segmentation by Semantic Proportions
May 24, 2023
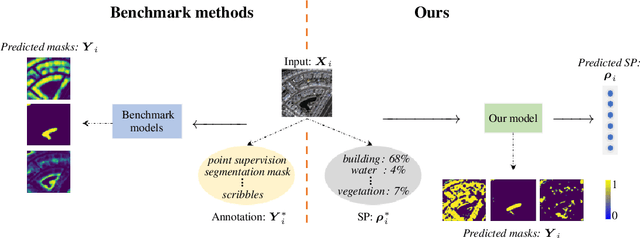
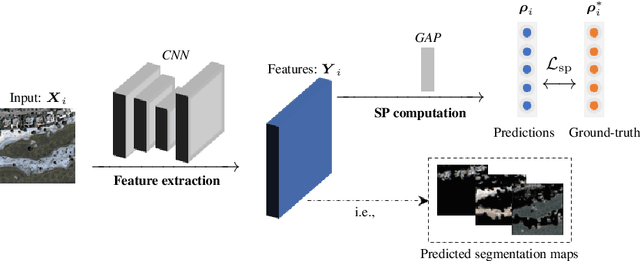
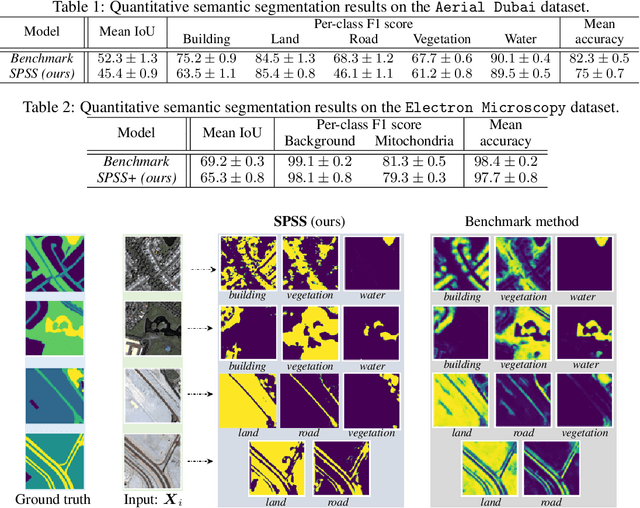
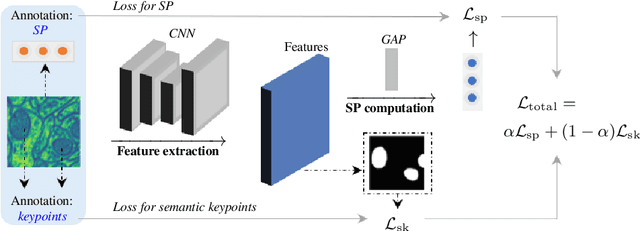
Semantic segmentation is a critical task in computer vision that aims to identify and classify individual pixels in an image, with numerous applications for example autonomous driving and medical image analysis. However, semantic segmentation can be super challenging particularly due to the need for large amounts of annotated data. Annotating images is a time-consuming and costly process, often requiring expert knowledge and significant effort. In this paper, we propose a novel approach for semantic segmentation by eliminating the need of ground-truth segmentation maps. Instead, our approach requires only the rough information of individual semantic class proportions, shortened as semantic proportions. It greatly simplifies the data annotation process and thus will significantly reduce the annotation time and cost, making it more feasible for large-scale applications. Moreover, it opens up new possibilities for semantic segmentation tasks where obtaining the full ground-truth segmentation maps may not be feasible or practical. Extensive experimental results demonstrate that our approach can achieve comparable and sometimes even better performance against the benchmark method that relies on the ground-truth segmentation maps. Utilising semantic proportions suggested in this work offers a promising direction for future research in the field of semantic segmentation.
A Tale of Two Features: Stable Diffusion Complements DINO for Zero-Shot Semantic Correspondence
May 24, 2023

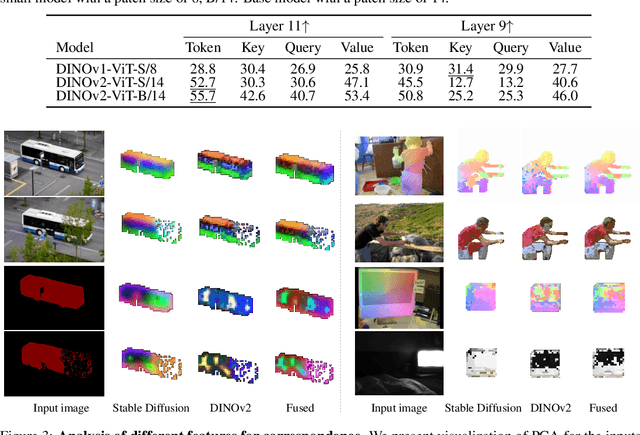
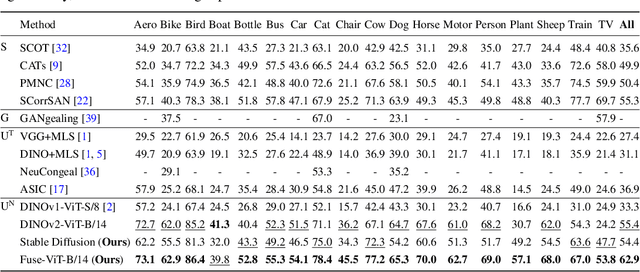
Text-to-image diffusion models have made significant advances in generating and editing high-quality images. As a result, numerous approaches have explored the ability of diffusion model features to understand and process single images for downstream tasks, e.g., classification, semantic segmentation, and stylization. However, significantly less is known about what these features reveal across multiple, different images and objects. In this work, we exploit Stable Diffusion (SD) features for semantic and dense correspondence and discover that with simple post-processing, SD features can perform quantitatively similar to SOTA representations. Interestingly, the qualitative analysis reveals that SD features have very different properties compared to existing representation learning features, such as the recently released DINOv2: while DINOv2 provides sparse but accurate matches, SD features provide high-quality spatial information but sometimes inaccurate semantic matches. We demonstrate that a simple fusion of these two features works surprisingly well, and a zero-shot evaluation using nearest neighbors on these fused features provides a significant performance gain over state-of-the-art methods on benchmark datasets, e.g., SPair-71k, PF-Pascal, and TSS. We also show that these correspondences can enable interesting applications such as instance swapping in two images.
Leveraging Future Relationship Reasoning for Vehicle Trajectory Prediction
May 24, 2023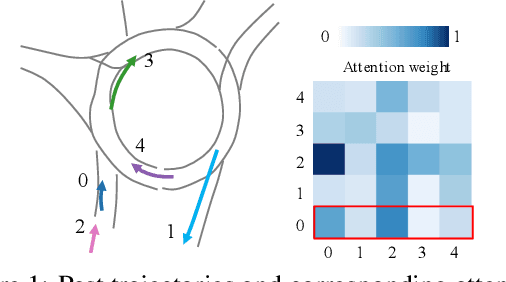
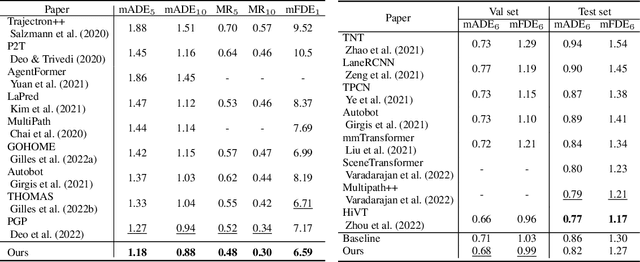
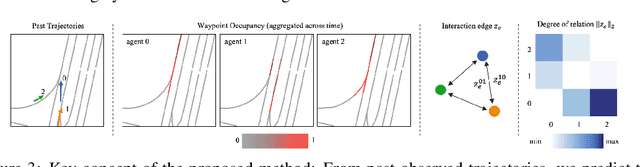
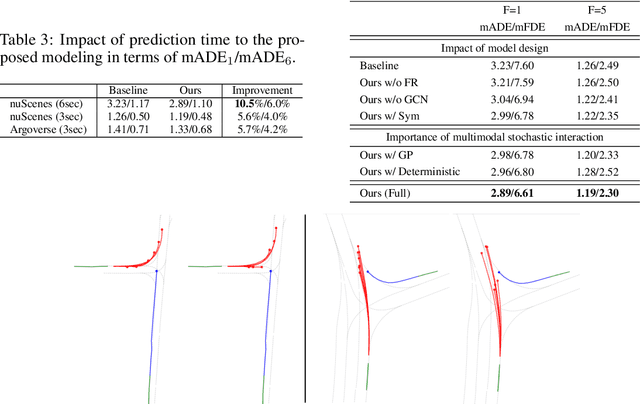
Understanding the interaction between multiple agents is crucial for realistic vehicle trajectory prediction. Existing methods have attempted to infer the interaction from the observed past trajectories of agents using pooling, attention, or graph-based methods, which rely on a deterministic approach. However, these methods can fail under complex road structures, as they cannot predict various interactions that may occur in the future. In this paper, we propose a novel approach that uses lane information to predict a stochastic future relationship among agents. To obtain a coarse future motion of agents, our method first predicts the probability of lane-level waypoint occupancy of vehicles. We then utilize the temporal probability of passing adjacent lanes for each agent pair, assuming that agents passing adjacent lanes will highly interact. We also model the interaction using a probabilistic distribution, which allows for multiple possible future interactions. The distribution is learned from the posterior distribution of interaction obtained from ground truth future trajectories. We validate our method on popular trajectory prediction datasets: nuScenes and Argoverse. The results show that the proposed method brings remarkable performance gain in prediction accuracy, and achieves state-of-the-art performance in long-term prediction benchmark dataset.
PaCE: Unified Multi-modal Dialogue Pre-training with Progressive and Compositional Experts
May 24, 2023
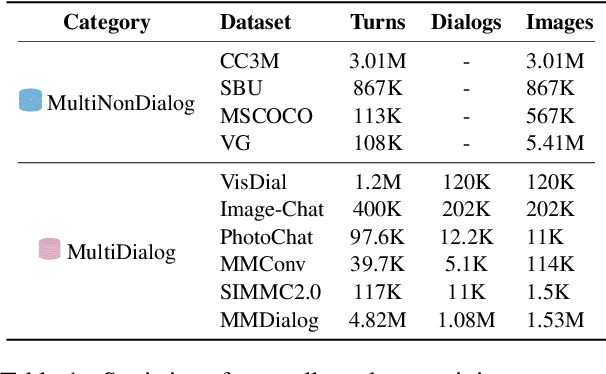
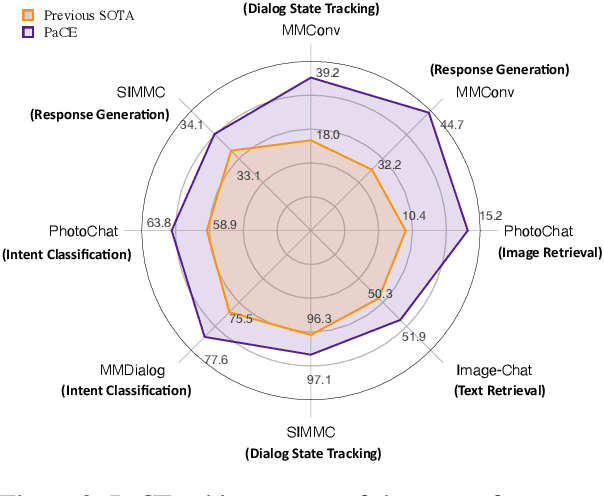
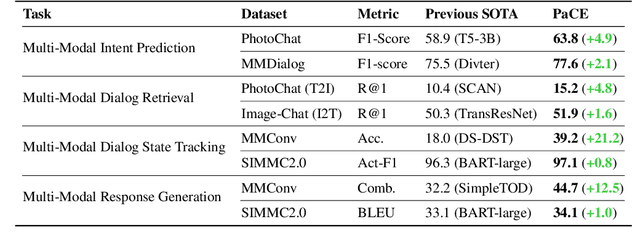
Perceiving multi-modal information and fulfilling dialogues with humans is a long-term goal of artificial intelligence. Pre-training is commonly regarded as an effective approach for multi-modal dialogue. However, due to the limited availability of multi-modal dialogue data, there is still scarce research on multi-modal dialogue pre-training. Yet another intriguing challenge emerges from the encompassing nature of multi-modal dialogue, which involves various modalities and tasks. Moreover, new forms of tasks may arise at unpredictable points in the future. Hence, it is essential for designed multi-modal dialogue models to possess sufficient flexibility to adapt to such scenarios. This paper proposes \textbf{PaCE}, a unified, structured, compositional multi-modal dialogue pre-training framework. It utilizes a combination of several fundamental experts to accommodate multiple dialogue-related tasks and can be pre-trained using limited dialogue and extensive non-dialogue multi-modal data. Furthermore, we propose a progressive training method where old experts from the past can assist new experts, facilitating the expansion of their capabilities. Experimental results demonstrate that PaCE achieves state-of-the-art results on eight multi-modal dialog benchmarks.
Transferring Visual Attributes from Natural Language to Verified Image Generation
May 24, 2023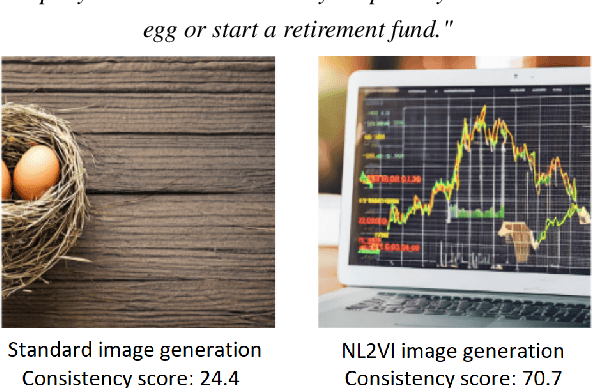

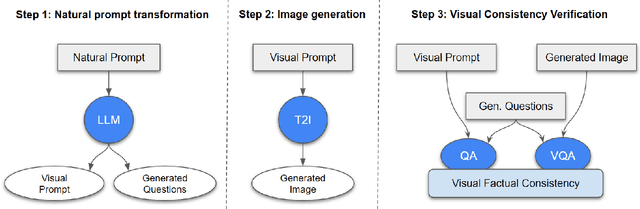
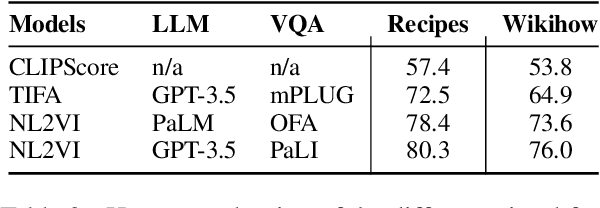
Text to image generation methods (T2I) are widely popular in generating art and other creative artifacts. While visual hallucinations can be a positive factor in scenarios where creativity is appreciated, such artifacts are poorly suited for cases where the generated image needs to be grounded in complex natural language without explicit visual elements. In this paper, we propose to strengthen the consistency property of T2I methods in the presence of natural complex language, which often breaks the limits of T2I methods by including non-visual information, and textual elements that require knowledge for accurate generation. To address these phenomena, we propose a Natural Language to Verified Image generation approach (NL2VI) that converts a natural prompt into a visual prompt, which is more suitable for image generation. A T2I model then generates an image for the visual prompt, which is then verified with VQA algorithms. Experimentally, aligning natural prompts with image generation can improve the consistency of the generated images by up to 11% over the state of the art. Moreover, improvements can generalize to challenging domains like cooking and DIY tasks, where the correctness of the generated image is crucial to illustrate actions.
Learning Semantic Role Labeling from Compatible Label Sequences
May 24, 2023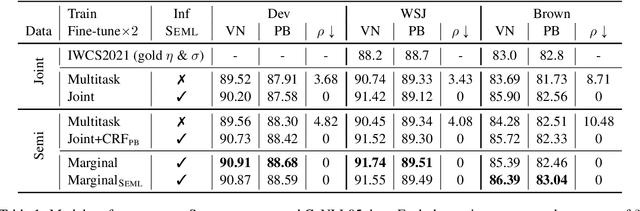
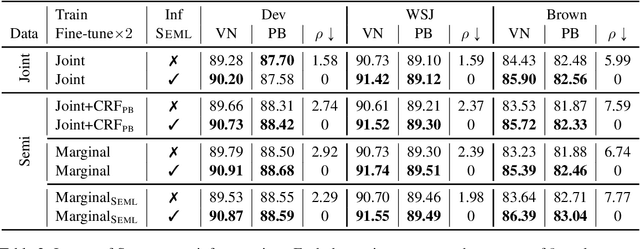
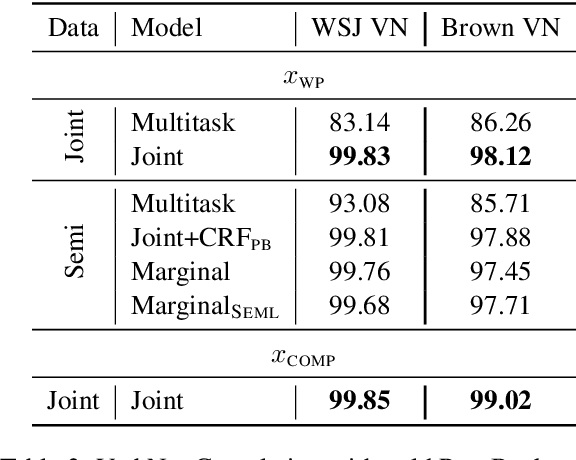
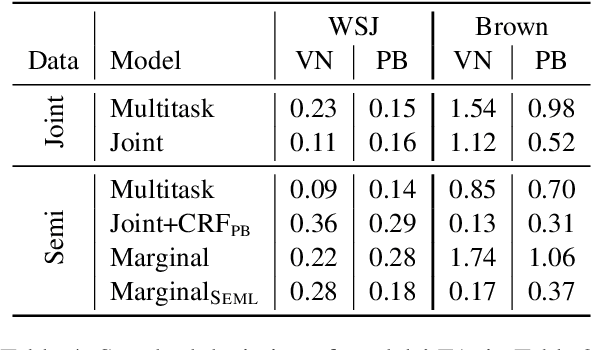
This paper addresses the question of how to efficiently learn from disjoint, compatible label sequences. We argue that the compatible structures between disjoint label sets help model learning and inference. We verify this hypothesis on the task of semantic role labeling (SRL), specifically, tagging a sentence with two role sequences: VerbNet arguments and PropBank arguments. Prior work has shown that cross-task interaction improves performance. However, the two tasks are still separately decoded, running the risk of generating structurally inconsistent label sequences (as per lexicons like SEMLINK). To eliminate this issue, we first propose a simple and effective setup that jointly handles VerbNet and PropBank labels as one sequence. With this setup, we show that enforcing SEMLINK constraints during decoding constantly improves the overall F1. With special input constructions, our joint model infers VerbNet arguments from PropBank arguments with over 99% accuracy. We also propose a constrained marginal model that uses SEMLINK information during training to further benefit from the large amounts of PropBank-only data. Our models achieve state-of-the-art F1's on VerbNet and PropBank argument labeling on the CoNLL05 dataset with strong out-of-domain generalization.
Radiomap Inpainting for Restricted Areas based on Propagation Priority and Depth Map
May 24, 2023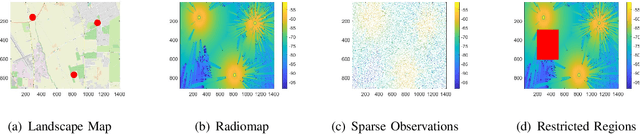
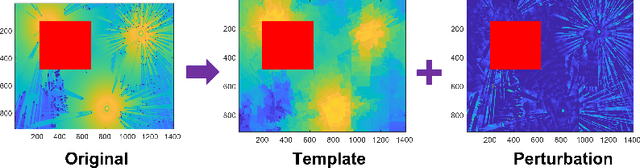
Providing rich and useful information regarding spectrum activities and propagation channels, radiomaps characterize the detailed distribution of power spectral density (PSD) and are important tools for network planning in modern wireless systems. Generally, radiomaps are constructed from radio strength measurements by deployed sensors and user devices. However, not all areas are accessible for radio measurements due to physical constraints and security consideration, leading to non-uniformly spaced measurements and blanks on a radiomap. In this work, we explore distribution of radio spectrum strengths in view of surrounding environments, and propose two radiomap inpainting approaches for the reconstruction of radiomaps that cover missing areas. Specifically, we first define a propagation-based priority and integrate exemplar-based inpainting with radio propagation model for fine-resolution small-size missing area reconstruction on a radiomap. Then, we introduce a novel radio depth map and propose a two-step template-perturbation approach for large-size restricted region inpainting. Our experimental results demonstrate the power of the proposed propagation priority and radio depth map in capturing the PSD distribution, as well as the efficacy of the proposed methods for radiomap reconstruction.
Localizing Multiple Radiation Sources Actively with a Particle Filter
May 24, 2023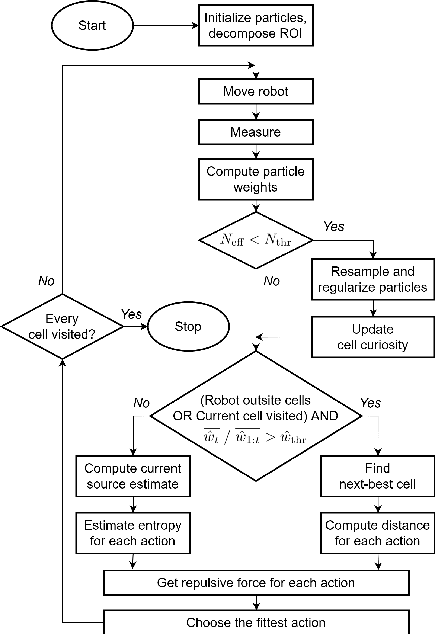
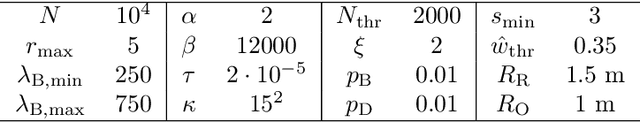
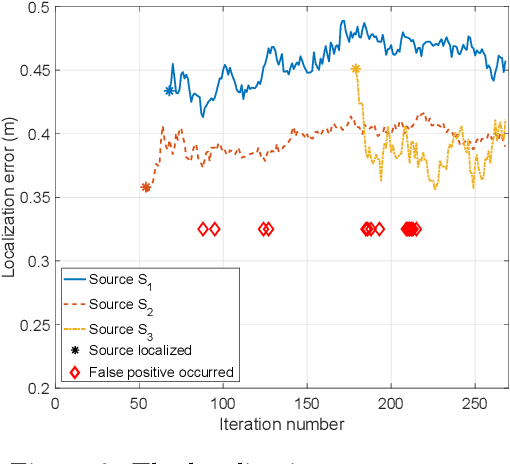
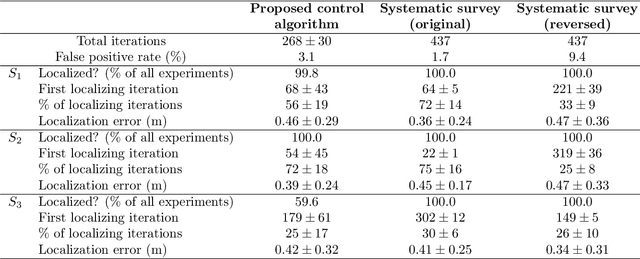
The article discusses the localization of radiation sources whose number and other relevant parameters are not known in advance. The data collection is ensured by an autonomous mobile robot that performs a survey in a defined region of interest populated with static obstacles. The measurement trajectory is information-driven rather than pre-planned. The localization exploits a regularized particle filter estimating the sources' parameters continuously. The dynamic robot control switches between two modes, one attempting to minimize the Shannon entropy and the other aiming to reduce the variance of expected measurements in unexplored parts of the target area; both of the modes maintain safe clearance from the obstacles. The performance of the algorithms was tested in a simulation study based on real-world data acquired previously from three radiation sources exhibiting various activities. Our approach reduces the time necessary to explore the region and to find the sources by approximately 40 %; at present, however, the method is unable to reliably localize sources that have a relatively low intensity. In this context, additional research has been planned to increase the credibility and robustness of the procedure and to improve the robotic platform autonomy.
ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers
May 24, 2023
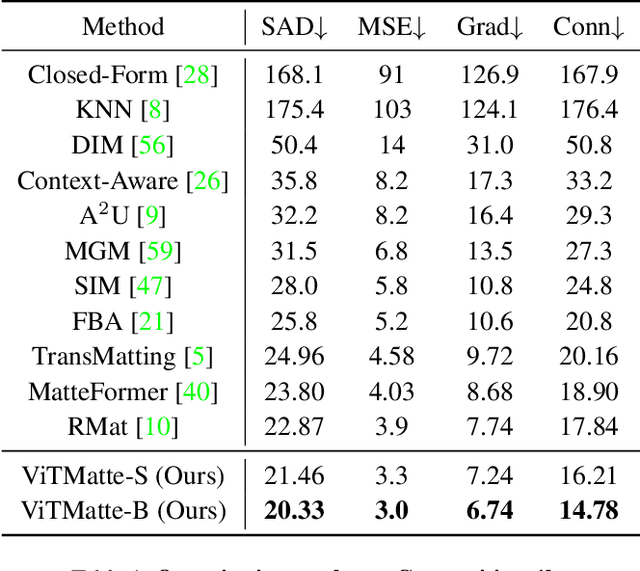
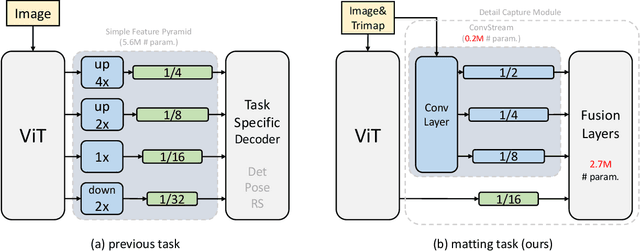
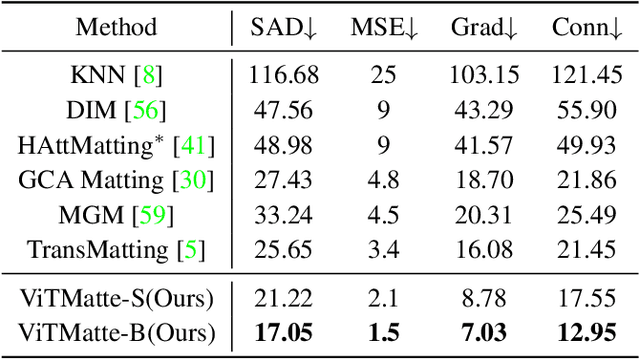
Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.
Mining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023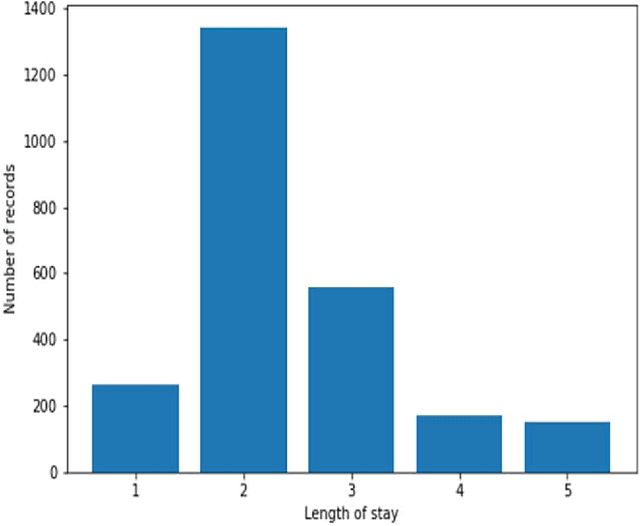
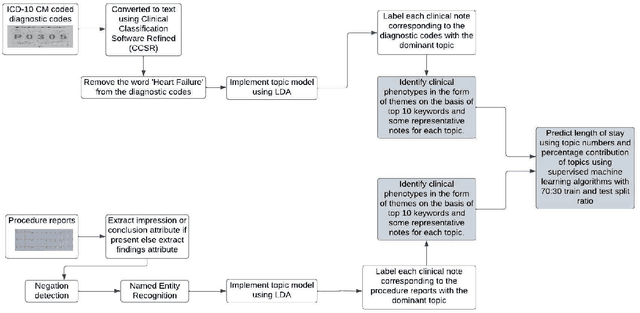

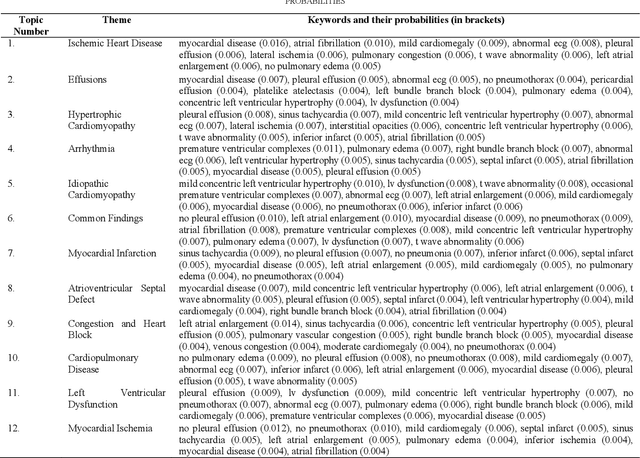
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.