 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ST-GIN: An Uncertainty Quantification Approach in Traffic Data Imputation with Spatio-temporal Graph Attention and Bidirectional Recurrent United Neural Networks
May 19, 2023
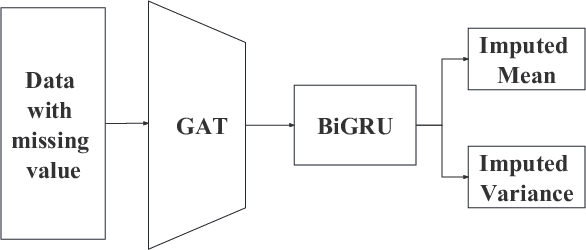
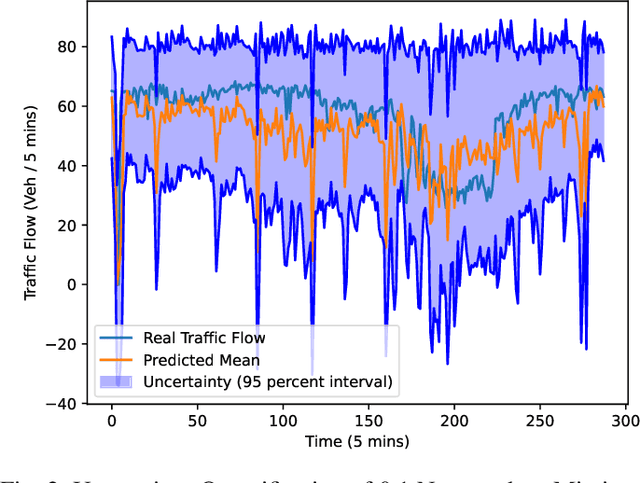
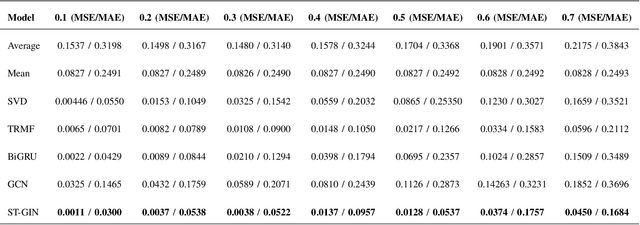
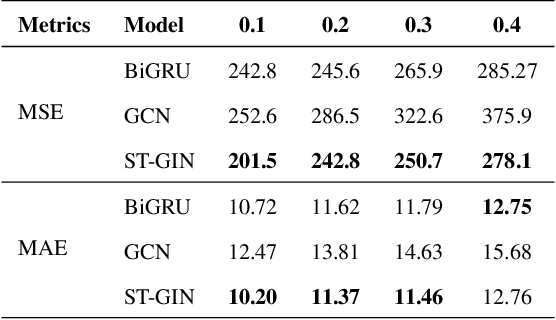
Traffic data serves as a fundamental component in both research and applications within intelligent transportation systems. However, real-world transportation data, collected from loop detectors or similar sources, often contain missing values (MVs), which can adversely impact associated applications and research. Instead of discarding this incomplete data, researchers have sought to recover these missing values through numerical statistics, tensor decomposition, and deep learning techniques. In this paper, we propose an innovative deep-learning approach for imputing missing data. A graph attention architecture is employed to capture the spatial correlations present in traffic data, while a bidirectional neural network is utilized to learn temporal information. Experimental results indicate that our proposed method outperforms all other benchmark techniques, thus demonstrating its effectiveness.
Graph Neural Network for spatiotemporal data: methods and applications
May 30, 2023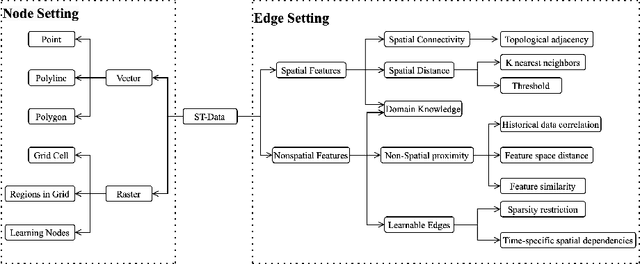

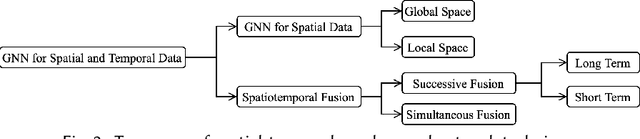
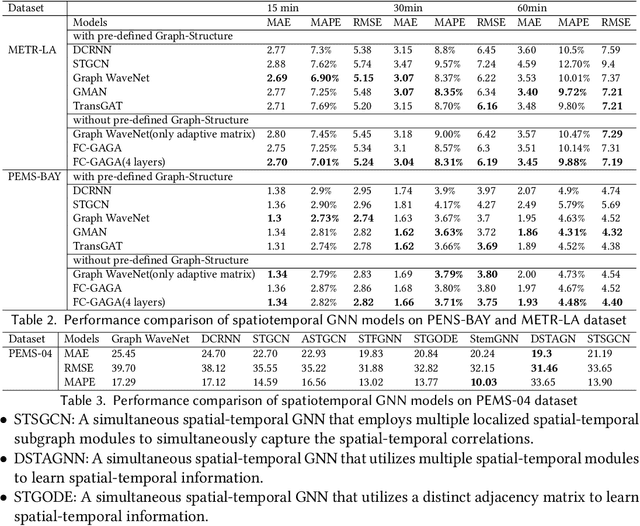
In the era of big data, there has been a surge in the availability of data containing rich spatial and temporal information, offering valuable insights into dynamic systems and processes for applications such as weather forecasting, natural disaster management, intelligent transport systems, and precision agriculture. Graph neural networks (GNNs) have emerged as a powerful tool for modeling and understanding data with dependencies to each other such as spatial and temporal dependencies. There is a large amount of existing work that focuses on addressing the complex spatial and temporal dependencies in spatiotemporal data using GNNs. However, the strong interdisciplinary nature of spatiotemporal data has created numerous GNNs variants specifically designed for distinct application domains. Although the techniques are generally applicable across various domains, cross-referencing these methods remains essential yet challenging due to the absence of a comprehensive literature review on GNNs for spatiotemporal data. This article aims to provide a systematic and comprehensive overview of the technologies and applications of GNNs in the spatiotemporal domain. First, the ways of constructing graphs from spatiotemporal data are summarized to help domain experts understand how to generate graphs from various types of spatiotemporal data. Then, a systematic categorization and summary of existing spatiotemporal GNNs are presented to enable domain experts to identify suitable techniques and to support model developers in advancing their research. Moreover, a comprehensive overview of significant applications in the spatiotemporal domain is offered to introduce a broader range of applications to model developers and domain experts, assisting them in exploring potential research topics and enhancing the impact of their work. Finally, open challenges and future directions are discussed.
Multi-source adversarial transfer learning for ultrasound image segmentation with limited similarity
May 30, 2023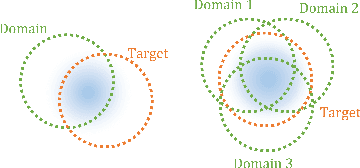
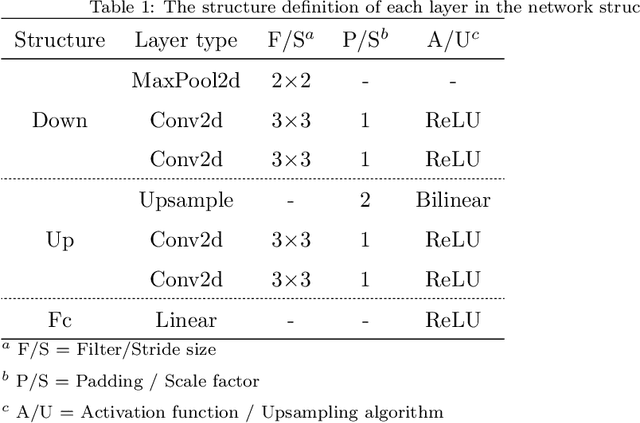
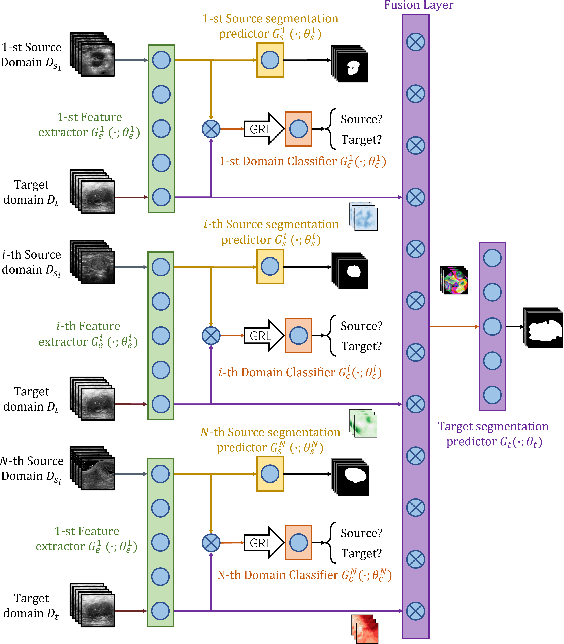
Lesion segmentation of ultrasound medical images based on deep learning techniques is a widely used method for diagnosing diseases. Although there is a large amount of ultrasound image data in medical centers and other places, labeled ultrasound datasets are a scarce resource, and it is likely that no datasets are available for new tissues/organs. Transfer learning provides the possibility to solve this problem, but there are too many features in natural images that are not related to the target domain. As a source domain, redundant features that are not conducive to the task will be extracted. Migration between ultrasound images can avoid this problem, but there are few types of public datasets, and it is difficult to find sufficiently similar source domains. Compared with natural images, ultrasound images have less information, and there are fewer transferable features between different ultrasound images, which may cause negative transfer. To this end, a multi-source adversarial transfer learning network for ultrasound image segmentation is proposed. Specifically, to address the lack of annotations, the idea of adversarial transfer learning is used to adaptively extract common features between a certain pair of source and target domains, which provides the possibility to utilize unlabeled ultrasound data. To alleviate the lack of knowledge in a single source domain, multi-source transfer learning is adopted to fuse knowledge from multiple source domains. In order to ensure the effectiveness of the fusion and maximize the use of precious data, a multi-source domain independent strategy is also proposed to improve the estimation of the target domain data distribution, which further increases the learning ability of the multi-source adversarial migration learning network in multiple domains.
Fourier-DeepONet: Fourier-enhanced deep operator networks for full waveform inversion with improved accuracy, generalizability, and robustness
May 26, 2023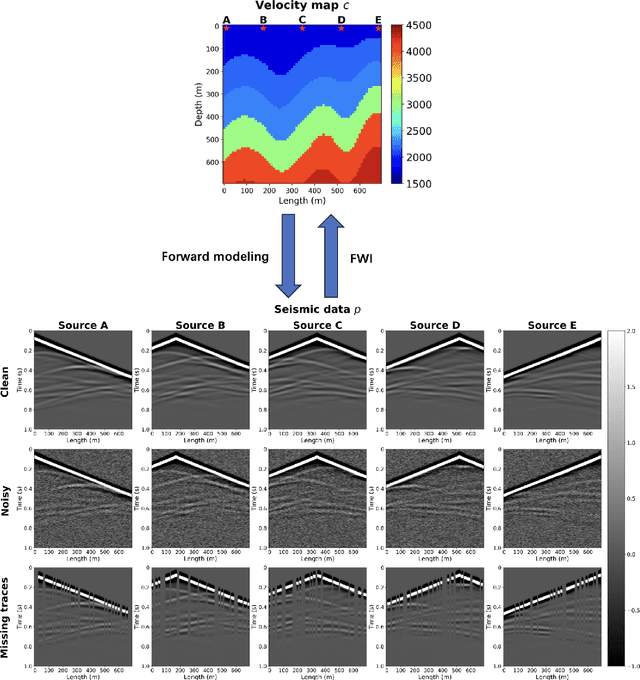

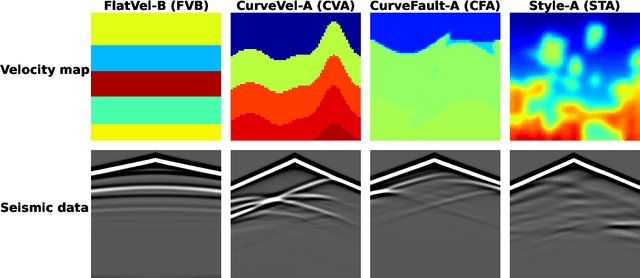

Full waveform inversion (FWI) infers the subsurface structure information from seismic waveform data by solving a non-convex optimization problem. Data-driven FWI has been increasingly studied with various neural network architectures to improve accuracy and computational efficiency. Nevertheless, the applicability of pre-trained neural networks is severely restricted by potential discrepancies between the source function used in the field survey and the one utilized during training. Here, we develop a Fourier-enhanced deep operator network (Fourier-DeepONet) for FWI with the generalization of seismic sources, including the frequencies and locations of sources. Specifically, we employ the Fourier neural operator as the decoder of DeepONet, and we utilize source parameters as one input of Fourier-DeepONet, facilitating the resolution of FWI with variable sources. To test Fourier-DeepONet, we develop two new and realistic FWI benchmark datasets (FWI-F and FWI-L) with varying source frequencies and locations. Our experiments demonstrate that compared with existing data-driven FWI methods, Fourier-DeepONet obtains more accurate predictions of subsurface structures in a wide range of source parameters. Moreover, the proposed Fourier-DeepONet exhibits superior robustness when dealing with noisy inputs or inputs with missing traces, paving the way for more reliable and accurate subsurface imaging across diverse real conditions.
Parameter-Efficient Fine-Tuning without Introducing New Latency
May 26, 2023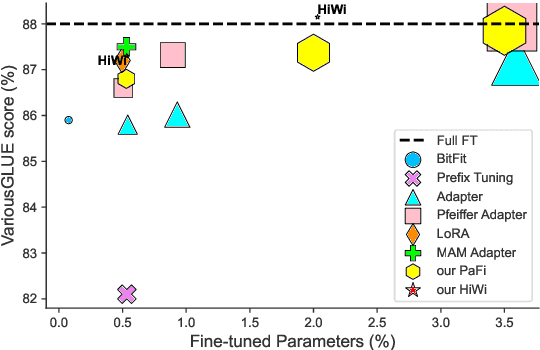
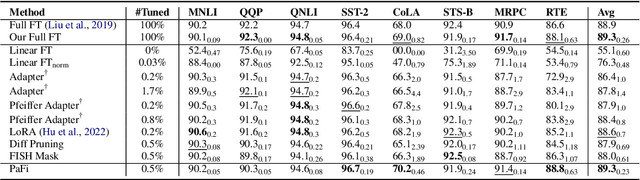
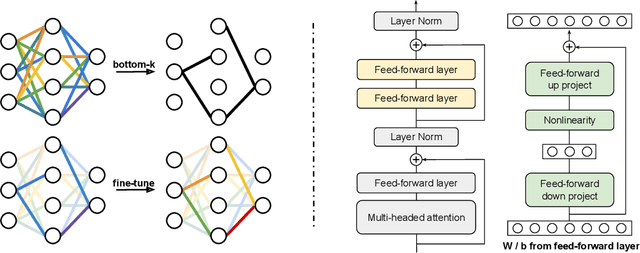
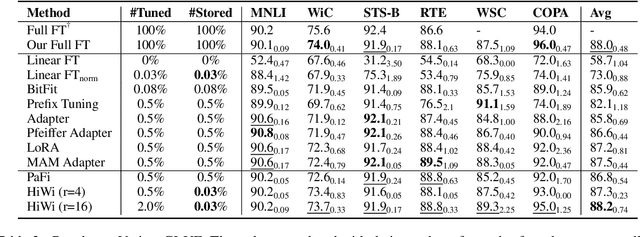
Parameter-efficient fine-tuning (PEFT) of pre-trained language models has recently demonstrated remarkable achievements, effectively matching the performance of full fine-tuning while utilizing significantly fewer trainable parameters, and consequently addressing the storage and communication constraints. Nonetheless, various PEFT methods are limited by their inherent characteristics. In the case of sparse fine-tuning, which involves modifying only a small subset of the existing parameters, the selection of fine-tuned parameters is task- and domain-specific, making it unsuitable for federated learning. On the other hand, PEFT methods with adding new parameters typically introduce additional inference latency. In this paper, we demonstrate the feasibility of generating a sparse mask in a task-agnostic manner, wherein all downstream tasks share a common mask. Our approach, which relies solely on the magnitude information of pre-trained parameters, surpasses existing methodologies by a significant margin when evaluated on the GLUE benchmark. Additionally, we introduce a novel adapter technique that directly applies the adapter to pre-trained parameters instead of the hidden representation, thereby achieving identical inference speed to that of full fine-tuning. Through extensive experiments, our proposed method attains a new state-of-the-art outcome in terms of both performance and storage efficiency, storing only 0.03% parameters of full fine-tuning.
Conjunct Resolution in the Face of Verbal Omissions
May 26, 2023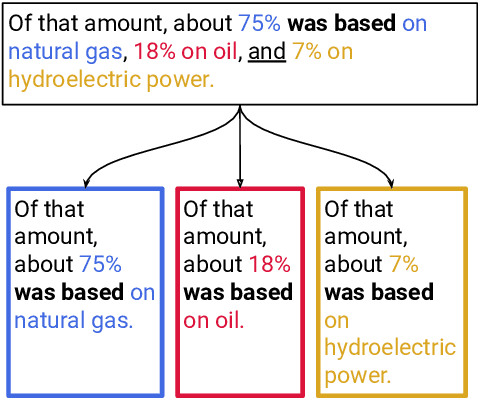
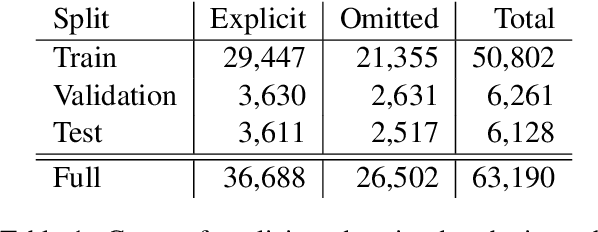
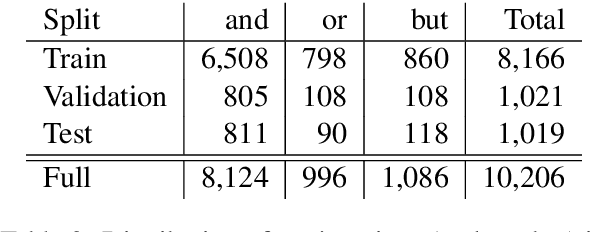
Verbal omissions are complex syntactic phenomena in VP coordination structures. They occur when verbs and (some of) their arguments are omitted from subsequent clauses after being explicitly stated in an initial clause. Recovering these omitted elements is necessary for accurate interpretation of the sentence, and while humans easily and intuitively fill in the missing information, state-of-the-art models continue to struggle with this task. Previous work is limited to small-scale datasets, synthetic data creation methods, and to resolution methods in the dependency-graph level. In this work we propose a conjunct resolution task that operates directly on the text and makes use of a split-and-rephrase paradigm in order to recover the missing elements in the coordination structure. To this end, we first formulate a pragmatic framework of verbal omissions which describes the different types of omissions, and develop an automatic scalable collection method. Based on this method, we curate a large dataset, containing over 10K examples of naturally-occurring verbal omissions with crowd-sourced annotations of the resolved conjuncts. We train various neural baselines for this task, and show that while our best method obtains decent performance, it leaves ample space for improvement. We propose our dataset, metrics and models as a starting point for future research on this topic.
Emergent Agentic Transformer from Chain of Hindsight Experience
May 26, 2023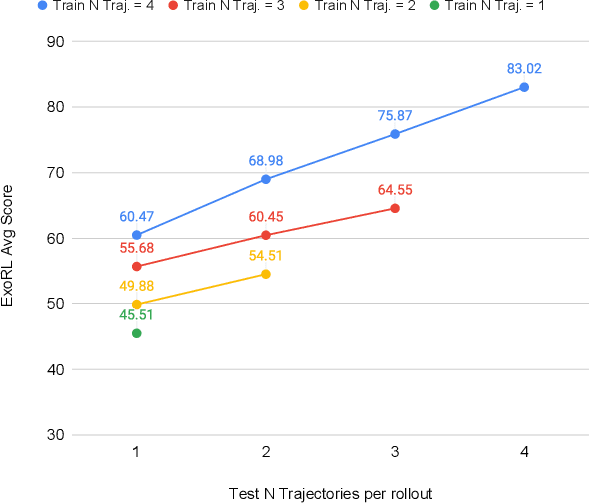

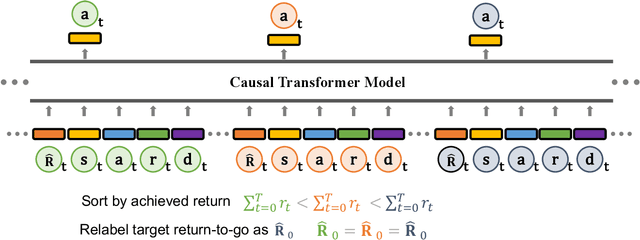
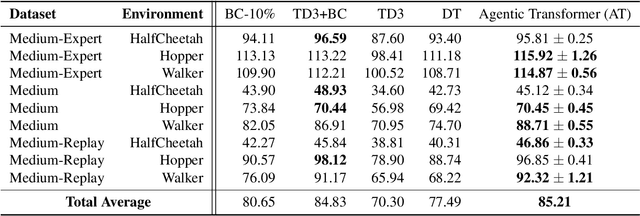
Large transformer models powered by diverse data and model scale have dominated natural language modeling and computer vision and pushed the frontier of multiple AI areas. In reinforcement learning (RL), despite many efforts into transformer-based policies, a key limitation, however, is that current transformer-based policies cannot learn by directly combining information from multiple sub-optimal trials. In this work, we address this issue using recently proposed chain of hindsight to relabel experience, where we train a transformer on a sequence of trajectory experience ascending sorted according to their total rewards. Our method consists of relabelling target return of each trajectory to the maximum total reward among in sequence of trajectories and training an autoregressive model to predict actions conditioning on past states, actions, rewards, target returns, and task completion tokens, the resulting model, Agentic Transformer (AT), can learn to improve upon itself both at training and test time. As we show on D4RL and ExoRL benchmarks, to the best our knowledge, this is the first time that a simple transformer-based model performs competitively with both temporal-difference and imitation-learning-based approaches, even from sub-optimal data. Our Agentic Transformer also shows a promising scaling trend that bigger models consistently improve results.
D-CALM: A Dynamic Clustering-based Active Learning Approach for Mitigating Bias
May 26, 2023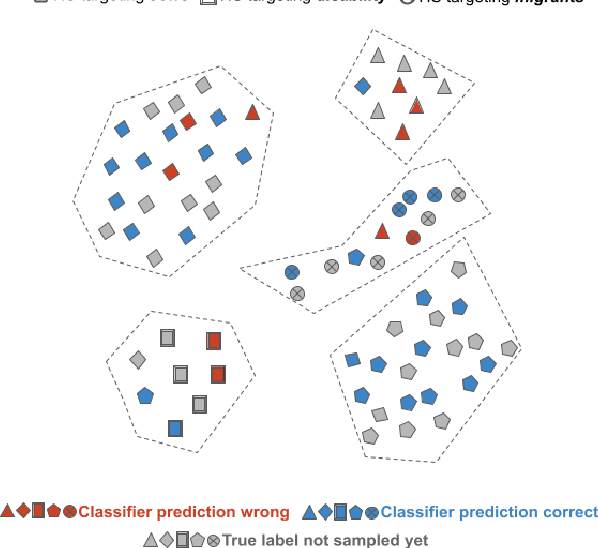
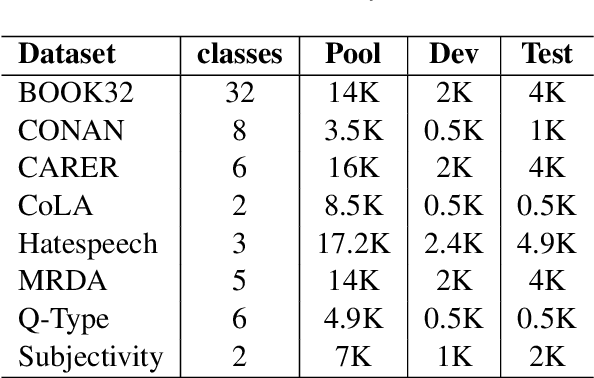
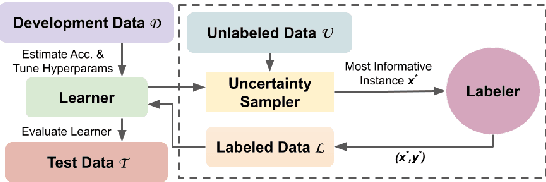
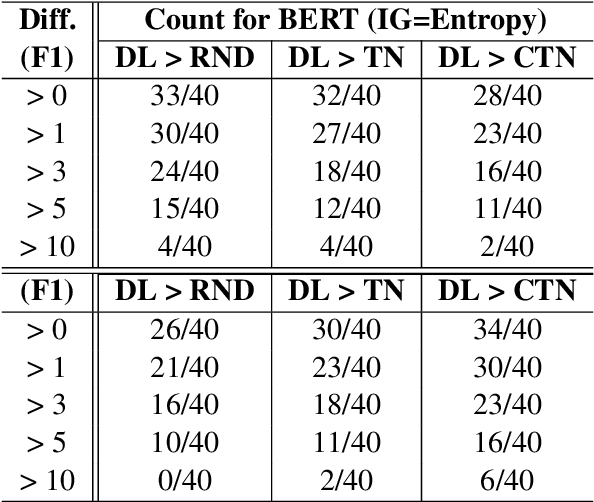
Despite recent advancements, NLP models continue to be vulnerable to bias. This bias often originates from the uneven distribution of real-world data and can propagate through the annotation process. Escalated integration of these models in our lives calls for methods to mitigate bias without overbearing annotation costs. While active learning (AL) has shown promise in training models with a small amount of annotated data, AL's reliance on the model's behavior for selective sampling can lead to an accumulation of unwanted bias rather than bias mitigation. However, infusing clustering with AL can overcome the bias issue of both AL and traditional annotation methods while exploiting AL's annotation efficiency. In this paper, we propose a novel adaptive clustering-based active learning algorithm, D-CALM, that dynamically adjusts clustering and annotation efforts in response to an estimated classifier error-rate. Experiments on eight datasets for a diverse set of text classification tasks, including emotion, hatespeech, dialog act, and book type detection, demonstrate that our proposed algorithm significantly outperforms baseline AL approaches with both pretrained transformers and traditional Support Vector Machines. D-CALM showcases robustness against different measures of information gain and, as evident from our analysis of label and error distribution, can significantly reduce unwanted model bias.
Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models
May 29, 2023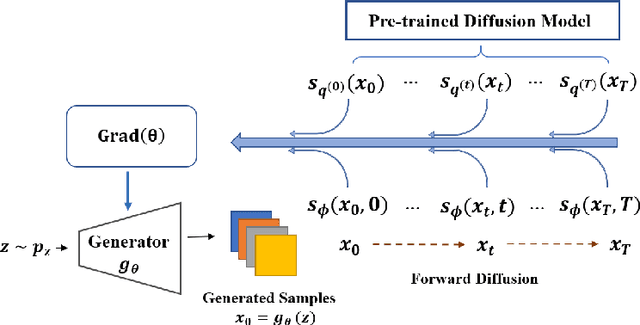
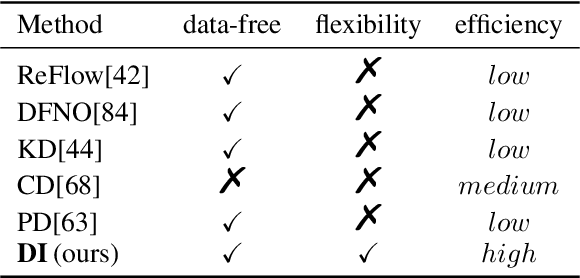

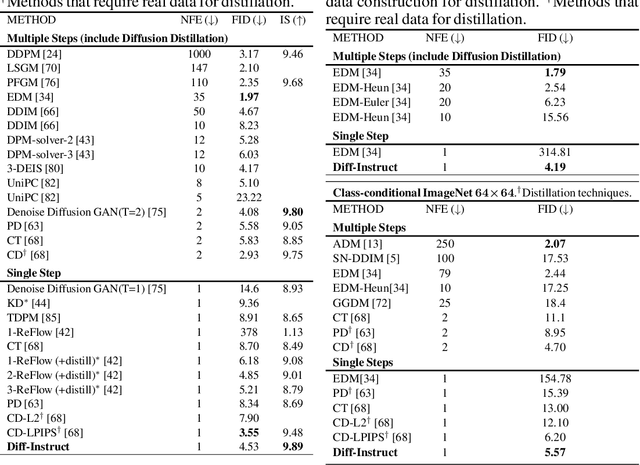
Due to the ease of training, ability to scale, and high sample quality, diffusion models (DMs) have become the preferred option for generative modeling, with numerous pre-trained models available for a wide variety of datasets. Containing intricate information about data distributions, pre-trained DMs are valuable assets for downstream applications. In this work, we consider learning from pre-trained DMs and transferring their knowledge to other generative models in a data-free fashion. Specifically, we propose a general framework called Diff-Instruct to instruct the training of arbitrary generative models as long as the generated samples are differentiable with respect to the model parameters. Our proposed Diff-Instruct is built on a rigorous mathematical foundation where the instruction process directly corresponds to minimizing a novel divergence we call Integral Kullback-Leibler (IKL) divergence. IKL is tailored for DMs by calculating the integral of the KL divergence along a diffusion process, which we show to be more robust in comparing distributions with misaligned supports. We also reveal non-trivial connections of our method to existing works such as DreamFusion, and generative adversarial training. To demonstrate the effectiveness and universality of Diff-Instruct, we consider two scenarios: distilling pre-trained diffusion models and refining existing GAN models. The experiments on distilling pre-trained diffusion models show that Diff-Instruct results in state-of-the-art single-step diffusion-based models. The experiments on refining GAN models show that the Diff-Instruct can consistently improve the pre-trained generators of GAN models across various settings.
Generating Topic Pages for Scientific Concepts Using Scientific Publications
Apr 24, 2023In this paper, we describe Topic Pages, an inventory of scientific concepts and information around them extracted from a large collection of scientific books and journals. The main aim of Topic Pages is to provide all the necessary information to the readers to understand scientific concepts they come across while reading scholarly content in any scientific domain. Topic Pages are a collection of automatically generated information pages using NLP and ML, each corresponding to a scientific concept. Each page contains three pieces of information: a definition, related concepts, and the most relevant snippets, all extracted from scientific peer-reviewed publications. In this paper, we discuss the details of different components to extract each of these elements. The collection of pages in production contains over 360,000 Topic Pages across 20 different scientific domains with an average of 23 million unique visits per month, constituting it a popular source for scientific information.