 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Drafting Event Schemas using Language Models
May 24, 2023

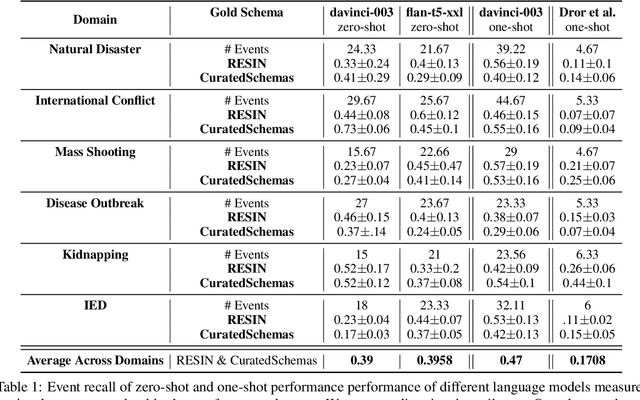
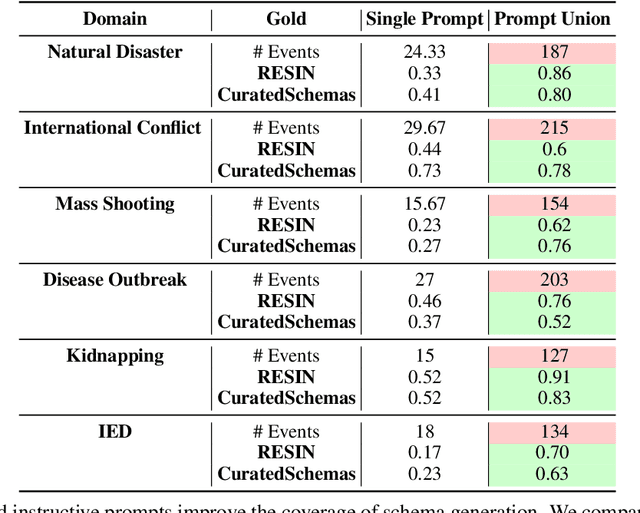
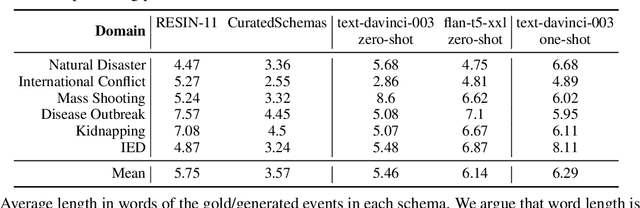
Past work has studied event prediction and event language modeling, sometimes mediated through structured representations of knowledge in the form of event schemas. Such schemas can lead to explainable predictions and forecasting of unseen events given incomplete information. In this work, we look at the process of creating such schemas to describe complex events. We use large language models (LLMs) to draft schemas directly in natural language, which can be further refined by human curators as necessary. Our focus is on whether we can achieve sufficient diversity and recall of key events and whether we can produce the schemas in a sufficiently descriptive style. We show that large language models are able to achieve moderate recall against schemas taken from two different datasets, with even better results when multiple prompts and multiple samples are combined. Moreover, we show that textual entailment methods can be used for both matching schemas to instances of events as well as evaluating overlap between gold and predicted schemas. Our method paves the way for easier distillation of event knowledge from large language model into schemas.
Pre-training Multi-party Dialogue Models with Latent Discourse Inference
May 24, 2023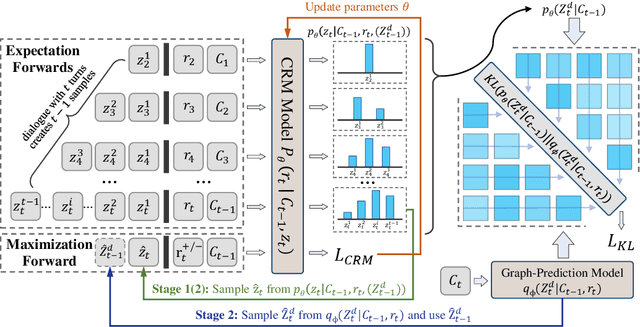



Multi-party dialogues are more difficult for models to understand than one-to-one two-party dialogues, since they involve multiple interlocutors, resulting in interweaving reply-to relations and information flows. To step over these obstacles, an effective way is to pre-train a model that understands the discourse structure of multi-party dialogues, namely, to whom each utterance is replying. However, due to the lack of explicitly annotated discourse labels in multi-party dialogue corpora, previous works fail to scale up the pre-training process by putting aside the unlabeled multi-party conversational data for nothing. To fully utilize the unlabeled data, we propose to treat the discourse structures as latent variables, then jointly infer them and pre-train the discourse-aware model by unsupervised latent variable inference methods. Experiments on multiple downstream tasks show that our pre-trained model outperforms strong baselines by large margins and achieves state-of-the-art (SOTA) results, justifying the effectiveness of our method. The official implementation of this paper is available at https://github.com/EricLee8/MPD_EMVI.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
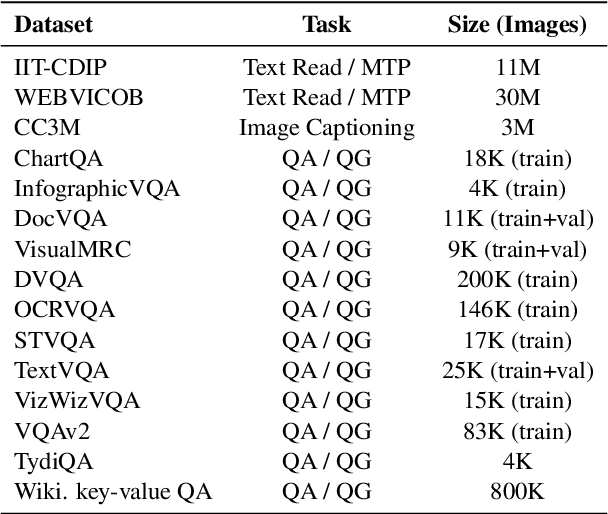
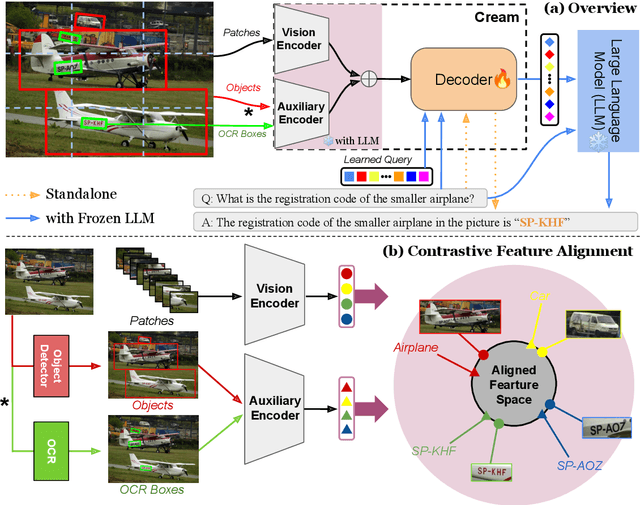

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream
Human-Centered Metrics for Dialog System Evaluation
May 24, 2023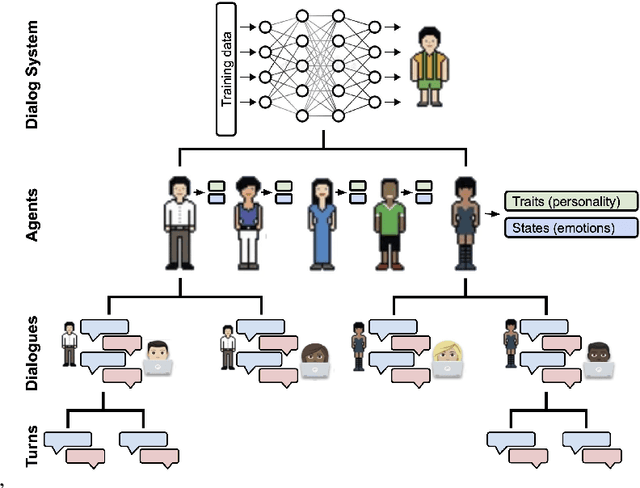
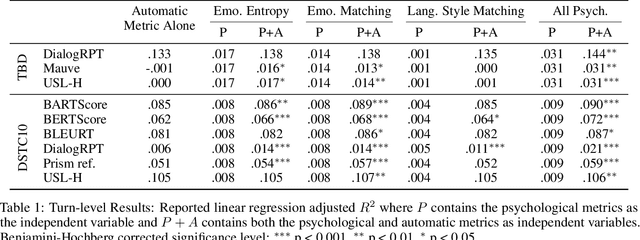
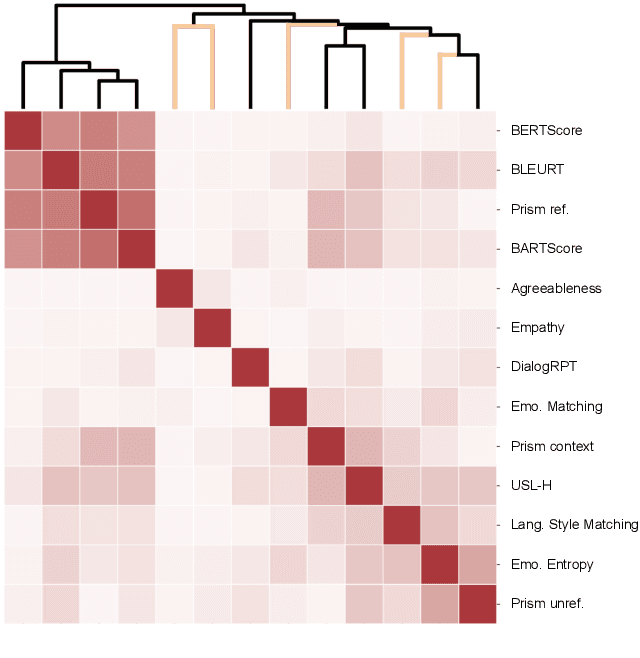
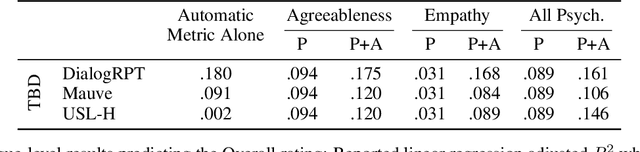
We present metrics for evaluating dialog systems through a psychologically-grounded "human" lens: conversational agents express a diversity of both states (short-term factors like emotions) and traits (longer-term factors like personality) just as people do. These interpretable metrics consist of five measures from established psychology constructs that can be applied both across dialogs and on turns within dialogs: emotional entropy, linguistic style and emotion matching, as well as agreeableness and empathy. We compare these human metrics against 6 state-of-the-art automatic metrics (e.g. BARTScore and BLEURT) on 7 standard dialog system data sets. We also introduce a novel data set, the Three Bot Dialog Evaluation Corpus, which consists of annotated conversations from ChatGPT, GPT-3, and BlenderBot. We demonstrate the proposed human metrics offer novel information, are uncorrelated with automatic metrics, and lead to increased accuracy beyond existing automatic metrics for predicting crowd-sourced dialog judgements. The interpretability and unique signal of our proposed human-centered framework make it a valuable tool for evaluating and improving dialog systems.
PastNet: Introducing Physical Inductive Biases for Spatio-temporal Video Prediction
May 24, 2023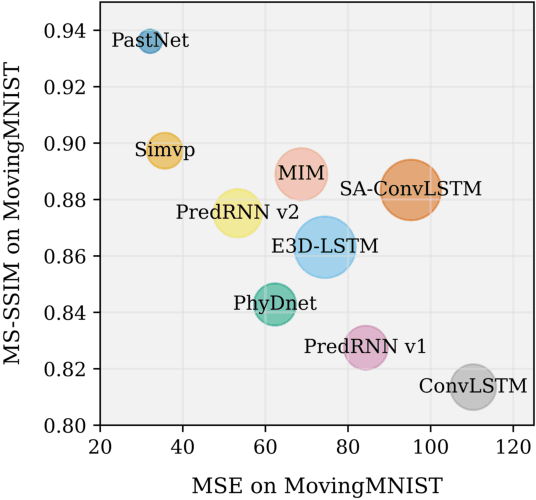
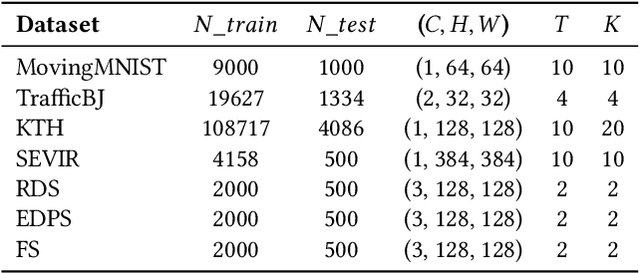
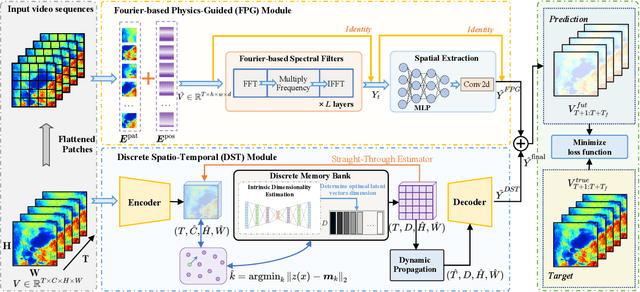
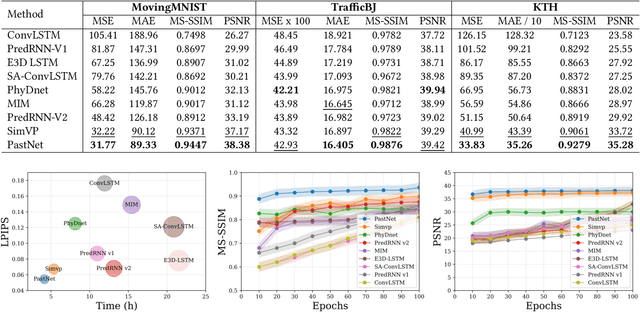
In this paper, we investigate the challenge of spatio-temporal video prediction, which involves generating future videos based on historical data streams. Existing approaches typically utilize external information such as semantic maps to enhance video prediction, which often neglect the inherent physical knowledge embedded within videos. Furthermore, their high computational demands could impede their applications for high-resolution videos. To address these constraints, we introduce a novel approach called Physics-assisted Spatio-temporal Network (PastNet) for generating high-quality video predictions. The core of our PastNet lies in incorporating a spectral convolution operator in the Fourier domain, which efficiently introduces inductive biases from the underlying physical laws. Additionally, we employ a memory bank with the estimated intrinsic dimensionality to discretize local features during the processing of complex spatio-temporal signals, thereby reducing computational costs and facilitating efficient high-resolution video prediction. Extensive experiments on various widely-used datasets demonstrate the effectiveness and efficiency of the proposed PastNet compared with state-of-the-art methods, particularly in high-resolution scenarios. Our code is available at https://github.com/easylearningscores/PastNet.
Inverse Preference Learning: Preference-based RL without a Reward Function
May 24, 2023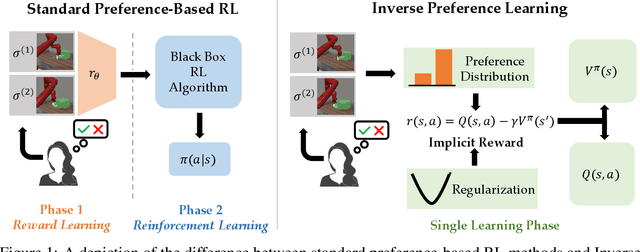
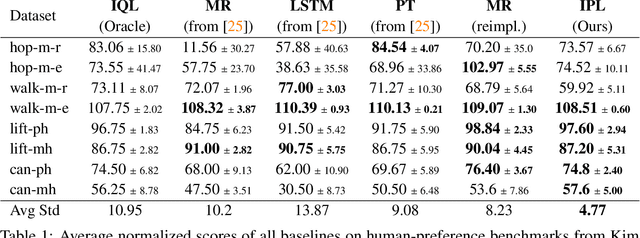
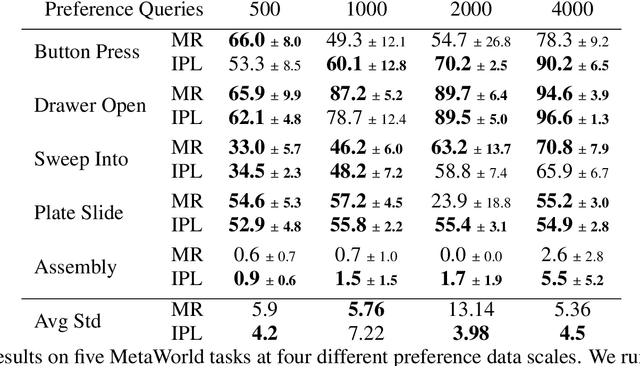
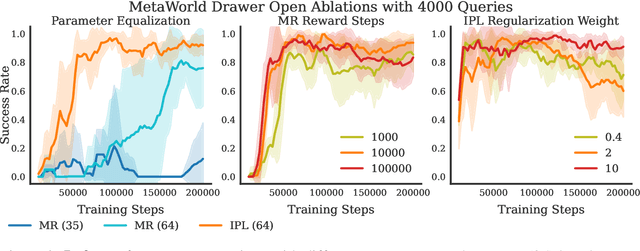
Reward functions are difficult to design and often hard to align with human intent. Preference-based Reinforcement Learning (RL) algorithms address these problems by learning reward functions from human feedback. However, the majority of preference-based RL methods na\"ively combine supervised reward models with off-the-shelf RL algorithms. Contemporary approaches have sought to improve performance and query complexity by using larger and more complex reward architectures such as transformers. Instead of using highly complex architectures, we develop a new and parameter-efficient algorithm, Inverse Preference Learning (IPL), specifically designed for learning from offline preference data. Our key insight is that for a fixed policy, the $Q$-function encodes all information about the reward function, effectively making them interchangeable. Using this insight, we completely eliminate the need for a learned reward function. Our resulting algorithm is simpler and more parameter-efficient. Across a suite of continuous control and robotics benchmarks, IPL attains competitive performance compared to more complex approaches that leverage transformer-based and non-Markovian reward functions while having fewer algorithmic hyperparameters and learned network parameters. Our code is publicly released.
Adversarial robustness of amortized Bayesian inference
May 24, 2023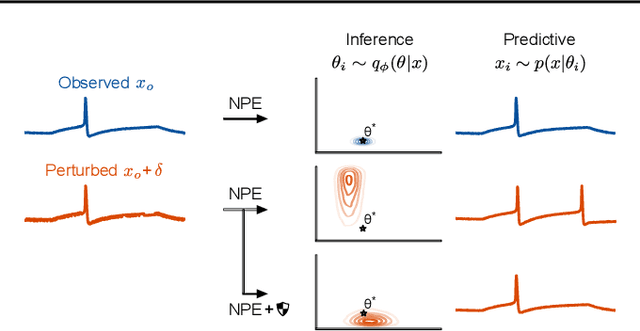
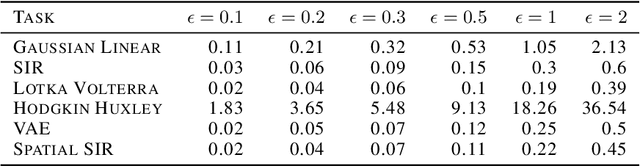
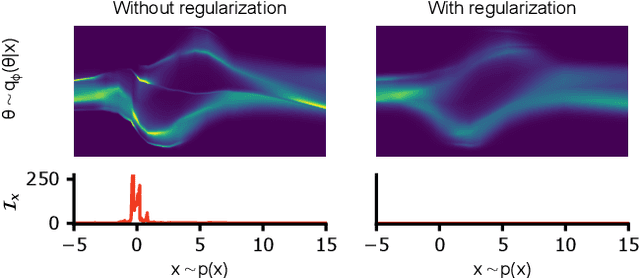
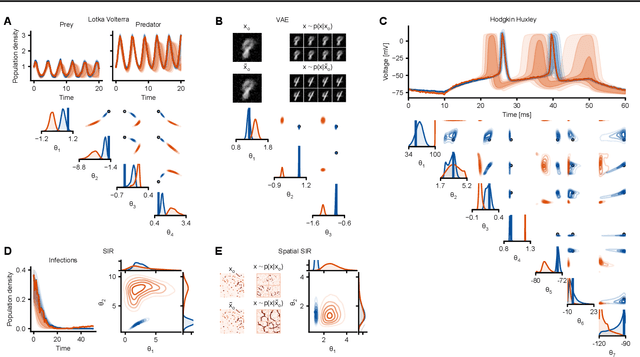
Bayesian inference usually requires running potentially costly inference procedures separately for every new observation. In contrast, the idea of amortized Bayesian inference is to initially invest computational cost in training an inference network on simulated data, which can subsequently be used to rapidly perform inference (i.e., to return estimates of posterior distributions) for new observations. This approach has been applied to many real-world models in the sciences and engineering, but it is unclear how robust the approach is to adversarial perturbations in the observed data. Here, we study the adversarial robustness of amortized Bayesian inference, focusing on simulation-based estimation of multi-dimensional posterior distributions. We show that almost unrecognizable, targeted perturbations of the observations can lead to drastic changes in the predicted posterior and highly unrealistic posterior predictive samples, across several benchmark tasks and a real-world example from neuroscience. We propose a computationally efficient regularization scheme based on penalizing the Fisher information of the conditional density estimator, and show how it improves the adversarial robustness of amortized Bayesian inference.
Cost-aware learning of relevant contextual variables within Bayesian optimization
May 24, 2023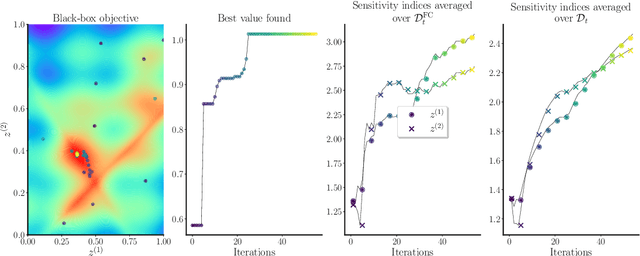

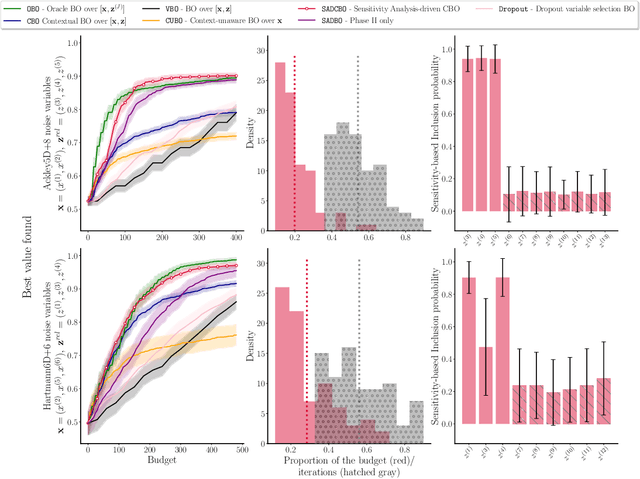
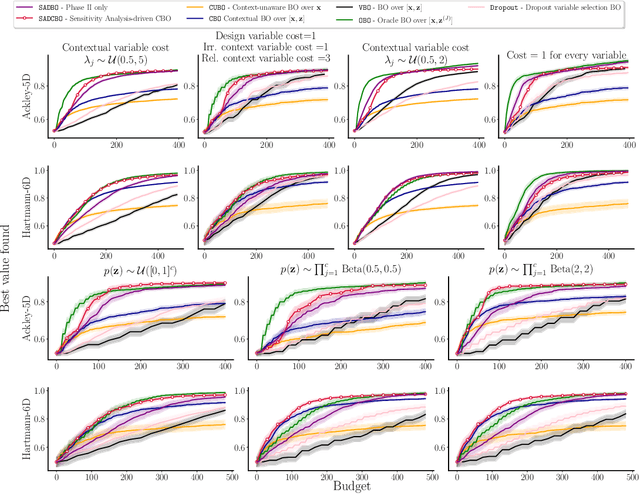
Contextual Bayesian Optimization (CBO) is a powerful framework for optimizing black-box, expensive-to-evaluate functions with respect to design variables, while simultaneously efficiently integrating relevant contextual information regarding the environment, such as experimental conditions. However, in many practical scenarios, the relevance of contextual variables is not necessarily known beforehand. Moreover, the contextual variables can sometimes be optimized themselves, a setting that current CBO algorithms do not take into account. Optimizing contextual variables may be costly, which raises the question of determining a minimal relevant subset. In this paper, we frame this problem as a cost-aware model selection BO task and address it using a novel method, Sensitivity-Analysis-Driven Contextual BO (SADCBO). We learn the relevance of context variables by sensitivity analysis of the posterior surrogate model at specific input points, whilst minimizing the cost of optimization by leveraging recent developments on early stopping for BO. We empirically evaluate our proposed SADCBO against alternatives on synthetic experiments together with extensive ablation studies, and demonstrate a consistent improvement across examples.
Text encoders are performance bottlenecks in contrastive vision-language models
May 24, 2023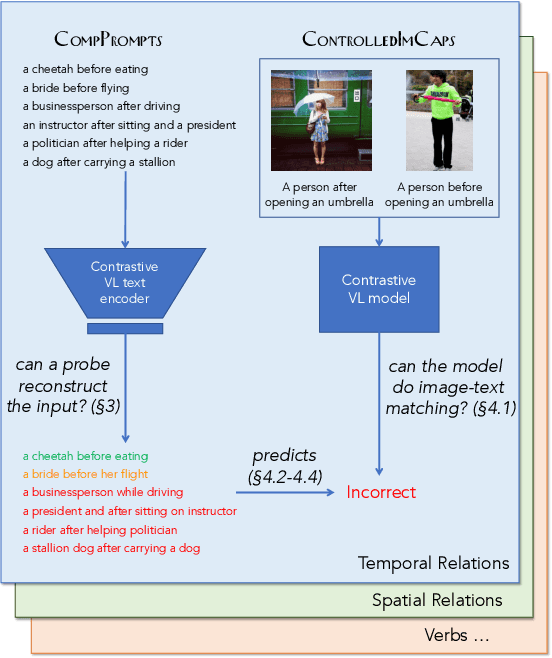
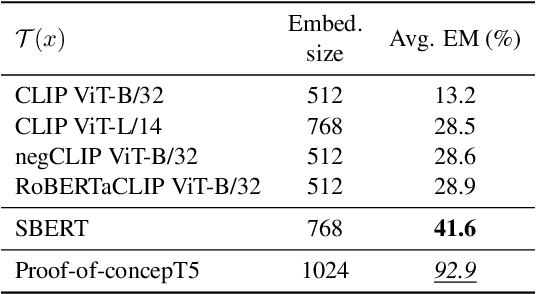
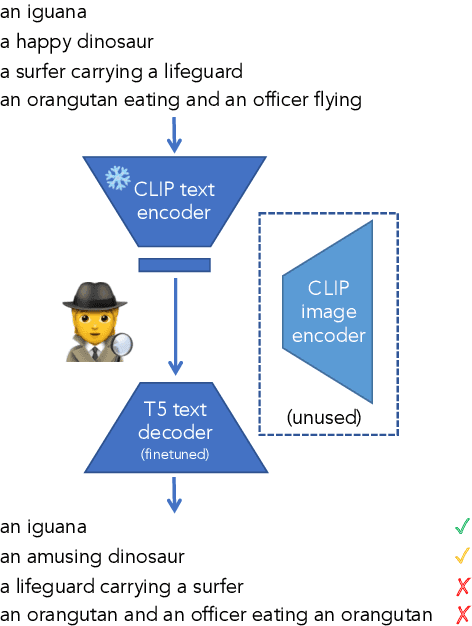
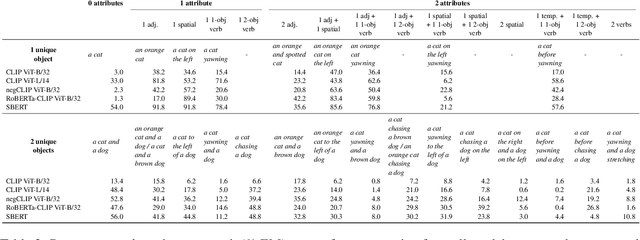
Performant vision-language (VL) models like CLIP represent captions using a single vector. How much information about language is lost in this bottleneck? We first curate CompPrompts, a set of increasingly compositional image captions that VL models should be able to capture (e.g., single object, to object+property, to multiple interacting objects). Then, we train text-only recovery probes that aim to reconstruct captions from single-vector text representations produced by several VL models. This approach doesn't require images, allowing us to test on a broader range of scenes compared to prior work. We find that: 1) CLIP's text encoder falls short on object relationships, attribute-object association, counting, and negations; 2) some text encoders work significantly better than others; and 3) text-only recovery performance predicts multi-modal matching performance on ControlledImCaps: a new evaluation benchmark we collect+release consisting of fine-grained compositional images+captions. Specifically -- our results suggest text-only recoverability is a necessary (but not sufficient) condition for modeling compositional factors in contrastive vision+language models. We release data+code.
Guessing Winning Policies in LTL Synthesis by Semantic Learning
May 24, 2023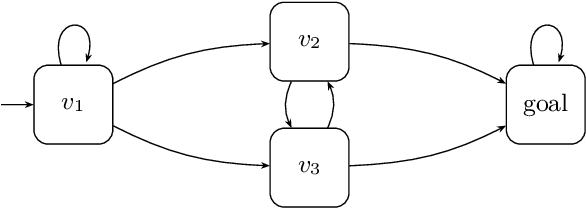

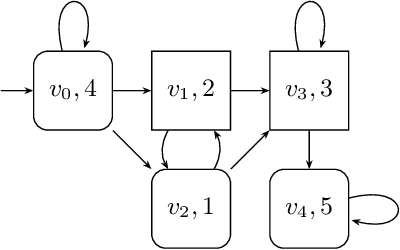
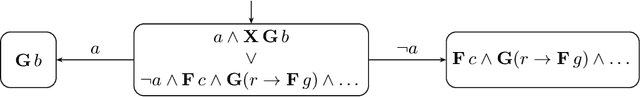
We provide a learning-based technique for guessing a winning strategy in a parity game originating from an LTL synthesis problem. A cheaply obtained guess can be useful in several applications. Not only can the guessed strategy be applied as best-effort in cases where the game's huge size prohibits rigorous approaches, but it can also increase the scalability of rigorous LTL synthesis in several ways. Firstly, checking whether a guessed strategy is winning is easier than constructing one. Secondly, even if the guess is wrong in some places, it can be fixed by strategy iteration faster than constructing one from scratch. Thirdly, the guess can be used in on-the-fly approaches to prioritize exploration in the most fruitful directions. In contrast to previous works, we (i)~reflect the highly structured logical information in game's states, the so-called semantic labelling, coming from the recent LTL-to-automata translations, and (ii)~learn to reflect it properly by learning from previously solved games, bringing the solving process closer to human-like reasoning.