 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DCCRN-KWS: an audio bias based model for noise robust small-footprint keyword spotting
May 23, 2023
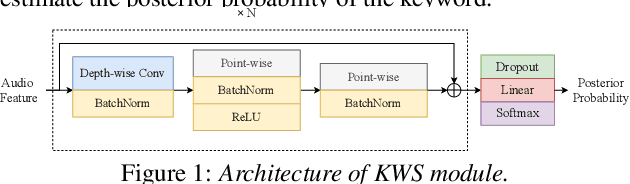

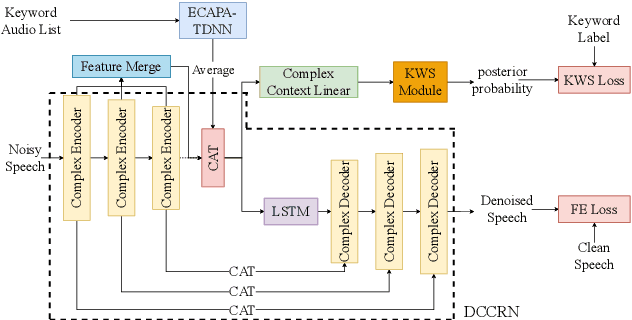
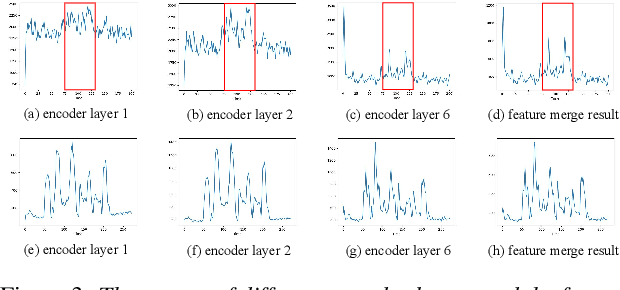
Real-world complex acoustic environments especially the ones with a low signal-to-noise ratio (SNR) will bring tremendous challenges to a keyword spotting (KWS) system. Inspired by the recent advances of neural speech enhancement and context bias in speech recognition, we propose a robust audio context bias based DCCRN-KWS model to address this challenge. We form the whole architecture as a multi-task learning framework for both denosing and keyword spotting, where the DCCRN encoder is connected with the KWS model. Helped with the denoising task, we further introduce an audio context bias module to leverage the real keyword samples and bias the network to better iscriminate keywords in noisy conditions. Feature merge and complex context linear modules are also introduced to strength such discrimination and to effectively leverage contextual information respectively. Experiments on the internal challenging dataset and the HIMIYA public dataset show that our DCCRN-KWS system is superior in performance, while ablation study demonstrates the good design of the whole model.
A Conversationalist Approach to Information Quality in Information Interaction and Retrieval
Oct 13, 2022Rather than using (proxies of) end user or expert judgment to decide on the ranking of information, this paper asks whether conversations about information quality might offer a feasible and valuable addition for ranking information. We introduce a theoretical framework for information quality, outlining how information interaction should be perceived as a conversation and quality be evaluated as a conversational contribution. Next, an overview is given of different systems of social alignment and their value for assessing quality and ranking information. We propose that a collaborative approach to quality assessment is preferable and raise key questions about the feasibility and value of such an approach for ranking information. We conclude that information quality is an inherently interactive concept, which involves an interaction between users of different backgrounds and in different situations as well as of quality signals on users' search behavior and experience.
Reward Collapse in Aligning Large Language Models
May 28, 2023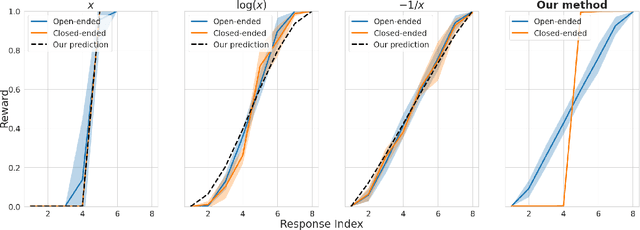
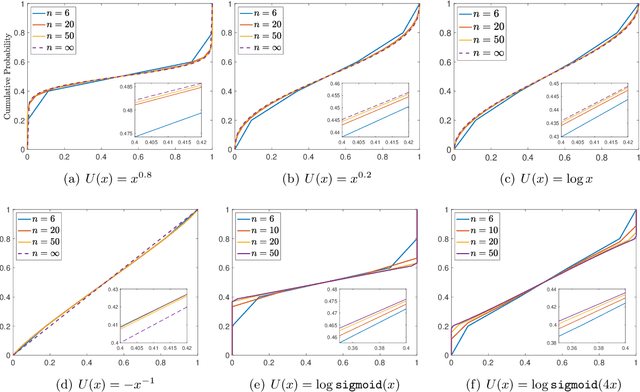
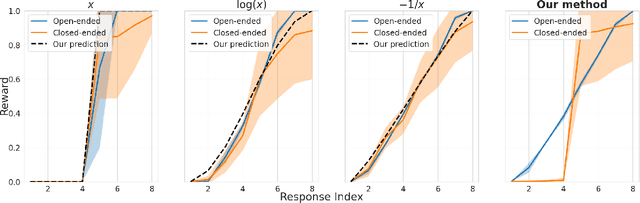
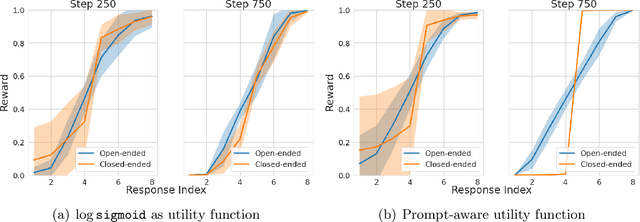
The extraordinary capabilities of large language models (LLMs) such as ChatGPT and GPT-4 are in part unleashed by aligning them with reward models that are trained on human preferences, which are often represented as rankings of responses to prompts. In this paper, we document the phenomenon of \textit{reward collapse}, an empirical observation where the prevailing ranking-based approach results in an \textit{identical} reward distribution \textit{regardless} of the prompts during the terminal phase of training. This outcome is undesirable as open-ended prompts like ``write a short story about your best friend'' should yield a continuous range of rewards for their completions, while specific prompts like ``what is the capital of New Zealand'' should generate either high or low rewards. Our theoretical investigation reveals that reward collapse is primarily due to the insufficiency of the ranking-based objective function to incorporate prompt-related information during optimization. This insight allows us to derive closed-form expressions for the reward distribution associated with a set of utility functions in an asymptotic regime. To overcome reward collapse, we introduce a prompt-aware optimization scheme that provably admits a prompt-dependent reward distribution within the interpolating regime. Our experimental results suggest that our proposed prompt-aware utility functions significantly alleviate reward collapse during the training of reward models.
Conditional score-based diffusion models for Bayesian inference in infinite dimensions
May 28, 2023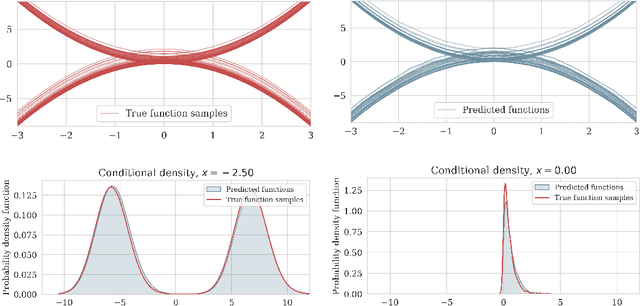
Since their first introduction, score-based diffusion models (SDMs) have been successfully applied to solve a variety of linear inverse problems in finite-dimensional vector spaces due to their ability to efficiently approximate the posterior distribution. However, using SDMs for inverse problems in infinite-dimensional function spaces has only been addressed recently and by learning the unconditional score. While this approach has some advantages, depending on the specific inverse problem at hand, in order to sample from the conditional distribution it needs to incorporate the information from the observed data with a proximal optimization step, solving an optimization problem numerous times. This may not be feasible in inverse problems with computationally costly forward operators. To address these limitations, in this work we propose a method to learn the posterior distribution in infinite-dimensional Bayesian linear inverse problems using amortized conditional SDMs. In particular, we prove that the conditional denoising estimator is a consistent estimator of the conditional score in infinite dimensions. We show that the extension of SDMs to the conditional setting requires some care because the conditional score typically blows up for small times contrarily to the unconditional score. We also discuss the robustness of the learned distribution against perturbations of the observations. We conclude by presenting numerical examples that validate our approach and provide additional insights.
TaleCrafter: Interactive Story Visualization with Multiple Characters
May 30, 2023

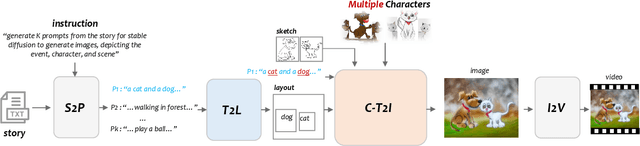
Accurate Story visualization requires several necessary elements, such as identity consistency across frames, the alignment between plain text and visual content, and a reasonable layout of objects in images. Most previous works endeavor to meet these requirements by fitting a text-to-image (T2I) model on a set of videos in the same style and with the same characters, e.g., the FlintstonesSV dataset. However, the learned T2I models typically struggle to adapt to new characters, scenes, and styles, and often lack the flexibility to revise the layout of the synthesized images. This paper proposes a system for generic interactive story visualization, capable of handling multiple novel characters and supporting the editing of layout and local structure. It is developed by leveraging the prior knowledge of large language and T2I models, trained on massive corpora. The system comprises four interconnected components: story-to-prompt generation (S2P), text-to-layout generation (T2L), controllable text-to-image generation (C-T2I), and image-to-video animation (I2V). First, the S2P module converts concise story information into detailed prompts required for subsequent stages. Next, T2L generates diverse and reasonable layouts based on the prompts, offering users the ability to adjust and refine the layout to their preference. The core component, C-T2I, enables the creation of images guided by layouts, sketches, and actor-specific identifiers to maintain consistency and detail across visualizations. Finally, I2V enriches the visualization process by animating the generated images. Extensive experiments and a user study are conducted to validate the effectiveness and flexibility of interactive editing of the proposed system.
Improving accuracy of GPT-3/4 results on biomedical data using a retrieval-augmented language model
May 30, 2023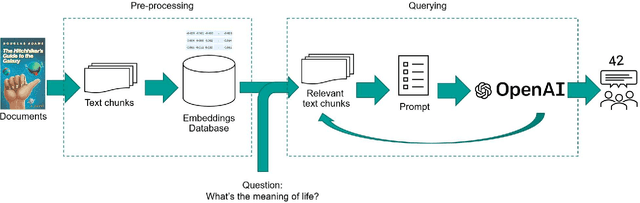
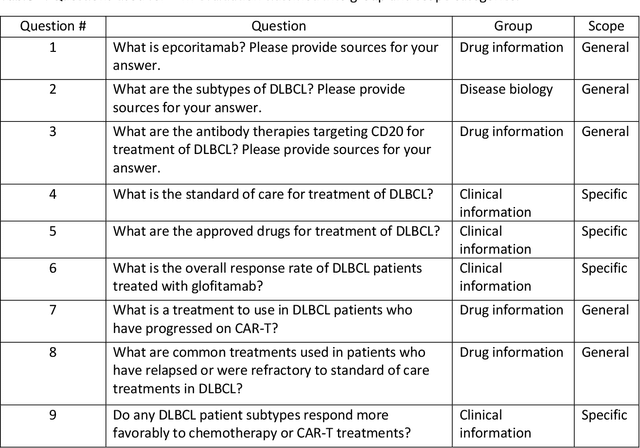

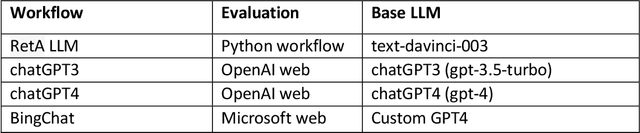
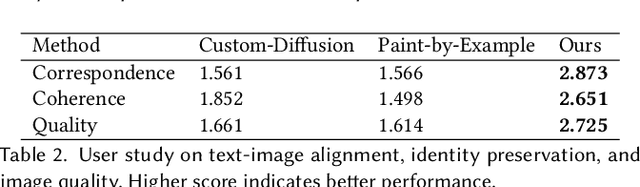
Large language models (LLMs) have made significant advancements in natural language processing (NLP). Broad corpora capture diverse patterns but can introduce irrelevance, while focused corpora enhance reliability by reducing misleading information. Training LLMs on focused corpora poses computational challenges. An alternative approach is to use a retrieval-augmentation (RetA) method tested in a specific domain. To evaluate LLM performance, OpenAI's GPT-3, GPT-4, Bing's Prometheus, and a custom RetA model were compared using 19 questions on diffuse large B-cell lymphoma (DLBCL) disease. Eight independent reviewers assessed responses based on accuracy, relevance, and readability (rated 1-3). The RetA model performed best in accuracy (12/19 3-point scores, total=47) and relevance (13/19, 50), followed by GPT-4 (8/19, 43; 11/19, 49). GPT-4 received the highest readability scores (17/19, 55), followed by GPT-3 (15/19, 53) and the RetA model (11/19, 47). Prometheus underperformed in accuracy (34), relevance (32), and readability (38). Both GPT-3.5 and GPT-4 had more hallucinations in all 19 responses compared to the RetA model and Prometheus. Hallucinations were mostly associated with non-existent references or fabricated efficacy data. These findings suggest that RetA models, supplemented with domain-specific corpora, may outperform general-purpose LLMs in accuracy and relevance within specific domains. However, this evaluation was limited to specific questions and metrics and may not capture challenges in semantic search and other NLP tasks. Further research will explore different LLM architectures, RetA methodologies, and evaluation methods to assess strengths and limitations more comprehensively.
Intrinsic shape analysis in archaeology: A case study on ancient sundials
May 30, 2023
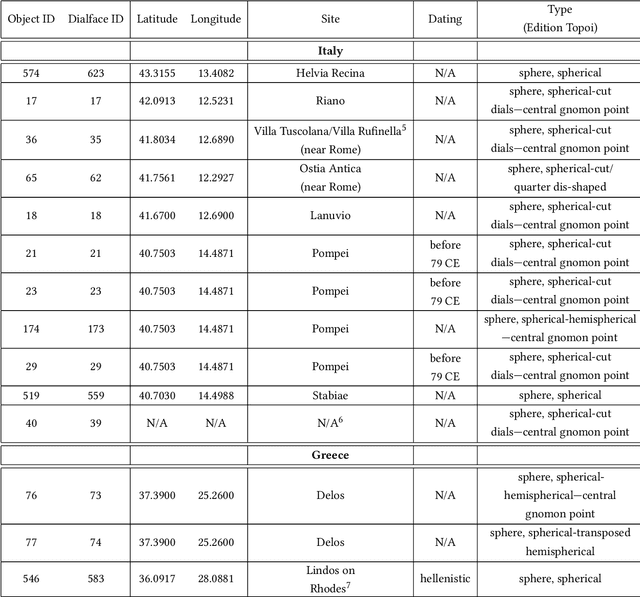
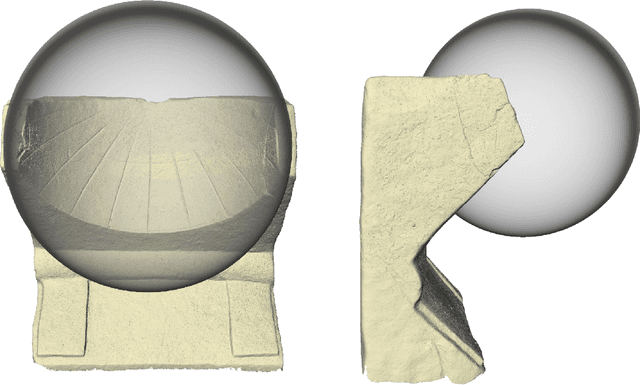
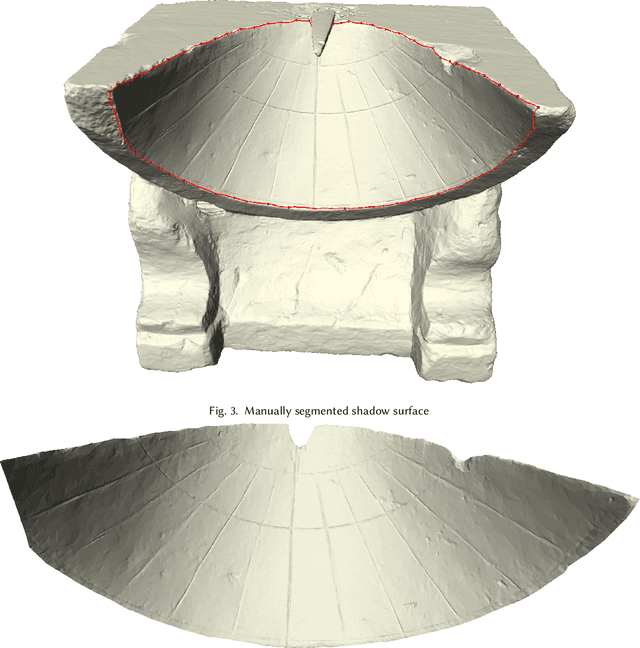
This paper explores a novel mathematical approach to extract archaeological insights from ensembles of similar artifact shapes. We show that by considering all the shape information in a find collection, it is possible to identify shape patterns that would be difficult to discern by considering the artifacts individually or by classifying shapes into predefined archaeological types and analyzing the associated distinguishing characteristics. Recently, series of high-resolution digital representations of artifacts have become available, and we explore their potential on a set of 3D models of ancient Greek and Roman sundials, with the aim of providing alternatives to the traditional archaeological method of ``trend extraction by ordination'' (typology). In the proposed approach, each 3D shape is represented as a point in a shape space -- a high-dimensional, curved, non-Euclidean space. By performing regression in shape space, we find that for Roman sundials, the bend of the sundials' shadow-receiving surface changes with the location's latitude. This suggests that, apart from the inscribed hour lines, also a sundial's shape was adjusted to the place of installation. As an example of more advanced inference, we use the identified trend to infer the latitude at which a sundial, whose installation location is unknown, was placed. We also derive a novel method for differentiated morphological trend assertion, building upon and extending the theory of geometric statistics and shape analysis. Specifically, we present a regression-based method for statistical normalization of shapes that serves as a means of disentangling parameter-dependent effects (trends) and unexplained variability.
DHRL-FNMR: An Intelligent Multicast Routing Approach Based on Deep Hierarchical Reinforcement Learning in SDN
May 30, 2023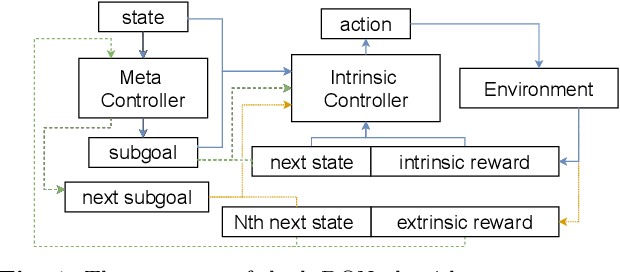
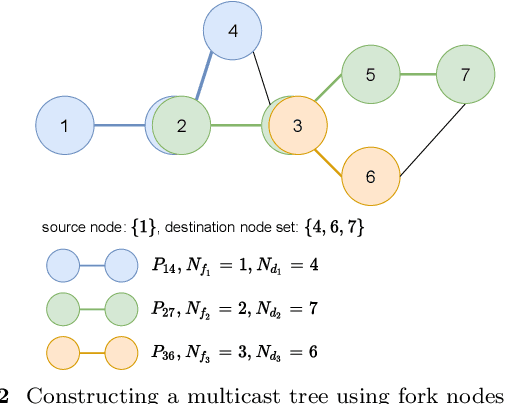
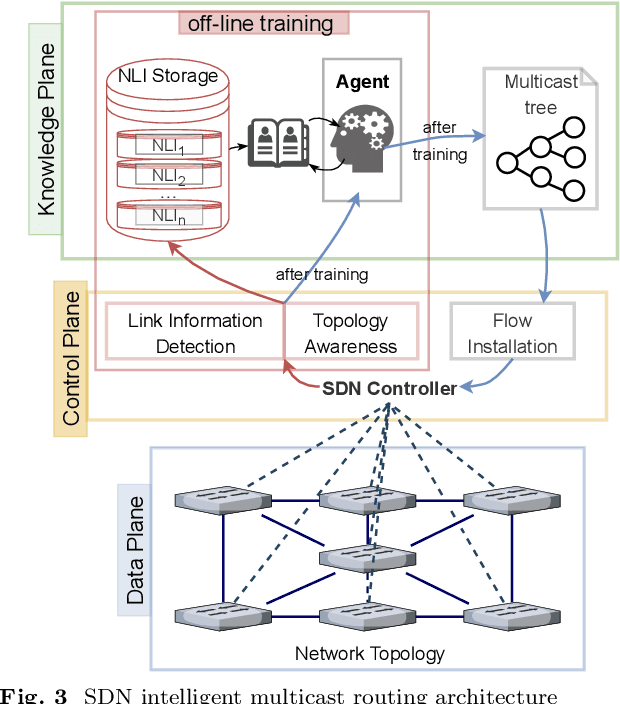
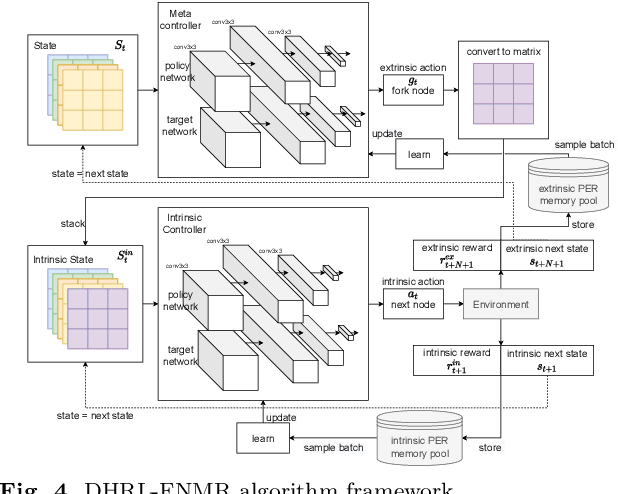
The optimal multicast tree problem in the Software-Defined Networking (SDN) multicast routing is an NP-hard combinatorial optimization problem. Although existing SDN intelligent solution methods, which are based on deep reinforcement learning, can dynamically adapt to complex network link state changes, these methods are plagued by problems such as redundant branches, large action space, and slow agent convergence. In this paper, an SDN intelligent multicast routing algorithm based on deep hierarchical reinforcement learning is proposed to circumvent the aforementioned problems. First, the multicast tree construction problem is decomposed into two sub-problems: the fork node selection problem and the construction of the optimal path from the fork node to the destination node. Second, based on the information characteristics of SDN global network perception, the multicast tree state matrix, link bandwidth matrix, link delay matrix, link packet loss rate matrix, and sub-goal matrix are designed as the state space of intrinsic and meta controllers. Then, in order to mitigate the excessive action space, our approach constructs different action spaces at the upper and lower levels. The meta-controller generates an action space using network nodes to select the fork node, and the intrinsic controller uses the adjacent edges of the current node as its action space, thus implementing four different action selection strategies in the construction of the multicast tree. To facilitate the intelligent agent in constructing the optimal multicast tree with greater speed, we developed alternative reward strategies that distinguish between single-step node actions and multi-step actions towards multiple destination nodes.
Reason to explain: Interactive contrastive explanations (REASONX)
May 29, 2023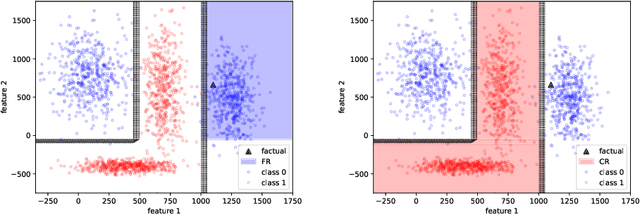
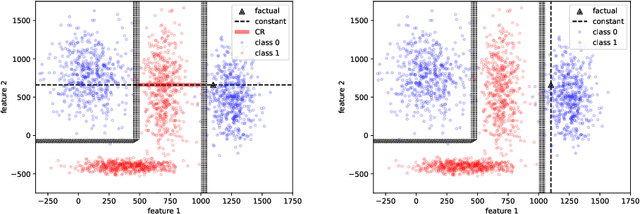
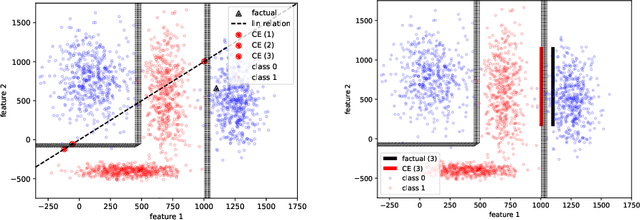
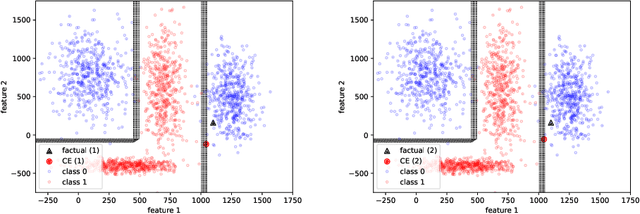
Many high-performing machine learning models are not interpretable. As they are increasingly used in decision scenarios that can critically affect individuals, it is necessary to develop tools to better understand their outputs. Popular explanation methods include contrastive explanations. However, they suffer several shortcomings, among others an insufficient incorporation of background knowledge, and a lack of interactivity. While (dialogue-like) interactivity is important to better communicate an explanation, background knowledge has the potential to significantly improve their quality, e.g., by adapting the explanation to the needs of the end-user. To close this gap, we present REASONX, an explanation tool based on Constraint Logic Programming (CLP). REASONX provides interactive contrastive explanations that can be augmented by background knowledge, and allows to operate under a setting of under-specified information, leading to increased flexibility in the provided explanations. REASONX computes factual and constrative decision rules, as well as closest constrative examples. It provides explanations for decision trees, which can be the ML models under analysis, or global/local surrogate models of any ML model. While the core part of REASONX is built on CLP, we also provide a program layer that allows to compute the explanations via Python, making the tool accessible to a wider audience. We illustrate the capability of REASONX on a synthetic data set, and on a a well-developed example in the credit domain. In both cases, we can show how REASONX can be flexibly used and tailored to the needs of the user.
Secrecy Capacity Analysis of 4-WFRFT Based Physical Layer Security in MIMO System
May 29, 2023
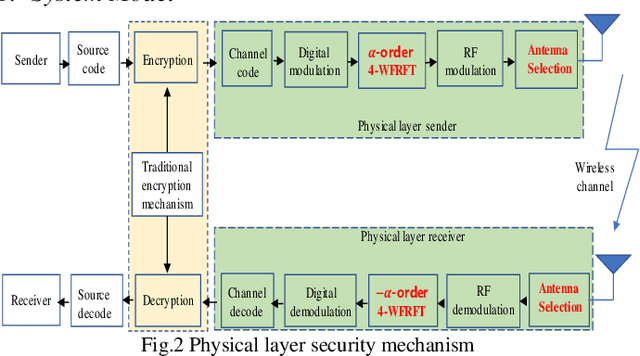
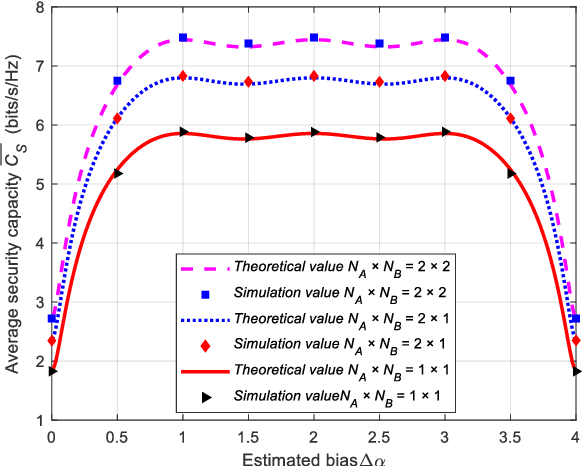

The traditional information security based on cryptosystem is seriously threatened due to the exponential growth of computing capacity. In order to improve for the upper cryptosystem security, the secure transmission at the physical layer is introduced into the wireless communication system. However, considering the openness of wireless channel, the performance analysis of security wireless communication systems has become a hot issue in recent years. Due to the existence of the upper layer cryptosystem being cracked and the openness of wireless channel security problems, the Multiple-Input Multiple-Output (MIMO) technology increases the difference between channels, the development of its rich spatial degrees of freedom can greatly improve the channel capacity and achieve the purpose of enhancing the Physical layer security (PLS); On this basis, Weighted Type Fractional Fourier Transform (WFrFT) technology rotates and splits the constellation points of signals, it is equivalent to increasing the artificial noise to enhance the PLS. The Average security capacity is an important index to measure the PLS, Therefore, this paper deduces the Average security capacity in MIMO scenario and gives a specific closed expression when considering the channel correlation. By analyzing the expression, the increase of the number of MIMO antennas will improve the Average security capacity. When the estimated bias is 1 in 4-WFRFT, the Average security capacity will be significantly improved; the Average security capacity will reach the maximum value, thus enhancing the PLS.