 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond Active Learning: Leveraging the Full Potential of Human Interaction via Auto-Labeling, Human Correction, and Human Verification
Jun 02, 2023

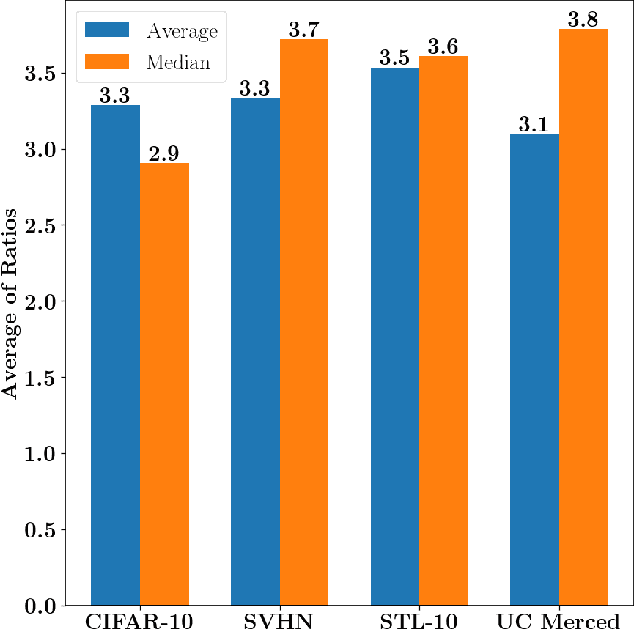
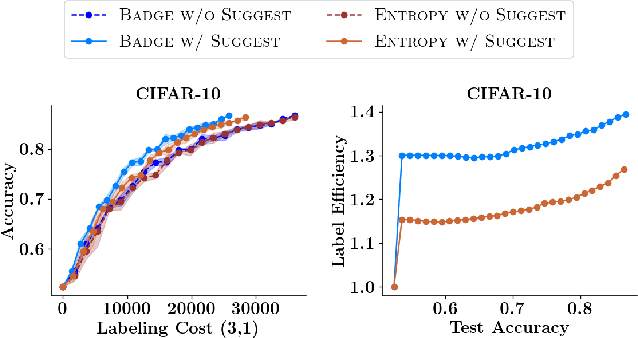
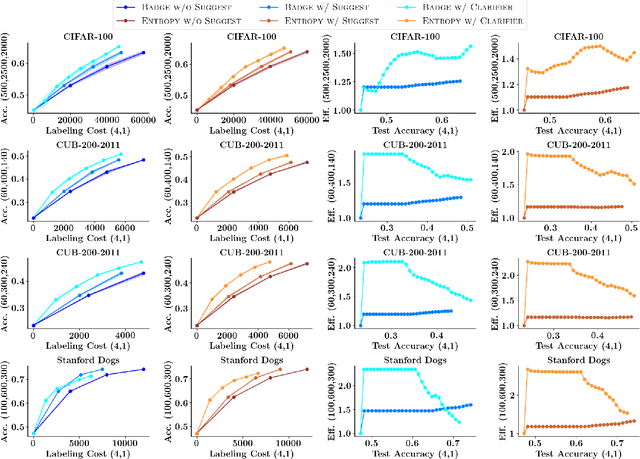
Active Learning (AL) is a human-in-the-loop framework to interactively and adaptively label data instances, thereby enabling significant gains in model performance compared to random sampling. AL approaches function by selecting the hardest instances to label, often relying on notions of diversity and uncertainty. However, we believe that these current paradigms of AL do not leverage the full potential of human interaction granted by automated label suggestions. Indeed, we show that for many classification tasks and datasets, most people verifying if an automatically suggested label is correct take $3\times$ to $4\times$ less time than they do changing an incorrect suggestion to the correct label (or labeling from scratch without any suggestion). Utilizing this result, we propose CLARIFIER (aCtive LeARnIng From tIEred haRdness), an Interactive Learning framework that admits more effective use of human interaction by leveraging the reduced cost of verification. By targeting the hard (uncertain) instances with existing AL methods, the intermediate instances with a novel label suggestion scheme using submodular mutual information functions on a per-class basis, and the easy (confident) instances with highest-confidence auto-labeling, CLARIFIER can improve over the performance of existing AL approaches on multiple datasets -- particularly on those that have a large number of classes -- by almost 1.5$\times$ to 2$\times$ in terms of relative labeling cost.
Chemical Property-Guided Neural Networks for Naphtha Composition Prediction
Jun 02, 2023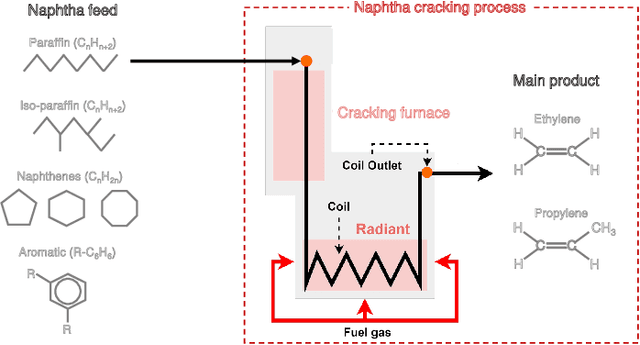
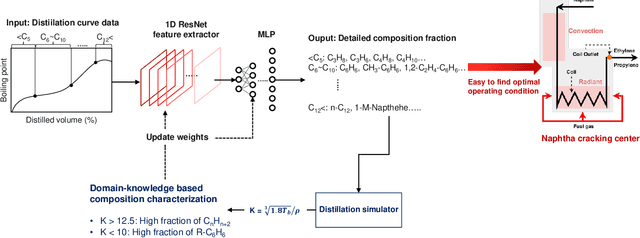
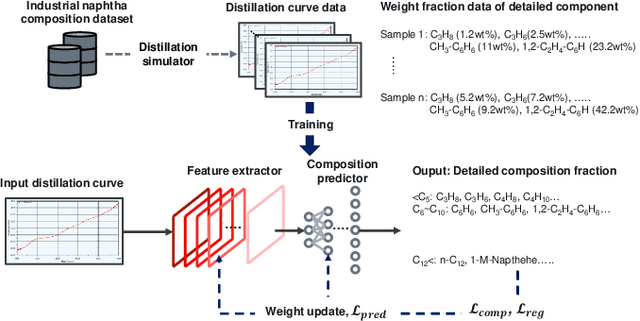
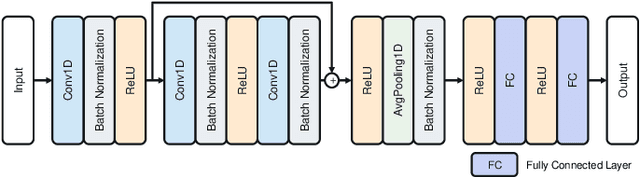
The naphtha cracking process heavily relies on the composition of naphtha, which is a complex blend of different hydrocarbons. Predicting the naphtha composition accurately is crucial for efficiently controlling the cracking process and achieving maximum performance. Traditional methods, such as gas chromatography and true boiling curve, are not feasible due to the need for pilot-plant-scale experiments or cost constraints. In this paper, we propose a neural network framework that utilizes chemical property information to improve the performance of naphtha composition prediction. Our proposed framework comprises two parts: a Watson K factor estimation network and a naphtha composition prediction network. Both networks share a feature extraction network based on Convolutional Neural Network (CNN) architecture, while the output layers use Multi-Layer Perceptron (MLP) based networks to generate two different outputs - Watson K factor and naphtha composition. The naphtha composition is expressed in percentages, and its sum should be 100%. To enhance the naphtha composition prediction, we utilize a distillation simulator to obtain the distillation curve from the naphtha composition, which is dependent on its chemical properties. By designing a loss function between the estimated and simulated Watson K factors, we improve the performance of both Watson K estimation and naphtha composition prediction. The experimental results show that our proposed framework can predict the naphtha composition accurately while reflecting real naphtha chemical properties.
Challenges in Context-Aware Neural Machine Translation
May 23, 2023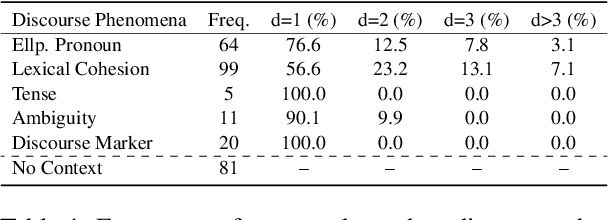
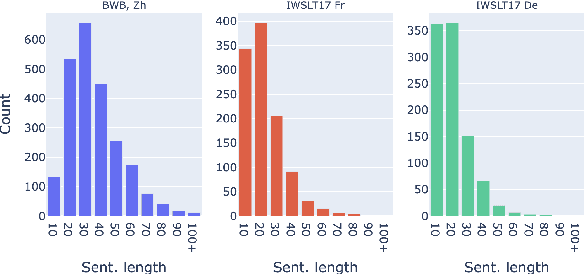
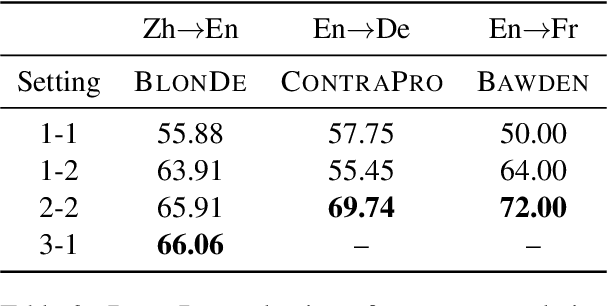

Context-aware neural machine translation involves leveraging information beyond sentence-level context to resolve inter-sentential discourse dependencies and improve document-level translation quality, and has given rise to a number of recent techniques. However, despite well-reasoned intuitions, most context-aware translation models show only modest improvements over sentence-level systems. In this work, we investigate several challenges that impede progress within this field, relating to discourse phenomena, context usage, model architectures, and document-level evaluation. To address these problems, we propose a more realistic setting for document-level translation, called paragraph-to-paragraph (para2para) translation, and collect a new dataset of Chinese-English novels to promote future research.
A Quantitative Review on Language Model Efficiency Research
May 28, 2023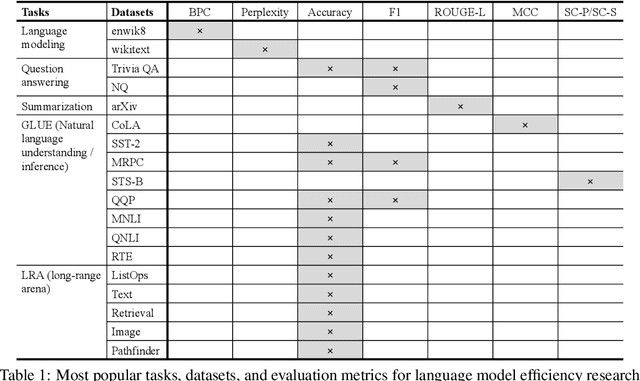
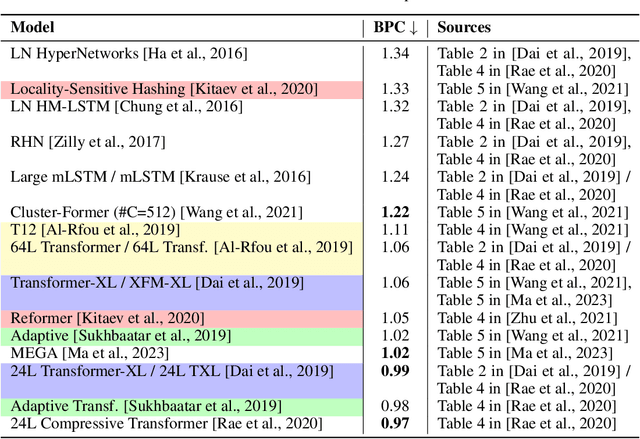
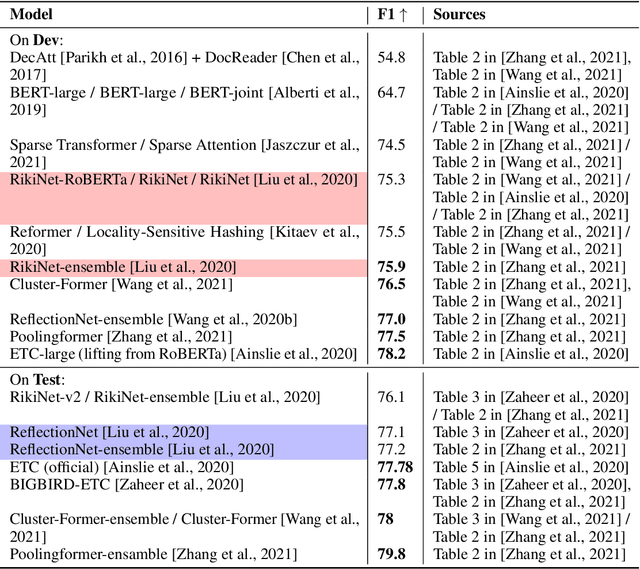
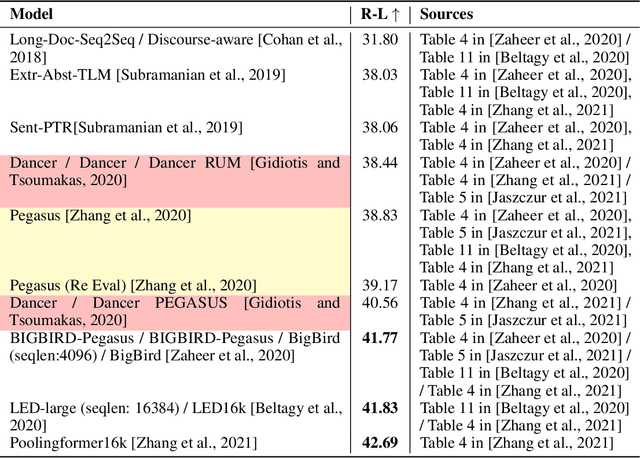
Language models (LMs) are being scaled and becoming powerful. Improving their efficiency is one of the core research topics in neural information processing systems. Tay et al. (2022) provided a comprehensive overview of efficient Transformers that have become an indispensable staple in the field of NLP. However, in the section of "On Evaluation", they left an open question "which fundamental efficient Transformer one should consider," answered by "still a mystery" because "many research papers select their own benchmarks." Unfortunately, there was not quantitative analysis about the performances of Transformers on any benchmarks. Moreover, state space models (SSMs) have demonstrated their abilities of modeling long-range sequences with non-attention mechanisms, which were not discussed in the prior review. This article makes a meta analysis on the results from a set of papers on efficient Transformers as well as those on SSMs. It provides a quantitative review on LM efficiency research and gives suggestions for future research.
Efficient Multi-Grained Knowledge Reuse for Class Incremental Segmentation
Jun 03, 2023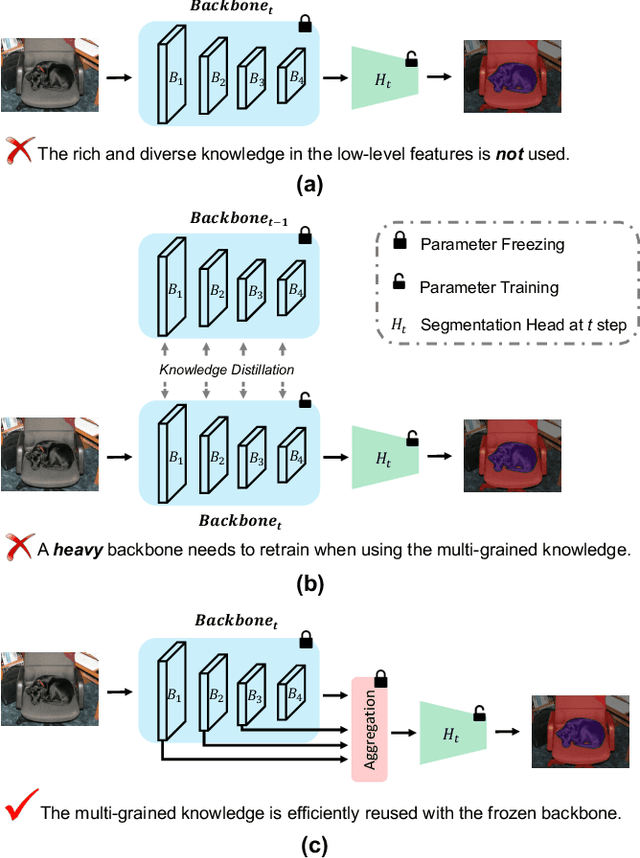

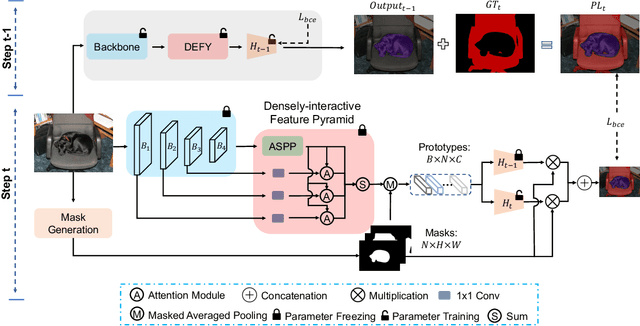

Class Incremental Semantic Segmentation (CISS) has been a trend recently due to its great significance in real-world applications. Although the existing CISS methods demonstrate remarkable performance, they either leverage the high-level knowledge (feature) only while neglecting the rich and diverse knowledge in the low-level features, leading to poor old knowledge preservation and weak new knowledge exploration; or use multi-level features for knowledge distillation by retraining a heavy backbone, which is computationally intensive. In this paper, we for the first time propose to efficiently reuse the multi-grained knowledge for CISS by fusing multi-level features with the frozen backbone and show a simple aggregation of varying-level features, i.e., naive feature pyramid, can boost the performance significantly. We further introduce a novel densely-interactive feature pyramid (DEFY) module that enhances the fusion of high- and low-level features by enabling their dense interaction. Specifically, DEFY establishes a per-pixel relationship between pairs of feature maps, allowing for multi-pair outputs to be aggregated. This results in improved semantic segmentation by leveraging the complementary information from multi-level features. We show that DEFY can be effortlessly integrated into three representative methods for performance enhancement. Our method yields a new state-of-the-art performance when combined with the current SOTA by notably averaged mIoU gains on two widely used benchmarks, i.e., 2.5% on PASCAL VOC 2012 and 2.3% on ADE20K.
Lightweight Structure-aware Transformer Network for VHR Remote Sensing Image Change Detection
Jun 03, 2023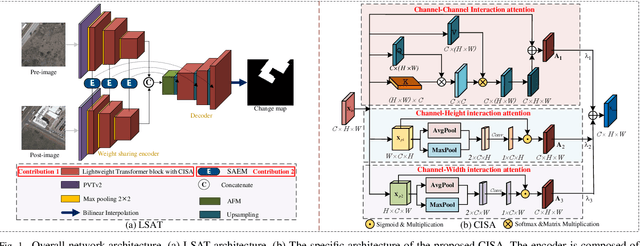
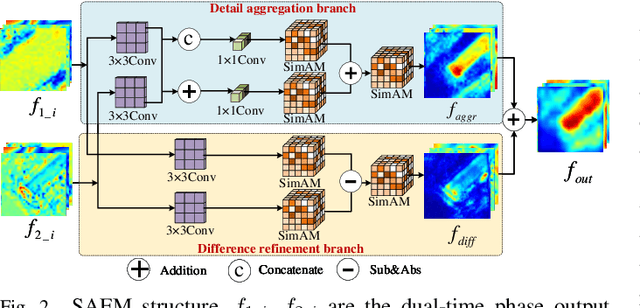
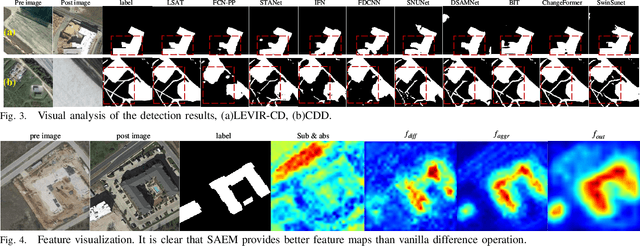
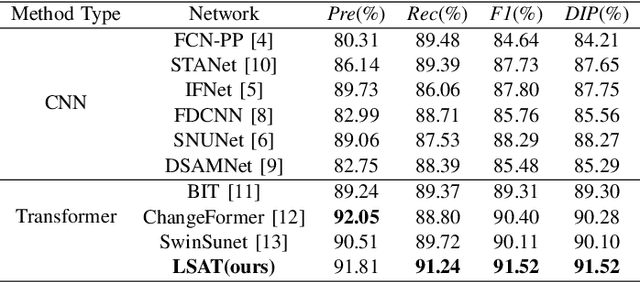
Popular Transformer networks have been successfully applied to remote sensing (RS) image change detection (CD) identifications and achieve better results than most convolutional neural networks (CNNs), but they still suffer from two main problems. First, the computational complexity of the Transformer grows quadratically with the increase of image spatial resolution, which is unfavorable to very high-resolution (VHR) RS images. Second, these popular Transformer networks tend to ignore the importance of fine-grained features, which results in poor edge integrity and internal tightness for largely changed objects and leads to the loss of small changed objects. To address the above issues, this Letter proposes a Lightweight Structure-aware Transformer (LSAT) network for RS image CD. The proposed LSAT has two advantages. First, a Cross-dimension Interactive Self-attention (CISA) module with linear complexity is designed to replace the vanilla self-attention in visual Transformer, which effectively reduces the computational complexity while improving the feature representation ability of the proposed LSAT. Second, a Structure-aware Enhancement Module (SAEM) is designed to enhance difference features and edge detail information, which can achieve double enhancement by difference refinement and detail aggregation so as to obtain fine-grained features of bi-temporal RS images. Experimental results show that the proposed LSAT achieves significant improvement in detection accuracy and offers a better tradeoff between accuracy and computational costs than most state-of-the-art CD methods for VHR RS images.
A Peer-to-peer Federated Continual Learning Network for Improving CT Imaging from Multiple Institutions
Jun 03, 2023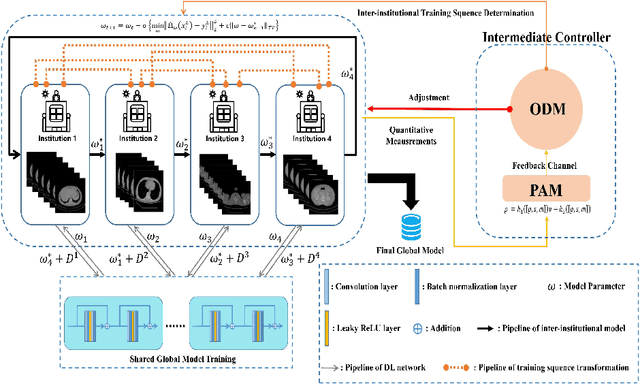
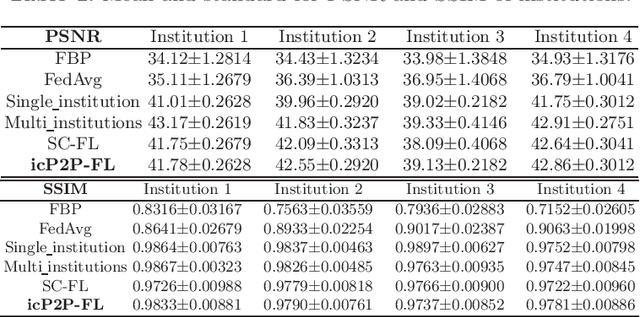
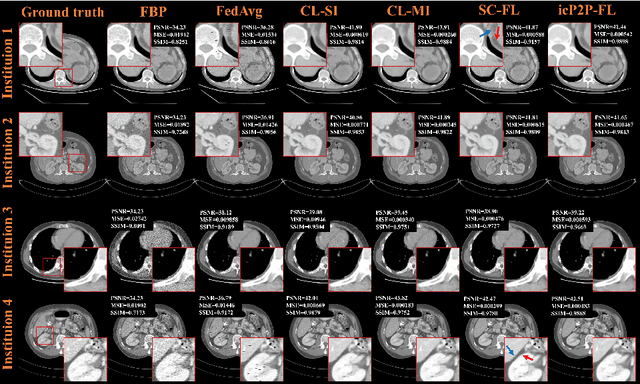
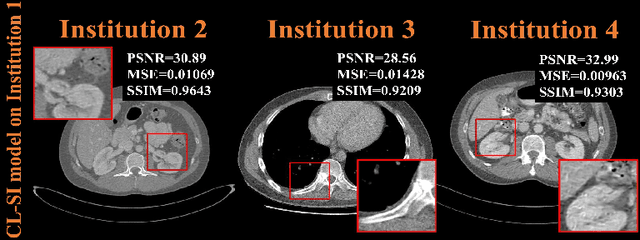
Deep learning techniques have been widely used in computed tomography (CT) but require large data sets to train networks. Moreover, data sharing among multiple institutions is limited due to data privacy constraints, which hinders the development of high-performance DL-based CT imaging models from multi-institutional collaborations. Federated learning (FL) strategy is an alternative way to train the models without centralizing data from multi-institutions. In this work, we propose a novel peer-to-peer federated continual learning strategy to improve low-dose CT imaging performance from multiple institutions. The newly proposed method is called peer-to-peer continual FL with intermediate controllers, i.e., icP2P-FL. Specifically, different from the conventional FL model, the proposed icP2P-FL does not require a central server that coordinates training information for a global model. In the proposed icP2P-FL method, the peer-to-peer federated continual learning is introduced wherein the DL-based model is continually trained one client after another via model transferring and inter institutional parameter sharing due to the common characteristics of CT data among the clients. Furthermore, an intermediate controller is developed to make the overall training more flexible. Numerous experiments were conducted on the AAPM low-dose CT Grand Challenge dataset and local datasets, and the experimental results showed that the proposed icP2P-FL method outperforms the other comparative methods both qualitatively and quantitatively, and reaches an accuracy similar to a model trained with pooling data from all the institutions.
Iterative Adversarial Attack on Image-guided Story Ending Generation
May 16, 2023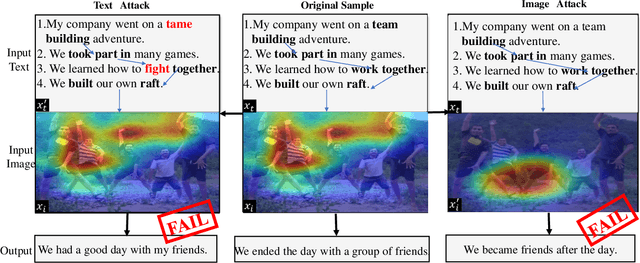
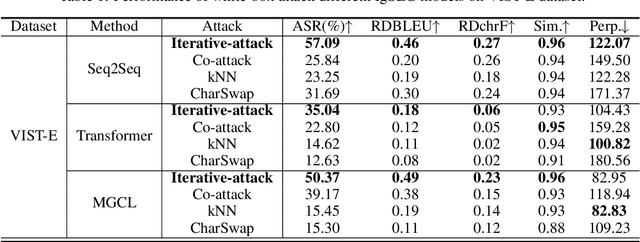
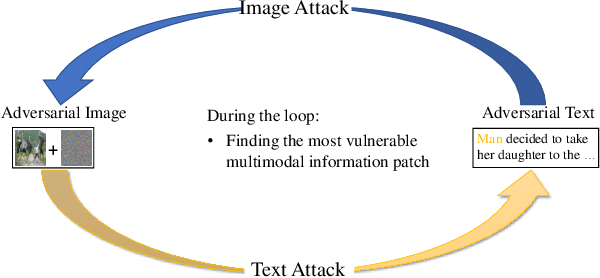
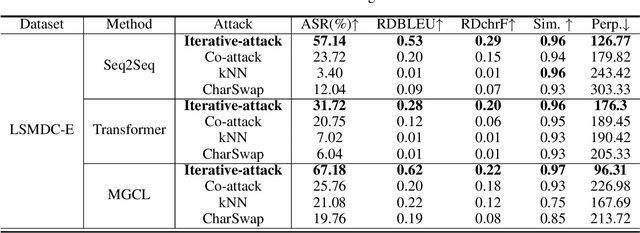
Multimodal learning involves developing models that can integrate information from various sources like images and texts. In this field, multimodal text generation is a crucial aspect that involves processing data from multiple modalities and outputting text. The image-guided story ending generation (IgSEG) is a particularly significant task, targeting on an understanding of complex relationships between text and image data with a complete story text ending. Unfortunately, deep neural networks, which are the backbone of recent IgSEG models, are vulnerable to adversarial samples. Current adversarial attack methods mainly focus on single-modality data and do not analyze adversarial attacks for multimodal text generation tasks that use cross-modal information. To this end, we propose an iterative adversarial attack method (Iterative-attack) that fuses image and text modality attacks, allowing for an attack search for adversarial text and image in an more effective iterative way. Experimental results demonstrate that the proposed method outperforms existing single-modal and non-iterative multimodal attack methods, indicating the potential for improving the adversarial robustness of multimodal text generation models, such as multimodal machine translation, multimodal question answering, etc.
Rapid Adaptation in Online Continual Learning: Are We Evaluating It Right?
May 16, 2023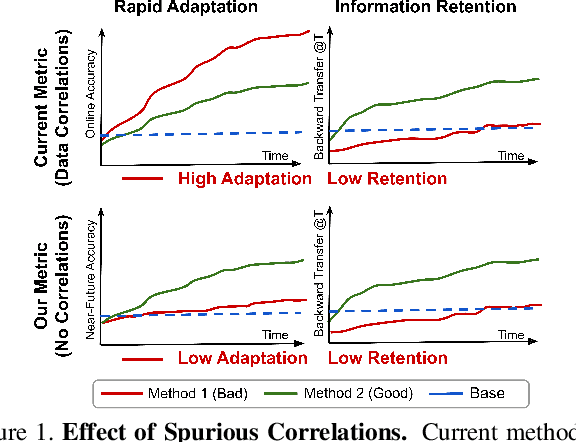
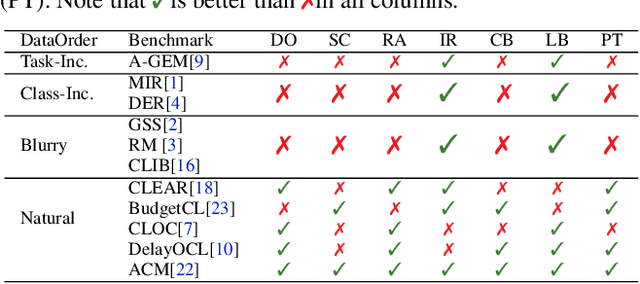
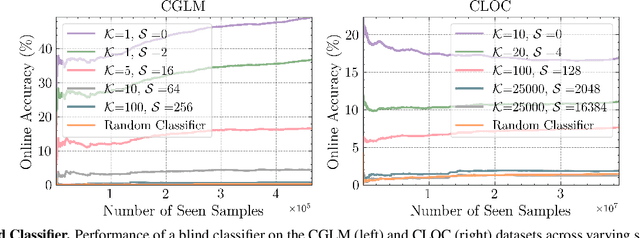
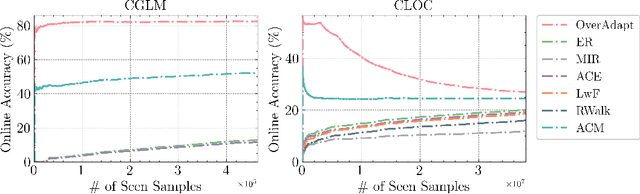
We revisit the common practice of evaluating adaptation of Online Continual Learning (OCL) algorithms through the metric of online accuracy, which measures the accuracy of the model on the immediate next few samples. However, we show that this metric is unreliable, as even vacuous blind classifiers, which do not use input images for prediction, can achieve unrealistically high online accuracy by exploiting spurious label correlations in the data stream. Our study reveals that existing OCL algorithms can also achieve high online accuracy, but perform poorly in retaining useful information, suggesting that they unintentionally learn spurious label correlations. To address this issue, we propose a novel metric for measuring adaptation based on the accuracy on the near-future samples, where spurious correlations are removed. We benchmark existing OCL approaches using our proposed metric on large-scale datasets under various computational budgets and find that better generalization can be achieved by retaining and reusing past seen information. We believe that our proposed metric can aid in the development of truly adaptive OCL methods. We provide code to reproduce our results at https://github.com/drimpossible/EvalOCL.
Understanding the Generalization Ability of Deep Learning Algorithms: A Kernelized Renyi's Entropy Perspective
May 02, 2023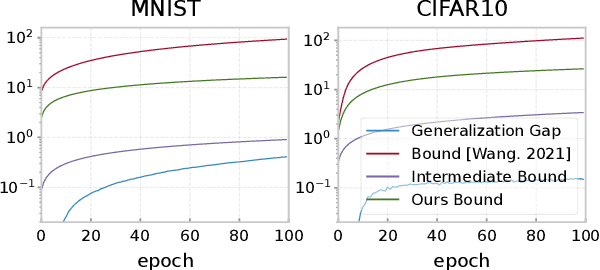

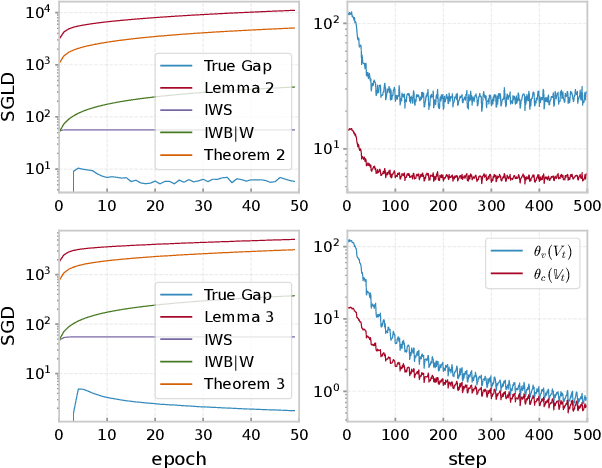
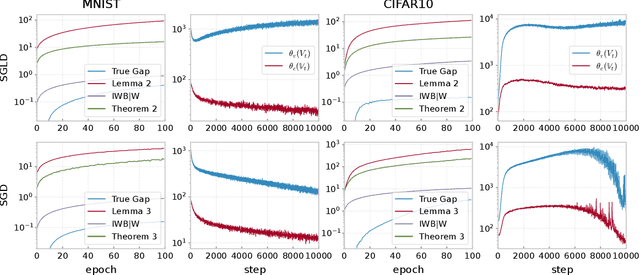
Recently, information theoretic analysis has become a popular framework for understanding the generalization behavior of deep neural networks. It allows a direct analysis for stochastic gradient/Langevin descent (SGD/SGLD) learning algorithms without strong assumptions such as Lipschitz or convexity conditions. However, the current generalization error bounds within this framework are still far from optimal, while substantial improvements on these bounds are quite challenging due to the intractability of high-dimensional information quantities. To address this issue, we first propose a novel information theoretical measure: kernelized Renyi's entropy, by utilizing operator representation in Hilbert space. It inherits the properties of Shannon's entropy and can be effectively calculated via simple random sampling, while remaining independent of the input dimension. We then establish the generalization error bounds for SGD/SGLD under kernelized Renyi's entropy, where the mutual information quantities can be directly calculated, enabling evaluation of the tightness of each intermediate step. We show that our information-theoretical bounds depend on the statistics of the stochastic gradients evaluated along with the iterates, and are rigorously tighter than the current state-of-the-art (SOTA) results. The theoretical findings are also supported by large-scale empirical studies1.