 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Analyzing the Internals of Neural Radiance Fields
Jun 01, 2023
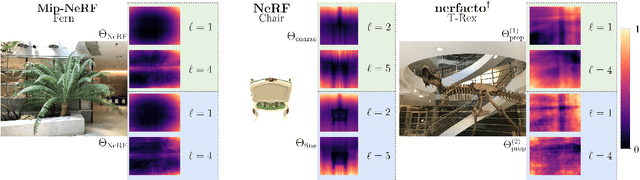
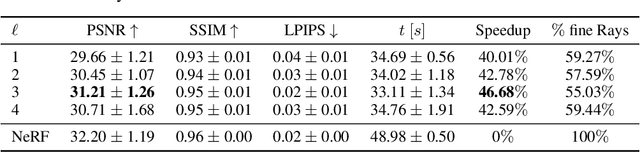
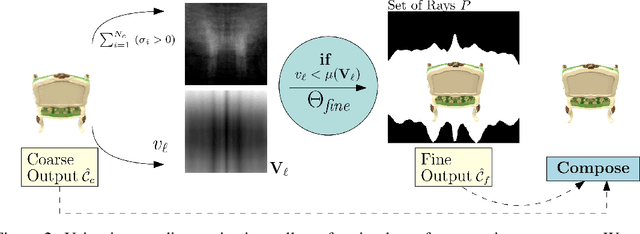
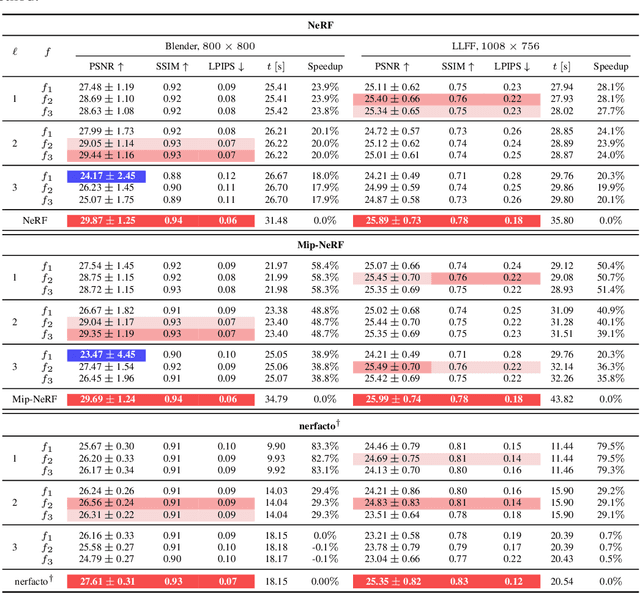
Modern Neural Radiance Fields (NeRFs) learn a mapping from position to volumetric density via proposal network samplers. In contrast to the coarse-to-fine sampling approach with two NeRFs, this offers significant potential for speedups using lower network capacity as the task of mapping spatial coordinates to volumetric density involves no view-dependent effects and is thus much easier to learn. Given that most of the network capacity is utilized to estimate radiance, NeRFs could store valuable density information in their parameters or their deep features. To this end, we take one step back and analyze large, trained ReLU-MLPs used in coarse-to-fine sampling. We find that trained NeRFs, Mip-NeRFs and proposal network samplers map samples with high density to local minima along a ray in activation feature space. We show how these large MLPs can be accelerated by transforming the intermediate activations to a weight estimate, without any modifications to the parameters post-optimization. With our approach, we can reduce the computational requirements of trained NeRFs by up to 50% with only a slight hit in rendering quality and no changes to the training protocol or architecture. We evaluate our approach on a variety of architectures and datasets, showing that our proposition holds in various settings.
Learning Across Decentralized Multi-Modal Remote Sensing Archives with Federated Learning
Jun 01, 2023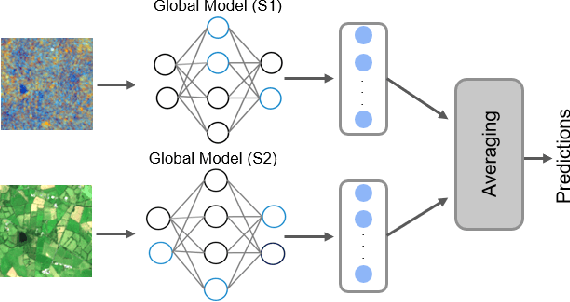
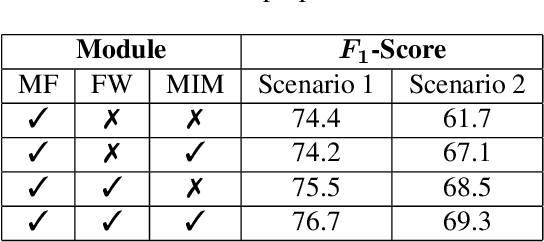
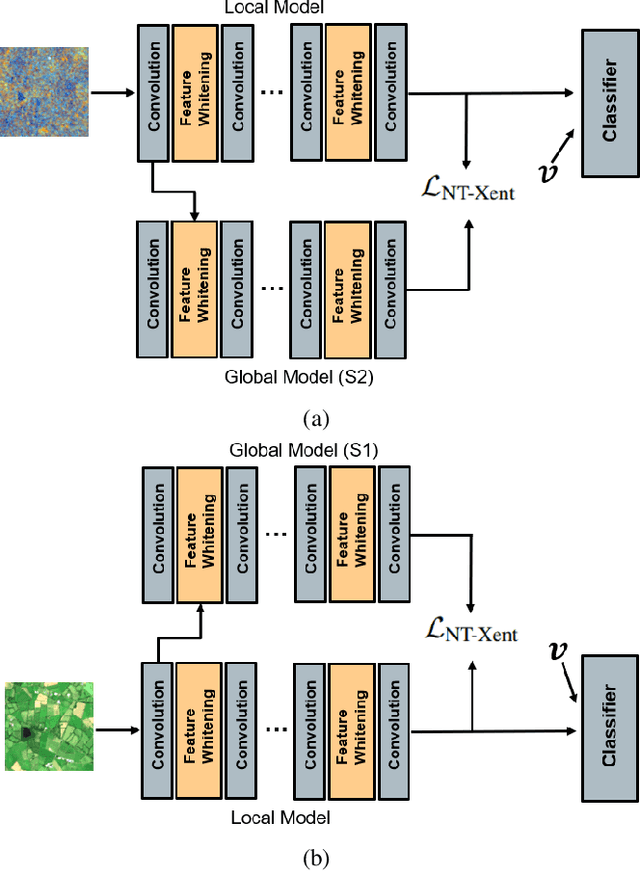
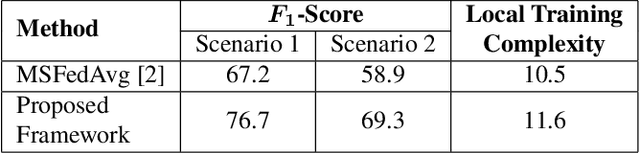
The development of federated learning (FL) methods, which aim to learn from distributed databases (i.e., clients) without accessing data on clients, has recently attracted great attention. Most of these methods assume that the clients are associated with the same data modality. However, remote sensing (RS) images in different clients can be associated with different data modalities that can improve the classification performance when jointly used. To address this problem, in this paper we introduce a novel multi-modal FL framework that aims to learn from decentralized multi-modal RS image archives for RS image classification problems. The proposed framework is made up of three modules: 1) multi-modal fusion (MF); 2) feature whitening (FW); and 3) mutual information maximization (MIM). The MF module performs iterative model averaging to learn without accessing data on clients in the case that clients are associated with different data modalities. The FW module aligns the representations learned among the different clients. The MIM module maximizes the similarity of images from different modalities. Experimental results show the effectiveness of the proposed framework compared to iterative model averaging, which is a widely used algorithm in FL. The code of the proposed framework is publicly available at https://git.tu-berlin.de/rsim/MM-FL.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023
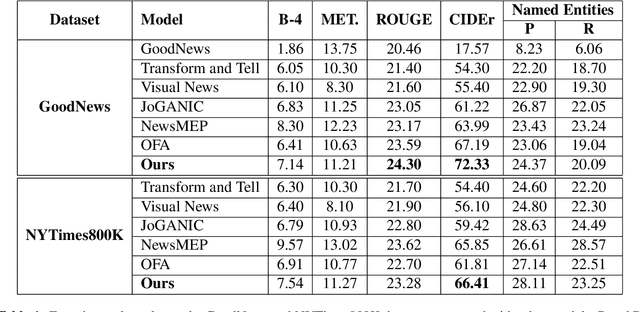
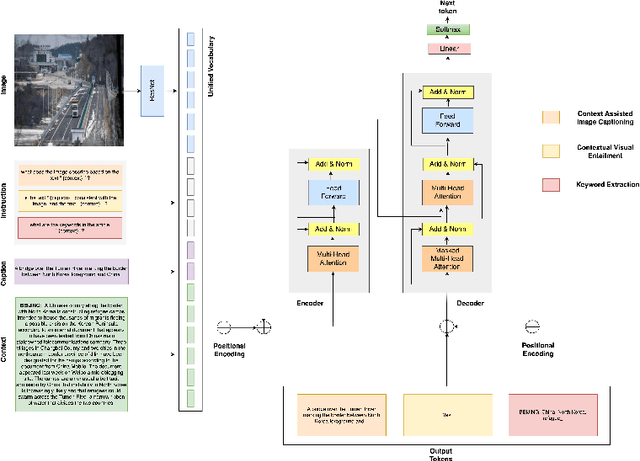
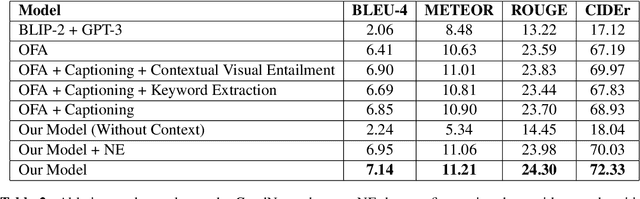
Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
When Does Bottom-up Beat Top-down in Hierarchical Community Detection?
Jun 01, 2023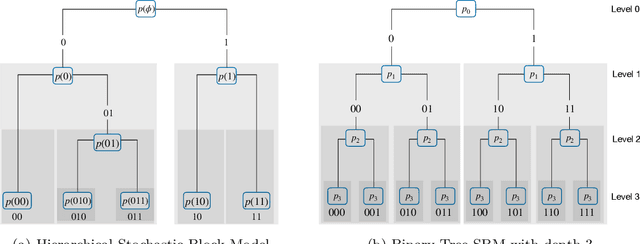
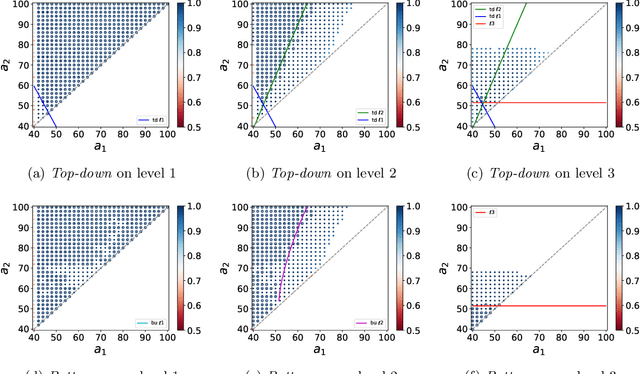

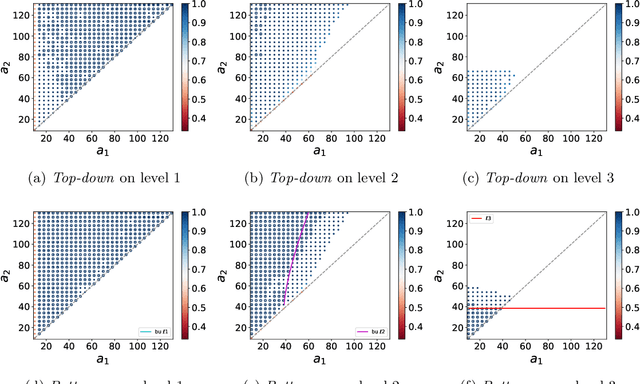
Hierarchical clustering of networks consists in finding a tree of communities, such that lower levels of the hierarchy reveal finer-grained community structures. There are two main classes of algorithms tackling this problem. Divisive ($\textit{top-down}$) algorithms recursively partition the nodes into two communities, until a stopping rule indicates that no further split is needed. In contrast, agglomerative ($\textit{bottom-up}$) algorithms first identify the smallest community structure and then repeatedly merge the communities using a $\textit{linkage}$ method. In this article, we establish theoretical guarantees for the recovery of the hierarchical tree and community structure of a Hierarchical Stochastic Block Model by a bottom-up algorithm. We also establish that this bottom-up algorithm attains the information-theoretic threshold for exact recovery at intermediate levels of the hierarchy. Notably, these recovery conditions are less restrictive compared to those existing for top-down algorithms. This shows that bottom-up algorithms extend the feasible region for achieving exact recovery at intermediate levels. Numerical experiments on both synthetic and real data sets confirm the superiority of bottom-up algorithms over top-down algorithms. We also observe that top-down algorithms can produce dendrograms with inversions. These findings contribute to a better understanding of hierarchical clustering techniques and their applications in network analysis.
Evaluation of Multi-indicator And Multi-organ Medical Image Segmentation Models
Jun 01, 2023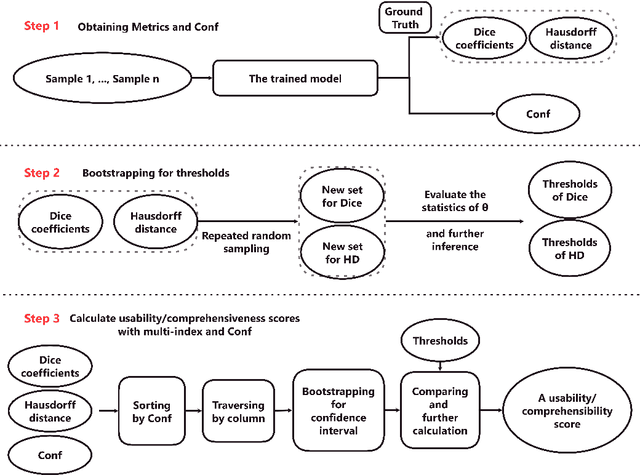
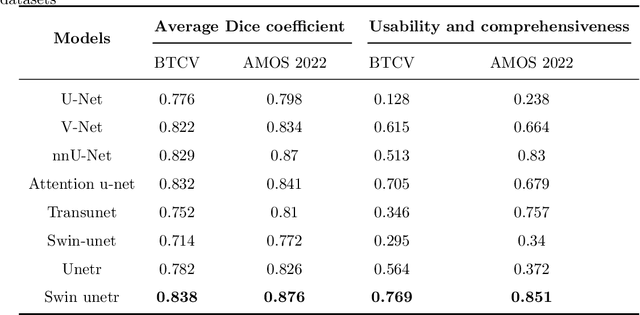

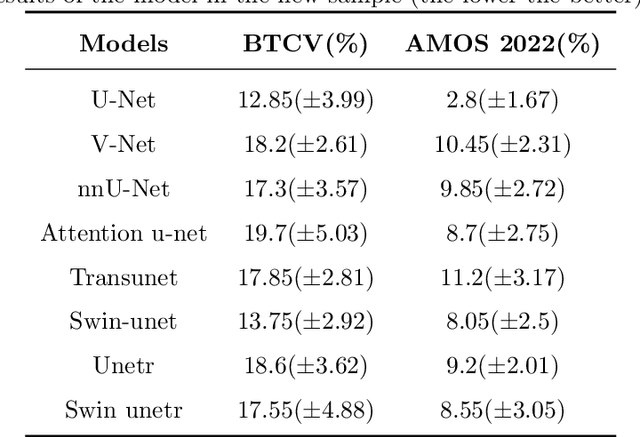
In recent years, "U-shaped" neural networks featuring encoder and decoder structures have gained popularity in the field of medical image segmentation. Various variants of this model have been developed. Nevertheless, the evaluation of these models has received less attention compared to model development. In response, we propose a comprehensive method for evaluating medical image segmentation models for multi-indicator and multi-organ (named MIMO). MIMO allows models to generate independent thresholds which are then combined with multi-indicator evaluation and confidence estimation to screen and measure each organ. As a result, MIMO offers detailed information on the segmentation of each organ in each sample, thereby aiding developers in analyzing and improving the model. Additionally, MIMO can produce concise usability and comprehensiveness scores for different models. Models with higher scores are deemed to be excellent models, which is convenient for clinical evaluation. Our research tests eight different medical image segmentation models on two abdominal multi-organ datasets and evaluates them from four perspectives: correctness, confidence estimation, Usable Region and MIMO. Furthermore, robustness experiments are tested. Experimental results demonstrate that MIMO offers novel insights into multi-indicator and multi-organ medical image evaluation and provides a specific and concise measure for the usability and comprehensiveness of the model. Code: https://github.com/SCUT-ML-GUO/MIMO
Physics-Informed Computer Vision: A Review and Perspectives
Jun 01, 2023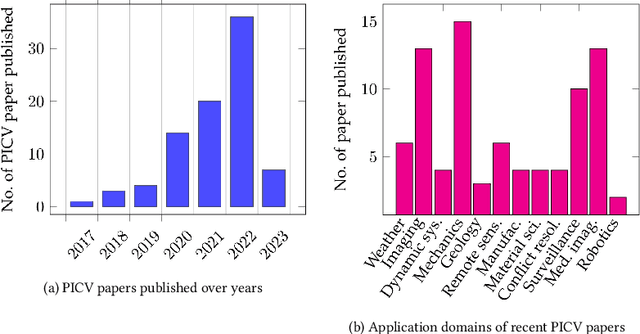
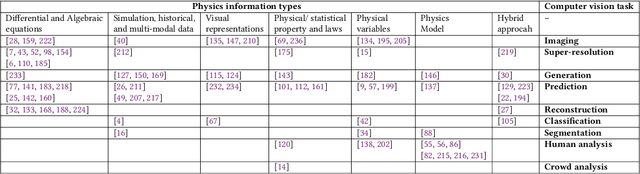
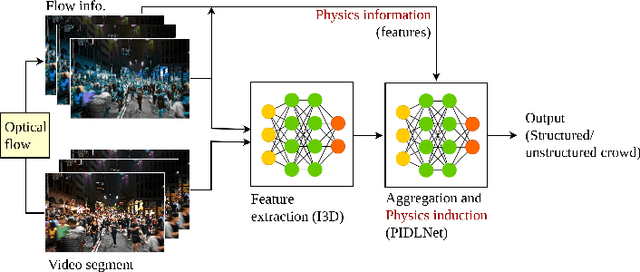
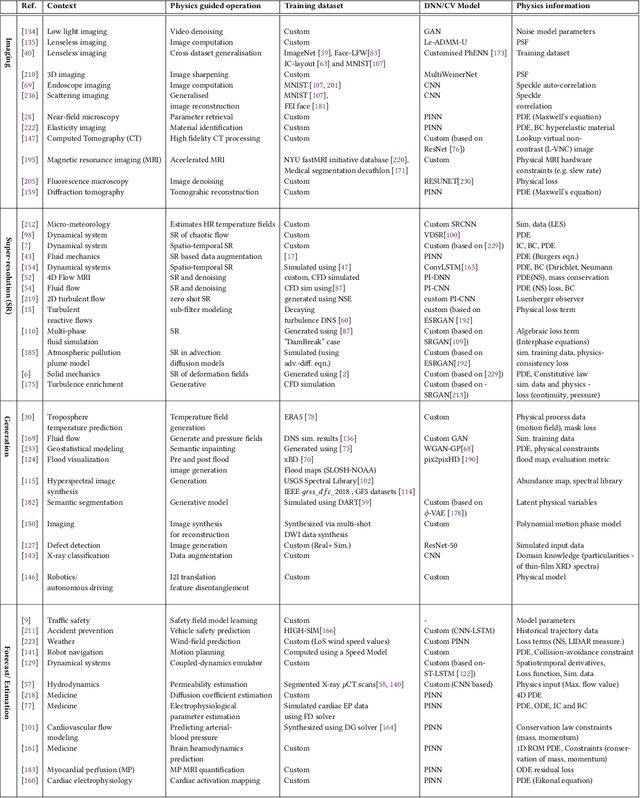
Incorporation of physical information in machine learning frameworks are opening and transforming many application domains. Here the learning process is augmented through the induction of fundamental knowledge and governing physical laws. In this work we explore their utility for computer vision tasks in interpreting and understanding visual data. We present a systematic literature review of formulation and approaches to computer vision tasks guided by physical laws. We begin by decomposing the popular computer vision pipeline into a taxonomy of stages and investigate approaches to incorporate governing physical equations in each stage. Existing approaches in each task are analyzed with regard to what governing physical processes are modeled, formulated and how they are incorporated, i.e. modify data (observation bias), modify networks (inductive bias), and modify losses (learning bias). The taxonomy offers a unified view of the application of the physics-informed capability, highlighting where physics-informed learning has been conducted and where the gaps and opportunities are. Finally, we highlight open problems and challenges to inform future research. While still in its early days, the study of physics-informed computer vision has the promise to develop better computer vision models that can improve physical plausibility, accuracy, data efficiency and generalization in increasingly realistic applications.
LIV: Language-Image Representations and Rewards for Robotic Control
Jun 01, 2023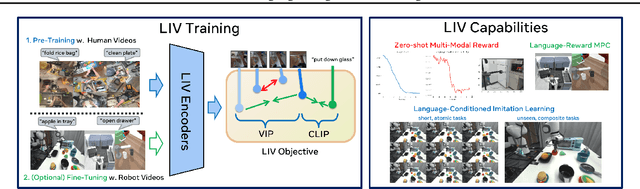
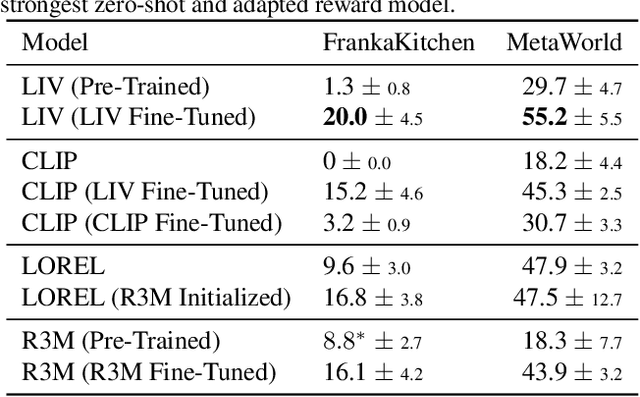
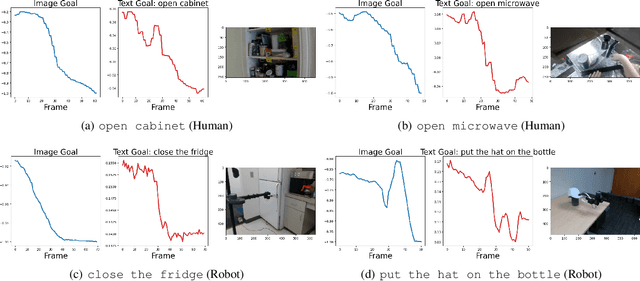
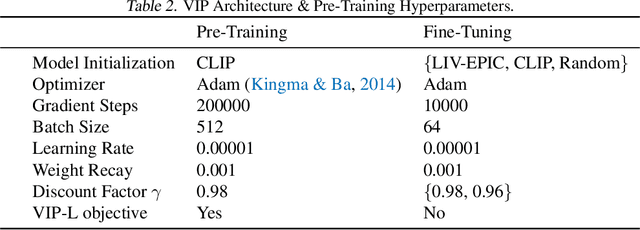
We present Language-Image Value learning (LIV), a unified objective for vision-language representation and reward learning from action-free videos with text annotations. Exploiting a novel connection between dual reinforcement learning and mutual information contrastive learning, the LIV objective trains a multi-modal representation that implicitly encodes a universal value function for tasks specified as language or image goals. We use LIV to pre-train the first control-centric vision-language representation from large human video datasets such as EpicKitchen. Given only a language or image goal, the pre-trained LIV model can assign dense rewards to each frame in videos of unseen robots or humans attempting that task in unseen environments. Further, when some target domain-specific data is available, the same objective can be used to fine-tune and improve LIV and even other pre-trained representations for robotic control and reward specification in that domain. In our experiments on several simulated and real-world robot environments, LIV models consistently outperform the best prior input state representations for imitation learning, as well as reward specification methods for policy synthesis. Our results validate the advantages of joint vision-language representation and reward learning within the unified, compact LIV framework.
Validating Multimedia Content Moderation Software via Semantic Fusion
May 23, 2023
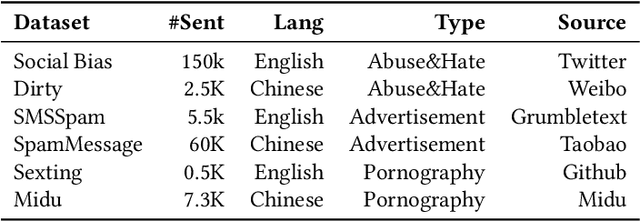

The exponential growth of social media platforms, such as Facebook and TikTok, has revolutionized communication and content publication in human society. Users on these platforms can publish multimedia content that delivers information via the combination of text, audio, images, and video. Meanwhile, the multimedia content release facility has been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisements, and pornography. To this end, content moderation software has been widely deployed on these platforms to detect and blocks toxic content. However, due to the complexity of content moderation models and the difficulty of understanding information across multiple modalities, existing content moderation software can fail to detect toxic content, which often leads to extremely negative impacts. We introduce Semantic Fusion, a general, effective methodology for validating multimedia content moderation software. Our key idea is to fuse two or more existing single-modal inputs (e.g., a textual sentence and an image) into a new input that combines the semantics of its ancestors in a novel manner and has toxic nature by construction. This fused input is then used for validating multimedia content moderation software. We realized Semantic Fusion as DUO, a practical content moderation software testing tool. In our evaluation, we employ DUO to test five commercial content moderation software and two state-of-the-art models against three kinds of toxic content. The results show that DUO achieves up to 100% error finding rate (EFR) when testing moderation software. In addition, we leverage the test cases generated by DUO to retrain the two models we explored, which largely improves model robustness while maintaining the accuracy on the original test set.
Appraising the Potential Uses and Harms of LLMs for Medical Systematic Reviews
May 22, 2023
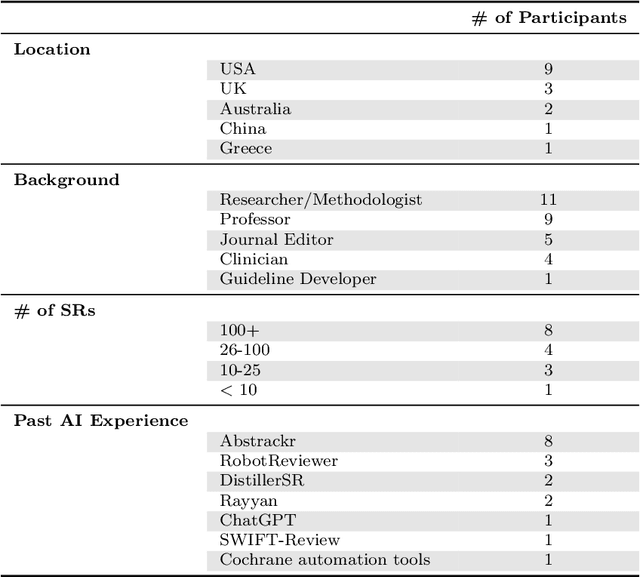
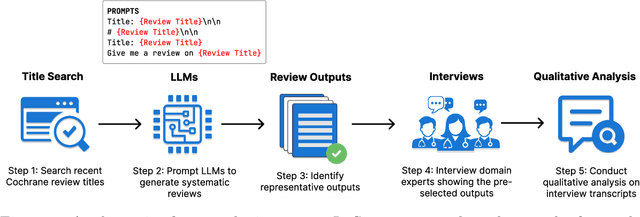
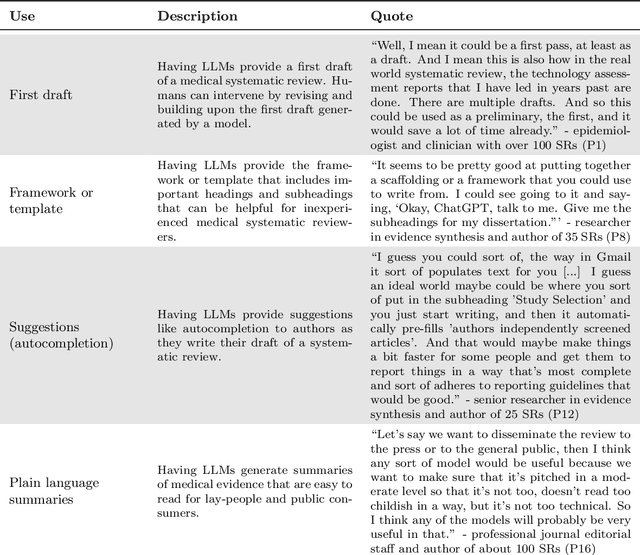
Medical systematic reviews are crucial for informing clinical decision making and healthcare policy. But producing such reviews is onerous and time-consuming. Thus, high-quality evidence synopses are not available for many questions and may be outdated even when they are available. Large language models (LLMs) are now capable of generating long-form texts, suggesting the tantalizing possibility of automatically generating literature reviews on demand. However, LLMs sometimes generate inaccurate (and potentially misleading) texts by hallucinating or omitting important information. In the healthcare context, this may render LLMs unusable at best and dangerous at worst. Most discussion surrounding the benefits and risks of LLMs have been divorced from specific applications. In this work, we seek to qualitatively characterize the potential utility and risks of LLMs for assisting in production of medical evidence reviews. We conducted 16 semi-structured interviews with international experts in systematic reviews, grounding discussion in the context of generating evidence reviews. Domain experts indicated that LLMs could aid writing reviews, as a tool for drafting or creating plain language summaries, generating templates or suggestions, distilling information, crosschecking, and synthesizing or interpreting text inputs. But they also identified issues with model outputs and expressed concerns about potential downstream harms of confidently composed but inaccurate LLM outputs which might mislead. Other anticipated potential downstream harms included lessened accountability and proliferation of automatically generated reviews that might be of low quality. Informed by this qualitative analysis, we identify criteria for rigorous evaluation of biomedical LLMs aligned with domain expert views.
Symbol-Level Noise-Guessing Decoding with Antenna Sorting for URLLC Massive MIMO
May 22, 2023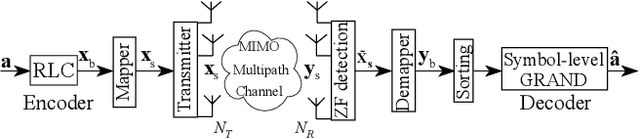
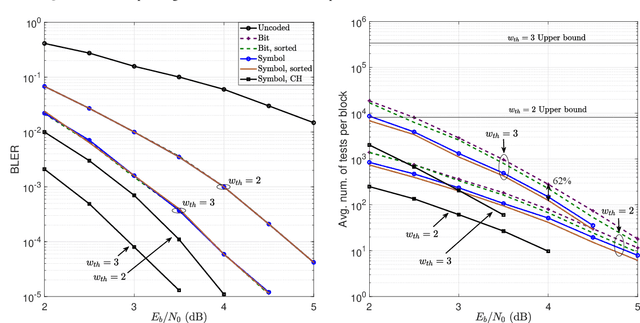
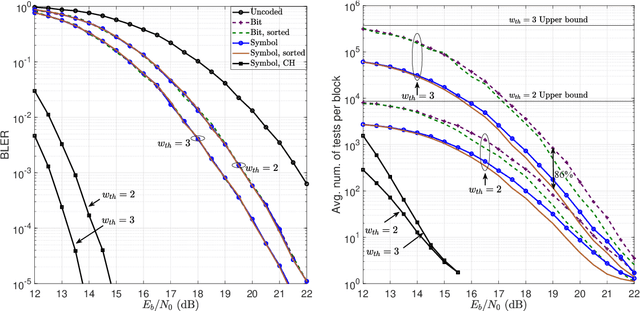
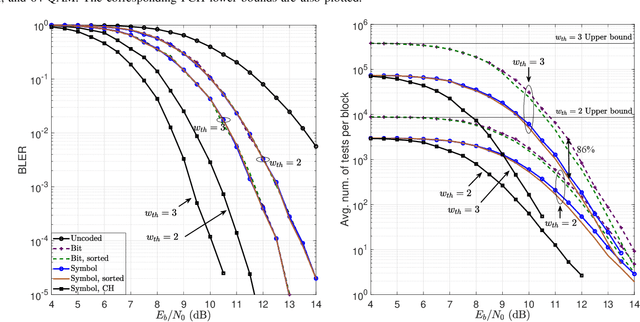
Providing ultra-reliable and low-latency transmission is a current issue in wireless communications (URLLC). While it is commonly known that channel coding with large codewords improves reliability, this usually necessitates using interleavers, which incur undesired latency. Using short codewords is a necessary adjustment that will eliminate the requirement for interleaving and reduce decoding latency. This paper suggests a coding and decoding system that, combined with the high spectral efficiency of spatial multiplexing, can provide URLLC over a fading wireless channel. Random linear codes (RLCs) are used over a block-fading massive multiple input-multiple-output (mMIMO) channel followed by zero-forcing (ZF) detection and guessing random additive noise decoding (GRAND). A variation of GRAND, called symbol-level GRAND, originally proposed for single-antenna systems, is generalized to spatial multiplexing. Symbol-level GRAND is much more computationally effective than bit-level GRAND as it takes advantage of the structure of the constellation of the modulation. The paper analyses the performance of symbol-level GRAND depending on the orthogonality defect (OD) of the underlying lattice. Symbol-level GRAND takes advantage of the a priori probability of each error pattern given a received symbol, and specifies the order in which error patterns are tested. The paper further proposes to make use of further side-information that comes from the mMIMO channel-state information (CSI) and its impacts on the reliability of each antenna. This induces an antenna sorting order that further reduces the decoding complexity by over 80 percent when comparing with bit-level GRAND.