 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023
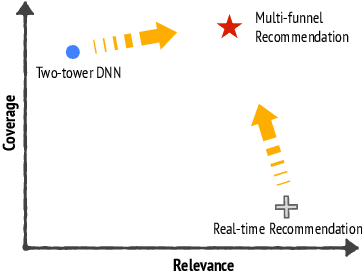
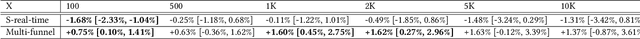
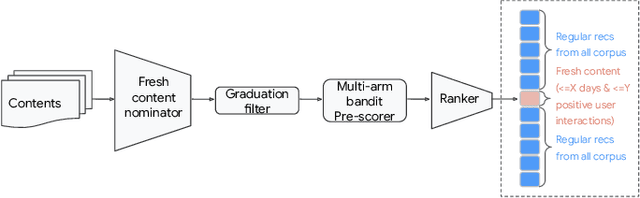

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Linked Deep Gaussian Process Emulation for Model Networks
Jun 02, 2023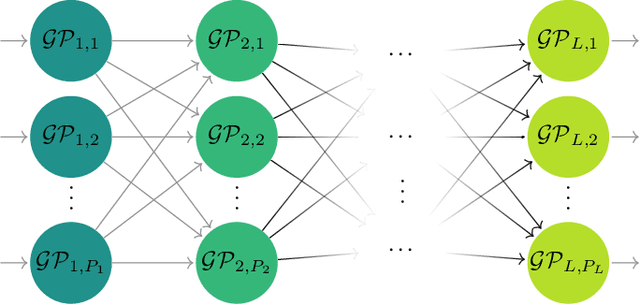
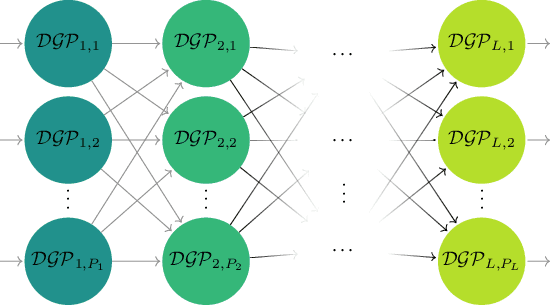
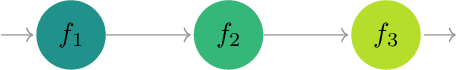
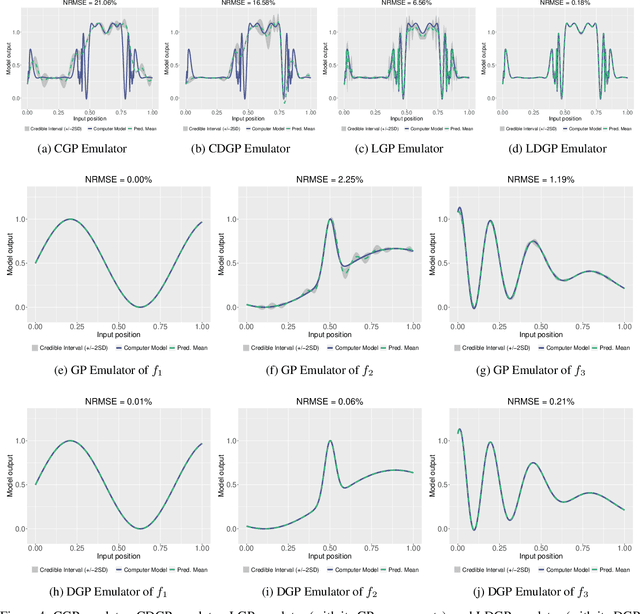
Modern scientific problems are often multi-disciplinary and require integration of computer models from different disciplines, each with distinct functional complexities, programming environments, and computation times. Linked Gaussian process (LGP) emulation tackles this challenge through a divide-and-conquer strategy that integrates Gaussian process emulators of the individual computer models in a network. However, the required stationarity of the component Gaussian process emulators within the LGP framework limits its applicability in many real-world applications. In this work, we conceptualize a network of computer models as a deep Gaussian process with partial exposure of its hidden layers. We develop a method for inference for these partially exposed deep networks that retains a key strength of the LGP framework, whereby each model can be emulated separately using a DGP and then linked together. We show in both synthetic and empirical examples that our linked deep Gaussian process emulators exhibit significantly better predictive performance than standard LGP emulators in terms of accuracy and uncertainty quantification. They also outperform single DGPs fitted to the network as a whole because they are able to integrate information from the partially exposed hidden layers. Our methods are implemented in an R package $\texttt{dgpsi}$ that is freely available on CRAN.
Semantic-guided context modeling for indoor scene recognition
May 22, 2023
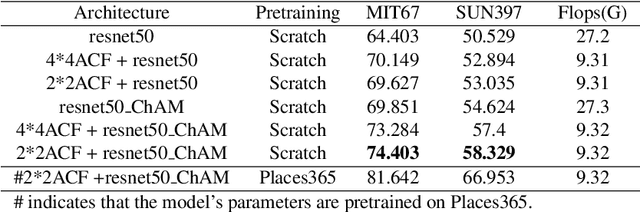
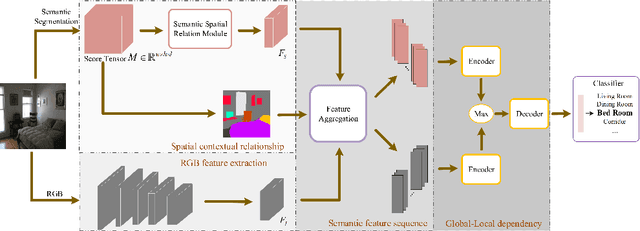
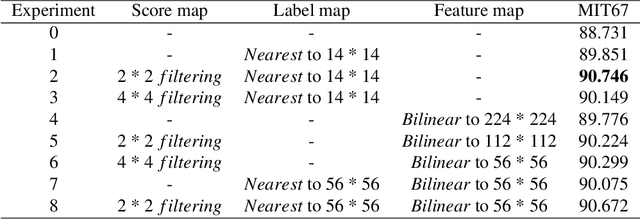
Exploring the semantic context in scene images is essential for indoor scene recognition. However, due to the diverse intra-class spatial layouts and the coexisting inter-class objects, modeling contextual relationships to adapt various image characteristics is a great challenge. Existing contextual modeling methods for indoor scene recognition exhibit two limitations: 1) During training, space-independent information, such as color, may hinder optimizing the network's capacity to represent the spatial context. 2) These methods often overlook the differences in coexisting objects across different scenes, suppressing the performance of scene recognition. To address these limitations, we propose SpaCoNet, a novel approach that simultaneously models the Spatial relation and Co-occurrence of objects based on semantic segmentation. Firstly, the semantic spatial relation module (SSRM) is designed to explore the spatial relations among objects within a scene. With the help of semantic segmentation, this module decouples the spatial information from the image, effectively avoiding the influence of irrelevant features. Secondly, both spatial context features from SSRM and deep features from RGB feature extractor are used to distinguish the coexisting object across different scenes. Finally, utilizing the discriminative features mentioned above, we employ the self-attention mechanism to explore the long-range co-occurrence relationships among objects, and further generate a semantic-guided feature representation for indoor scene recognition. Experimental results on three publicly available datasets demonstrate the effectiveness and generality of the proposed method. The code will be made publicly available after the blind-review process is completed.
Bert4CMR: Cross-Market Recommendation with Bidirectional Encoder Representations from Transformer
May 24, 2023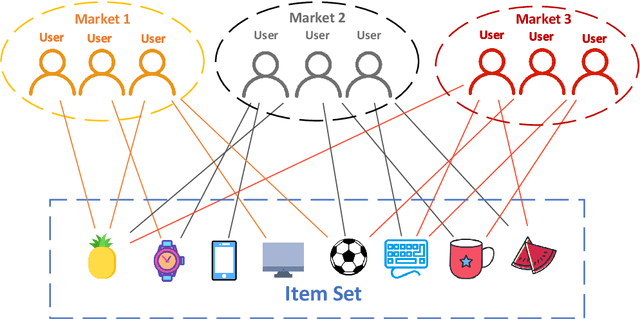
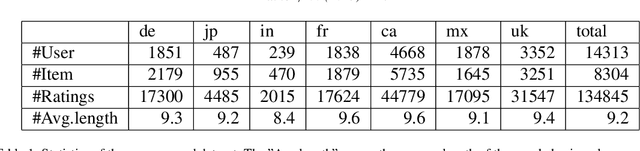
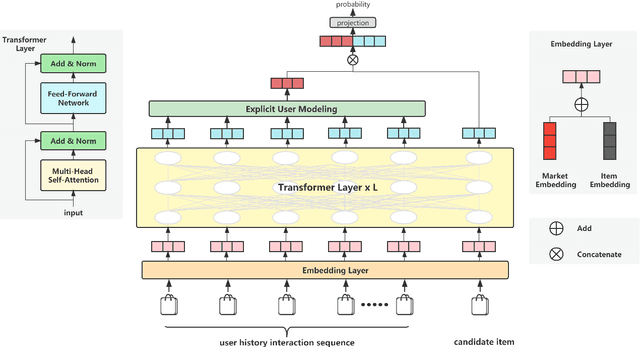
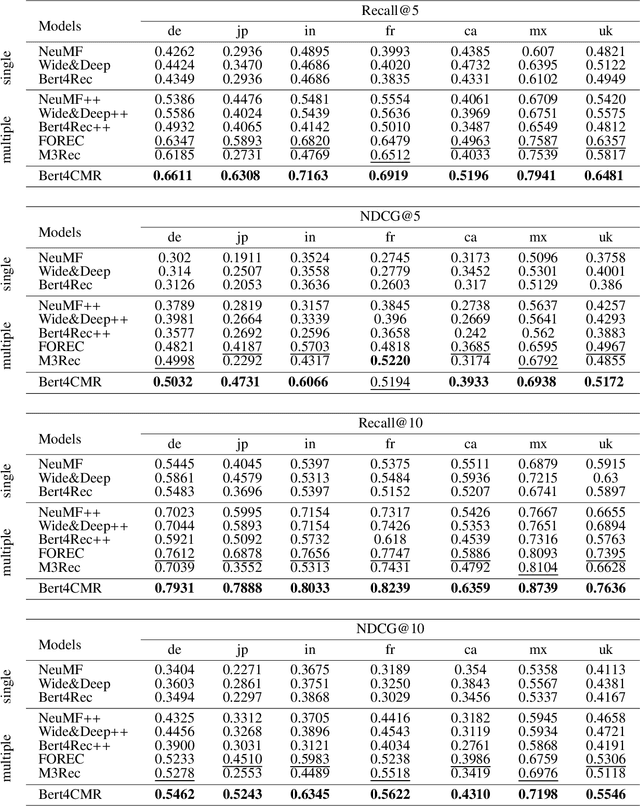
Real-world multinational e-commerce companies, such as Amazon and eBay, serve in multiple countries and regions. Obviously, these markets have similar goods but different users. Some markets are data-scarce, while others are data-rich. In recent years, cross-market recommendation (CMR) has been proposed to enhance data-scarce markets by leveraging auxiliary information from data-rich markets. Previous works fine-tune the pre-trained model on the local market after freezing part of the parameters or introducing inter-market similarity into the local market to improve the performance of CMR. However, they generally do not consider eliminating the mutual interference between markets. Therefore, the existing methods are neither unable to learn unbiased general knowledge nor efficient transfer reusable information across markets. In this paper, we propose a novel attention-based model called Bert4CMR to simultaneously improve all markets' recommendation performance. Specifically, we employ the attention mechanism to capture user interests by modelling user behavioural sequences. We pre-train the proposed model on global data to learn the general knowledge of items. Then we fine-tune specific target markets to perform local recommendations. We propose market embedding to model the bias of each market and reduce the mutual inference between the parallel markets. Extensive experiments conducted on seven markets show that our model is state-of-the-art. Our model outperforms the suboptimal model by 4.82%, 4.73%, 7.66% and 6.49% on average of seven datasets in terms of four metrics, respectively. We conduct ablation experiments to analyse the effectiveness of the proposed components. Experimental results indicate that our model is able to learn general knowledge through global data and shield the mutual interference between markets.
Colexifications for Bootstrapping Cross-lingual Datasets: The Case of Phonology, Concreteness, and Affectiveness
Jun 05, 2023


Colexification refers to the linguistic phenomenon where a single lexical form is used to convey multiple meanings. By studying cross-lingual colexifications, researchers have gained valuable insights into fields such as psycholinguistics and cognitive sciences [Jackson et al.,2019]. While several multilingual colexification datasets exist, there is untapped potential in using this information to bootstrap datasets across such semantic features. In this paper, we aim to demonstrate how colexifications can be leveraged to create such cross-lingual datasets. We showcase curation procedures which result in a dataset covering 142 languages across 21 language families across the world. The dataset includes ratings of concreteness and affectiveness, mapped with phonemes and phonological features. We further analyze the dataset along different dimensions to demonstrate potential of the proposed procedures in facilitating further interdisciplinary research in psychology, cognitive science, and multilingual natural language processing (NLP). Based on initial investigations, we observe that i) colexifications that are closer in concreteness/affectiveness are more likely to colexify; ii) certain initial/last phonemes are significantly correlated with concreteness/affectiveness intra language families, such as /k/ as the initial phoneme in both Turkic and Tai-Kadai correlated with concreteness, and /p/ in Dravidian and Sino-Tibetan correlated with Valence; iii) the type-to-token ratio (TTR) of phonemes are positively correlated with concreteness across several language families, while the length of phoneme segments are negatively correlated with concreteness; iv) certain phonological features are negatively correlated with concreteness across languages. The dataset is made public online for further research.
Path-Specific Counterfactual Fairness for Recommender Systems
Jun 05, 2023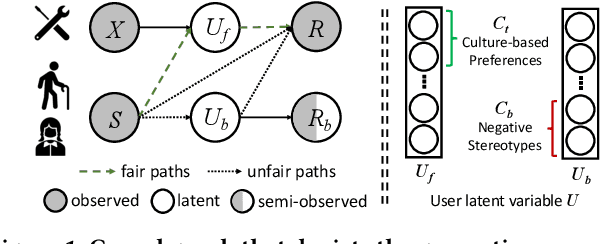
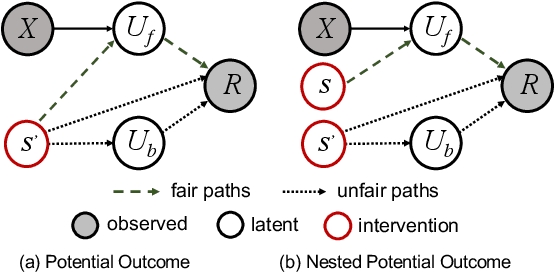
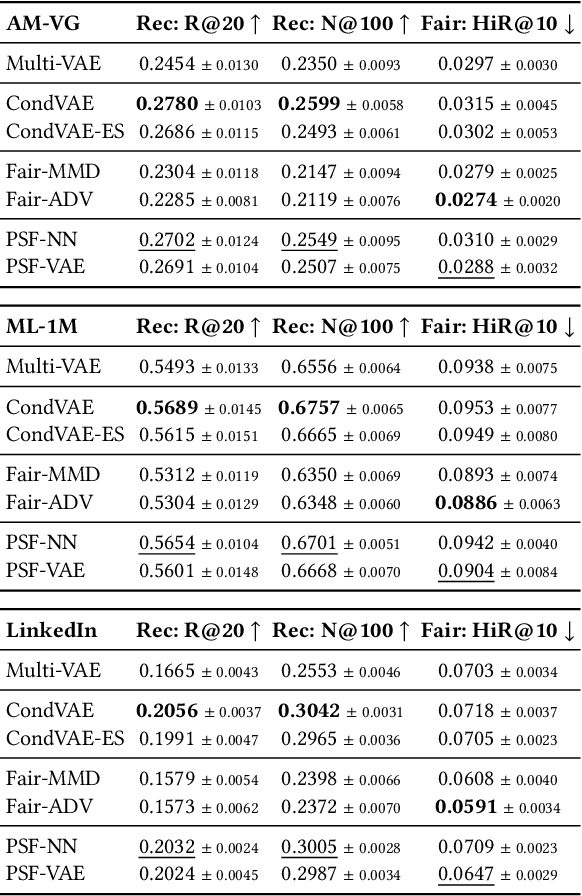
Recommender systems (RSs) have become an indispensable part of online platforms. With the growing concerns of algorithmic fairness, RSs are not only expected to deliver high-quality personalized content, but are also demanded not to discriminate against users based on their demographic information. However, existing RSs could capture undesirable correlations between sensitive features and observed user behaviors, leading to biased recommendations. Most fair RSs tackle this problem by completely blocking the influences of sensitive features on recommendations. But since sensitive features may also affect user interests in a fair manner (e.g., race on culture-based preferences), indiscriminately eliminating all the influences of sensitive features inevitably degenerate the recommendations quality and necessary diversities. To address this challenge, we propose a path-specific fair RS (PSF-RS) for recommendations. Specifically, we summarize all fair and unfair correlations between sensitive features and observed ratings into two latent proxy mediators, where the concept of path-specific bias (PS-Bias) is defined based on path-specific counterfactual inference. Inspired by Pearl's minimal change principle, we address the PS-Bias by minimally transforming the biased factual world into a hypothetically fair world, where a fair RS model can be learned accordingly by solving a constrained optimization problem. For the technical part, we propose a feasible implementation of PSF-RS, i.e., PSF-VAE, with weakly-supervised variational inference, which robustly infers the latent mediators such that unfairness can be mitigated while necessary recommendation diversities can be maximally preserved simultaneously. Experiments conducted on semi-simulated and real-world datasets demonstrate the effectiveness of PSF-RS.
Using Sequences of Life-events to Predict Human Lives
Jun 05, 2023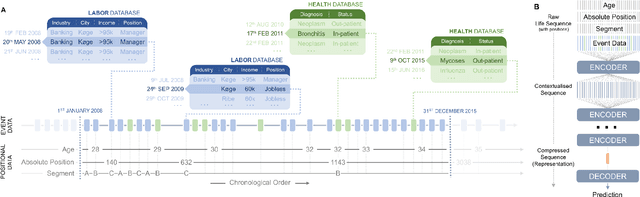
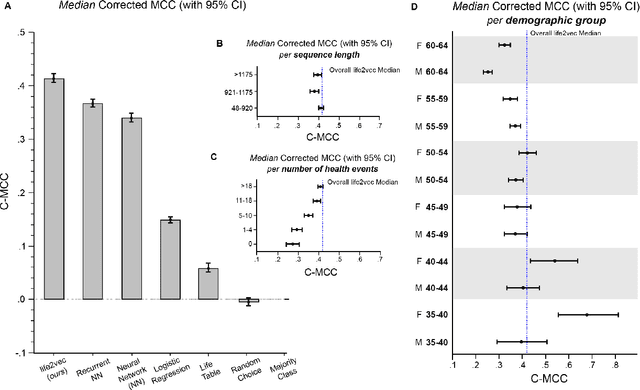
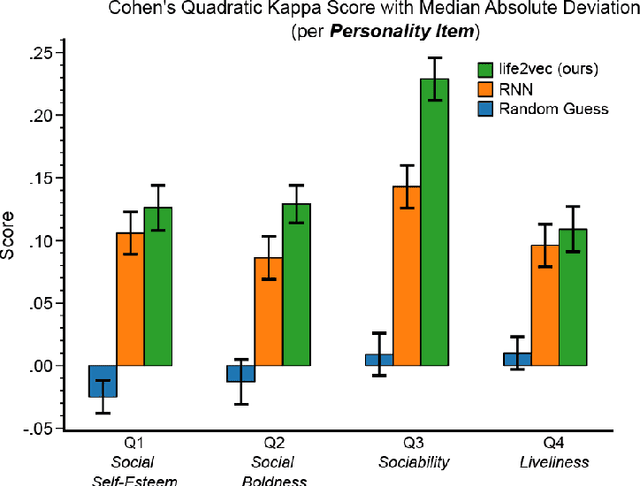
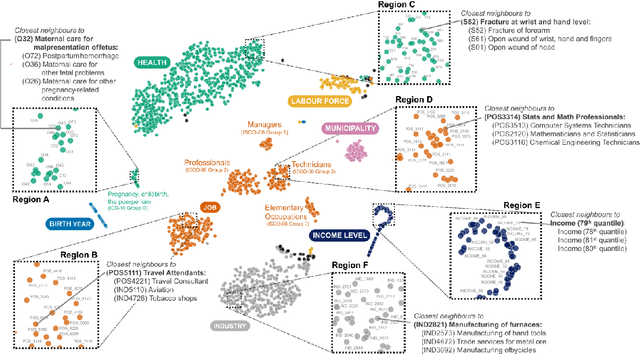
Over the past decade, machine learning has revolutionized computers' ability to analyze text through flexible computational models. Due to their structural similarity to written language, transformer-based architectures have also shown promise as tools to make sense of a range of multi-variate sequences from protein-structures, music, electronic health records to weather-forecasts. We can also represent human lives in a way that shares this structural similarity to language. From one perspective, lives are simply sequences of events: People are born, visit the pediatrician, start school, move to a new location, get married, and so on. Here, we exploit this similarity to adapt innovations from natural language processing to examine the evolution and predictability of human lives based on detailed event sequences. We do this by drawing on arguably the most comprehensive registry data in existence, available for an entire nation of more than six million individuals across decades. Our data include information about life-events related to health, education, occupation, income, address, and working hours, recorded with day-to-day resolution. We create embeddings of life-events in a single vector space showing that this embedding space is robust and highly structured. Our models allow us to predict diverse outcomes ranging from early mortality to personality nuances, outperforming state-of-the-art models by a wide margin. Using methods for interpreting deep learning models, we probe the algorithm to understand the factors that enable our predictions. Our framework allows researchers to identify new potential mechanisms that impact life outcomes and associated possibilities for personalized interventions.
Physics-Assisted Reduced-Order Modeling for Identifying Dominant Features of Transonic Buffet
May 23, 2023
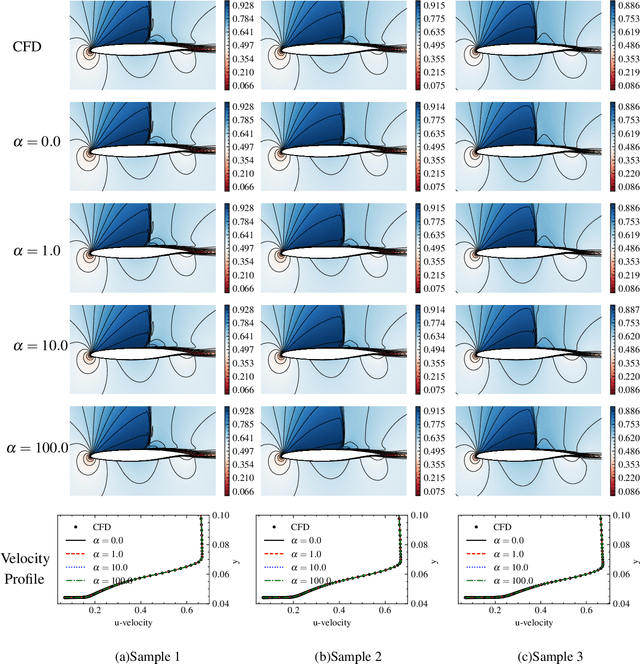
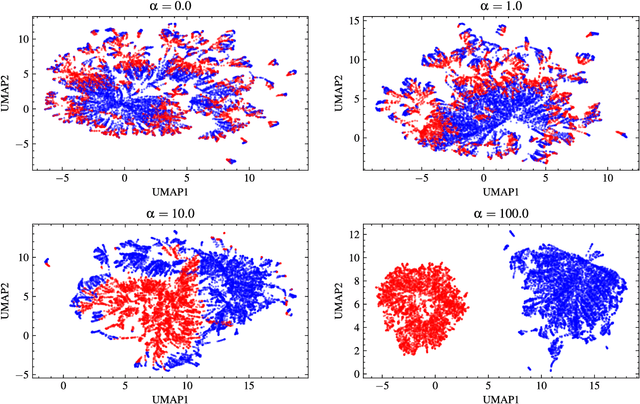
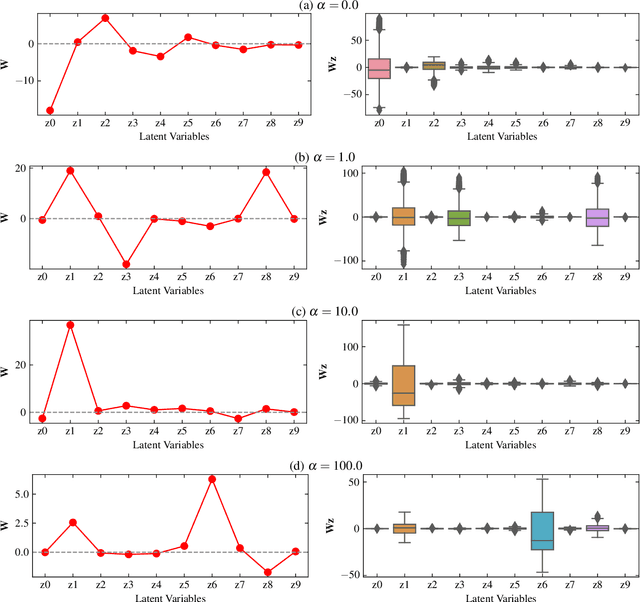
Transonic buffet is a flow instability phenomenon that arises from the interaction between the shock wave and the separated boundary layer. This flow phenomenon is considered to be highly detrimental during flight and poses a significant risk to the structural strength and fatigue life of aircraft. Up to now, there has been a lack of an accurate, efficient, and intuitive metric to predict buffet and impose a feasible constraint on aerodynamic design. In this paper, a Physics-Assisted Variational Autoencoder (PAVAE) is proposed to identify dominant features of transonic buffet, which combines unsupervised reduced-order modeling with additional physical information embedded via a buffet classifier. Specifically, four models with various weights adjusting the contribution of the classifier are trained, so as to investigate the impact of buffet information on the latent space. Statistical results reveal that buffet state can be determined exactly with just one latent space when a proper weight of classifier is chosen. The dominant latent space further reveals a strong relevance with the key flow features located in the boundary layers downstream of shock. Based on this identification, the displacement thickness at 80% chordwise location is proposed as a metric for buffet prediction. This metric achieves an accuracy of 98.5% in buffet state classification, which is more reliable than the existing separation metric used in design. The proposed method integrates the benefits of feature extraction, flow reconstruction, and buffet prediction into a unified framework, demonstrating its potential in low-dimensional representations of high-dimensional flow data and interpreting the "black box" neural network.
Explainability Techniques for Chemical Language Models
May 25, 2023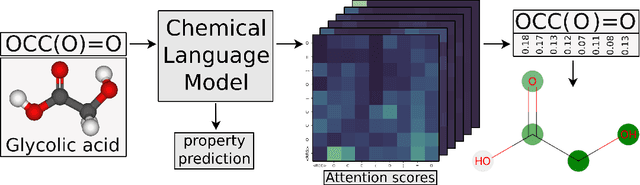
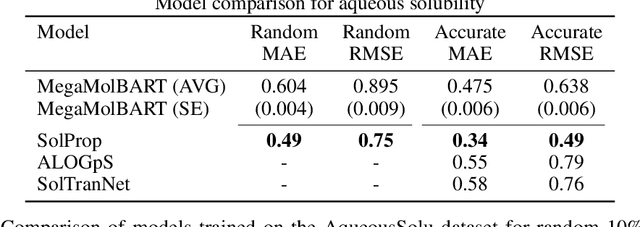
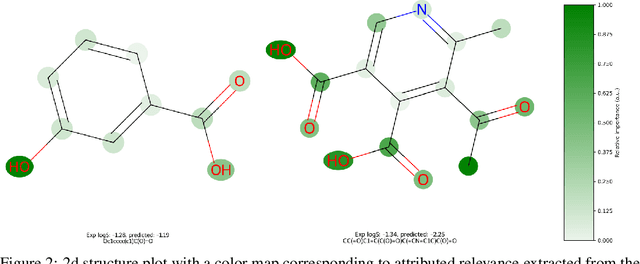
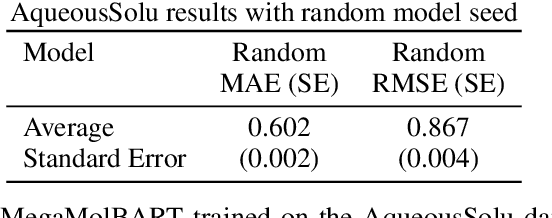
Explainability techniques are crucial in gaining insights into the reasons behind the predictions of deep learning models, which have not yet been applied to chemical language models. We propose an explainable AI technique that attributes the importance of individual atoms towards the predictions made by these models. Our method backpropagates the relevance information towards the chemical input string and visualizes the importance of individual atoms. We focus on self-attention Transformers operating on molecular string representations and leverage a pretrained encoder for finetuning. We showcase the method by predicting and visualizing solubility in water and organic solvents. We achieve competitive model performance while obtaining interpretable predictions, which we use to inspect the pretrained model.
Optimization and Interpretability of Graph Attention Networks for Small Sparse Graph Structures in Automotive Applications
May 25, 2023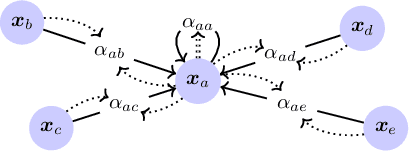
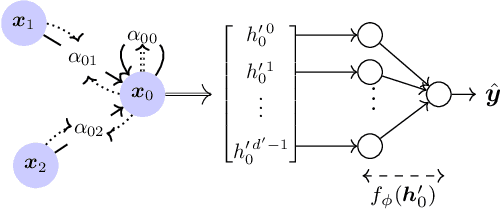
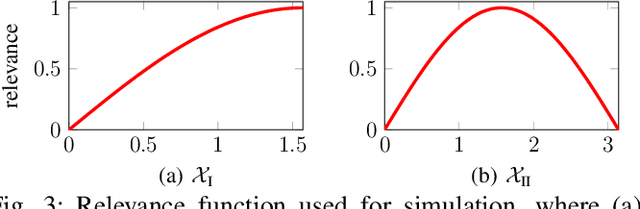
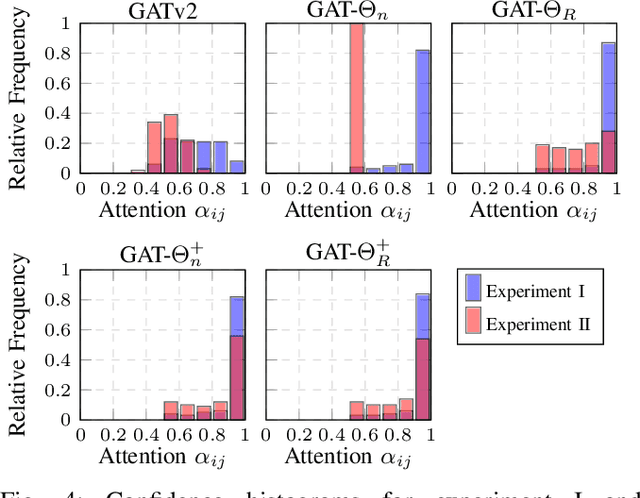
For automotive applications, the Graph Attention Network (GAT) is a prominently used architecture to include relational information of a traffic scenario during feature embedding. As shown in this work, however, one of the most popular GAT realizations, namely GATv2, has potential pitfalls that hinder an optimal parameter learning. Especially for small and sparse graph structures a proper optimization is problematic. To surpass limitations, this work proposes architectural modifications of GATv2. In controlled experiments, it is shown that the proposed model adaptions improve prediction performance in a node-level regression task and make it more robust to parameter initialization. This work aims for a better understanding of the attention mechanism and analyzes its interpretability of identifying causal importance.