 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Interactive Image Inpainting via Sketch Refinement
Jun 01, 2023
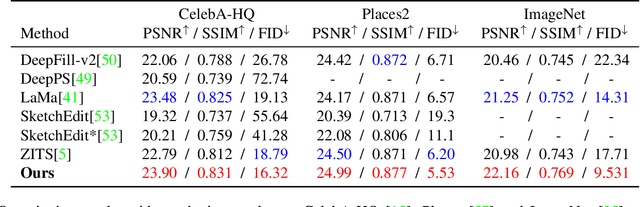
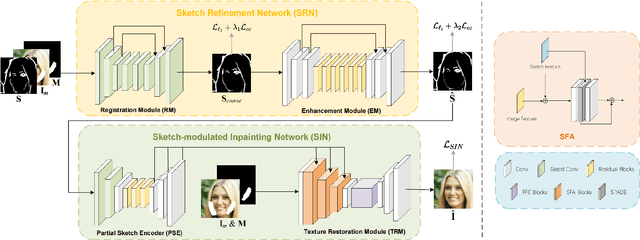
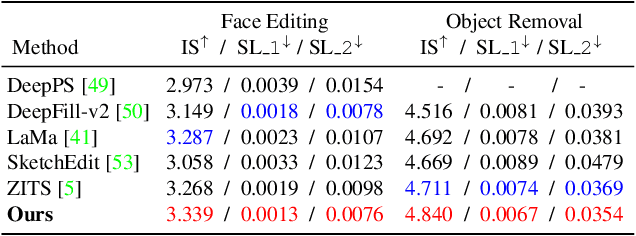

One tough problem of image inpainting is to restore complex structures in the corrupted regions. It motivates interactive image inpainting which leverages additional hints, e.g., sketches, to assist the inpainting process. Sketch is simple and intuitive to end users, but meanwhile has free forms with much randomness. Such randomness may confuse the inpainting models, and incur severe artifacts in completed images. To address this problem, we propose a two-stage image inpainting method termed SketchRefiner. In the first stage, we propose using a cross-correlation loss function to robustly calibrate and refine the user-provided sketches in a coarse-to-fine fashion. In the second stage, we learn to extract informative features from the abstracted sketches in the feature space and modulate the inpainting process. We also propose an algorithm to simulate real sketches automatically and build a test protocol with different applications. Experimental results on public datasets demonstrate that SketchRefiner effectively utilizes sketch information and eliminates the artifacts due to the free-form sketches. Our method consistently outperforms the state-of-the-art ones both qualitatively and quantitatively, meanwhile revealing great potential in real-world applications. Our code and dataset are available.
Stay on Track: A Frenet Wrapper to Overcome Off-road Trajectories in Vehicle Motion Prediction
Jun 01, 2023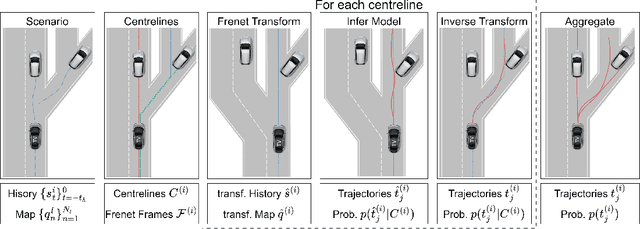
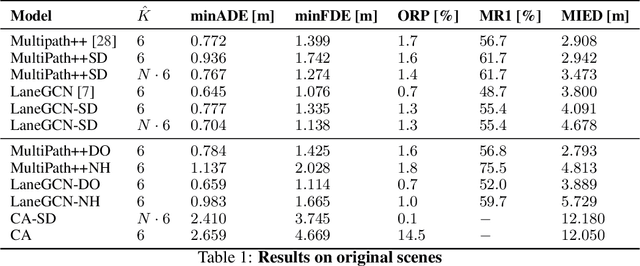
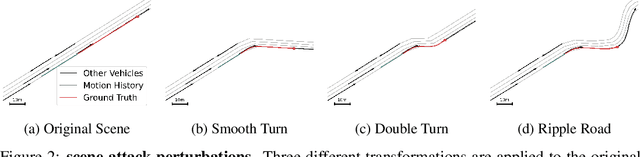
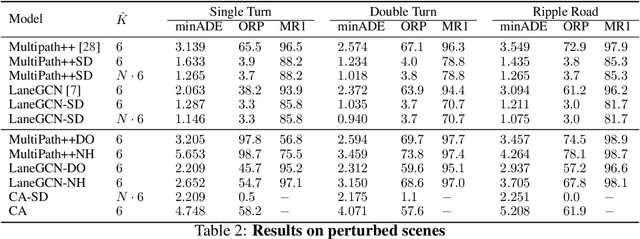
Predicting the future motion of observed vehicles is a crucial enabler for safe autonomous driving. The field of motion prediction has seen large progress recently with State-of-the-Art (SotA) models achieving impressive results on large-scale public benchmarks. However, recent work revealed that learning-based methods are prone to predict off-road trajectories in challenging scenarios. These can be created by perturbing existing scenarios with additional turns in front of the target vehicle while the motion history is left unchanged. We argue that this indicates that SotA models do not consider the map information sufficiently and demonstrate how this can be solved, by representing model inputs and outputs in a Frenet frame defined by lane centreline sequences. To this end, we present a general wrapper that leverages a Frenet representation of the scene and that can be applied to SotA models without changing their architecture. We demonstrate the effectiveness of this approach in a comprehensive benchmark using two SotA motion prediction models. Our experiments show that this reduces the off-road rate on challenging scenarios by more than 90\%, without sacrificing average performance.
Decision-Oriented Dialogue for Human-AI Collaboration
Jun 01, 2023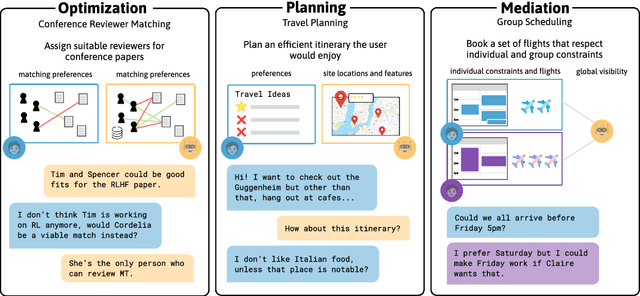

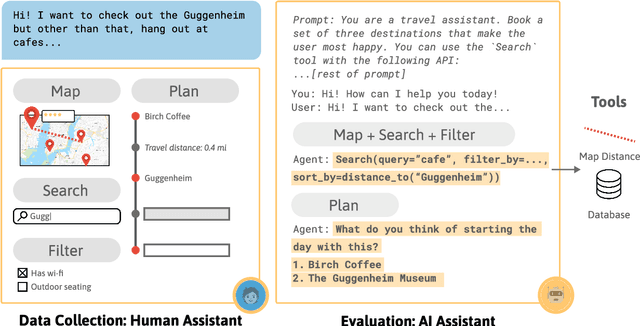
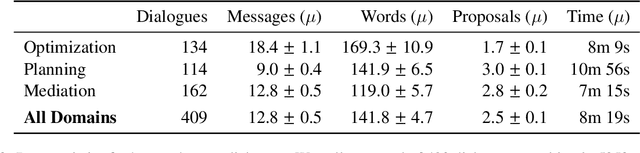
We describe a class of tasks called decision-oriented dialogues, in which AI assistants must collaborate with one or more humans via natural language to help them make complex decisions. We formalize three domains in which users face everyday decisions: (1) choosing an assignment of reviewers to conference papers, (2) planning a multi-step itinerary in a city, and (3) negotiating travel plans for a group of friends. In each of these settings, AI assistants and users have disparate abilities that they must combine to arrive at the best decision: assistants can access and process large amounts of information, while users have preferences and constraints external to the system. For each task, we build a dialogue environment where agents receive a reward based on the quality of the final decision they reach. Using these environments, we collect human-human dialogues with humans playing the role of assistant. To compare how current AI assistants communicate in these settings, we present baselines using large language models in self-play. Finally, we highlight a number of challenges models face in decision-oriented dialogues, ranging from efficient communication to reasoning and optimization, and release our environments as a testbed for future modeling work.
Executive Voiced Laughter and Social Approval: An Explorative Machine Learning Study
May 20, 2023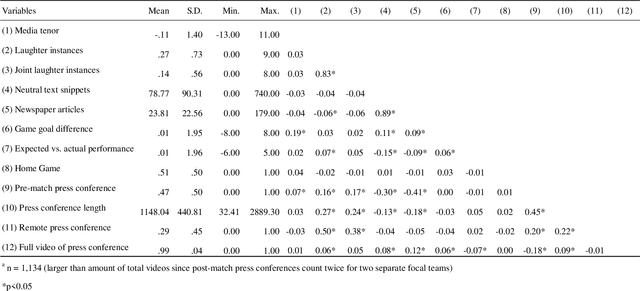
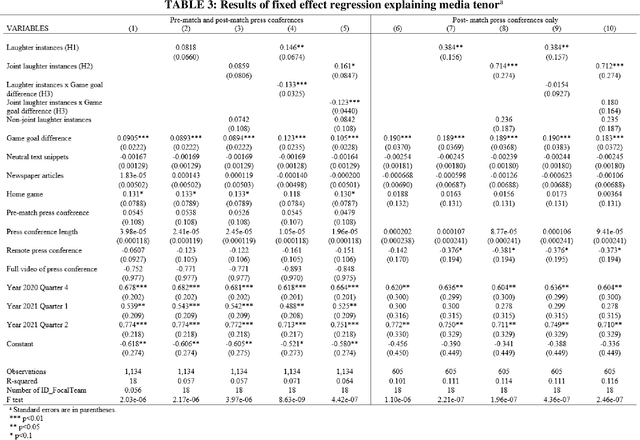
We study voiced laughter in executive communication and its effect on social approval. Integrating research on laughter, affect-as-information, and infomediaries' social evaluations of firms, we hypothesize that voiced laughter in executive communication positively affects social approval, defined as audience perceptions of affinity towards an organization. We surmise that the effect of laughter is especially strong for joint laughter, i.e., the number of instances in a given communication venue for which the focal executive and the audience laugh simultaneously. Finally, combining the notions of affect-as-information and negativity bias in human cognition, we hypothesize that the positive effect of laughter on social approval increases with bad organizational performance. We find partial support for our ideas when testing them on panel data comprising 902 German Bundesliga soccer press conferences and media tenor, applying state-of-the-art machine learning approaches for laughter detection as well as sentiment analysis. Our findings contribute to research at the nexus of executive communication, strategic leadership, and social evaluations, especially by introducing laughter as a highly consequential potential, but understudied social lubricant at the executive-infomediary interface. Our research is unique by focusing on reflexive microprocesses of social evaluations, rather than the infomediary-routines perspectives in infomediaries' evaluations. We also make methodological contributions.
Inter Subject Emotion Recognition Using Spatio-Temporal Features From EEG Signal
May 27, 2023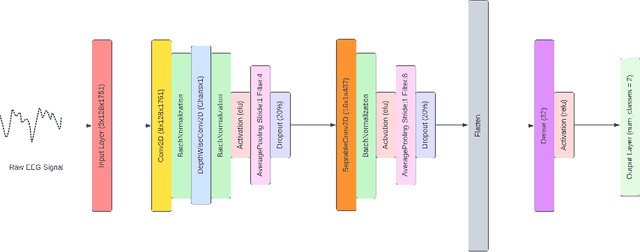

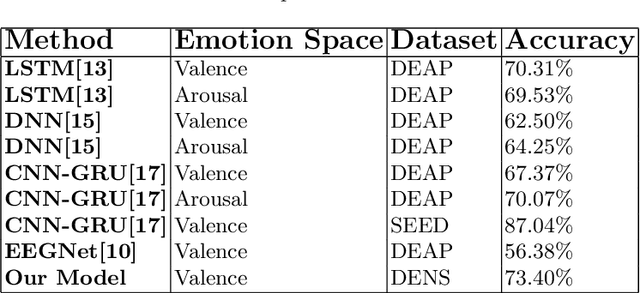
Inter-subject or subject-independent emotion recognition has been a challenging task in affective computing. This work is about an easy-to-implement emotion recognition model that classifies emotions from EEG signals subject independently. It is based on the famous EEGNet architecture, which is used in EEG-related BCIs. We used the Dataset on Emotion using Naturalistic Stimuli (DENS) dataset. The dataset contains the Emotional Events -- the precise information of the emotion timings that participants felt. The model is a combination of regular, depthwise and separable convolution layers of CNN to classify the emotions. The model has the capacity to learn the spatial features of the EEG channels and the temporal features of the EEG signals variability with time. The model is evaluated for the valence space ratings. The model achieved an accuracy of 73.04%.
RDFC-GAN: RGB-Depth Fusion CycleGAN for Indoor Depth Completion
Jun 06, 2023
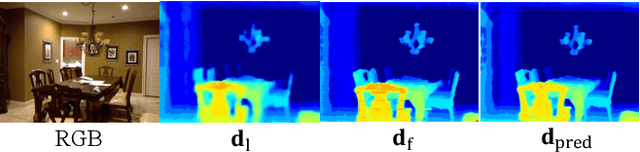

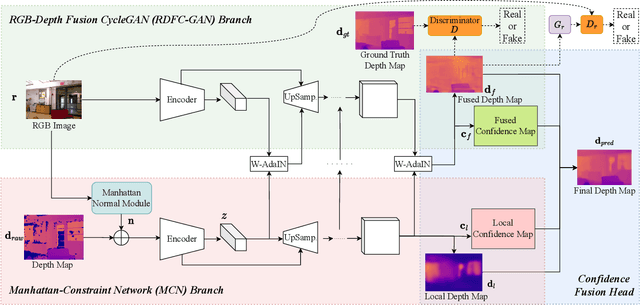
The raw depth image captured by indoor depth sensors usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and the limited distance range. The incomplete depth map with missing values burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing large contiguous regions of missing depth values, which is common and critical in images captured in indoor environments. To overcome these challenges, we design a novel two-branch end-to-end fusion network named RDFC-GAN, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure, by adhering to the Manhattan world assumption and utilizing normal maps from RGB-D information as guidance, to regress the local dense depth values from the raw depth map. In the other branch, we propose an RGB-depth fusion CycleGAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments, with the help of our proposed pseudo depth maps in training.
Mobile User Interface Element Detection Via Adaptively Prompt Tuning
May 16, 2023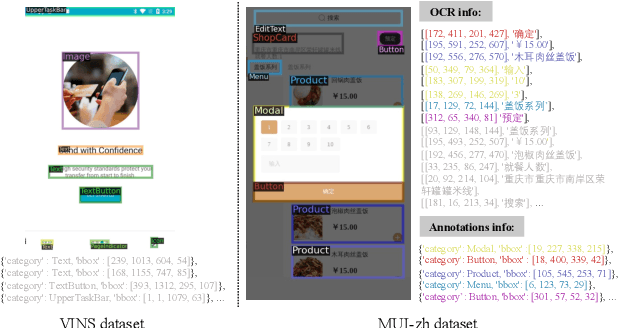
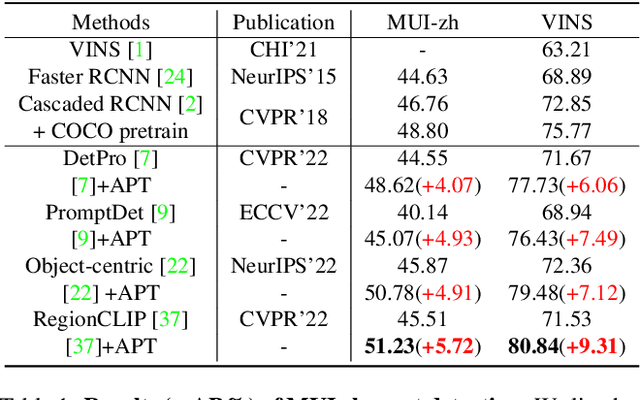
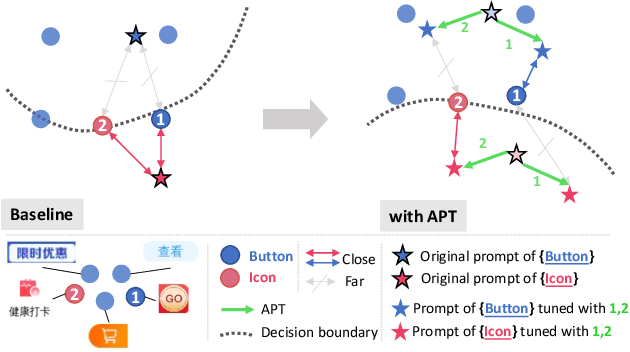
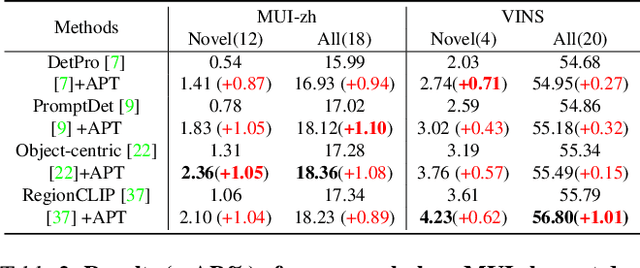
Recent object detection approaches rely on pretrained vision-language models for image-text alignment. However, they fail to detect the Mobile User Interface (MUI) element since it contains additional OCR information, which describes its content and function but is often ignored. In this paper, we develop a new MUI element detection dataset named MUI-zh and propose an Adaptively Prompt Tuning (APT) module to take advantage of discriminating OCR information. APT is a lightweight and effective module to jointly optimize category prompts across different modalities. For every element, APT uniformly encodes its visual features and OCR descriptions to dynamically adjust the representation of frozen category prompts. We evaluate the effectiveness of our plug-and-play APT upon several existing CLIP-based detectors for both standard and open-vocabulary MUI element detection. Extensive experiments show that our method achieves considerable improvements on two datasets. The datasets is available at \url{github.com/antmachineintelligence/MUI-zh}.
Differentially private low-dimensional representation of high-dimensional data
May 26, 2023Differentially private synthetic data provide a powerful mechanism to enable data analysis while protecting sensitive information about individuals. However, when the data lie in a high-dimensional space, the accuracy of the synthetic data suffers from the curse of dimensionality. In this paper, we propose a differentially private algorithm to generate low-dimensional synthetic data efficiently from a high-dimensional dataset with a utility guarantee with respect to the Wasserstein distance. A key step of our algorithm is a private principal component analysis (PCA) procedure with a near-optimal accuracy bound that circumvents the curse of dimensionality. Different from the standard perturbation analysis using the Davis-Kahan theorem, our analysis of private PCA works without assuming the spectral gap for the sample covariance matrix.
Hardware-in-the-Loop and Road Testing of RLVW and GLOSA Connected Vehicle Applications
Jun 02, 2023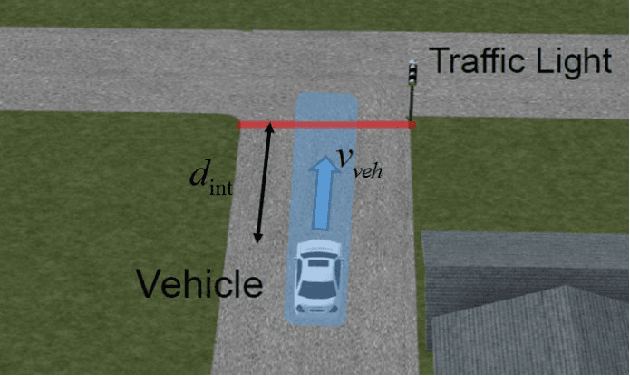

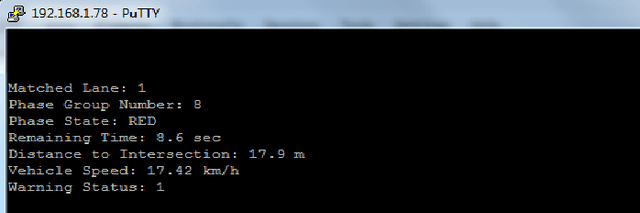
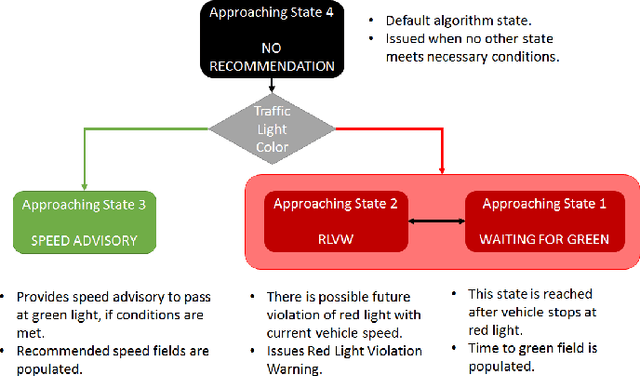
This paper presents an evaluation of two different Vehicle to Infrastructure (V2I) applications, namely Red Light Violation Warning (RLVW) and Green Light Optimized Speed Advisory (GLOSA). The evaluation method is to first develop and use Hardware-in-the-Loop (HIL) simulator testing, followed by extension of the HIL testing to road testing using an experimental connected vehicle. The HIL simulator used in the testing is a state-of-the-art simulator that consists of the same hardware like the road side unit and traffic cabinet as is used in real intersections and allows testing of numerous different traffic and intersection geometry and timing scenarios realistically. First, the RLVW V2I algorithm is tested in the HIL simulator and then implemented in an On-Board-Unit (OBU) in our experimental vehicle and tested at real world intersections. This same approach of HIL testing followed by testing in real intersections using our experimental vehicle is later extended to the GLOSA application. The GLOSA application that is tested in this paper has both an optimal speed advisory for passing at the green light and also includes a red light violation warning system. The paper presents the HIL and experimental vehicle evaluation systems, information about RLVW and GLOSA and HIL simulation and road testing results and their interpretations.
Egocentric Planning for Scalable Embodied Task Achievement
Jun 02, 2023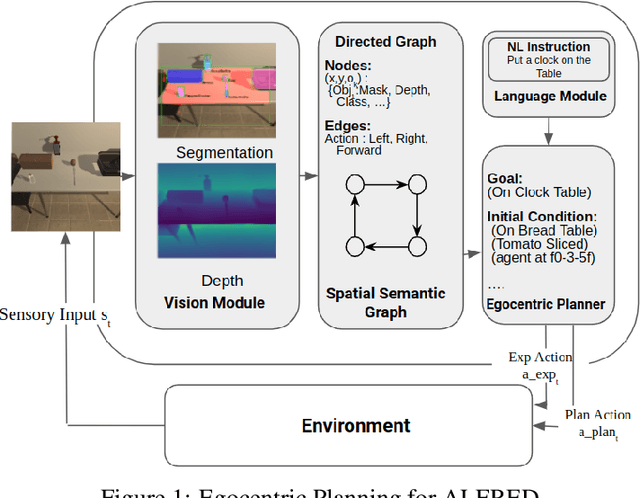
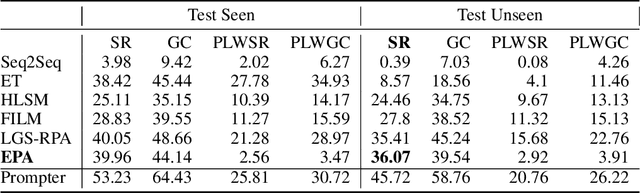
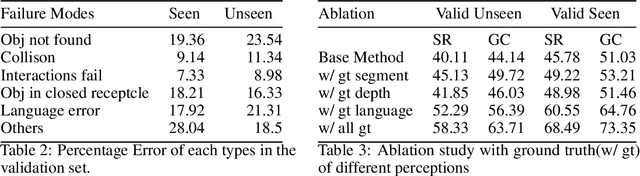
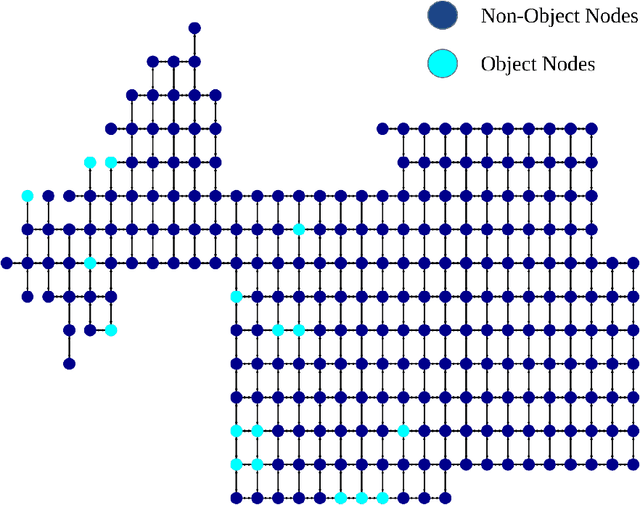
Embodied agents face significant challenges when tasked with performing actions in diverse environments, particularly in generalizing across object types and executing suitable actions to accomplish tasks. Furthermore, agents should exhibit robustness, minimizing the execution of illegal actions. In this work, we present Egocentric Planning, an innovative approach that combines symbolic planning and Object-oriented POMDPs to solve tasks in complex environments, harnessing existing models for visual perception and natural language processing. We evaluated our approach in ALFRED, a simulated environment designed for domestic tasks, and demonstrated its high scalability, achieving an impressive 36.07% unseen success rate in the ALFRED benchmark and winning the ALFRED challenge at CVPR Embodied AI workshop. Our method requires reliable perception and the specification or learning of a symbolic description of the preconditions and effects of the agent's actions, as well as what object types reveal information about others. It is capable of naturally scaling to solve new tasks beyond ALFRED, as long as they can be solved using the available skills. This work offers a solid baseline for studying end-to-end and hybrid methods that aim to generalize to new tasks, including recent approaches relying on LLMs, but often struggle to scale to long sequences of actions or produce robust plans for novel tasks.