 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diagnosis and Prognosis of Head and Neck Cancer Patients using Artificial Intelligence
May 31, 2023
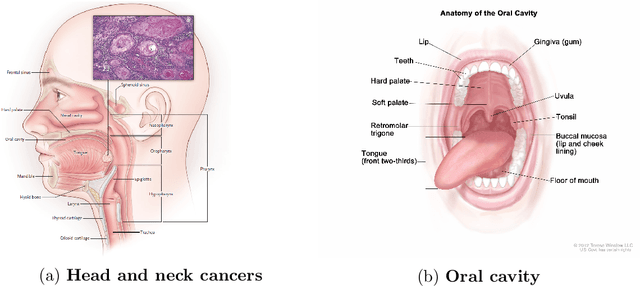
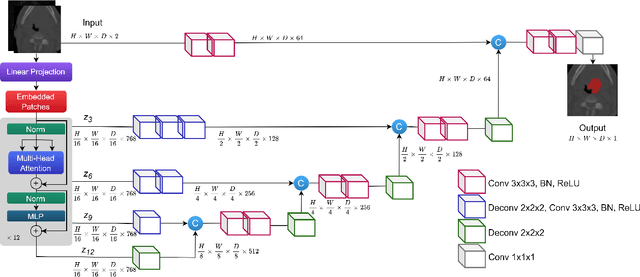

Cancer is one of the most life-threatening diseases worldwide, and head and neck (H&N) cancer is a prevalent type with hundreds of thousands of new cases recorded each year. Clinicians use medical imaging modalities such as computed tomography and positron emission tomography to detect the presence of a tumor, and they combine that information with clinical data for patient prognosis. The process is mostly challenging and time-consuming. Machine learning and deep learning can automate these tasks to help clinicians with highly promising results. This work studies two approaches for H&N tumor segmentation: (i) exploration and comparison of vision transformer (ViT)-based and convolutional neural network-based models; and (ii) proposal of a novel 2D perspective to working with 3D data. Furthermore, this work proposes two new architectures for the prognosis task. An ensemble of several models predicts patient outcomes (which won the HECKTOR 2021 challenge prognosis task), and a ViT-based framework concurrently performs patient outcome prediction and tumor segmentation, which outperforms the ensemble model.
A Hybrid Semantic-Geometric Approach for Clutter-Resistant Floorplan Generation from Building Point Clouds
May 15, 2023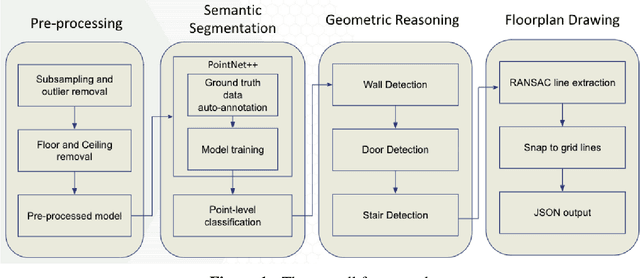
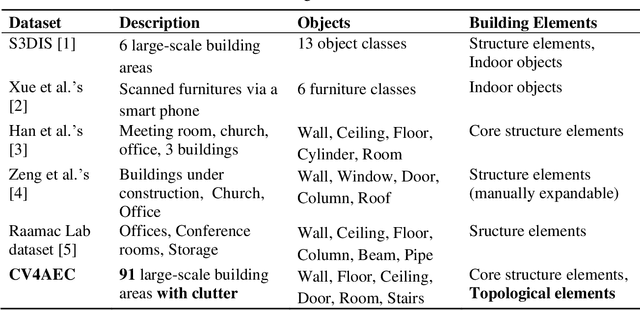
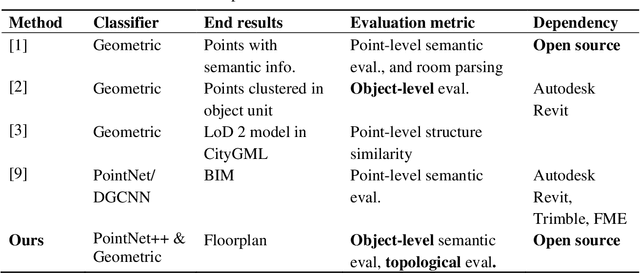

Building Information Modeling (BIM) technology is a key component of modern construction engineering and project management workflows. As-is BIM models that represent the spatial reality of a project site can offer crucial information to stakeholders for construction progress monitoring, error checking, and building maintenance purposes. Geometric methods for automatically converting raw scan data into BIM models (Scan-to-BIM) often fail to make use of higher-level semantic information in the data. Whereas, semantic segmentation methods only output labels at the point level without creating object level models that is necessary for BIM. To address these issues, this research proposes a hybrid semantic-geometric approach for clutter-resistant floorplan generation from laser-scanned building point clouds. The input point clouds are first pre-processed by normalizing the coordinate system and removing outliers. Then, a semantic segmentation network based on PointNet++ is used to label each point as ceiling, floor, wall, door, stair, and clutter. The clutter points are removed whereas the wall, door, and stair points are used for 2D floorplan generation. A region-growing segmentation algorithm paired with geometric reasoning rules is applied to group the points together into individual building elements. Finally, a 2-fold Random Sample Consensus (RANSAC) algorithm is applied to parameterize the building elements into 2D lines which are used to create the output floorplan. The proposed method is evaluated using the metrics of precision, recall, Intersection-over-Union (IOU), Betti error, and warping error.
Continually Improving Extractive QA via Human Feedback
May 21, 2023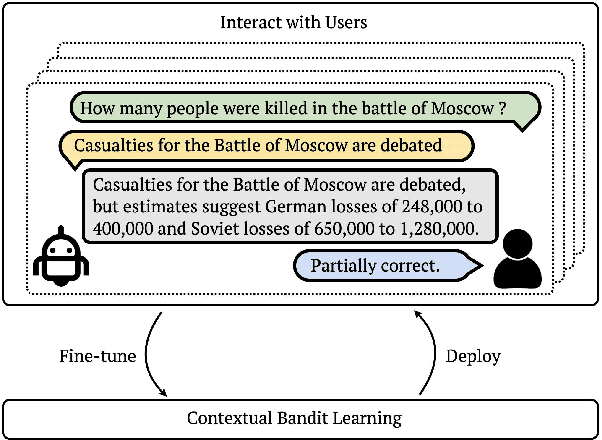

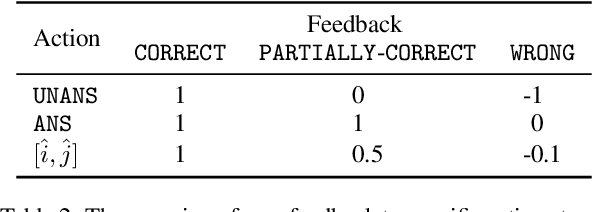
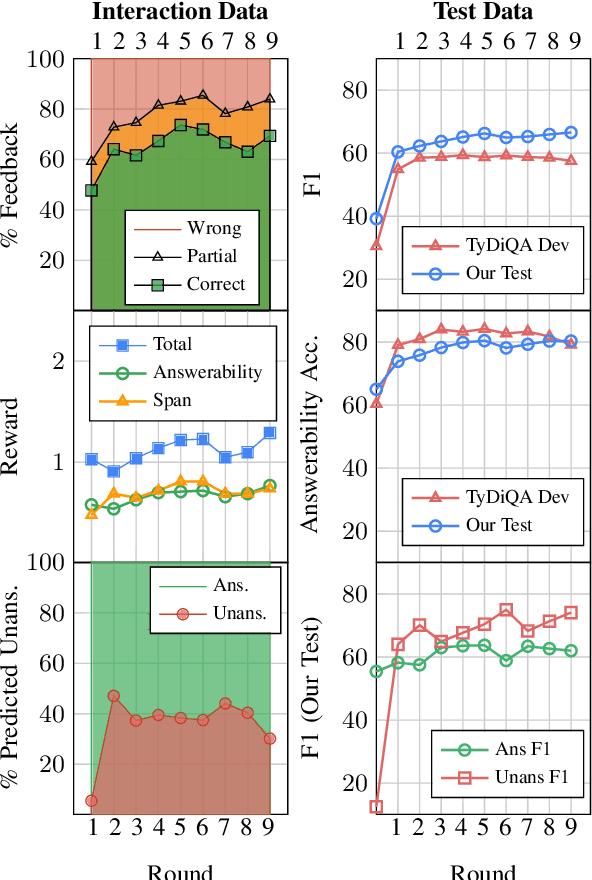
We study continually improving an extractive question answering (QA) system via human user feedback. We design and deploy an iterative approach, where information-seeking users ask questions, receive model-predicted answers, and provide feedback. We conduct experiments involving thousands of user interactions under diverse setups to broaden the understanding of learning from feedback over time. Our experiments show effective improvement from user feedback of extractive QA models over time across different data regimes, including significant potential for domain adaptation.
A Knowledge Graph Perspective on Supply Chain Resilience
May 15, 2023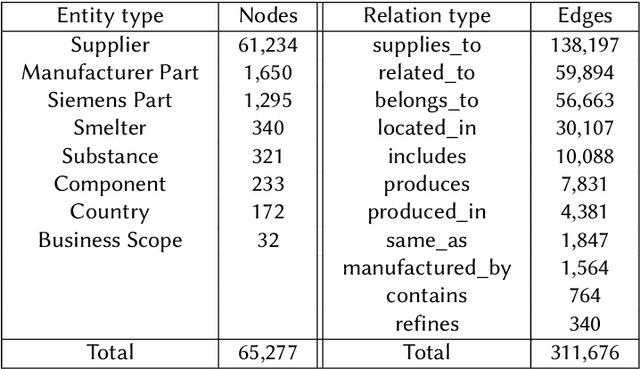
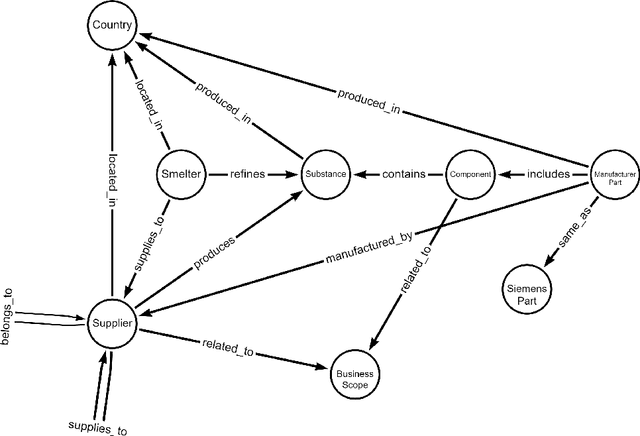
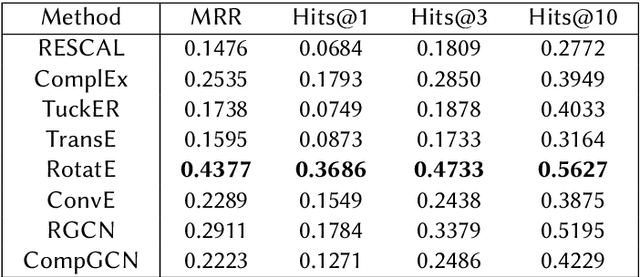
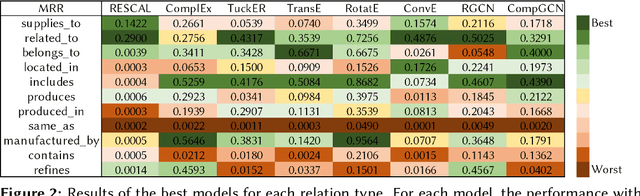
Global crises and regulatory developments require increased supply chain transparency and resilience. Companies do not only need to react to a dynamic environment but have to act proactively and implement measures to prevent production delays and reduce risks in the supply chains. However, information about supply chains, especially at the deeper levels, is often intransparent and incomplete, making it difficult to obtain precise predictions about prospective risks. By connecting different data sources, we model the supply network as a knowledge graph and achieve transparency up to tier-3 suppliers. To predict missing information in the graph, we apply state-of-the-art knowledge graph completion methods and attain a mean reciprocal rank of 0.4377 with the best model. Further, we apply graph analysis algorithms to identify critical entities in the supply network, supporting supply chain managers in automated risk identification.
Abstracting Imperfect Information Away from Two-Player Zero-Sum Games
Jan 22, 2023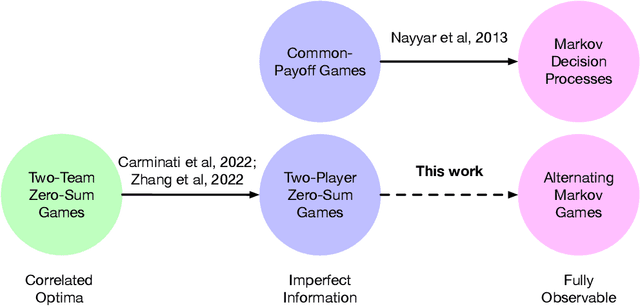
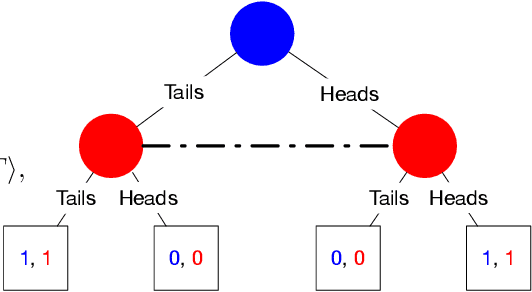
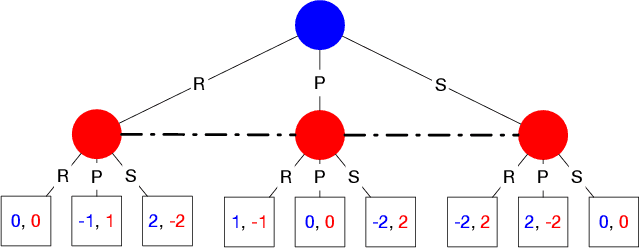
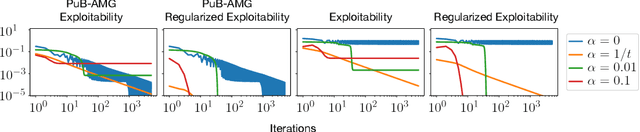
In their seminal work, Nayyar et al. (2013) showed that imperfect information can be abstracted away from common-payoff games by having players publicly announce their policies as they play. This insight underpins sound solvers and decision-time planning algorithms for common-payoff games. Unfortunately, a naive application of the same insight to two-player zero-sum games fails because Nash equilibria of the game with public policy announcements may not correspond to Nash equilibria of the original game. As a consequence, existing sound decision-time planning algorithms require complicated additional mechanisms that have unappealing properties. The main contribution of this work is showing that certain regularized equilibria do not possess the aforementioned non-correspondence problem -- thus, computing them can be treated as perfect information problems. Because these regularized equilibria can be made arbitrarily close to Nash equilibria, our result opens the door to a new perspective on solving two-player zero-sum games and, in particular, yields a simplified framework for decision-time planning in two-player zero-sum games, void of the unappealing properties that plague existing decision-time planning approaches.
Investigating Pre-trained Audio Encoders in the Low-Resource Condition
May 28, 2023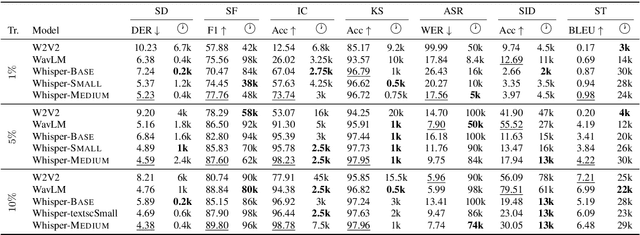

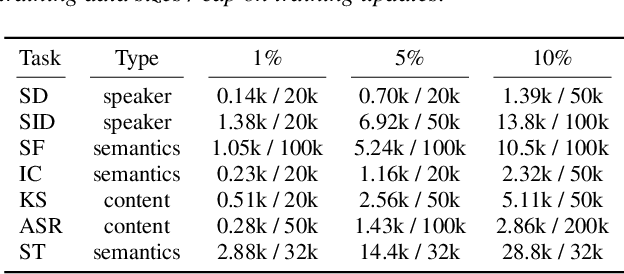
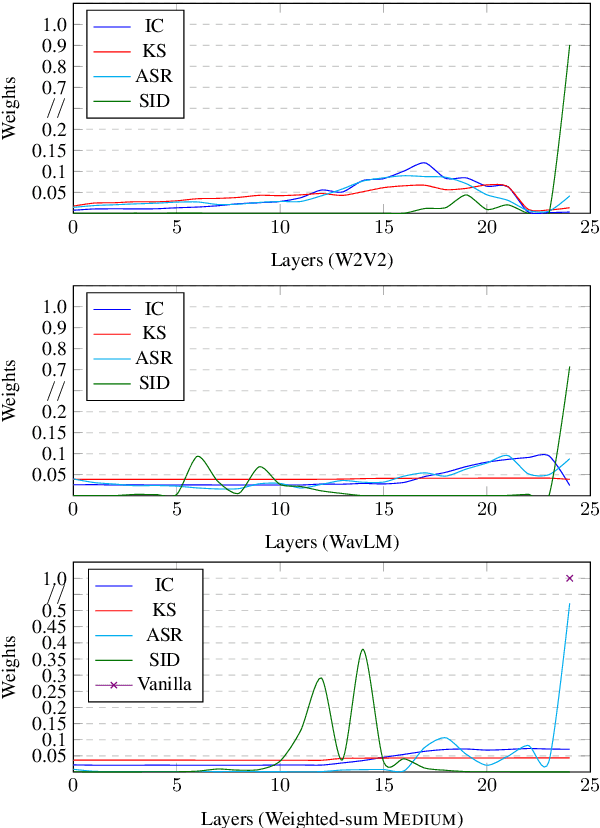
Pre-trained speech encoders have been central to pushing state-of-the-art results across various speech understanding and generation tasks. Nonetheless, the capabilities of these encoders in low-resource settings are yet to be thoroughly explored. To address this, we conduct a comprehensive set of experiments using a representative set of 3 state-of-the-art encoders (Wav2vec2, WavLM, Whisper) in the low-resource setting across 7 speech understanding and generation tasks. We provide various quantitative and qualitative analyses on task performance, convergence speed, and representational properties of the encoders. We observe a connection between the pre-training protocols of these encoders and the way in which they capture information in their internal layers. In particular, we observe the Whisper encoder exhibits the greatest low-resource capabilities on content-driven tasks in terms of performance and convergence speed.
Schema-adaptable Knowledge Graph Construction
May 19, 2023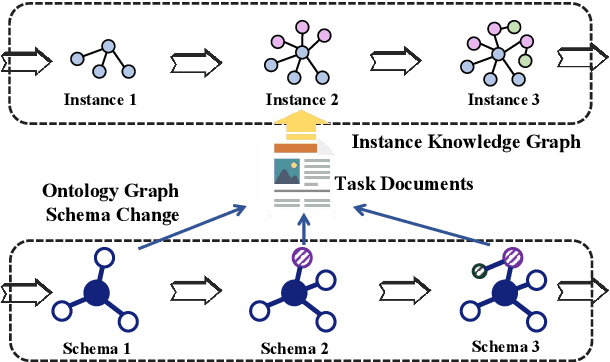
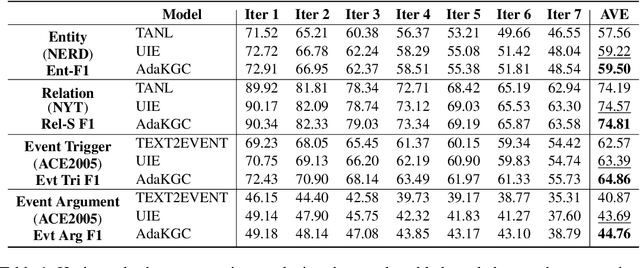
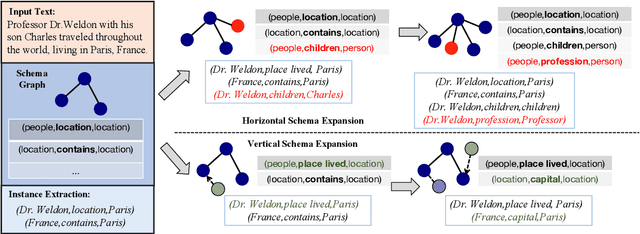
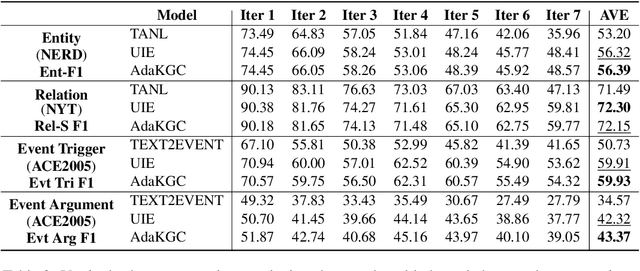
Conventional Knowledge Graph Construction (KGC) approaches typically follow the static information extraction paradigm with a closed set of pre-defined schema. As a result, such approaches fall short when applied to dynamic scenarios or domains, whereas a new type of knowledge emerges. This necessitates a system that can handle evolving schema automatically to extract information for KGC. To address this need, we propose a new task called schema-adaptable KGC, which aims to continually extract entity, relation, and event based on a dynamically changing schema graph without re-training. We first split and convert existing datasets based on three principles to build a benchmark, i.e., horizontal schema expansion, vertical schema expansion, and hybrid schema expansion; then investigate the schema-adaptable performance of several well-known approaches such as Text2Event, TANL, UIE and GPT-3.5. We further propose a simple yet effective baseline dubbed AdaKGC, which contains schema-enriched prefix instructor and schema-conditioned dynamic decoding to better handle evolving schema. Comprehensive experimental results illustrate that AdaKGC can outperform baselines but still have room for improvement. We hope the proposed work can deliver benefits to the community. Code and datasets will be available in https://github.com/zjunlp/AdaKGC.
Towards Accurate Image Coding: Improved Autoregressive Image Generation with Dynamic Vector Quantization
May 19, 2023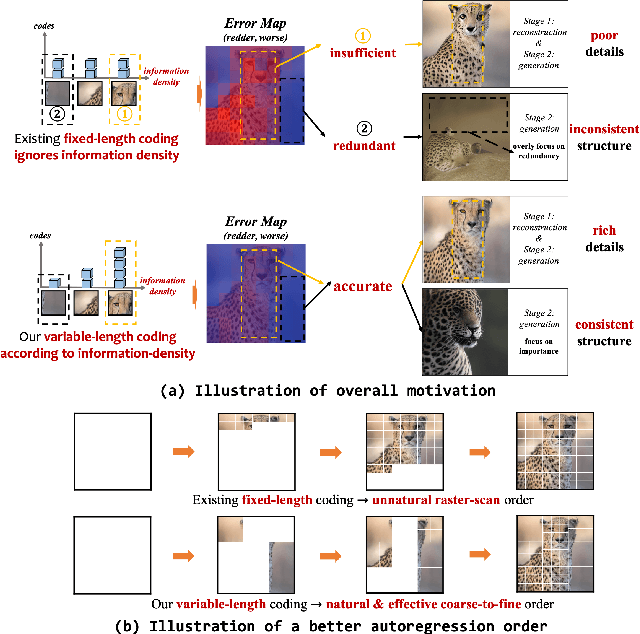

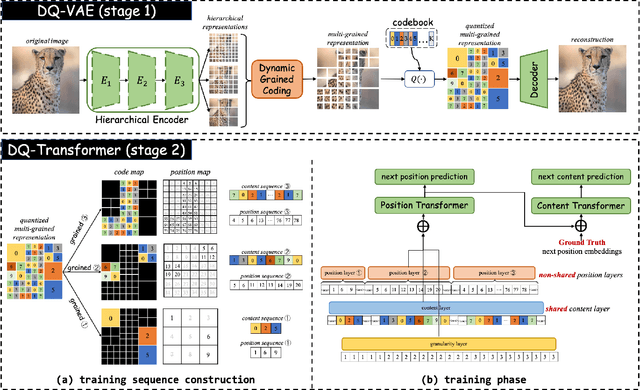
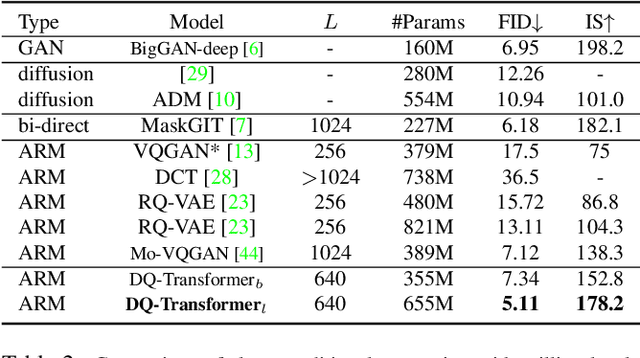
Existing vector quantization (VQ) based autoregressive models follow a two-stage generation paradigm that first learns a codebook to encode images as discrete codes, and then completes generation based on the learned codebook. However, they encode fixed-size image regions into fixed-length codes and ignore their naturally different information densities, which results in insufficiency in important regions and redundancy in unimportant ones, and finally degrades the generation quality and speed. Moreover, the fixed-length coding leads to an unnatural raster-scan autoregressive generation. To address the problem, we propose a novel two-stage framework: (1) Dynamic-Quantization VAE (DQ-VAE) which encodes image regions into variable-length codes based on their information densities for an accurate and compact code representation. (2) DQ-Transformer which thereby generates images autoregressively from coarse-grained (smooth regions with fewer codes) to fine-grained (details regions with more codes) by modeling the position and content of codes in each granularity alternately, through a novel stacked-transformer architecture and shared-content, non-shared position input layers designs. Comprehensive experiments on various generation tasks validate our superiorities in both effectiveness and efficiency. Code will be released at https://github.com/CrossmodalGroup/DynamicVectorQuantization.
Taxonomy Completion with Probabilistic Scorer via Box Embedding
May 19, 2023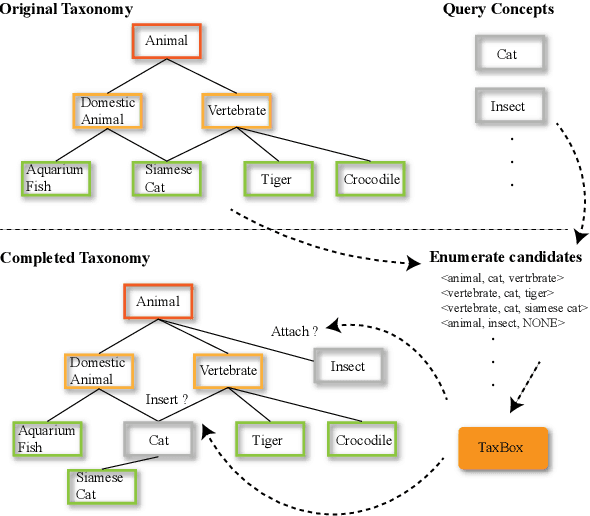
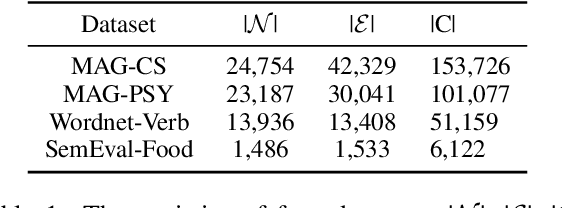
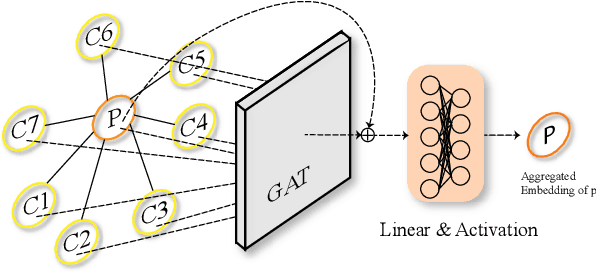

Taxonomy completion, a task aimed at automatically enriching an existing taxonomy with new concepts, has gained significant interest in recent years. Previous works have introduced complex modules, external information, and pseudo-leaves to enrich the representation and unify the matching process of attachment and insertion. While they have achieved good performance, these introductions may have brought noise and unfairness during training and scoring. In this paper, we present TaxBox, a novel framework for taxonomy completion that maps taxonomy concepts to box embeddings and employs two probabilistic scorers for concept attachment and insertion, avoiding the need for pseudo-leaves. Specifically, TaxBox consists of three components: (1) a graph aggregation module to leverage the structural information of the taxonomy and two lightweight decoders that map features to box embedding and capture complex relationships between concepts; (2) two probabilistic scorers that correspond to attachment and insertion operations and ensure the avoidance of pseudo-leaves; and (3) three learning objectives that assist the model in mapping concepts more granularly onto the box embedding space. Experimental results on four real-world datasets suggest that TaxBox outperforms baseline methods by a considerable margin and surpasses previous state-of-art methods to a certain extent.
A Multi-Modal Context Reasoning Approach for Conditional Inference on Joint Textual and Visual Clues
May 08, 2023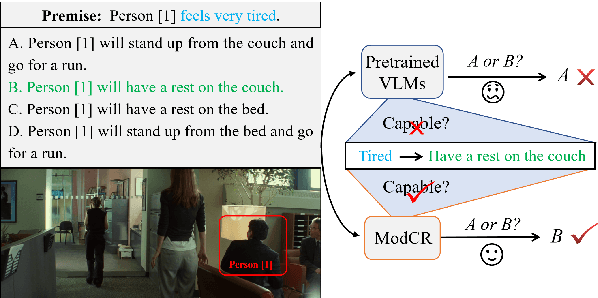
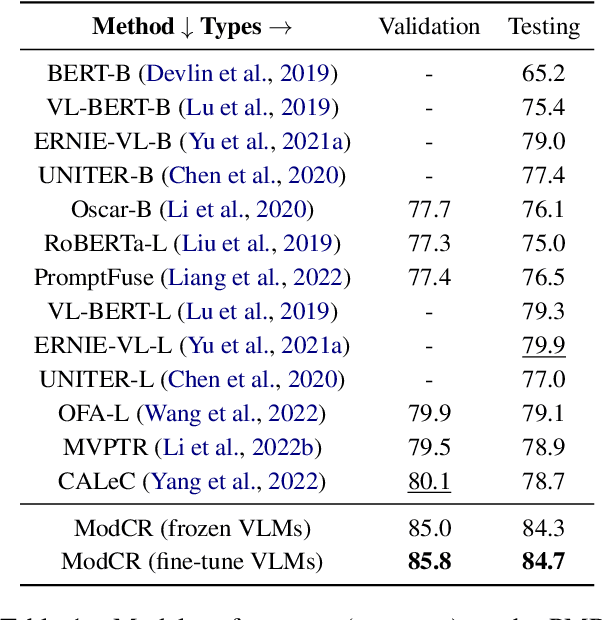
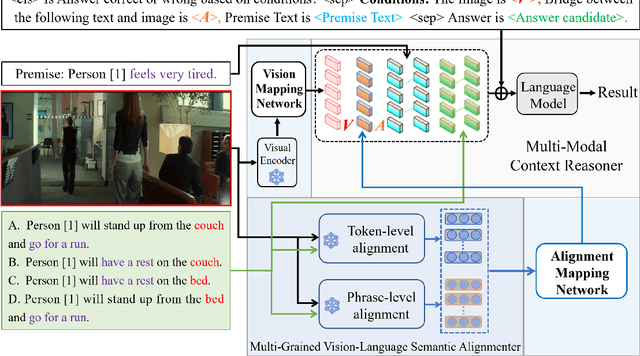
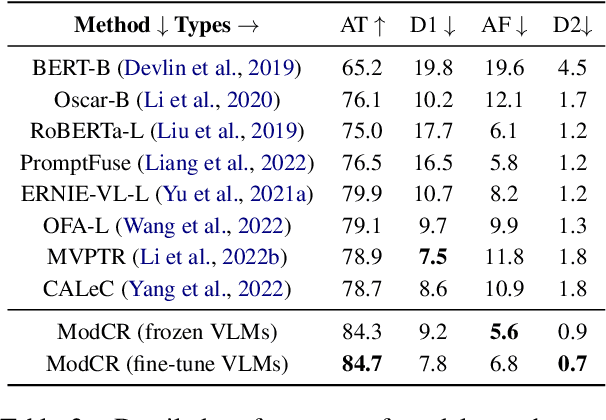
Conditional inference on joint textual and visual clues is a multi-modal reasoning task that textual clues provide prior permutation or external knowledge, which are complementary with visual content and pivotal to deducing the correct option. Previous methods utilizing pretrained vision-language models (VLMs) have achieved impressive performances, yet they show a lack of multimodal context reasoning capability, especially for text-modal information. To address this issue, we propose a Multi-modal Context Reasoning approach, named ModCR. Compared to VLMs performing reasoning via cross modal semantic alignment, it regards the given textual abstract semantic and objective image information as the pre-context information and embeds them into the language model to perform context reasoning. Different from recent vision-aided language models used in natural language processing, ModCR incorporates the multi-view semantic alignment information between language and vision by introducing the learnable alignment prefix between image and text in the pretrained language model. This makes the language model well-suitable for such multi-modal reasoning scenario on joint textual and visual clues. We conduct extensive experiments on two corresponding data sets and experimental results show significantly improved performance (exact gain by 4.8% on PMR test set) compared to previous strong baselines. Code Link: \url{https://github.com/YunxinLi/Multimodal-Context-Reasoning}.