 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CO3: Low-resource Contrastive Co-training for Generative Conversational Query Rewrite
Mar 18, 2024

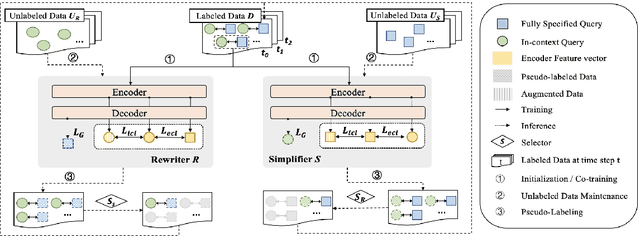

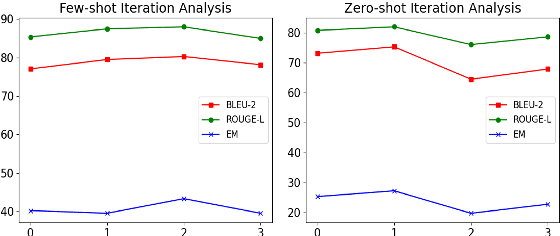
Generative query rewrite generates reconstructed query rewrites using the conversation history while rely heavily on gold rewrite pairs that are expensive to obtain. Recently, few-shot learning is gaining increasing popularity for this task, whereas these methods are sensitive to the inherent noise due to limited data size. Besides, both attempts face performance degradation when there exists language style shift between training and testing cases. To this end, we study low-resource generative conversational query rewrite that is robust to both noise and language style shift. The core idea is to utilize massive unlabeled data to make further improvements via a contrastive co-training paradigm. Specifically, we co-train two dual models (namely Rewriter and Simplifier) such that each of them provides extra guidance through pseudo-labeling for enhancing the other in an iterative manner. We also leverage contrastive learning with data augmentation, which enables our model pay more attention on the truly valuable information than the noise. Extensive experiments demonstrate the superiority of our model under both few-shot and zero-shot scenarios. We also verify the better generalization ability of our model when encountering language style shift.
VideoAgent: Long-form Video Understanding with Large Language Model as Agent
Mar 15, 2024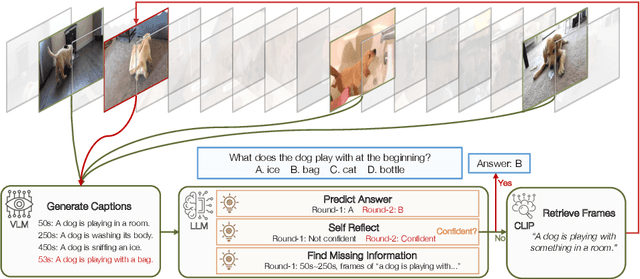
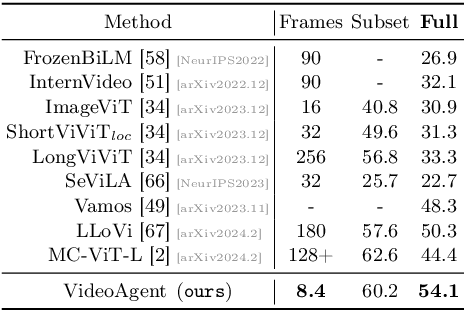

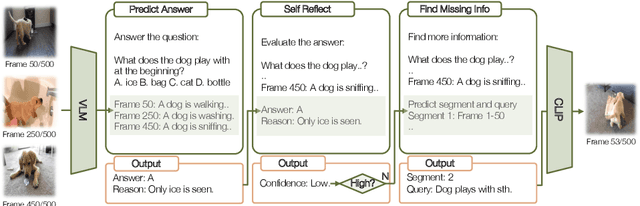
Long-form video understanding represents a significant challenge within computer vision, demanding a model capable of reasoning over long multi-modal sequences. Motivated by the human cognitive process for long-form video understanding, we emphasize interactive reasoning and planning over the ability to process lengthy visual inputs. We introduce a novel agent-based system, VideoAgent, that employs a large language model as a central agent to iteratively identify and compile crucial information to answer a question, with vision-language foundation models serving as tools to translate and retrieve visual information. Evaluated on the challenging EgoSchema and NExT-QA benchmarks, VideoAgent achieves 54.1% and 71.3% zero-shot accuracy with only 8.4 and 8.2 frames used on average. These results demonstrate superior effectiveness and efficiency of our method over the current state-of-the-art methods, highlighting the potential of agent-based approaches in advancing long-form video understanding.
Bidirectional Multi-Step Domain Generalization for Visible-Infrared Person Re-Identification
Mar 16, 2024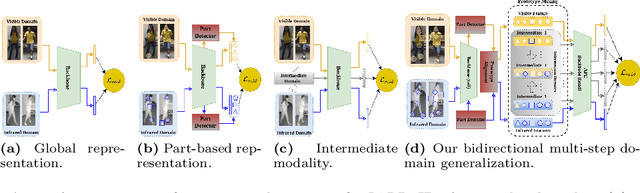
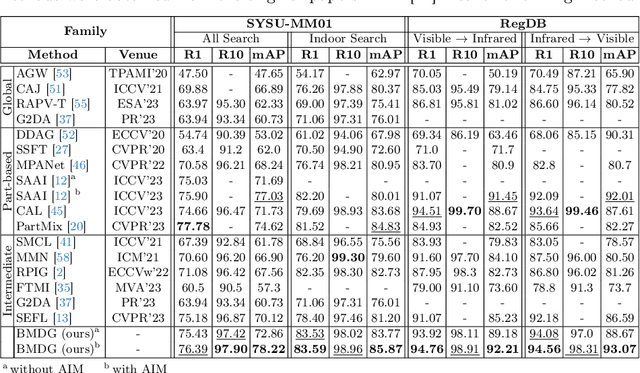
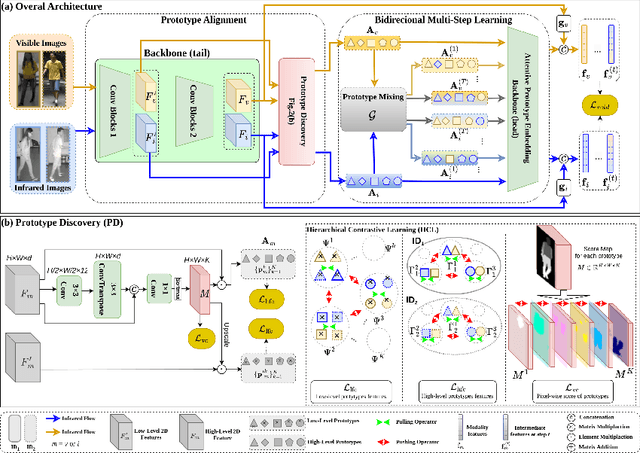
A key challenge in visible-infrared person re-identification (V-I ReID) is training a backbone model capable of effectively addressing the significant discrepancies across modalities. State-of-the-art methods that generate a single intermediate bridging domain are often less effective, as this generated domain may not adequately capture sufficient common discriminant information. This paper introduces the Bidirectional Multi-step Domain Generalization (BMDG), a novel approach for unifying feature representations across diverse modalities. BMDG creates multiple virtual intermediate domains by finding and aligning body part features extracted from both I and V modalities. Indeed, BMDG aims to reduce the modality gaps in two steps. First, it aligns modalities in feature space by learning shared and modality-invariant body part prototypes from V and I images. Then, it generalizes the feature representation by applying bidirectional multi-step learning, which progressively refines feature representations in each step and incorporates more prototypes from both modalities. In particular, our method minimizes the cross-modal gap by identifying and aligning shared prototypes that capture key discriminative features across modalities, then uses multiple bridging steps based on this information to enhance the feature representation. Experiments conducted on challenging V-I ReID datasets indicate that our BMDG approach outperforms state-of-the-art part-based models or methods that generate an intermediate domain from V-I person ReID.
Rethinking Mutual Information for Language Conditioned Skill Discovery on Imitation Learning
Feb 27, 2024Language-conditioned robot behavior plays a vital role in executing complex tasks by associating human commands or instructions with perception and actions. The ability to compose long-horizon tasks based on unconstrained language instructions necessitates the acquisition of a diverse set of general-purpose skills. However, acquiring inherent primitive skills in a coupled and long-horizon environment without external rewards or human supervision presents significant challenges. In this paper, we evaluate the relationship between skills and language instructions from a mathematical perspective, employing two forms of mutual information within the framework of language-conditioned policy learning. To maximize the mutual information between language and skills in an unsupervised manner, we propose an end-to-end imitation learning approach known as Language Conditioned Skill Discovery (LCSD). Specifically, we utilize vector quantization to learn discrete latent skills and leverage skill sequences of trajectories to reconstruct high-level semantic instructions. Through extensive experiments on language-conditioned robotic navigation and manipulation tasks, encompassing BabyAI, LORel, and CALVIN, we demonstrate the superiority of our method over prior works. Our approach exhibits enhanced generalization capabilities towards unseen tasks, improved skill interpretability, and notably higher rates of task completion success.
Few-Shot Class Incremental Learning with Attention-Aware Self-Adaptive Prompt
Mar 14, 2024
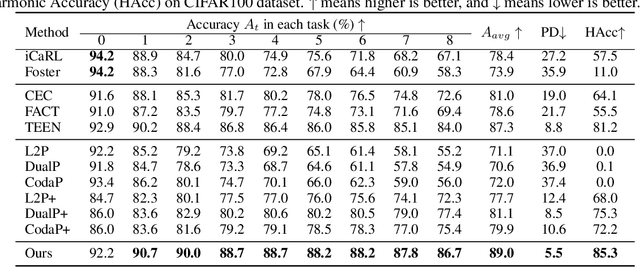
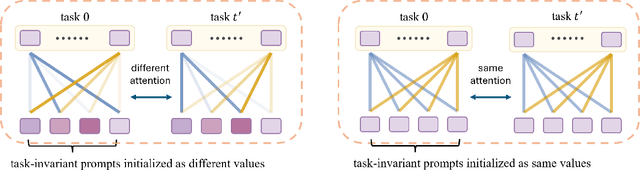
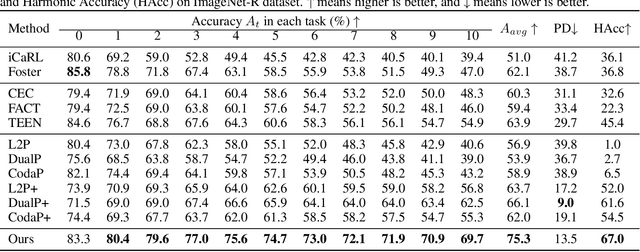
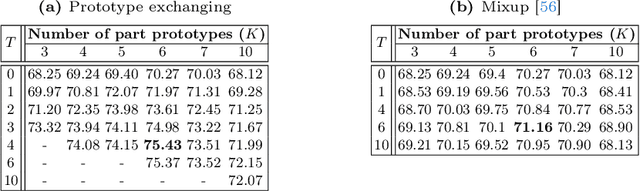
Few-Shot Class-Incremental Learning (FSCIL) models aim to incrementally learn new classes with scarce samples while preserving knowledge of old ones. Existing FSCIL methods usually fine-tune the entire backbone, leading to overfitting and hindering the potential to learn new classes. On the other hand, recent prompt-based CIL approaches alleviate forgetting by training prompts with sufficient data in each task. In this work, we propose a novel framework named Attention-aware Self-adaptive Prompt (ASP). ASP encourages task-invariant prompts to capture shared knowledge by reducing specific information from the attention aspect. Additionally, self-adaptive task-specific prompts in ASP provide specific information and transfer knowledge from old classes to new classes with an Information Bottleneck learning objective. In summary, ASP prevents overfitting on base task and does not require enormous data in few-shot incremental tasks. Extensive experiments on three benchmark datasets validate that ASP consistently outperforms state-of-the-art FSCIL and prompt-based CIL methods in terms of both learning new classes and mitigating forgetting.
GazeMotion: Gaze-guided Human Motion Forecasting
Mar 14, 2024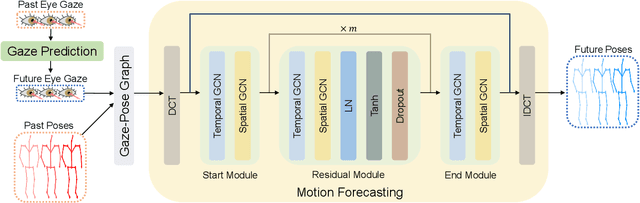
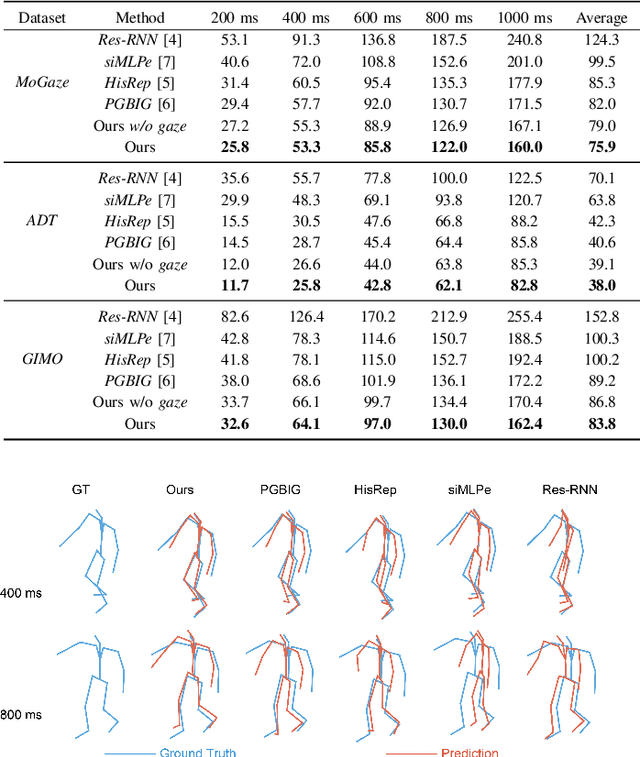
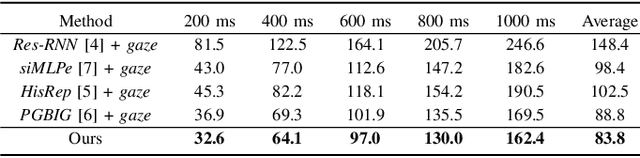
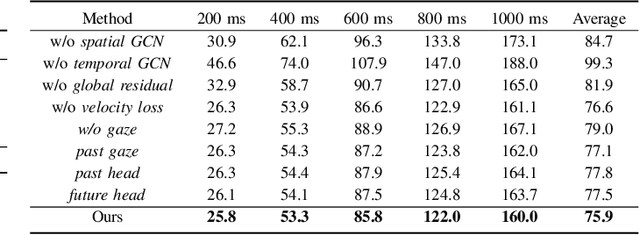
We present GazeMotion, a novel method for human motion forecasting that combines information on past human poses with human eye gaze. Inspired by evidence from behavioural sciences showing that human eye and body movements are closely coordinated, GazeMotion first predicts future eye gaze from past gaze, then fuses predicted future gaze and past poses into a gaze-pose graph, and finally uses a residual graph convolutional network to forecast body motion. We extensively evaluate our method on the MoGaze, ADT, and GIMO benchmark datasets and show that it outperforms state-of-the-art methods by up to 7.4% improvement in mean per joint position error. Using head direction as a proxy to gaze, our method still achieves an average improvement of 5.5%. We finally report an online user study showing that our method also outperforms prior methods in terms of perceived realism. These results show the significant information content available in eye gaze for human motion forecasting as well as the effectiveness of our method in exploiting this information.
A Categorization of Complexity Classes for Information Retrieval and Synthesis Using Natural Logic
Feb 28, 2024Given the emergent reasoning abilities of large language models, information retrieval is becoming more complex. Rather than just retrieve a document, modern information retrieval systems advertise that they can synthesize an answer based on potentially many different documents, conflicting data sources, and using reasoning. But, different kinds of questions have different answers, and different answers have different complexities. In this paper, we introduce a novel framework for analyzing the complexity of a question answer based on the natural deduction calculus as presented in Prawitz (1965). Our framework is novel both in that no one to our knowledge has used this logic as a basis for complexity classes, and also in that no other existing complexity classes to these have been delineated using any analogous methods either. We identify three decidable fragments in particular called the forward, query and planning fragments, and we compare this to what would be needed to do proofs for the complete first-order calculus, for which theorem-proving is long known to be undecidable.
EffiPerception: an Efficient Framework for Various Perception Tasks
Mar 18, 2024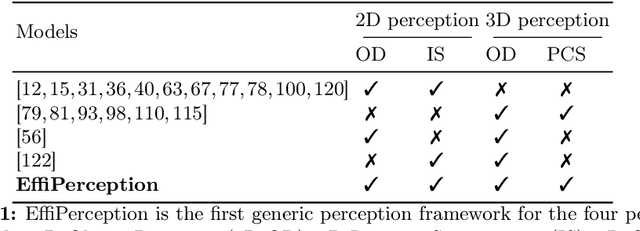
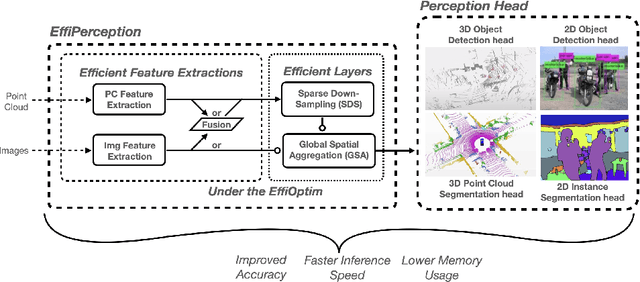
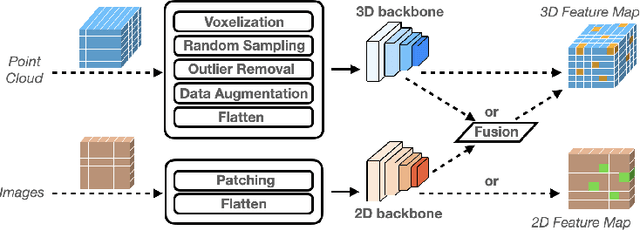
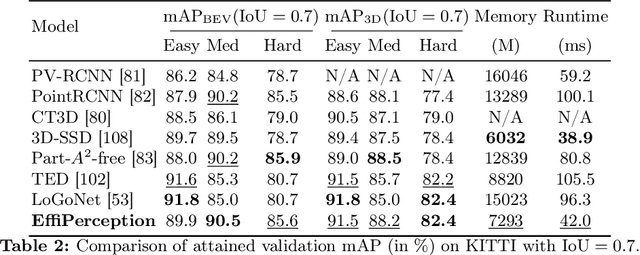
The accuracy-speed-memory trade-off is always the priority to consider for several computer vision perception tasks. Previous methods mainly focus on a single or small couple of these tasks, such as creating effective data augmentation, feature extractor, learning strategies, etc. These approaches, however, could be inherently task-specific: their proposed model's performance may depend on a specific perception task or a dataset. Targeting to explore common learning patterns and increasing the module robustness, we propose the EffiPerception framework. It could achieve great accuracy-speed performance with relatively low memory cost under several perception tasks: 2D Object Detection, 3D Object Detection, 2D Instance Segmentation, and 3D Point Cloud Segmentation. Overall, the framework consists of three parts: (1) Efficient Feature Extractors, which extract the input features for each modality. (2) Efficient Layers, plug-in plug-out layers that further process the feature representation, aggregating core learned information while pruning noisy proposals. (3) The EffiOptim, an 8-bit optimizer to further cut down the computational cost and facilitate performance stability. Extensive experiments on the KITTI, semantic-KITTI, and COCO datasets revealed that EffiPerception could show great accuracy-speed-memory overall performance increase within the four detection and segmentation tasks, in comparison to earlier, well-respected methods.
Learning Useful Representations of Recurrent Neural Network Weight Matrices
Mar 18, 2024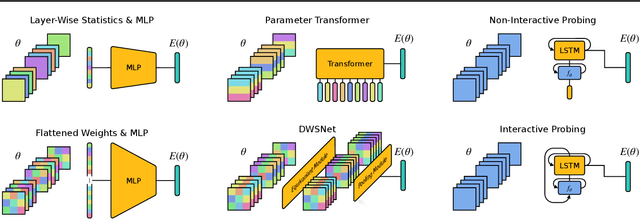

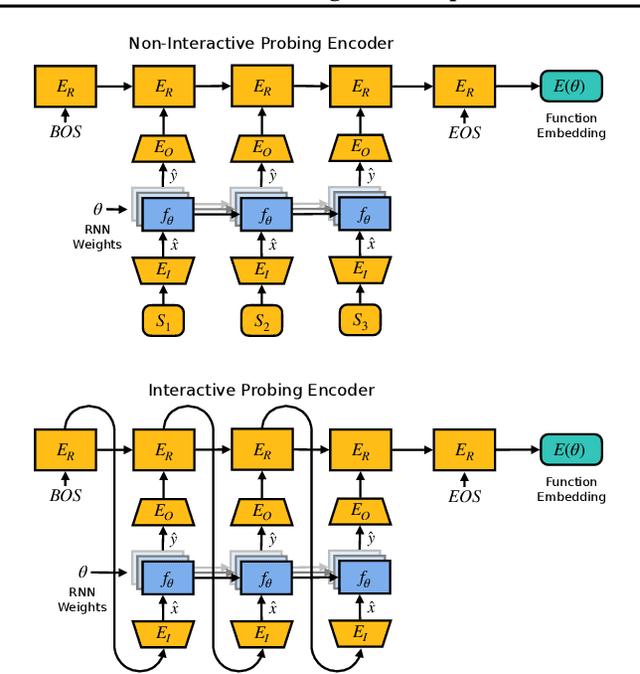
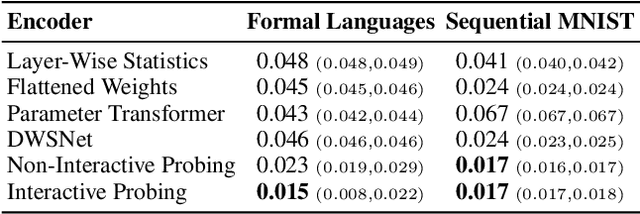
Recurrent Neural Networks (RNNs) are general-purpose parallel-sequential computers. The program of an RNN is its weight matrix. How to learn useful representations of RNN weights that facilitate RNN analysis as well as downstream tasks? While the mechanistic approach directly looks at some RNN's weights to predict its behavior, the functionalist approach analyzes its overall functionality -- specifically, its input-output mapping. We consider several mechanistic approaches for RNN weights and adapt the permutation equivariant Deep Weight Space layer for RNNs. Our two novel functionalist approaches extract information from RNN weights by 'interrogating' the RNN through probing inputs. We develop a theoretical framework that demonstrates conditions under which the functionalist approach can generate rich representations that help determine RNN behavior. We create and release the first two 'model zoo' datasets for RNN weight representation learning. One consists of generative models of a class of formal languages, and the other one of classifiers of sequentially processed MNIST digits. With the help of an emulation-based self-supervised learning technique we compare and evaluate the different RNN weight encoding techniques on multiple downstream applications. On the most challenging one, namely predicting which exact task the RNN was trained on, functionalist approaches show clear superiority.
Using Generative Text Models to Create Qualitative Codebooks for Student Evaluations of Teaching
Mar 18, 2024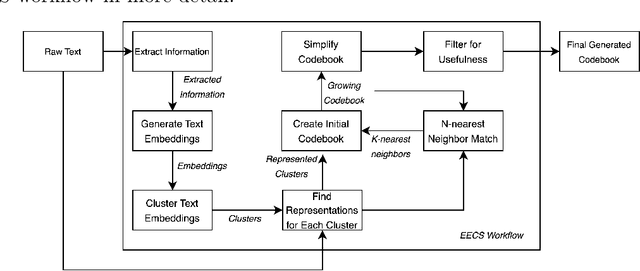

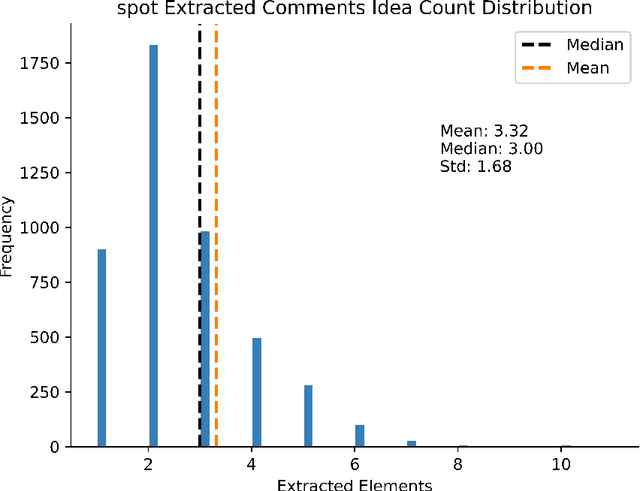

Feedback is a critical aspect of improvement. Unfortunately, when there is a lot of feedback from multiple sources, it can be difficult to distill the information into actionable insights. Consider student evaluations of teaching (SETs), which are important sources of feedback for educators. They can give instructors insights into what worked during a semester. A collection of SETs can also be useful to administrators as signals for courses or entire programs. However, on a large scale as in high-enrollment courses or administrative records over several years, the volume of SETs can render them difficult to analyze. In this paper, we discuss a novel method for analyzing SETs using natural language processing (NLP) and large language models (LLMs). We demonstrate the method by applying it to a corpus of 5,000 SETs from a large public university. We show that the method can be used to extract, embed, cluster, and summarize the SETs to identify the themes they express. More generally, this work illustrates how to use the combination of NLP techniques and LLMs to generate a codebook for SETs. We conclude by discussing the implications of this method for analyzing SETs and other types of student writing in teaching and research settings.