 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FedPDD: A Privacy-preserving Double Distillation Framework for Cross-silo Federated Recommendation
May 09, 2023
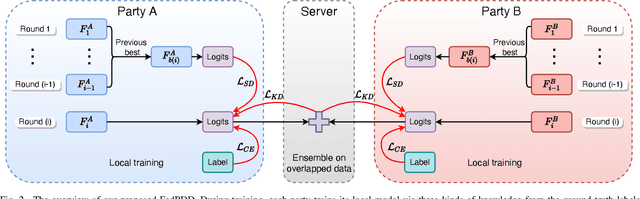
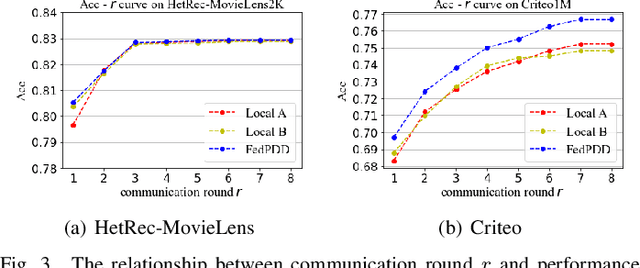
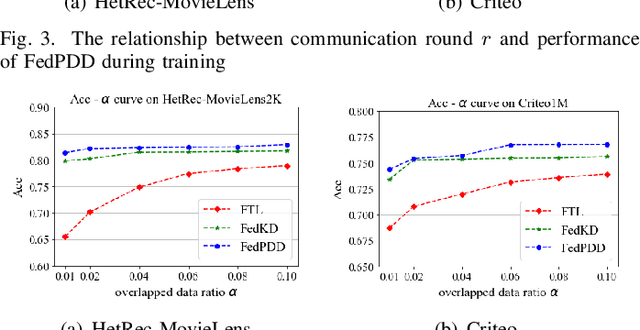
Cross-platform recommendation aims to improve recommendation accuracy by gathering heterogeneous features from different platforms. However, such cross-silo collaborations between platforms are restricted by increasingly stringent privacy protection regulations, thus data cannot be aggregated for training. Federated learning (FL) is a practical solution to deal with the data silo problem in recommendation scenarios. Existing cross-silo FL methods transmit model information to collaboratively build a global model by leveraging the data of overlapped users. However, in reality, the number of overlapped users is often very small, thus largely limiting the performance of such approaches. Moreover, transmitting model information during training requires high communication costs and may cause serious privacy leakage. In this paper, we propose a novel privacy-preserving double distillation framework named FedPDD for cross-silo federated recommendation, which efficiently transfers knowledge when overlapped users are limited. Specifically, our double distillation strategy enables local models to learn not only explicit knowledge from the other party but also implicit knowledge from its past predictions. Moreover, to ensure privacy and high efficiency, we employ an offline training scheme to reduce communication needs and privacy leakage risk. In addition, we adopt differential privacy to further protect the transmitted information. The experiments on two real-world recommendation datasets, HetRec-MovieLens and Criteo, demonstrate the effectiveness of FedPDD compared to the state-of-the-art approaches.
Domain Agnostic Image-to-image Translation using Low-Resolution Conditioning
May 11, 2023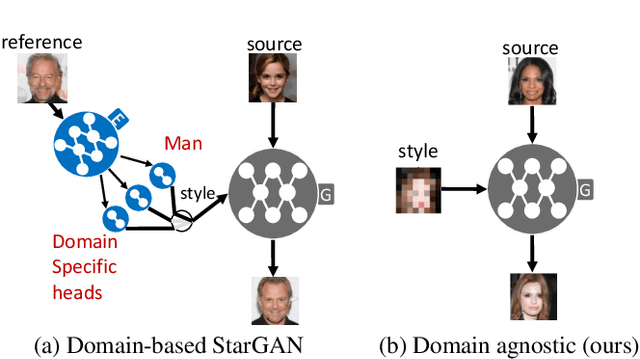
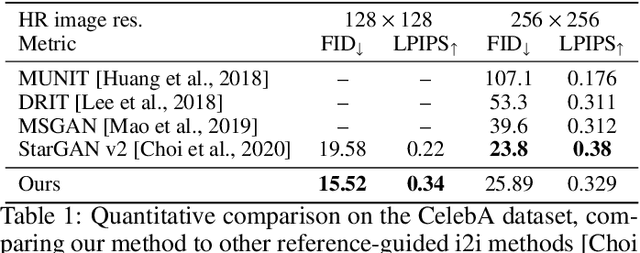
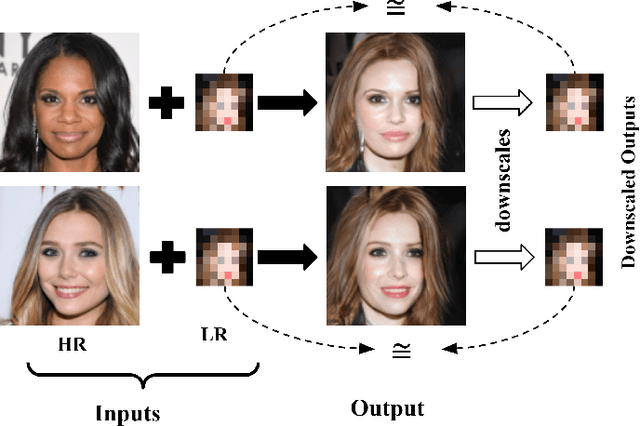
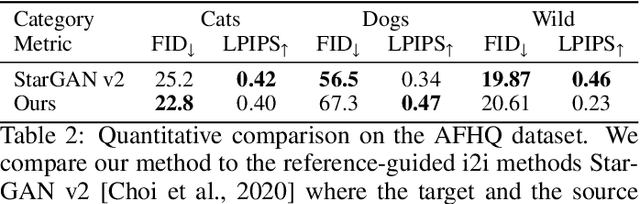
Generally, image-to-image translation (i2i) methods aim at learning mappings across domains with the assumption that the images used for translation share content (e.g., pose) but have their own domain-specific information (a.k.a. style). Conditioned on a target image, such methods extract the target style and combine it with the source image content, keeping coherence between the domains. In our proposal, we depart from this traditional view and instead consider the scenario where the target domain is represented by a very low-resolution (LR) image, proposing a domain-agnostic i2i method for fine-grained problems, where the domains are related. More specifically, our domain-agnostic approach aims at generating an image that combines visual features from the source image with low-frequency information (e.g. pose, color) of the LR target image. To do so, we present a novel approach that relies on training the generative model to produce images that both share distinctive information of the associated source image and correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates realistic samples compared to state-of-the-art methods such as StarGAN v2. Ablation studies also reveal that our method is robust to changes in color, it can be applied to out-of-distribution images, and it allows for manual control over the final results.
Autonomous GIS: the next-generation AI-powered GIS
May 10, 2023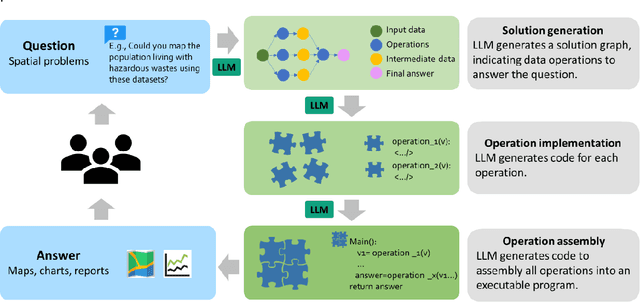
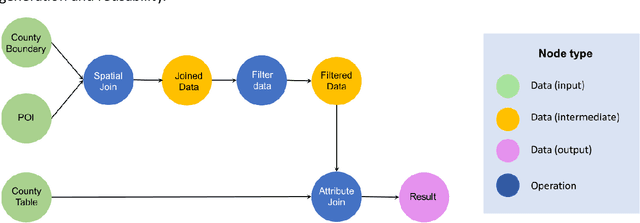


Large Language Models (LLMs), such as ChatGPT, demonstrate a strong understanding of human natural language and have been explored and applied in various fields, including reasoning, creative writing, code generation, translation, and information retrieval. By adopting LLM as the reasoning core, we propose Autonomous GIS, an AI-powered geographic information system (GIS) that leverages the LLM's general abilities in natural language understanding, reasoning and coding for addressing spatial problems with automatic spatial data collection, analysis and visualization. We envision that autonomous GIS will need to achieve five autonomous goals including self-generating, self-organizing, self-verifying, self-executing, and self-growing. We introduce the design principles of autonomous GIS to achieve these five autonomous goals from the aspects of information sufficiency, LLM ability, and agent architecture. We developed a prototype system called LLM-Geo using GPT-4 API in a Python environment, demonstrating what an autonomous GIS looks like and how it delivers expected results without human intervention using two case studies. For both case studies, LLM-Geo successfully returned accurate results, including aggregated numbers, graphs, and maps, significantly reducing manual operation time. Although still lacking several important modules such as logging and code testing, LLM-Geo demonstrates a potential path towards next-generation AI-powered GIS. We advocate for the GIScience community to dedicate more effort to the research and development of autonomous GIS, making spatial analysis easier, faster, and more accessible to a broader audience.
Finding Meaningful Distributions of ML Black-boxes under Forensic Investigation
May 10, 2023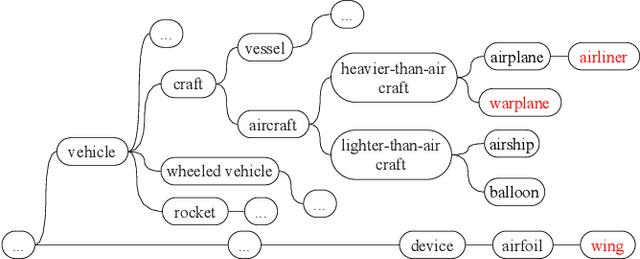
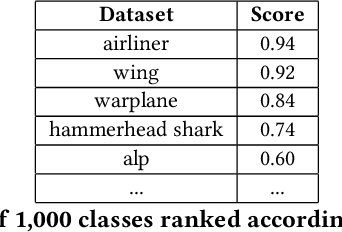
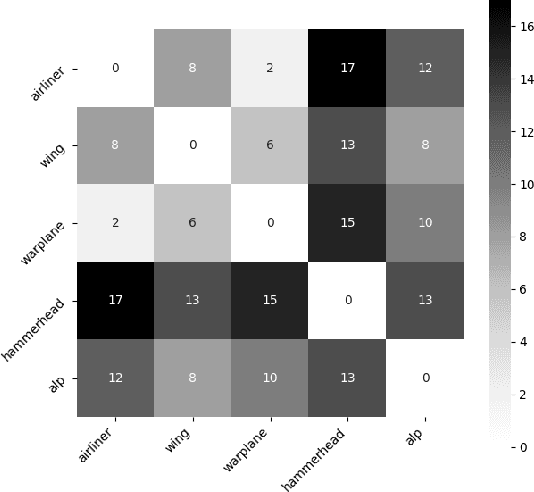
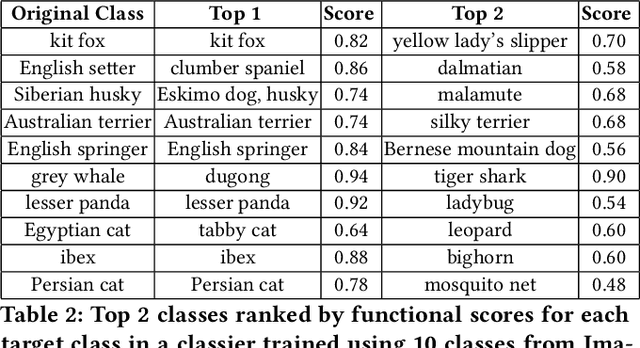
Given a poorly documented neural network model, we take the perspective of a forensic investigator who wants to find out the model's data domain (e.g. whether on face images or traffic signs). Although existing methods such as membership inference and model inversion can be used to uncover some information about an unknown model, they still require knowledge of the data domain to start with. In this paper, we propose solving this problem by leveraging on comprehensive corpus such as ImageNet to select a meaningful distribution that is close to the original training distribution and leads to high performance in follow-up investigations. The corpus comprises two components, a large dataset of samples and meta information such as hierarchical structure and textual information on the samples. Our goal is to select a set of samples from the corpus for the given model. The core of our method is an objective function that considers two criteria on the selected samples: the model functional properties (derived from the dataset), and semantics (derived from the metadata). We also give an algorithm to efficiently search the large space of all possible subsets w.r.t. the objective function. Experimentation results show that the proposed method is effective. For example, cloning a given model (originally trained with CIFAR-10) by using Caltech 101 can achieve 45.5% accuracy. By using datasets selected by our method, the accuracy is improved to 72.0%.
Novel deep learning methods for 3D flow field segmentation and classification
May 10, 2023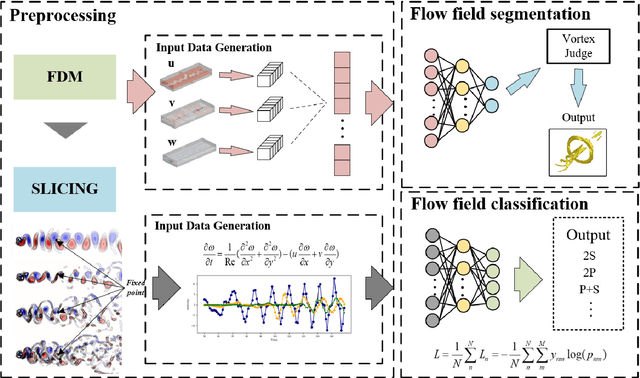
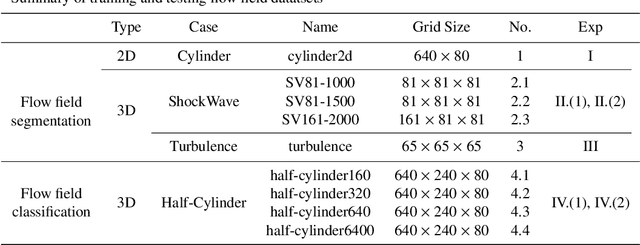
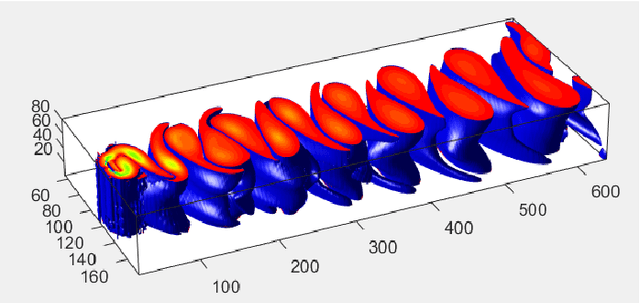
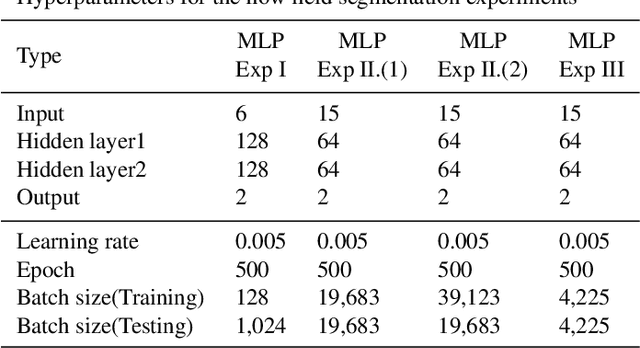
Flow field segmentation and classification help researchers to understand vortex structure and thus turbulent flow. Existing deep learning methods mainly based on global information and focused on 2D circumstance. Based on flow field theory, we propose novel flow field segmentation and classification deep learning methods in three-dimensional space. We construct segmentation criterion based on local velocity information and classification criterion based on the relationship between local vorticity and vortex wake, to identify vortex structure in 3D flow field, and further classify the type of vortex wakes accurately and rapidly. Simulation experiment results showed that, compared with existing methods, our segmentation method can identify the vortex area more accurately, while the time consumption is reduced more than 50\%; our classification method can reduce the time consumption by more than 90\% while maintaining the same classification accuracy level.
DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models
May 24, 2023

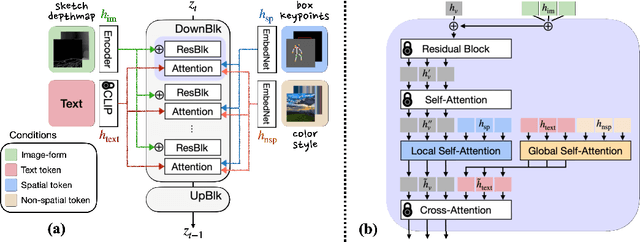
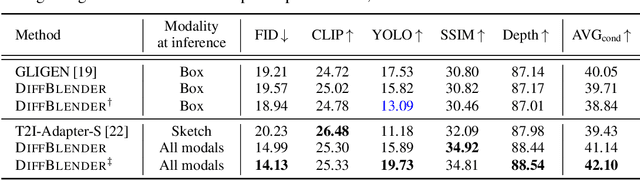
The recent progress in diffusion-based text-to-image generation models has significantly expanded generative capabilities via conditioning the text descriptions. However, since relying solely on text prompts is still restrictive for fine-grained customization, we aim to extend the boundaries of conditional generation to incorporate diverse types of modalities, e.g., sketch, box, and style embedding, simultaneously. We thus design a multimodal text-to-image diffusion model, coined as DiffBlender, that achieves the aforementioned goal in a single model by training only a few small hypernetworks. DiffBlender facilitates a convenient scaling of input modalities, without altering the parameters of an existing large-scale generative model to retain its well-established knowledge. Furthermore, our study sets new standards for multimodal generation by conducting quantitative and qualitative comparisons with existing approaches. By diversifying the channels of conditioning modalities, DiffBlender faithfully reflects the provided information or, in its absence, creates imaginative generation.
Unsupervised Semantic Correspondence Using Stable Diffusion
May 24, 2023
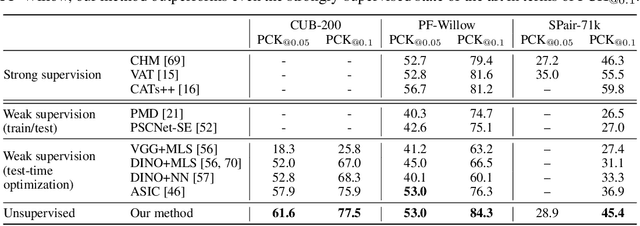

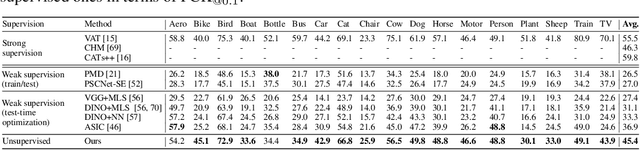
Text-to-image diffusion models are now capable of generating images that are often indistinguishable from real images. To generate such images, these models must understand the semantics of the objects they are asked to generate. In this work we show that, without any training, one can leverage this semantic knowledge within diffusion models to find semantic correspondences -- locations in multiple images that have the same semantic meaning. Specifically, given an image, we optimize the prompt embeddings of these models for maximum attention on the regions of interest. These optimized embeddings capture semantic information about the location, which can then be transferred to another image. By doing so we obtain results on par with the strongly supervised state of the art on the PF-Willow dataset and significantly outperform (20.9% relative for the SPair-71k dataset) any existing weakly or unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
Think Before You Act: Decision Transformers with Internal Working Memory
May 24, 2023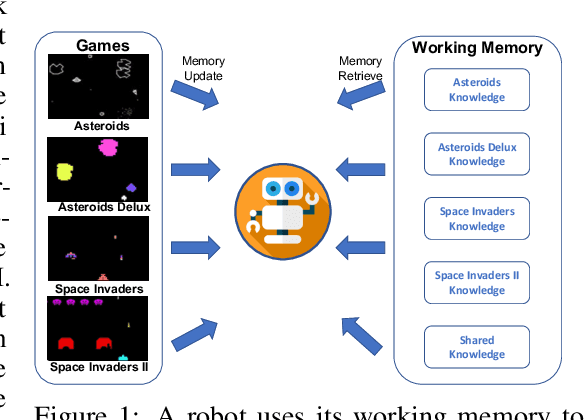
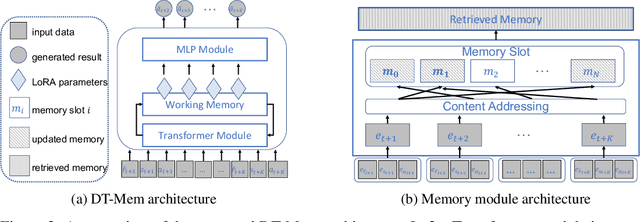

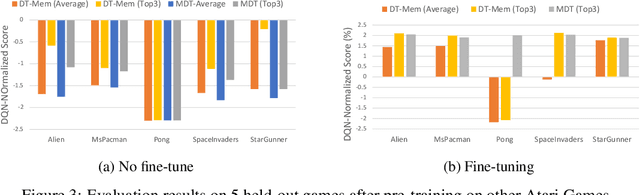
Large language model (LLM)-based decision-making agents have shown the ability to generalize across multiple tasks. However, their performance relies on massive data and compute. We argue that this inefficiency stems from the forgetting phenomenon, in which a model memorizes its behaviors in parameters throughout training. As a result, training on a new task may deteriorate the model's performance on previous tasks. In contrast to LLMs' implicit memory mechanism, the human brain utilizes distributed memory storage, which helps manage and organize multiple skills efficiently, mitigating the forgetting phenomenon. Thus inspired, we propose an internal working memory module to store, blend, and retrieve information for different downstream tasks. Evaluation results show that the proposed method improves training efficiency and generalization in both Atari games and meta-world object manipulation tasks. Moreover, we demonstrate that memory fine-tuning further enhances the adaptability of the proposed architecture.
Towards Foundation Models for Relational Databases [Vision Paper]
May 24, 2023![Figure 1 for Towards Foundation Models for Relational Databases [Vision Paper]](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fe3154ffced7e2279f42b6a13c00f621f6d41c213%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Towards Foundation Models for Relational Databases [Vision Paper]](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fe3154ffced7e2279f42b6a13c00f621f6d41c213%2F4-Table1-1.png&w=640&q=75)
Tabular representation learning has recently gained a lot of attention. However, existing approaches only learn a representation from a single table, and thus ignore the potential to learn from the full structure of relational databases, including neighboring tables that can contain important information for a contextualized representation. Moreover, current models are significantly limited in scale, which prevents that they learn from large databases. In this paper, we thus introduce our vision of relational representation learning, that can not only learn from the full relational structure, but also can scale to larger database sizes that are commonly found in real-world. Moreover, we also discuss opportunities and challenges we see along the way to enable this vision and present initial very promising results. Overall, we argue that this direction can lead to foundation models for relational databases that are today only available for text and images.
On the road to more accurate mobile cellular traffic predictions
May 24, 2023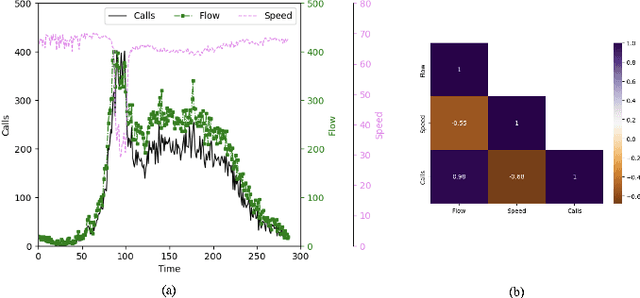
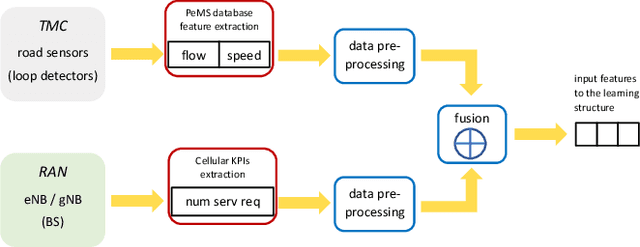
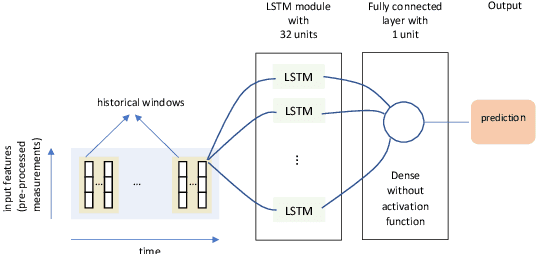
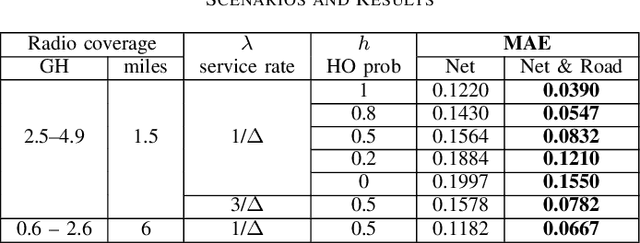
The main contribution reported in the paper is a novel paradigm through which mobile cellular traffic forecasting is made substantially more accurate. Specifically, by incorporating freely available road metrics we characterise the data generation process and spatial dependencies. Therefore, this provides a means for improving the forecasting estimates. We employ highway flow and average speed variables together with a cellular network traffic metric in a light learning structure to predict the short-term future load on a cell covering a segment of a highway. This is in sharp contrast to prior art that mainly studies urban scenarios (with pedestrian and limited vehicular speeds) and develops machine learning approaches that use exclusively network metrics and meta information to make mid-term and long-term predictions. The learning structure can be used at a cell or edge level, and can find application in both federated and centralised learning.