 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A sequential transit network design algorithm with optimal learning under correlated beliefs
May 16, 2023
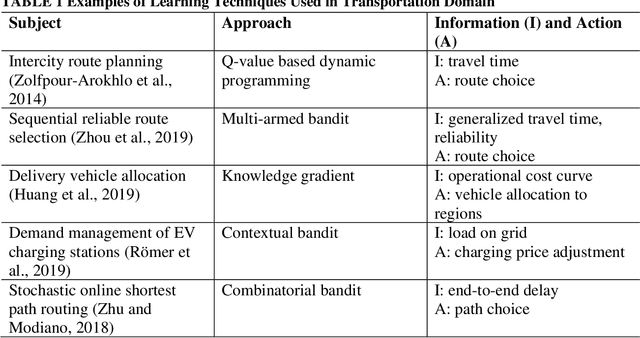
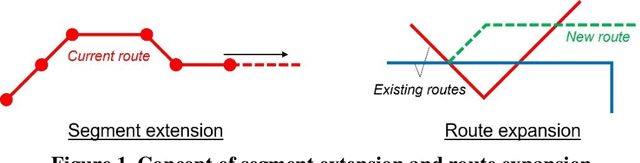
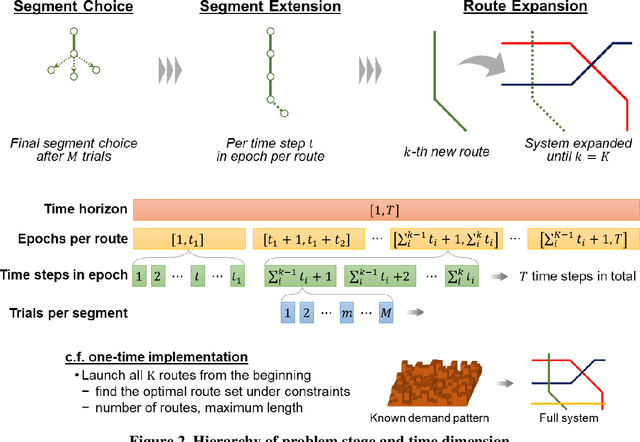
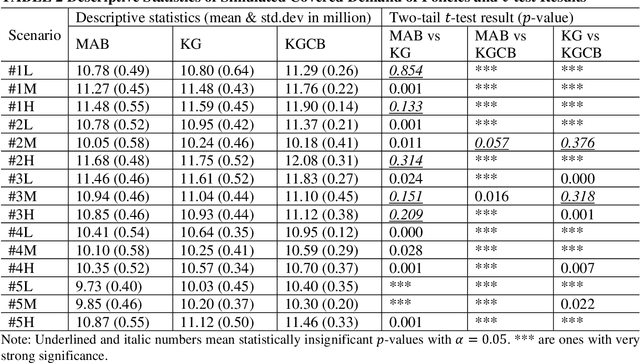
Mobility service route design requires potential demand information to well accommodate travel demand within the service region. Transit planners and operators can access various data sources including household travel survey data and mobile device location logs. However, when implementing a mobility system with emerging technologies, estimating demand level becomes harder because of more uncertainties with user behaviors. Therefore, this study proposes an artificial intelligence-driven algorithm that combines sequential transit network design with optimal learning. An operator gradually expands its route system to avoid risks from inconsistency between designed routes and actual travel demand. At the same time, observed information is archived to update the knowledge that the operator currently uses. Three learning policies are compared within the algorithm: multi-armed bandit, knowledge gradient, and knowledge gradient with correlated beliefs. For validation, a new route system is designed on an artificial network based on public use microdata areas in New York City. Prior knowledge is reproduced from the regional household travel survey data. The results suggest that exploration considering correlations can achieve better performance compared to greedy choices in general. In future work, the problem may incorporate more complexities such as demand elasticity to travel time, no limitations to the number of transfers, and costs for expansion.
xPQA: Cross-Lingual Product Question Answering across 12 Languages
May 16, 2023
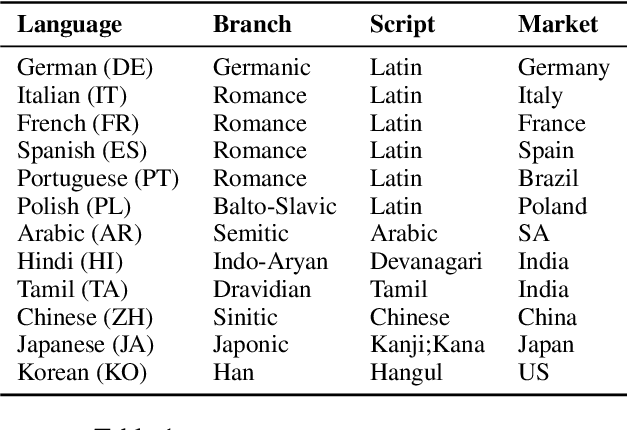
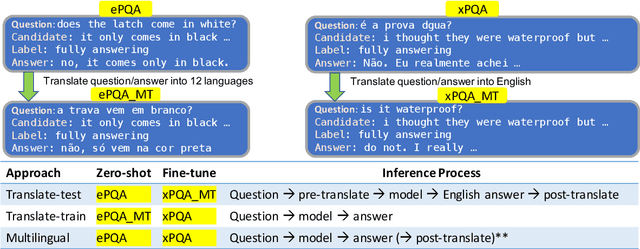
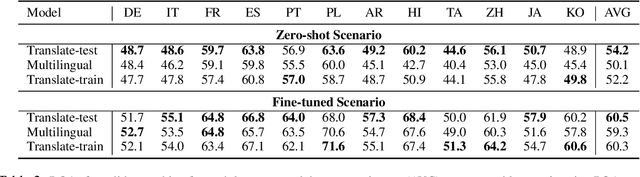
Product Question Answering (PQA) systems are key in e-commerce applications to provide responses to customers' questions as they shop for products. While existing work on PQA focuses mainly on English, in practice there is need to support multiple customer languages while leveraging product information available in English. To study this practical industrial task, we present xPQA, a large-scale annotated cross-lingual PQA dataset in 12 languages across 9 branches, and report results in (1) candidate ranking, to select the best English candidate containing the information to answer a non-English question; and (2) answer generation, to generate a natural-sounding non-English answer based on the selected English candidate. We evaluate various approaches involving machine translation at runtime or offline, leveraging multilingual pre-trained LMs, and including or excluding xPQA training data. We find that (1) In-domain data is essential as cross-lingual rankers trained on other domains perform poorly on the PQA task; (2) Candidate ranking often prefers runtime-translation approaches while answer generation prefers multilingual approaches; (3) Translating offline to augment multilingual models helps candidate ranking mainly on languages with non-Latin scripts; and helps answer generation mainly on languages with Latin scripts. Still, there remains a significant performance gap between the English and the cross-lingual test sets.
Unique Brain Network Identification Number for Parkinson's Individuals Using Structural MRI
Jun 02, 2023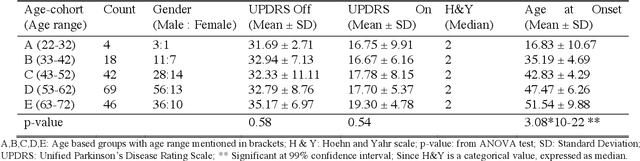
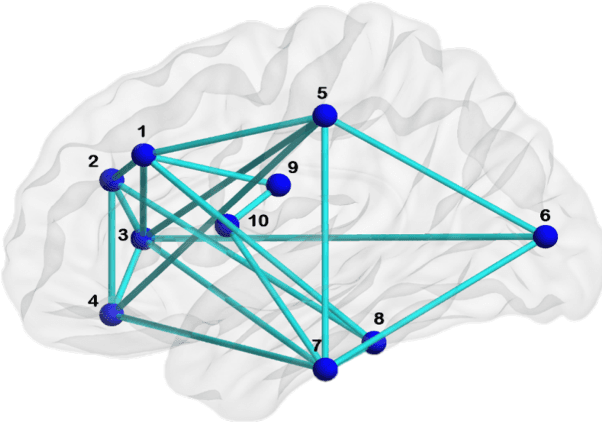
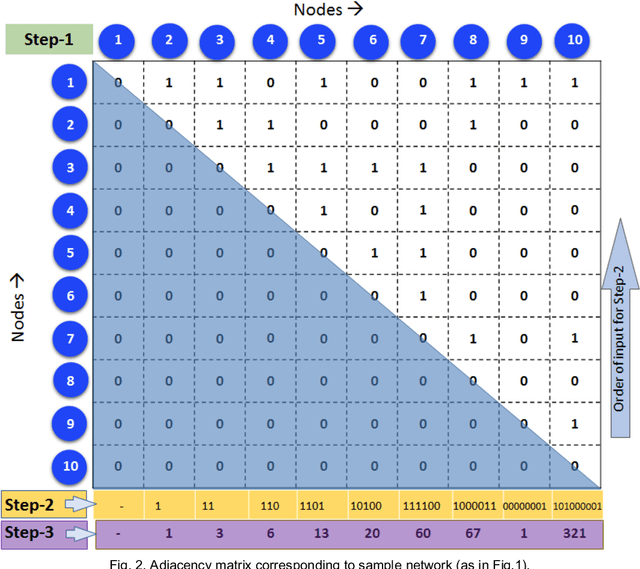
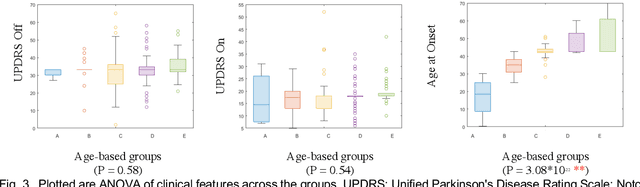
We propose a novel algorithm called Unique Brain Network Identification Number (UBNIN) for encoding brain networks of individual subject. To realize this objective, we employed T1-weighted structural MRI of 180 Parkinson's disease (PD) patients from National Institute of Mental Health and Neurosciences, India. We parcellated each subject's brain volume and constructed individual adjacency matrix using correlation between grey matter (GM) volume of every pair of regions. The unique code is derived from values representing connections of every node (i), weighted by a factor of 2^-(i-1). The numerical representation UBNIN was observed to be distinct for each individual brain network, which may also be applied to other neuroimaging modalities. This model may be implemented as neural signature of a person's unique brain connectivity, thereby useful for brainprinting applications. Additionally, we segregated the above dataset into five age-cohorts: A:22-32years, B:33-42years, C:43-52years, D:53-62years and E:63-72years to study the variation in network topology over age. Sparsity was adopted as the threshold estimate to binarize each age-based correlation matrix. Connectivity metrics were obtained using Brain Connectivity toolbox-based MATLAB functions. For each age-cohort, a decreasing trend was observed in mean clustering coefficient with increasing sparsity. Significantly different clustering coefficient was noted between age-cohort B and C (sparsity: 0.63,0.66), C and E (sparsity: 0.66,0.69). Our findings suggest network connectivity patterns change with age, indicating network disruption due to the underlying neuropathology. Varying clustering coefficient for different cohorts indicate that information transfer between neighboring nodes change with age. This provides evidence on age-related brain shrinkage and network degeneration.
Quantifying Sample Anonymity in Score-Based Generative Models with Adversarial Fingerprinting
Jun 02, 2023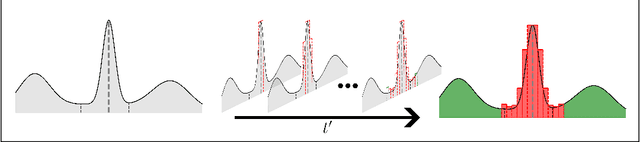
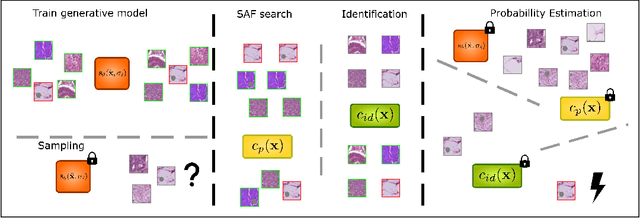
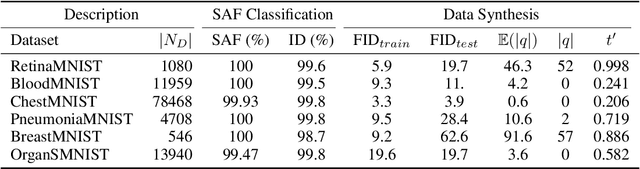
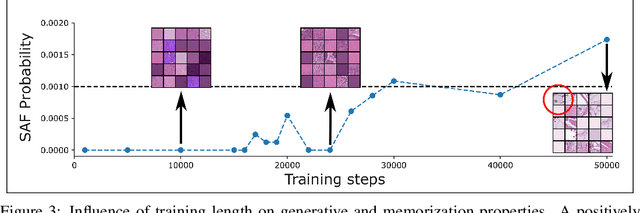
Recent advances in score-based generative models have led to a huge spike in the development of downstream applications using generative models ranging from data augmentation over image and video generation to anomaly detection. Despite publicly available trained models, their potential to be used for privacy preserving data sharing has not been fully explored yet. Training diffusion models on private data and disseminating the models and weights rather than the raw dataset paves the way for innovative large-scale data-sharing strategies, particularly in healthcare, where safeguarding patients' personal health information is paramount. However, publishing such models without individual consent of, e.g., the patients from whom the data was acquired, necessitates guarantees that identifiable training samples will never be reproduced, thus protecting personal health data and satisfying the requirements of policymakers and regulatory bodies. This paper introduces a method for estimating the upper bound of the probability of reproducing identifiable training images during the sampling process. This is achieved by designing an adversarial approach that searches for anatomic fingerprints, such as medical devices or dermal art, which could potentially be employed to re-identify training images. Our method harnesses the learned score-based model to estimate the probability of the entire subspace of the score function that may be utilized for one-to-one reproduction of training samples. To validate our estimates, we generate anomalies containing a fingerprint and investigate whether generated samples from trained generative models can be uniquely mapped to the original training samples. Overall our results show that privacy-breaching images are reproduced at sampling time if the models were trained without care.
AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap
Jun 02, 2023
The rise of powerful large language models (LLMs) brings about tremendous opportunities for innovation but also looming risks for individuals and society at large. We have reached a pivotal moment for ensuring that LLMs and LLM-infused applications are developed and deployed responsibly. However, a central pillar of responsible AI -- transparency -- is largely missing from the current discourse around LLMs. It is paramount to pursue new approaches to provide transparency for LLMs, and years of research at the intersection of AI and human-computer interaction (HCI) highlight that we must do so with a human-centered perspective: Transparency is fundamentally about supporting appropriate human understanding, and this understanding is sought by different stakeholders with different goals in different contexts. In this new era of LLMs, we must develop and design approaches to transparency by considering the needs of stakeholders in the emerging LLM ecosystem, the novel types of LLM-infused applications being built, and the new usage patterns and challenges around LLMs, all while building on lessons learned about how people process, interact with, and make use of information. We reflect on the unique challenges that arise in providing transparency for LLMs, along with lessons learned from HCI and responsible AI research that has taken a human-centered perspective on AI transparency. We then lay out four common approaches that the community has taken to achieve transparency -- model reporting, publishing evaluation results, providing explanations, and communicating uncertainty -- and call out open questions around how these approaches may or may not be applied to LLMs. We hope this provides a starting point for discussion and a useful roadmap for future research.
Group channel pruning and spatial attention distilling for object detection
Jun 02, 2023Due to the over-parameterization of neural networks, many model compression methods based on pruning and quantization have emerged. They are remarkable in reducing the size, parameter number, and computational complexity of the model. However, most of the models compressed by such methods need the support of special hardware and software, which increases the deployment cost. Moreover, these methods are mainly used in classification tasks, and rarely directly used in detection tasks. To address these issues, for the object detection network we introduce a three-stage model compression method: dynamic sparse training, group channel pruning, and spatial attention distilling. Firstly, to select out the unimportant channels in the network and maintain a good balance between sparsity and accuracy, we put forward a dynamic sparse training method, which introduces a variable sparse rate, and the sparse rate will change with the training process of the network. Secondly, to reduce the effect of pruning on network accuracy, we propose a novel pruning method called group channel pruning. In particular, we divide the network into multiple groups according to the scales of the feature layer and the similarity of module structure in the network, and then we use different pruning thresholds to prune the channels in each group. Finally, to recover the accuracy of the pruned network, we use an improved knowledge distillation method for the pruned network. Especially, we extract spatial attention information from the feature maps of specific scales in each group as knowledge for distillation. In the experiments, we use YOLOv4 as the object detection network and PASCAL VOC as the training dataset. Our method reduces the parameters of the model by 64.7 % and the calculation by 34.9%.
* Appl Intell
Multimodal Information Fusion For The Diagnosis Of Diabetic Retinopathy
Mar 20, 2023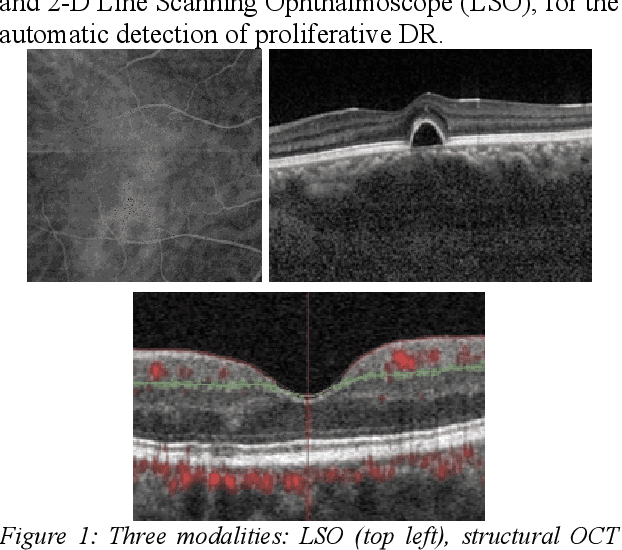

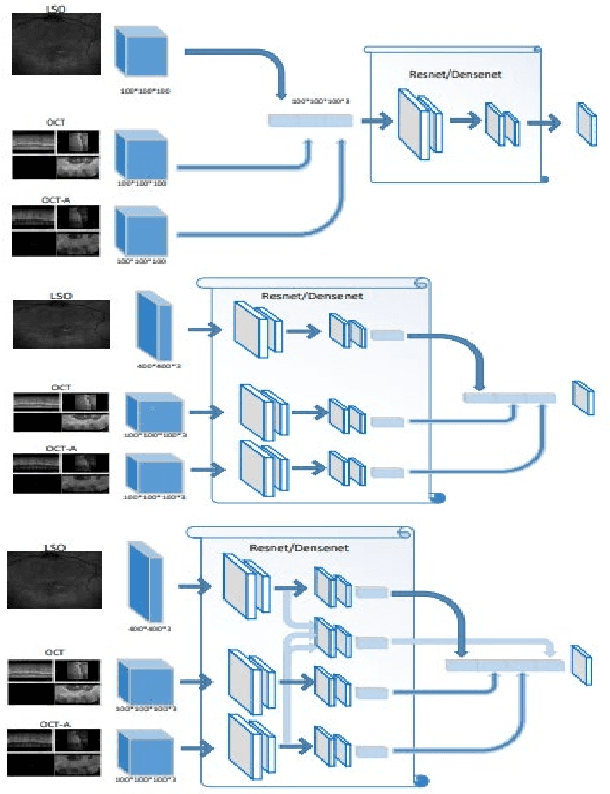
Diabetes is a chronic disease characterized by excess sugar in the blood and affects 422 million people worldwide, including 3.3 million in France. One of the frequent complications of diabetes is diabetic retinopathy (DR): it is the leading cause of blindness in the working population of developed countries. As a result, ophthalmology is on the verge of a revolution in screening, diagnosing, and managing of pathologies. This upheaval is led by the arrival of technologies based on artificial intelligence. The "Evaluation intelligente de la r\'etinopathie diab\'etique" (EviRed) project uses artificial intelligence to answer a medical need: replacing the current classification of diabetic retinopathy which is mainly based on outdated fundus photography and providing an insufficient prediction precision. EviRed exploits modern fundus imaging devices and artificial intelligence to properly integrate the vast amount of data they provide with other available medical data of the patient. The goal is to improve diagnosis and prediction and help ophthalmologists to make better decisions during diabetic retinopathy follow-up. In this study, we investigate the fusion of different modalities acquired simultaneously with a PLEXElite 9000 (Carl Zeiss Meditec Inc. Dublin, California, USA), namely 3-D structural optical coherence tomography (OCT), 3-D OCT angiography (OCTA) and 2-D Line Scanning Ophthalmoscope (LSO), for the automatic detection of proliferative DR.
Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising
May 29, 2023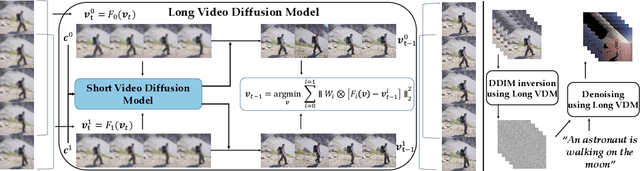


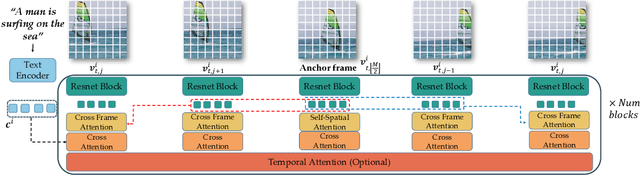
Leveraging large-scale image-text datasets and advancements in diffusion models, text-driven generative models have made remarkable strides in the field of image generation and editing. This study explores the potential of extending the text-driven ability to the generation and editing of multi-text conditioned long videos. Current methodologies for video generation and editing, while innovative, are often confined to extremely short videos (typically less than 24 frames) and are limited to a single text condition. These constraints significantly limit their applications given that real-world videos usually consist of multiple segments, each bearing different semantic information. To address this challenge, we introduce a novel paradigm dubbed as Gen-L-Video, capable of extending off-the-shelf short video diffusion models for generating and editing videos comprising hundreds of frames with diverse semantic segments without introducing additional training, all while preserving content consistency. We have implemented three mainstream text-driven video generation and editing methodologies and extended them to accommodate longer videos imbued with a variety of semantic segments with our proposed paradigm. Our experimental outcomes reveal that our approach significantly broadens the generative and editing capabilities of video diffusion models, offering new possibilities for future research and applications. The code is available at https://github.com/G-U-N/Gen-L-Video.
Pre-training Contextualized World Models with In-the-wild Videos for Reinforcement Learning
May 29, 2023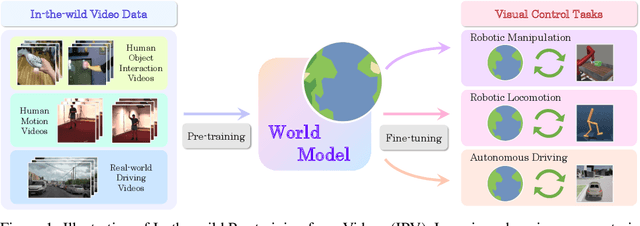
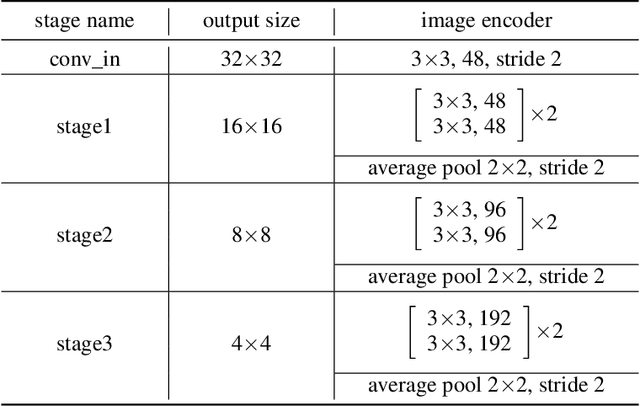
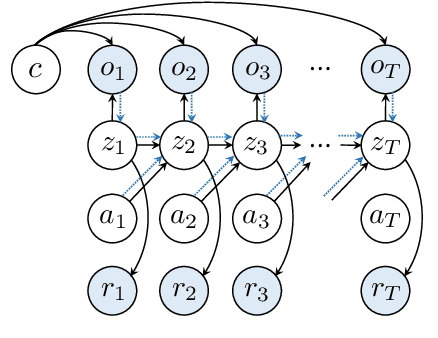

Unsupervised pre-training methods utilizing large and diverse datasets have achieved tremendous success across a range of domains. Recent work has investigated such unsupervised pre-training methods for model-based reinforcement learning (MBRL) but is limited to domain-specific or simulated data. In this paper, we study the problem of pre-training world models with abundant in-the-wild videos for efficient learning of downstream visual control tasks. However, in-the-wild videos are complicated with various contextual factors, such as intricate backgrounds and textured appearance, which precludes a world model from extracting shared world knowledge to generalize better. To tackle this issue, we introduce Contextualized World Models (ContextWM) that explicitly model both the context and dynamics to overcome the complexity and diversity of in-the-wild videos and facilitate knowledge transfer between distinct scenes. Specifically, a contextualized extension of the latent dynamics model is elaborately realized by incorporating a context encoder to retain contextual information and empower the image decoder, which allows the latent dynamics model to concentrate on essential temporal variations. Our experiments show that in-the-wild video pre-training equipped with ContextWM can significantly improve the sample-efficiency of MBRL in various domains, including robotic manipulation, locomotion, and autonomous driving.
Perimeter Control Using Deep Reinforcement Learning: A Model-free Approach towards Homogeneous Flow Rate Optimization
May 29, 2023
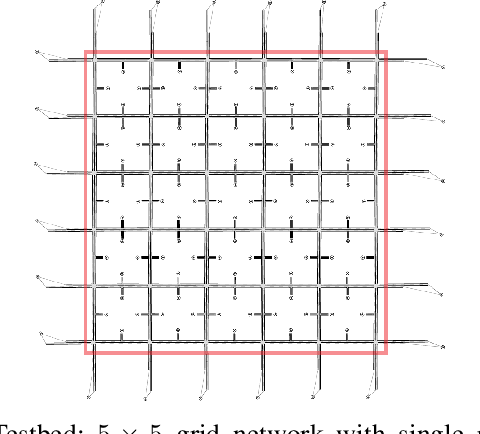
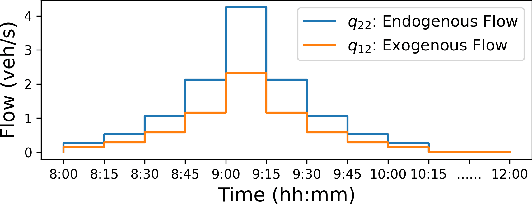
Perimeter control maintains high traffic efficiency within protected regions by controlling transfer flows among regions to ensure that their traffic densities are below critical values. Existing approaches can be categorized as either model-based or model-free, depending on whether they rely on network transmission models (NTMs) and macroscopic fundamental diagrams (MFDs). Although model-based approaches are more data efficient and have performance guarantees, they are inherently prone to model bias and inaccuracy. For example, NTMs often become imprecise for a large number of protected regions, and MFDs can exhibit scatter and hysteresis that are not captured in existing model-based works. Moreover, no existing studies have employed reinforcement learning for homogeneous flow rate optimization in microscopic simulation, where spatial characteristics, vehicle-level information, and metering realizations -- often overlooked in macroscopic simulations -- are taken into account. To circumvent issues of model-based approaches and macroscopic simulation, we propose a model-free deep reinforcement learning approach that optimizes the flow rate homogeneously at the perimeter at the microscopic level. Results demonstrate that our model-free reinforcement learning approach without any knowledge of NTMs or MFDs can compete and match the performance of a model-based approach, and exhibits enhanced generalizability and scalability.