 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Schema-adaptable Knowledge Graph Construction
May 15, 2023
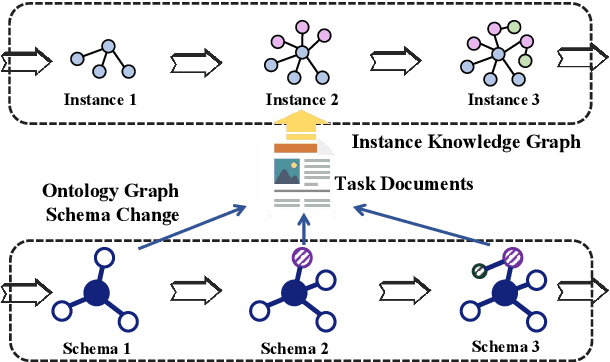
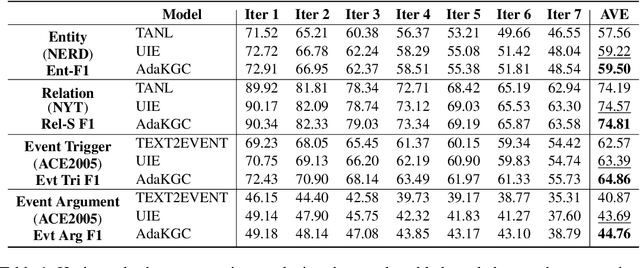
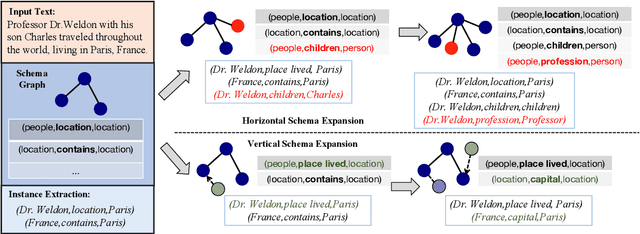
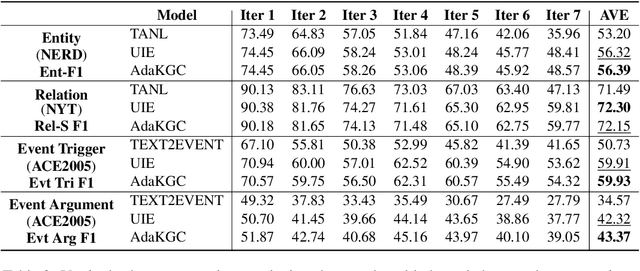
Conventional Knowledge Graph Construction (KGC) approaches typically follow the static information extraction paradigm with a closed set of pre-defined schema. As a result, such approaches fall short when applied to dynamic scenarios or domains, whereas a new type of knowledge emerges. This necessitates a system that can handle evolving schema automatically to extract information for KGC. To address this need, we propose a new task called schema-adaptable KGC, which aims to continually extract entity, relation, and event based on a dynamically changing schema graph without re-training. We first split and convert existing datasets based on three principles to build a benchmark, i.e., horizontal schema expansion, vertical schema expansion, and hybrid schema expansion; then investigate the schema-adaptable performance of several well-known approaches such as Text2Event, TANL, UIE and GPT-3. We further propose a simple yet effective baseline dubbed AdaKGC, which contains schema-enriched prefix instructor and schema-conditioned dynamic decoding to better handle evolving schema. Comprehensive experimental results illustrate that AdaKGC can outperform baselines but still have room for improvement. We hope the proposed work can deliver benefits to the community. Code and datasets will be available in https://github.com/zjunlp/AdaKGC.
Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering
May 18, 2023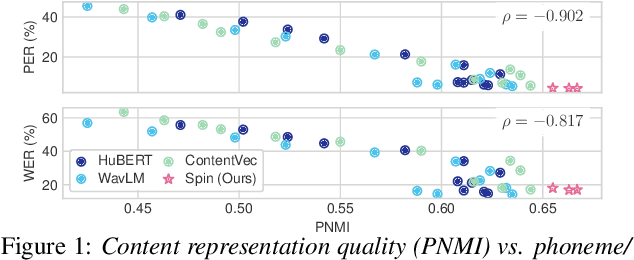
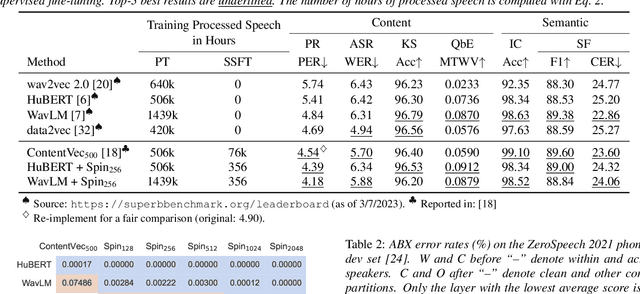
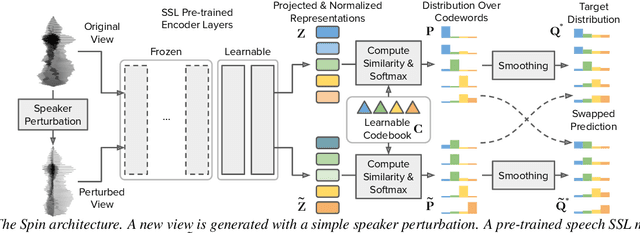
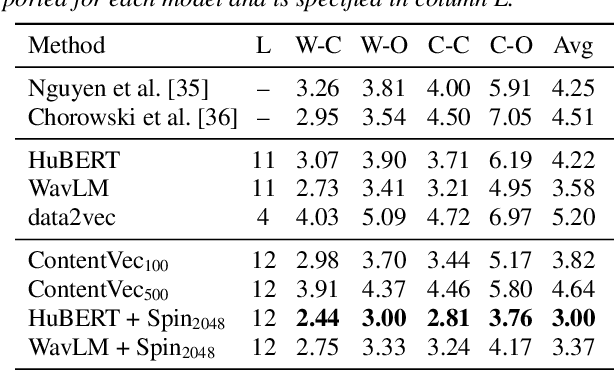
Self-supervised speech representation models have succeeded in various tasks, but improving them for content-related problems using unlabeled data is challenging. We propose speaker-invariant clustering (Spin), a novel self-supervised learning method that clusters speech representations and performs swapped prediction between the original and speaker-perturbed utterances. Spin disentangles speaker information and preserves content representations with just 45 minutes of fine-tuning on a single GPU. Spin improves pre-trained networks and outperforms prior methods in speech recognition and acoustic unit discovery.
Self-attention Dual Embedding for Graphs with Heterophily
May 28, 2023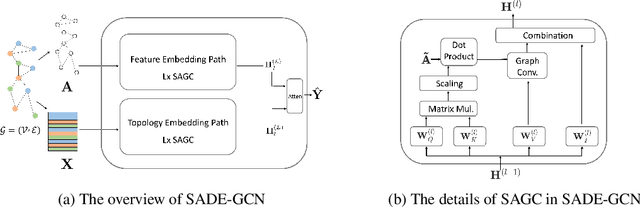

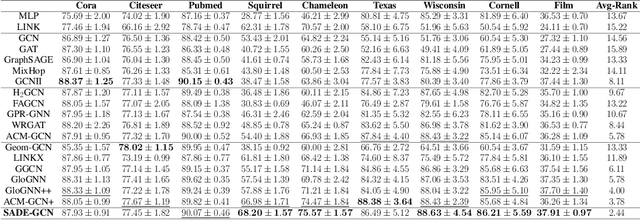
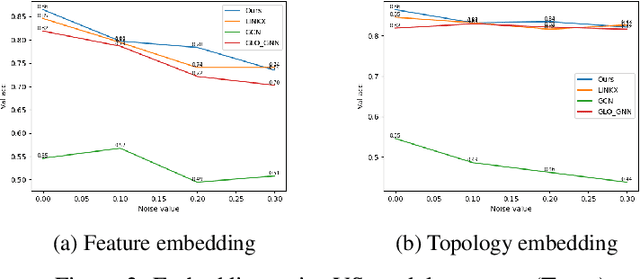
Graph Neural Networks (GNNs) have been highly successful for the node classification task. GNNs typically assume graphs are homophilic, i.e. neighboring nodes are likely to belong to the same class. However, a number of real-world graphs are heterophilic, and this leads to much lower classification accuracy using standard GNNs. In this work, we design a novel GNN which is effective for both heterophilic and homophilic graphs. Our work is based on three main observations. First, we show that node features and graph topology provide different amounts of informativeness in different graphs, and therefore they should be encoded independently and prioritized in an adaptive manner. Second, we show that allowing negative attention weights when propagating graph topology information improves accuracy. Finally, we show that asymmetric attention weights between nodes are helpful. We design a GNN which makes use of these observations through a novel self-attention mechanism. We evaluate our algorithm on real-world graphs containing thousands to millions of nodes and show that we achieve state-of-the-art results compared to existing GNNs. We also analyze the effectiveness of the main components of our design on different graphs.
Learning a Structural Causal Model for Intuition Reasoning in Conversation
May 28, 2023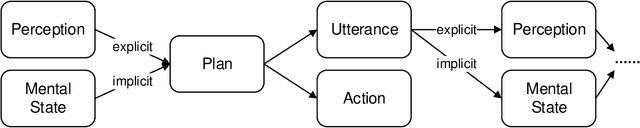
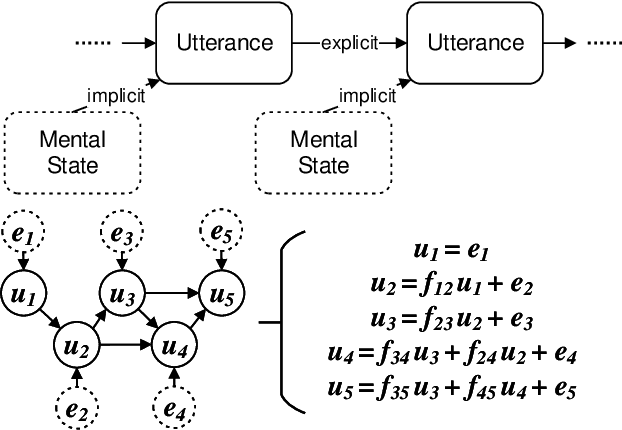

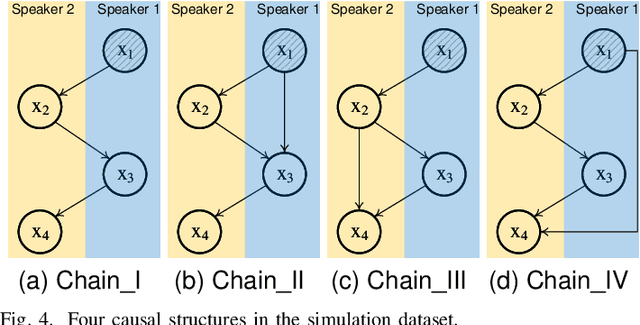
Reasoning, a crucial aspect of NLP research, has not been adequately addressed by prevailing models including Large Language Model. Conversation reasoning, as a critical component of it, remains largely unexplored due to the absence of a well-designed cognitive model. In this paper, inspired by intuition theory on conversation cognition, we develop a conversation cognitive model (CCM) that explains how each utterance receives and activates channels of information recursively. Besides, we algebraically transformed CCM into a structural causal model (SCM) under some mild assumptions, rendering it compatible with various causal discovery methods. We further propose a probabilistic implementation of the SCM for utterance-level relation reasoning. By leveraging variational inference, it explores substitutes for implicit causes, addresses the issue of their unobservability, and reconstructs the causal representations of utterances through the evidence lower bounds. Moreover, we constructed synthetic and simulated datasets incorporating implicit causes and complete cause labels, alleviating the current situation where all available datasets are implicit-causes-agnostic. Extensive experiments demonstrate that our proposed method significantly outperforms existing methods on synthetic, simulated, and real-world datasets. Finally, we analyze the performance of CCM under latent confounders and propose theoretical ideas for addressing this currently unresolved issue.
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
May 23, 2023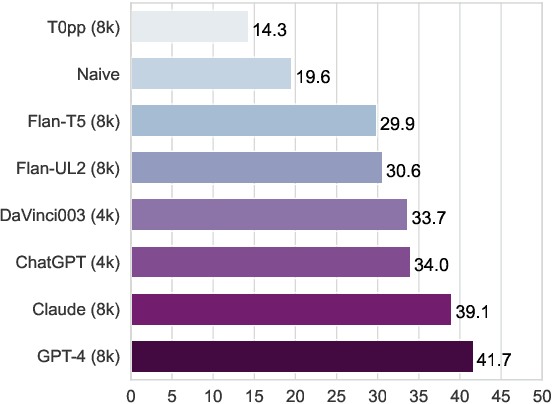
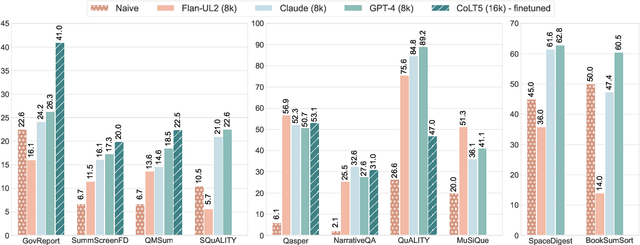
We introduce ZeroSCROLLS, a zero-shot benchmark for natural language understanding over long texts, which contains only test sets, without training or development data. We adapt six tasks from the SCROLLS benchmark, and add four new datasets, including two novel information fusing tasks, such as aggregating the percentage of positive reviews. Using ZeroSCROLLS, we conduct a comprehensive evaluation of both open-source and closed large language models, finding that Claude outperforms ChatGPT, and that GPT-4 achieves the highest average score. However, there is still room for improvement on multiple open challenges in ZeroSCROLLS, such as aggregation tasks, where models struggle to pass the naive baseline. As the state of the art is a moving target, we invite researchers to evaluate their ideas on the live ZeroSCROLLS leaderboard
Using Textual Interface to Align External Knowledge for End-to-End Task-Oriented Dialogue Systems
May 23, 2023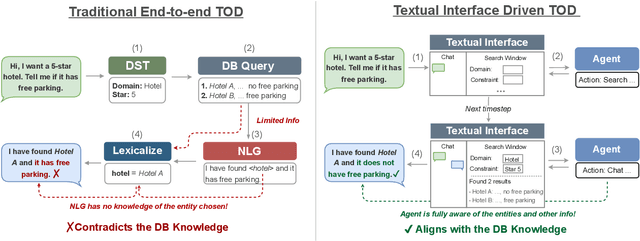
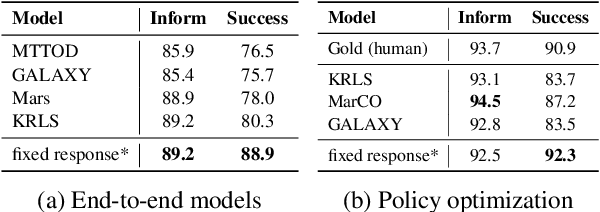
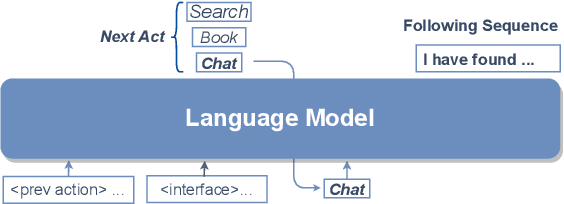
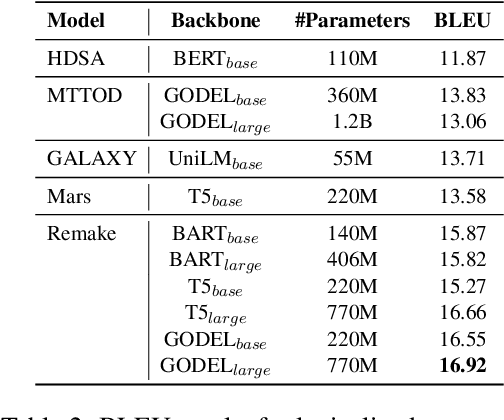
Traditional end-to-end task-oriented dialogue systems have been built with a modularized design. However, such design often causes misalignment between the agent response and external knowledge, due to inadequate representation of information. Furthermore, its evaluation metrics emphasize assessing the agent's pre-lexicalization response, neglecting the quality of the completed response. In this work, we propose a novel paradigm that uses a textual interface to align external knowledge and eliminate redundant processes. We demonstrate our paradigm in practice through MultiWOZ-Remake, including an interactive textual interface built for the MultiWOZ database and a correspondingly re-processed dataset. We train an end-to-end dialogue system to evaluate this new dataset. The experimental results show that our approach generates more natural final responses and achieves a greater task success rate compared to the previous models.
Exploring Representational Disparities Between Multilingual and Bilingual Translation Models
May 23, 2023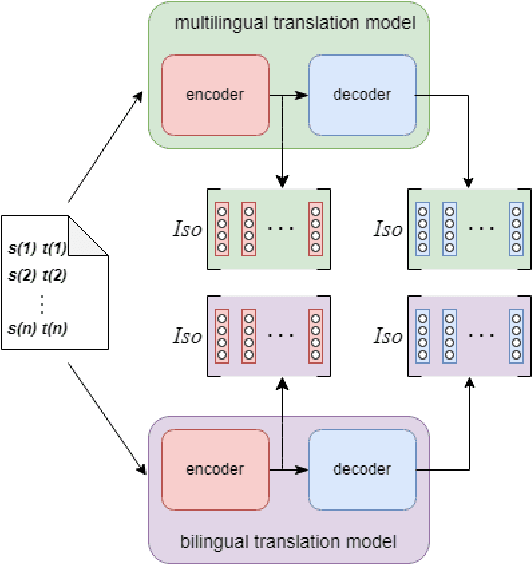

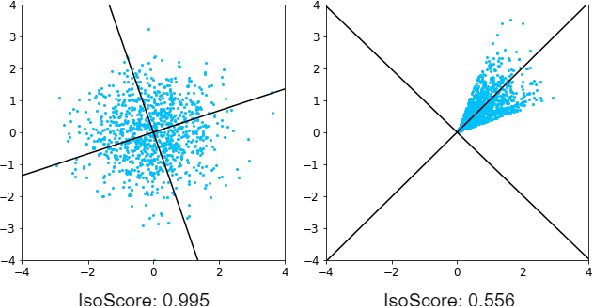
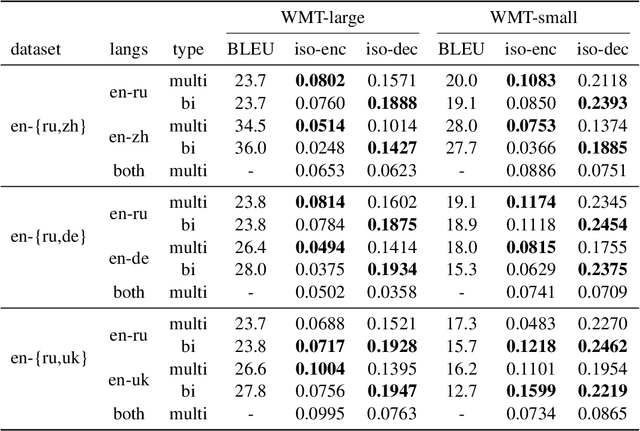
Multilingual machine translation has proven immensely useful for low-resource and zero-shot language pairs. However, language pairs in multilingual models sometimes see worse performance than in bilingual models, especially when translating in a one-to-many setting. To understand why, we examine the geometric differences in the representations from bilingual models versus those from one-to-many multilingual models. Specifically, we evaluate the isotropy of the representations, to measure how well they utilize the dimensions in their underlying vector space. Using the same evaluation data in both models, we find that multilingual model decoder representations tend to be less isotropic than bilingual model decoder representations. Additionally, we show that much of the anisotropy in multilingual decoder representations can be attributed to modeling language-specific information, therefore limiting remaining representational capacity.
Statistical Indistinguishability of Learning Algorithms
May 23, 2023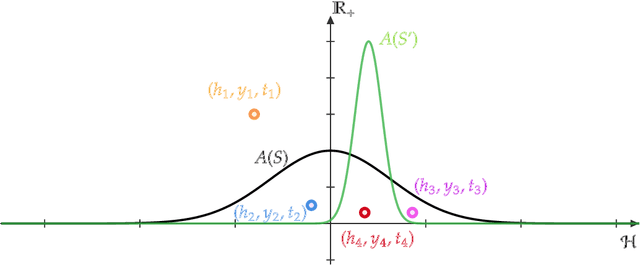
When two different parties use the same learning rule on their own data, how can we test whether the distributions of the two outcomes are similar? In this paper, we study the similarity of outcomes of learning rules through the lens of the Total Variation (TV) distance of distributions. We say that a learning rule is TV indistinguishable if the expected TV distance between the posterior distributions of its outputs, executed on two training data sets drawn independently from the same distribution, is small. We first investigate the learnability of hypothesis classes using TV indistinguishable learners. Our main results are information-theoretic equivalences between TV indistinguishability and existing algorithmic stability notions such as replicability and approximate differential privacy. Then, we provide statistical amplification and boosting algorithms for TV indistinguishable learners.
Deep GEM-Based Network for Weakly Supervised UWB Ranging Error Mitigation
May 23, 2023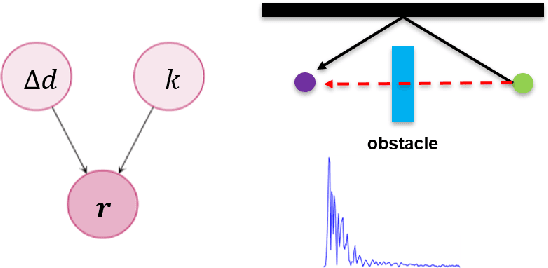
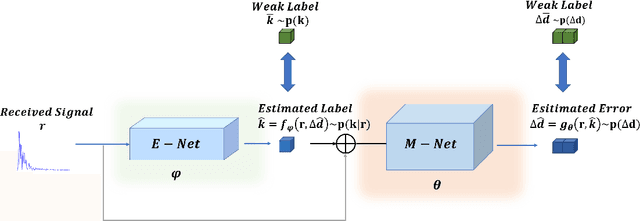
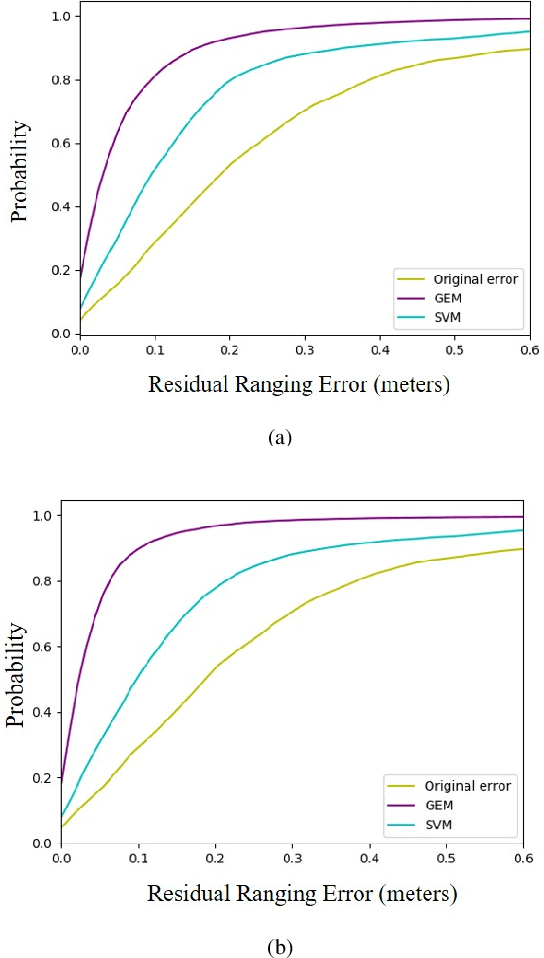
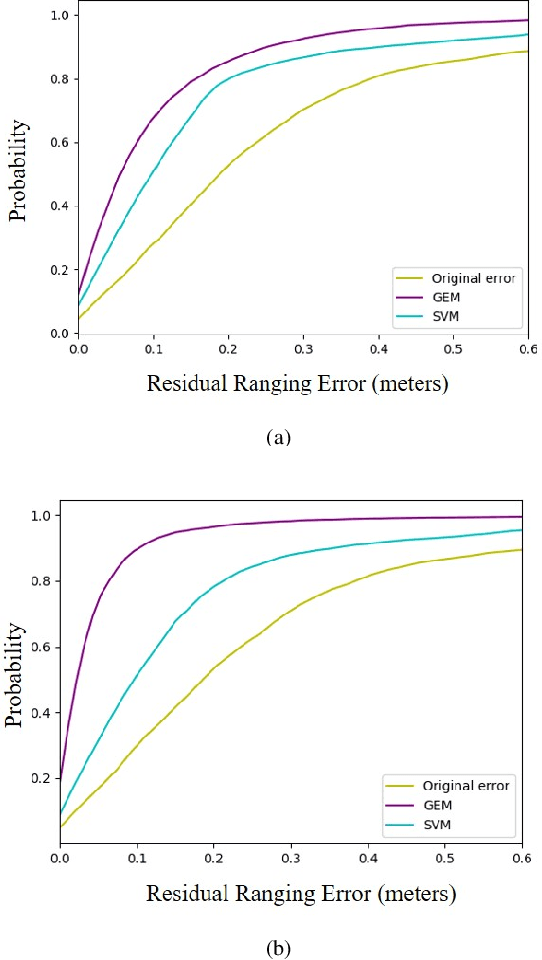
Ultra-wideband (UWB)-based techniques, while becoming mainstream approaches for high-accurate positioning, tend to be challenged by ranging bias in harsh environments. The emerging learning-based methods for error mitigation have shown great performance improvement via exploiting high semantic features from raw data. However, these methods rely heavily on fully labeled data, leading to a high cost for data acquisition. We present a learning framework based on weak supervision for UWB ranging error mitigation. Specifically, we propose a deep learning method based on the generalized expectation-maximization (GEM) algorithm for robust UWB ranging error mitigation under weak supervision. Such method integrate probabilistic modeling into the deep learning scheme, and adopt weakly supervised labels as prior information. Extensive experiments in various supervision scenarios illustrate the superiority of the proposed method.
* 6 pages, 4 figures, Published in: MILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM)
Unique Brain Network Identification Number for Parkinson's Individuals Using Structural MRI
Jun 02, 2023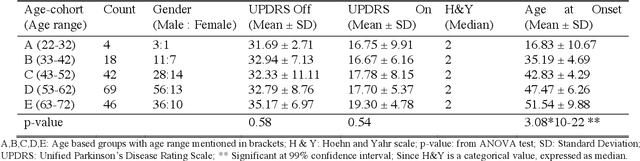
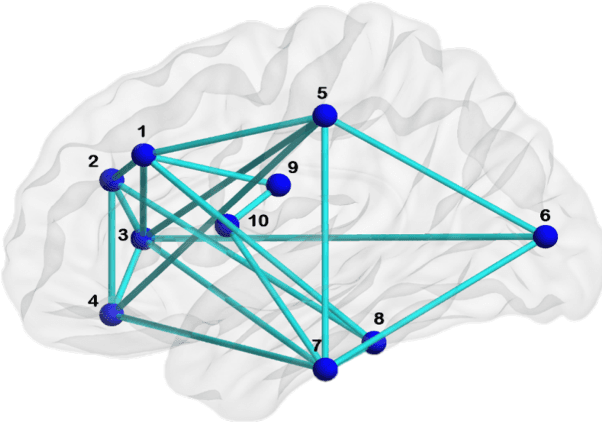
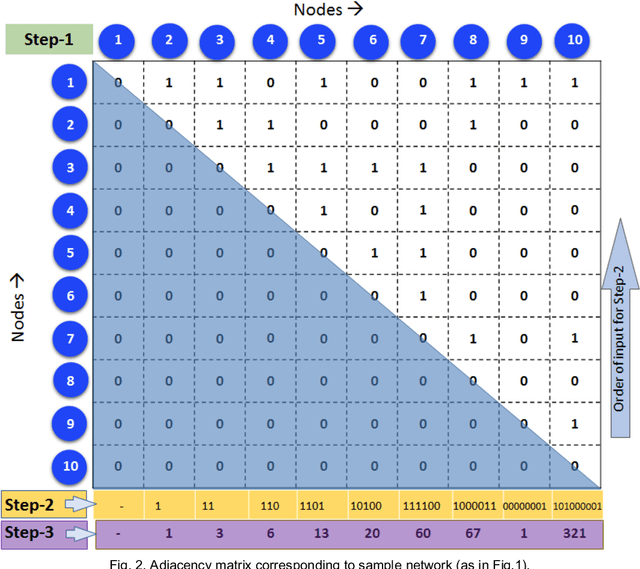
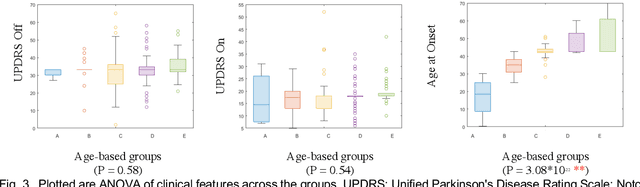
We propose a novel algorithm called Unique Brain Network Identification Number (UBNIN) for encoding brain networks of individual subject. To realize this objective, we employed T1-weighted structural MRI of 180 Parkinson's disease (PD) patients from National Institute of Mental Health and Neurosciences, India. We parcellated each subject's brain volume and constructed individual adjacency matrix using correlation between grey matter (GM) volume of every pair of regions. The unique code is derived from values representing connections of every node (i), weighted by a factor of 2^-(i-1). The numerical representation UBNIN was observed to be distinct for each individual brain network, which may also be applied to other neuroimaging modalities. This model may be implemented as neural signature of a person's unique brain connectivity, thereby useful for brainprinting applications. Additionally, we segregated the above dataset into five age-cohorts: A:22-32years, B:33-42years, C:43-52years, D:53-62years and E:63-72years to study the variation in network topology over age. Sparsity was adopted as the threshold estimate to binarize each age-based correlation matrix. Connectivity metrics were obtained using Brain Connectivity toolbox-based MATLAB functions. For each age-cohort, a decreasing trend was observed in mean clustering coefficient with increasing sparsity. Significantly different clustering coefficient was noted between age-cohort B and C (sparsity: 0.63,0.66), C and E (sparsity: 0.66,0.69). Our findings suggest network connectivity patterns change with age, indicating network disruption due to the underlying neuropathology. Varying clustering coefficient for different cohorts indicate that information transfer between neighboring nodes change with age. This provides evidence on age-related brain shrinkage and network degeneration.