 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Optimizing ViViT Training: Time and Memory Reduction for Action Recognition
Jun 07, 2023
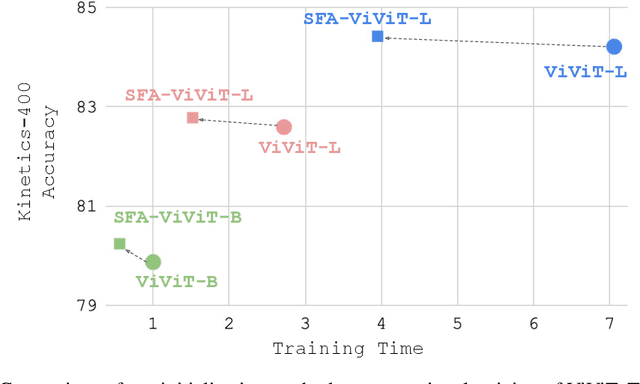
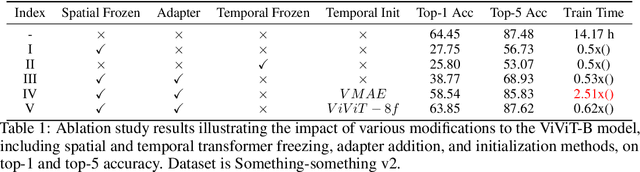
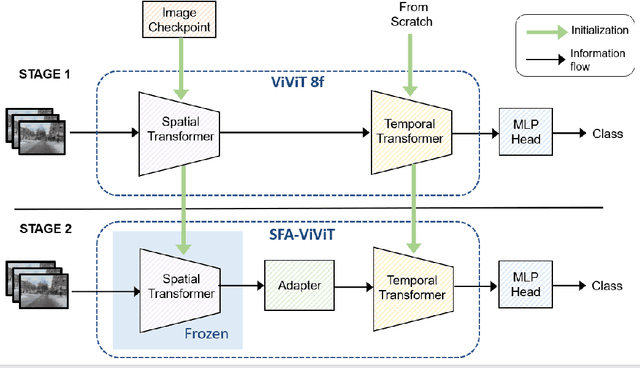

In this paper, we address the challenges posed by the substantial training time and memory consumption associated with video transformers, focusing on the ViViT (Video Vision Transformer) model, in particular the Factorised Encoder version, as our baseline for action recognition tasks. The factorised encoder variant follows the late-fusion approach that is adopted by many state of the art approaches. Despite standing out for its favorable speed/accuracy tradeoffs among the different variants of ViViT, its considerable training time and memory requirements still pose a significant barrier to entry. Our method is designed to lower this barrier and is based on the idea of freezing the spatial transformer during training. This leads to a low accuracy model if naively done. But we show that by (1) appropriately initializing the temporal transformer (a module responsible for processing temporal information) (2) introducing a compact adapter model connecting frozen spatial representations ((a module that selectively focuses on regions of the input image) to the temporal transformer, we can enjoy the benefits of freezing the spatial transformer without sacrificing accuracy. Through extensive experimentation over 6 benchmarks, we demonstrate that our proposed training strategy significantly reduces training costs (by $\sim 50\%$) and memory consumption while maintaining or slightly improving performance by up to 1.79\% compared to the baseline model. Our approach additionally unlocks the capability to utilize larger image transformer models as our spatial transformer and access more frames with the same memory consumption.
Recent applications of machine learning, remote sensing, and iot approaches in yield prediction: a critical review
Jun 07, 2023

The integration of remote sensing and machine learning in agriculture is transforming the industry by providing insights and predictions through data analysis. This combination leads to improved yield prediction and water management, resulting in increased efficiency, better yields, and more sustainable agricultural practices. Achieving the United Nations' Sustainable Development Goals, especially "zero hunger," requires the investigation of crop yield and precipitation gaps, which can be accomplished through, the usage of artificial intelligence (AI), machine learning (ML), remote sensing (RS), and the internet of things (IoT). By integrating these technologies, a robust agricultural mobile or web application can be developed, providing farmers and decision-makers with valuable information and tools for improving crop management and increasing efficiency. Several studies have investigated these new technologies and their potential for diverse tasks such as crop monitoring, yield prediction, irrigation management, etc. Through a critical review, this paper reviews relevant articles that have used RS, ML, cloud computing, and IoT in crop yield prediction. It reviews the current state-of-the-art in this field by critically evaluating different machine-learning approaches proposed in the literature for crop yield prediction and water management. It provides insights into how these methods can improve decision-making in agricultural production systems. This work will serve as a compendium for those interested in yield prediction in terms of primary literature but, most importantly, what approaches can be used for real-time and robust prediction.
Small Moving Object Detection Algorithm Based on Motion Information
Jan 05, 2023
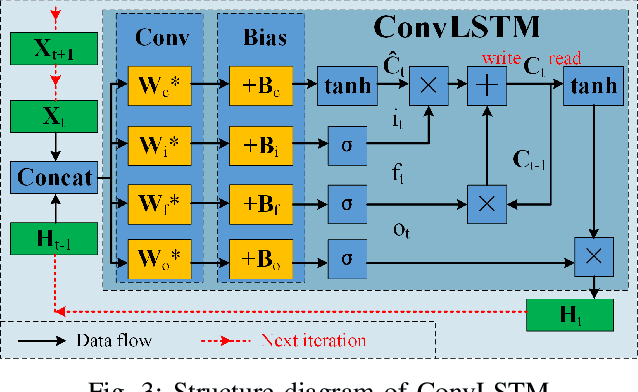
A Samll Moving Object Detection algorithm Based on Motion Information (SMOD-BMI) was proposed to detect small moving objects with low Signal-to-Noise Ratio (SNR). Firstly, To capture suspicious moving objects, a ConvLSTM-SCM-PAN model structure was designed, in which the Convolutional Long and Short Time Memory (ConvLSTM) network fused temporal and spatial information, the Selective Concatenate Module (SCM) was selected to solve the problem of channel unbalance during feature fusion, and the Path Aggregation Network (PAN) located the suspicious moving objects. Then, an object tracking algorithm is used to track suspicious moving objects and calculate their Motion Range (MR). At the same time, according to the moving speed of the suspicious moving objects, the size of their MR is adjusted adaptively (To be specific, if the objects move slowly, we expand their MR according their speed to ensure the contextual environment information) to obtain their Adaptive Candidate Motion Range (ACMR), so as to ensure that the SNR of the moving object is improved while the necessary context information is retained adaptively. Finally, a LightWeight SCM U-Shape Net (LW-SCM-USN) based on ACMR with a SCM module is designed to classify and locate small moving objects accurately and quickly. In this paper, the moving bird in surveillance video is used as the experimental dataset to verify the performance of the algorithm. The experimental results show that the proposed small moving object detection method based on motion information can effectively reduce the missing rate and false detection rate, and its performance is better than the existing moving small object detection method of SOTA.
Photo-zSNthesis: Converting Type Ia Supernova Lightcurves to Redshift Estimates via Deep Learning
May 19, 2023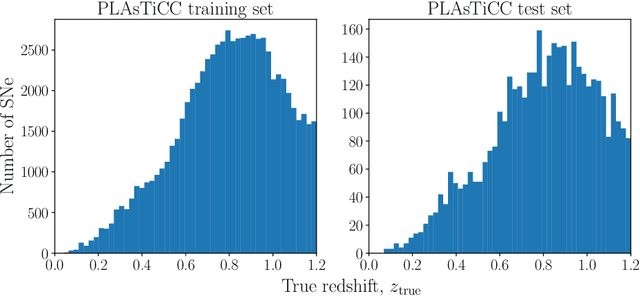

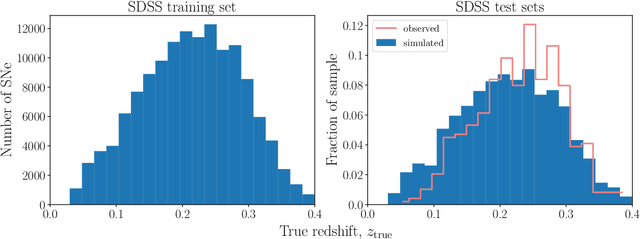
Upcoming photometric surveys will discover tens of thousands of Type Ia supernovae (SNe Ia), vastly outpacing the capacity of our spectroscopic resources. In order to maximize the science return of these observations in the absence of spectroscopic information, we must accurately extract key parameters, such as SN redshifts, with photometric information alone. We present Photo-zSNthesis, a convolutional neural network-based method for predicting full redshift probability distributions from multi-band supernova lightcurves, tested on both simulated Sloan Digital Sky Survey (SDSS) and Vera C. Rubin Legacy Survey of Space and Time (LSST) data as well as observed SDSS SNe. We show major improvements over predictions from existing methods on both simulations and real observations as well as minimal redshift-dependent bias, which is a challenge due to selection effects, e.g. Malmquist bias. The PDFs produced by this method are well-constrained and will maximize the cosmological constraining power of photometric SNe Ia samples.
Video Killed the HD-Map: Predicting Driving Behavior Directly From Drone Images
May 19, 2023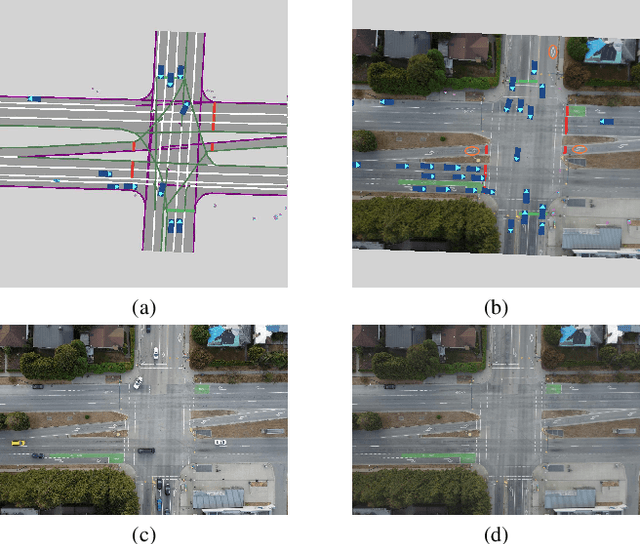
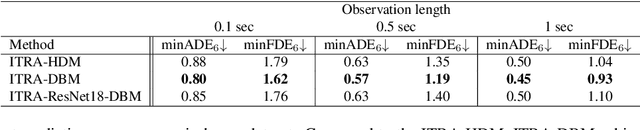
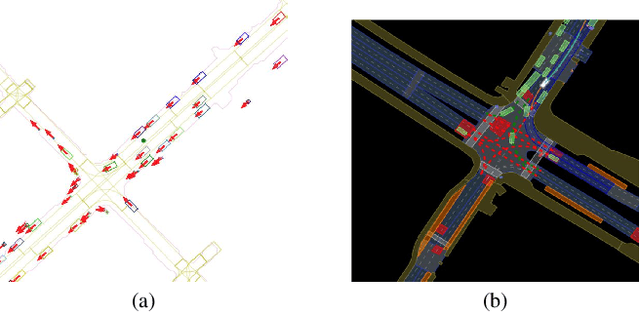

The development of algorithms that learn behavioral driving models using human demonstrations has led to increasingly realistic simulations. In general, such models learn to jointly predict trajectories for all controlled agents by exploiting road context information such as drivable lanes obtained from manually annotated high-definition (HD) maps. Recent studies show that these models can greatly benefit from increasing the amount of human data available for training. However, the manual annotation of HD maps which is necessary for every new location puts a bottleneck on efficiently scaling up human traffic datasets. We propose a drone birdview image-based map (DBM) representation that requires minimal annotation and provides rich road context information. We evaluate multi-agent trajectory prediction using the DBM by incorporating it into a differentiable driving simulator as an image-texture-based differentiable rendering module. Our results demonstrate competitive multi-agent trajectory prediction performance when using our DBM representation as compared to models trained with rasterized HD maps.
Incomplete Multi-view Clustering via Diffusion Completion
May 19, 2023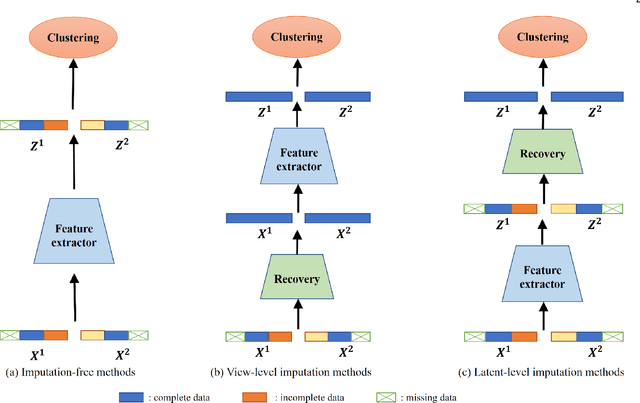
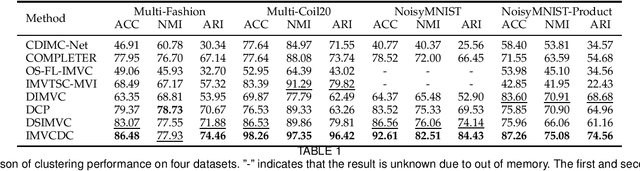
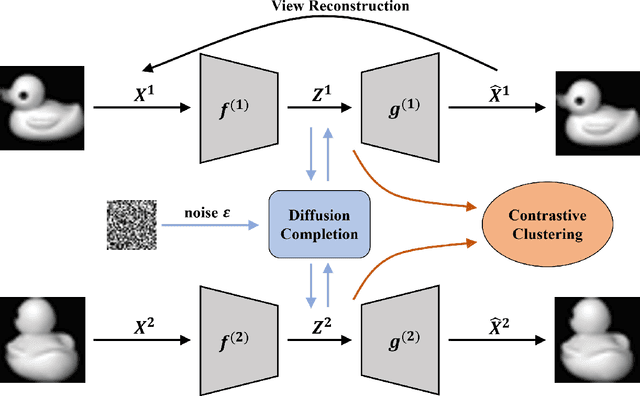

Incomplete multi-view clustering is a challenging and non-trivial task to provide effective data analysis for large amounts of unlabeled data in the real world. All incomplete multi-view clustering methods need to address the problem of how to reduce the impact of missing views. To address this issue, we propose diffusion completion to recover the missing views integrated into an incomplete multi-view clustering framework. Based on the observable views information, the diffusion model is used to recover the missing views, and then the consistency information of the multi-view data is learned by contrastive learning to improve the performance of multi-view clustering. To the best of our knowledge, this may be the first work to incorporate diffusion models into an incomplete multi-view clustering framework. Experimental results show that the proposed method performs well in recovering the missing views while achieving superior clustering performance compared to state-of-the-art methods.
Multi-query Vehicle Re-identification: Viewpoint-conditioned Network, Unified Dataset and New Metric
May 25, 2023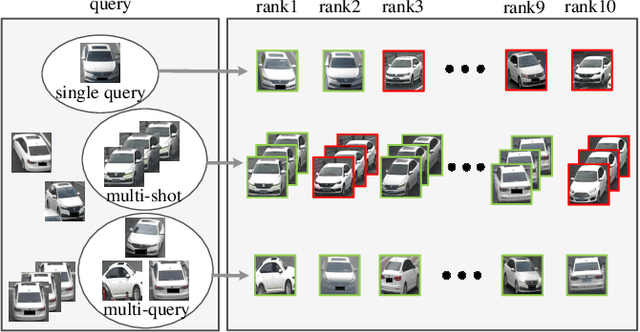
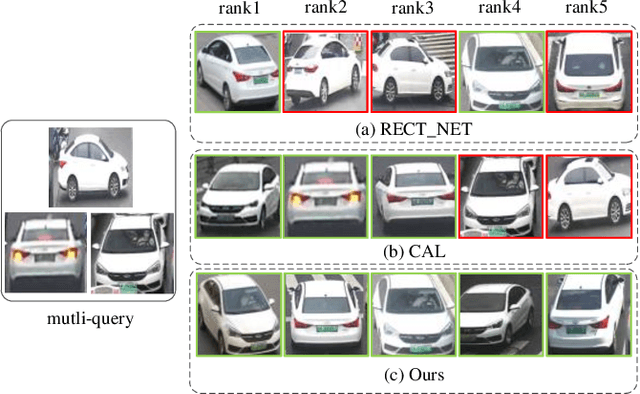
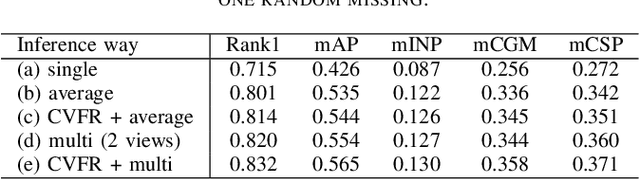
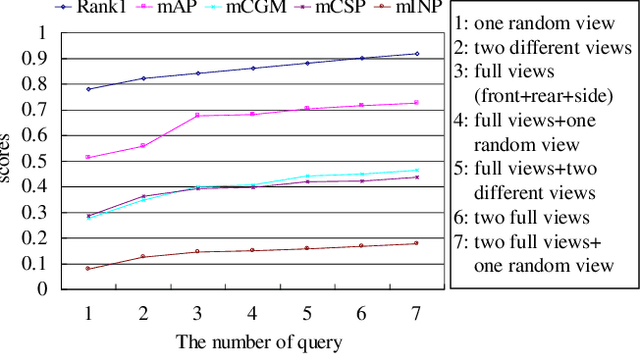
Existing vehicle re-identification methods mainly rely on the single query, which has limited information for vehicle representation and thus significantly hinders the performance of vehicle Re-ID in complicated surveillance networks. In this paper, we propose a more realistic and easily accessible task, called multi-query vehicle Re-ID, which leverages multiple queries to overcome viewpoint limitation of single one. Based on this task, we make three major contributions. First, we design a novel viewpoint-conditioned network (VCNet), which adaptively combines the complementary information from different vehicle viewpoints, for multi-query vehicle Re-ID. Moreover, to deal with the problem of missing vehicle viewpoints, we propose a cross-view feature recovery module which recovers the features of the missing viewpoints by learnt the correlation between the features of available and missing viewpoints. Second, we create a unified benchmark dataset, taken by 6142 cameras from a real-life transportation surveillance system, with comprehensive viewpoints and large number of crossed scenes of each vehicle for multi-query vehicle Re-ID evaluation. Finally, we design a new evaluation metric, called mean cross-scene precision (mCSP), which measures the ability of cross-scene recognition by suppressing the positive samples with similar viewpoints from same camera. Comprehensive experiments validate the superiority of the proposed method against other methods, as well as the effectiveness of the designed metric in the evaluation of multi-query vehicle Re-ID.
Shape-based pose estimation for automatic standard views of the knee
May 26, 2023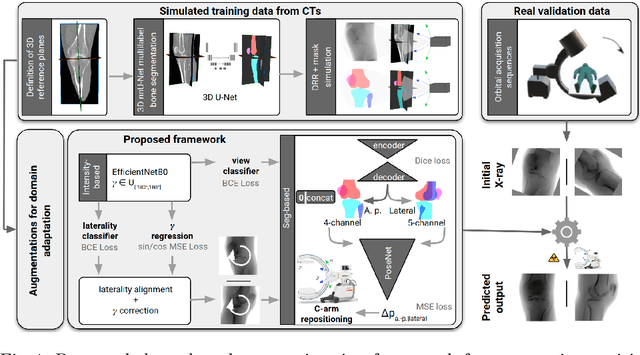


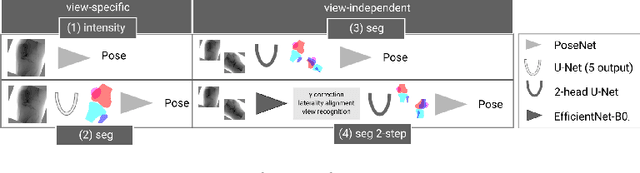
Surgical treatment of complicated knee fractures is guided by real-time imaging using a mobile C-arm. Immediate and continuous control is achieved via 2D anatomy-specific standard views that correspond to a specific C-arm pose relative to the patient positioning, which is currently determined manually, following a trial-and-error approach at the cost of time and radiation dose. The characteristics of the standard views of the knee suggests that the shape information of individual bones could guide an automatic positioning procedure, reducing time and the amount of unnecessary radiation during C-arm positioning. To fully automate the C-arm positioning task during knee surgeries, we propose a complete framework that enables (1) automatic laterality and standard view classification and (2) automatic shape-based pose regression toward the desired standard view based on a single initial X-ray. A suitable shape representation is proposed to incorporate semantic information into the pose regression pipeline. The pipeline is designed to handle two distinct standard views simultaneously. Experiments were conducted to assess the performance of the proposed system on 3528 synthetic and 1386 real X-rays for the a.-p. and lateral standard. The view/laterality classificator resulted in an accuracy of 100\%/98\% on the simulated and 99\%/98\% on the real X-rays. The pose regression performance was $d\theta_{a.-p}=5.8\pm3.3\degree,\,d\theta_{lateral}=3.7\pm2.0\degree$ on the simulated data and $d\theta_{a.-p}=7.4\pm5.0\degree,\,d\theta_{lateral}=8.4\pm5.4\degree$ on the real data outperforming intensity-based pose regression.
Birth of a Transformer: A Memory Viewpoint
Jun 01, 2023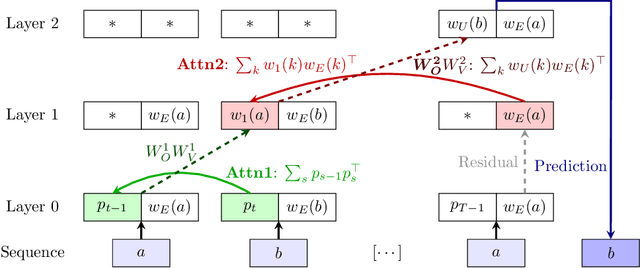

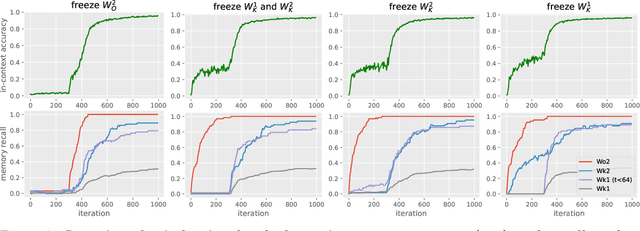
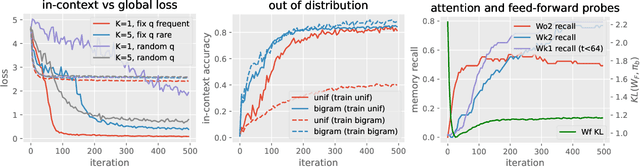
Large language models based on transformers have achieved great empirical successes. However, as they are deployed more widely, there is a growing need to better understand their internal mechanisms in order to make them more reliable. These models appear to store vast amounts of knowledge from their training data, and to adapt quickly to new information provided in their context or prompt. We study how transformers balance these two types of knowledge by considering a synthetic setup where tokens are generated from either global or context-specific bigram distributions. By a careful empirical analysis of the training process on a simplified two-layer transformer, we illustrate the fast learning of global bigrams and the slower development of an "induction head" mechanism for the in-context bigrams. We highlight the role of weight matrices as associative memories, provide theoretical insights on how gradients enable their learning during training, and study the role of data-distributional properties.
Robust T-Loss for Medical Image Segmentation
Jun 01, 2023
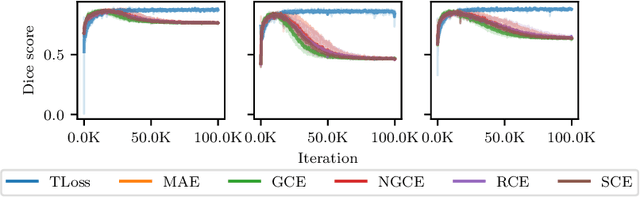
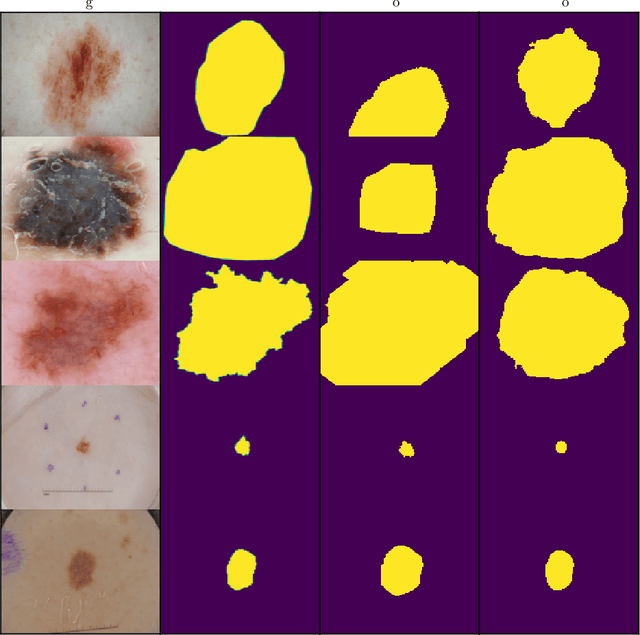
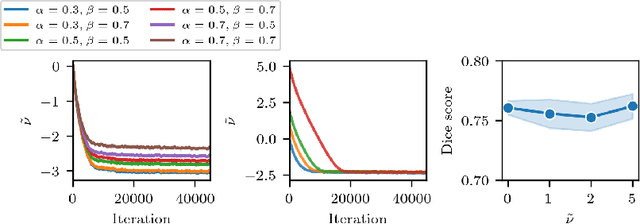
This paper presents a new robust loss function, the T-Loss, for medical image segmentation. The proposed loss is based on the negative log-likelihood of the Student-t distribution and can effectively handle outliers in the data by controlling its sensitivity with a single parameter. This parameter is updated during the backpropagation process, eliminating the need for additional computation or prior information about the level and spread of noisy labels. Our experiments show that the T-Loss outperforms traditional loss functions in terms of dice scores on two public medical datasets for skin lesion and lung segmentation. We also demonstrate the ability of T-Loss to handle different types of simulated label noise, resembling human error. Our results provide strong evidence that the T-Loss is a promising alternative for medical image segmentation where high levels of noise or outliers in the dataset are a typical phenomenon in practice. The project website can be found at https://robust-tloss.github.io