 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical clustering with dot products recovers hidden tree structure
May 24, 2023
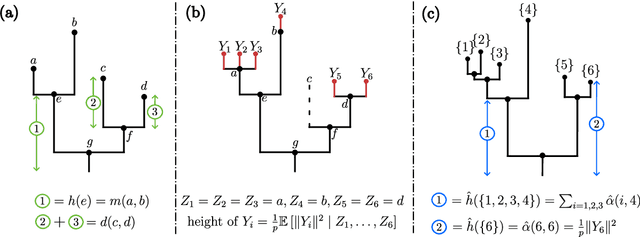

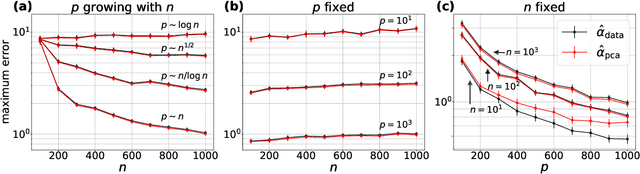
In this paper we offer a new perspective on the well established agglomerative clustering algorithm, focusing on recovery of hierarchical structure. We recommend a simple variant of the standard algorithm, in which clusters are merged by maximum average dot product and not, for example, by minimum distance or within-cluster variance. We demonstrate that the tree output by this algorithm provides a bona fide estimate of generative hierarchical structure in data, under a generic probabilistic graphical model. The key technical innovations are to understand how hierarchical information in this model translates into tree geometry which can be recovered from data, and to characterise the benefits of simultaneously growing sample size and data dimension. We demonstrate superior tree recovery performance with real data over existing approaches such as UPGMA, Ward's method, and HDBSCAN.
Twin support vector quantile regression
May 06, 2023We propose a twin support vector quantile regression (TSVQR) to capture the heterogeneous and asymmetric information in modern data. Using a quantile parameter, TSVQR effectively depicts the heterogeneous distribution information with respect to all portions of data points. Correspondingly, TSVQR constructs two smaller sized quadratic programming problems (QPPs) to generate two nonparallel planes to measure the distributional asymmetry between the lower and upper bounds at each quantile level. The QPPs in TSVQR are smaller and easier to solve than those in previous quantile regression methods. Moreover, the dual coordinate descent algorithm for TSVQR also accelerates the training speed. Experimental results on six artiffcial data sets, ffve benchmark data sets, two large scale data sets, two time-series data sets, and two imbalanced data sets indicate that the TSVQR outperforms previous quantile regression methods in terms of the effectiveness of completely capturing the heterogeneous and asymmetric information and the efffciency of the learning process.
Proposal-Based Multiple Instance Learning for Weakly-Supervised Temporal Action Localization
May 29, 2023
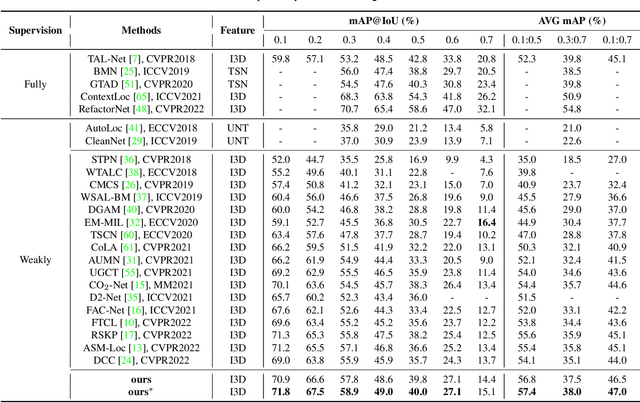
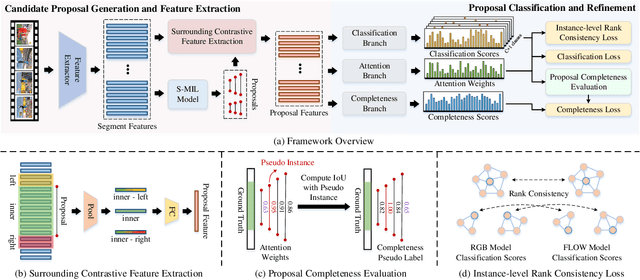

Weakly-supervised temporal action localization aims to localize and recognize actions in untrimmed videos with only video-level category labels during training. Without instance-level annotations, most existing methods follow the Segment-based Multiple Instance Learning (S-MIL) framework, where the predictions of segments are supervised by the labels of videos. However, the objective for acquiring segment-level scores during training is not consistent with the target for acquiring proposal-level scores during testing, leading to suboptimal results. To deal with this problem, we propose a novel Proposal-based Multiple Instance Learning (P-MIL) framework that directly classifies the candidate proposals in both the training and testing stages, which includes three key designs: 1) a surrounding contrastive feature extraction module to suppress the discriminative short proposals by considering the surrounding contrastive information, 2) a proposal completeness evaluation module to inhibit the low-quality proposals with the guidance of the completeness pseudo labels, and 3) an instance-level rank consistency loss to achieve robust detection by leveraging the complementarity of RGB and FLOW modalities. Extensive experimental results on two challenging benchmarks including THUMOS14 and ActivityNet demonstrate the superior performance of our method.
Emergent Incident Response for Unmanned Warehouses with Multi-agent Systems*
May 29, 2023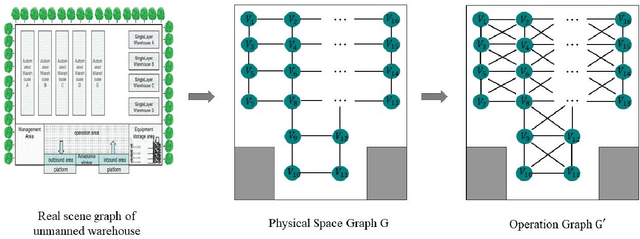
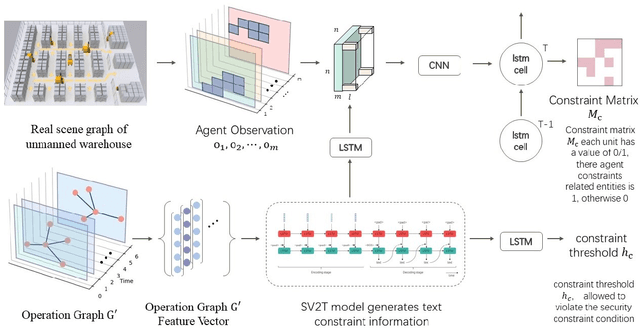
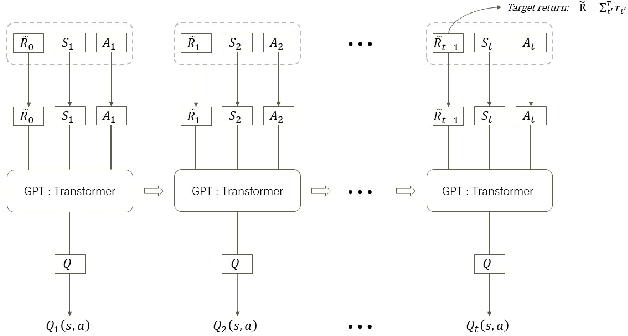
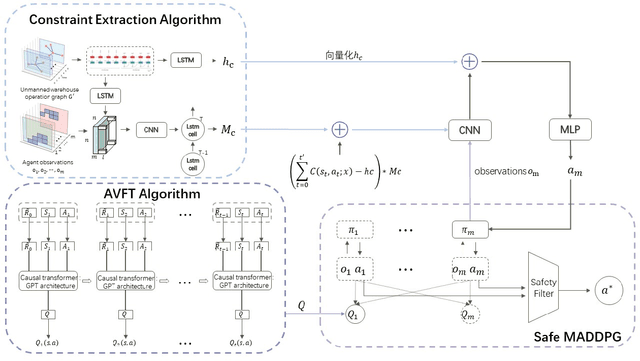
Unmanned warehouses are an important part of logistics, and improving their operational efficiency can effectively enhance service efficiency. However, due to the complexity of unmanned warehouse systems and their susceptibility to errors, incidents may occur during their operation, most often in inbound and outbound operations, which can decrease operational efficiency. Hence it is crucial to to improve the response to such incidents. This paper proposes a collaborative optimization algorithm for emergent incident response based on Safe-MADDPG. To meet safety requirements during emergent incident response, we investigated the intrinsic hidden relationships between various factors. By obtaining constraint information of agents during the emergent incident response process and of the dynamic environment of unmanned warehouses on agents, the algorithm reduces safety risks and avoids the occurrence of chain accidents; this enables an unmanned system to complete emergent incident response tasks and achieve its optimization objectives: (1) minimizing the losses caused by emergent incidents; and (2) maximizing the operational efficiency of inbound and outbound operations during the response process. A series of experiments conducted in a simulated unmanned warehouse scenario demonstrate the effectiveness of the proposed method.
Counterpart Fairness -- Addressing Systematic between-group Differences in Fairness Evaluation
May 29, 2023

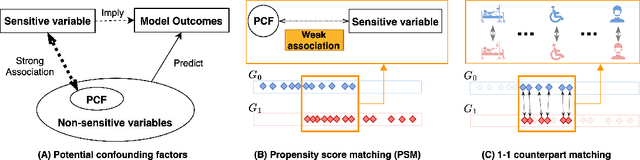

When using machine learning (ML) to aid decision-making, it is critical to ensure that an algorithmic decision is fair, i.e., it does not discriminate against specific individuals/groups, particularly those from underprivileged populations. Existing group fairness methods require equal group-wise measures, which however fails to consider systematic between-group differences. The confounding factors, which are non-sensitive variables but manifest systematic differences, can significantly affect fairness evaluation. To mitigate this problem, we believe that a fairness measurement should be based on the comparison between counterparts (i.e., individuals who are similar to each other with respect to the task of interest) from different groups, whose group identities cannot be distinguished algorithmically by exploring confounding factors. We have developed a propensity-score-based method for identifying counterparts, which prevents fairness evaluation from comparing "oranges" with "apples". In addition, we propose a counterpart-based statistical fairness index, termed Counterpart-Fairness (CFair), to assess fairness of ML models. Empirical studies on the Medical Information Mart for Intensive Care (MIMIC)-IV database were conducted to validate the effectiveness of CFair. We publish our code at \url{https://github.com/zhengyjo/CFair}.
AxWin Transformer: A Context-Aware Vision Transformer Backbone with Axial Windows
May 02, 2023
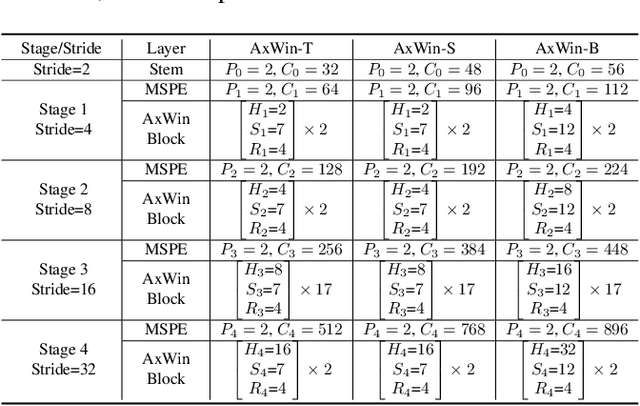
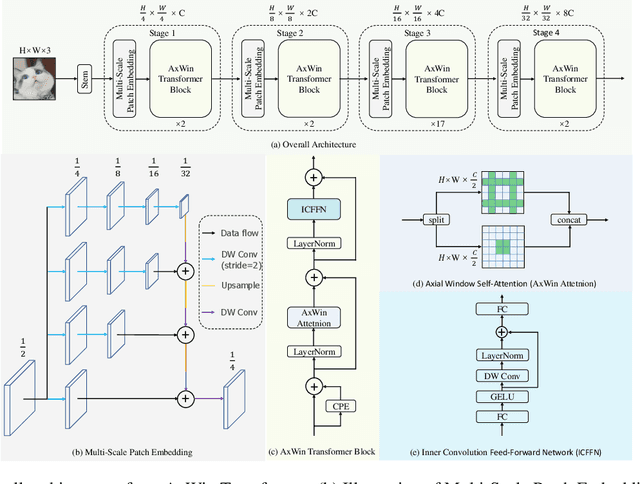
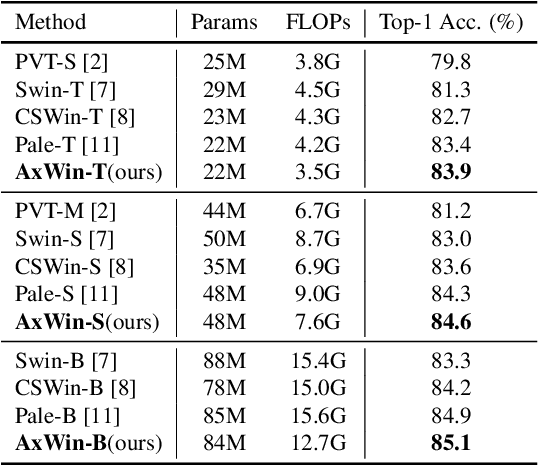
Recently Transformer has shown good performance in several vision tasks due to its powerful modeling capabilities. To reduce the quadratic complexity caused by the attention, some outstanding work restricts attention to local regions or extends axial interactions. However, these methos often lack the interaction of local and global information, balancing coarse and fine-grained information. To address this problem, we propose AxWin Attention, which models context information in both local windows and axial views. Based on the AxWin Attention, we develop a context-aware vision transformer backbone, named AxWin Transformer, which outperforming the state-of-the-art methods in both classification and downstream segmentation and detection tasks.
CVGG-Net: Ship Recognition for SAR Images Based on Complex-Valued Convolutional Neural Network
May 13, 2023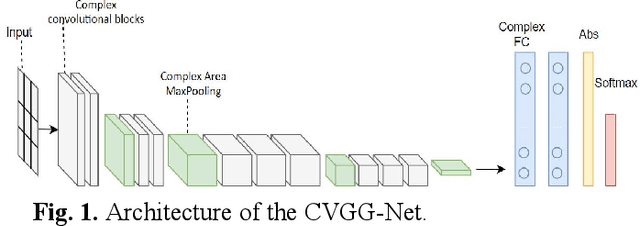
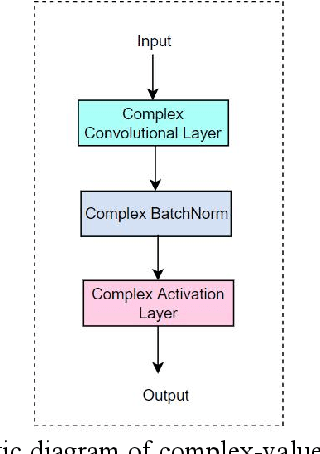
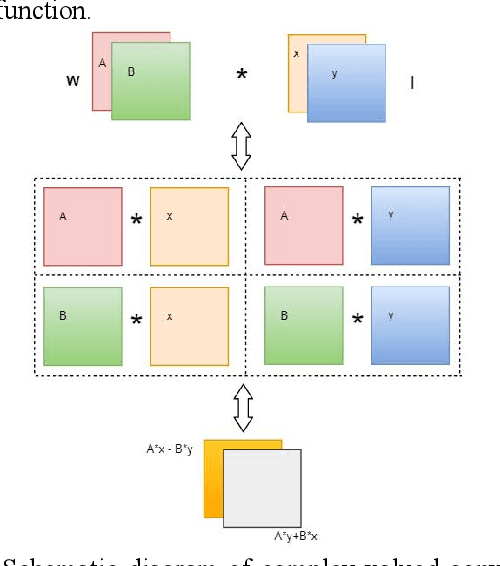
Ship target recognition is a vital task in synthetic aperture radar (SAR) imaging applications. Although convolutional neural networks have been successfully employed for SAR image target recognition, surpassing traditional algorithms, most existing research concentrates on the amplitude domain and neglects the essential phase information. Furthermore, several complex-valued neural networks utilize average pooling to achieve full complex values, resulting in suboptimal performance. To address these concerns, this paper introduces a Complex-valued Convolutional Neural Network (CVGG-Net) specifically designed for SAR image ship recognition. CVGG-Net effectively leverages both the amplitude and phase information in complex-valued SAR data. Additionally, this study examines the impact of various widely-used complex activation functions on network performance and presents a novel complex max-pooling method, called Complex Area Max-Pooling. Experimental results from two measured SAR datasets demonstrate that the proposed algorithm outperforms conventional real-valued convolutional neural networks. The proposed framework is validated on several SAR datasets.
CausalAPM: Generalizable Literal Disentanglement for NLU Debiasing
May 04, 2023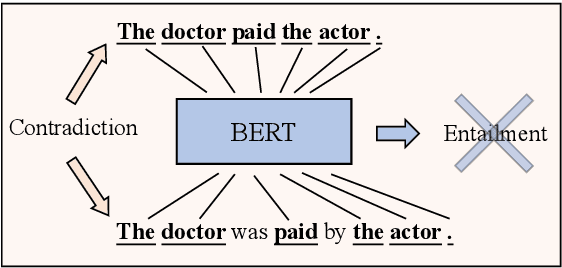
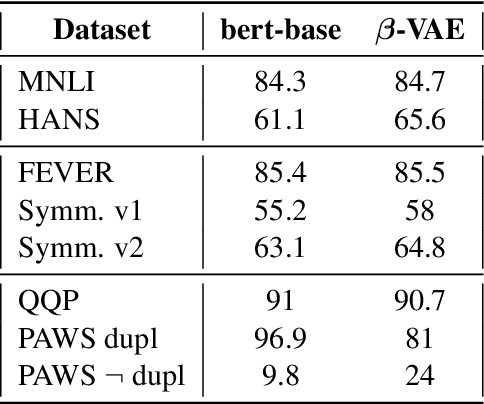
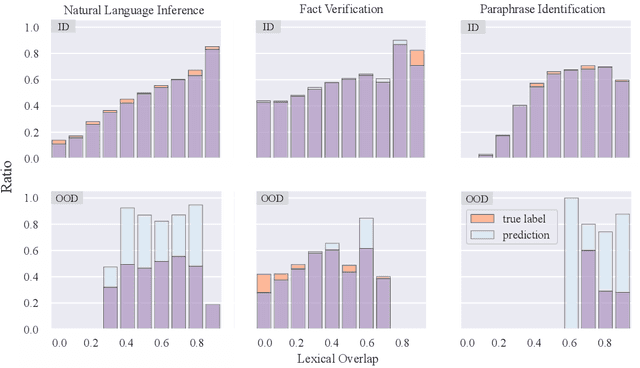
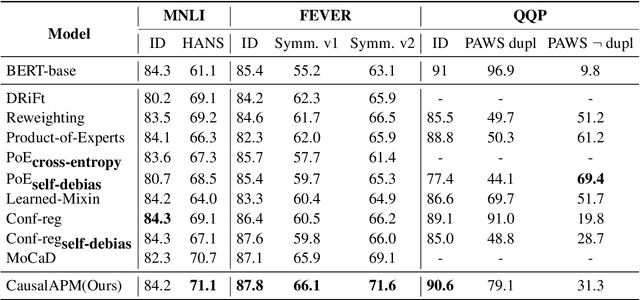
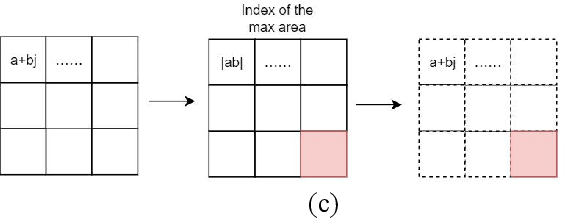
Dataset bias, i.e., the over-reliance on dataset-specific literal heuristics, is getting increasing attention for its detrimental effect on the generalization ability of NLU models. Existing works focus on eliminating dataset bias by down-weighting problematic data in the training process, which induce the omission of valid feature information while mitigating bias. In this work, We analyze the causes of dataset bias from the perspective of causal inference and propose CausalAPM, a generalizable literal disentangling framework to ameliorate the bias problem from feature granularity. The proposed approach projects literal and semantic information into independent feature subspaces, and constrains the involvement of literal information in subsequent predictions. Extensive experiments on three NLP benchmarks (MNLI, FEVER, and QQP) demonstrate that our proposed framework significantly improves the OOD generalization performance while maintaining ID performance.
Optimal Preconditioning and Fisher Adaptive Langevin Sampling
May 23, 2023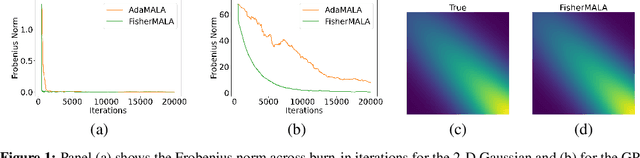
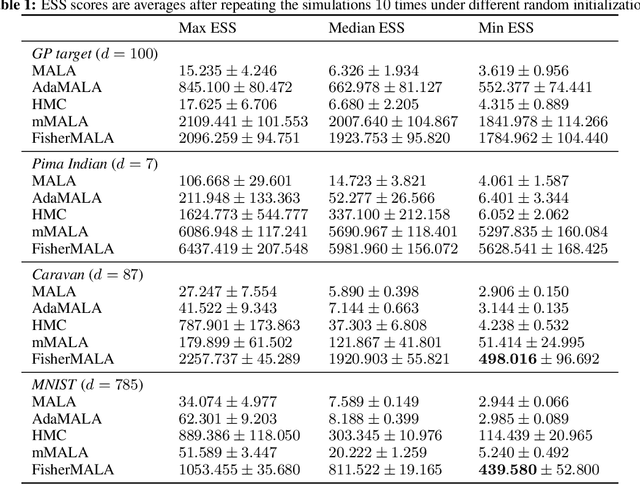
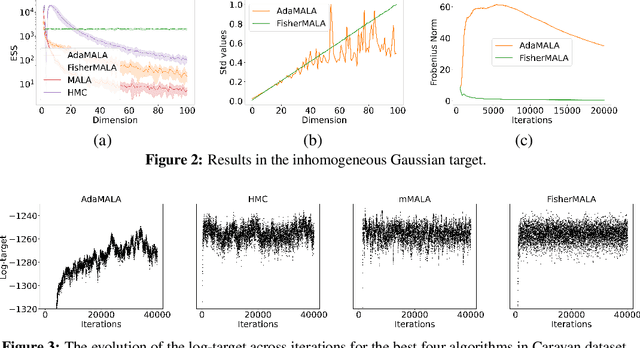
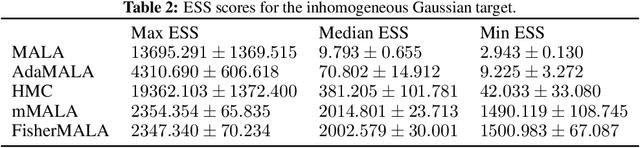
We define an optimal preconditioning for the Langevin diffusion by analytically maximizing the expected squared jumped distance. This yields as the optimal preconditioning an inverse Fisher information covariance matrix, where the covariance matrix is computed as the outer product of log target gradients averaged under the target. We apply this result to the Metropolis adjusted Langevin algorithm (MALA) and derive a computationally efficient adaptive MCMC scheme that learns the preconditioning from the history of gradients produced as the algorithm runs. We show in several experiments that the proposed algorithm is very robust in high dimensions and significantly outperforms other methods, including a closely related adaptive MALA scheme that learns the preconditioning with standard adaptive MCMC as well as the position-dependent Riemannian manifold MALA sampler.
Semantic-aware Transmission Scheduling: a Monotonicity-driven Deep Reinforcement Learning Approach
May 23, 2023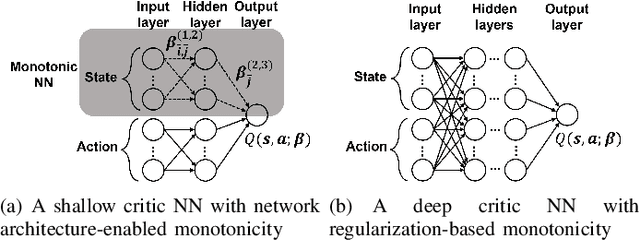
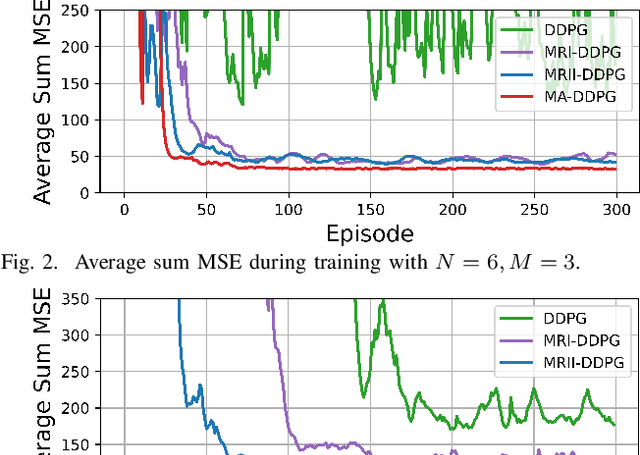
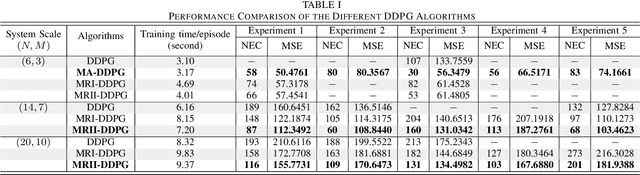
For cyber-physical systems in the 6G era, semantic communications connecting distributed devices for dynamic control and remote state estimation are required to guarantee application-level performance, not merely focus on communication-centric performance. Semantics here is a measure of the usefulness of information transmissions. Semantic-aware transmission scheduling of a large system often involves a large decision-making space, and the optimal policy cannot be obtained by existing algorithms effectively. In this paper, we first investigate the fundamental properties of the optimal semantic-aware scheduling policy and then develop advanced deep reinforcement learning (DRL) algorithms by leveraging the theoretical guidelines. Our numerical results show that the proposed algorithms can substantially reduce training time and enhance training performance compared to benchmark algorithms.