 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lexical Retrieval Hypothesis in Multimodal Context
May 28, 2023
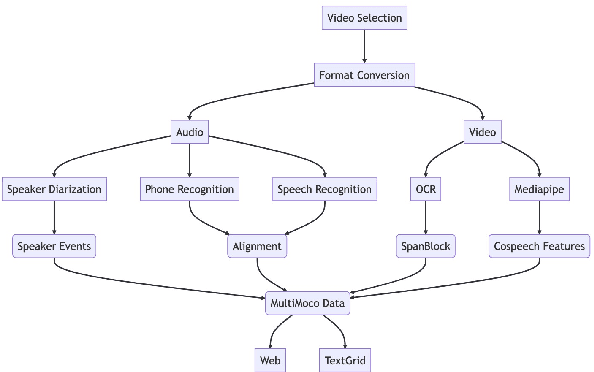
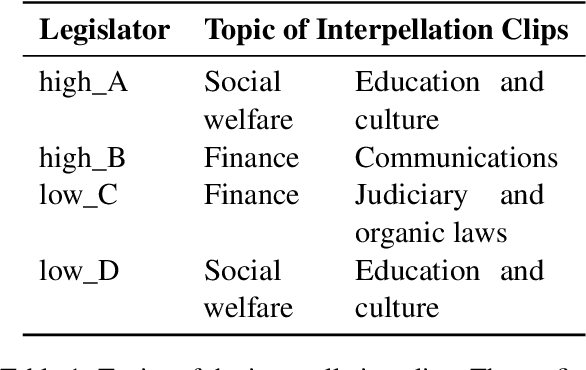
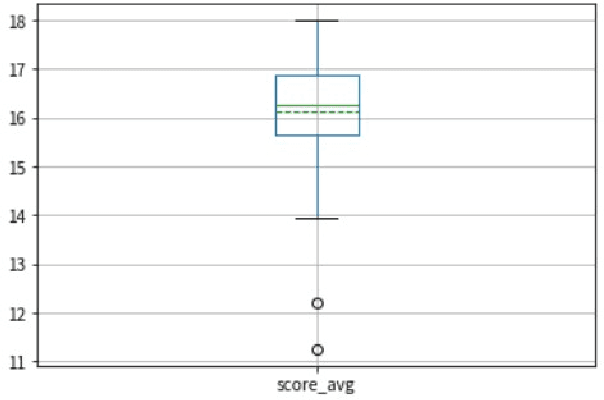
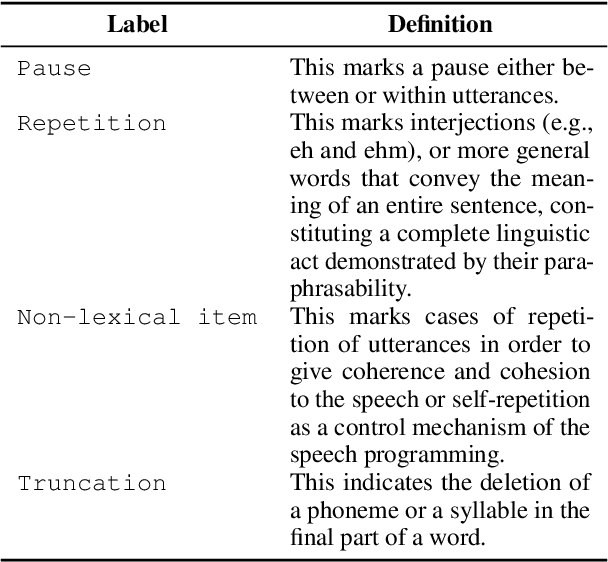
Multimodal corpora have become an essential language resource for language science and grounded natural language processing (NLP) systems due to the growing need to understand and interpret human communication across various channels. In this paper, we first present our efforts in building the first Multimodal Corpus for Languages in Taiwan (MultiMoco). Based on the corpus, we conduct a case study investigating the Lexical Retrieval Hypothesis (LRH), specifically examining whether the hand gestures co-occurring with speech constants facilitate lexical retrieval or serve other discourse functions. With detailed annotations on eight parliamentary interpellations in Taiwan Mandarin, we explore the co-occurrence between speech constants and non-verbal features (i.e., head movement, face movement, hand gesture, and function of hand gesture). Our findings suggest that while hand gestures do serve as facilitators for lexical retrieval in some cases, they also serve the purpose of information emphasis. This study highlights the potential of the MultiMoco Corpus to provide an important resource for in-depth analysis and further research in multimodal communication studies.
Spherical acquisition trajectories for X-ray computed tomography with a robotic sample holder
May 28, 2023
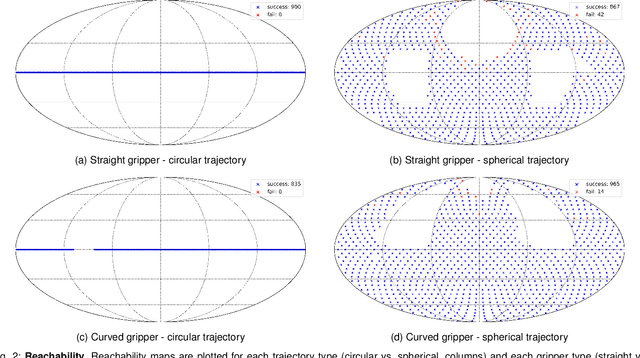
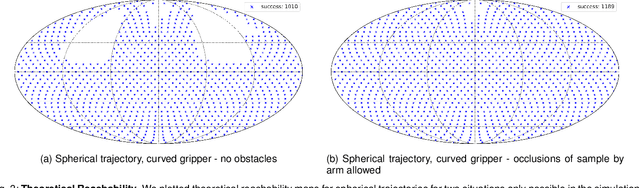

This work presents methods for the seamless execution of arbitrary spherical trajectories with a seven-degree-of-freedom robotic arm as a sample holder. The sample holder is integrated into an existing X-ray computed tomography setup. We optimized the path planning and robot control algorithms for the seamless execution of spherical trajectories. A precision-manufactured sample holder part is attached to the robotic arm for the calibration procedure. Different designs of this part are tested and compared to each other for optimal coverage of trajectories and reconstruction image quality. We present experimental results with the robotic sample holder where a sample measurement on a spherical trajectory achieves improved reconstruction quality compared to a conventional circular trajectory. Our results demonstrate the superiority of the discussed system as it outperforms single-axis systems by reaching nearly 82\% of all possible rotations. The proposed system is a step towards higher image reconstruction quality in flexible X-ray CT systems. It will enable reduced scan times and radiation dose exposure with task-specific trajectories in the future, as it can capture information from various sample angles.
Towards Understanding and Improving Knowledge Distillation for Neural Machine Translation
May 14, 2023

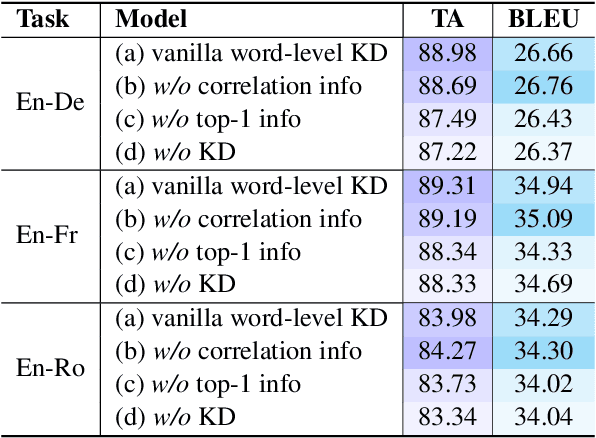
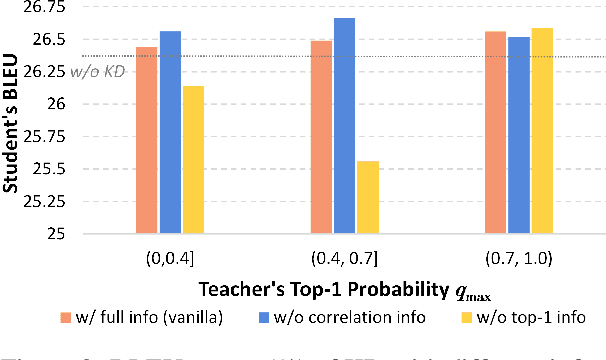
Knowledge distillation (KD) is a promising technique for model compression in neural machine translation. However, where the knowledge hides in KD is still not clear, which may hinder the development of KD. In this work, we first unravel this mystery from an empirical perspective and show that the knowledge comes from the top-1 predictions of teachers, which also helps us build a potential connection between word- and sequence-level KD. Further, we point out two inherent issues in vanilla word-level KD based on this finding. Firstly, the current objective of KD spreads its focus to whole distributions to learn the knowledge, yet lacks special treatment on the most crucial top-1 information. Secondly, the knowledge is largely covered by the golden information due to the fact that most top-1 predictions of teachers overlap with ground-truth tokens, which further restricts the potential of KD. To address these issues, we propose a novel method named \textbf{T}op-1 \textbf{I}nformation \textbf{E}nhanced \textbf{K}nowledge \textbf{D}istillation (TIE-KD). Specifically, we design a hierarchical ranking loss to enforce the learning of the top-1 information from the teacher. Additionally, we develop an iterative KD procedure to infuse more additional knowledge by distilling on the data without ground-truth targets. Experiments on WMT'14 English-German, WMT'14 English-French and WMT'16 English-Romanian demonstrate that our method can respectively boost Transformer$_{base}$ students by +1.04, +0.60 and +1.11 BLEU scores and significantly outperform the vanilla word-level KD baseline. Besides, our method shows higher generalizability on different teacher-student capacity gaps than existing KD techniques.
CHSEL: Producing Diverse Plausible Pose Estimates from Contact and Free Space Data
May 14, 2023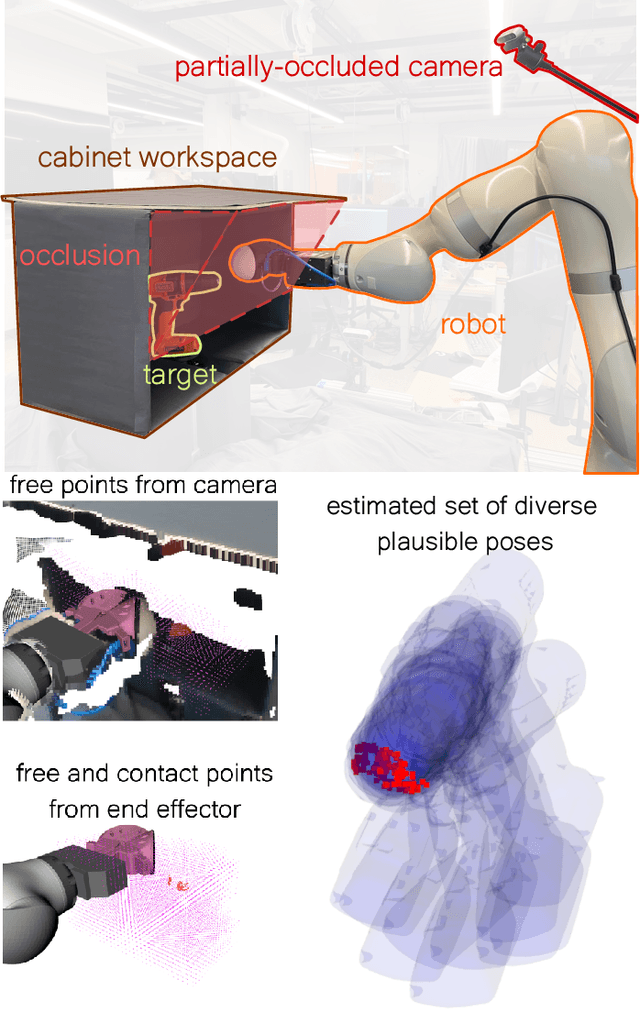
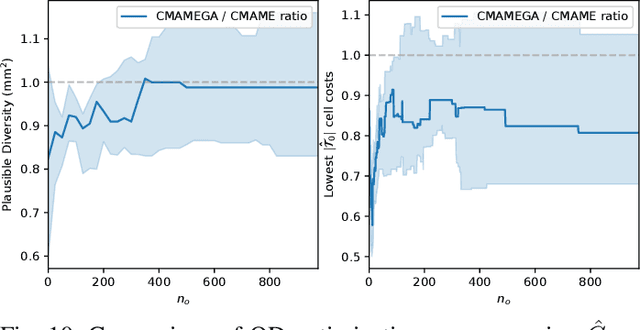
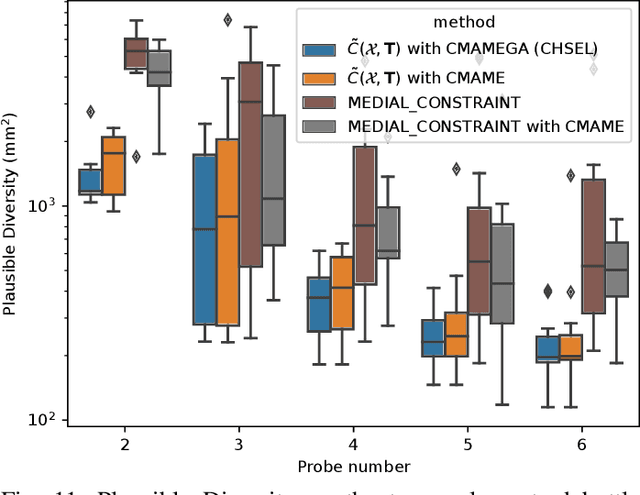
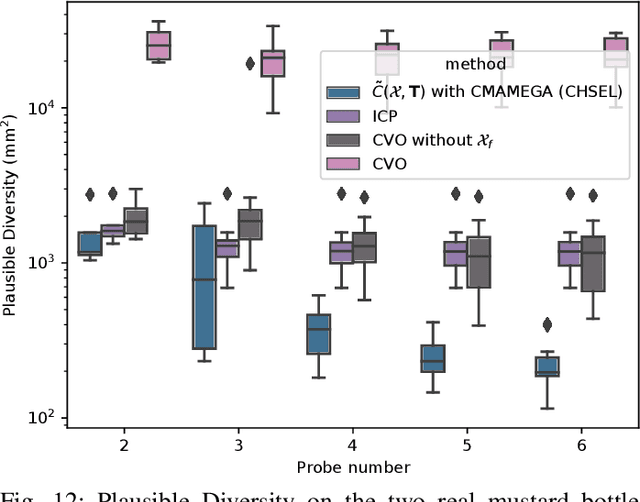
This paper proposes a novel method for estimating the set of plausible poses of a rigid object from a set of points with volumetric information, such as whether each point is in free space or on the surface of the object. In particular, we study how pose can be estimated from force and tactile data arising from contact. Using data derived from contact is challenging because it is inherently less information-dense than visual data, and thus the pose estimation problem is severely under-constrained when there are few contacts. Rather than attempting to estimate the true pose of the object, which is not tractable without a large number of contacts, we seek to estimate a plausible set of poses which obey the constraints imposed by the sensor data. Existing methods struggle to estimate this set because they are either designed for single pose estimates or require informative priors to be effective. Our approach to this problem, Constrained pose Hypothesis Set Elimination (CHSEL), has three key attributes: 1) It considers volumetric information, which allows us to account for known free space; 2) It uses a novel differentiable volumetric cost function to take advantage of powerful gradient-based optimization tools; and 3) It uses methods from the Quality Diversity (QD) optimization literature to produce a diverse set of high-quality poses. To our knowledge, QD methods have not been used previously for pose registration. We also show how to update our plausible pose estimates online as more data is gathered by the robot. Our experiments suggest that CHSEL shows large performance improvements over several baseline methods for both simulated and real-world data.
Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning
May 25, 2023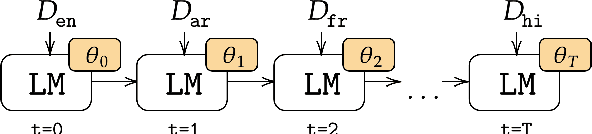
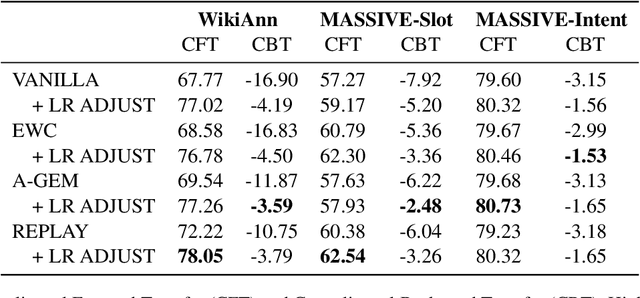
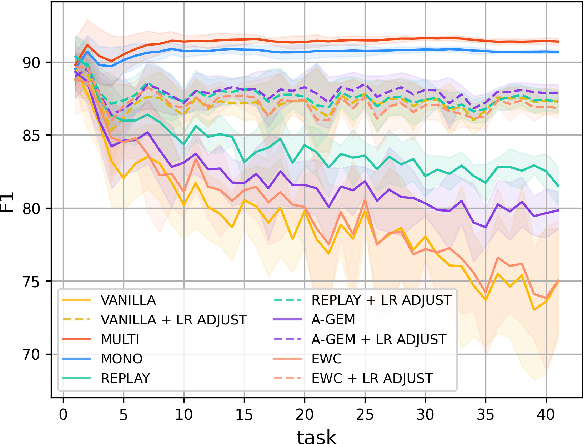
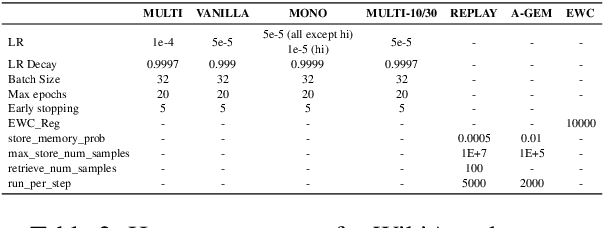
Real-life multilingual systems should be able to efficiently incorporate new languages as data distributions fed to the system evolve and shift over time. To do this, systems need to handle the issue of catastrophic forgetting, where the model performance drops for languages or tasks seen further in its past. In this paper, we study catastrophic forgetting, as well as methods to minimize this, in a massively multilingual continual learning framework involving up to 51 languages and covering both classification and sequence labeling tasks. We present LR ADJUST, a learning rate scheduling method that is simple, yet effective in preserving new information without strongly overwriting past knowledge. Furthermore, we show that this method is effective across multiple continual learning approaches. Finally, we provide further insights into the dynamics of catastrophic forgetting in this massively multilingual setup.
Linguistic More: Taking a Further Step toward Efficient and Accurate Scene Text Recognition
May 10, 2023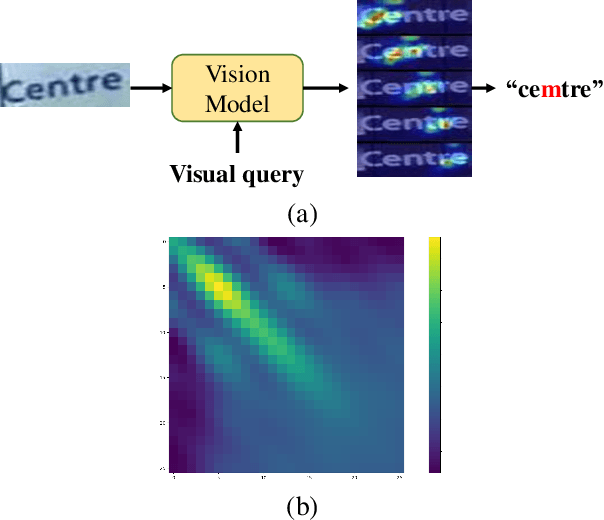
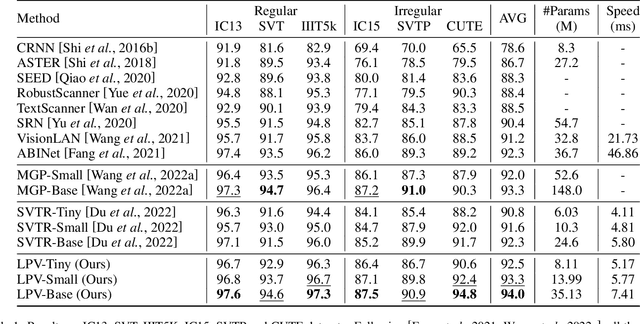
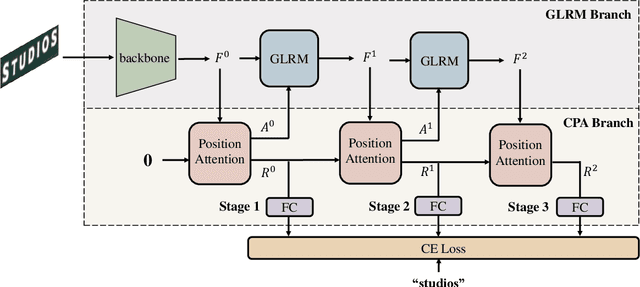
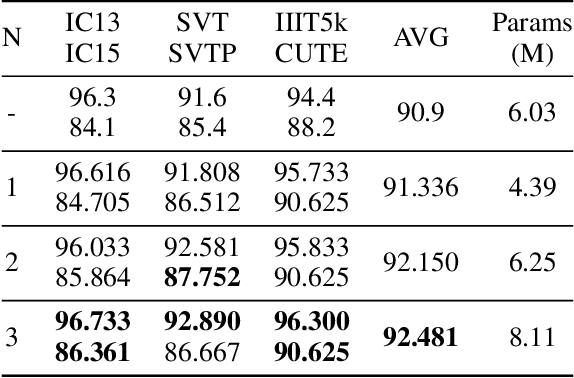
Vision model have gained increasing attention due to their simplicity and efficiency in Scene Text Recognition (STR) task. However, due to lacking the perception of linguistic knowledge and information, recent vision models suffer from two problems: (1) the pure vision-based query results in attention drift, which usually causes poor recognition and is summarized as linguistic insensitive drift (LID) problem in this paper. (2) the visual feature is suboptimal for the recognition in some vision-missing cases (e.g. occlusion, etc.). To address these issues, we propose a $\textbf{L}$inguistic $\textbf{P}$erception $\textbf{V}$ision model (LPV), which explores the linguistic capability of vision model for accurate text recognition. To alleviate the LID problem, we introduce a Cascade Position Attention (CPA) mechanism that obtains high-quality and accurate attention maps through step-wise optimization and linguistic information mining. Furthermore, a Global Linguistic Reconstruction Module (GLRM) is proposed to improve the representation of visual features by perceiving the linguistic information in the visual space, which gradually converts visual features into semantically rich ones during the cascade process. Different from previous methods, our method obtains SOTA results while keeping low complexity (92.4% accuracy with only 8.11M parameters). Code is available at https://github.com/CyrilSterling/LPV.
Heterogeneous Directed Hypergraph Neural Network over abstract syntax tree (AST) for Code Classification
May 10, 2023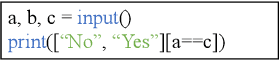
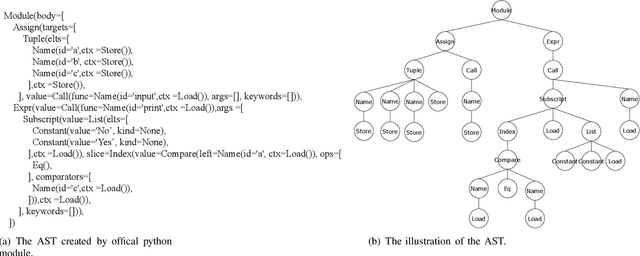
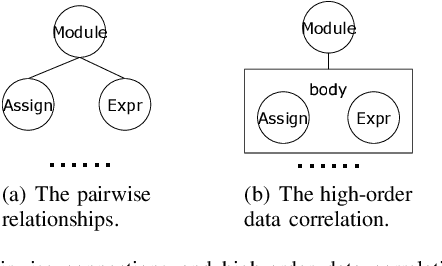
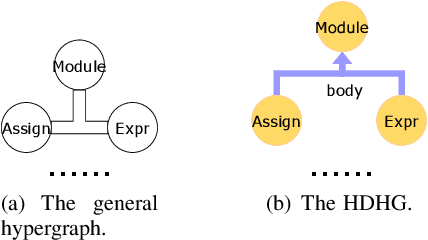
Code classification is a difficult issue in program understanding and automatic coding. Due to the elusive syntax and complicated semantics in programs, most existing studies use techniques based on abstract syntax tree (AST) and graph neural network (GNN) to create code representations for code classification. These techniques utilize the structure and semantic information of the code, but they only take into account pairwise associations and neglect the high-order correlations that already exist between nodes in the AST, which may result in the loss of code structural information. On the other hand, while a general hypergraph can encode high-order data correlations, it is homogeneous and undirected which will result in a lack of semantic and structural information such as node types, edge types, and directions between child nodes and parent nodes when modeling AST. In this study, we propose to represent AST as a heterogeneous directed hypergraph (HDHG) and process the graph by heterogeneous directed hypergraph neural network (HDHGN) for code classification. Our method improves code understanding and can represent high-order data correlations beyond paired interactions. We assess heterogeneous directed hypergraph neural network (HDHGN) on public datasets of Python and Java programs. Our method outperforms previous AST-based and GNN-based methods, which demonstrates the capability of our model.
Joint Channel Estimation and Turbo Equalization of Single-Carrier Systems over Time-Varying Channels
May 16, 2023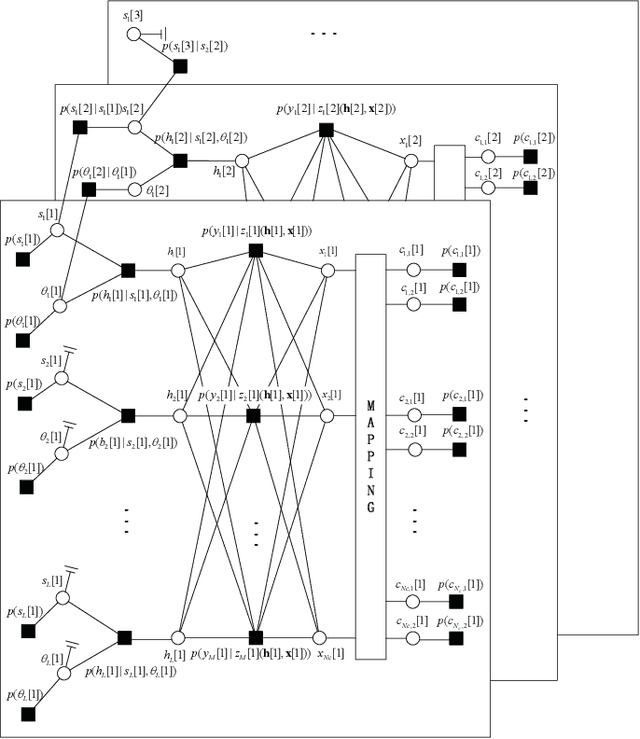
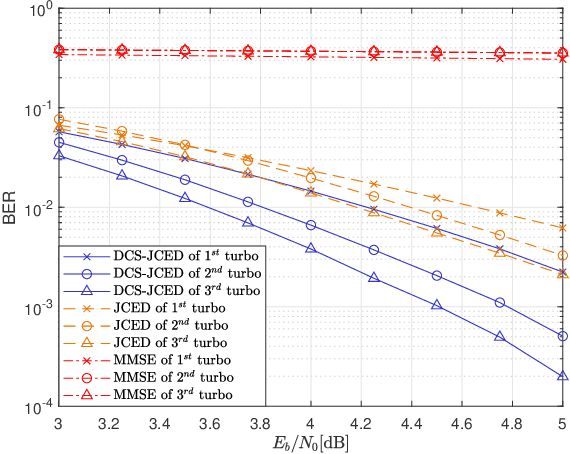
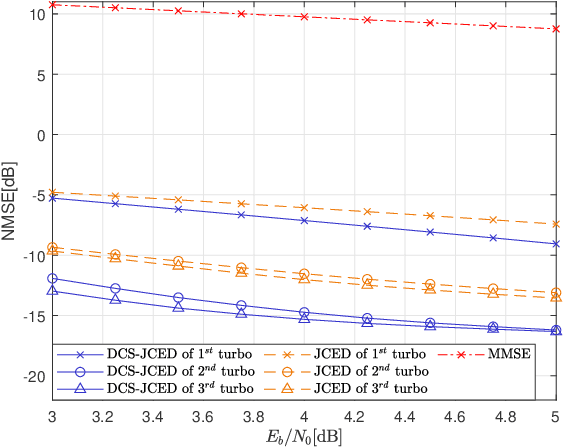
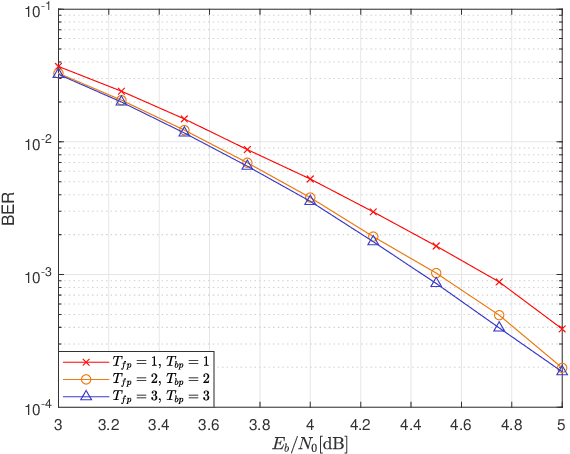
Block transmission systems have been proven successful over frequency-selective channels. For time-varying channel such as in high-speed mobile communication and underwater communication, existing equalizers assume that channels over different data frames are independent. However, the real-world channels over different data frames are correlated, thereby indicating potentials for performance improvement. In this paper, we propose a joint channel estimation and equalization/decoding algorithm for a single-carrier system that exploits temporal correlations of channel between transmitted data frames. Leveraging the concept of dynamic compressive sensing, our method can utilize the information of several data frames to achieve better performance. The information not only passes between the channel and symbol, but also the channels over different data frames. Numerical simulations using an extensively validated underwater acoustic model with a time-varying channel establish that the proposed algorithm outperforms the former bilinear generalized approximate message passing equalizer and classic minimum mean square error turbo equalizer in bit error rate and channel estimation normalized mean square error. The algorithm idea we present can also find applications in other bilinear multiple measurements vector compressive sensing problems.
BundleRecon: Ray Bundle-Based 3D Neural Reconstruction
May 12, 2023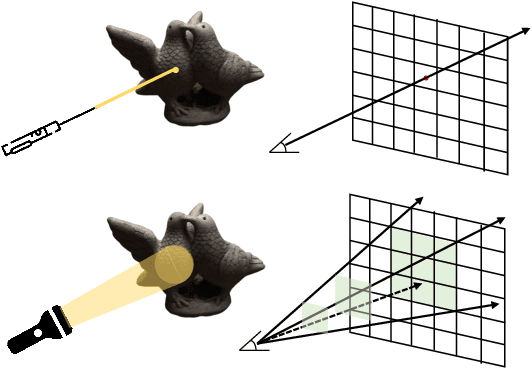
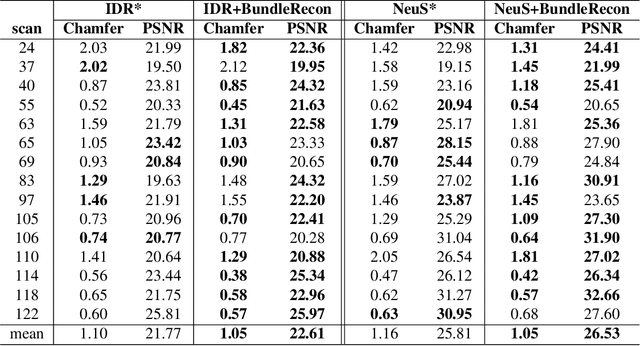
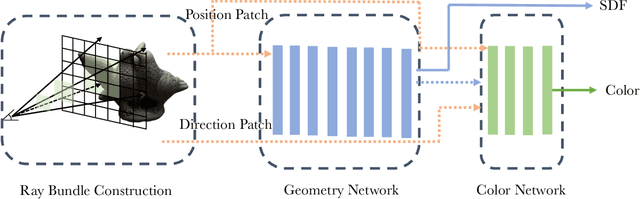
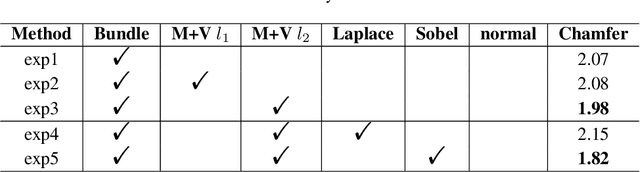
With the growing popularity of neural rendering, there has been an increasing number of neural implicit multi-view reconstruction methods. While many models have been enhanced in terms of positional encoding, sampling, rendering, and other aspects to improve the reconstruction quality, current methods do not fully leverage the information among neighboring pixels during the reconstruction process. To address this issue, we propose an enhanced model called BundleRecon. In the existing approaches, sampling is performed by a single ray that corresponds to a single pixel. In contrast, our model samples a patch of pixels using a bundle of rays, which incorporates information from neighboring pixels. Furthermore, we design bundle-based constraints to further improve the reconstruction quality. Experimental results demonstrate that BundleRecon is compatible with the existing neural implicit multi-view reconstruction methods and can improve their reconstruction quality.
Proposal-Based Multiple Instance Learning for Weakly-Supervised Temporal Action Localization
May 29, 2023
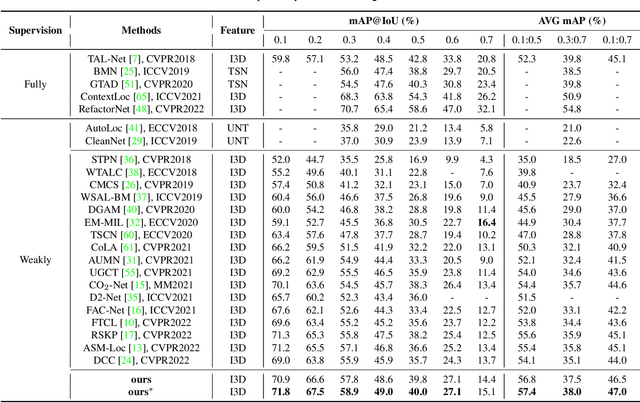
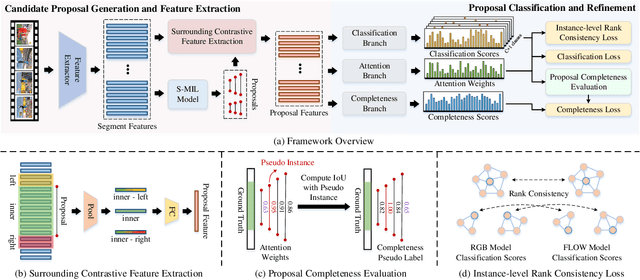

Weakly-supervised temporal action localization aims to localize and recognize actions in untrimmed videos with only video-level category labels during training. Without instance-level annotations, most existing methods follow the Segment-based Multiple Instance Learning (S-MIL) framework, where the predictions of segments are supervised by the labels of videos. However, the objective for acquiring segment-level scores during training is not consistent with the target for acquiring proposal-level scores during testing, leading to suboptimal results. To deal with this problem, we propose a novel Proposal-based Multiple Instance Learning (P-MIL) framework that directly classifies the candidate proposals in both the training and testing stages, which includes three key designs: 1) a surrounding contrastive feature extraction module to suppress the discriminative short proposals by considering the surrounding contrastive information, 2) a proposal completeness evaluation module to inhibit the low-quality proposals with the guidance of the completeness pseudo labels, and 3) an instance-level rank consistency loss to achieve robust detection by leveraging the complementarity of RGB and FLOW modalities. Extensive experimental results on two challenging benchmarks including THUMOS14 and ActivityNet demonstrate the superior performance of our method.