 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transfer learning for atomistic simulations using GNNs and kernel mean embeddings
Jun 02, 2023
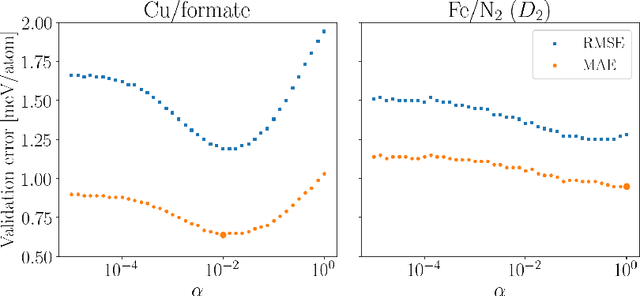
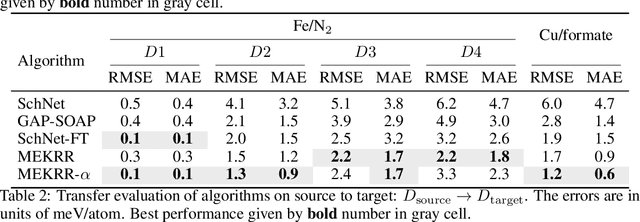
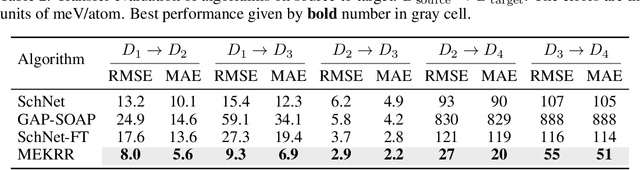
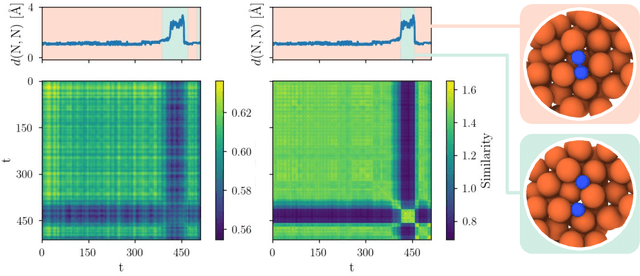
Interatomic potentials learned using machine learning methods have been successfully applied to atomistic simulations. However, deep learning pipelines are notoriously data-hungry, while generating reference calculations is computationally demanding. To overcome this difficulty, we propose a transfer learning algorithm that leverages the ability of graph neural networks (GNNs) in describing chemical environments, together with kernel mean embeddings. We extract a feature map from GNNs pre-trained on the OC20 dataset and use it to learn the potential energy surface from system-specific datasets of catalytic processes. Our method is further enhanced by a flexible kernel function that incorporates chemical species information, resulting in improved performance and interpretability. We test our approach on a series of realistic datasets of increasing complexity, showing excellent generalization and transferability performance, and improving on methods that rely on GNNs or ridge regression alone, as well as similar fine-tuning approaches. We make the code available to the community at https://github.com/IsakFalk/atomistic_transfer_mekrr.
Comparing a composite model versus chained models to locate a nearest visual object
Jun 02, 2023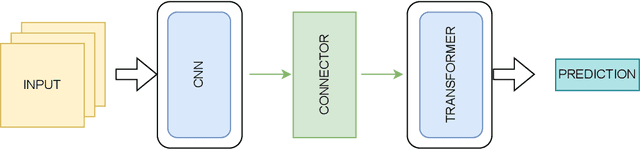

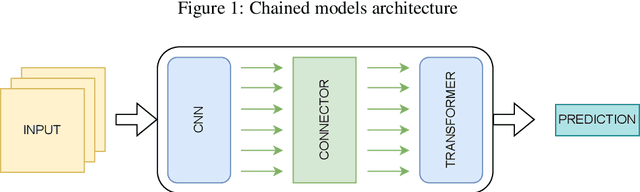
Extracting information from geographic images and text is crucial for autonomous vehicles to determine in advance the best cell stations to connect to along their future path. Multiple artificial neural network models can address this challenge; however, there is no definitive guidance on the selection of an appropriate model for such use cases. Therefore, we experimented two architectures to solve such a task: a first architecture with chained models where each model in the chain addresses a sub-task of the task; and a second architecture with a single model that addresses the whole task. Our results showed that these two architectures achieved the same level performance with a root mean square error (RMSE) of 0.055 and 0.056; The findings further revealed that when the task can be decomposed into sub-tasks, the chain architecture exhibits a twelve-fold increase in training speed compared to the composite model. Nevertheless, the composite model significantly alleviates the burden of data labeling.
Privacy Distillation: Reducing Re-identification Risk of Multimodal Diffusion Models
Jun 02, 2023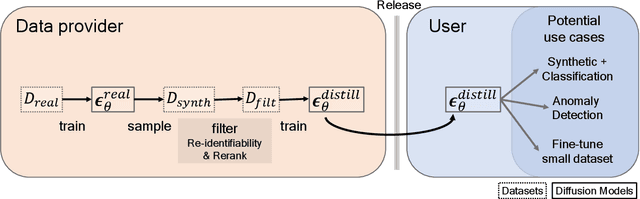


Knowledge distillation in neural networks refers to compressing a large model or dataset into a smaller version of itself. We introduce Privacy Distillation, a framework that allows a text-to-image generative model to teach another model without exposing it to identifiable data. Here, we are interested in the privacy issue faced by a data provider who wishes to share their data via a multimodal generative model. A question that immediately arises is ``How can a data provider ensure that the generative model is not leaking identifiable information about a patient?''. Our solution consists of (1) training a first diffusion model on real data (2) generating a synthetic dataset using this model and filtering it to exclude images with a re-identifiability risk (3) training a second diffusion model on the filtered synthetic data only. We showcase that datasets sampled from models trained with privacy distillation can effectively reduce re-identification risk whilst maintaining downstream performance.
Exploring Better Text Image Translation with Multimodal Codebook
Jun 02, 2023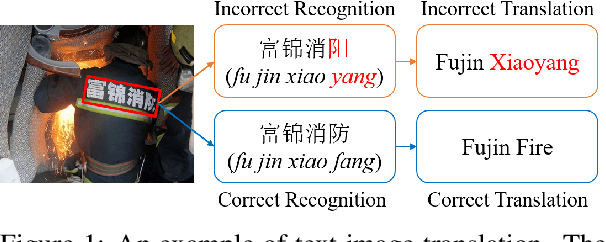
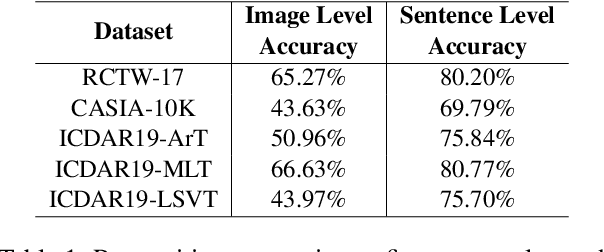
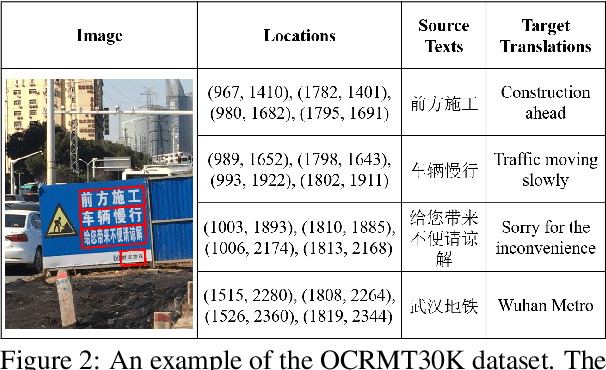
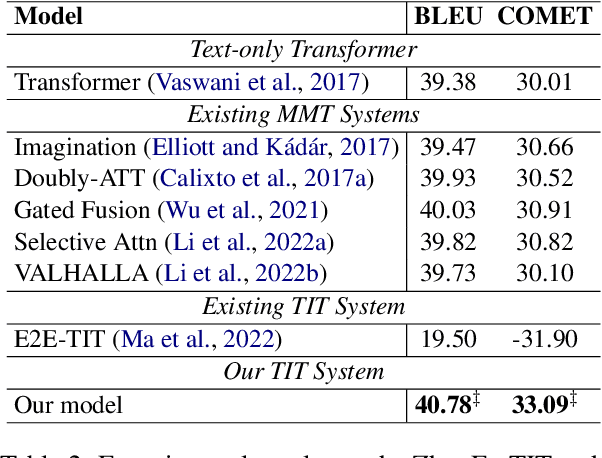
Text image translation (TIT) aims to translate the source texts embedded in the image to target translations, which has a wide range of applications and thus has important research value. However, current studies on TIT are confronted with two main bottlenecks: 1) this task lacks a publicly available TIT dataset, 2) dominant models are constructed in a cascaded manner, which tends to suffer from the error propagation of optical character recognition (OCR). In this work, we first annotate a Chinese-English TIT dataset named OCRMT30K, providing convenience for subsequent studies. Then, we propose a TIT model with a multimodal codebook, which is able to associate the image with relevant texts, providing useful supplementary information for translation. Moreover, we present a multi-stage training framework involving text machine translation, image-text alignment, and TIT tasks, which fully exploits additional bilingual texts, OCR dataset and our OCRMT30K dataset to train our model. Extensive experiments and in-depth analyses strongly demonstrate the effectiveness of our proposed model and training framework.
Predicting risk of delirium from ambient noise and light information in the ICU
Mar 11, 2023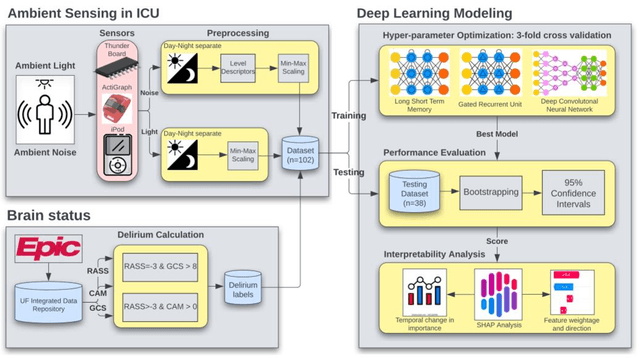
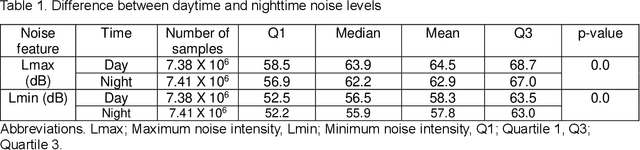
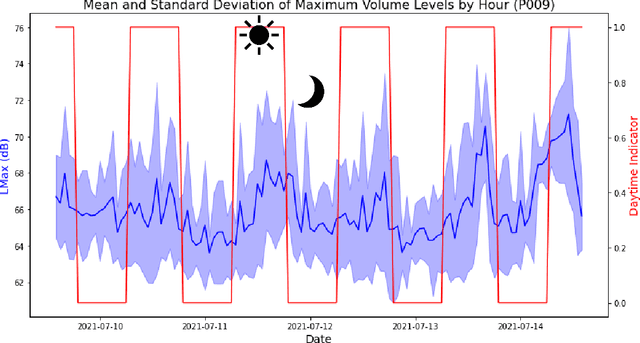
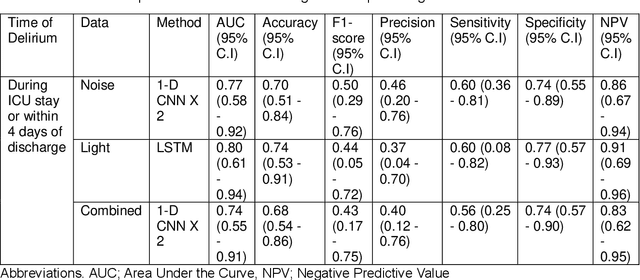
Existing Intensive Care Unit (ICU) delirium prediction models do not consider environmental factors despite strong evidence of their influence on delirium. This study reports the first deep-learning based delirium prediction model for ICU patients using only ambient noise and light information. Ambient light and noise intensities were measured from ICU rooms of 102 patients from May 2021 to September 2022 using Thunderboard, ActiGraph sensors and an iPod with AudioTools application. These measurements were divided into daytime (0700 to 1859) and nighttime (1900 to 0659). Deep learning models were trained using this data to predict the incidence of delirium during ICU stay or within 4 days of discharge. Finally, outcome scores were analyzed to evaluate the importance and directionality of every feature. Daytime noise levels were significantly higher than nighttime noise levels. When using only noise features or a combination of noise and light features 1-D convolutional neural networks (CNN) achieved the strongest performance: AUC=0.77, 0.74; Sensitivity=0.60, 0.56; Specificity=0.74, 0.74; Precision=0.46, 0.40 respectively. Using only light features, Long Short-Term Memory (LSTM) networks performed best: AUC=0.80, Sensitivity=0.60, Specificity=0.77, Precision=0.37. Maximum nighttime and minimum daytime noise levels were the strongest positive and negative predictors of delirium respectively. Nighttime light level was a stronger predictor of delirium than daytime light level. Total influence of light features outweighed that of noise features on the second and fourth day of ICU stay. This study shows that ambient light and noise intensities are strong predictors of long-term delirium incidence in the ICU. It reveals that daytime and nighttime environmental factors might influence delirium differently and that the importance of light and noise levels vary over the course of an ICU stay.
Probing reaction channels via reinforcement learning
May 27, 2023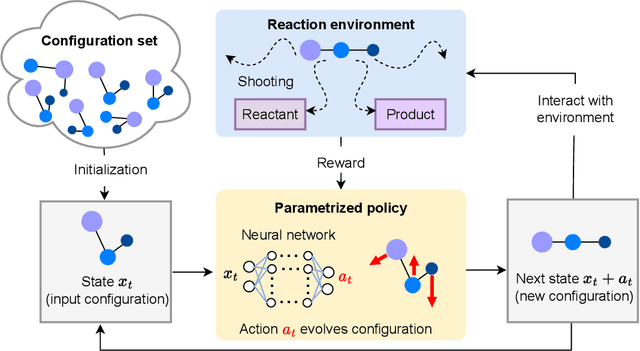


We propose a reinforcement learning based method to identify important configurations that connect reactant and product states along chemical reaction paths. By shooting multiple trajectories from these configurations, we can generate an ensemble of configurations that concentrate on the transition path ensemble. This configuration ensemble can be effectively employed in a neural network-based partial differential equation solver to obtain an approximation solution of a restricted Backward Kolmogorov equation, even when the dimension of the problem is very high. The resulting solution, known as the committor function, encodes mechanistic information for the reaction and can in turn be used to evaluate reaction rates.
Light-VQA: A Multi-Dimensional Quality Assessment Model for Low-Light Video Enhancement
May 16, 2023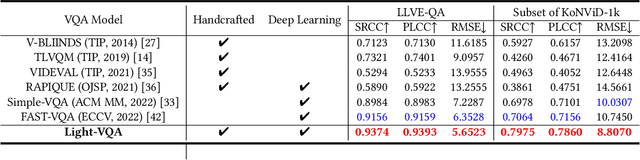
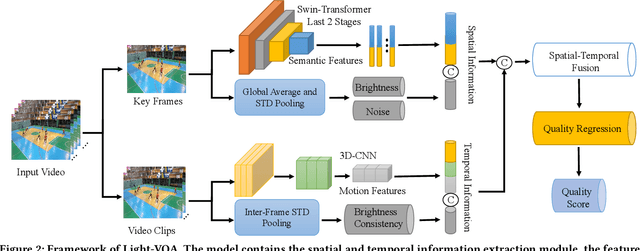

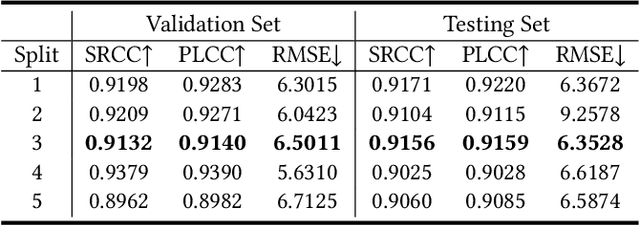
Recently, Users Generated Content (UGC) videos becomes ubiquitous in our daily lives. However, due to the limitations of photographic equipments and techniques, UGC videos often contain various degradations, in which one of the most visually unfavorable effects is the underexposure. Therefore, corresponding video enhancement algorithms such as Low-Light Video Enhancement (LLVE) have been proposed to deal with the specific degradation. However, different from video enhancement algorithms, almost all existing Video Quality Assessment (VQA) models are built generally rather than specifically, which measure the quality of a video from a comprehensive perspective. To the best of our knowledge, there is no VQA model specially designed for videos enhanced by LLVE algorithms. To this end, we first construct a Low-Light Video Enhancement Quality Assessment (LLVE-QA) dataset in which 254 original low-light videos are collected and then enhanced by leveraging 8 LLVE algorithms to obtain 2,060 videos in total. Moreover, we propose a quality assessment model specialized in LLVE, named Light-VQA. More concretely, since the brightness and noise have the most impact on low-light enhanced VQA, we handcraft corresponding features and integrate them with deep-learning-based semantic features as the overall spatial information. As for temporal information, in addition to deep-learning-based motion features, we also investigate the handcrafted brightness consistency among video frames, and the overall temporal information is their concatenation. Subsequently, spatial and temporal information is fused to obtain the quality-aware representation of a video. Extensive experimental results show that our Light-VQA achieves the best performance against the current State-Of-The-Art (SOTA) on LLVE-QA and public dataset. Dataset and Codes can be found at https://github.com/wenzhouyidu/Light-VQA.
End-to-end Knowledge Retrieval with Multi-modal Queries
Jun 01, 2023

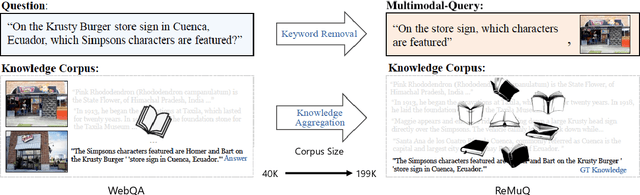
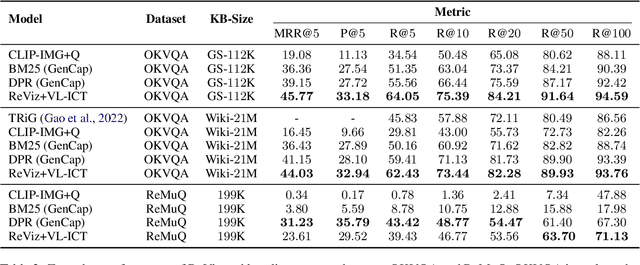
We investigate knowledge retrieval with multi-modal queries, i.e. queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. We curate a new dataset called ReMuQ for benchmarking progress on this task. ReMuQ requires a system to retrieve knowledge from a large corpus by integrating contents from both text and image queries. We introduce a retriever model ``ReViz'' that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators. We introduce a new pretraining task that is effective for learning knowledge retrieval with multimodal queries and also improves performance on downstream tasks. We demonstrate superior performance in retrieval on two datasets (ReMuQ and OK-VQA) under zero-shot settings as well as further improvements when finetuned on these datasets.
Overcoming Language Bias in Remote Sensing Visual Question Answering via Adversarial Training
Jun 01, 2023
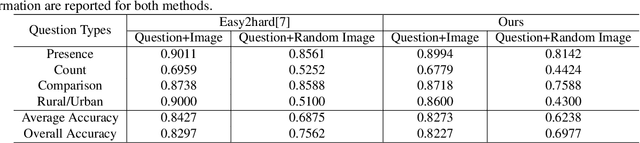
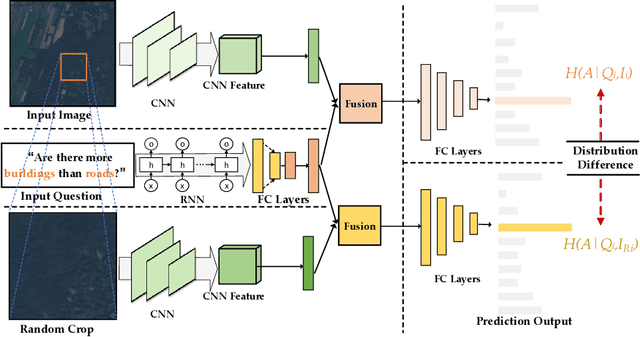
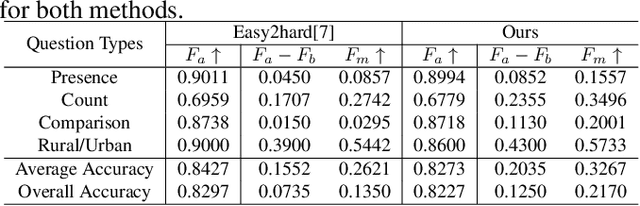
The Visual Question Answering (VQA) system offers a user-friendly interface and enables human-computer interaction. However, VQA models commonly face the challenge of language bias, resulting from the learned superficial correlation between questions and answers. To address this issue, in this study, we present a novel framework to reduce the language bias of the VQA for remote sensing data (RSVQA). Specifically, we add an adversarial branch to the original VQA framework. Based on the adversarial branch, we introduce two regularizers to constrain the training process against language bias. Furthermore, to evaluate the performance in terms of language bias, we propose a new metric that combines standard accuracy with the performance drop when incorporating question and random image information. Experimental results demonstrate the effectiveness of our method. We believe that our method can shed light on future work for reducing language bias on the RSVQA task.
Learning When to Speak: Latency and Quality Trade-offs for Simultaneous Speech-to-Speech Translation with Offline Models
Jun 01, 2023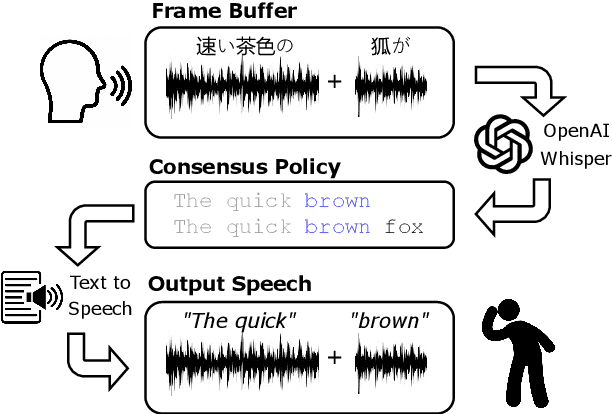
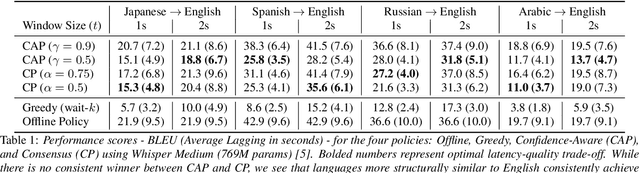
Recent work in speech-to-speech translation (S2ST) has focused primarily on offline settings, where the full input utterance is available before any output is given. This, however, is not reasonable in many real-world scenarios. In latency-sensitive applications, rather than waiting for the full utterance, translations should be spoken as soon as the information in the input is present. In this work, we introduce a system for simultaneous S2ST targeting real-world use cases. Our system supports translation from 57 languages to English with tunable parameters for dynamically adjusting the latency of the output -- including four policies for determining when to speak an output sequence. We show that these policies achieve offline-level accuracy with minimal increases in latency over a Greedy (wait-$k$) baseline. We open-source our evaluation code and interactive test script to aid future SimulS2ST research and application development.