 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Physics-informed UNets for Discovering Hidden Elasticity in Heterogeneous Materials
Jun 07, 2023
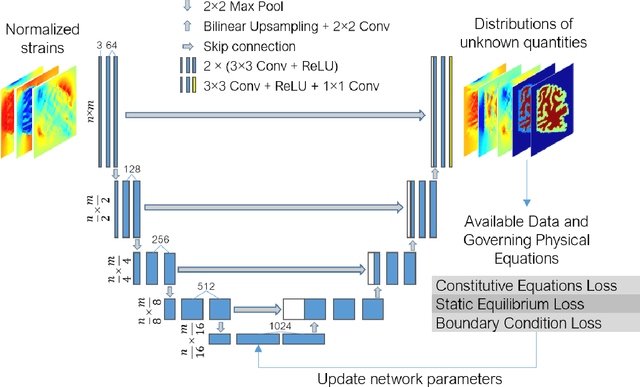
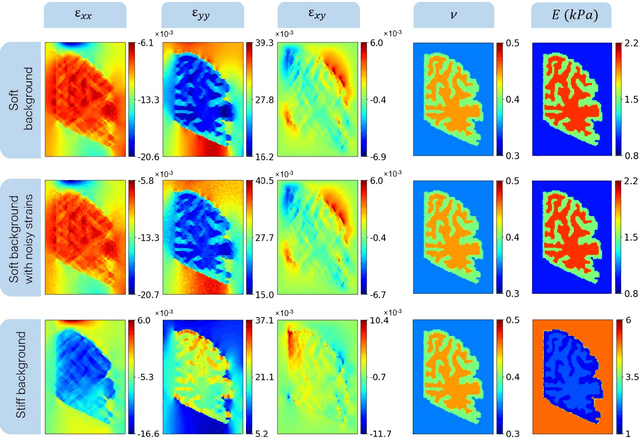
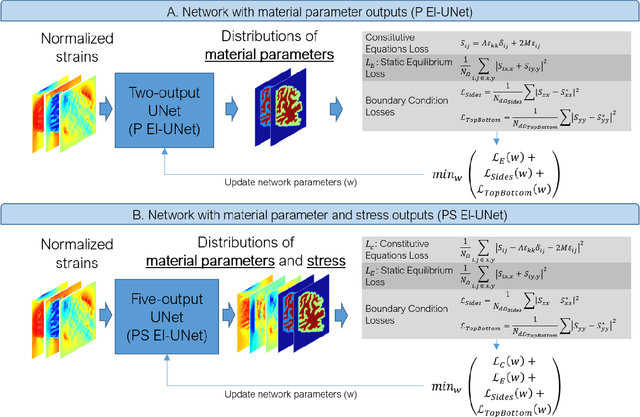
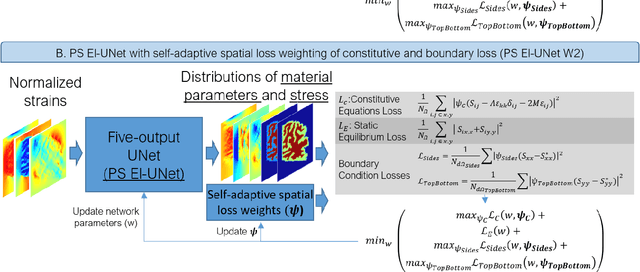
Soft biological tissues often have complex mechanical properties due to variation in structural components. In this paper, we develop a novel UNet-based neural network model for inversion in elasticity (El-UNet) to infer the spatial distributions of mechanical parameters from strain maps as input images, normal stress boundary conditions, and domain physics information. We show superior performance, both in terms of accuracy and computational cost, by El-UNet compared to fully-connected physics-informed neural networks in estimating unknown parameters and stress distributions for isotropic linear elasticity. We characterize different variations of El-UNet and propose a self-adaptive spatial loss weighting approach. To validate our inversion models, we performed various finite-element simulations of isotropic domains with heterogenous distributions of material parameters to generate synthetic data. El-UNet is faster and more accurate than the fully-connected physics-informed implementation in resolving the distribution of unknown fields. Among the tested models, the self-adaptive spatially weighted models had the most accurate reconstructions in equal computation times. The learned spatial weighting distribution visibly corresponded to regions that the unweighted models were resolving inaccurately. Our work demonstrates a computationally efficient inversion algorithm for elasticity imaging using convolutional neural networks and presents a potential fast framework for three-dimensional inverse elasticity problems that have proven unachievable through previously proposed methods.
Hardness of Deceptive Certificate Selection
Jun 07, 2023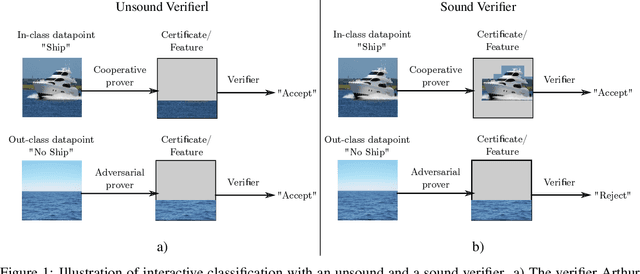
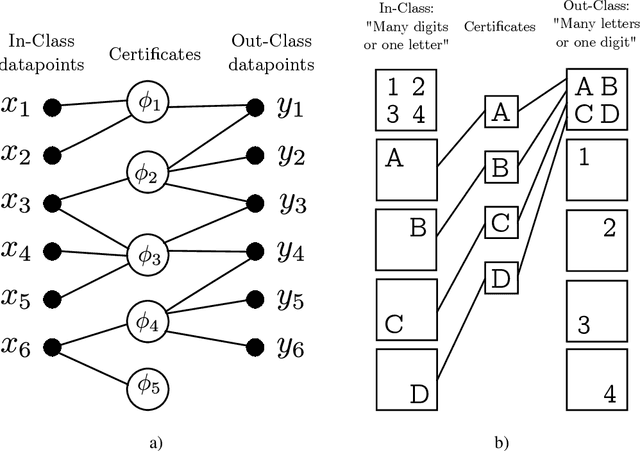
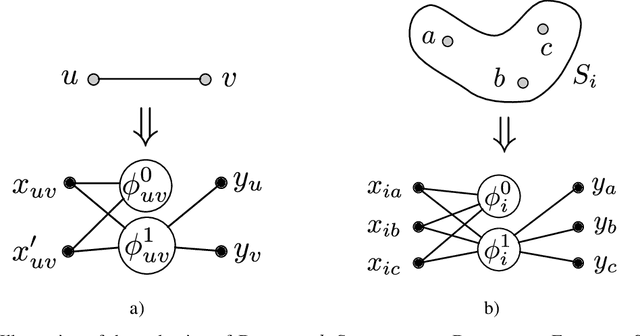
Recent progress towards theoretical interpretability guarantees for AI has been made with classifiers that are based on interactive proof systems. A prover selects a certificate from the datapoint and sends it to a verifier who decides the class. In the context of machine learning, such a certificate can be a feature that is informative of the class. For a setup with high soundness and completeness, the exchanged certificates must have a high mutual information with the true class of the datapoint. However, this guarantee relies on a bound on the Asymmetric Feature Correlation of the dataset, a property that so far is difficult to estimate for high-dimensional data. It was conjectured in W\"aldchen et al. that it is computationally hard to exploit the AFC, which is what we prove here. We consider a malicious prover-verifier duo that aims to exploit the AFC to achieve high completeness and soundness while using uninformative certificates. We show that this task is $\mathsf{NP}$-hard and cannot be approximated better than $\mathcal{O}(m^{1/8 - \epsilon})$, where $m$ is the number of possible certificates, for $\epsilon>0$ under the Dense-vs-Random conjecture. This is some evidence that AFC should not prevent the use of interactive classification for real-world tasks, as it is computationally hard to be exploited.
Extension of the Blackboard Architecture with Common Properties and Generic Rules
Jun 07, 2023
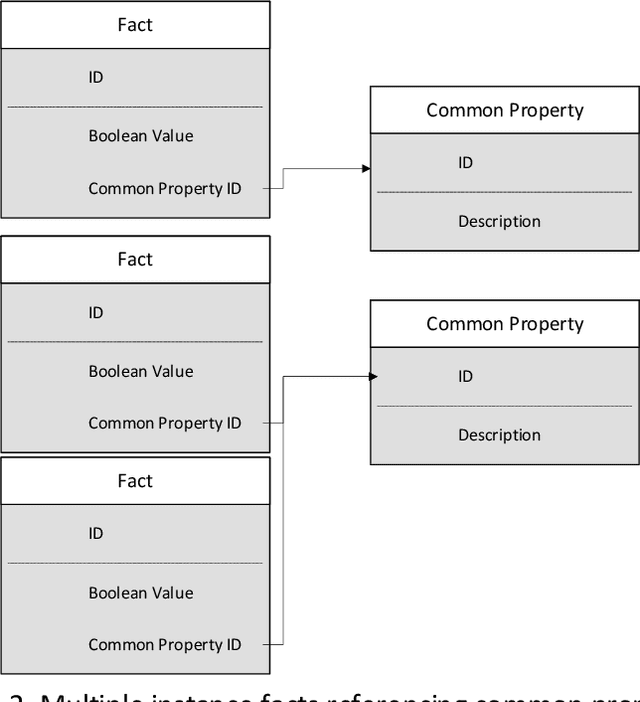
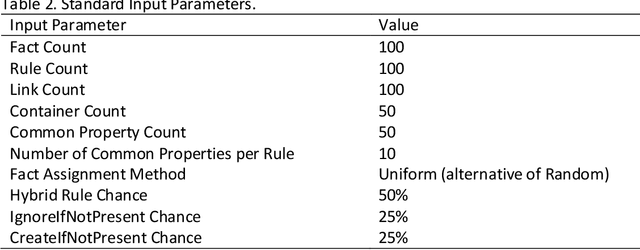
The Blackboard Architecture provides a mechanism for embodying data, decision making and actuation. Its versatility has been demonstrated across a wide number of application areas. However, it lacks the capability to directly model organizational, spatial and other relationships which may be useful in decision-making, in addition to the propositional logic embodied in the rule-fact-action network. Previous work has proposed the use of container objects and links as a mechanism to simultaneously model these organizational and other relationships, while leaving the operational logic modeled in the rules, facts and actions. While containers facilitate this modeling, their utility is limited by the need to manually define them. For systems which may have multiple instances of a particular type of object and which may build their network autonomously, based on sensing, the reuse of logical structures facilitates operations and reduces storage and processing needs. This paper, thus, presents and assesses two additional concepts to add to the Blackboard Architecture: common properties and generic rules. Common properties are facts associated with containers which are defined as representing the same information across the various objects that they are associated with. Generic rules provide logical propositions that use these generic rules across links and apply to any objects matching their definition. The potential uses of these two new concepts are discussed herein and their impact on system performance is characterized.
Improved Privacy-Preserving PCA Using Space-optimized Homomorphic Matrix Multiplication
Jun 07, 2023
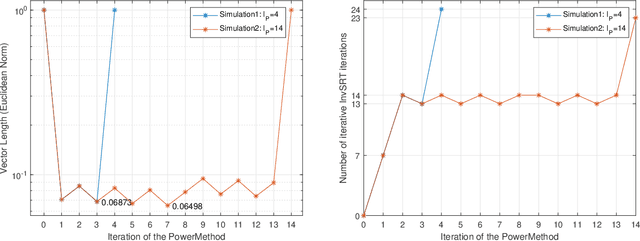

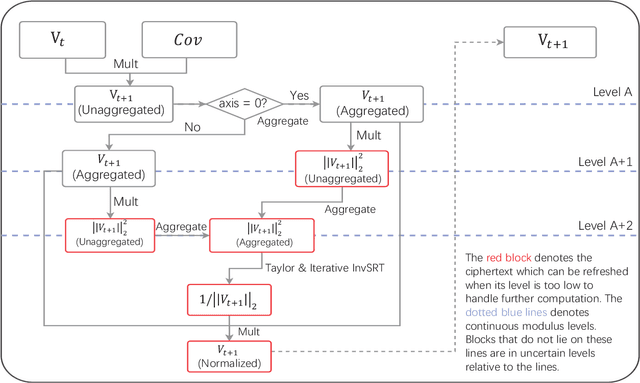
Principal Component Analysis (PCA) is a pivotal technique in the fields of machine learning and data analysis. It aims to reduce the dimensionality of a dataset while minimizing the loss of information. In recent years, there have been endeavors to utilize homomorphic encryption in privacy-preserving PCA algorithms. These approaches commonly employ a PCA routine known as PowerMethod, which takes the covariance matrix as input and generates an approximate eigenvector corresponding to the primary component of the dataset. However, their performance and accuracy are constrained by the incapability of homomorphic covariance matrix computation and the absence of a universal vector normalization strategy for the PowerMethod algorithm. In this study, we propose a novel approach to privacy-preserving PCA that addresses these limitations, resulting in superior efficiency, accuracy, and scalability compared to previous approaches. We attain such efficiency and precision through the following contributions: (i) We implement space optimization techniques for a homomorphic matrix multiplication method (Jiang et al., SIGSAC 2018), making it less prone to memory saturation in parallel computation scenarios. (ii) Leveraging the benefits of this optimized matrix multiplication, we devise an efficient homomorphic circuit for computing the covariance matrix homomorphically. (iii) Utilizing the covariance matrix, we develop a novel and efficient homomorphic circuit for the PowerMethod that incorporates a universal homomorphic vector normalization strategy to enhance both its accuracy and practicality.
Hybrid Graph: A Unified Graph Representation with Datasets and Benchmarks for Complex Graphs
Jun 08, 2023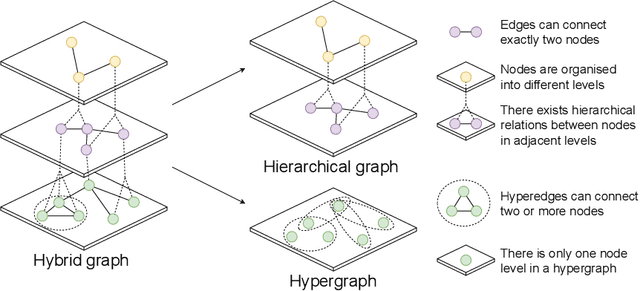
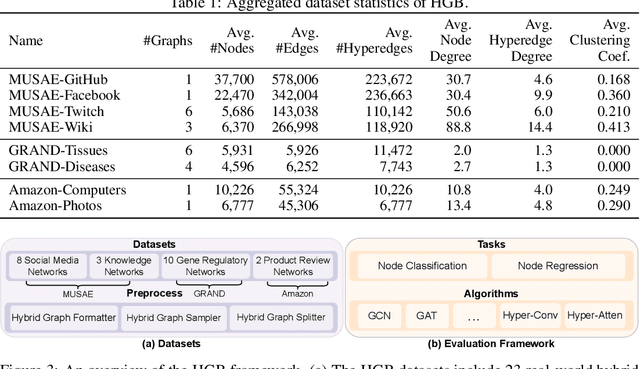
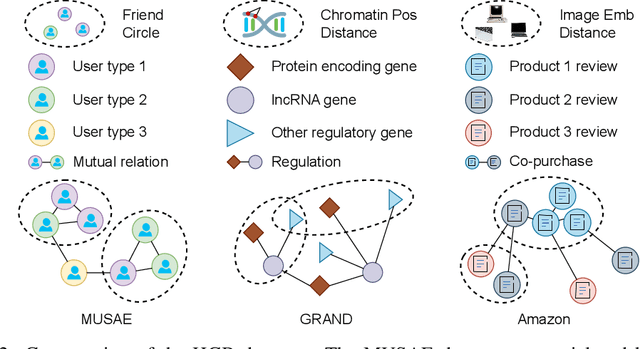
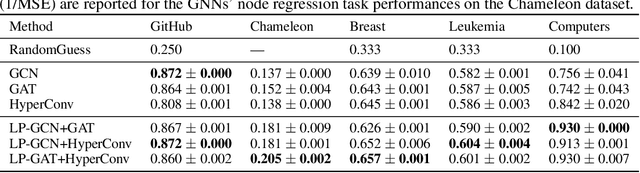
Graphs are widely used to encapsulate a variety of data formats, but real-world networks often involve complex node relations beyond only being pairwise. While hypergraphs and hierarchical graphs have been developed and employed to account for the complex node relations, they cannot fully represent these complexities in practice. Additionally, though many Graph Neural Networks (GNNs) have been proposed for representation learning on higher-order graphs, they are usually only evaluated on simple graph datasets. Therefore, there is a need for a unified modelling of higher-order graphs, and a collection of comprehensive datasets with an accessible evaluation framework to fully understand the performance of these algorithms on complex graphs. In this paper, we introduce the concept of hybrid graphs, a unified definition for higher-order graphs, and present the Hybrid Graph Benchmark (HGB). HGB contains 23 real-world hybrid graph datasets across various domains such as biology, social media, and e-commerce. Furthermore, we provide an extensible evaluation framework and a supporting codebase to facilitate the training and evaluation of GNNs on HGB. Our empirical study of existing GNNs on HGB reveals various research opportunities and gaps, including (1) evaluating the actual performance improvement of hypergraph GNNs over simple graph GNNs; (2) comparing the impact of different sampling strategies on hybrid graph learning methods; and (3) exploring ways to integrate simple graph and hypergraph information. We make our source code and full datasets publicly available at https://zehui127.github.io/hybrid-graph-benchmark/.
A Dynamic Feature Interaction Framework for Multi-task Visual Perception
Jun 08, 2023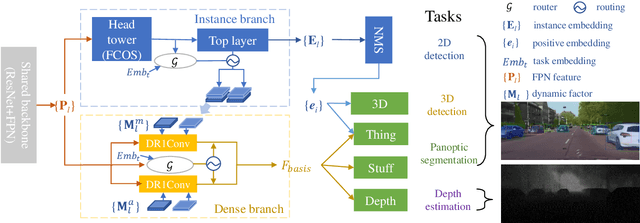
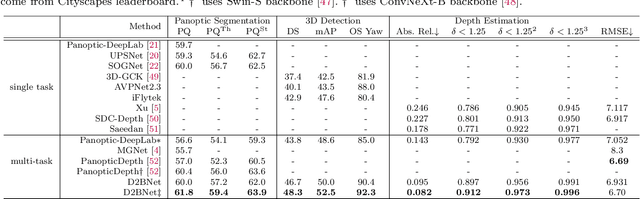
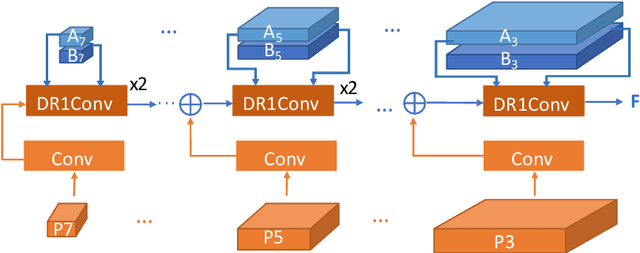
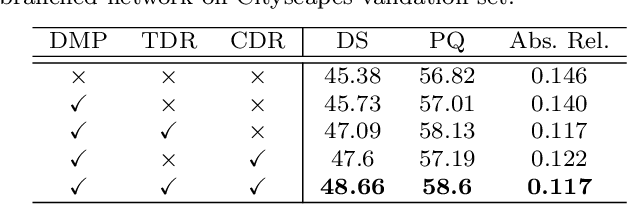
Multi-task visual perception has a wide range of applications in scene understanding such as autonomous driving. In this work, we devise an efficient unified framework to solve multiple common perception tasks, including instance segmentation, semantic segmentation, monocular 3D detection, and depth estimation. Simply sharing the same visual feature representations for these tasks impairs the performance of tasks, while independent task-specific feature extractors lead to parameter redundancy and latency. Thus, we design two feature-merge branches to learn feature basis, which can be useful to, and thus shared by, multiple perception tasks. Then, each task takes the corresponding feature basis as the input of the prediction task head to fulfill a specific task. In particular, one feature merge branch is designed for instance-level recognition the other for dense predictions. To enhance inter-branch communication, the instance branch passes pixel-wise spatial information of each instance to the dense branch using efficient dynamic convolution weighting. Moreover, a simple but effective dynamic routing mechanism is proposed to isolate task-specific features and leverage common properties among tasks. Our proposed framework, termed D2BNet, demonstrates a unique approach to parameter-efficient predictions for multi-task perception. In addition, as tasks benefit from co-training with each other, our solution achieves on par results on partially labeled settings on nuScenes and outperforms previous works for 3D detection and depth estimation on the Cityscapes dataset with full supervision.
covLLM: Large Language Models for COVID-19 Biomedical Literature
Jun 08, 2023
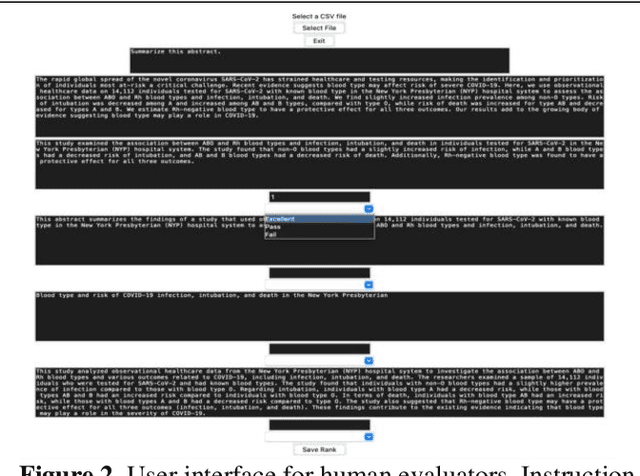
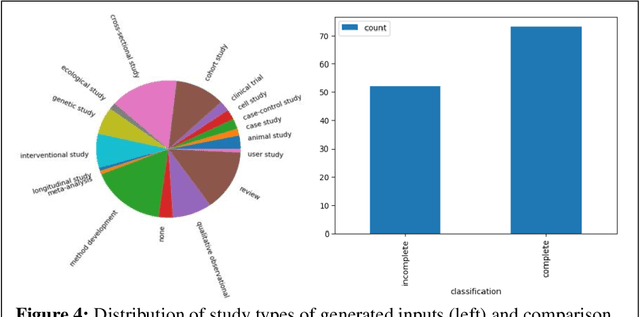
The COVID-19 pandemic led to 1.1 million deaths in the United States, despite the explosion of coronavirus research. These new findings are slow to translate to clinical interventions, leading to poorer patient outcomes and unnecessary deaths. One reason is that clinicians, overwhelmed by patients, struggle to keep pace with the rate of new coronavirus literature. A potential solution is developing a tool for evaluating coronavirus literature using large language models (LLMs) -- neural networks that are deployed for natural language processing. LLMs can be used to summarize and extract user-specified information. The greater availability and advancement of LLMs and pre-processed coronavirus literature databases provide the opportunity to assist clinicians in evaluating coronavirus literature through a coronavirus literature specific LLM (covLLM), a tool that directly takes an inputted research article and a user query to return an answer. Using the COVID-19 Open Research Dataset (CORD-19), we produced two datasets: (1) synCovid, which uses a combination of handwritten prompts and synthetic prompts generated using OpenAI, and (2) real abstracts, which contains abstract and title pairs. covLLM was trained with LLaMA 7B as a baseline model to produce three models trained on (1) the Alpaca and synCovid datasets, (2) the synCovid dataset, and (3) the synCovid and real abstract datasets. These models were evaluated by two human evaluators and ChatGPT. Results demonstrate that training covLLM on the synCovid and abstract pairs datasets performs competitively with ChatGPT and outperforms covLLM trained primarily using the Alpaca dataset.
FheFL: Fully Homomorphic Encryption Friendly Privacy-Preserving Federated Learning with Byzantine Users
Jun 08, 2023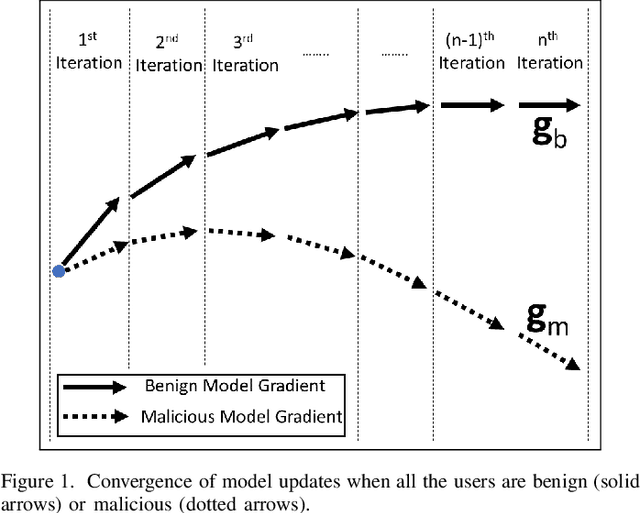
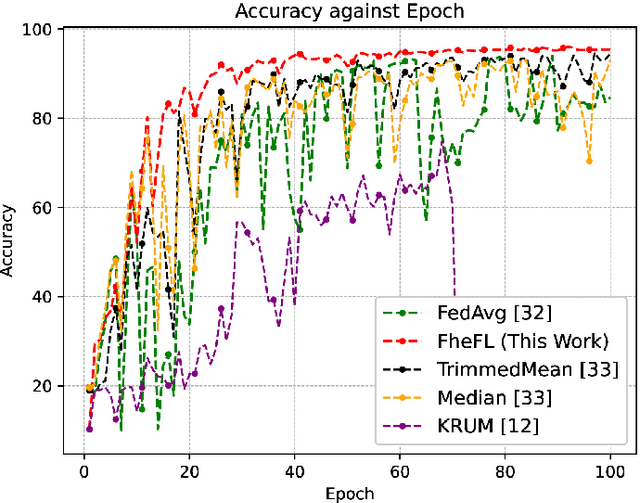
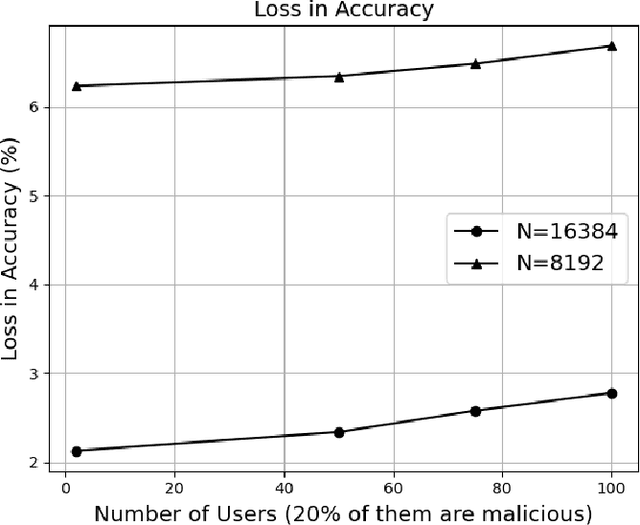
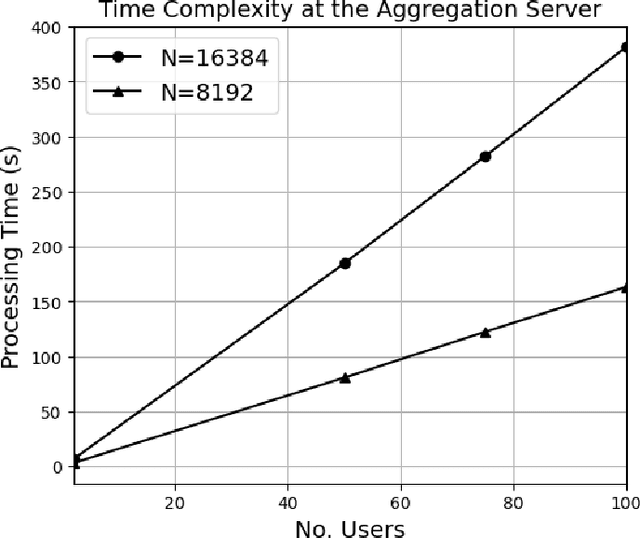
The federated learning (FL) technique was initially developed to mitigate data privacy issues that can arise in the traditional machine learning paradigm. While FL ensures that a user's data always remain with the user, the gradients of the locally trained models must be communicated with the centralized server to build the global model. This results in privacy leakage, where the server can infer private information of the users' data from the shared gradients. To mitigate this flaw, the next-generation FL architectures proposed encryption and anonymization techniques to protect the model updates from the server. However, this approach creates other challenges, such as a malicious user might sabotage the global model by sharing false gradients. Since the gradients are encrypted, the server is unable to identify and eliminate rogue users which would protect the global model. Therefore, to mitigate both attacks, this paper proposes a novel fully homomorphic encryption (FHE) based scheme suitable for FL. We modify the one-to-one single-key Cheon-Kim-Kim-Song (CKKS)-based FHE scheme into a distributed multi-key additive homomorphic encryption scheme that supports model aggregation in FL. We employ a novel aggregation scheme within the encrypted domain, utilizing users' non-poisoning rates, to effectively address data poisoning attacks while ensuring privacy is preserved by the proposed encryption scheme. Rigorous security, privacy, convergence, and experimental analyses have been provided to show that FheFL is novel, secure, and private, and achieves comparable accuracy at reasonable computational cost.
Solution of physics-based inverse problems using conditional generative adversarial networks with full gradient penalty
Jun 08, 2023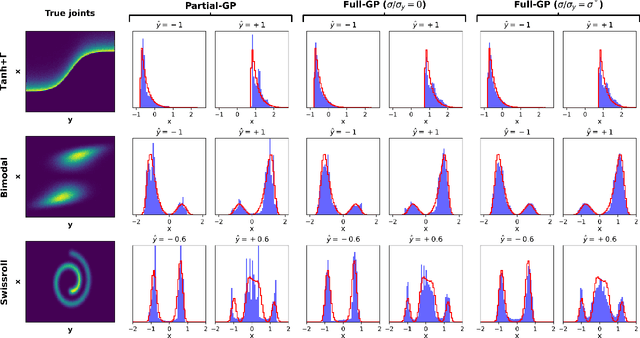
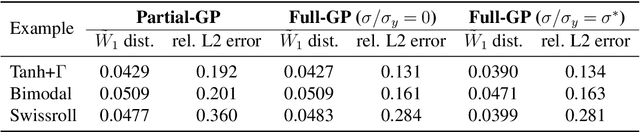
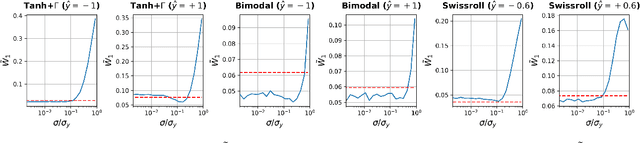

The solution of probabilistic inverse problems for which the corresponding forward problem is constrained by physical principles is challenging. This is especially true if the dimension of the inferred vector is large and the prior information about it is in the form of a collection of samples. In this work, a novel deep learning based approach is developed and applied to solving these types of problems. The approach utilizes samples of the inferred vector drawn from the prior distribution and a physics-based forward model to generate training data for a conditional Wasserstein generative adversarial network (cWGAN). The cWGAN learns the probability distribution for the inferred vector conditioned on the measurement and produces samples from this distribution. The cWGAN developed in this work differs from earlier versions in that its critic is required to be 1-Lipschitz with respect to both the inferred and the measurement vectors and not just the former. This leads to a loss term with the full (and not partial) gradient penalty. It is shown that this rather simple change leads to a stronger notion of convergence for the conditional density learned by the cWGAN and a more robust and accurate sampling strategy. Through numerical examples it is shown that this change also translates to better accuracy when solving inverse problems. The numerical examples considered include illustrative problems where the true distribution and/or statistics are known, and a more complex inverse problem motivated by applications in biomechanics.
EH Modelling and Achievable Rate for FSO SWIPT Systems with Non-linear Photovoltaic Receivers
May 05, 2023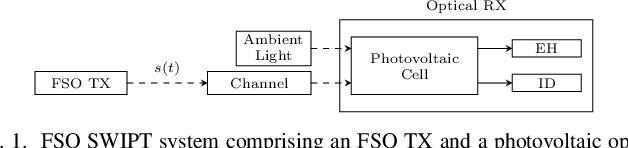
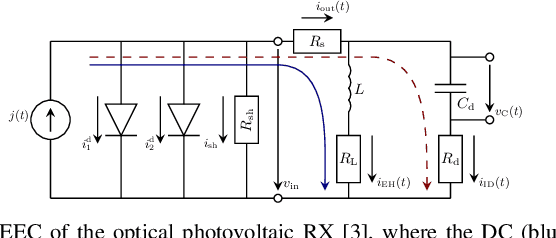
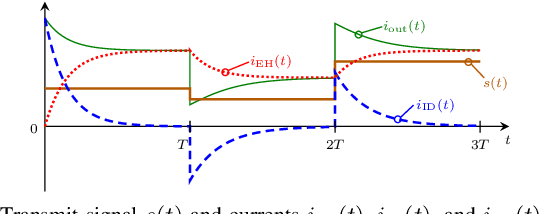
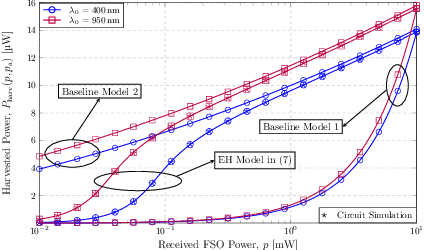
In this paper, we study optical simultaneous wireless information and power transfer (SWIPT) systems, where a photovoltaic optical receiver (RX) is illuminated by ambient light and an intensity-modulated free space optical (FSO) signal. To facilitate simultaneous information reception and energy harvesting (EH) at the RX, the received optical signal is first converted to an electrical signal, and then, its alternating current (AC) and direct current (DC) components are separated and utilized for information decoding and EH, respectively. By accurately analysing the equivalent electrical circuit of the photovoltaic RX, we model the current flow through the photovoltaic p-n junction in both the low and high input power regimes using a two-diode model of the p-n junction and we derive a closed-form non-linear EH model that characterizes the harvested power at the RX. Furthermore, taking into account the non-linear behaviour of the photovoltaic RX on information reception, we derive the optimal distribution of the transmit information signal that maximizes the achievable information rate. The proposed EH model is validated by circuit simulation results. Furthermore, we compare with two baseline models based on maximum power point (MPP) tracking at the RX and a single-diode p-n junction model, respectively, and demonstrate that in contrast to the proposed EH model, they are not able to fully capture the non-linearity of photovoltaic optical RXs. Finally, our numerical results highlight that the proposed optimal distribution of the transmit signal yields significantly higher achievable information rates compared to uniformly distributed transmit signals, which are optimal for linear optical information RXs.