 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Learning with Feedback Graphs: The True Shape of Regret
Jun 05, 2023
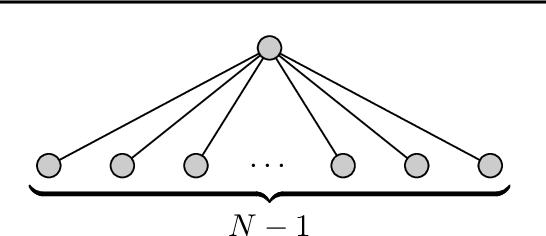
Sequential learning with feedback graphs is a natural extension of the multi-armed bandit problem where the problem is equipped with an underlying graph structure that provides additional information - playing an action reveals the losses of all the neighbors of the action. This problem was introduced by \citet{mannor2011} and received considerable attention in recent years. It is generally stated in the literature that the minimax regret rate for this problem is of order $\sqrt{\alpha T}$, where $\alpha$ is the independence number of the graph, and $T$ is the time horizon. However, this is proven only when the number of rounds $T$ is larger than $\alpha^3$, which poses a significant restriction for the usability of this result in large graphs. In this paper, we define a new quantity $R^*$, called the \emph{problem complexity}, and prove that the minimax regret is proportional to $R^*$ for any graph and time horizon $T$. Introducing an intricate exploration strategy, we define the \mainAlgorithm algorithm that achieves the minimax optimal regret bound and becomes the first provably optimal algorithm for this setting, even if $T$ is smaller than $\alpha^3$.
DecompX: Explaining Transformers Decisions by Propagating Token Decomposition
Jun 05, 2023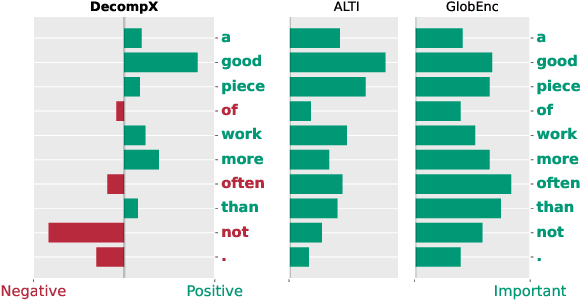
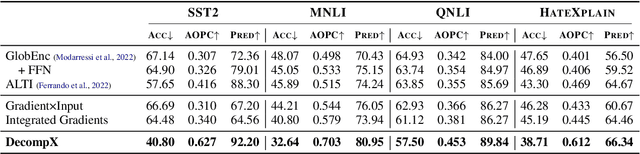
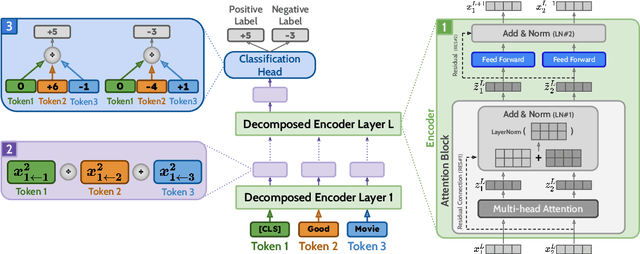
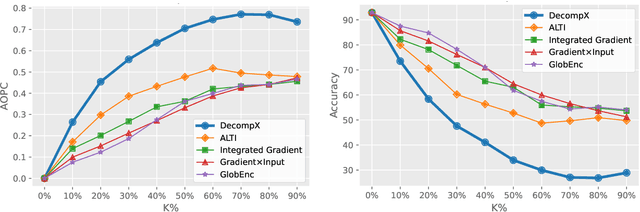
An emerging solution for explaining Transformer-based models is to use vector-based analysis on how the representations are formed. However, providing a faithful vector-based explanation for a multi-layer model could be challenging in three aspects: (1) Incorporating all components into the analysis, (2) Aggregating the layer dynamics to determine the information flow and mixture throughout the entire model, and (3) Identifying the connection between the vector-based analysis and the model's predictions. In this paper, we present DecompX to tackle these challenges. DecompX is based on the construction of decomposed token representations and their successive propagation throughout the model without mixing them in between layers. Additionally, our proposal provides multiple advantages over existing solutions for its inclusion of all encoder components (especially nonlinear feed-forward networks) and the classification head. The former allows acquiring precise vectors while the latter transforms the decomposition into meaningful prediction-based values, eliminating the need for norm- or summation-based vector aggregation. According to the standard faithfulness evaluations, DecompX consistently outperforms existing gradient-based and vector-based approaches on various datasets. Our code is available at https://github.com/mohsenfayyaz/DecompX.
Exploring Depth Information for Face Manipulation Detection
Dec 29, 2022
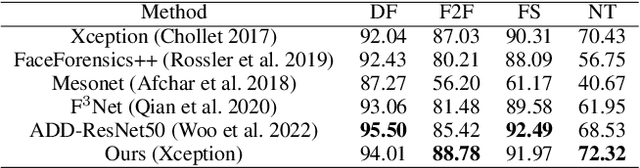
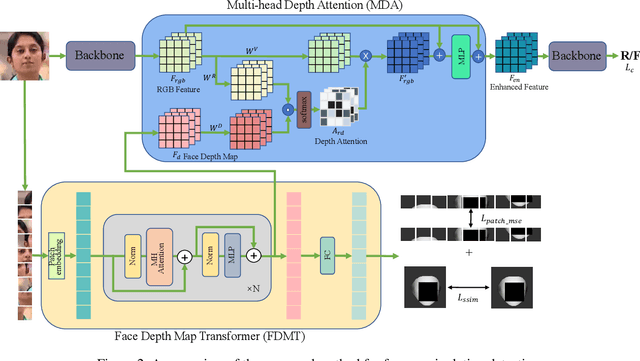
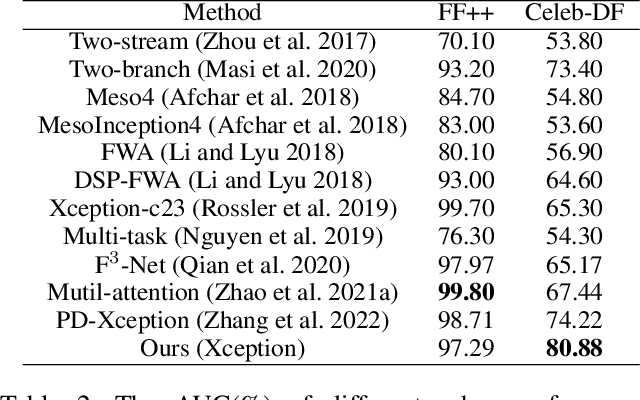
Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as the face recognition or face detection, is unfortunately paid little attention to in literature for detecting the manipulated face images. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information to tackle the problem of face manipulation detection in real world applications. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from a RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.
Diffeomorphic Information Neural Estimation
Nov 20, 2022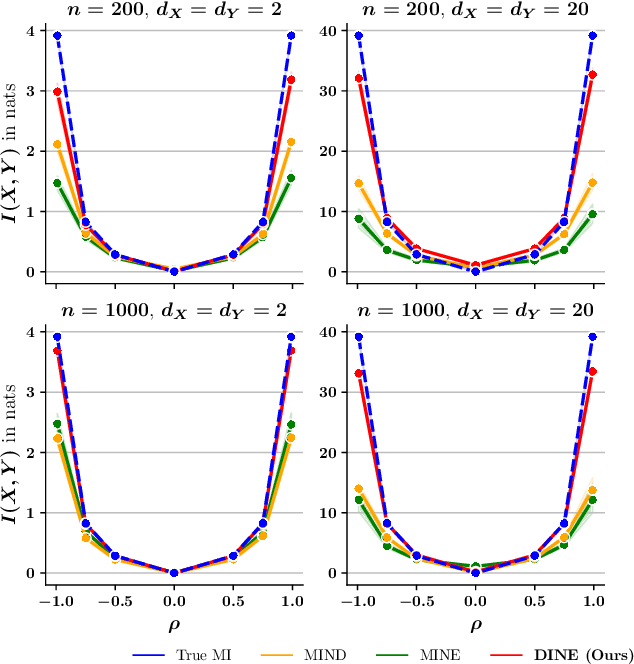
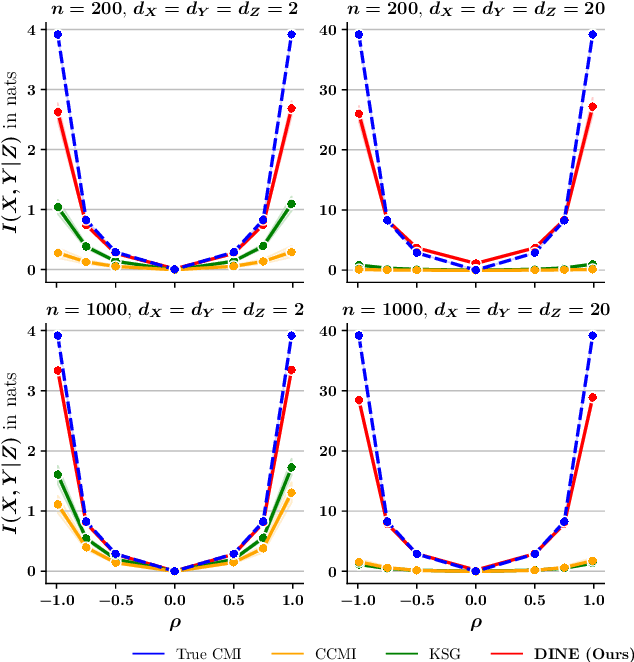
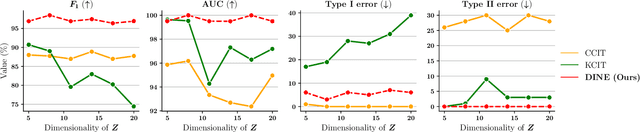
Mutual Information (MI) and Conditional Mutual Information (CMI) are multi-purpose tools from information theory that are able to naturally measure the statistical dependencies between random variables, thus they are usually of central interest in several statistical and machine learning tasks, such as conditional independence testing and representation learning. However, estimating CMI, or even MI, is infamously challenging due the intractable formulation. In this study, we introduce DINE (Diffeomorphic Information Neural Estimator)-a novel approach for estimating CMI of continuous random variables, inspired by the invariance of CMI over diffeomorphic maps. We show that the variables of interest can be replaced with appropriate surrogates that follow simpler distributions, allowing the CMI to be efficiently evaluated via analytical solutions. Additionally, we demonstrate the quality of the proposed estimator in comparison with state-of-the-arts in three important tasks, including estimating MI, CMI, as well as its application in conditional independence testing. The empirical evaluations show that DINE consistently outperforms competitors in all tasks and is able to adapt very well to complex and high-dimensional relationships.
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023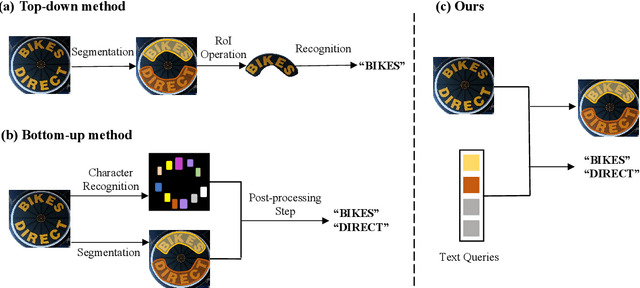
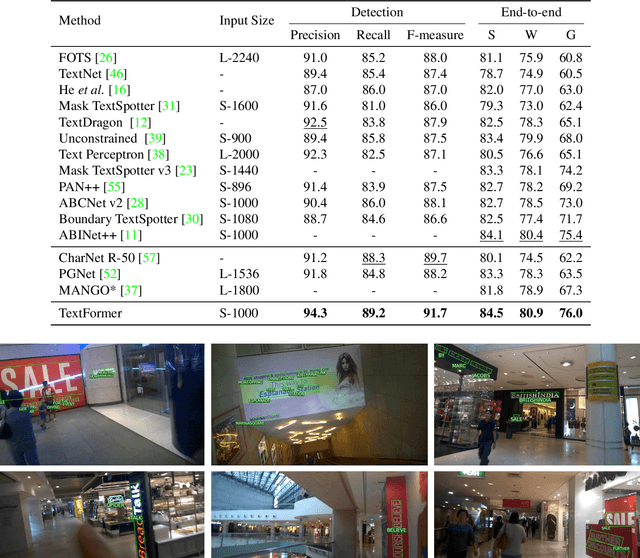

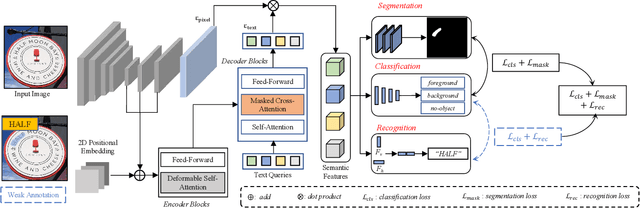
End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
How does over-squashing affect the power of GNNs?
Jun 06, 2023

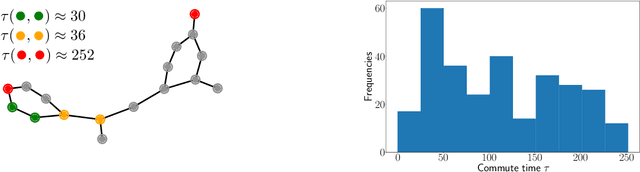
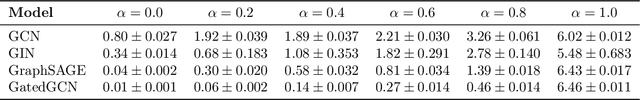
Graph Neural Networks (GNNs) are the state-of-the-art model for machine learning on graph-structured data. The most popular class of GNNs operate by exchanging information between adjacent nodes, and are known as Message Passing Neural Networks (MPNNs). Given their widespread use, understanding the expressive power of MPNNs is a key question. However, existing results typically consider settings with uninformative node features. In this paper, we provide a rigorous analysis to determine which function classes of node features can be learned by an MPNN of a given capacity. We do so by measuring the level of pairwise interactions between nodes that MPNNs allow for. This measure provides a novel quantitative characterization of the so-called over-squashing effect, which is observed to occur when a large volume of messages is aggregated into fixed-size vectors. Using our measure, we prove that, to guarantee sufficient communication between pairs of nodes, the capacity of the MPNN must be large enough, depending on properties of the input graph structure, such as commute times. For many relevant scenarios, our analysis results in impossibility statements in practice, showing that over-squashing hinders the expressive power of MPNNs. We validate our theoretical findings through extensive controlled experiments and ablation studies.
Designing explainable artificial intelligence with active inference: A framework for transparent introspection and decision-making
Jun 06, 2023
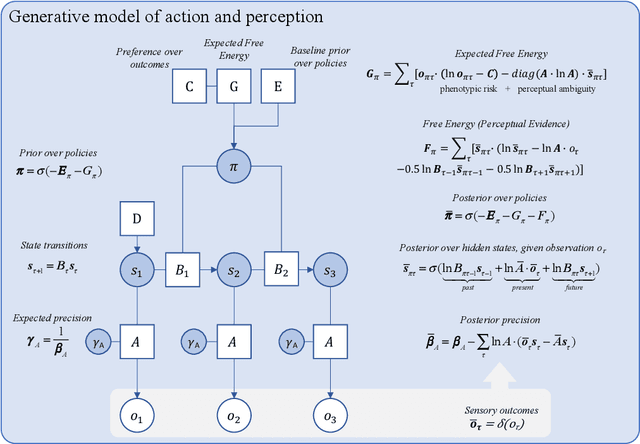
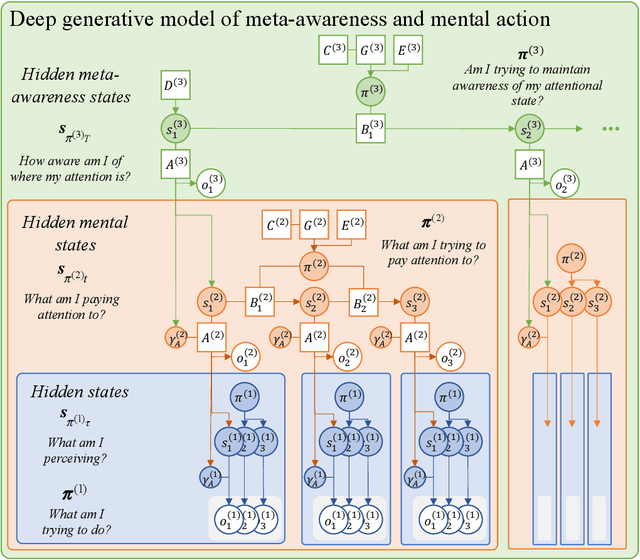
This paper investigates the prospect of developing human-interpretable, explainable artificial intelligence (AI) systems based on active inference and the free energy principle. We first provide a brief overview of active inference, and in particular, of how it applies to the modeling of decision-making, introspection, as well as the generation of overt and covert actions. We then discuss how active inference can be leveraged to design explainable AI systems, namely, by allowing us to model core features of ``introspective'' processes and by generating useful, human-interpretable models of the processes involved in decision-making. We propose an architecture for explainable AI systems using active inference. This architecture foregrounds the role of an explicit hierarchical generative model, the operation of which enables the AI system to track and explain the factors that contribute to its own decisions, and whose structure is designed to be interpretable and auditable by human users. We outline how this architecture can integrate diverse sources of information to make informed decisions in an auditable manner, mimicking or reproducing aspects of human-like consciousness and introspection. Finally, we discuss the implications of our findings for future research in AI, and the potential ethical considerations of developing AI systems with (the appearance of) introspective capabilities.
Can large language models democratize access to dual-use biotechnology?
Jun 06, 2023Large language models (LLMs) such as those embedded in 'chatbots' are accelerating and democratizing research by providing comprehensible information and expertise from many different fields. However, these models may also confer easy access to dual-use technologies capable of inflicting great harm. To evaluate this risk, the 'Safeguarding the Future' course at MIT tasked non-scientist students with investigating whether LLM chatbots could be prompted to assist non-experts in causing a pandemic. In one hour, the chatbots suggested four potential pandemic pathogens, explained how they can be generated from synthetic DNA using reverse genetics, supplied the names of DNA synthesis companies unlikely to screen orders, identified detailed protocols and how to troubleshoot them, and recommended that anyone lacking the skills to perform reverse genetics engage a core facility or contract research organization. Collectively, these results suggest that LLMs will make pandemic-class agents widely accessible as soon as they are credibly identified, even to people with little or no laboratory training. Promising nonproliferation measures include pre-release evaluations of LLMs by third parties, curating training datasets to remove harmful concepts, and verifiably screening all DNA generated by synthesis providers or used by contract research organizations and robotic cloud laboratories to engineer organisms or viruses.
Human-Object Interaction Prediction in Videos through Gaze Following
Jun 06, 2023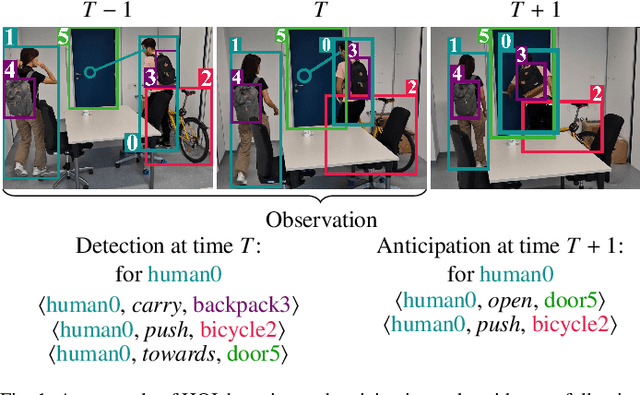
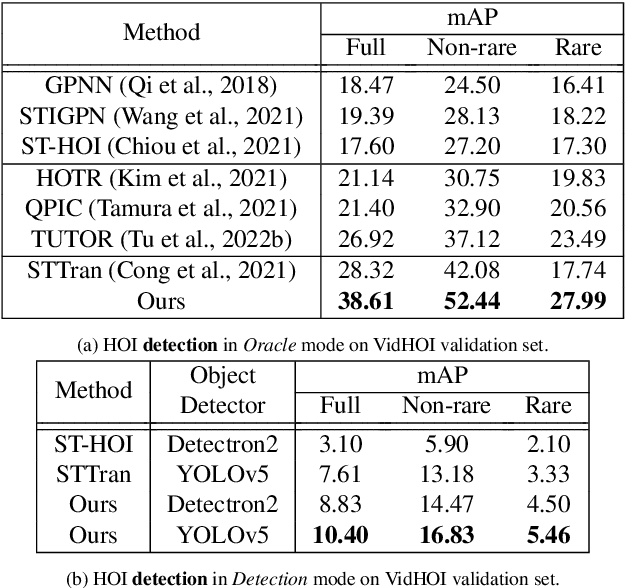
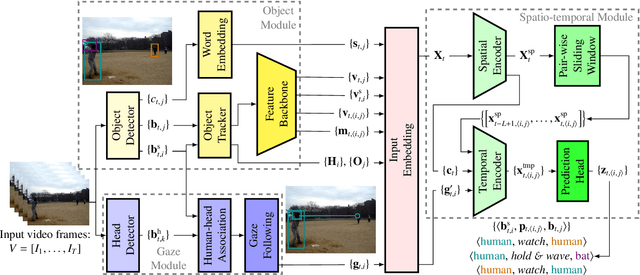
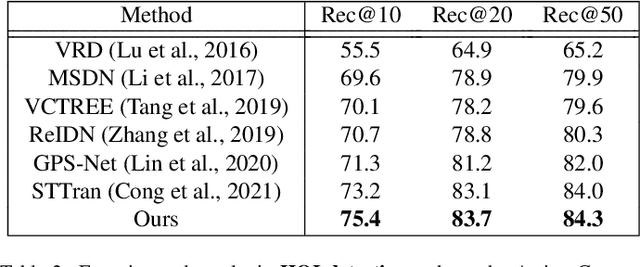
Understanding the human-object interactions (HOIs) from a video is essential to fully comprehend a visual scene. This line of research has been addressed by detecting HOIs from images and lately from videos. However, the video-based HOI anticipation task in the third-person view remains understudied. In this paper, we design a framework to detect current HOIs and anticipate future HOIs in videos. We propose to leverage human gaze information since people often fixate on an object before interacting with it. These gaze features together with the scene contexts and the visual appearances of human-object pairs are fused through a spatio-temporal transformer. To evaluate the model in the HOI anticipation task in a multi-person scenario, we propose a set of person-wise multi-label metrics. Our model is trained and validated on the VidHOI dataset, which contains videos capturing daily life and is currently the largest video HOI dataset. Experimental results in the HOI detection task show that our approach improves the baseline by a great margin of 36.3% relatively. Moreover, we conduct an extensive ablation study to demonstrate the effectiveness of our modifications and extensions to the spatio-temporal transformer. Our code is publicly available on https://github.com/nizhf/hoi-prediction-gaze-transformer.
MCD64A1 Burnt Area Dataset Assessment using Sentinel-2 and Landsat-8 on Google Earth Engine: A Case Study in Rompin, Pahang in Malaysia
Jun 06, 2023
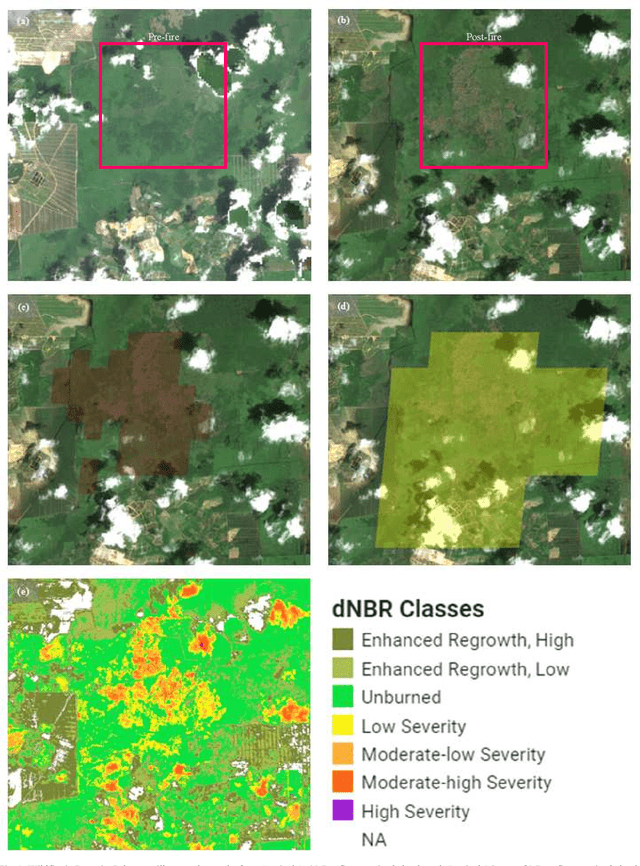
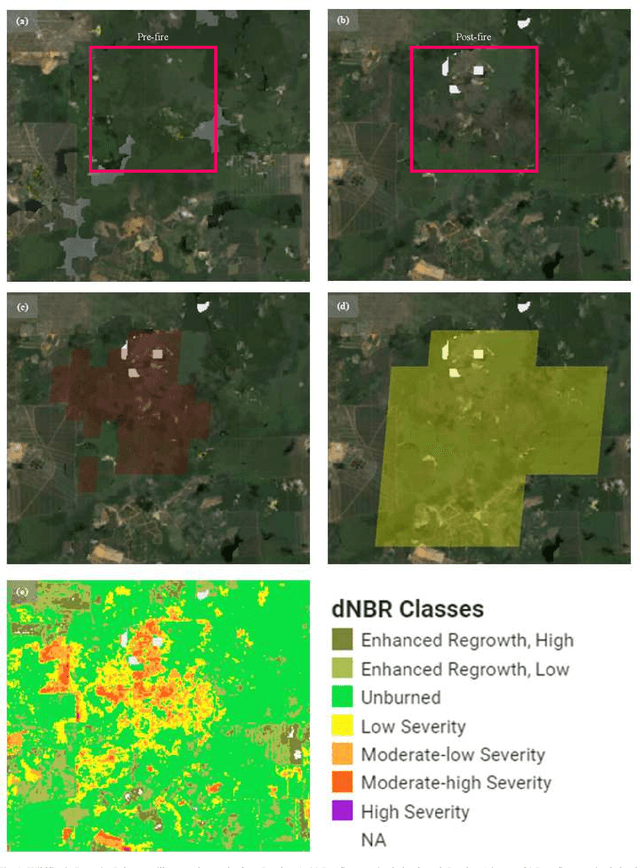
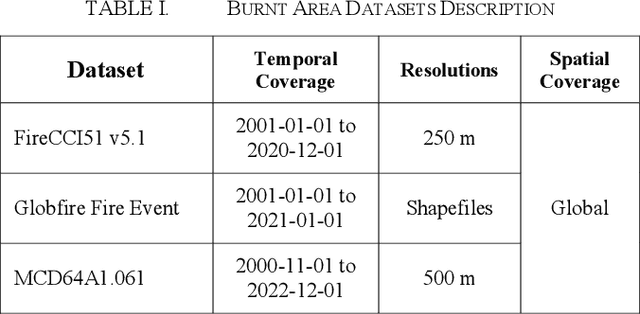
This research paper intends to explore the suitability of adopting the MCD64A1 product to detect burnt areas using Google Earth Engine (GEE) in Peninsular Malaysia. The primary aim of this study is to find out if the MCD64A1 is adequate to identify the small-scale fire in Peninsular Malaysia. To evaluate the MCD64A1, a fire that was instigated in Rompin, a district of Pahang on March 2021 has been chosen as the case study in this work. Although several other burnt area datasets had also been made available in GEE, only MCD64A1 is selected due to its temporal availability. In the absence of validation information associated with the fire from the Malaysian government, public news sources are utilized to retrieve details related to the fire in Rompin. Additionally, the MCD64A1 is also validated with the burnt area observed from the true color imagery produced from the surface reflectance of Sentinel-2 and Landsat-8. From the burnt area assessment, we scrutinize that the MCD64A1 product is practical to be exploited to discover the historical fire in Peninsular Malaysia. However, additional case studies involving other locations in Peninsular Malaysia are advocated to be carried out to substantiate the claims discussed in this work.