 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023
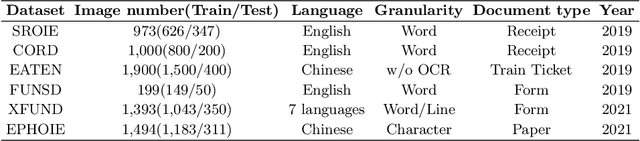
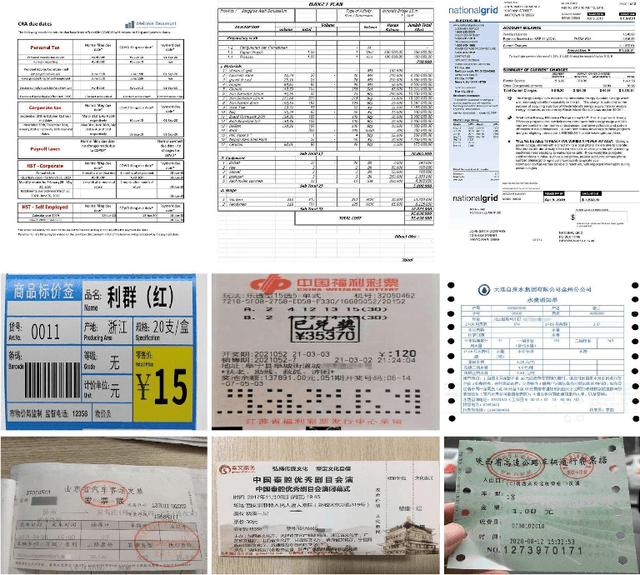

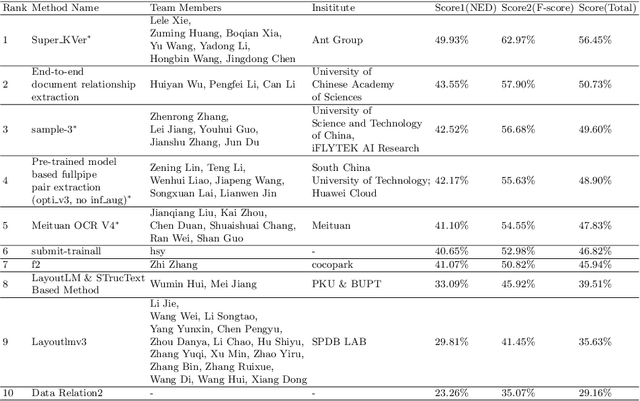
Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
Model-Based Deep Learning
Jun 05, 2023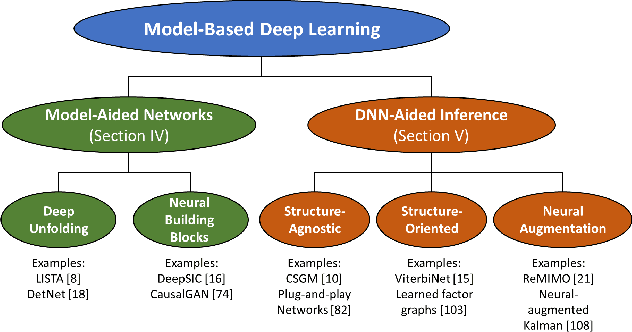
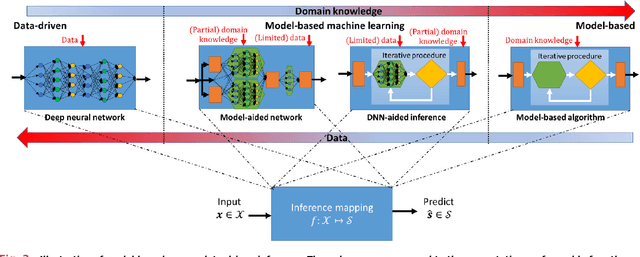
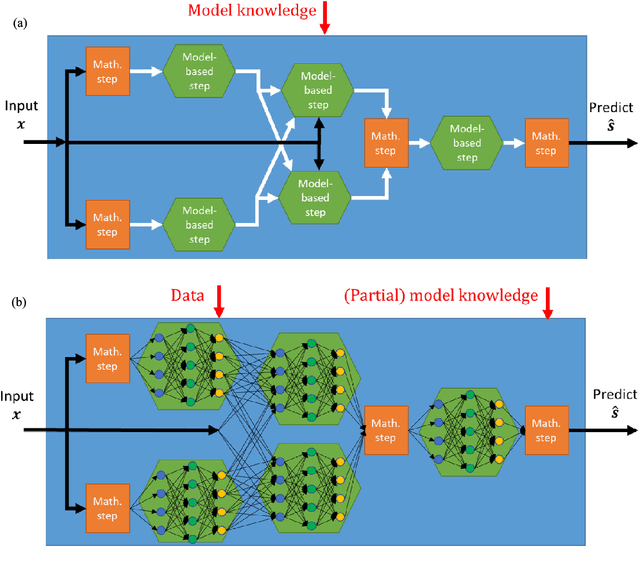
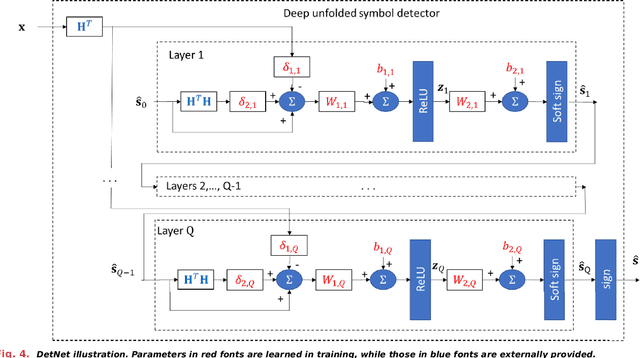
Signal processing traditionally relies on classical statistical modeling techniques. Such model-based methods utilize mathematical formulations that represent the underlying physics, prior information and additional domain knowledge. Simple classical models are useful but sensitive to inaccuracies and may lead to poor performance when real systems display complex or dynamic behavior. More recently, deep learning approaches that use deep neural networks are becoming increasingly popular. Deep learning systems do not rely on mathematical modeling, and learn their mapping from data, which allows them to operate in complex environments. However, they lack the interpretability and reliability of model-based methods, typically require large training sets to obtain good performance, and tend to be computationally complex. Model-based signal processing methods and data-centric deep learning each have their pros and cons. These paradigms can be characterized as edges of a continuous spectrum varying in specificity and parameterization. The methodologies that lie in the middle ground of this spectrum, thus integrating model-based signal processing with deep learning, are referred to as model-based deep learning, and are the focus here. This monograph provides a tutorial style presentation of model-based deep learning methodologies. These are families of algorithms that combine principled mathematical models with data-driven systems to benefit from the advantages of both approaches. Such model-based deep learning methods exploit both partial domain knowledge, via mathematical structures designed for specific problems, as well as learning from limited data. We accompany our presentation with running examples, in super-resolution, dynamic systems, and array processing. We show how they are expressed using the provided characterization and specialized in each of the detailed methodologies.
Mutual Information-based Generalized Category Discovery
Dec 01, 2022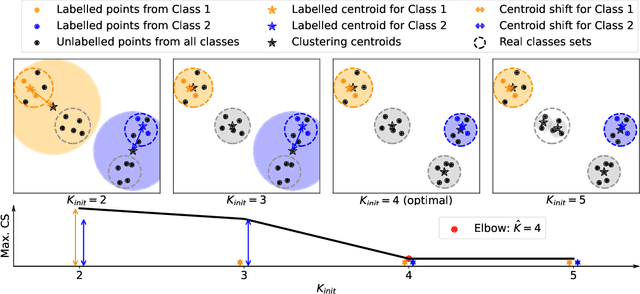

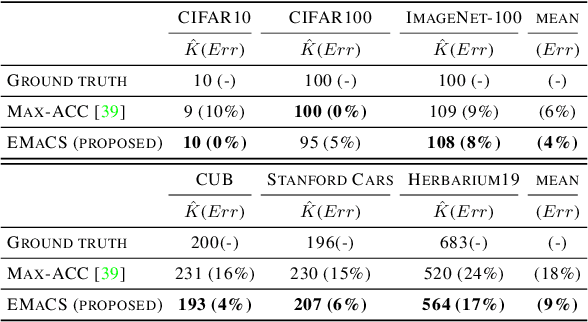
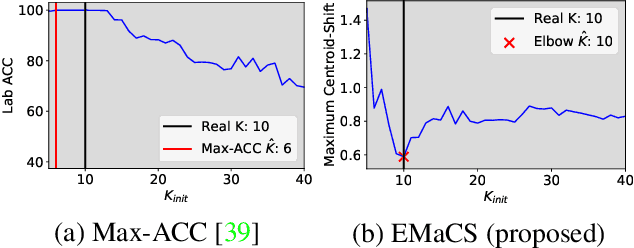
We introduce an information-maximization approach for the Generalized Category Discovery (GCD) problem. Specifically, we explore a parametric family of loss functions evaluating the mutual information between the features and the labels, and find automatically the one that maximizes the predictive performances. Furthermore, we introduce the Elbow Maximum Centroid-Shift (EMaCS) technique, which estimates the number of classes in the unlabeled set. We report comprehensive experiments, which show that our mutual information-based approach (MIB) is both versatile and highly competitive under various GCD scenarios. The gap between the proposed approach and the existing methods is significant, more so when dealing with fine-grained classification problems. Our code: \url{https://github.com/fchiaroni/Mutual-Information-Based-GCD}.
An Empirical Comparison of LM-based Question and Answer Generation Methods
May 26, 2023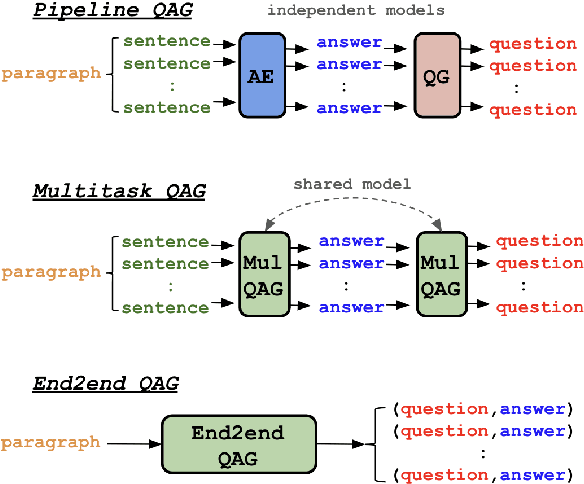
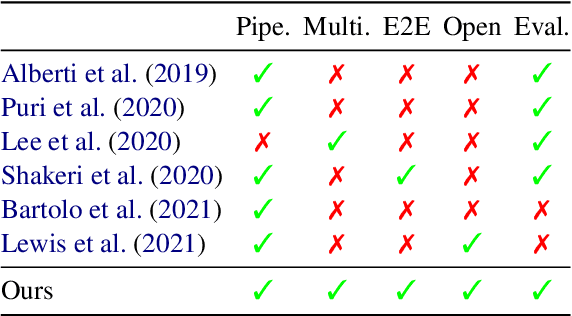
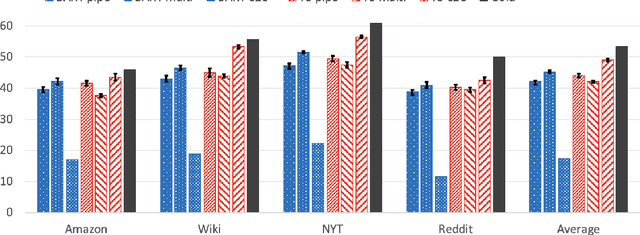
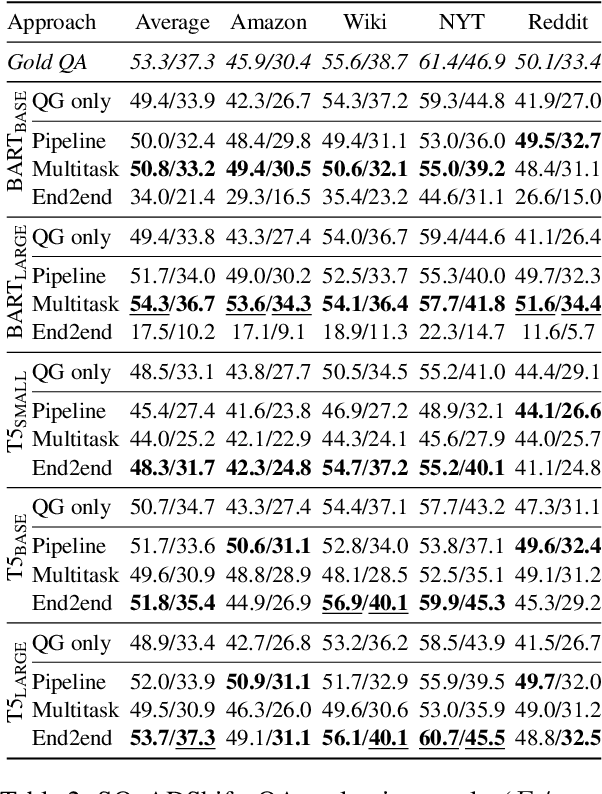
Question and answer generation (QAG) consists of generating a set of question-answer pairs given a context (e.g. a paragraph). This task has a variety of applications, such as data augmentation for question answering (QA) models, information retrieval and education. In this paper, we establish baselines with three different QAG methodologies that leverage sequence-to-sequence language model (LM) fine-tuning. Experiments show that an end-to-end QAG model, which is computationally light at both training and inference times, is generally robust and outperforms other more convoluted approaches. However, there are differences depending on the underlying generative LM. Finally, our analysis shows that QA models fine-tuned solely on generated question-answer pairs can be competitive when compared to supervised QA models trained on human-labeled data.
Analyzing the Internals of Neural Radiance Fields
Jun 01, 2023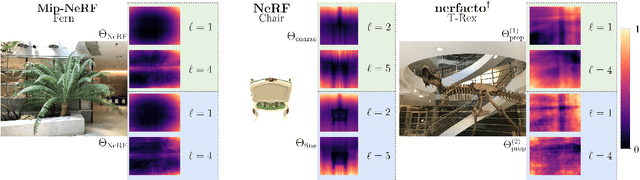
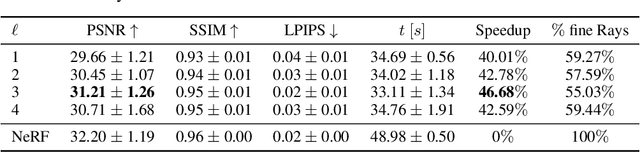
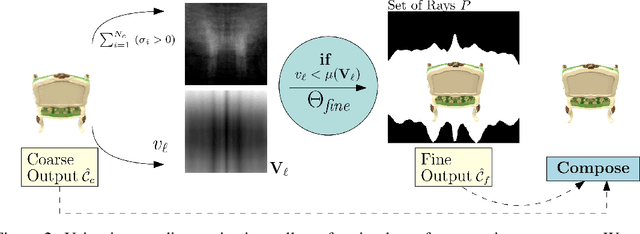
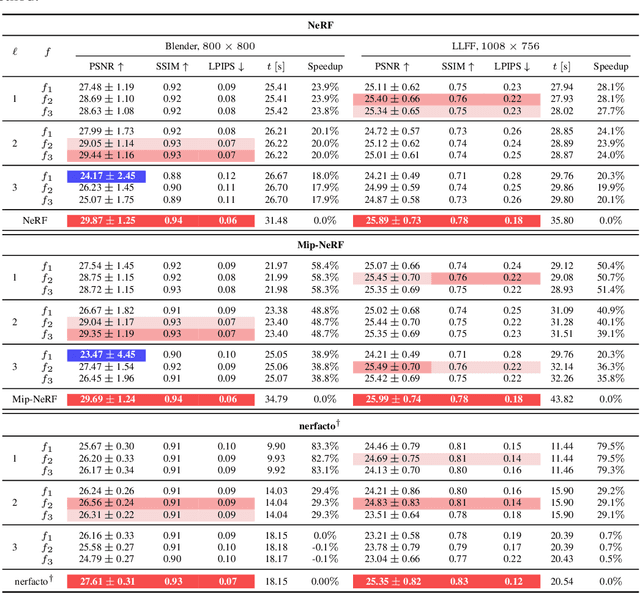
Modern Neural Radiance Fields (NeRFs) learn a mapping from position to volumetric density via proposal network samplers. In contrast to the coarse-to-fine sampling approach with two NeRFs, this offers significant potential for speedups using lower network capacity as the task of mapping spatial coordinates to volumetric density involves no view-dependent effects and is thus much easier to learn. Given that most of the network capacity is utilized to estimate radiance, NeRFs could store valuable density information in their parameters or their deep features. To this end, we take one step back and analyze large, trained ReLU-MLPs used in coarse-to-fine sampling. We find that trained NeRFs, Mip-NeRFs and proposal network samplers map samples with high density to local minima along a ray in activation feature space. We show how these large MLPs can be accelerated by transforming the intermediate activations to a weight estimate, without any modifications to the parameters post-optimization. With our approach, we can reduce the computational requirements of trained NeRFs by up to 50% with only a slight hit in rendering quality and no changes to the training protocol or architecture. We evaluate our approach on a variety of architectures and datasets, showing that our proposition holds in various settings.
Learning Across Decentralized Multi-Modal Remote Sensing Archives with Federated Learning
Jun 01, 2023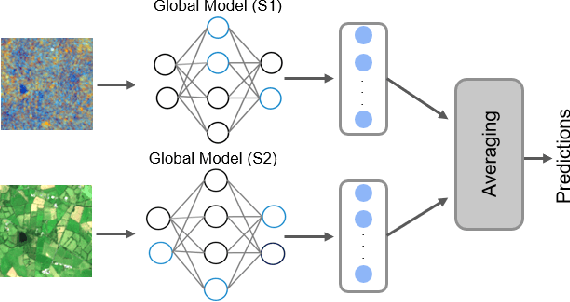
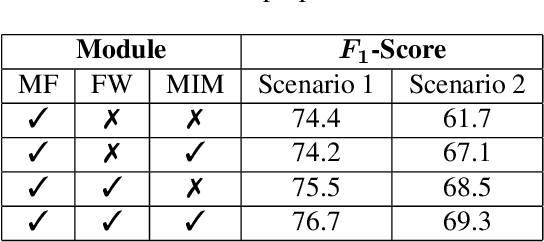
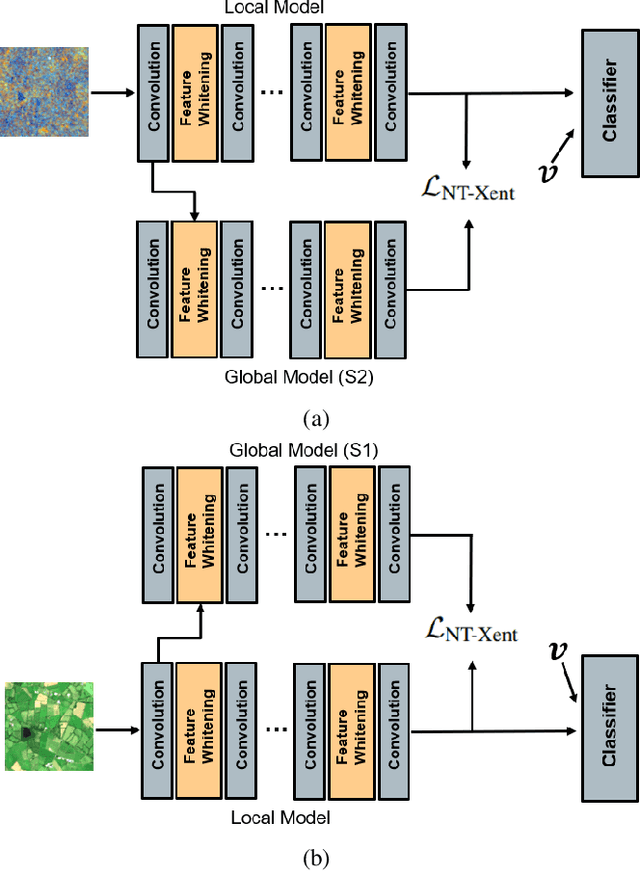
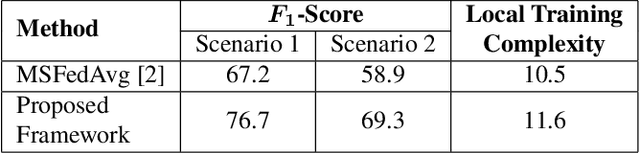
The development of federated learning (FL) methods, which aim to learn from distributed databases (i.e., clients) without accessing data on clients, has recently attracted great attention. Most of these methods assume that the clients are associated with the same data modality. However, remote sensing (RS) images in different clients can be associated with different data modalities that can improve the classification performance when jointly used. To address this problem, in this paper we introduce a novel multi-modal FL framework that aims to learn from decentralized multi-modal RS image archives for RS image classification problems. The proposed framework is made up of three modules: 1) multi-modal fusion (MF); 2) feature whitening (FW); and 3) mutual information maximization (MIM). The MF module performs iterative model averaging to learn without accessing data on clients in the case that clients are associated with different data modalities. The FW module aligns the representations learned among the different clients. The MIM module maximizes the similarity of images from different modalities. Experimental results show the effectiveness of the proposed framework compared to iterative model averaging, which is a widely used algorithm in FL. The code of the proposed framework is publicly available at https://git.tu-berlin.de/rsim/MM-FL.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023
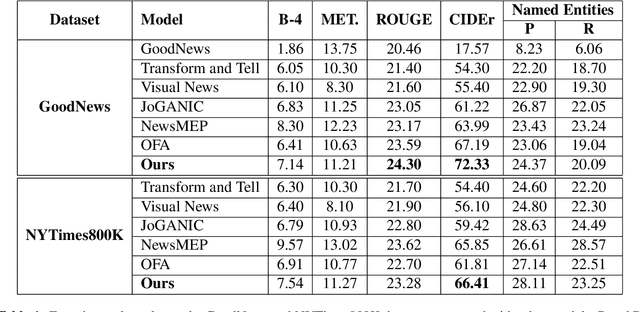
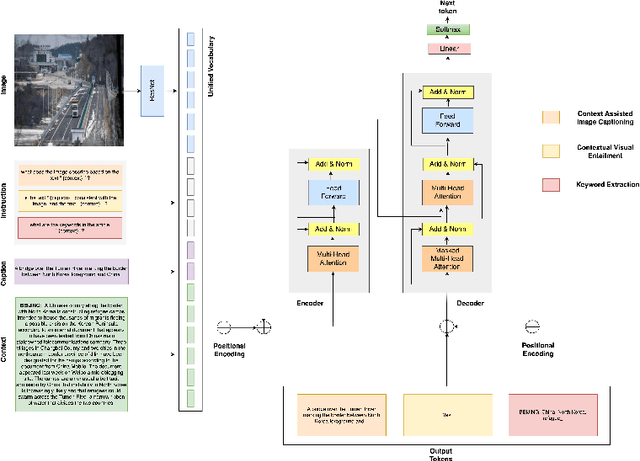
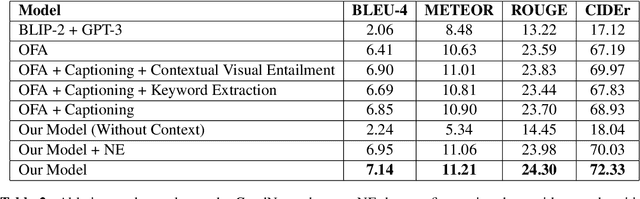
Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
When Does Bottom-up Beat Top-down in Hierarchical Community Detection?
Jun 01, 2023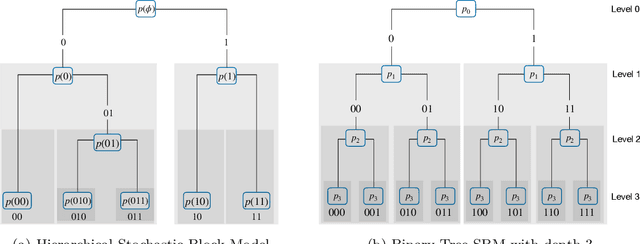
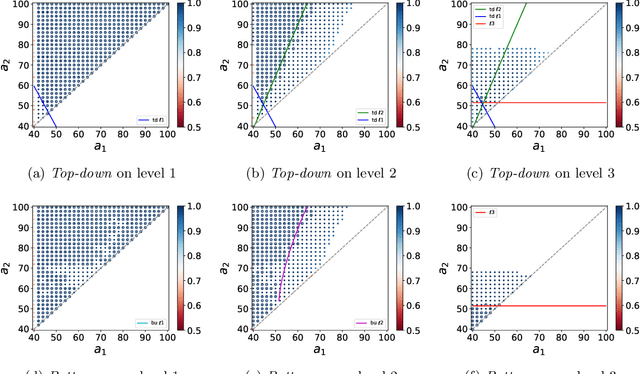

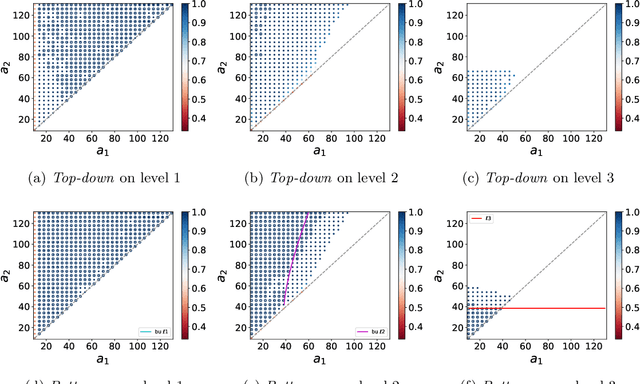
Hierarchical clustering of networks consists in finding a tree of communities, such that lower levels of the hierarchy reveal finer-grained community structures. There are two main classes of algorithms tackling this problem. Divisive ($\textit{top-down}$) algorithms recursively partition the nodes into two communities, until a stopping rule indicates that no further split is needed. In contrast, agglomerative ($\textit{bottom-up}$) algorithms first identify the smallest community structure and then repeatedly merge the communities using a $\textit{linkage}$ method. In this article, we establish theoretical guarantees for the recovery of the hierarchical tree and community structure of a Hierarchical Stochastic Block Model by a bottom-up algorithm. We also establish that this bottom-up algorithm attains the information-theoretic threshold for exact recovery at intermediate levels of the hierarchy. Notably, these recovery conditions are less restrictive compared to those existing for top-down algorithms. This shows that bottom-up algorithms extend the feasible region for achieving exact recovery at intermediate levels. Numerical experiments on both synthetic and real data sets confirm the superiority of bottom-up algorithms over top-down algorithms. We also observe that top-down algorithms can produce dendrograms with inversions. These findings contribute to a better understanding of hierarchical clustering techniques and their applications in network analysis.
Evaluation of Multi-indicator And Multi-organ Medical Image Segmentation Models
Jun 01, 2023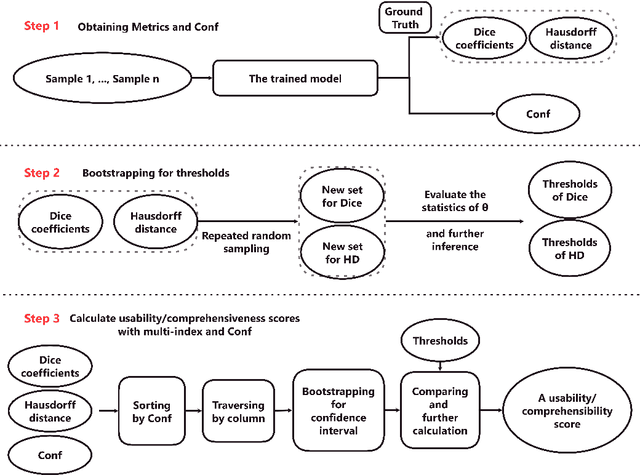
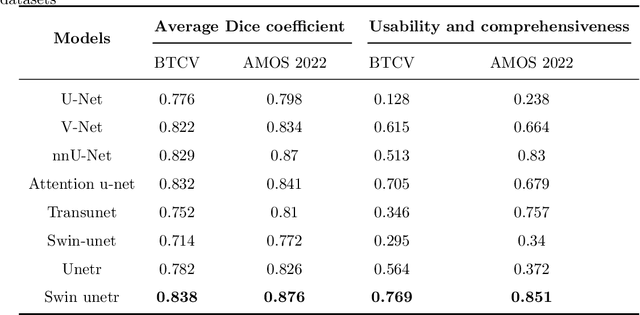

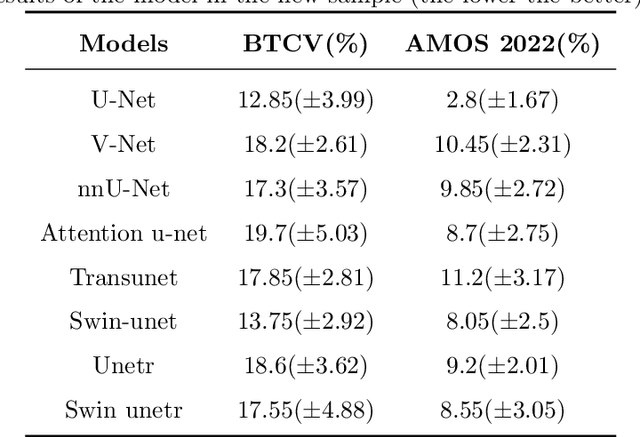
In recent years, "U-shaped" neural networks featuring encoder and decoder structures have gained popularity in the field of medical image segmentation. Various variants of this model have been developed. Nevertheless, the evaluation of these models has received less attention compared to model development. In response, we propose a comprehensive method for evaluating medical image segmentation models for multi-indicator and multi-organ (named MIMO). MIMO allows models to generate independent thresholds which are then combined with multi-indicator evaluation and confidence estimation to screen and measure each organ. As a result, MIMO offers detailed information on the segmentation of each organ in each sample, thereby aiding developers in analyzing and improving the model. Additionally, MIMO can produce concise usability and comprehensiveness scores for different models. Models with higher scores are deemed to be excellent models, which is convenient for clinical evaluation. Our research tests eight different medical image segmentation models on two abdominal multi-organ datasets and evaluates them from four perspectives: correctness, confidence estimation, Usable Region and MIMO. Furthermore, robustness experiments are tested. Experimental results demonstrate that MIMO offers novel insights into multi-indicator and multi-organ medical image evaluation and provides a specific and concise measure for the usability and comprehensiveness of the model. Code: https://github.com/SCUT-ML-GUO/MIMO
Physics-Informed Computer Vision: A Review and Perspectives
Jun 01, 2023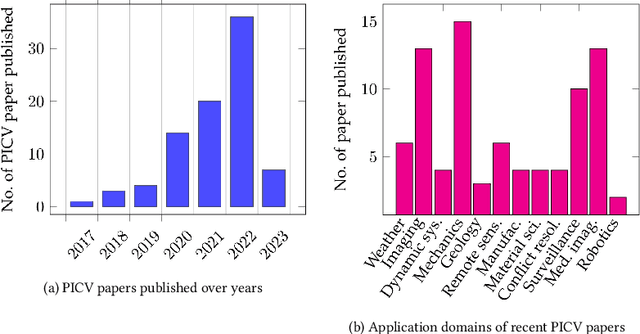
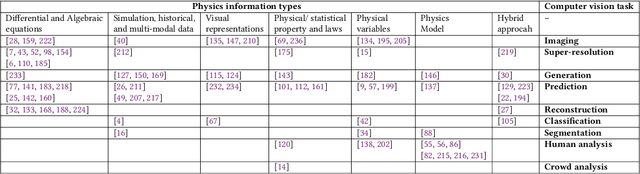
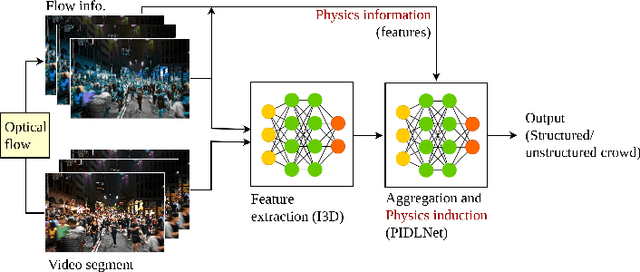
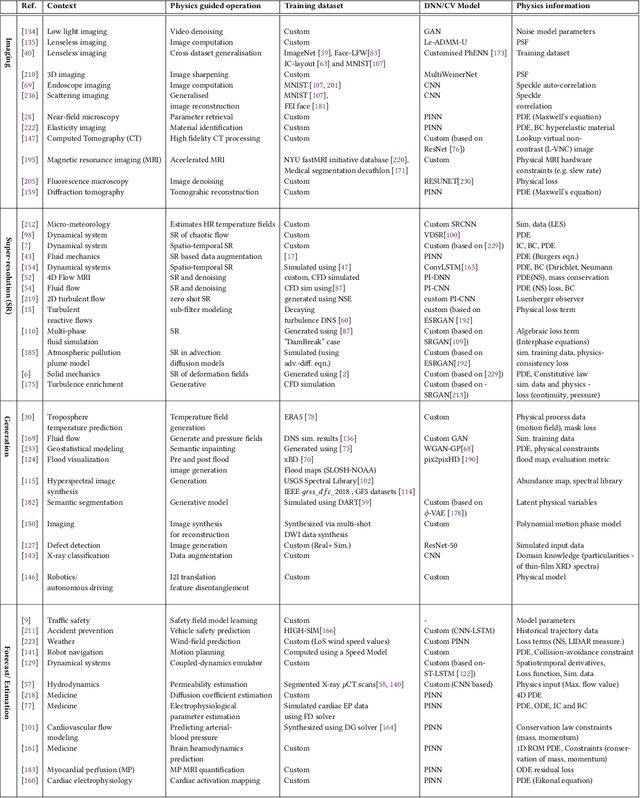
Incorporation of physical information in machine learning frameworks are opening and transforming many application domains. Here the learning process is augmented through the induction of fundamental knowledge and governing physical laws. In this work we explore their utility for computer vision tasks in interpreting and understanding visual data. We present a systematic literature review of formulation and approaches to computer vision tasks guided by physical laws. We begin by decomposing the popular computer vision pipeline into a taxonomy of stages and investigate approaches to incorporate governing physical equations in each stage. Existing approaches in each task are analyzed with regard to what governing physical processes are modeled, formulated and how they are incorporated, i.e. modify data (observation bias), modify networks (inductive bias), and modify losses (learning bias). The taxonomy offers a unified view of the application of the physics-informed capability, highlighting where physics-informed learning has been conducted and where the gaps and opportunities are. Finally, we highlight open problems and challenges to inform future research. While still in its early days, the study of physics-informed computer vision has the promise to develop better computer vision models that can improve physical plausibility, accuracy, data efficiency and generalization in increasingly realistic applications.