 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023
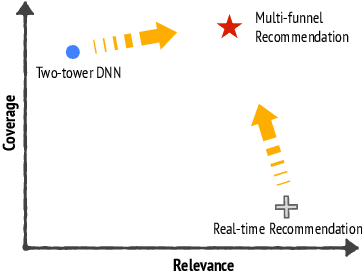
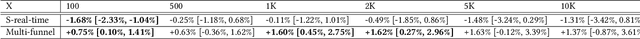
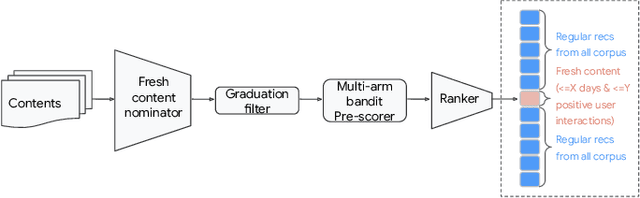

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Linked Deep Gaussian Process Emulation for Model Networks
Jun 02, 2023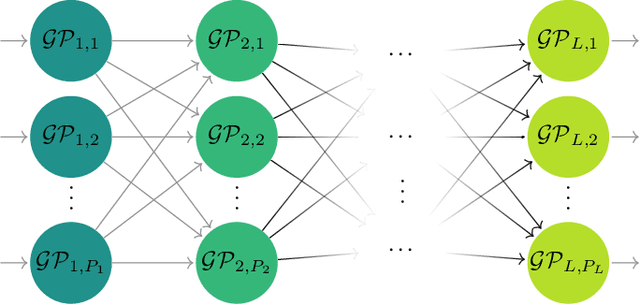
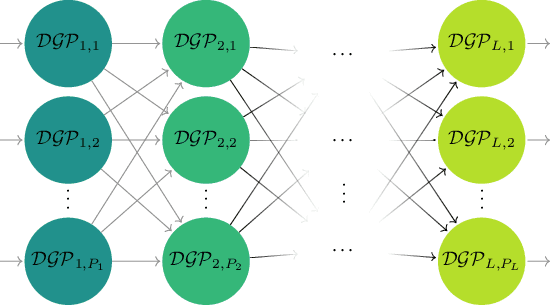
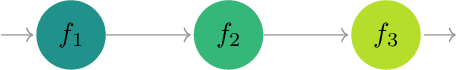
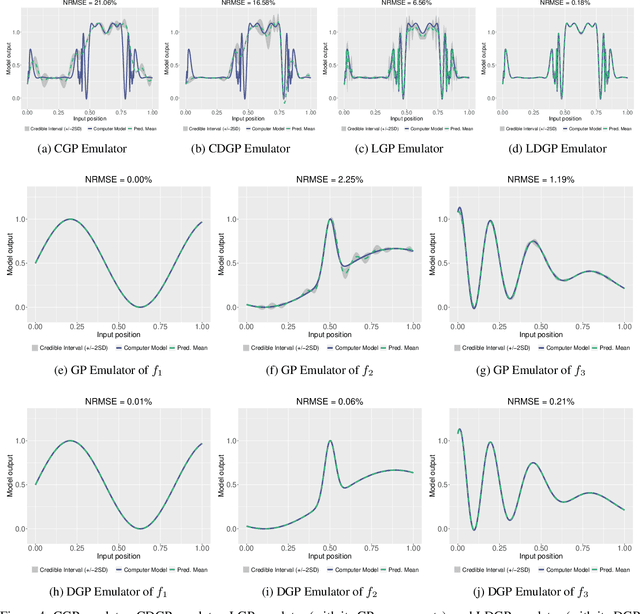
Modern scientific problems are often multi-disciplinary and require integration of computer models from different disciplines, each with distinct functional complexities, programming environments, and computation times. Linked Gaussian process (LGP) emulation tackles this challenge through a divide-and-conquer strategy that integrates Gaussian process emulators of the individual computer models in a network. However, the required stationarity of the component Gaussian process emulators within the LGP framework limits its applicability in many real-world applications. In this work, we conceptualize a network of computer models as a deep Gaussian process with partial exposure of its hidden layers. We develop a method for inference for these partially exposed deep networks that retains a key strength of the LGP framework, whereby each model can be emulated separately using a DGP and then linked together. We show in both synthetic and empirical examples that our linked deep Gaussian process emulators exhibit significantly better predictive performance than standard LGP emulators in terms of accuracy and uncertainty quantification. They also outperform single DGPs fitted to the network as a whole because they are able to integrate information from the partially exposed hidden layers. Our methods are implemented in an R package $\texttt{dgpsi}$ that is freely available on CRAN.
Online estimation of the hand-eye transformation from surgical scenes
Jun 04, 2023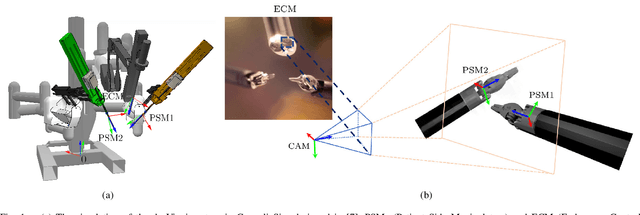

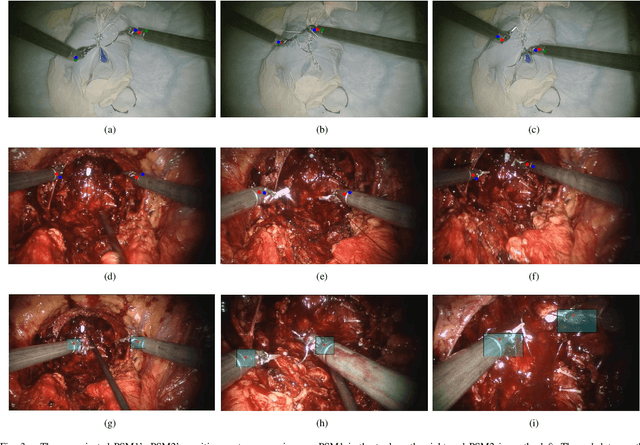
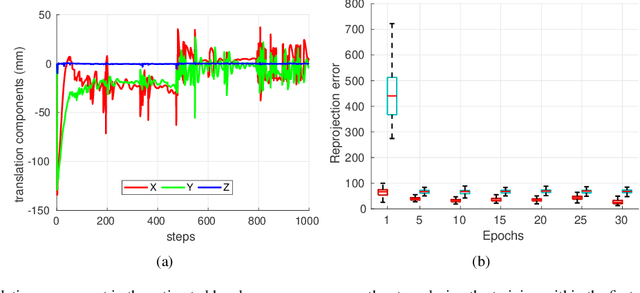
Hand-eye calibration algorithms are mature and provide accurate transformation estimations for an effective camera-robot link but rely on a sufficiently wide range of calibration data to avoid errors and degenerate configurations. To solve the hand-eye problem in robotic-assisted minimally invasive surgery and also simplify the calibration procedure by using neural network method cooporating with the new objective function. We present a neural network-based solution that estimates the transformation from a sequence of images and kinematic data which significantly simplifies the calibration procedure. The network utilises the long short-term memory architecture to extract temporal information from the data and solve the hand-eye problem. The objective function is derived from the linear combination of remote centre of motion constraint, the re-projection error and its derivative to induce a small change in the hand-eye transformation. The method is validated with the data from da Vinci Si and the result shows that the estimated hand-eye matrix is able to re-project the end-effector from the robot coordinate to the camera coordinate within 10 to 20 pixels of accuracy in both testing dataset. The calibration performance is also superior to the previous neural network-based hand-eye method. The proposed algorithm shows that the calibration procedure can be simplified by using deep learning techniques and the performance is improved by the assumption of non-static hand-eye transformations.
Top-Down Processing: Top-Down Network Combines Back-Propagation with Attention
Jun 04, 2023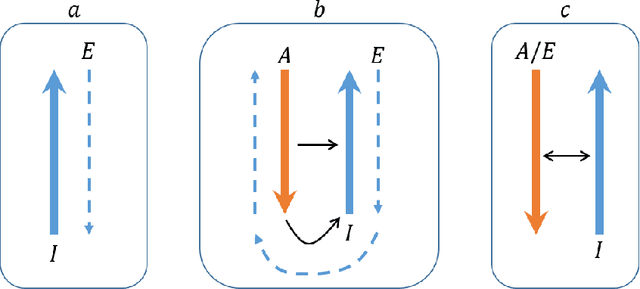
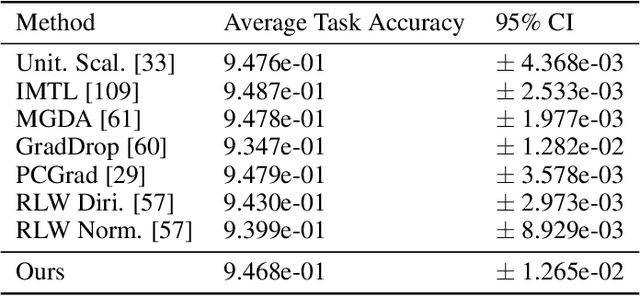
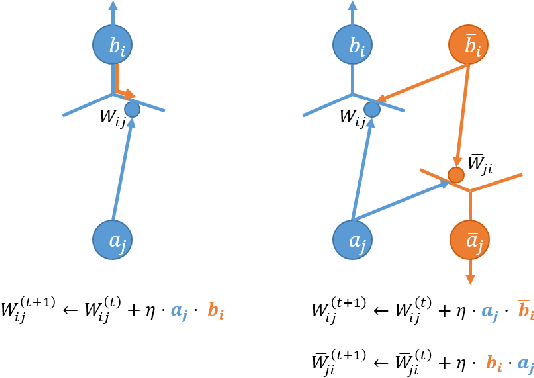
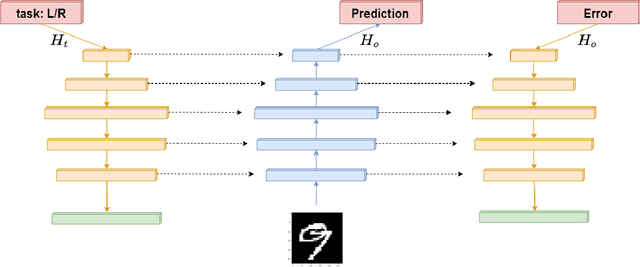
Early neural network models relied exclusively on bottom-up processing going from the input signals to higher-level representations. Many recent models also incorporate top-down networks going in the opposite direction. Top-down processing in deep learning models plays two primary roles: learning and directing attention. These two roles are accomplished in current models through distinct mechanisms. While top-down attention is often implemented by extending the model's architecture with additional units that propagate information from high to low levels of the network, learning is typically accomplished by an external learning algorithm such as back-propagation. In the current work, we present an integration of the two functions above, which appear unrelated, using a single unified mechanism. We propose a novel symmetric bottom-up top-down network structure that can integrate standard bottom-up networks with a symmetric top-down counterpart, allowing each network to guide and influence the other. The same top-down network is being used for both learning, via back-propagating feedback signals, and at the same time also for top-down attention, by guiding the bottom-up network to perform a selected task. We show that our method achieves competitive performance on a standard multi-task learning benchmark. Yet, we rely on standard single-task architectures and optimizers, without any task-specific parameters. Additionally, our learning algorithm addresses in a new way some neuroscience issues that arise in biological modeling of learning in the brain.
Asymptotically Optimal Pure Exploration for Infinite-Armed Bandits
Jun 03, 2023We study pure exploration with infinitely many bandit arms generated i.i.d. from an unknown distribution. Our goal is to efficiently select a single high quality arm whose average reward is, with probability $1-\delta$, within $\varepsilon$ of being among the top $\eta$-fraction of arms; this is a natural adaptation of the classical PAC guarantee for infinite action sets. We consider both the fixed confidence and fixed budget settings, aiming respectively for minimal expected and fixed sample complexity. For fixed confidence, we give an algorithm with expected sample complexity $O\left(\frac{\log (1/\eta)\log (1/\delta)}{\eta\varepsilon^2}\right)$. This is optimal except for the $\log (1/\eta)$ factor, and the $\delta$-dependence closes a quadratic gap in the literature. For fixed budget, we show the asymptotically optimal sample complexity as $\delta\to 0$ is $c^{-1}\log(1/\delta)\big(\log\log(1/\delta)\big)^2$ to leading order. Equivalently, the optimal failure probability given exactly $N$ samples decays as $\exp\big(-cN/\log^2 N\big)$, up to a factor $1\pm o_N(1)$ inside the exponent. The constant $c$ depends explicitly on the problem parameters (including the unknown arm distribution) through a certain Fisher information distance. Even the strictly super-linear dependence on $\log(1/\delta)$ was not known and resolves a question of Grossman and Moshkovitz (FOCS 2016, SIAM Journal on Computing 2020).
TransDocAnalyser: A Framework for Offline Semi-structured Handwritten Document Analysis in the Legal Domain
Jun 03, 2023
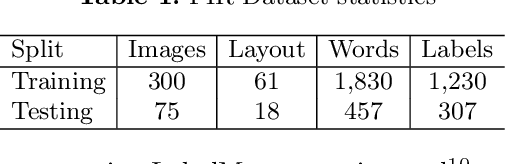

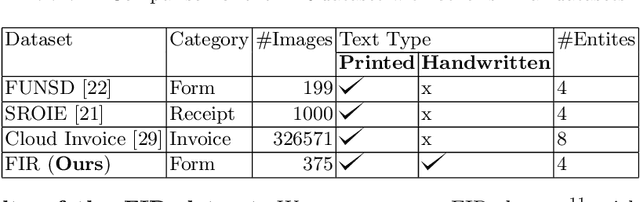
State-of-the-art offline Optical Character Recognition (OCR) frameworks perform poorly on semi-structured handwritten domain-specific documents due to their inability to localize and label form fields with domain-specific semantics. Existing techniques for semi-structured document analysis have primarily used datasets comprising invoices, purchase orders, receipts, and identity-card documents for benchmarking. In this work, we build the first semi-structured document analysis dataset in the legal domain by collecting a large number of First Information Report (FIR) documents from several police stations in India. This dataset, which we call the FIR dataset, is more challenging than most existing document analysis datasets, since it combines a wide variety of handwritten text with printed text. We also propose an end-to-end framework for offline processing of handwritten semi-structured documents, and benchmark it on our novel FIR dataset. Our framework used Encoder-Decoder architecture for localizing and labelling the form fields and for recognizing the handwritten content. The encoder consists of Faster-RCNN and Vision Transformers. Further the Transformer-based decoder architecture is trained with a domain-specific tokenizer. We also propose a post-correction method to handle recognition errors pertaining to the domain-specific terms. Our proposed framework achieves state-of-the-art results on the FIR dataset outperforming several existing models
Executive Voiced Laughter and Social Approval: An Explorative Machine Learning Study
May 20, 2023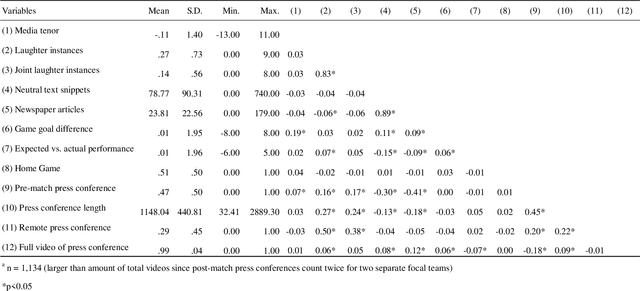
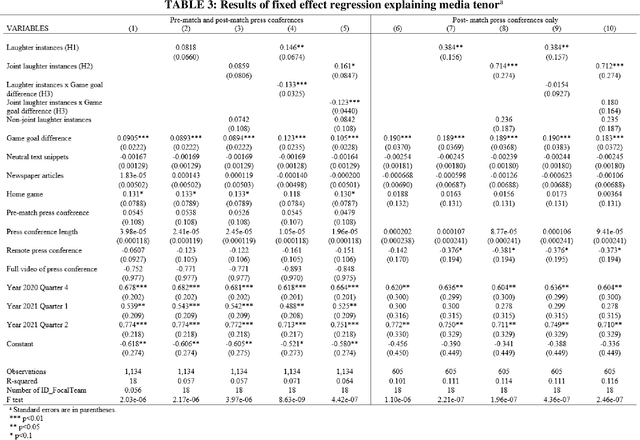
We study voiced laughter in executive communication and its effect on social approval. Integrating research on laughter, affect-as-information, and infomediaries' social evaluations of firms, we hypothesize that voiced laughter in executive communication positively affects social approval, defined as audience perceptions of affinity towards an organization. We surmise that the effect of laughter is especially strong for joint laughter, i.e., the number of instances in a given communication venue for which the focal executive and the audience laugh simultaneously. Finally, combining the notions of affect-as-information and negativity bias in human cognition, we hypothesize that the positive effect of laughter on social approval increases with bad organizational performance. We find partial support for our ideas when testing them on panel data comprising 902 German Bundesliga soccer press conferences and media tenor, applying state-of-the-art machine learning approaches for laughter detection as well as sentiment analysis. Our findings contribute to research at the nexus of executive communication, strategic leadership, and social evaluations, especially by introducing laughter as a highly consequential potential, but understudied social lubricant at the executive-infomediary interface. Our research is unique by focusing on reflexive microprocesses of social evaluations, rather than the infomediary-routines perspectives in infomediaries' evaluations. We also make methodological contributions.
Differentially private low-dimensional representation of high-dimensional data
May 26, 2023Differentially private synthetic data provide a powerful mechanism to enable data analysis while protecting sensitive information about individuals. However, when the data lie in a high-dimensional space, the accuracy of the synthetic data suffers from the curse of dimensionality. In this paper, we propose a differentially private algorithm to generate low-dimensional synthetic data efficiently from a high-dimensional dataset with a utility guarantee with respect to the Wasserstein distance. A key step of our algorithm is a private principal component analysis (PCA) procedure with a near-optimal accuracy bound that circumvents the curse of dimensionality. Different from the standard perturbation analysis using the Davis-Kahan theorem, our analysis of private PCA works without assuming the spectral gap for the sample covariance matrix.
Multi-Scale Attention for Audio Question Answering
May 29, 2023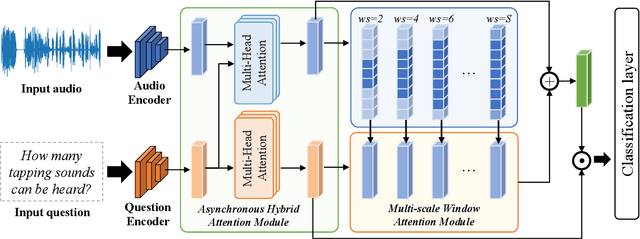
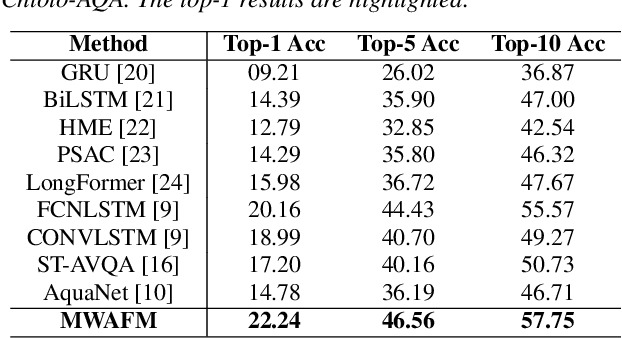
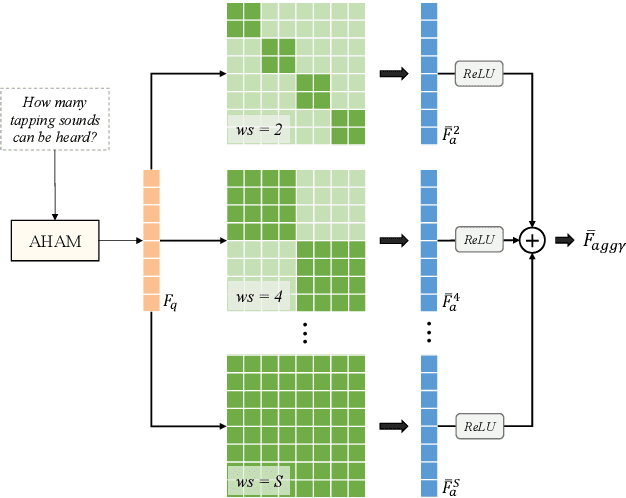
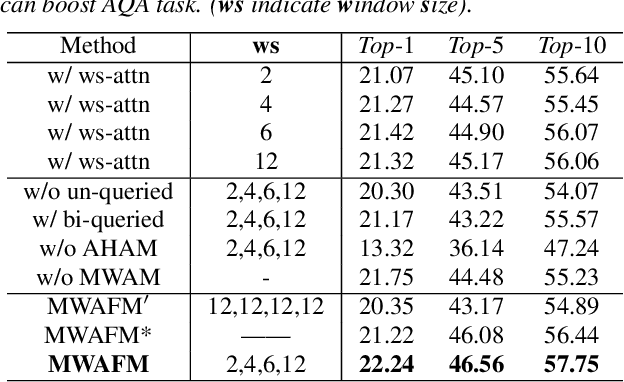
Audio question answering (AQA), acting as a widely used proxy task to explore scene understanding, has got more attention. The AQA is challenging for it requires comprehensive temporal reasoning from different scales' events of an audio scene. However, existing methods mostly extend the structures of visual question answering task to audio ones in a simple pattern but may not perform well when perceiving a fine-grained audio scene. To this end, we present a Multi-scale Window Attention Fusion Model (MWAFM) consisting of an asynchronous hybrid attention module and a multi-scale window attention module. The former is designed to aggregate unimodal and cross-modal temporal contexts, while the latter captures sound events of varying lengths and their temporal dependencies for a more comprehensive understanding. Extensive experiments are conducted to demonstrate that the proposed MWAFM can effectively explore temporal information to facilitate AQA in the fine-grained scene.Code: https://github.com/GeWu-Lab/MWAFM
Hierarchical Neural Memory Network for Low Latency Event Processing
May 29, 2023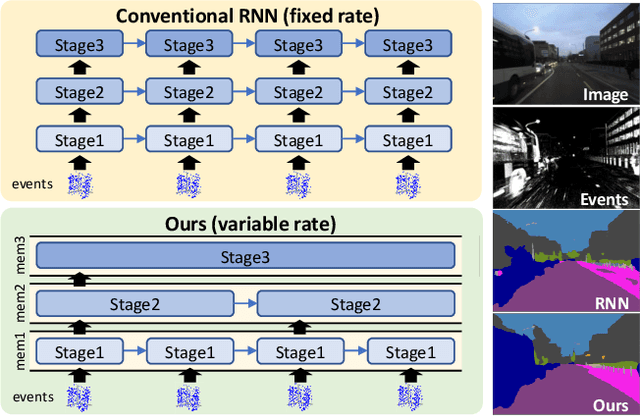
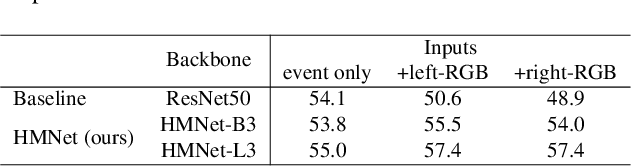
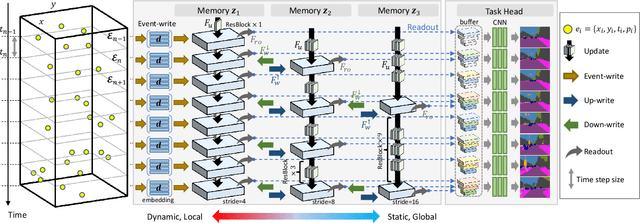
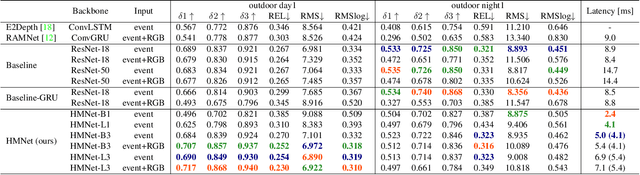
This paper proposes a low latency neural network architecture for event-based dense prediction tasks. Conventional architectures encode entire scene contents at a fixed rate regardless of their temporal characteristics. Instead, the proposed network encodes contents at a proper temporal scale depending on its movement speed. We achieve this by constructing temporal hierarchy using stacked latent memories that operate at different rates. Given low latency event steams, the multi-level memories gradually extract dynamic to static scene contents by propagating information from the fast to the slow memory modules. The architecture not only reduces the redundancy of conventional architectures but also exploits long-term dependencies. Furthermore, an attention-based event representation efficiently encodes sparse event streams into the memory cells. We conduct extensive evaluations on three event-based dense prediction tasks, where the proposed approach outperforms the existing methods on accuracy and latency, while demonstrating effective event and image fusion capabilities. The code is available at https://hamarh.github.io/hmnet/