 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Coordination in Social Embodied Rearrangement
May 31, 2023

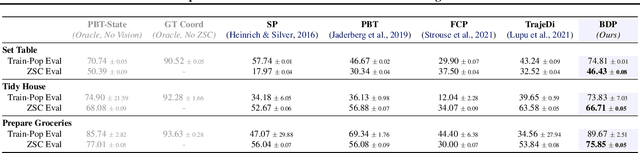
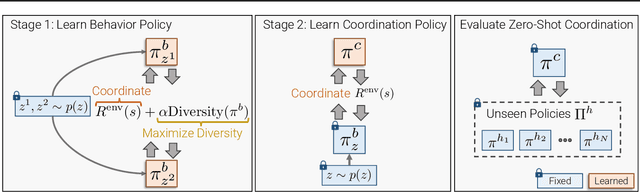
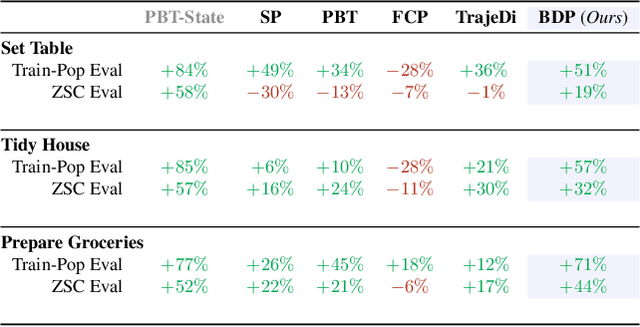
We present the task of "Social Rearrangement", consisting of cooperative everyday tasks like setting up the dinner table, tidying a house or unpacking groceries in a simulated multi-agent environment. In Social Rearrangement, two robots coordinate to complete a long-horizon task, using onboard sensing and egocentric observations, and no privileged information about the environment. We study zero-shot coordination (ZSC) in this task, where an agent collaborates with a new partner, emulating a scenario where a robot collaborates with a new human partner. Prior ZSC approaches struggle to generalize in our complex and visually rich setting, and on further analysis, we find that they fail to generate diverse coordination behaviors at training time. To counter this, we propose Behavior Diversity Play (BDP), a novel ZSC approach that encourages diversity through a discriminability objective. Our results demonstrate that BDP learns adaptive agents that can tackle visual coordination, and zero-shot generalize to new partners in unseen environments, achieving 35% higher success and 32% higher efficiency compared to baselines.
IDAS: Intent Discovery with Abstractive Summarization
May 31, 2023
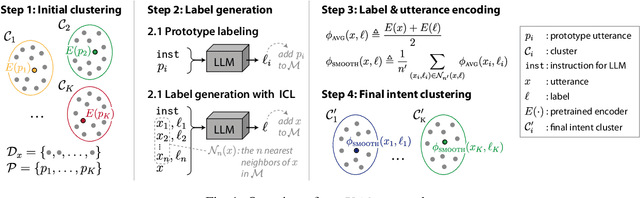
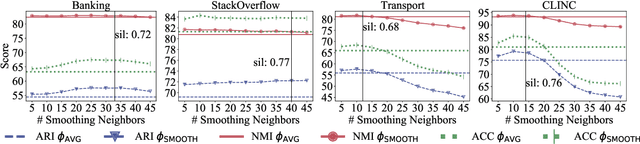
Intent discovery is the task of inferring latent intents from a set of unlabeled utterances, and is a useful step towards the efficient creation of new conversational agents. We show that recent competitive methods in intent discovery can be outperformed by clustering utterances based on abstractive summaries, i.e., "labels", that retain the core elements while removing non-essential information. We contribute the IDAS approach, which collects a set of descriptive utterance labels by prompting a Large Language Model, starting from a well-chosen seed set of prototypical utterances, to bootstrap an In-Context Learning procedure to generate labels for non-prototypical utterances. The utterances and their resulting noisy labels are then encoded by a frozen pre-trained encoder, and subsequently clustered to recover the latent intents. For the unsupervised task (without any intent labels) IDAS outperforms the state-of-the-art by up to +7.42% in standard cluster metrics for the Banking, StackOverflow, and Transport datasets. For the semi-supervised task (with labels for a subset of intents) IDAS surpasses 2 recent methods on the CLINC benchmark without even using labeled data.
Physics-Informed Ensemble Representation for Light-Field Image Super-Resolution
May 31, 2023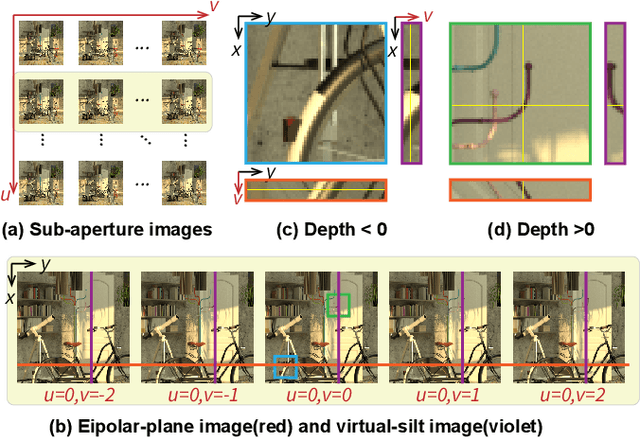
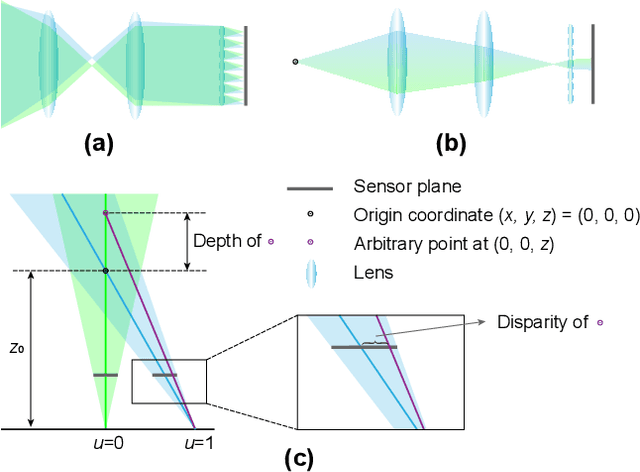
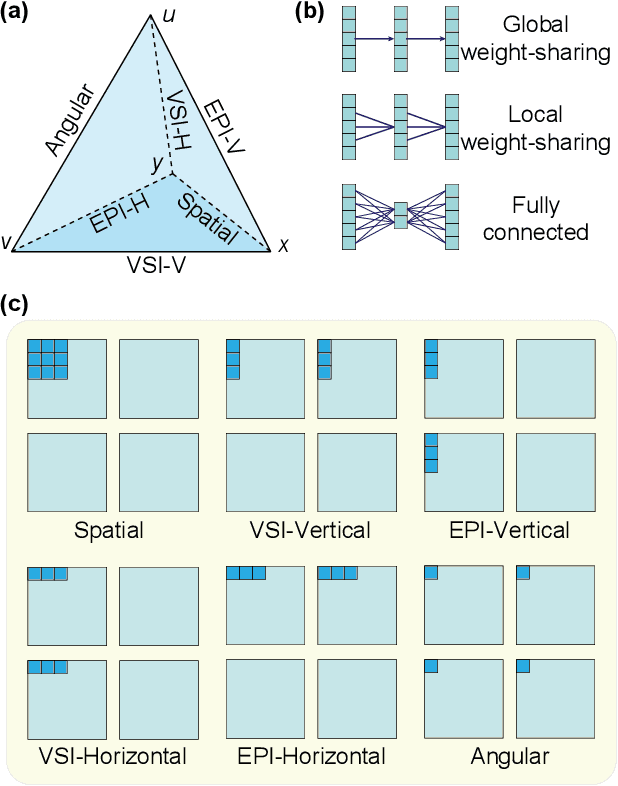
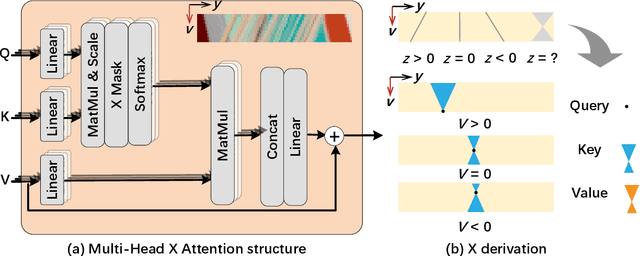
Recent learning-based approaches have achieved significant progress in light field (LF) image super-resolution (SR) by exploring convolution-based or transformer-based network structures. However, LF imaging has many intrinsic physical priors that have not been fully exploited. In this paper, we analyze the coordinate transformation of the LF imaging process to reveal the geometric relationship in the LF images. Based on such geometric priors, we introduce a new LF subspace of virtual-slit images (VSI) that provide sub-pixel information complementary to sub-aperture images. To leverage the abundant correlation across the four-dimensional data with manageable complexity, we propose learning ensemble representation of all $C_4^2$ LF subspaces for more effective feature extraction. To super-resolve image structures from undersampled LF data, we propose a geometry-aware decoder, named EPIXformer, which constrains the transformer's operational searching regions with a LF physical prior. Experimental results on both spatial and angular SR tasks demonstrate that the proposed method outperforms other state-of-the-art schemes, especially in handling various disparities.
Lottery Tickets in Evolutionary Optimization: On Sparse Backpropagation-Free Trainability
May 31, 2023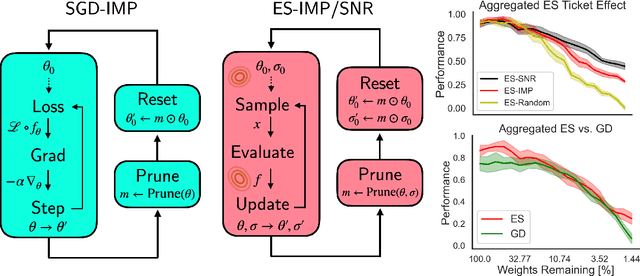
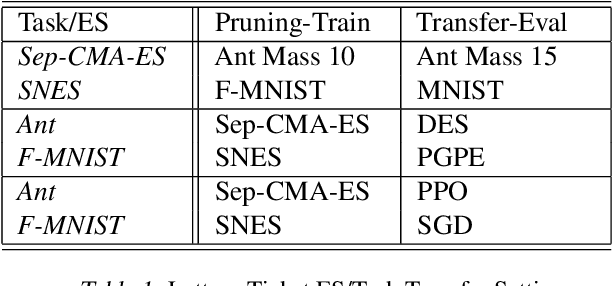
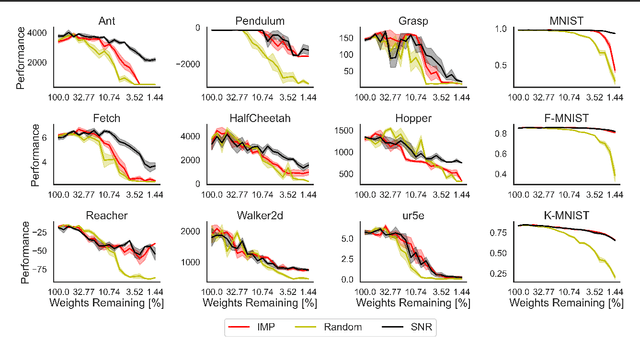
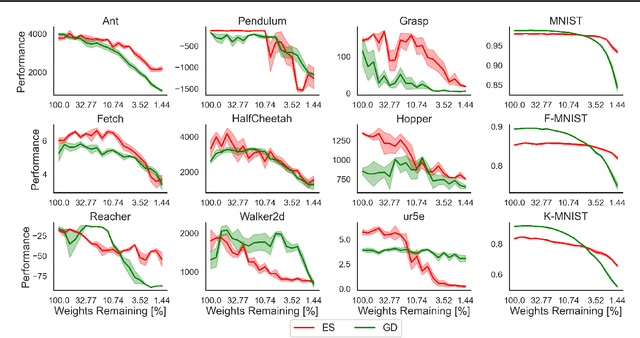
Is the lottery ticket phenomenon an idiosyncrasy of gradient-based training or does it generalize to evolutionary optimization? In this paper we establish the existence of highly sparse trainable initializations for evolution strategies (ES) and characterize qualitative differences compared to gradient descent (GD)-based sparse training. We introduce a novel signal-to-noise iterative pruning procedure, which incorporates loss curvature information into the network pruning step. This can enable the discovery of even sparser trainable network initializations when using black-box evolution as compared to GD-based optimization. Furthermore, we find that these initializations encode an inductive bias, which transfers across different ES, related tasks and even to GD-based training. Finally, we compare the local optima resulting from the different optimization paradigms and sparsity levels. In contrast to GD, ES explore diverse and flat local optima and do not preserve linear mode connectivity across sparsity levels and independent runs. The results highlight qualitative differences between evolution and gradient-based learning dynamics, which can be uncovered by the study of iterative pruning procedures.
Control4D: Dynamic Portrait Editing by Learning 4D GAN from 2D Diffusion-based Editor
May 31, 2023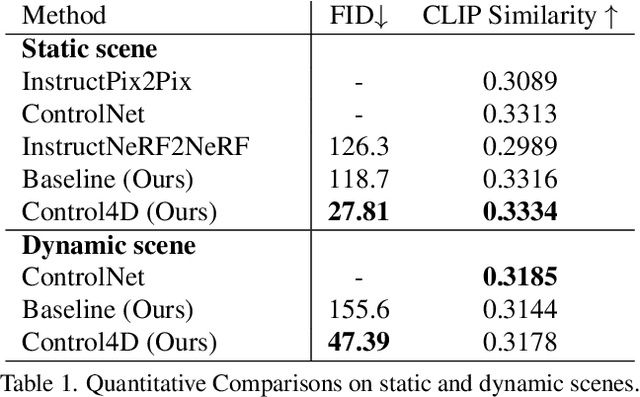
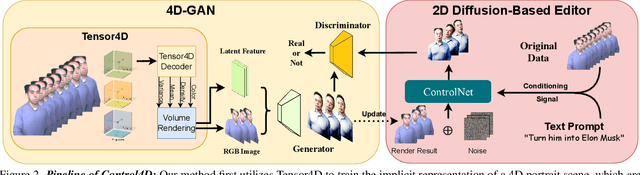
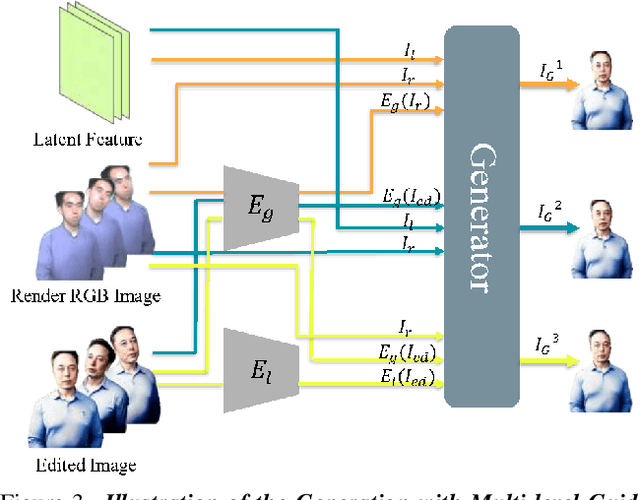

Recent years have witnessed considerable achievements in editing images with text instructions. When applying these editors to dynamic scene editing, the new-style scene tends to be temporally inconsistent due to the frame-by-frame nature of these 2D editors. To tackle this issue, we propose Control4D, a novel approach for high-fidelity and temporally consistent 4D portrait editing. Control4D is built upon an efficient 4D representation with a 2D diffusion-based editor. Instead of using direct supervisions from the editor, our method learns a 4D GAN from it and avoids the inconsistent supervision signals. Specifically, we employ a discriminator to learn the generation distribution based on the edited images and then update the generator with the discrimination signals. For more stable training, multi-level information is extracted from the edited images and used to facilitate the learning of the generator. Experimental results show that Control4D surpasses previous approaches and achieves more photo-realistic and consistent 4D editing performances. The link to our project website is https://control4darxiv.github.io.
Diagnosis and Prognosis of Head and Neck Cancer Patients using Artificial Intelligence
May 31, 2023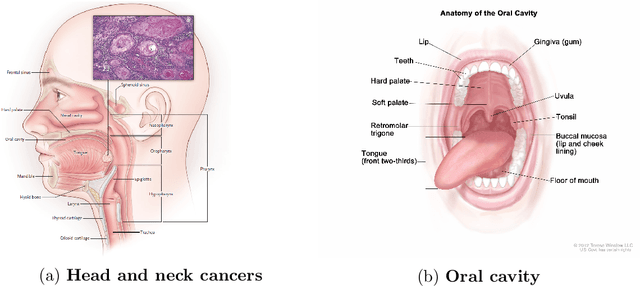
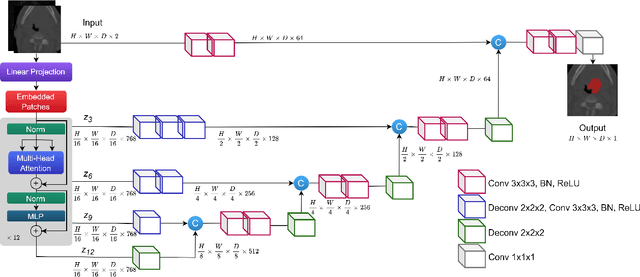

Cancer is one of the most life-threatening diseases worldwide, and head and neck (H&N) cancer is a prevalent type with hundreds of thousands of new cases recorded each year. Clinicians use medical imaging modalities such as computed tomography and positron emission tomography to detect the presence of a tumor, and they combine that information with clinical data for patient prognosis. The process is mostly challenging and time-consuming. Machine learning and deep learning can automate these tasks to help clinicians with highly promising results. This work studies two approaches for H&N tumor segmentation: (i) exploration and comparison of vision transformer (ViT)-based and convolutional neural network-based models; and (ii) proposal of a novel 2D perspective to working with 3D data. Furthermore, this work proposes two new architectures for the prognosis task. An ensemble of several models predicts patient outcomes (which won the HECKTOR 2021 challenge prognosis task), and a ViT-based framework concurrently performs patient outcome prediction and tumor segmentation, which outperforms the ensemble model.
A Hybrid Semantic-Geometric Approach for Clutter-Resistant Floorplan Generation from Building Point Clouds
May 15, 2023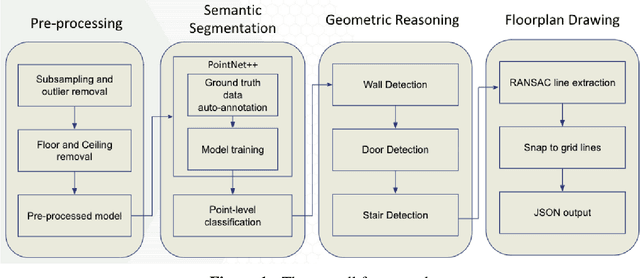
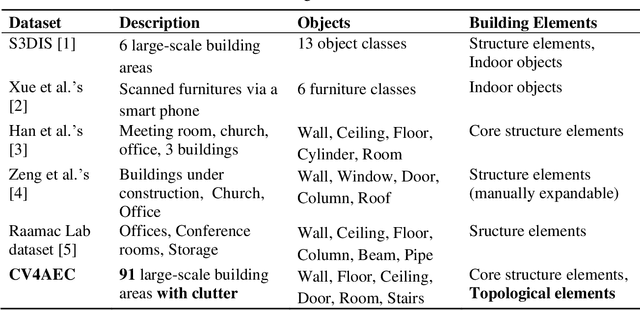
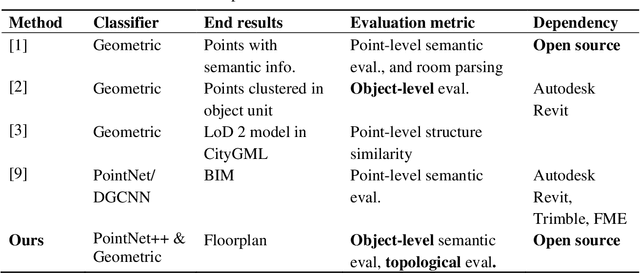

Building Information Modeling (BIM) technology is a key component of modern construction engineering and project management workflows. As-is BIM models that represent the spatial reality of a project site can offer crucial information to stakeholders for construction progress monitoring, error checking, and building maintenance purposes. Geometric methods for automatically converting raw scan data into BIM models (Scan-to-BIM) often fail to make use of higher-level semantic information in the data. Whereas, semantic segmentation methods only output labels at the point level without creating object level models that is necessary for BIM. To address these issues, this research proposes a hybrid semantic-geometric approach for clutter-resistant floorplan generation from laser-scanned building point clouds. The input point clouds are first pre-processed by normalizing the coordinate system and removing outliers. Then, a semantic segmentation network based on PointNet++ is used to label each point as ceiling, floor, wall, door, stair, and clutter. The clutter points are removed whereas the wall, door, and stair points are used for 2D floorplan generation. A region-growing segmentation algorithm paired with geometric reasoning rules is applied to group the points together into individual building elements. Finally, a 2-fold Random Sample Consensus (RANSAC) algorithm is applied to parameterize the building elements into 2D lines which are used to create the output floorplan. The proposed method is evaluated using the metrics of precision, recall, Intersection-over-Union (IOU), Betti error, and warping error.
Continually Improving Extractive QA via Human Feedback
May 21, 2023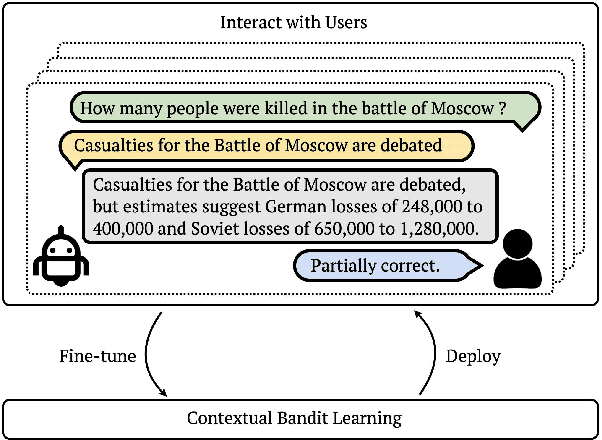

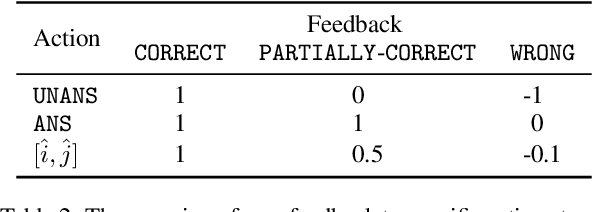
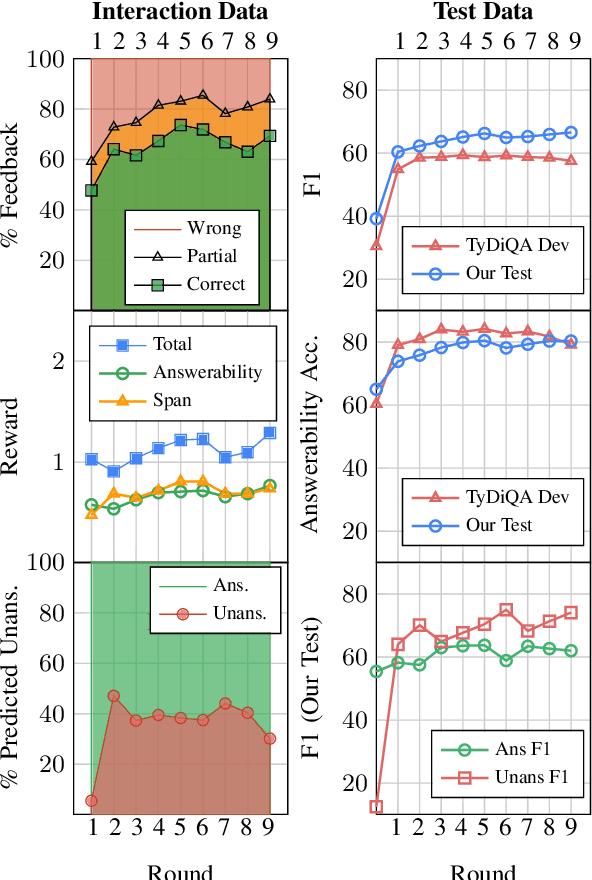
We study continually improving an extractive question answering (QA) system via human user feedback. We design and deploy an iterative approach, where information-seeking users ask questions, receive model-predicted answers, and provide feedback. We conduct experiments involving thousands of user interactions under diverse setups to broaden the understanding of learning from feedback over time. Our experiments show effective improvement from user feedback of extractive QA models over time across different data regimes, including significant potential for domain adaptation.
A Knowledge Graph Perspective on Supply Chain Resilience
May 15, 2023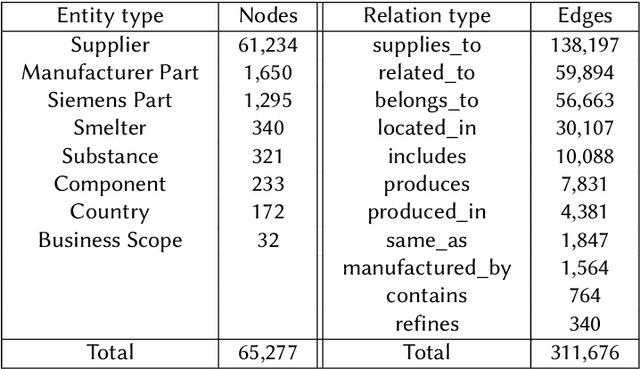
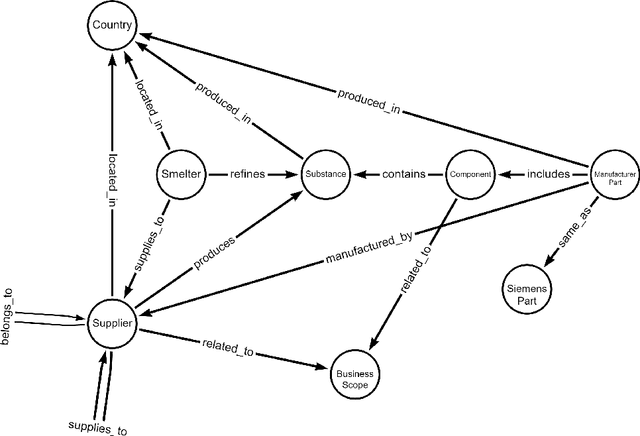
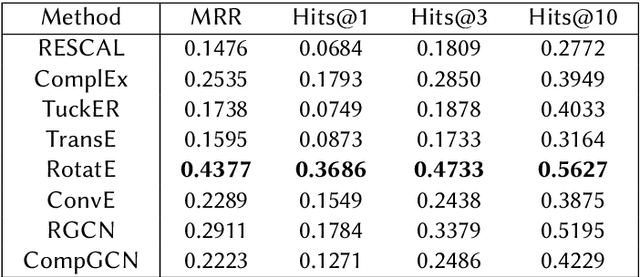
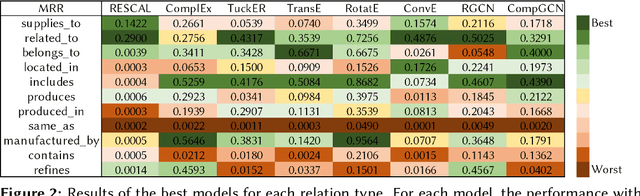
Global crises and regulatory developments require increased supply chain transparency and resilience. Companies do not only need to react to a dynamic environment but have to act proactively and implement measures to prevent production delays and reduce risks in the supply chains. However, information about supply chains, especially at the deeper levels, is often intransparent and incomplete, making it difficult to obtain precise predictions about prospective risks. By connecting different data sources, we model the supply network as a knowledge graph and achieve transparency up to tier-3 suppliers. To predict missing information in the graph, we apply state-of-the-art knowledge graph completion methods and attain a mean reciprocal rank of 0.4377 with the best model. Further, we apply graph analysis algorithms to identify critical entities in the supply network, supporting supply chain managers in automated risk identification.
Investigating Pre-trained Audio Encoders in the Low-Resource Condition
May 28, 2023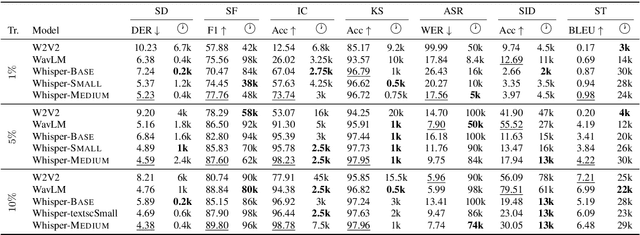

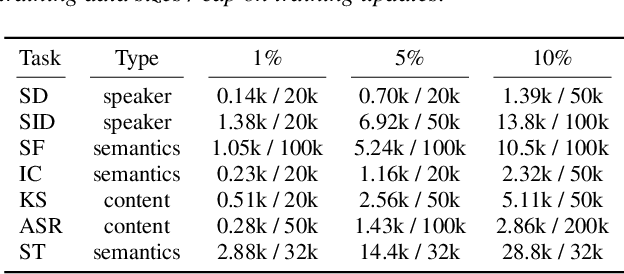
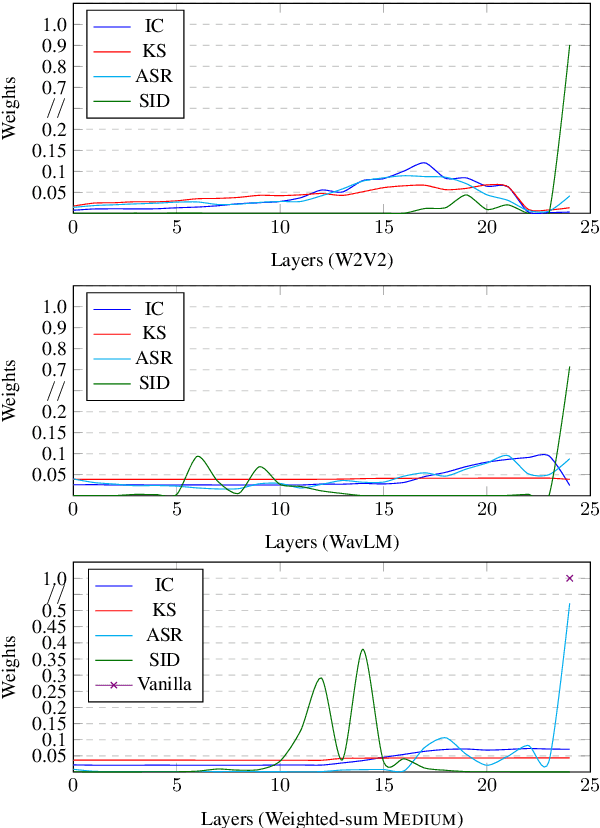
Pre-trained speech encoders have been central to pushing state-of-the-art results across various speech understanding and generation tasks. Nonetheless, the capabilities of these encoders in low-resource settings are yet to be thoroughly explored. To address this, we conduct a comprehensive set of experiments using a representative set of 3 state-of-the-art encoders (Wav2vec2, WavLM, Whisper) in the low-resource setting across 7 speech understanding and generation tasks. We provide various quantitative and qualitative analyses on task performance, convergence speed, and representational properties of the encoders. We observe a connection between the pre-training protocols of these encoders and the way in which they capture information in their internal layers. In particular, we observe the Whisper encoder exhibits the greatest low-resource capabilities on content-driven tasks in terms of performance and convergence speed.