 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CTRL: Connect Tabular and Language Model for CTR Prediction
Jun 08, 2023
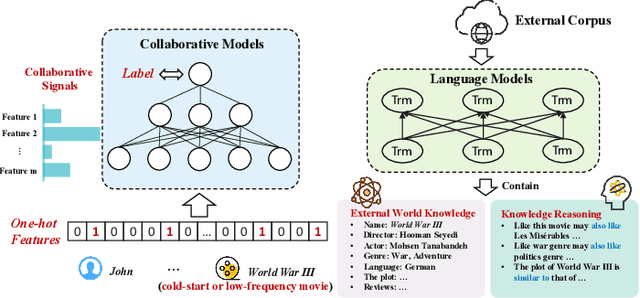

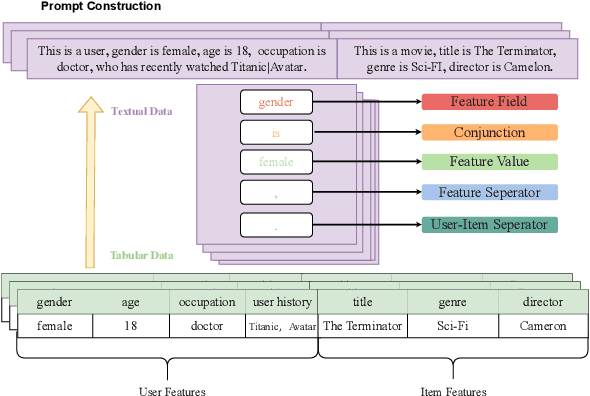
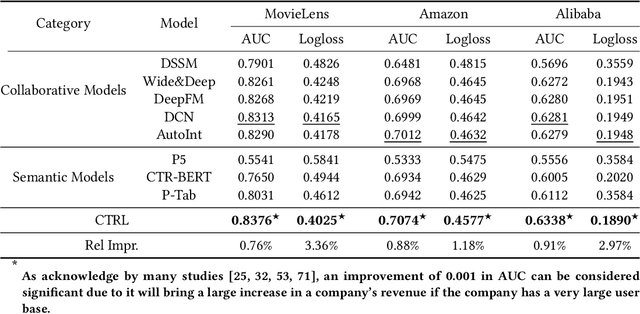
Traditional click-through rate (CTR) prediction models convert the tabular data into one-hot vectors and leverage the collaborative relations among features for inferring user's preference over items. This modeling paradigm discards the essential semantic information. Though some recent works like P5 and M6-Rec have explored the potential of using Pre-trained Language Models (PLMs) to extract semantic signals for CTR prediction, they are computationally expensive and suffer from low efficiency. Besides, the beneficial collaborative relations are not considered, hindering the recommendation performance. To solve these problems, in this paper, we propose a novel framework \textbf{CTRL}, which is industrial friendly and model-agnostic with high training and inference efficiency. Specifically, the original tabular data is first converted into textual data. Both tabular data and converted textual data are regarded as two different modalities and are separately fed into the collaborative CTR model and pre-trained language model. A cross-modal knowledge alignment procedure is performed to fine-grained align and integrate the collaborative and semantic signals, and the lightweight collaborative model can be deployed online for efficient serving after fine-tuned with supervised signals. Experimental results on three public datasets show that CTRL outperforms the SOTA CTR models significantly. Moreover, we further verify its effectiveness on a large-scale industrial recommender system.
Multi-Modal Classifiers for Open-Vocabulary Object Detection
Jun 08, 2023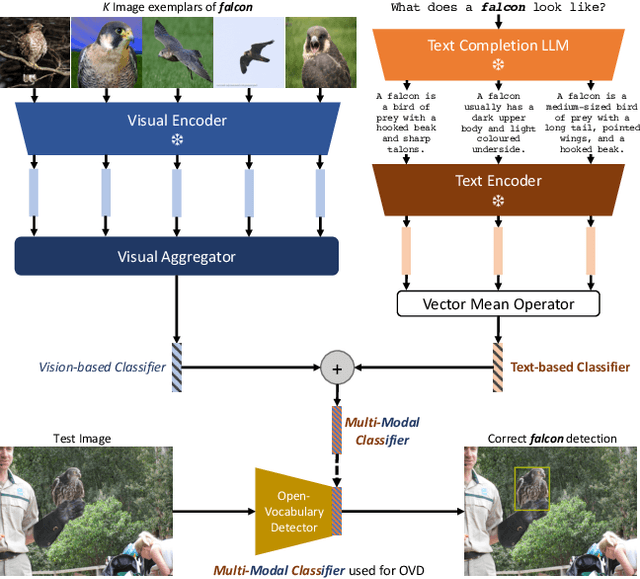
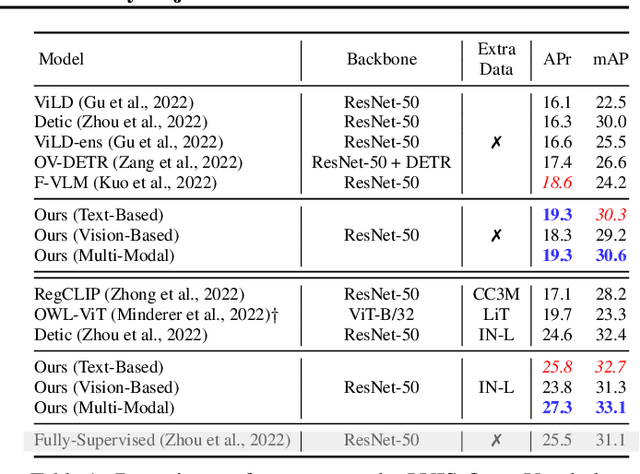
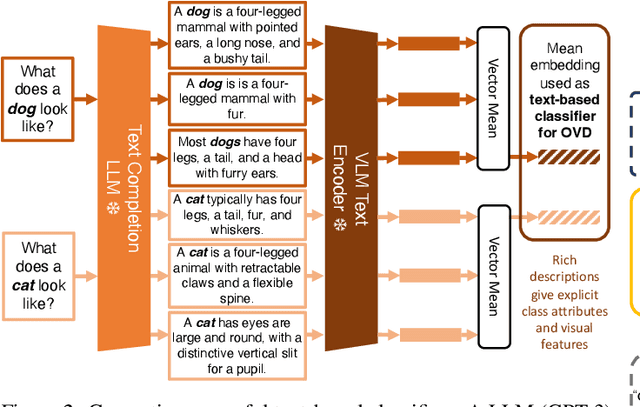
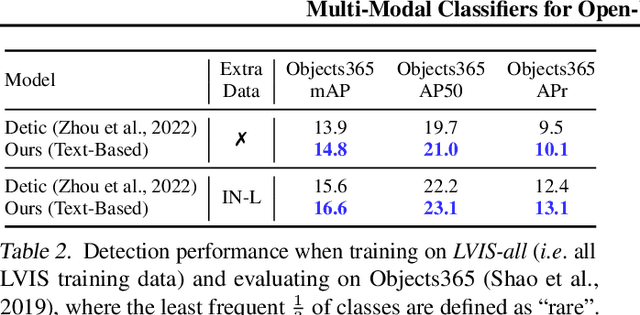
The goal of this paper is open-vocabulary object detection (OVOD) $\unicode{x2013}$ building a model that can detect objects beyond the set of categories seen at training, thus enabling the user to specify categories of interest at inference without the need for model retraining. We adopt a standard two-stage object detector architecture, and explore three ways for specifying novel categories: via language descriptions, via image exemplars, or via a combination of the two. We make three contributions: first, we prompt a large language model (LLM) to generate informative language descriptions for object classes, and construct powerful text-based classifiers; second, we employ a visual aggregator on image exemplars that can ingest any number of images as input, forming vision-based classifiers; and third, we provide a simple method to fuse information from language descriptions and image exemplars, yielding a multi-modal classifier. When evaluating on the challenging LVIS open-vocabulary benchmark we demonstrate that: (i) our text-based classifiers outperform all previous OVOD works; (ii) our vision-based classifiers perform as well as text-based classifiers in prior work; (iii) using multi-modal classifiers perform better than either modality alone; and finally, (iv) our text-based and multi-modal classifiers yield better performance than a fully-supervised detector.
MIMIC-IT: Multi-Modal In-Context Instruction Tuning
Jun 08, 2023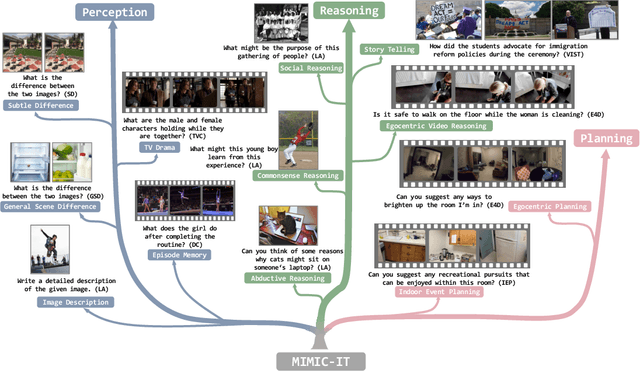
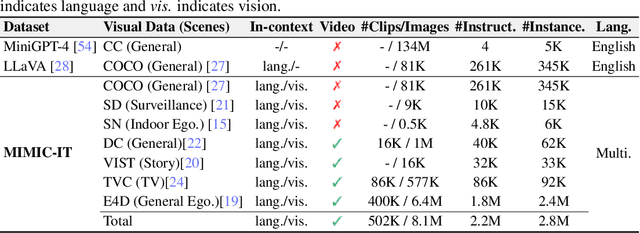

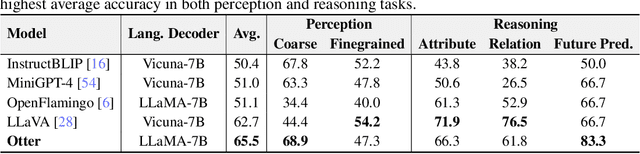
High-quality instructions and responses are essential for the zero-shot performance of large language models on interactive natural language tasks. For interactive vision-language tasks involving intricate visual scenes, a large quantity of diverse and creative instruction-response pairs should be imperative to tune vision-language models (VLMs). Nevertheless, the current availability of vision-language instruction-response pairs in terms of quantity, diversity, and creativity remains limited, posing challenges to the generalization of interactive VLMs. Here we present MultI-Modal In-Context Instruction Tuning (MIMIC-IT), a dataset comprising 2.8 million multimodal instruction-response pairs, with 2.2 million unique instructions derived from images and videos. Each pair is accompanied by multi-modal in-context information, forming conversational contexts aimed at empowering VLMs in perception, reasoning, and planning. The instruction-response collection process, dubbed as Syphus, is scaled using an automatic annotation pipeline that combines human expertise with GPT's capabilities. Using the MIMIC-IT dataset, we train a large VLM named Otter. Based on extensive evaluations conducted on vision-language benchmarks, it has been observed that Otter demonstrates remarkable proficiency in multi-modal perception, reasoning, and in-context learning. Human evaluation reveals it effectively aligns with the user's intentions. We release the MIMIC-IT dataset, instruction-response collection pipeline, benchmarks, and the Otter model.
Neuro-Symbolic Approaches for Context-Aware Human Activity Recognition
Jun 08, 2023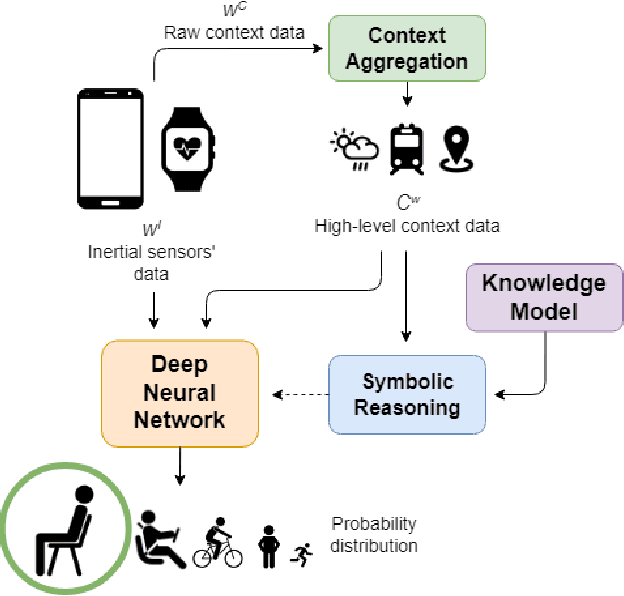
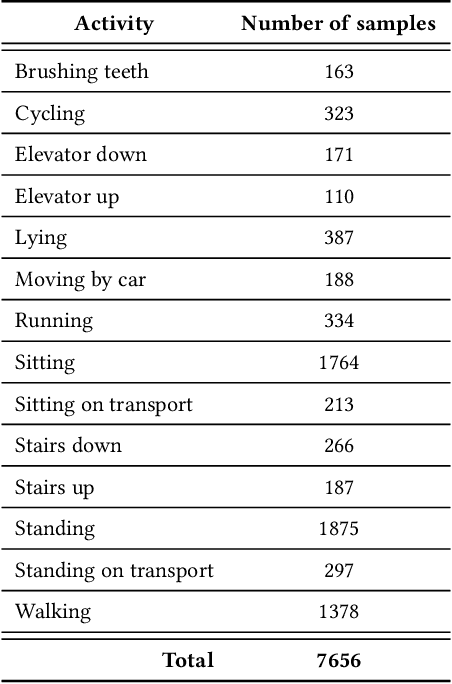
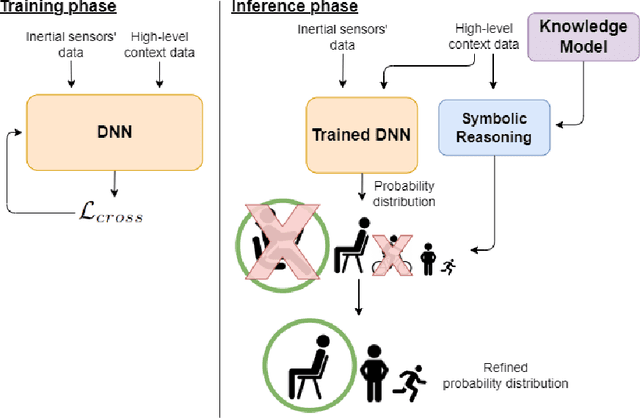
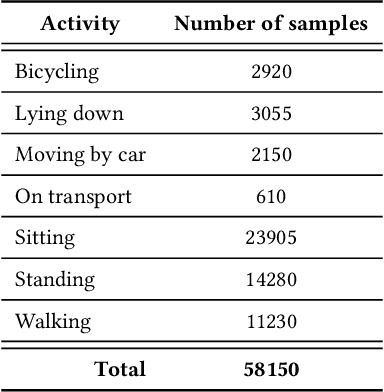
Deep Learning models are a standard solution for sensor-based Human Activity Recognition (HAR), but their deployment is often limited by labeled data scarcity and models' opacity. Neuro-Symbolic AI (NeSy) provides an interesting research direction to mitigate these issues by infusing knowledge about context information into HAR deep learning classifiers. However, existing NeSy methods for context-aware HAR require computationally expensive symbolic reasoners during classification, making them less suitable for deployment on resource-constrained devices (e.g., mobile devices). Additionally, NeSy approaches for context-aware HAR have never been evaluated on in-the-wild datasets, and their generalization capabilities in real-world scenarios are questionable. In this work, we propose a novel approach based on a semantic loss function that infuses knowledge constraints in the HAR model during the training phase, avoiding symbolic reasoning during classification. Our results on scripted and in-the-wild datasets show the impact of different semantic loss functions in outperforming a purely data-driven model. We also compare our solution with existing NeSy methods and analyze each approach's strengths and weaknesses. Our semantic loss remains the only NeSy solution that can be deployed as a single DNN without the need for symbolic reasoning modules, reaching recognition rates close (and better in some cases) to existing approaches.
TopoMask: Instance-Mask-Based Formulation for the Road Topology Problem via Transformer-Based Architecture
Jun 08, 2023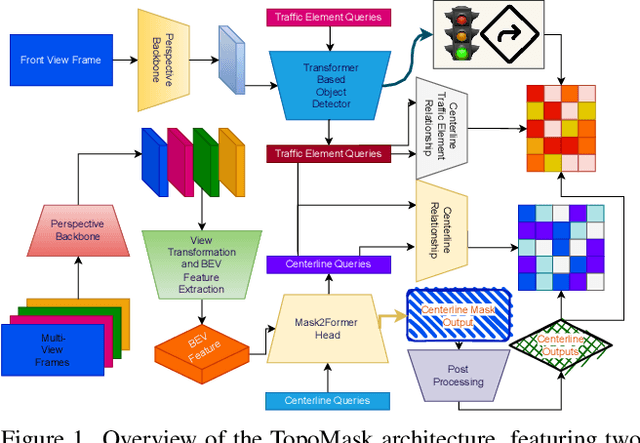



Driving scene understanding task involves detecting static elements such as lanes, traffic signs, and traffic lights, and their relationships with each other. To facilitate the development of comprehensive scene understanding solutions using multiple camera views, a new dataset called Road Genome (OpenLane-V2) has been released. This dataset allows for the exploration of complex road connections and situations where lane markings may be absent. Instead of using traditional lane markings, the lanes in this dataset are represented by centerlines, which offer a more suitable representation of lanes and their connections. In this study, we have introduced a new approach called TopoMask for predicting centerlines in road topology. Unlike existing approaches in the literature that rely on keypoints or parametric methods, TopoMask utilizes an instance-mask based formulation with a transformer-based architecture and, in order to enrich the mask instances with flow information, a direction label representation is proposed. TopoMask have ranked 4th in the OpenLane-V2 Score (OLS) and ranked 2nd in the F1 score of centerline prediction in OpenLane Topology Challenge 2023. In comparison to the current state-of-the-art method, TopoNet, the proposed method has achieved similar performance in Frechet-based lane detection and outperformed TopoNet in Chamfer-based lane detection without utilizing its scene graph neural network.
CLC: Cluster Assignment via Contrastive Representation Learning
Jun 08, 2023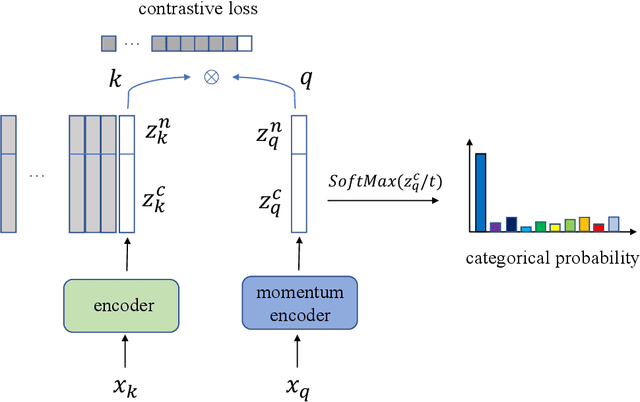
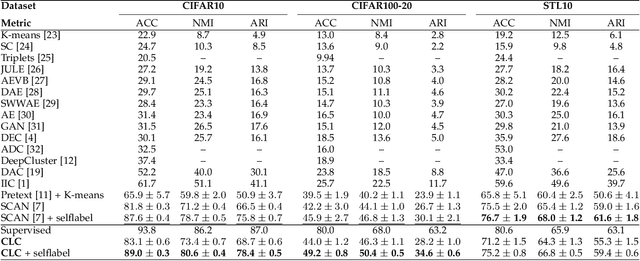
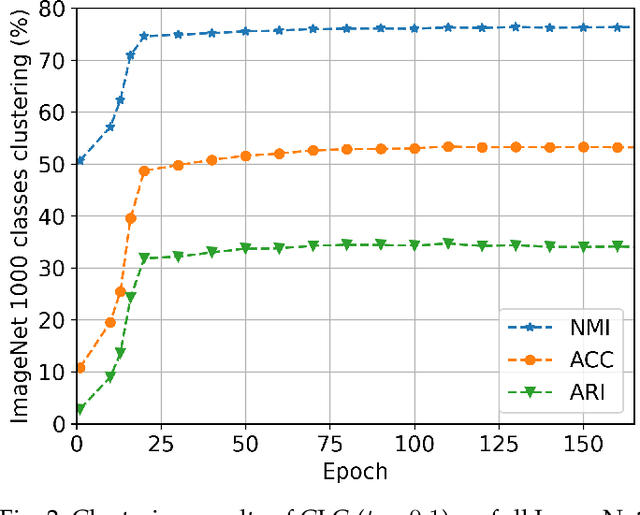

Clustering remains an important and challenging task of grouping samples into clusters without manual annotations. Recent works have achieved excellent results on small datasets by performing clustering on feature representations learned from self-supervised learning. However, for datasets with a large number of clusters, such as ImageNet, current methods still can not achieve high clustering performance. In this paper, we propose Contrastive Learning-based Clustering (CLC), which uses contrastive learning to directly learn cluster assignment. We decompose the representation into two parts: one encodes the categorical information under an equipartition constraint, and the other captures the instance-wise factors. We propose a contrastive loss using both parts of the representation. We theoretically analyze the proposed contrastive loss and reveal that CLC sets different weights for the negative samples while learning cluster assignments. Further gradient analysis shows that the larger weights tend to focus more on the hard negative samples. Therefore, the proposed loss has high expressiveness that enables us to efficiently learn cluster assignments. Experimental evaluation shows that CLC achieves overall state-of-the-art or highly competitive clustering performance on multiple benchmark datasets. In particular, we achieve 53.4% accuracy on the full ImageNet dataset and outperform existing methods by large margins (+ 10.2%).
InvPT++: Inverted Pyramid Multi-Task Transformer for Visual Scene Understanding
Jun 08, 2023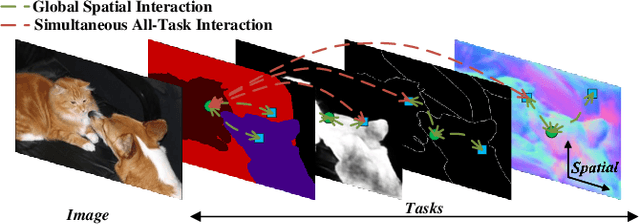

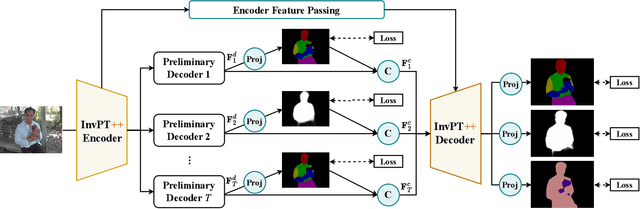
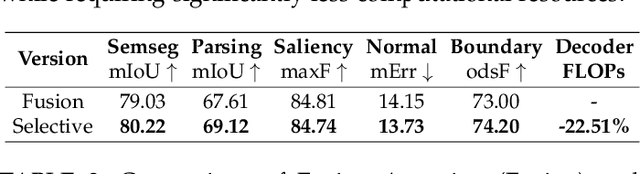
Multi-task scene understanding aims to design models that can simultaneously predict several scene understanding tasks with one versatile model. Previous studies typically process multi-task features in a more local way, and thus cannot effectively learn spatially global and cross-task interactions, which hampers the models' ability to fully leverage the consistency of various tasks in multi-task learning. To tackle this problem, we propose an Inverted Pyramid multi-task Transformer, capable of modeling cross-task interaction among spatial features of different tasks in a global context. Specifically, we first utilize a transformer encoder to capture task-generic features for all tasks. And then, we design a transformer decoder to establish spatial and cross-task interaction globally, and a novel UP-Transformer block is devised to increase the resolutions of multi-task features gradually and establish cross-task interaction at different scales. Furthermore, two types of Cross-Scale Self-Attention modules, i.e., Fusion Attention and Selective Attention, are proposed to efficiently facilitate cross-task interaction across different feature scales. An Encoder Feature Aggregation strategy is further introduced to better model multi-scale information in the decoder. Comprehensive experiments on several 2D/3D multi-task benchmarks clearly demonstrate our proposal's effectiveness, establishing significant state-of-the-art performances.
iPLAN: Intent-Aware Planning in Heterogeneous Traffic via Distributed Multi-Agent Reinforcement Learning
Jun 09, 2023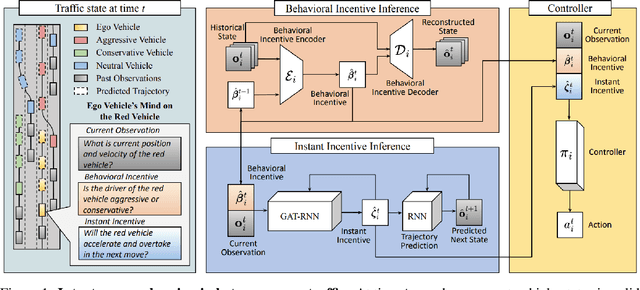
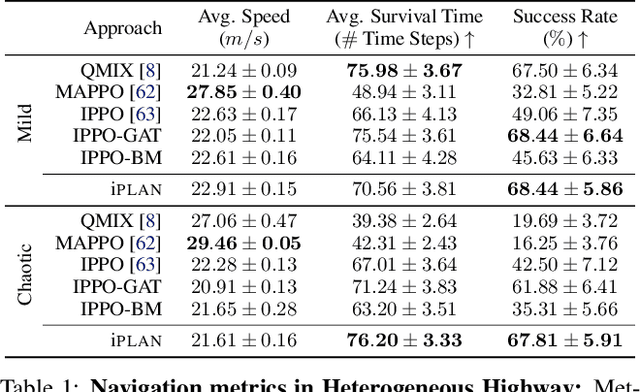
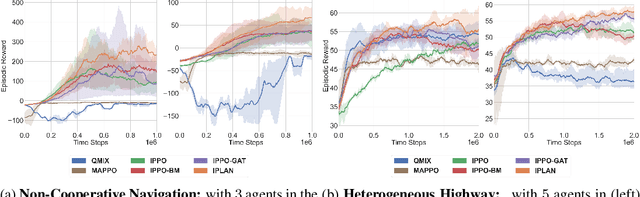
Navigating safely and efficiently in dense and heterogeneous traffic scenarios is challenging for autonomous vehicles (AVs) due to their inability to infer the behaviors or intentions of nearby drivers. In this work, we propose a distributed multi-agent reinforcement learning (MARL) algorithm with trajectory and intent prediction in dense and heterogeneous traffic scenarios. Our approach for intent-aware planning, iPLAN, allows agents to infer nearby drivers' intents solely from their local observations. We model two distinct incentives for agents' strategies: Behavioral incentives for agents' long-term planning based on their driving behavior or personality; Instant incentives for agents' short-term planning for collision avoidance based on the current traffic state. We design a two-stream inference module that allows agents to infer their opponents' incentives and incorporate their inferred information into decision-making. We perform experiments on two simulation environments, Non-Cooperative Navigation and Heterogeneous Highway. In Heterogeneous Highway, results show that, compared with centralized MARL baselines such as QMIX and MAPPO, our method yields a 4.0% and 35.7% higher episodic reward in mild and chaotic traffic, with 48.1% higher success rate and 80.6% longer survival time in chaotic traffic. We also compare with a decentralized baseline IPPO and demonstrate a higher episodic reward of 9.2% and 10.3% in mild traffic and chaotic traffic, 25.3% higher success rate, and 13.7% longer survival time.
EfficientBioAI: Making Bioimaging AI Models Efficient in Energy, Latency and Representation
Jun 09, 2023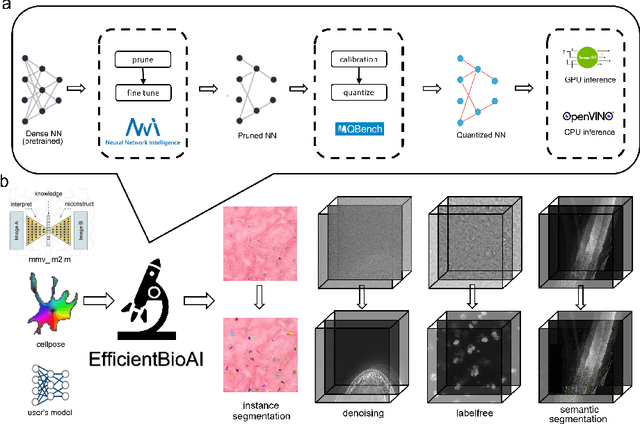
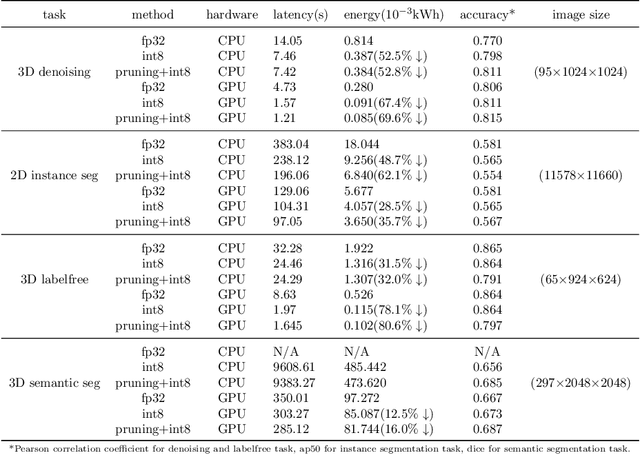
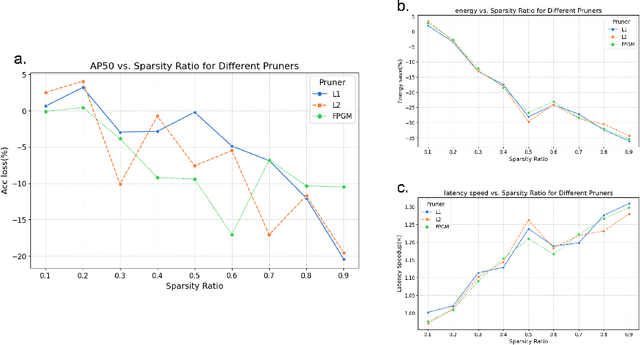
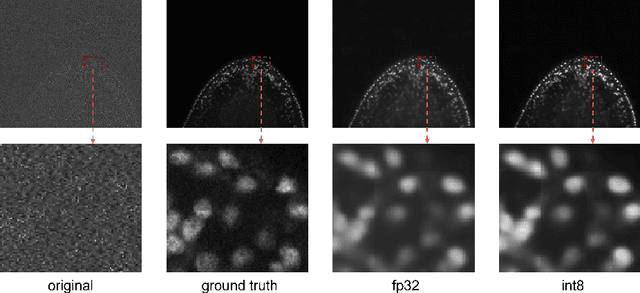
Artificial intelligence (AI) has been widely used in bioimage image analysis nowadays, but the efficiency of AI models, like the energy consumption and latency is not ignorable due to the growing model size and complexity, as well as the fast-growing analysis needs in modern biomedical studies. Like we can compress large images for efficient storage and sharing, we can also compress the AI models for efficient applications and deployment. In this work, we present EfficientBioAI, a plug-and-play toolbox that can compress given bioimaging AI models for them to run with significantly reduced energy cost and inference time on both CPU and GPU, without compromise on accuracy. In some cases, the prediction accuracy could even increase after compression, since the compression procedure could remove redundant information in the model representation and therefore reduce over-fitting. From four different bioimage analysis applications, we observed around 2-5 times speed-up during inference and 30-80$\%$ saving in energy. Cutting the runtime of large scale bioimage analysis from days to hours or getting a two-minutes bioimaging AI model inference done in near real-time will open new doors for method development and biomedical discoveries. We hope our toolbox will facilitate resource-constrained bioimaging AI and accelerate large-scale AI-based quantitative biological studies in an eco-friendly way, as well as stimulate further research on the efficiency of bioimaging AI.
Robust Active and Passive Beamforming for RIS-Assisted Full-Duplex Systems under Imperfect CSI
Jun 09, 2023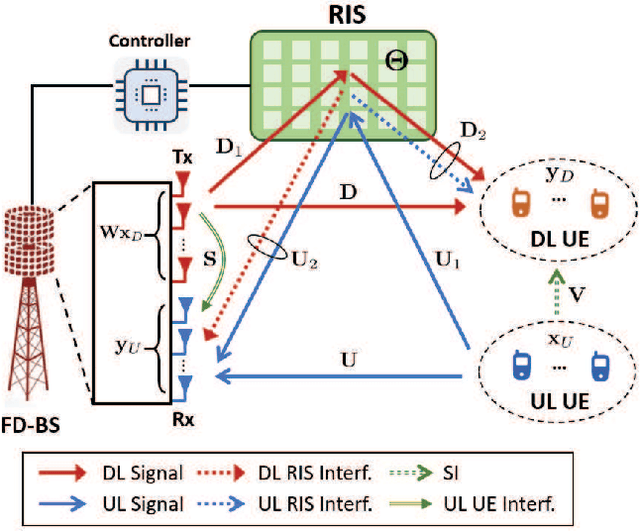
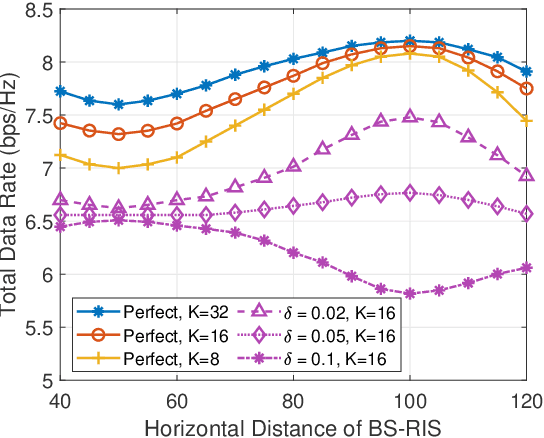
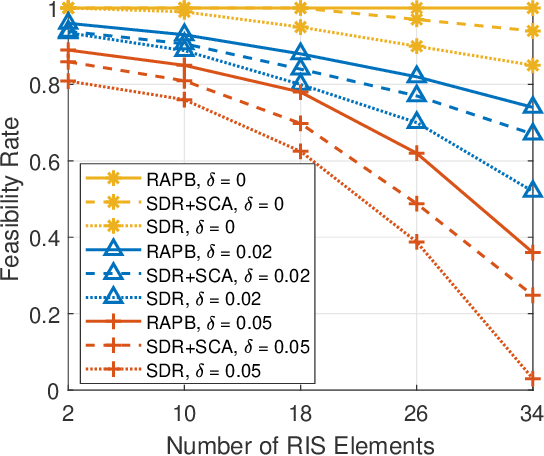
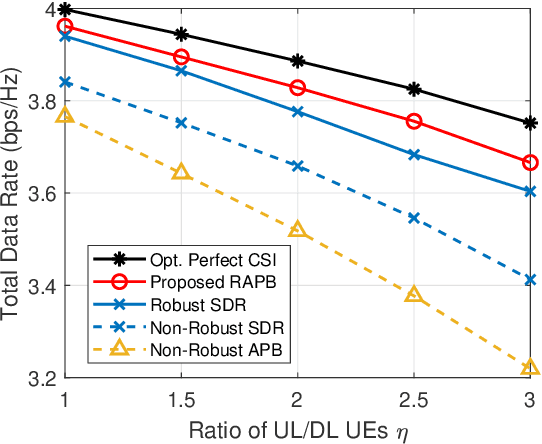
The sixth-generation (6G) wireless technology recognizes the potential of reconfigurable intelligent surfaces (RIS) as an effective technique for intelligently manipulating channel paths through reflection to serve desired users. Full-duplex (FD) systems, enabling simultaneous transmission and reception from a base station (BS), offer the theoretical advantage of doubled spectrum efficiency. However, the presence of strong self-interference (SI) in FD systems significantly degrades performance, which can be mitigated by leveraging the capabilities of RIS. Moreover, accurately obtaining channel state information (CSI) from RIS poses a critical challenge. Our objective is to maximize downlink (DL) user data rates while ensuring quality-of-service (QoS) for uplink (UL) users under imperfect CSI from reflected channels. To address this, we introduce the robust active BS and passive RIS beamforming (RAPB) scheme for RIS-FD, accounting for both SI and imperfect CSI. RAPB incorporates distributionally robust design, conditional value-at-risk (CVaR), and penalty convex-concave programming (PCCP) techniques. Additionally, RAPB extends to active and passive beamforming (APB) with perfect channel estimation. Simulation results demonstrate the UL/DL rate improvements achieved considering various levels of imperfect CSI. The proposed RAPB/APB schemes validate their effectiveness across different RIS deployment and RIS/BS configurations. Benefited from robust beamforming, RAPB outperforms existing methods in terms of non-robustness, deployment without RIS, conventional successive convex approximation, and half-duplex systems.