 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pair-Variational Autoencoders (PairVAE) for Linking and Cross-Reconstruction of Characterization Data from Complementary Structural Characterization Techniques
May 25, 2023

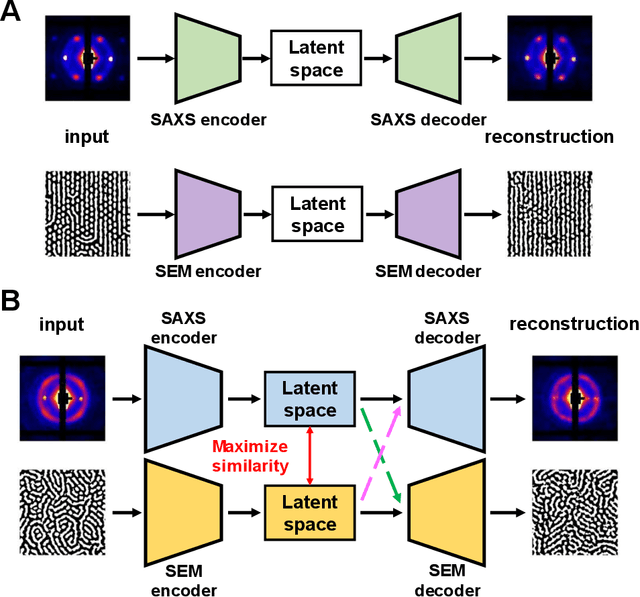
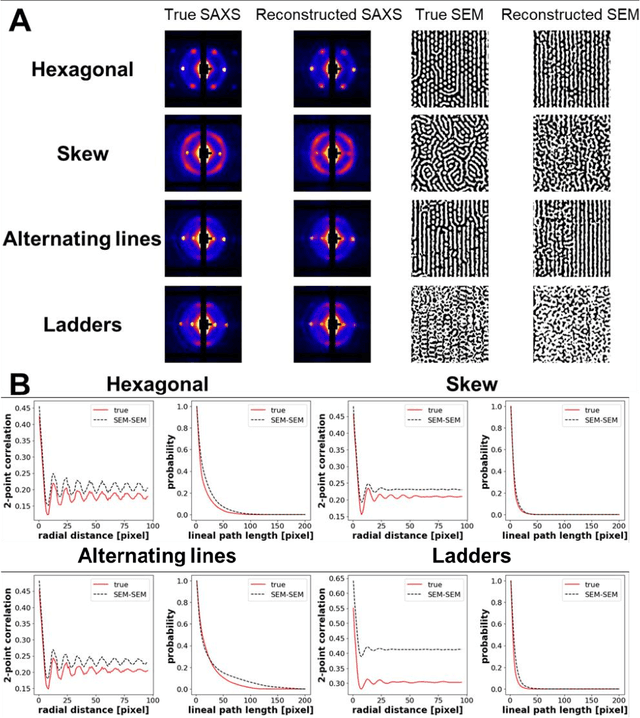
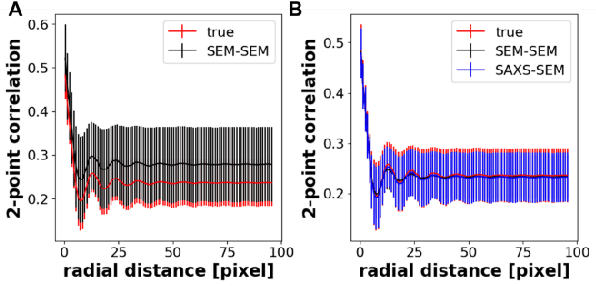
In material research, structural characterization often requires multiple complementary techniques to obtain a holistic morphological view of the synthesized material. Depending on the availability of and accessibility of the different characterization techniques (e.g., scattering, microscopy, spectroscopy), each research facility or academic research lab may have access to high-throughput capability in one technique but face limitations (sample preparation, resolution, access time) with other techniques(s). Furthermore, one type of structural characterization data may be easier to interpret than another (e.g., microscopy images are easier to interpret than small angle scattering profiles). Thus, it is useful to have machine learning models that can be trained on paired structural characterization data from multiple techniques so that the model can generate one set of characterization data from the other. In this paper we demonstrate one such machine learning workflow, PairVAE, that works with data from Small Angle X-Ray Scattering (SAXS) that presents information about bulk morphology and images from Scanning Electron Microscopy (SEM) that presents two-dimensional local structural information of the sample. Using paired SAXS and SEM data of novel block copolymer assembled morphologies [open access data from Doerk G.S., et al. Science Advances. 2023 Jan 13;9(2): eadd3687], we train our PairVAE. After successful training, we demonstrate that the PairVAE can generate SEM images of the block copolymer morphology when it takes as input that sample's corresponding SAXS 2D pattern, and vice versa. This method can be extended to other soft materials morphologies as well and serves as a valuable tool for easy interpretation of 2D SAXS patterns as well as creating a database for other downstream calculations of structure-property relationships.
FusionBooster: A Unified Image Fusion Boosting Paradigm
May 10, 2023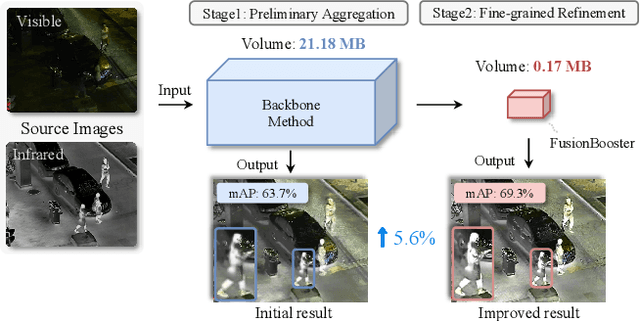
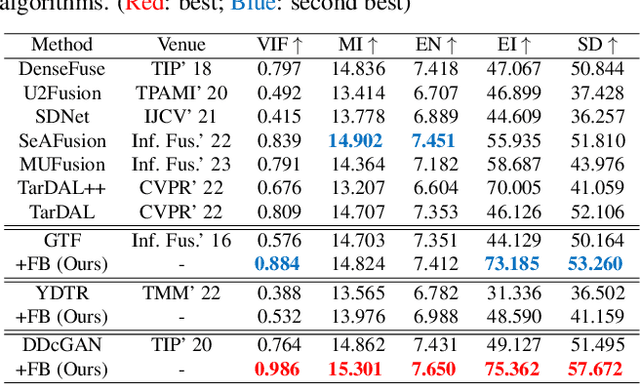
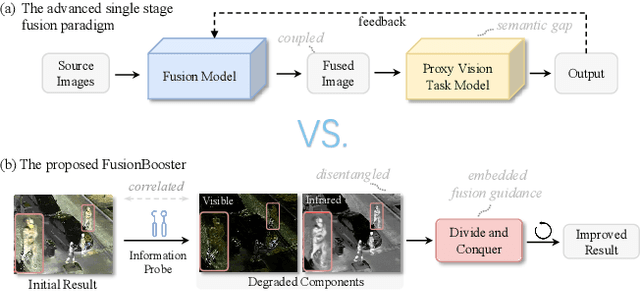
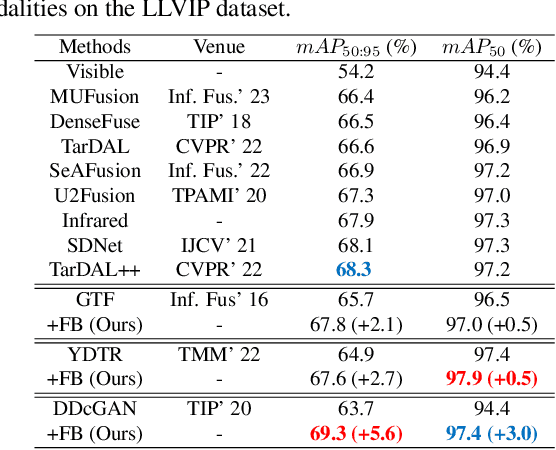
Numerous ideas have emerged for designing fusion rules in the image fusion field. Essentially, all the existing formulations try to manage the diverse levels of information communicated by the source images to achieve the best fusion result. We argue that there is a scope for improving the performance of existing methods further with the help of FusionBooster, a fusion guidance method proposed in this paper. Our booster is based on the divide and conquer strategy controlled by an information probe. The booster is composed of three building blocks: the probe units, the booster layer, and the assembling module. Given the embedding produced by a backbone method, the probe units assess the source images and divide them according to their information content. This is instrumental in identifying missing information, as a step to its recovery. The recovery of the degraded components along with the fusion guidance are embedded in the booster layer. Lastly, the assembling module is responsible for piecing these advanced components together to deliver the output. We use concise reconstruction loss functions and lightweight models to formulate the network, with marginal computational increase. The experimental results obtained in various fusion tasks, as well as downstream detection tasks, consistently demonstrate that the proposed FusionBooster significantly improves the performance. Our codes will be publicly available on the project homepage.
LMEye: An Interactive Perception Network for Large Language Models
May 05, 2023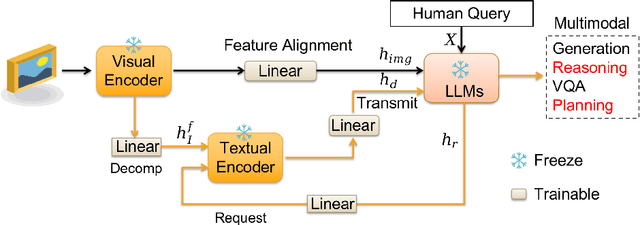
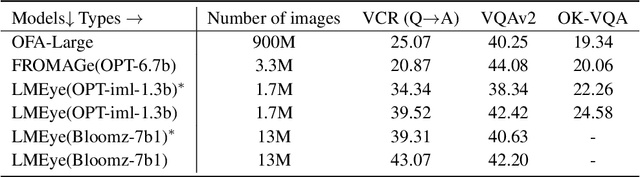

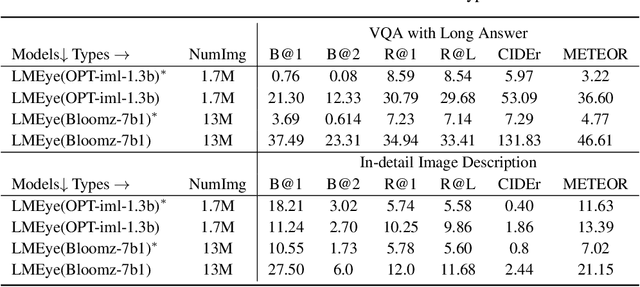
Training a Large Visual Language Model (LVLM) from scratch, like GPT-4, is resource-intensive. Our paper proposes an alternative method called LMEye, a play-plug-in Interactive Perception Network for Large Language Models (LLMs), aiming to improve the accuracy of image understanding for the LVLM. Previous methods that infuse visual information into LLMs utilize a static visual mapping network, but lack dynamic interaction between the LLMs and visual information. LMEye addresses this issue by allowing the LLM to incorporate the visual information that aligned with human instruction. Specifically, the LMEye network consists of a static visual mapping network to provide the basic perception of an image to LLMs. Then, it also contains additional linear layers responsible for acquiring requests from LLMs, decomposing image features, and transmitting the interleaved information to LLMs, respectively. In this way, LLMs act to be in charge of understanding human instructions, sending it to the interactive perception network, and generating the response based on the interleaved multimodal information. We evaluate LMEye through extensive experiments on multimodal question answering and reasoning tasks, demonstrating that it significantly improves the zero-shot performance of LLMs on multimodal tasks compared to previous methods.
Fashion CUT: Unsupervised domain adaptation for visual pattern classification in clothes using synthetic data and pseudo-labels
May 09, 2023Accurate product information is critical for e-commerce stores to allow customers to browse, filter, and search for products. Product data quality is affected by missing or incorrect information resulting in poor customer experience. While machine learning can be used to correct inaccurate or missing information, achieving high performance on fashion image classification tasks requires large amounts of annotated data, but it is expensive to generate due to labeling costs. One solution can be to generate synthetic data which requires no manual labeling. However, training a model with a dataset of solely synthetic images can lead to poor generalization when performing inference on real-world data because of the domain shift. We introduce a new unsupervised domain adaptation technique that converts images from the synthetic domain into the real-world domain. Our approach combines a generative neural network and a classifier that are jointly trained to produce realistic images while preserving the synthetic label information. We found that using real-world pseudo-labels during training helps the classifier to generalize in the real-world domain, reducing the synthetic bias. We successfully train a visual pattern classification model in the fashion domain without real-world annotations. Experiments show that our method outperforms other unsupervised domain adaptation algorithms.
Pragmatic Reasoning in Structured Signaling Games
May 17, 2023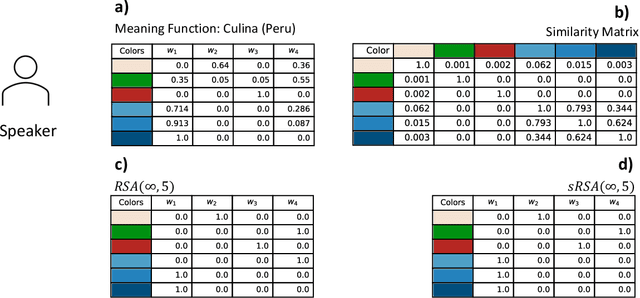

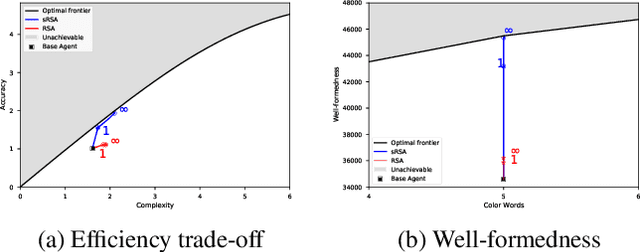
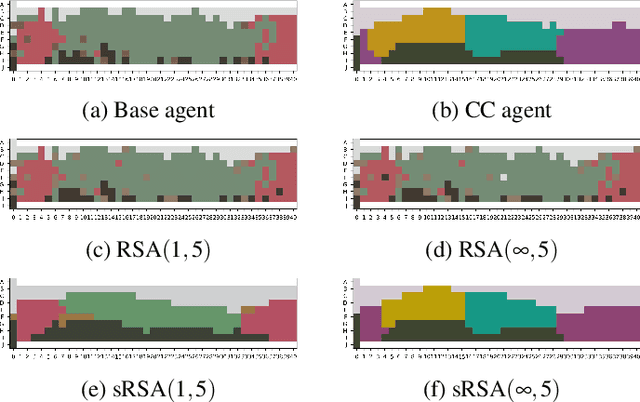
In this work we introduce a structured signaling game, an extension of the classical signaling game with a similarity structure between meanings in the context, along with a variant of the Rational Speech Act (RSA) framework which we call structured-RSA (sRSA) for pragmatic reasoning in structured domains. We explore the behavior of the sRSA in the domain of color and show that pragmatic agents using sRSA on top of semantic representations, derived from the World Color Survey, attain efficiency very close to the information theoretic limit after only 1 or 2 levels of recursion. We also explore the interaction between pragmatic reasoning and learning in multi-agent reinforcement learning framework. Our results illustrate that artificial agents using sRSA develop communication closer to the information theoretic frontier compared to agents using RSA and just reinforcement learning. We also find that the ambiguity of the semantic representation increases as the pragmatic agents are allowed to perform deeper reasoning about each other during learning.
Learning Summary-Worthy Visual Representation for Abstractive Summarization in Video
May 08, 2023
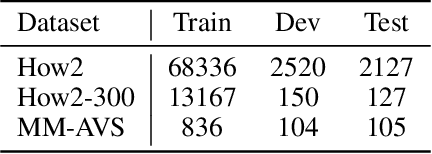
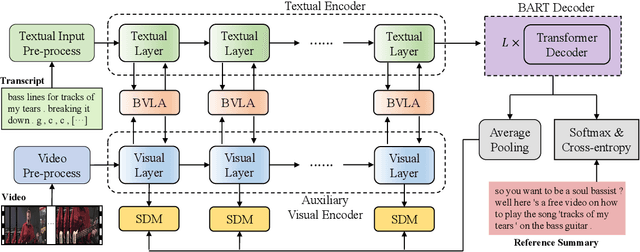
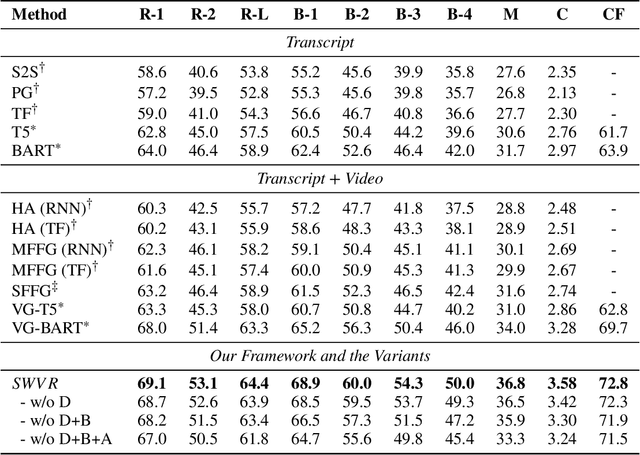
Multimodal abstractive summarization for videos (MAS) requires generating a concise textual summary to describe the highlights of a video according to multimodal resources, in our case, the video content and its transcript. Inspired by the success of the large-scale generative pre-trained language model (GPLM) in generating high-quality textual content (e.g., summary), recent MAS methods have proposed to adapt the GPLM to this task by equipping it with the visual information, which is often obtained through a general-purpose visual feature extractor. However, the generally extracted visual features may overlook some summary-worthy visual information, which impedes model performance. In this work, we propose a novel approach to learning the summary-worthy visual representation that facilitates abstractive summarization. Our method exploits the summary-worthy information from both the cross-modal transcript data and the knowledge that distills from the pseudo summary. Extensive experiments on three public multimodal datasets show that our method outperforms all competing baselines. Furthermore, with the advantages of summary-worthy visual information, our model can have a significant improvement on small datasets or even datasets with limited training data.
OverPrompt: Enhancing ChatGPT Capabilities through an Efficient In-Context Learning Approach
May 24, 2023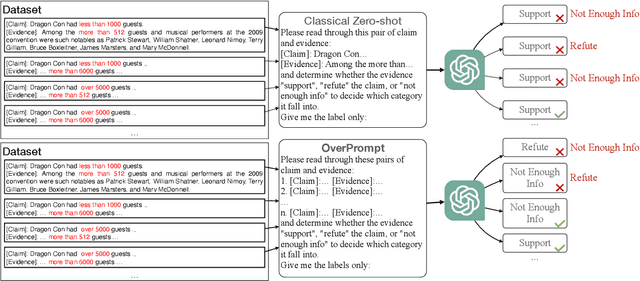
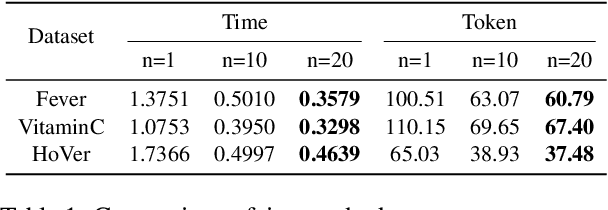
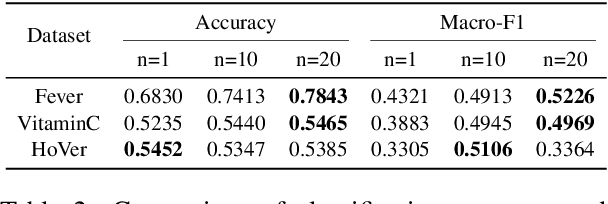
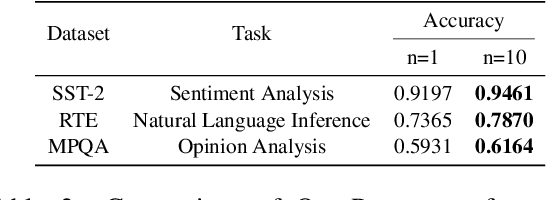
The exceptional performance of pre-trained large language models has revolutionised various applications, but their adoption in production environments is hindered by prohibitive costs and inefficiencies, particularly when utilising long prompts. This paper proposes OverPrompt, an in-context learning method aimed at improving LLM efficiency and performance by processing multiple inputs in parallel. Evaluated across diverse datasets, OverPrompt enhances task efficiency and integrates a diverse range of examples for improved performance. Particularly, it amplifies fact-checking and sentiment analysis tasks when supplemented with contextual information. Synthetic data grouping further enhances performance, suggesting a viable approach for data augmentation.
Towards Efficient Deep Hashing Retrieval: Condensing Your Data via Feature-Embedding Matching
May 29, 2023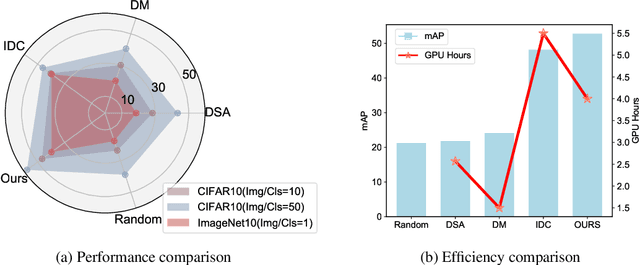
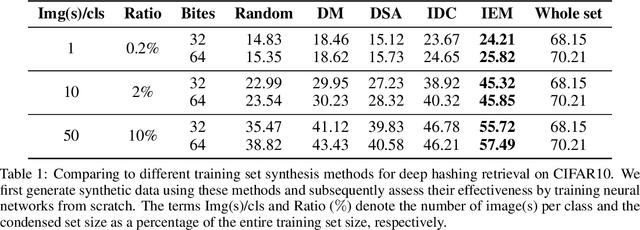
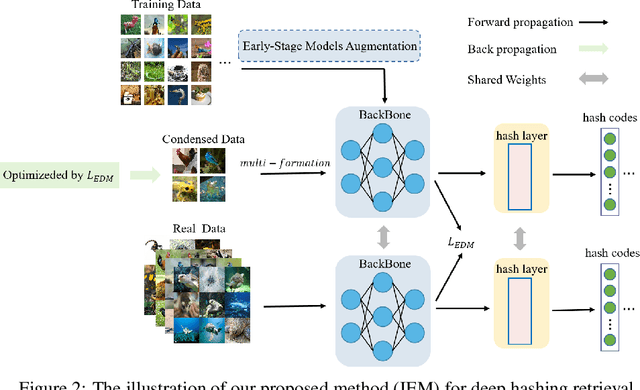
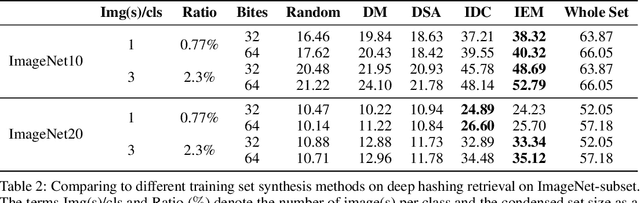
The expenses involved in training state-of-the-art deep hashing retrieval models have witnessed an increase due to the adoption of more sophisticated models and large-scale datasets. Dataset Distillation (DD) or Dataset Condensation(DC) focuses on generating smaller synthetic dataset that retains the original information. Nevertheless, existing DD methods face challenges in maintaining a trade-off between accuracy and efficiency. And the state-of-the-art dataset distillation methods can not expand to all deep hashing retrieval methods. In this paper, we propose an efficient condensation framework that addresses these limitations by matching the feature-embedding between synthetic set and real set. Furthermore, we enhance the diversity of features by incorporating the strategies of early-stage augmented models and multi-formation. Extensive experiments provide compelling evidence of the remarkable superiority of our approach, both in terms of performance and efficiency, compared to state-of-the-art baseline methods.
Generative Diffusion for 3D Turbulent Flows
May 29, 2023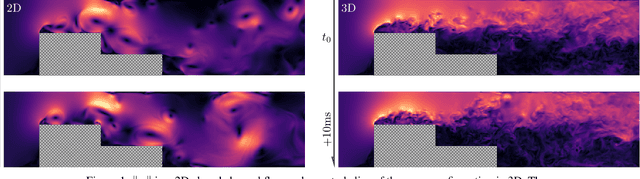
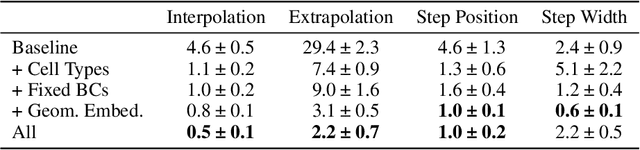
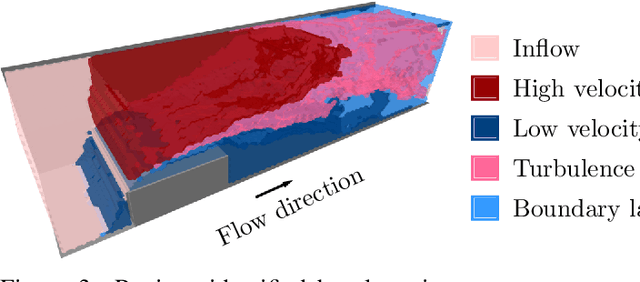
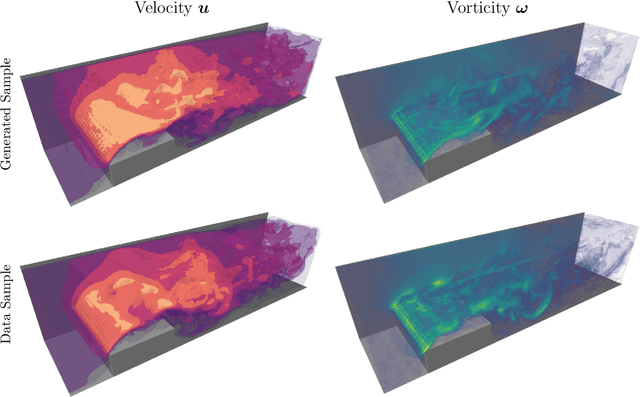
Turbulent flows are well known to be chaotic and hard to predict; however, their dynamics differ between two and three dimensions. While 2D turbulence tends to form large, coherent structures, in three dimensions vortices cascade to smaller and smaller scales. This cascade creates many fast-changing, small-scale structures and amplifies the unpredictability, making regression-based methods infeasible. We propose the first generative model for forced turbulence in arbitrary 3D geometries and introduce a sample quality metric for turbulent flows based on the Wasserstein distance of the generated velocity-vorticity distribution. In several experiments, we show that our generative diffusion model circumvents the unpredictability of turbulent flows and produces high-quality samples based solely on geometric information. Furthermore, we demonstrate that our model beats an industrial-grade numerical solver in the time to generate a turbulent flow field from scratch by an order of magnitude.
Rare Life Event Detection via Mobile Sensing Using Multi-Task Learning
May 31, 2023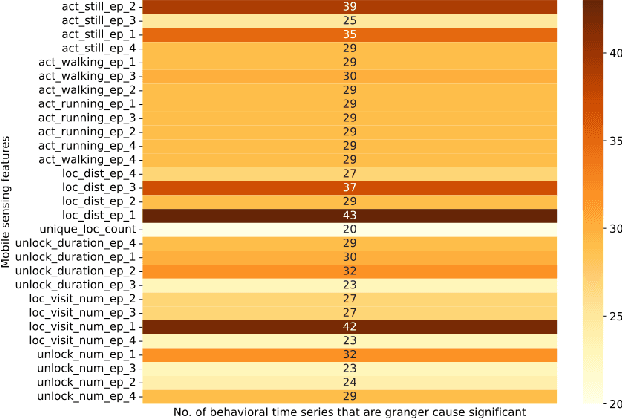
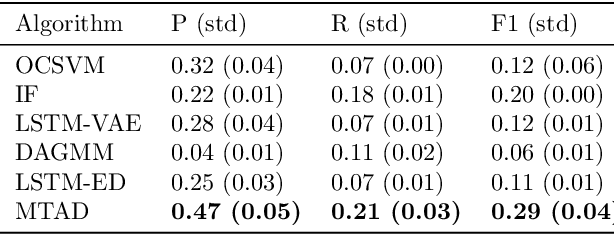
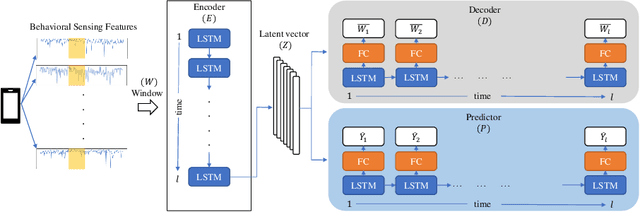
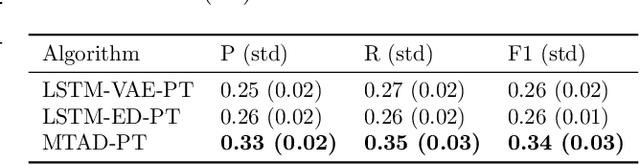
Rare life events significantly impact mental health, and their detection in behavioral studies is a crucial step towards health-based interventions. We envision that mobile sensing data can be used to detect these anomalies. However, the human-centered nature of the problem, combined with the infrequency and uniqueness of these events makes it challenging for unsupervised machine learning methods. In this paper, we first investigate granger-causality between life events and human behavior using sensing data. Next, we propose a multi-task framework with an unsupervised autoencoder to capture irregular behavior, and an auxiliary sequence predictor that identifies transitions in workplace performance to contextualize events. We perform experiments using data from a mobile sensing study comprising N=126 information workers from multiple industries, spanning 10106 days with 198 rare events (<2%). Through personalized inference, we detect the exact day of a rare event with an F1 of 0.34, demonstrating that our method outperforms several baselines. Finally, we discuss the implications of our work from the context of real-world deployment.