 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023

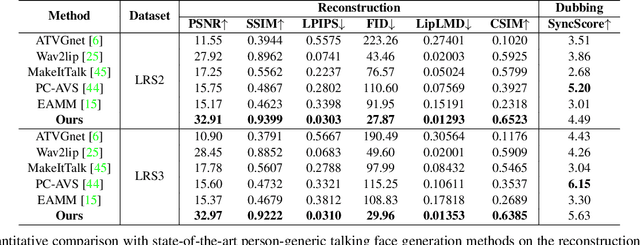
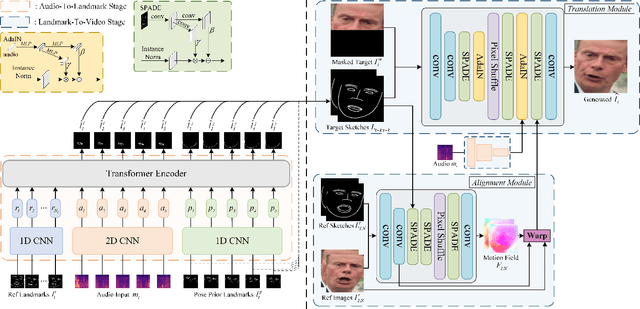
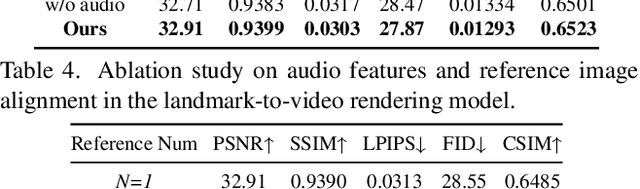
Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
Homonymy Information for English WordNet
Dec 16, 2022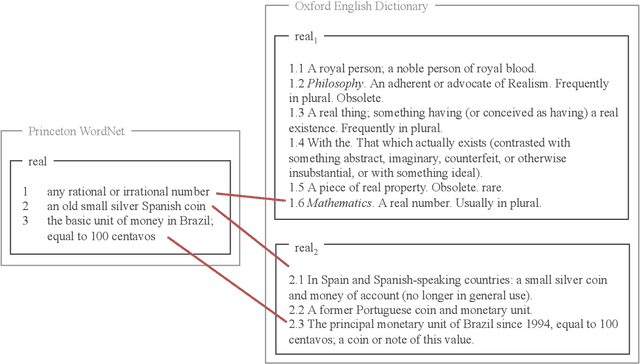
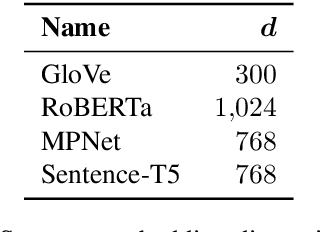

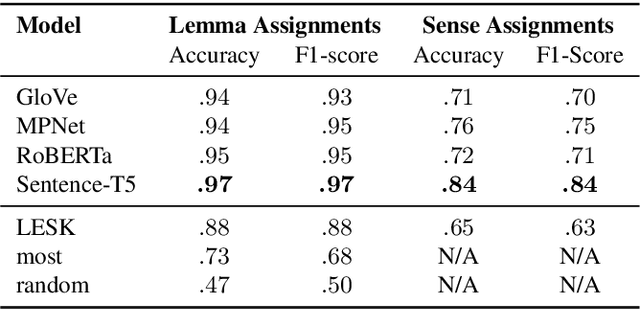
A widely acknowledged shortcoming of WordNet is that it lacks a distinction between word meanings which are systematically related (polysemy), and those which are coincidental (homonymy). Several previous works have attempted to fill this gap, by inferring this information using computational methods. We revisit this task, and exploit recent advances in language modelling to synthesise homonymy annotation for Princeton WordNet. Previous approaches treat the problem using clustering methods; by contrast, our method works by linking WordNet to the Oxford English Dictionary, which contains the information we need. To perform this alignment, we pair definitions based on their proximity in an embedding space produced by a Transformer model. Despite the simplicity of this approach, our best model attains an F1 of .97 on an evaluation set that we annotate. The outcome of our work is a high-quality homonymy annotation layer for Princeton WordNet, which we release.
Calibration of Transformer-based Models for Identifying Stress and Depression in Social Media
May 26, 2023
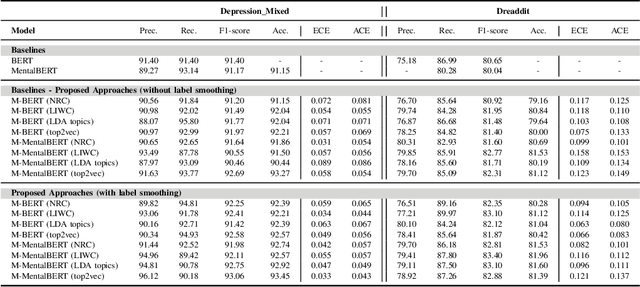
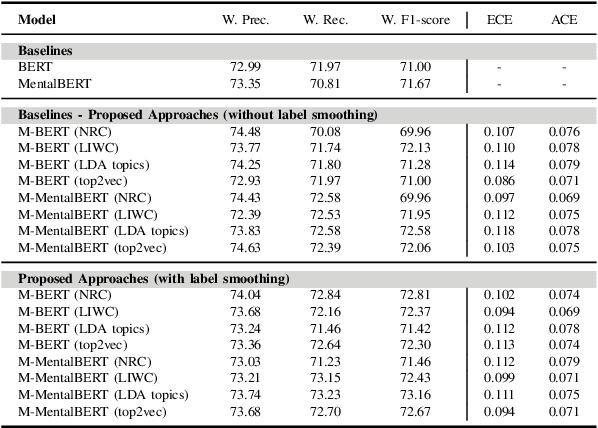
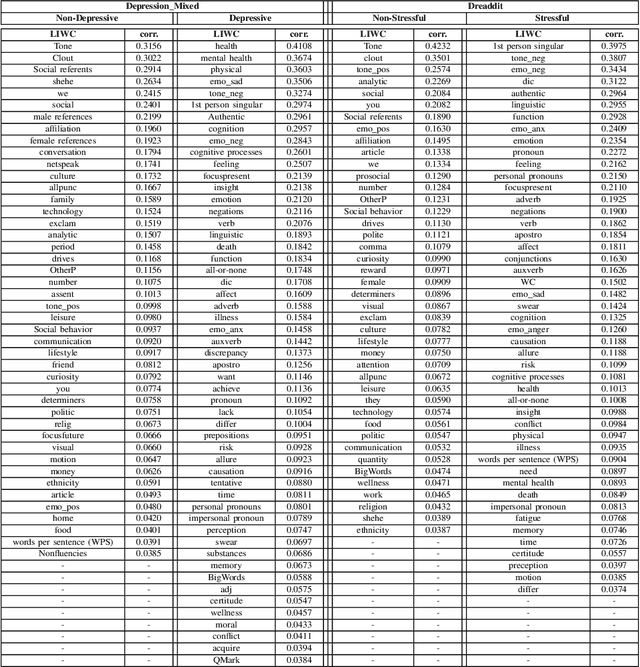
In today's fast-paced world, the rates of stress and depression present a surge. Social media provide assistance for the early detection of mental health conditions. Existing methods mainly introduce feature extraction approaches and train shallow machine learning classifiers. Other researches use deep neural networks or transformers. Despite the fact that transformer-based models achieve noticeable improvements, they cannot often capture rich factual knowledge. Although there have been proposed a number of studies aiming to enhance the pretrained transformer-based models with extra information or additional modalities, no prior work has exploited these modifications for detecting stress and depression through social media. In addition, although the reliability of a machine learning model's confidence in its predictions is critical for high-risk applications, there is no prior work taken into consideration the model calibration. To resolve the above issues, we present the first study in the task of depression and stress detection in social media, which injects extra linguistic information in transformer-based models, namely BERT and MentalBERT. Specifically, the proposed approach employs a Multimodal Adaptation Gate for creating the combined embeddings, which are given as input to a BERT (or MentalBERT) model. For taking into account the model calibration, we apply label smoothing. We test our proposed approaches in three publicly available datasets and demonstrate that the integration of linguistic features into transformer-based models presents a surge in the performance. Also, the usage of label smoothing contributes to both the improvement of the model's performance and the calibration of the model. We finally perform a linguistic analysis of the posts and show differences in language between stressful and non-stressful texts, as well as depressive and non-depressive posts.
Quantum Convolutional Neural Networks for Multi-Channel Supervised Learning
May 30, 2023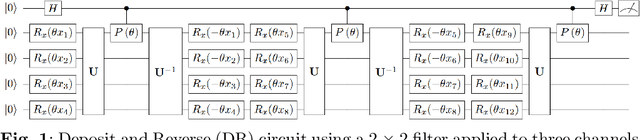
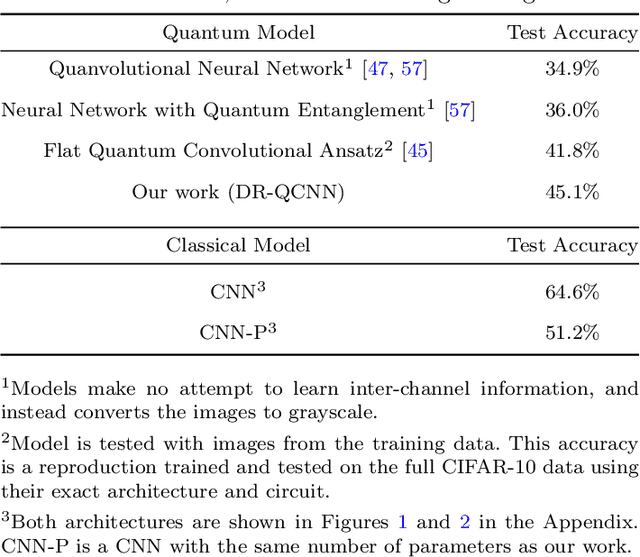
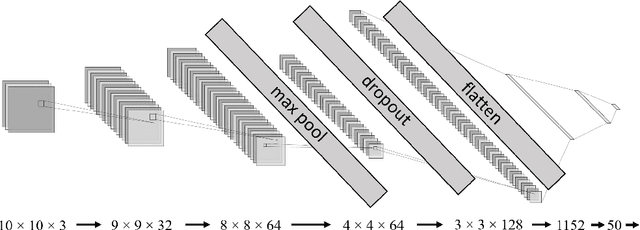
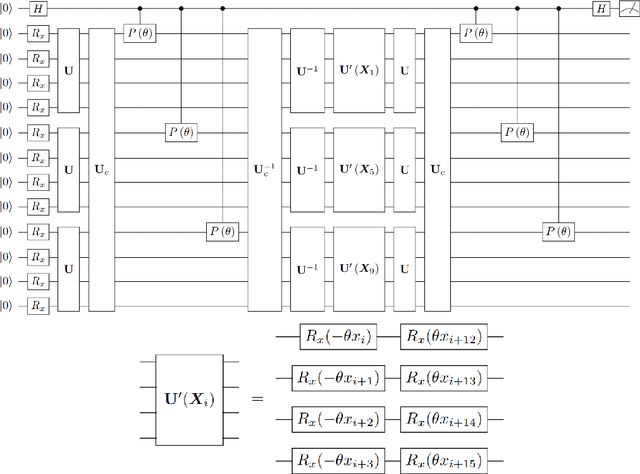
As the rapidly evolving field of machine learning continues to produce incredibly useful tools and models, the potential for quantum computing to provide speed up for machine learning algorithms is becoming increasingly desirable. In particular, quantum circuits in place of classical convolutional filters for image detection-based tasks are being investigated for the ability to exploit quantum advantage. However, these attempts, referred to as quantum convolutional neural networks (QCNNs), lack the ability to efficiently process data with multiple channels and therefore are limited to relatively simple inputs. In this work, we present a variety of hardware-adaptable quantum circuit ansatzes for use as convolutional kernels, and demonstrate that the quantum neural networks we report outperform existing QCNNs on classification tasks involving multi-channel data. We envision that the ability of these implementations to effectively learn inter-channel information will allow quantum machine learning methods to operate with more complex data. This work is available as open source at https://github.com/anthonysmaldone/QCNN-Multi-Channel-Supervised-Learning.
BLEU Meets COMET: Combining Lexical and Neural Metrics Towards Robust Machine Translation Evaluation
May 30, 2023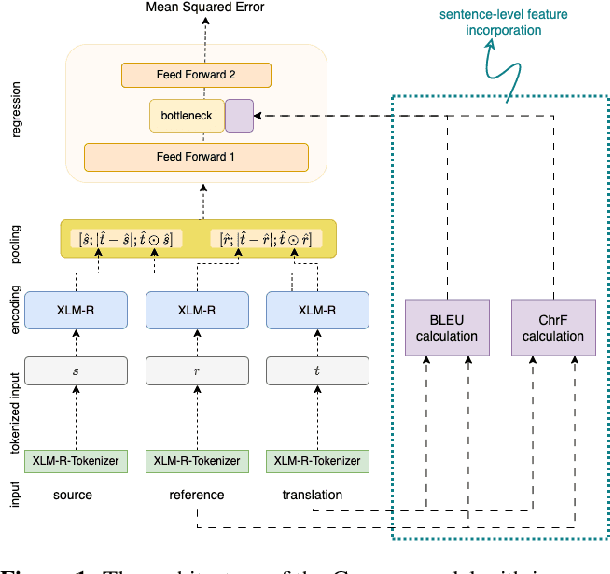
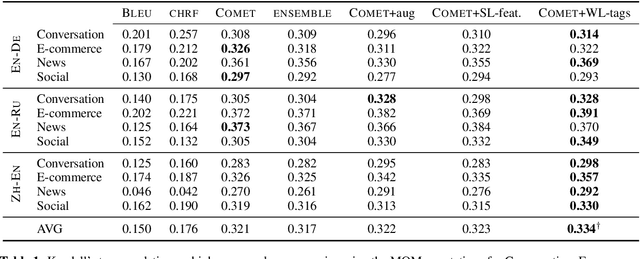
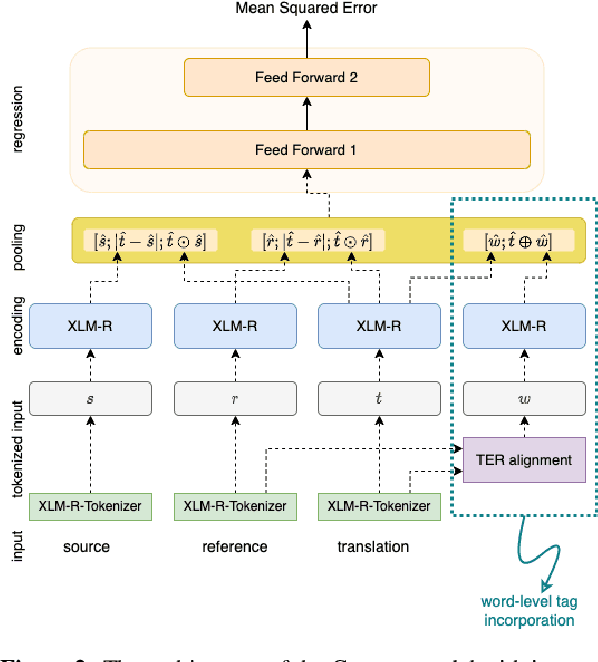

Although neural-based machine translation evaluation metrics, such as COMET or BLEURT, have achieved strong correlations with human judgements, they are sometimes unreliable in detecting certain phenomena that can be considered as critical errors, such as deviations in entities and numbers. In contrast, traditional evaluation metrics, such as BLEU or chrF, which measure lexical or character overlap between translation hypotheses and human references, have lower correlations with human judgements but are sensitive to such deviations. In this paper, we investigate several ways of combining the two approaches in order to increase robustness of state-of-the-art evaluation methods to translations with critical errors. We show that by using additional information during training, such as sentence-level features and word-level tags, the trained metrics improve their capability to penalize translations with specific troublesome phenomena, which leads to gains in correlation with human judgments and on recent challenge sets on several language pairs.
Video ControlNet: Towards Temporally Consistent Synthetic-to-Real Video Translation Using Conditional Image Diffusion Models
May 30, 2023
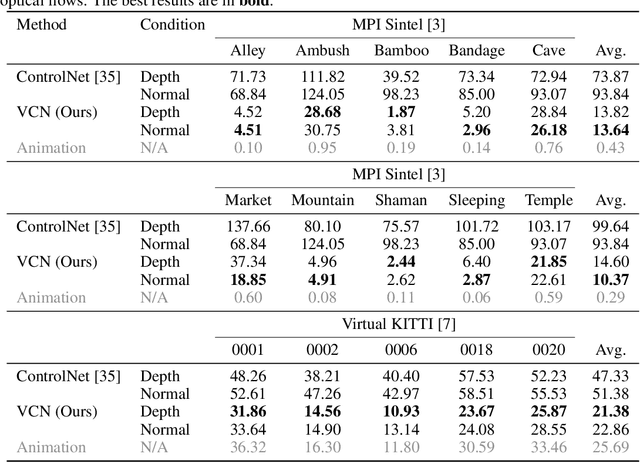
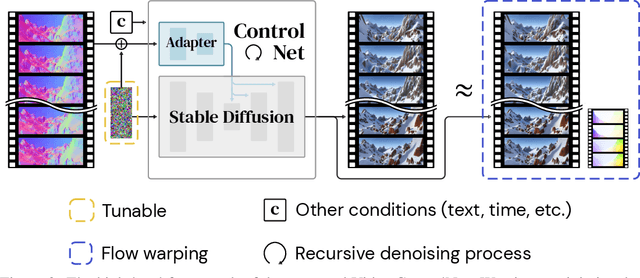
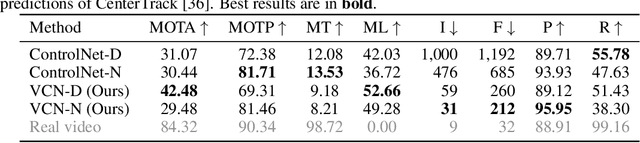
In this study, we present an efficient and effective approach for achieving temporally consistent synthetic-to-real video translation in videos of varying lengths. Our method leverages off-the-shelf conditional image diffusion models, allowing us to perform multiple synthetic-to-real image generations in parallel. By utilizing the available optical flow information from the synthetic videos, our approach seamlessly enforces temporal consistency among corresponding pixels across frames. This is achieved through joint noise optimization, effectively minimizing spatial and temporal discrepancies. To the best of our knowledge, our proposed method is the first to accomplish diverse and temporally consistent synthetic-to-real video translation using conditional image diffusion models. Furthermore, our approach does not require any training or fine-tuning of the diffusion models. Extensive experiments conducted on various benchmarks for synthetic-to-real video translation demonstrate the effectiveness of our approach, both quantitatively and qualitatively. Finally, we show that our method outperforms other baseline methods in terms of both temporal consistency and visual quality.
Investigating model performance in language identification: beyond simple error statistics
May 30, 2023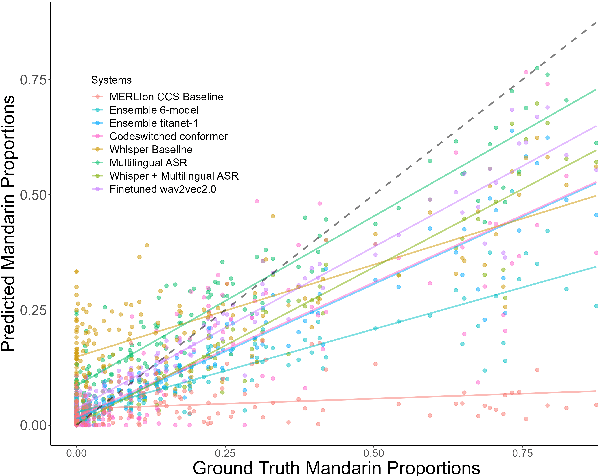
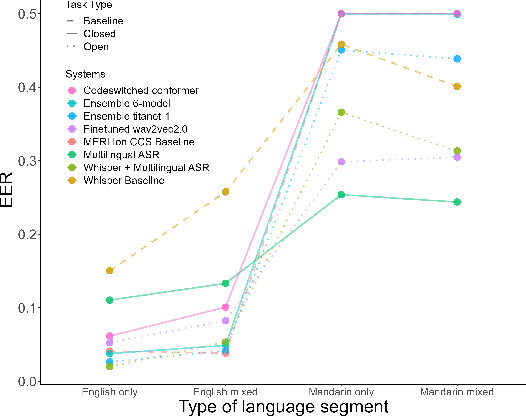
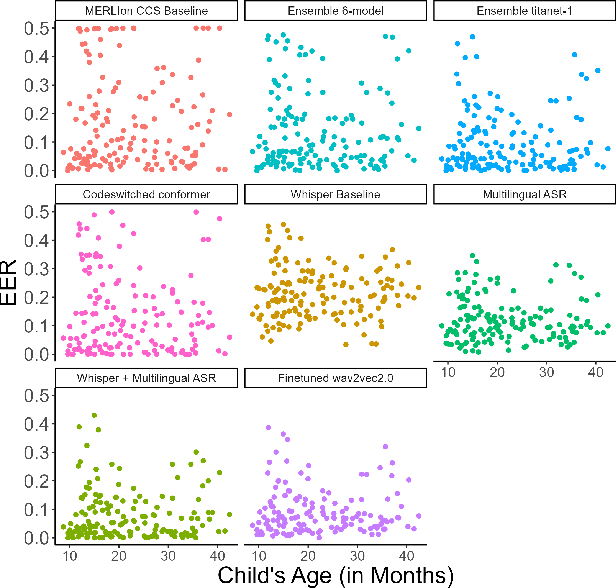
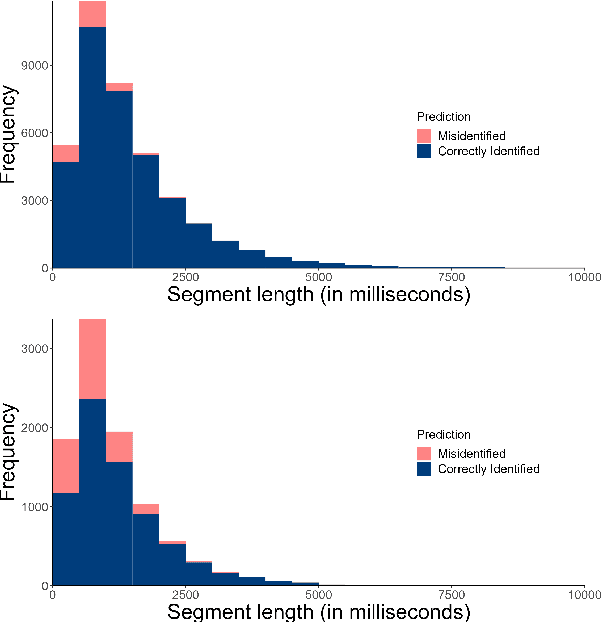
Language development experts need tools that can automatically identify languages from fluent, conversational speech, and provide reliable estimates of usage rates at the level of an individual recording. However, language identification systems are typically evaluated on metrics such as equal error rate and balanced accuracy, applied at the level of an entire speech corpus. These overview metrics do not provide information about model performance at the level of individual speakers, recordings, or units of speech with different linguistic characteristics. Overview statistics may therefore mask systematic errors in model performance for some subsets of the data, and consequently, have worse performance on data derived from some subsets of human speakers, creating a kind of algorithmic bias. In the current paper, we investigate how well a number of language identification systems perform on individual recordings and speech units with different linguistic properties in the MERLIon CCS Challenge. The Challenge dataset features accented English-Mandarin code-switched child-directed speech.
Pair-Variational Autoencoders (PairVAE) for Linking and Cross-Reconstruction of Characterization Data from Complementary Structural Characterization Techniques
May 25, 2023
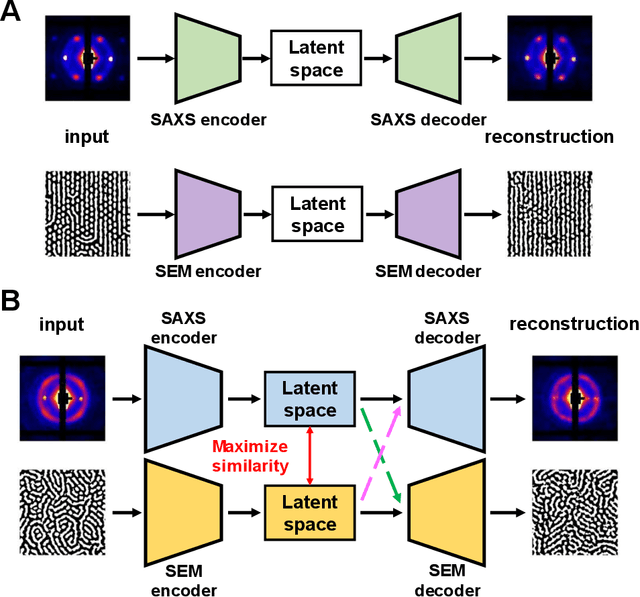
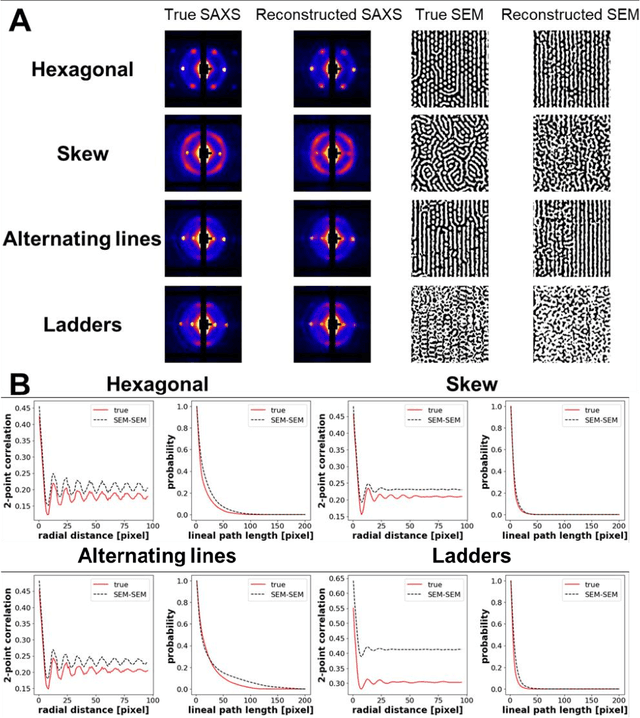
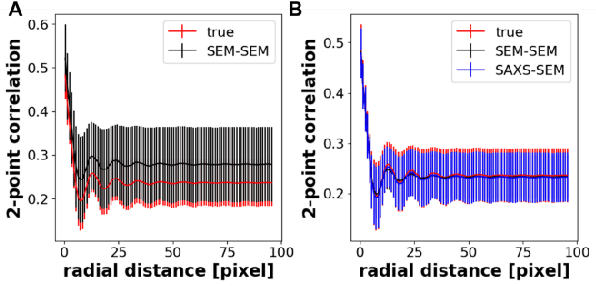
In material research, structural characterization often requires multiple complementary techniques to obtain a holistic morphological view of the synthesized material. Depending on the availability of and accessibility of the different characterization techniques (e.g., scattering, microscopy, spectroscopy), each research facility or academic research lab may have access to high-throughput capability in one technique but face limitations (sample preparation, resolution, access time) with other techniques(s). Furthermore, one type of structural characterization data may be easier to interpret than another (e.g., microscopy images are easier to interpret than small angle scattering profiles). Thus, it is useful to have machine learning models that can be trained on paired structural characterization data from multiple techniques so that the model can generate one set of characterization data from the other. In this paper we demonstrate one such machine learning workflow, PairVAE, that works with data from Small Angle X-Ray Scattering (SAXS) that presents information about bulk morphology and images from Scanning Electron Microscopy (SEM) that presents two-dimensional local structural information of the sample. Using paired SAXS and SEM data of novel block copolymer assembled morphologies [open access data from Doerk G.S., et al. Science Advances. 2023 Jan 13;9(2): eadd3687], we train our PairVAE. After successful training, we demonstrate that the PairVAE can generate SEM images of the block copolymer morphology when it takes as input that sample's corresponding SAXS 2D pattern, and vice versa. This method can be extended to other soft materials morphologies as well and serves as a valuable tool for easy interpretation of 2D SAXS patterns as well as creating a database for other downstream calculations of structure-property relationships.
A bioinspired three-stage model for camouflaged object detection
May 22, 2023
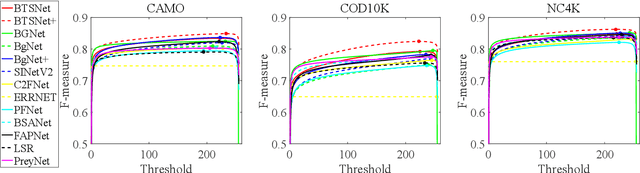


Camouflaged objects are typically assimilated into their backgrounds and exhibit fuzzy boundaries. The complex environmental conditions and the high intrinsic similarity between camouflaged targets and their surroundings pose significant challenges in accurately locating and segmenting these objects in their entirety. While existing methods have demonstrated remarkable performance in various real-world scenarios, they still face limitations when confronted with difficult cases, such as small targets, thin structures, and indistinct boundaries. Drawing inspiration from human visual perception when observing images containing camouflaged objects, we propose a three-stage model that enables coarse-to-fine segmentation in a single iteration. Specifically, our model employs three decoders to sequentially process subsampled features, cropped features, and high-resolution original features. This proposed approach not only reduces computational overhead but also mitigates interference caused by background noise. Furthermore, considering the significance of multi-scale information, we have designed a multi-scale feature enhancement module that enlarges the receptive field while preserving detailed structural cues. Additionally, a boundary enhancement module has been developed to enhance performance by leveraging boundary information. Subsequently, a mask-guided fusion module is proposed to generate fine-grained results by integrating coarse prediction maps with high-resolution feature maps. Our network surpasses state-of-the-art CNN-based counterparts without unnecessary complexities. Upon acceptance of the paper, the source code will be made publicly available at https://github.com/clelouch/BTSNet.
Distributed Learning over Networks with Graph-Attention-Based Personalization
May 22, 2023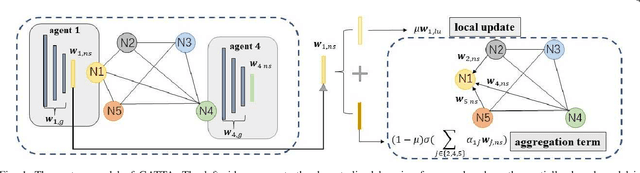
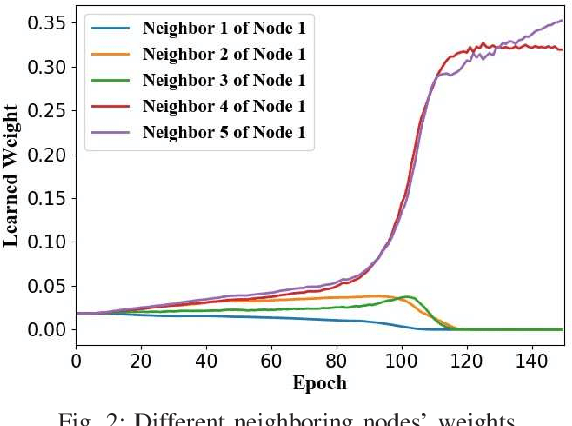
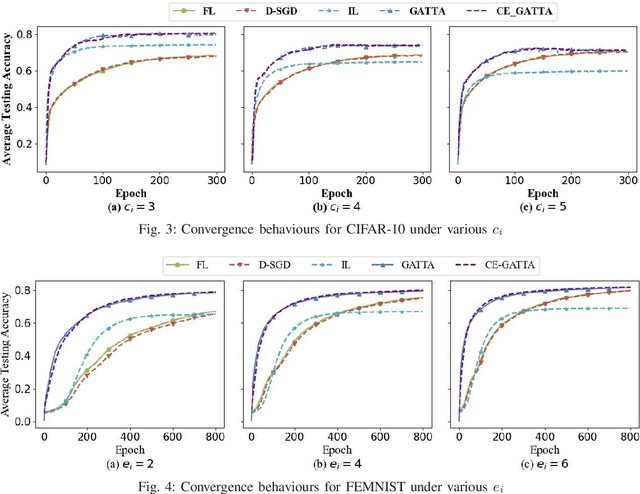
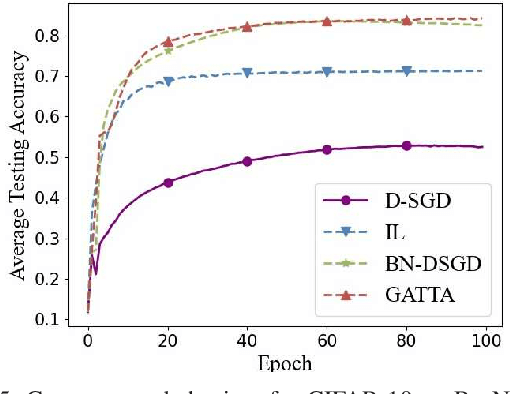
In conventional distributed learning over a network, multiple agents collaboratively build a common machine learning model. However, due to the underlying non-i.i.d. data distribution among agents, the unified learning model becomes inefficient for each agent to process its locally accessible data. To address this problem, we propose a graph-attention-based personalized training algorithm (GATTA) for distributed deep learning. The GATTA enables each agent to train its local personalized model while exploiting its correlation with neighboring nodes and utilizing their useful information for aggregation. In particular, the personalized model in each agent is composed of a global part and a node-specific part. By treating each agent as one node in a graph and the node-specific parameters as its features, the benefits of the graph attention mechanism can be inherited. Namely, instead of aggregation based on averaging, it learns the specific weights for different neighboring nodes without requiring prior knowledge about the graph structure or the neighboring nodes' data distribution. Furthermore, relying on the weight-learning procedure, we develop a communication-efficient GATTA by skipping the transmission of information with small aggregation weights. Additionally, we theoretically analyze the convergence properties of GATTA for non-convex loss functions. Numerical results validate the excellent performances of the proposed algorithms in terms of convergence and communication cost.