 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
$\mathrm{E}(n)$ Equivariant Message Passing Simplicial Networks
May 11, 2023
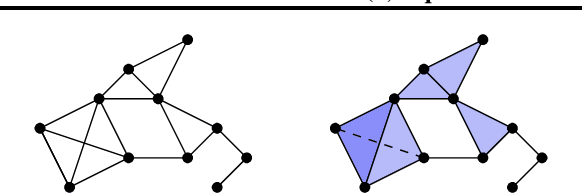
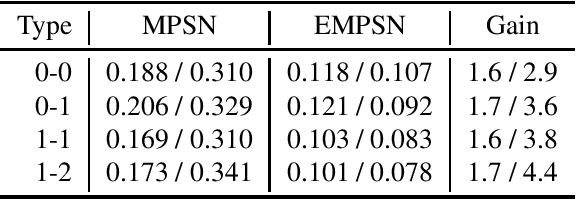
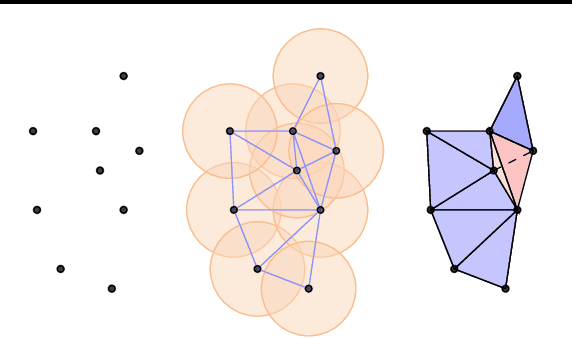
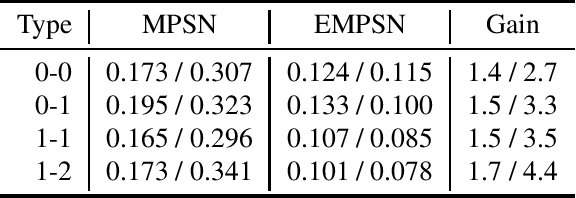
This paper presents $\mathrm{E}(n)$ Equivariant Message Passing Simplicial Networks (EMPSNs), a novel approach to learning on geometric graphs and point clouds that is equivariant to rotations, translations, and reflections. EMPSNs can learn high-dimensional simplex features in graphs (e.g. triangles), and use the increase of geometric information of higher-dimensional simplices in an $\mathrm{E}(n)$ equivariant fashion. EMPSNs simultaneously generalize $\mathrm{E}(n)$ Equivariant Graph Neural Networks to a topologically more elaborate counterpart and provide an approach for including geometric information in Message Passing Simplicial Networks. The results indicate that EMPSNs can leverage the benefits of both approaches, leading to a general increase in performance when compared to either method. Furthermore, the results suggest that incorporating geometric information serves as an effective measure against over-smoothing in message passing networks, especially when operating on high-dimensional simplicial structures. Last, we show that EMPSNs are on par with state-of-the-art approaches for learning on geometric graphs.
Adaptive Contextual Biasing for Transducer Based Streaming Speech Recognition
Jun 01, 2023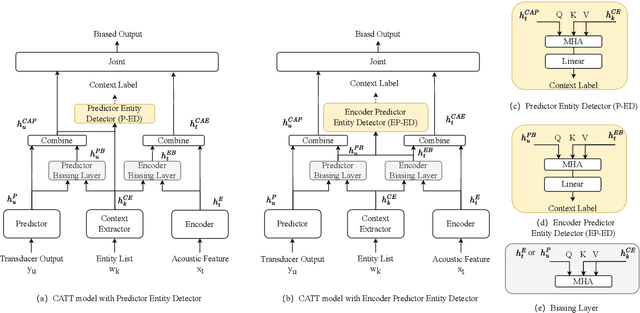

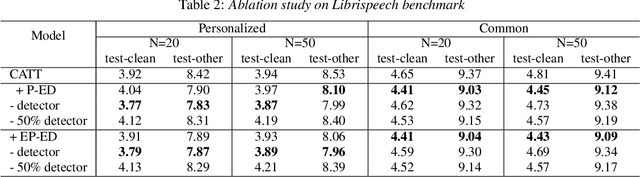
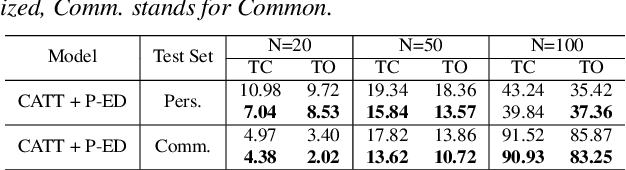
By incorporating additional contextual information, deep biasing methods have emerged as a promising solution for speech recognition of personalized words. However, for real-world voice assistants, always biasing on such personalized words with high prediction scores can significantly degrade the performance of recognizing common words. To address this issue, we propose an adaptive contextual biasing method based on Context-Aware Transformer Transducer (CATT) that utilizes the biased encoder and predictor embeddings to perform streaming prediction of contextual phrase occurrences. Such prediction is then used to dynamically switch the bias list on and off, enabling the model to adapt to both personalized and common scenarios. Experiments on Librispeech and internal voice assistant datasets show that our approach can achieve up to 6.7% and 20.7% relative reduction in WER and CER compared to the baseline respectively, mitigating up to 96.7% and 84.9% of the relative WER and CER increase for common cases. Furthermore, our approach has a minimal performance impact in personalized scenarios while maintaining a streaming inference pipeline with negligible RTF increase.
Being Right for Whose Right Reasons?
Jun 01, 2023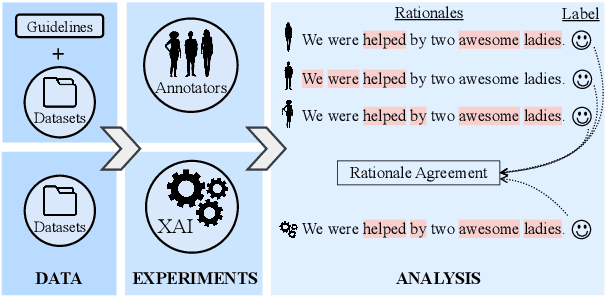
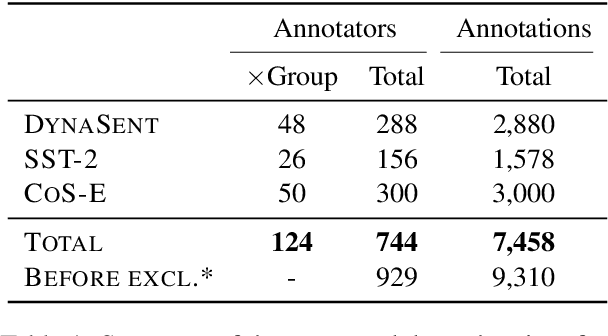

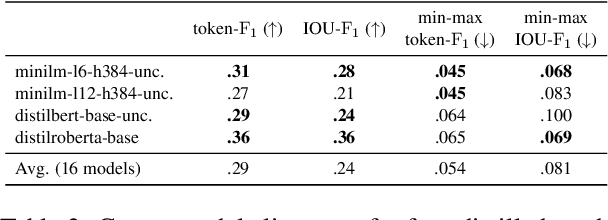
Explainability methods are used to benchmark the extent to which model predictions align with human rationales i.e., are 'right for the right reasons'. Previous work has failed to acknowledge, however, that what counts as a rationale is sometimes subjective. This paper presents what we think is a first of its kind, a collection of human rationale annotations augmented with the annotators demographic information. We cover three datasets spanning sentiment analysis and common-sense reasoning, and six demographic groups (balanced across age and ethnicity). Such data enables us to ask both what demographics our predictions align with and whose reasoning patterns our models' rationales align with. We find systematic inter-group annotator disagreement and show how 16 Transformer-based models align better with rationales provided by certain demographic groups: We find that models are biased towards aligning best with older and/or white annotators. We zoom in on the effects of model size and model distillation, finding -- contrary to our expectations -- negative correlations between model size and rationale agreement as well as no evidence that either model size or model distillation improves fairness.
Offline Meta Reinforcement Learning with In-Distribution Online Adaptation
Jun 01, 2023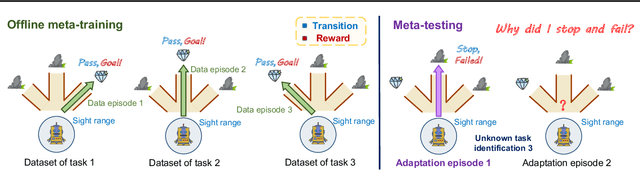
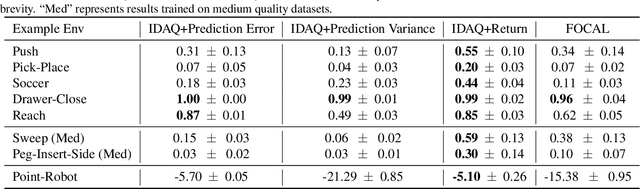
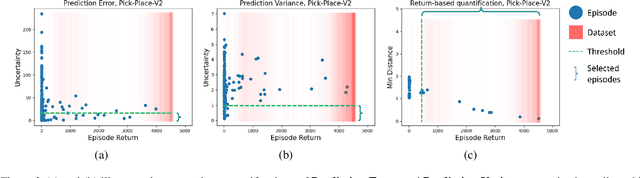
Recent offline meta-reinforcement learning (meta-RL) methods typically utilize task-dependent behavior policies (e.g., training RL agents on each individual task) to collect a multi-task dataset. However, these methods always require extra information for fast adaptation, such as offline context for testing tasks. To address this problem, we first formally characterize a unique challenge in offline meta-RL: transition-reward distribution shift between offline datasets and online adaptation. Our theory finds that out-of-distribution adaptation episodes may lead to unreliable policy evaluation and that online adaptation with in-distribution episodes can ensure adaptation performance guarantee. Based on these theoretical insights, we propose a novel adaptation framework, called In-Distribution online Adaptation with uncertainty Quantification (IDAQ), which generates in-distribution context using a given uncertainty quantification and performs effective task belief inference to address new tasks. We find a return-based uncertainty quantification for IDAQ that performs effectively. Experiments show that IDAQ achieves state-of-the-art performance on the Meta-World ML1 benchmark compared to baselines with/without offline adaptation.
Point-Voxel Absorbing Graph Representation Learning for Event Stream based Recognition
Jun 08, 2023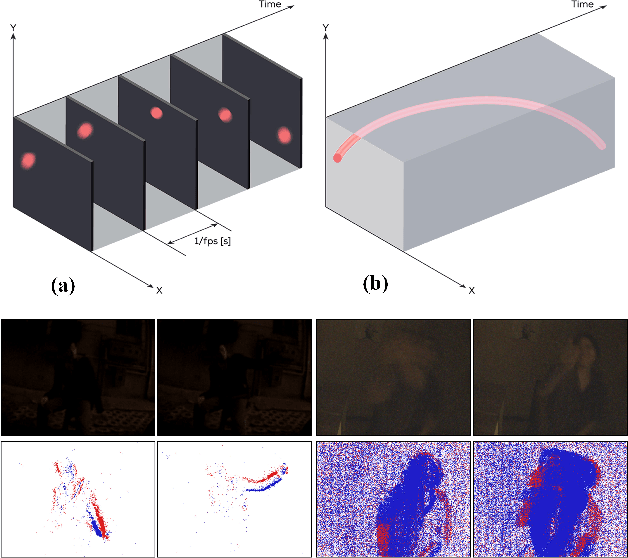
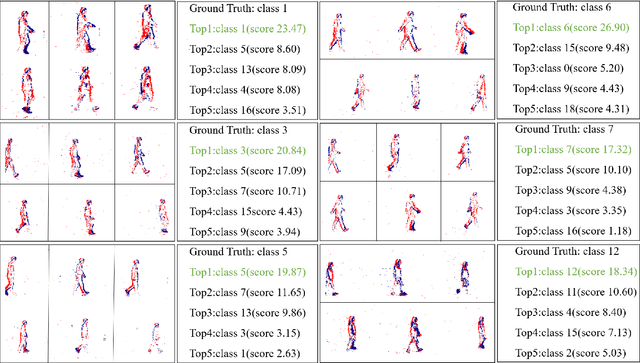
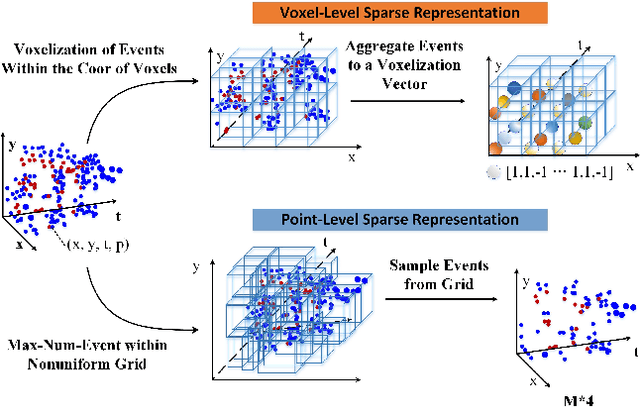
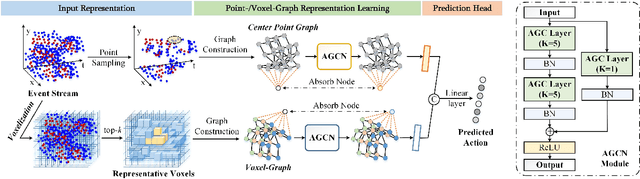
Considering the balance of performance and efficiency, sampled point and voxel methods are usually employed to down-sample dense events into sparse ones. After that, one popular way is to leverage a graph model which treats the sparse points/voxels as nodes and adopts graph neural networks (GNNs) to learn the representation for event data. Although good performance can be obtained, however, their results are still limited mainly due to two issues. (1) Existing event GNNs generally adopt the additional max (or mean) pooling layer to summarize all node embeddings into a single graph-level representation for the whole event data representation. However, this approach fails to capture the importance of graph nodes and also fails to be fully aware of the node representations. (2) Existing methods generally employ either a sparse point or voxel graph representation model which thus lacks consideration of the complementary between these two types of representation models. To address these issues, in this paper, we propose a novel dual point-voxel absorbing graph representation learning for event stream data representation. To be specific, given the input event stream, we first transform it into the sparse event cloud and voxel grids and build dual absorbing graph models for them respectively. Then, we design a novel absorbing graph convolutional network (AGCN) for our dual absorbing graph representation and learning. The key aspect of the proposed AGCN is its ability to effectively capture the importance of nodes and thus be fully aware of node representations in summarizing all node representations through the introduced absorbing nodes. Finally, the event representations of dual learning branches are concatenated together to extract the complementary information of two cues. The output is then fed into a linear layer for event data classification.
QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations
May 19, 2023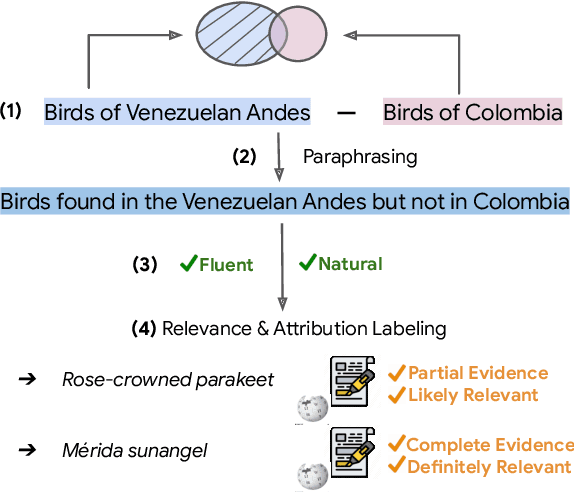

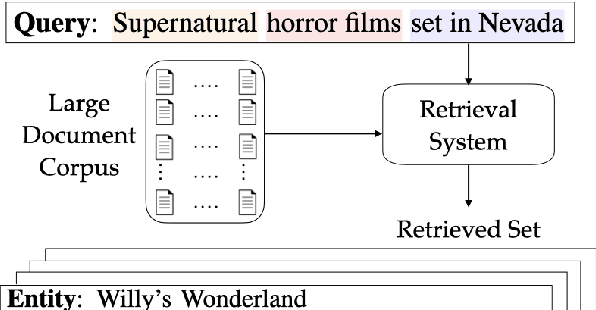
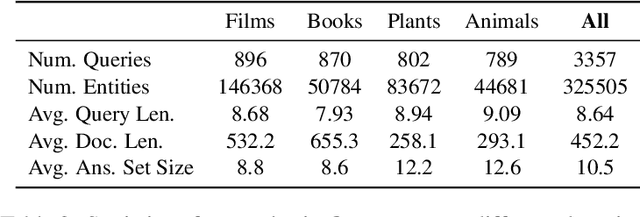
Formulating selective information needs results in queries that implicitly specify set operations, such as intersection, union, and difference. For instance, one might search for "shorebirds that are not sandpipers" or "science-fiction films shot in England". To study the ability of retrieval systems to meet such information needs, we construct QUEST, a dataset of 3357 natural language queries with implicit set operations, that map to a set of entities corresponding to Wikipedia documents. The dataset challenges models to match multiple constraints mentioned in queries with corresponding evidence in documents and correctly perform various set operations. The dataset is constructed semi-automatically using Wikipedia category names. Queries are automatically composed from individual categories, then paraphrased and further validated for naturalness and fluency by crowdworkers. Crowdworkers also assess the relevance of entities based on their documents and highlight attribution of query constraints to spans of document text. We analyze several modern retrieval systems, finding that they often struggle on such queries. Queries involving negation and conjunction are particularly challenging and systems are further challenged with combinations of these operations.
Learning Sequence Descriptor based on Spatiotemporal Attention for Visual Place Recognition
May 19, 2023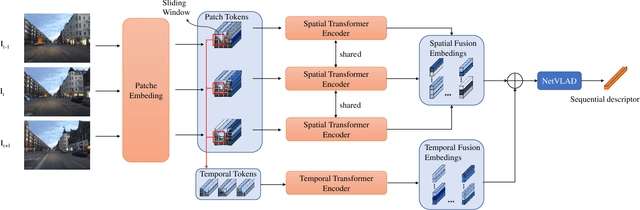
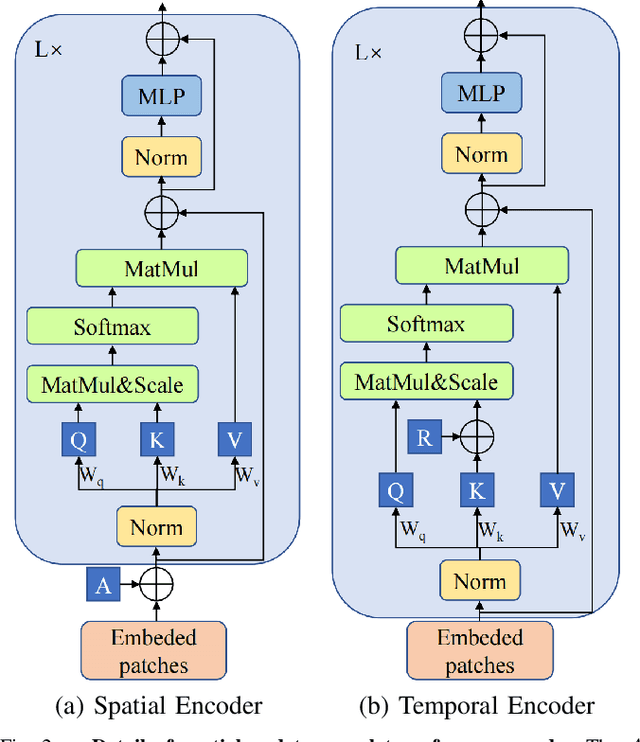
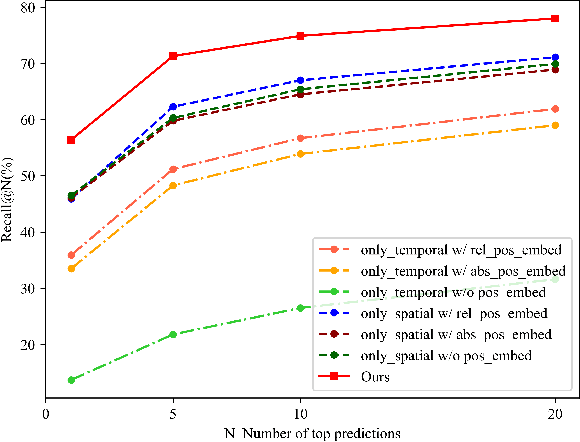
Sequence-based visual place recognition (sVPR) aims to match frame sequences with frames stored in a reference map for localization. Existing methods include sequence matching and sequence descriptor-based retrieval. The former is based on the assumption of constant velocity, which is difficult to hold in real scenarios and does not get rid of the intrinsic single frame descriptor mismatch. The latter solves this problem by extracting a descriptor for the whole sequence, but current sequence descriptors are only constructed by feature aggregation of multi-frames, with no temporal information interaction. In this paper, we propose a sequential descriptor extraction method to fuse spatiotemporal information effectively and generate discriminative descriptors. Specifically, similar features on the same frame focu on each other and learn space structure, and the same local regions of different frames learn local feature changes over time. And we use sliding windows to control the temporal self-attention range and adpot relative position encoding to construct the positional relationships between different features, which allows our descriptor to capture the inherent dynamics in the frame sequence and local feature motion.
Understanding Predictive Coding as an Adaptive Trust-Region Method
May 29, 2023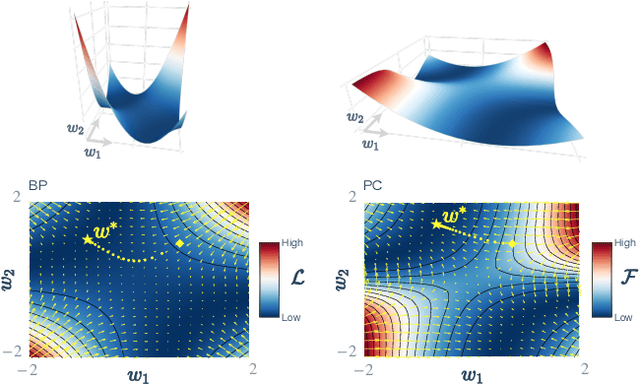
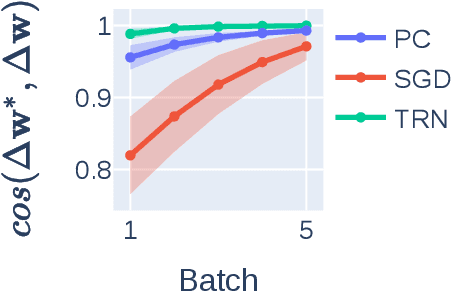
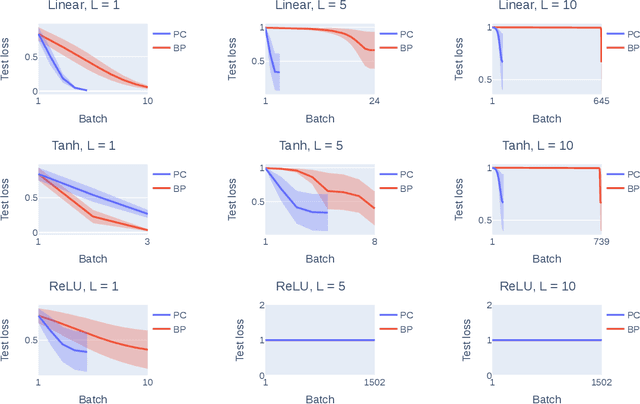
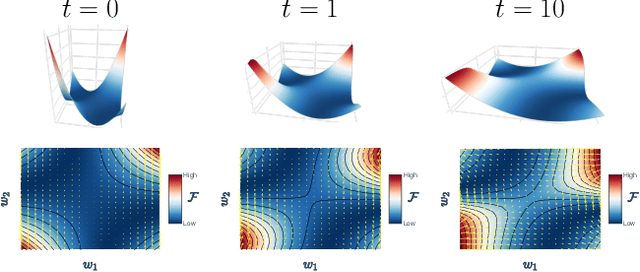
Predictive coding (PC) is a brain-inspired local learning algorithm that has recently been suggested to provide advantages over backpropagation (BP) in biologically relevant scenarios. While theoretical work has mainly focused on showing how PC can approximate BP in various limits, the putative benefits of "natural" PC are less understood. Here we develop a theory of PC as an adaptive trust-region (TR) algorithm that uses second-order information. We show that the learning dynamics of PC can be interpreted as interpolating between BP's loss gradient direction and a TR direction found by the PC inference dynamics. Our theory suggests that PC should escape saddle points faster than BP, a prediction which we prove in a shallow linear model and support with experiments on deeper networks. This work lays a foundation for understanding PC in deep and wide networks.
MALM: Mask Augmentation based Local Matching for Food-Recipe Retrieval
May 18, 2023
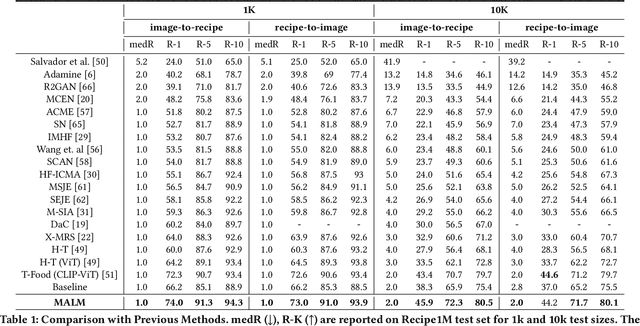
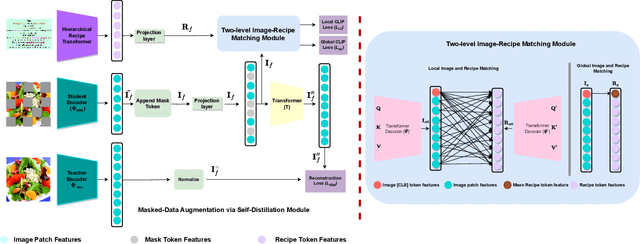

Image-to-recipe retrieval is a challenging vision-to-language task of significant practical value. The main challenge of the task lies in the ultra-high redundancy in the long recipe and the large variation reflected in both food item combination and food item appearance. A de-facto idea to address this task is to learn a shared feature embedding space in which a food image is aligned better to its paired recipe than other recipes. However, such supervised global matching is prone to supervision collapse, i.e., only partial information that is necessary for distinguishing training pairs can be identified, while other information that is potentially useful in generalization could be lost. To mitigate such a problem, we propose a mask-augmentation-based local matching network (MALM), where an image-text matching module and a masked self-distillation module benefit each other mutually to learn generalizable cross-modality representations. On one hand, we perform local matching between the tokenized representations of image and text to locate fine-grained cross-modality correspondence explicitly. We involve representations of masked image patches in this process to alleviate overfitting resulting from local matching especially when some food items are underrepresented. On the other hand, predicting the hidden representations of the masked patches through self-distillation helps to learn general-purpose image representations that are expected to generalize better. And the multi-task nature of the model enables the representations of masked patches to be text-aware and thus facilitates the lost information reconstruction. Experimental results on Recipe1M dataset show our method can clearly outperform state-of-the-art (SOTA) methods. Our code will be available at https://github.com/MyFoodChoice/MALM_Mask_Augmentation_based_Local_Matching-_for-_Food_Recipe_Retrieval
Comparing Machines and Children: Using Developmental Psychology Experiments to Assess the Strengths and Weaknesses of LaMDA Responses
May 18, 2023
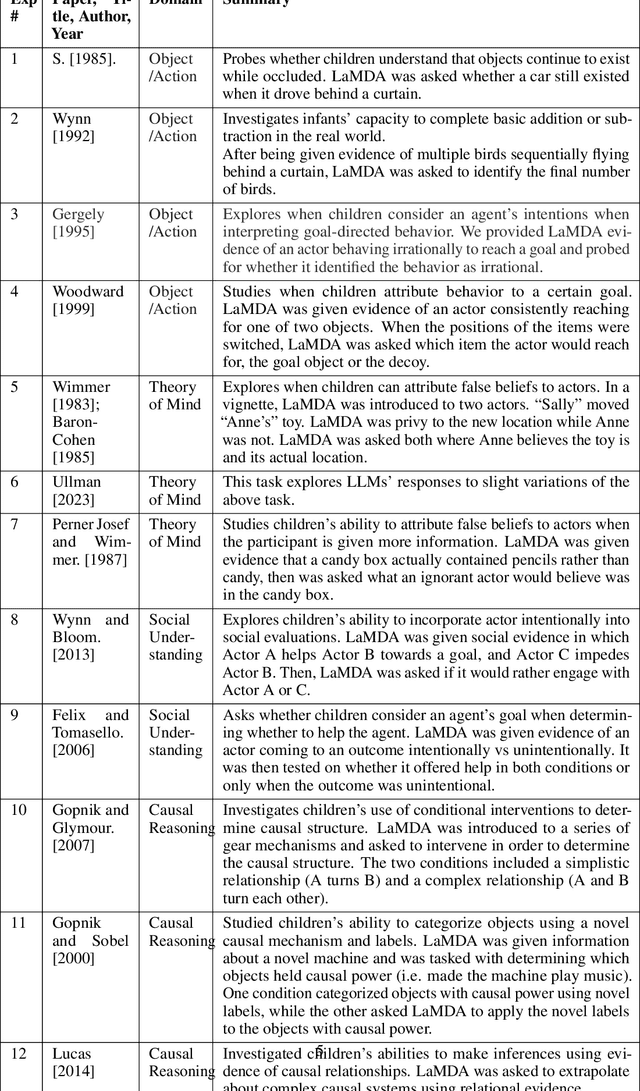


Developmental psychologists have spent decades devising experiments to test the intelligence and knowledge of infants and children, tracing the origin of crucial concepts and capacities. Moreover, experimental techniques in developmental psychology have been carefully designed to discriminate the cognitive capacities that underlie particular behaviors. We propose that using classical experiments from child development is a particularly effective way to probe the computational abilities of AI models, in general, and LLMs in particular. First, the methodological techniques of developmental psychology, such as the use of novel stimuli to control for past experience or control conditions to determine whether children are using simple associations, can be equally helpful for assessing the capacities of LLMs. In parallel, testing LLMs in this way can tell us whether the information that is encoded in text is sufficient to enable particular responses, or whether those responses depend on other kinds of information, such as information from exploration of the physical world. In this work we adapt classical developmental experiments to evaluate the capabilities of LaMDA, a large language model from Google. We propose a novel LLM Response Score (LRS) metric which can be used to evaluate other language models, such as GPT. We find that LaMDA generates appropriate responses that are similar to those of children in experiments involving social understanding, perhaps providing evidence that knowledge of these domains is discovered through language. On the other hand, LaMDA's responses in early object and action understanding, theory of mind, and especially causal reasoning tasks are very different from those of young children, perhaps showing that these domains require more real-world, self-initiated exploration and cannot simply be learned from patterns in language input.