 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-query Vehicle Re-identification: Viewpoint-conditioned Network, Unified Dataset and New Metric
May 25, 2023
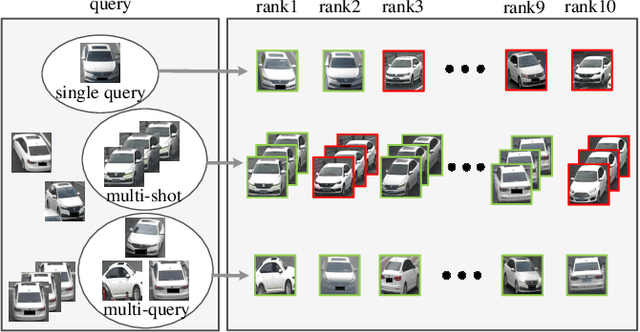
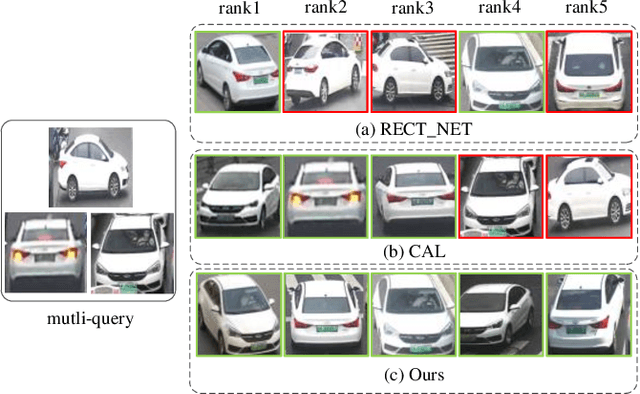
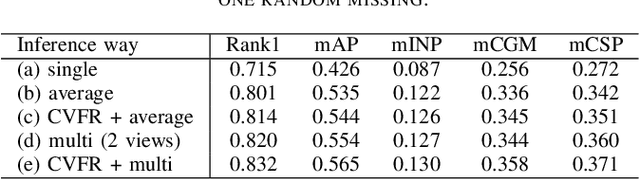
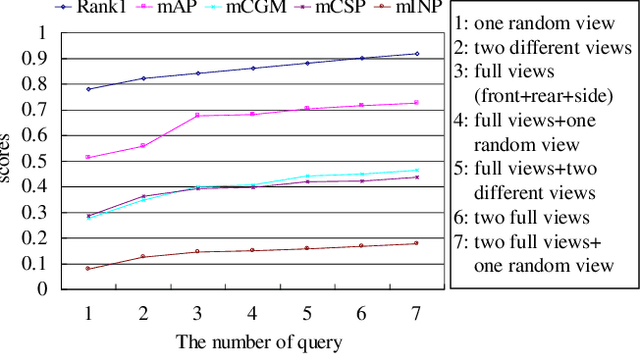
Existing vehicle re-identification methods mainly rely on the single query, which has limited information for vehicle representation and thus significantly hinders the performance of vehicle Re-ID in complicated surveillance networks. In this paper, we propose a more realistic and easily accessible task, called multi-query vehicle Re-ID, which leverages multiple queries to overcome viewpoint limitation of single one. Based on this task, we make three major contributions. First, we design a novel viewpoint-conditioned network (VCNet), which adaptively combines the complementary information from different vehicle viewpoints, for multi-query vehicle Re-ID. Moreover, to deal with the problem of missing vehicle viewpoints, we propose a cross-view feature recovery module which recovers the features of the missing viewpoints by learnt the correlation between the features of available and missing viewpoints. Second, we create a unified benchmark dataset, taken by 6142 cameras from a real-life transportation surveillance system, with comprehensive viewpoints and large number of crossed scenes of each vehicle for multi-query vehicle Re-ID evaluation. Finally, we design a new evaluation metric, called mean cross-scene precision (mCSP), which measures the ability of cross-scene recognition by suppressing the positive samples with similar viewpoints from same camera. Comprehensive experiments validate the superiority of the proposed method against other methods, as well as the effectiveness of the designed metric in the evaluation of multi-query vehicle Re-ID.
Methods and Tools to Advance the Retrieval of Mathematical Knowledge from Digital Libraries for Search-, Recommendation-, and Assistance-Systems
May 12, 2023
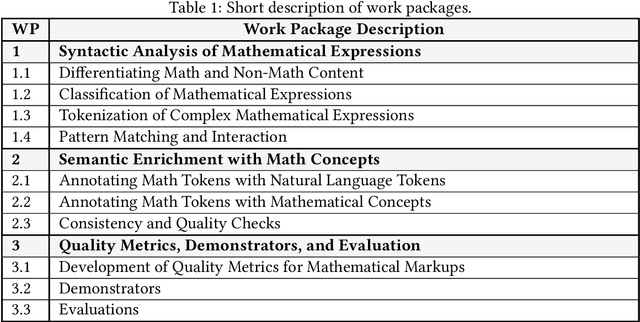

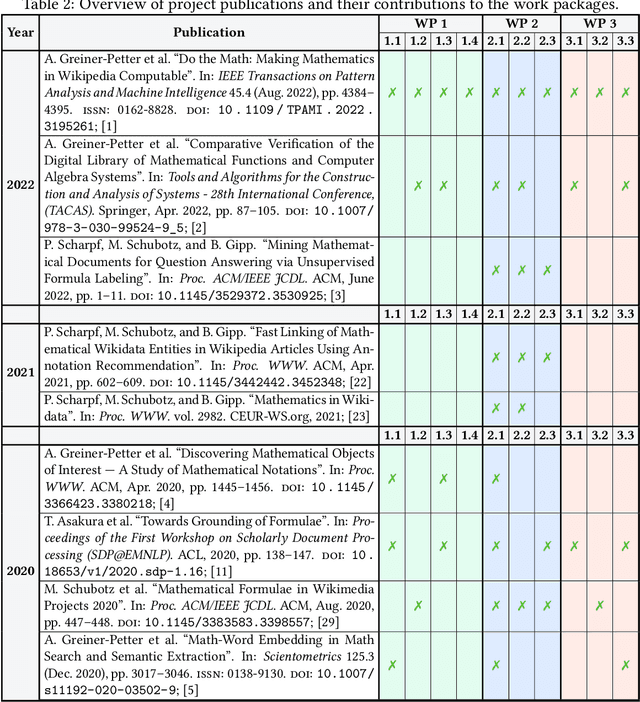
This project investigated new approaches and technologies to enhance the accessibility of mathematical content and its semantic information for a broad range of information retrieval applications. To achieve this goal, the project addressed three main research challenges: (1) syntactic analysis of mathematical expressions, (2) semantic enrichment of mathematical expressions, and (3) evaluation using quality metrics and demonstrators. To make our research useful for the research community, we published tools that enable researchers to process mathematical expressions more effectively and efficiently.
Photo-zSNthesis: Converting Type Ia Supernova Lightcurves to Redshift Estimates via Deep Learning
May 19, 2023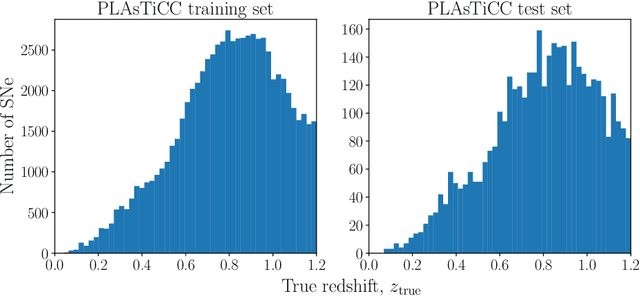

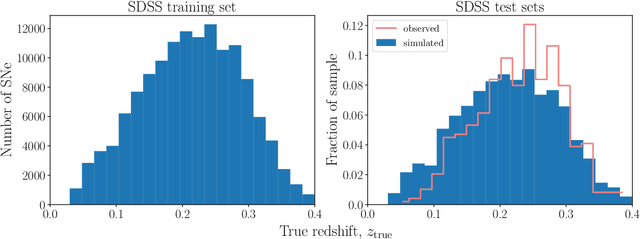
Upcoming photometric surveys will discover tens of thousands of Type Ia supernovae (SNe Ia), vastly outpacing the capacity of our spectroscopic resources. In order to maximize the science return of these observations in the absence of spectroscopic information, we must accurately extract key parameters, such as SN redshifts, with photometric information alone. We present Photo-zSNthesis, a convolutional neural network-based method for predicting full redshift probability distributions from multi-band supernova lightcurves, tested on both simulated Sloan Digital Sky Survey (SDSS) and Vera C. Rubin Legacy Survey of Space and Time (LSST) data as well as observed SDSS SNe. We show major improvements over predictions from existing methods on both simulations and real observations as well as minimal redshift-dependent bias, which is a challenge due to selection effects, e.g. Malmquist bias. The PDFs produced by this method are well-constrained and will maximize the cosmological constraining power of photometric SNe Ia samples.
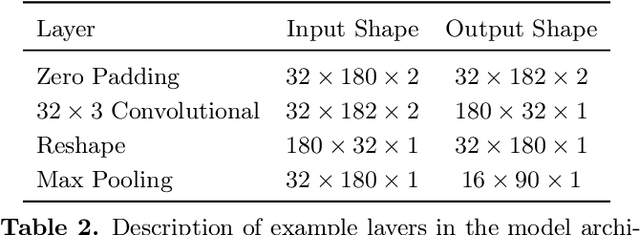
Video Killed the HD-Map: Predicting Driving Behavior Directly From Drone Images
May 19, 2023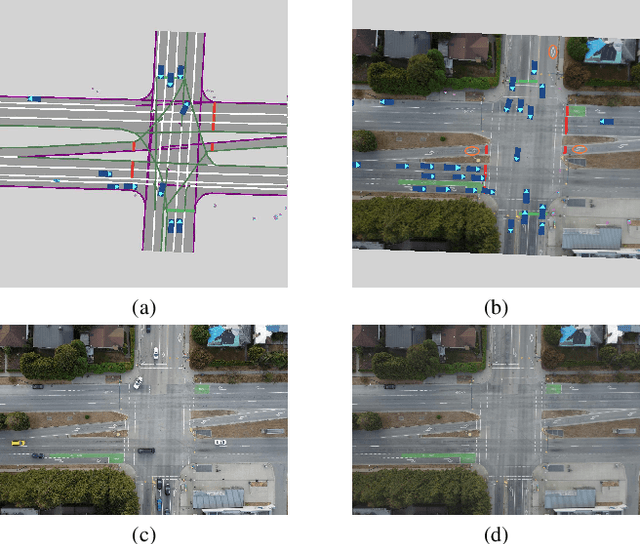
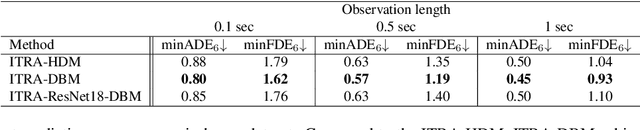
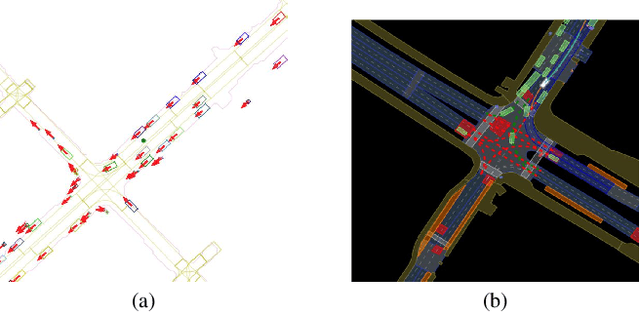

The development of algorithms that learn behavioral driving models using human demonstrations has led to increasingly realistic simulations. In general, such models learn to jointly predict trajectories for all controlled agents by exploiting road context information such as drivable lanes obtained from manually annotated high-definition (HD) maps. Recent studies show that these models can greatly benefit from increasing the amount of human data available for training. However, the manual annotation of HD maps which is necessary for every new location puts a bottleneck on efficiently scaling up human traffic datasets. We propose a drone birdview image-based map (DBM) representation that requires minimal annotation and provides rich road context information. We evaluate multi-agent trajectory prediction using the DBM by incorporating it into a differentiable driving simulator as an image-texture-based differentiable rendering module. Our results demonstrate competitive multi-agent trajectory prediction performance when using our DBM representation as compared to models trained with rasterized HD maps.
Incomplete Multi-view Clustering via Diffusion Completion
May 19, 2023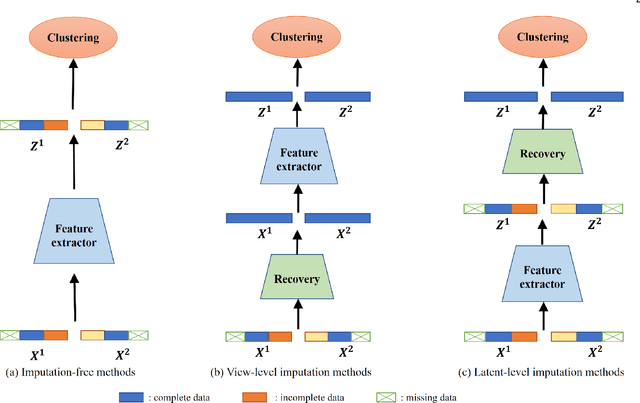
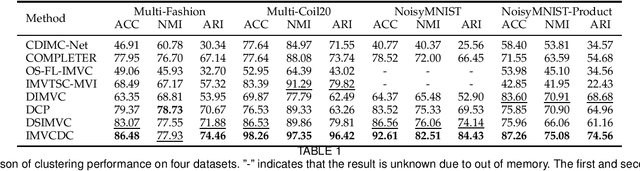
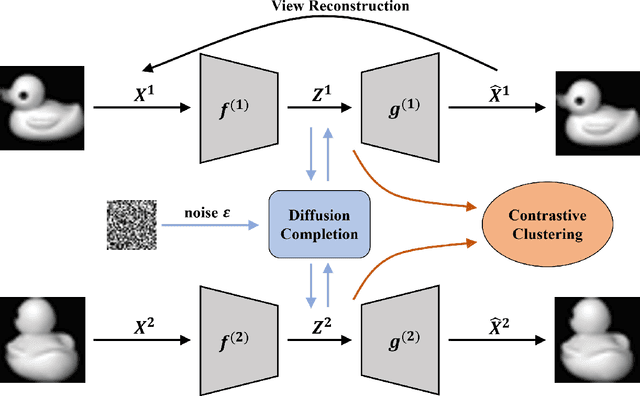

Incomplete multi-view clustering is a challenging and non-trivial task to provide effective data analysis for large amounts of unlabeled data in the real world. All incomplete multi-view clustering methods need to address the problem of how to reduce the impact of missing views. To address this issue, we propose diffusion completion to recover the missing views integrated into an incomplete multi-view clustering framework. Based on the observable views information, the diffusion model is used to recover the missing views, and then the consistency information of the multi-view data is learned by contrastive learning to improve the performance of multi-view clustering. To the best of our knowledge, this may be the first work to incorporate diffusion models into an incomplete multi-view clustering framework. Experimental results show that the proposed method performs well in recovering the missing views while achieving superior clustering performance compared to state-of-the-art methods.
Deliberate then Generate: Enhanced Prompting Framework for Text Generation
May 31, 2023
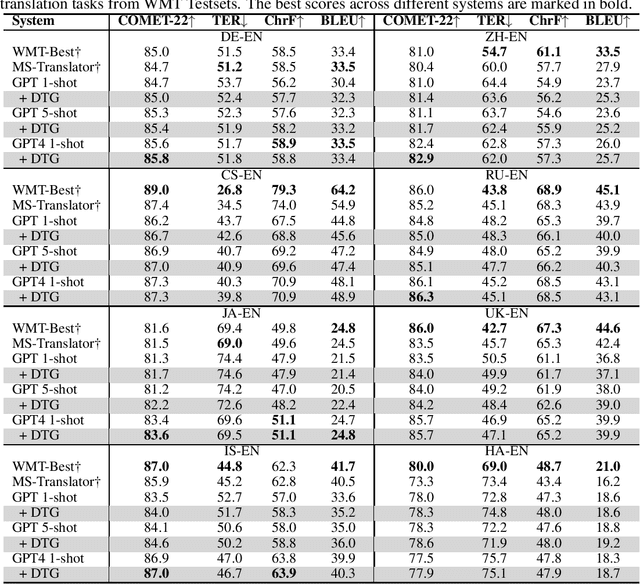

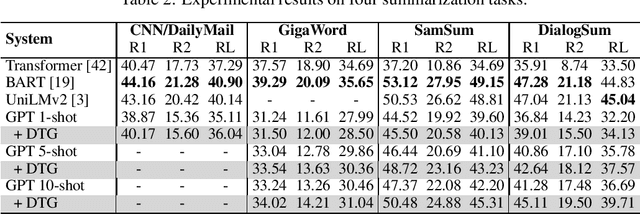
Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
Causal discovery for time series with constraint-based model and PMIME measure
May 31, 2023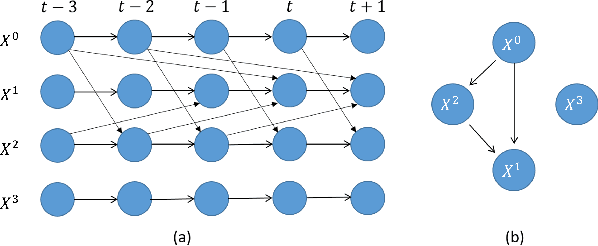
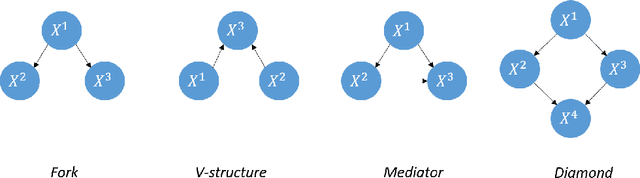
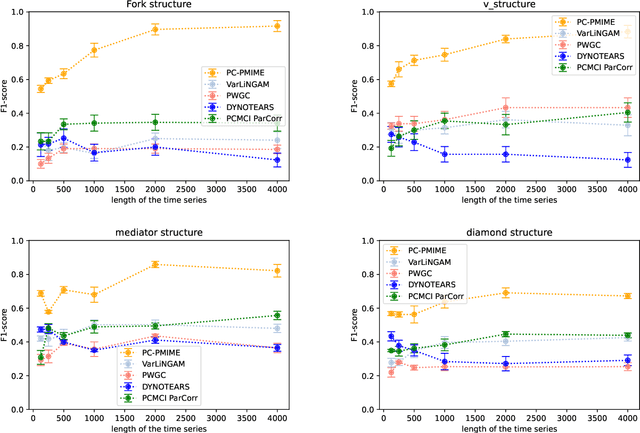
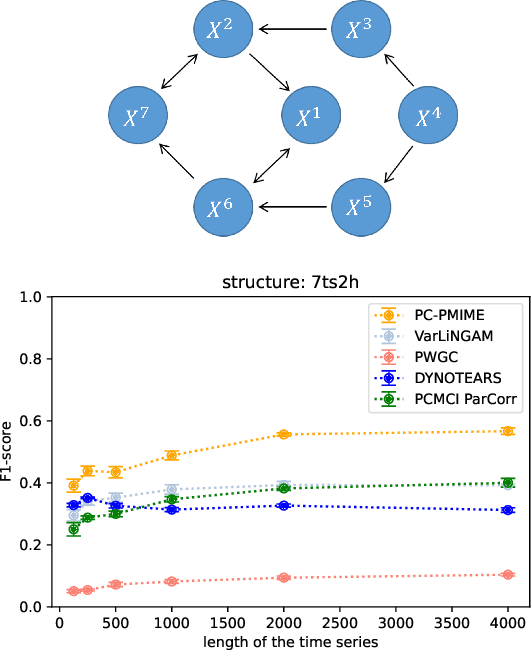
Causality defines the relationship between cause and effect. In multivariate time series field, this notion allows to characterize the links between several time series considering temporal lags. These phenomena are particularly important in medicine to analyze the effect of a drug for example, in manufacturing to detect the causes of an anomaly in a complex system or in social sciences... Most of the time, studying these complex systems is made through correlation only. But correlation can lead to spurious relationships. To circumvent this problem, we present in this paper a novel approach for discovering causality in time series data that combines a causal discovery algorithm with an information theoretic-based measure. Hence the proposed method allows inferring both linear and non-linear relationships and building the underlying causal graph. We evaluate the performance of our approach on several simulated data sets, showing promising results.
ViLaS: Integrating Vision and Language into Automatic Speech Recognition
May 31, 2023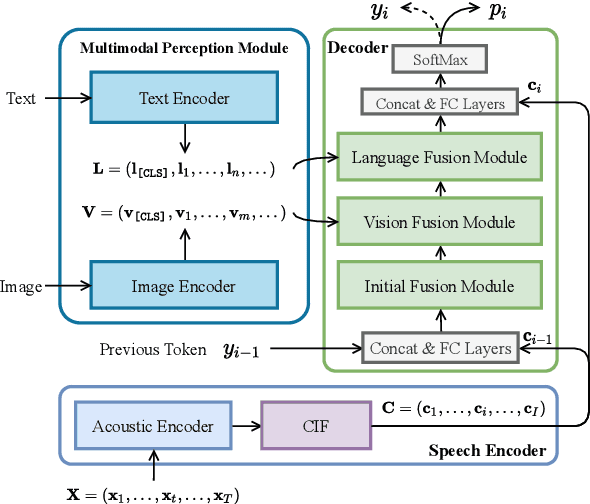
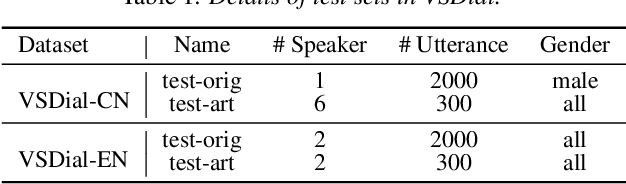
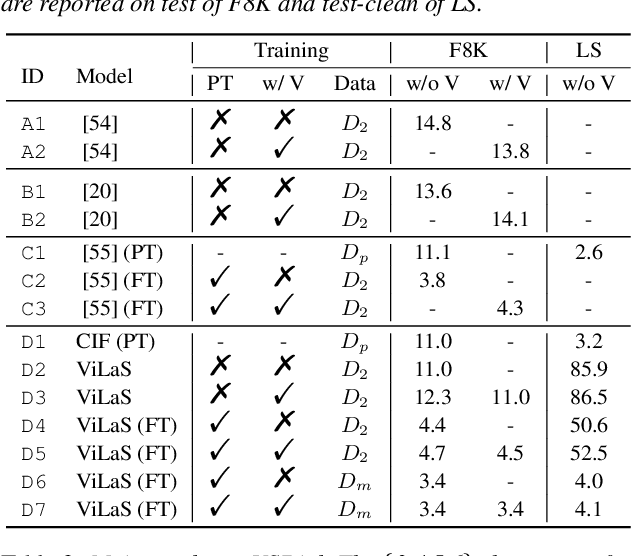
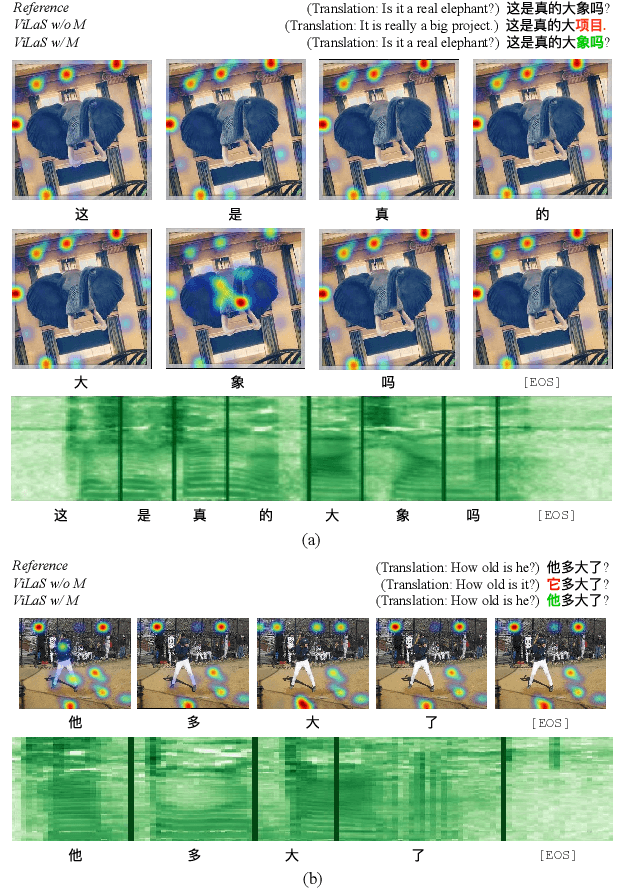
Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.
Designing Closed-Loop Models for Task Allocation
May 31, 2023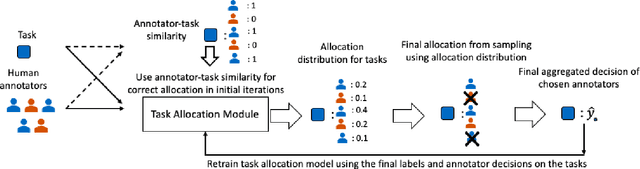
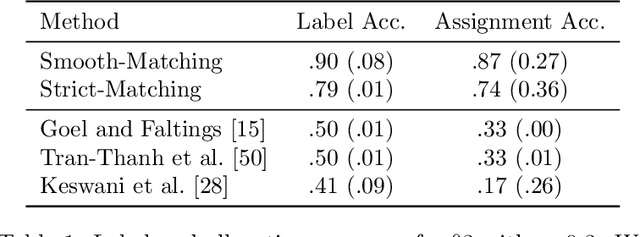

Automatically assigning tasks to people is challenging because human performance can vary across tasks for many reasons. This challenge is further compounded in real-life settings in which no oracle exists to assess the quality of human decisions and task assignments made. Instead, we find ourselves in a "closed" decision-making loop in which the same fallible human decisions we rely on in practice must also be used to guide task allocation. How can imperfect and potentially biased human decisions train an accurate allocation model? Our key insight is to exploit weak prior information on human-task similarity to bootstrap model training. We show that the use of such a weak prior can improve task allocation accuracy, even when human decision-makers are fallible and biased. We present both theoretical analysis and empirical evaluation over synthetic data and a social media toxicity detection task. Results demonstrate the efficacy of our approach.
Space Net Optimization
May 31, 2023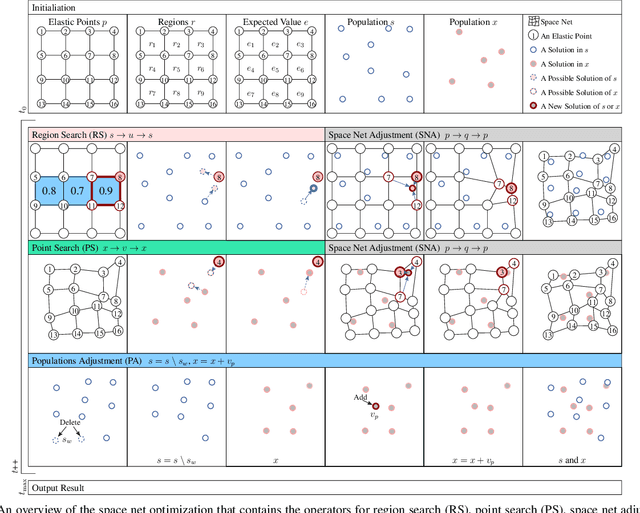

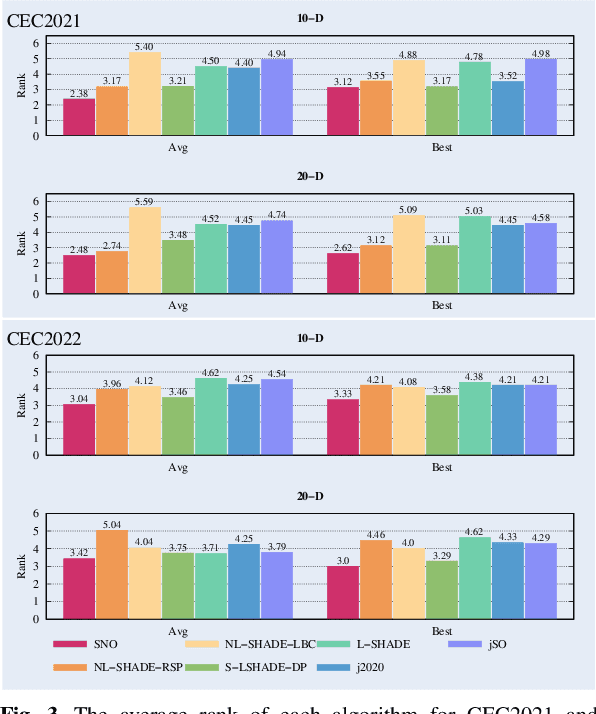
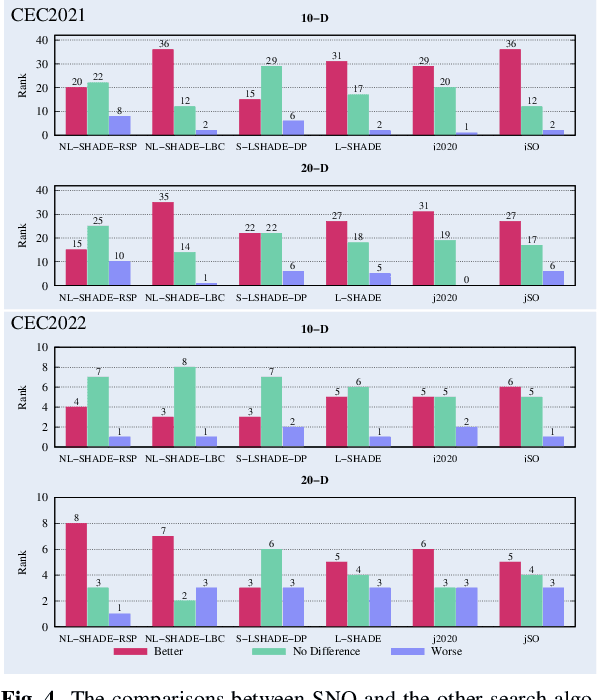
Most metaheuristic algorithms rely on a few searched solutions to guide later searches during the convergence process for a simple reason: the limited computing resource of a computer makes it impossible to retain all the searched solutions. This also reveals that each search of most metaheuristic algorithms is just like a ballpark guess. To help address this issue, we present a novel metaheuristic algorithm called space net optimization (SNO). It is equipped with a new mechanism called space net; thus, making it possible for a metaheuristic algorithm to use most information provided by all searched solutions to depict the landscape of the solution space. With the space net, a metaheuristic algorithm is kind of like having a ``vision'' on the solution space. Simulation results show that SNO outperforms all the other metaheuristic algorithms compared in this study for a set of well-known single objective bound constrained problems in most cases.