 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
End-to-end Knowledge Retrieval with Multi-modal Queries
Jun 01, 2023


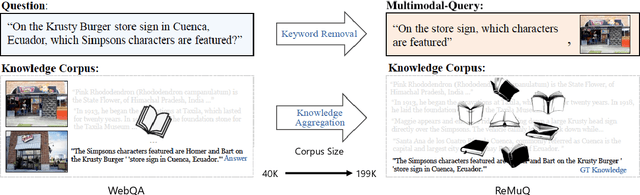
We investigate knowledge retrieval with multi-modal queries, i.e. queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. We curate a new dataset called ReMuQ for benchmarking progress on this task. ReMuQ requires a system to retrieve knowledge from a large corpus by integrating contents from both text and image queries. We introduce a retriever model ``ReViz'' that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators. We introduce a new pretraining task that is effective for learning knowledge retrieval with multimodal queries and also improves performance on downstream tasks. We demonstrate superior performance in retrieval on two datasets (ReMuQ and OK-VQA) under zero-shot settings as well as further improvements when finetuned on these datasets.
Overcoming Language Bias in Remote Sensing Visual Question Answering via Adversarial Training
Jun 01, 2023
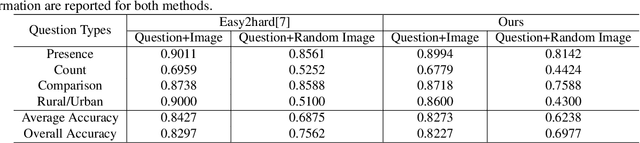
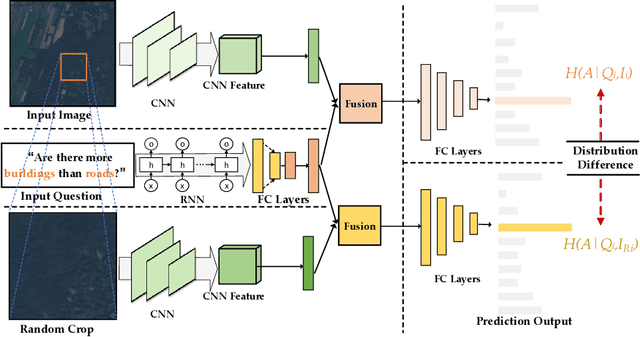
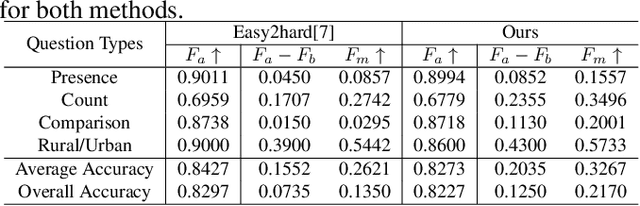
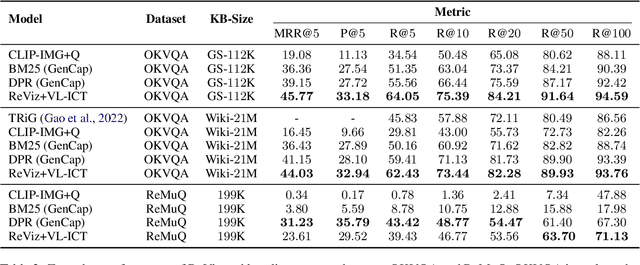
The Visual Question Answering (VQA) system offers a user-friendly interface and enables human-computer interaction. However, VQA models commonly face the challenge of language bias, resulting from the learned superficial correlation between questions and answers. To address this issue, in this study, we present a novel framework to reduce the language bias of the VQA for remote sensing data (RSVQA). Specifically, we add an adversarial branch to the original VQA framework. Based on the adversarial branch, we introduce two regularizers to constrain the training process against language bias. Furthermore, to evaluate the performance in terms of language bias, we propose a new metric that combines standard accuracy with the performance drop when incorporating question and random image information. Experimental results demonstrate the effectiveness of our method. We believe that our method can shed light on future work for reducing language bias on the RSVQA task.
Learning When to Speak: Latency and Quality Trade-offs for Simultaneous Speech-to-Speech Translation with Offline Models
Jun 01, 2023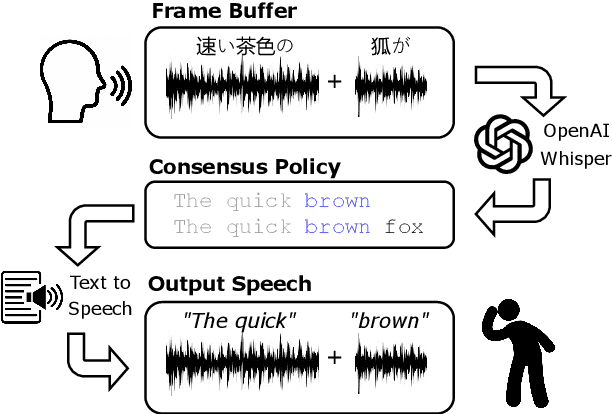
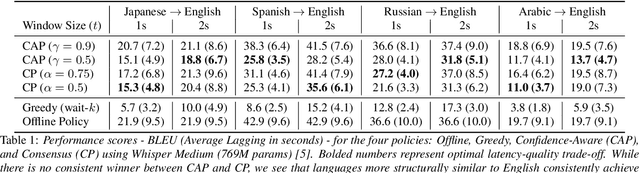
Recent work in speech-to-speech translation (S2ST) has focused primarily on offline settings, where the full input utterance is available before any output is given. This, however, is not reasonable in many real-world scenarios. In latency-sensitive applications, rather than waiting for the full utterance, translations should be spoken as soon as the information in the input is present. In this work, we introduce a system for simultaneous S2ST targeting real-world use cases. Our system supports translation from 57 languages to English with tunable parameters for dynamically adjusting the latency of the output -- including four policies for determining when to speak an output sequence. We show that these policies achieve offline-level accuracy with minimal increases in latency over a Greedy (wait-$k$) baseline. We open-source our evaluation code and interactive test script to aid future SimulS2ST research and application development.
Space-Time Phase Coupling in STMM-based Wireless Communications
Jun 01, 2023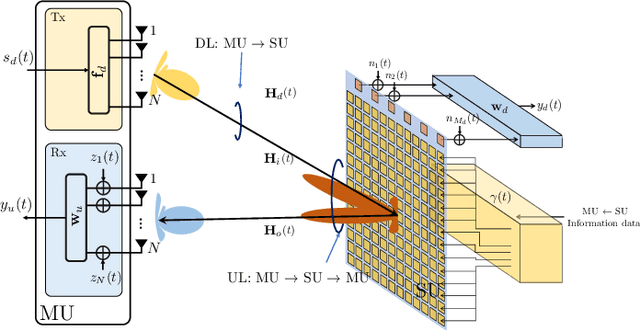
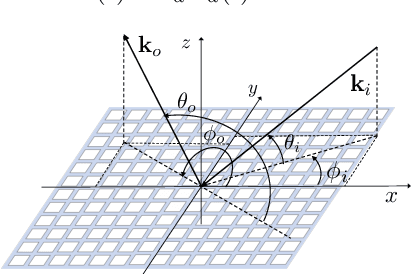
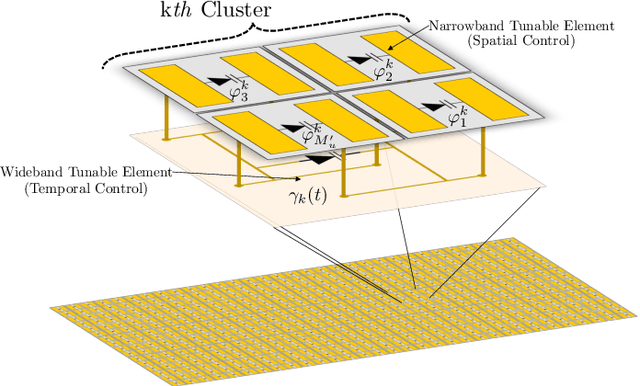
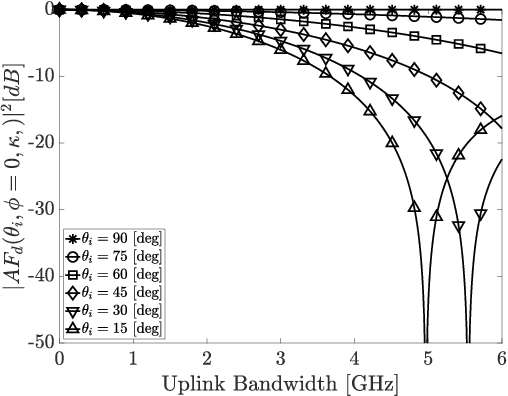
Space-time modulated metasurfaces (STMMs) are a recently proposed generalization of reconfigurable intelligent surfaces, which include a proper time-varying phase at the metasurface elements, enabling higher flexibility and control of the reflected signals. The spatial component can be designed to control the direction of reflection, while the temporal one can be adjusted to change the frequency of the reflected signal or to convey information. However, the coupling between the spatial and temporal phases at the STMM can adversely affect its performance. Therefore, this paper analyzes the system parameters that affect the space-time coupling. Furthermore, two methods for space-time decoupling are investigated. Numerical results highlight the effectiveness of the proposed decoupling methods and reveal that the space-time phase coupling increases with the bandwidth of the temporal phase, the size of the STMM, and with grazing angles of incidence onto the STMM.
A Neural RDE-based model for solving path-dependent PDEs
Jun 01, 2023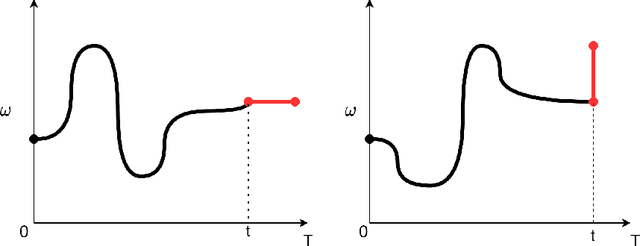
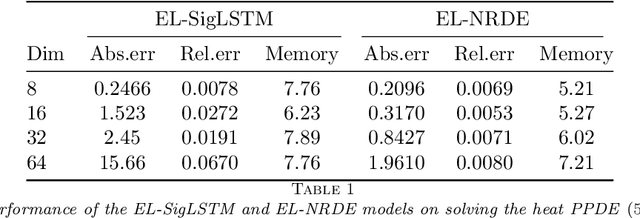
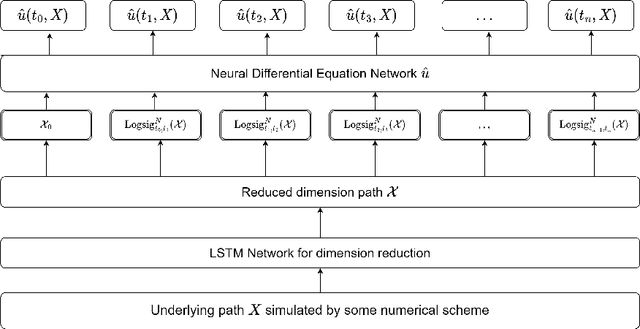
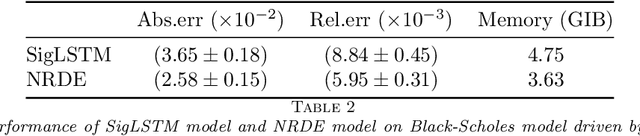
The concept of the path-dependent partial differential equation (PPDE) was first introduced in the context of path-dependent derivatives in financial markets. Its semilinear form was later identified as a non-Markovian backward stochastic differential equation (BSDE). Compared to the classical PDE, the solution of a PPDE involves an infinite-dimensional spatial variable, making it challenging to approximate, if not impossible. In this paper, we propose a neural rough differential equation (NRDE)-based model to learn PPDEs, which effectively encodes the path information through the log-signature feature while capturing the fundamental dynamics. The proposed continuous-time model for the PPDE solution offers the benefits of efficient memory usage and the ability to scale with dimensionality. Several numerical experiments, provided to validate the performance of the proposed model in comparison to the strong baseline in the literature, are used to demonstrate its effectiveness.
Does Black-box Attribute Inference Attacks on Graph Neural Networks Constitute Privacy Risk?
Jun 01, 2023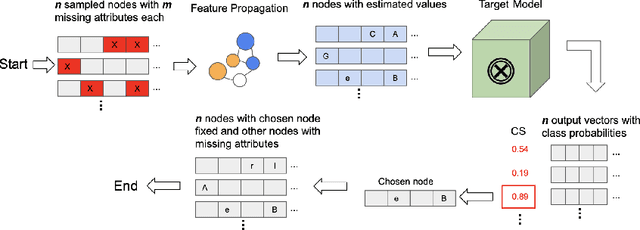
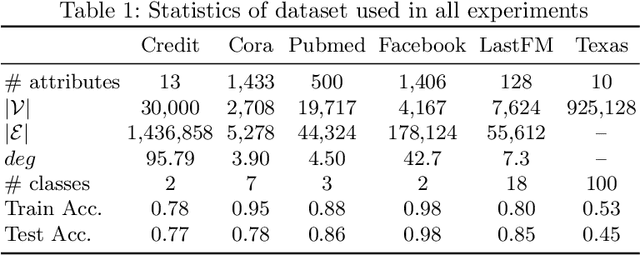
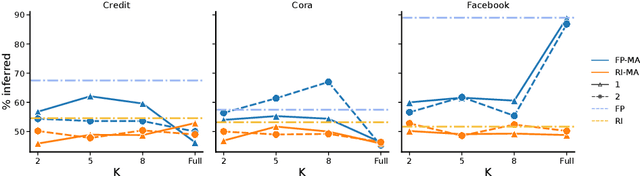
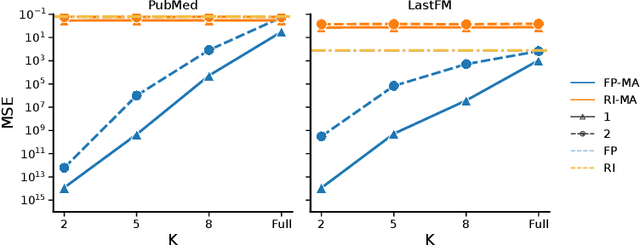
Graph neural networks (GNNs) have shown promising results on real-life datasets and applications, including healthcare, finance, and education. However, recent studies have shown that GNNs are highly vulnerable to attacks such as membership inference attack and link reconstruction attack. Surprisingly, attribute inference attacks has received little attention. In this paper, we initiate the first investigation into attribute inference attack where an attacker aims to infer the sensitive user attributes based on her public or non-sensitive attributes. We ask the question whether black-box attribute inference attack constitutes a significant privacy risk for graph-structured data and their corresponding GNN model. We take a systematic approach to launch the attacks by varying the adversarial knowledge and assumptions. Our findings reveal that when an attacker has black-box access to the target model, GNNs generally do not reveal significantly more information compared to missing value estimation techniques. Code is available.
Sea Ice Extraction via Remote Sensed Imagery: Algorithms, Datasets, Applications and Challenges
Jun 01, 2023
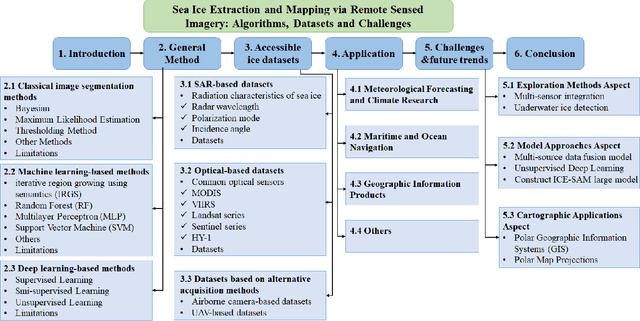
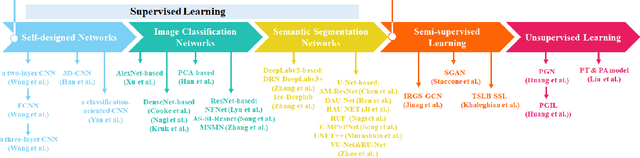
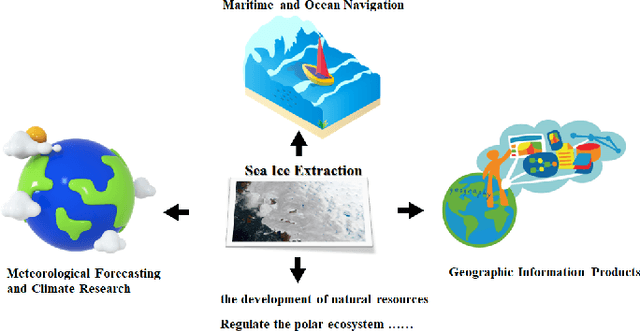
The deep learning, which is a dominating technique in artificial intelligence, has completely changed the image understanding over the past decade. As a consequence, the sea ice extraction (SIE) problem has reached a new era. We present a comprehensive review of four important aspects of SIE, including algorithms, datasets, applications, and the future trends. Our review focuses on researches published from 2016 to the present, with a specific focus on deep learning-based approaches in the last five years. We divided all relegated algorithms into 3 categories, including classical image segmentation approach, machine learning-based approach and deep learning-based methods. We reviewed the accessible ice datasets including SAR-based datasets, the optical-based datasets and others. The applications are presented in 4 aspects including climate research, navigation, geographic information systems (GIS) production and others. It also provides insightful observations and inspiring future research directions.
Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction
Mar 07, 2023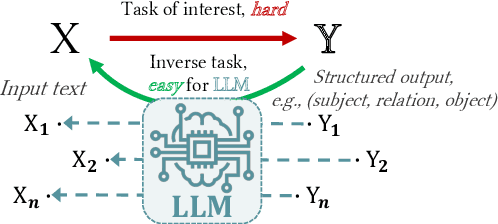

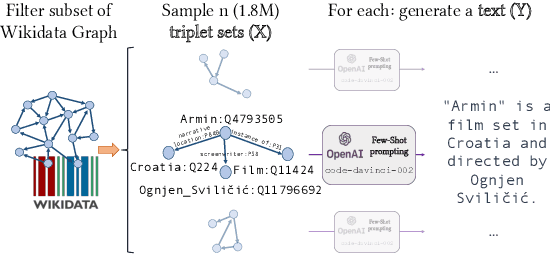
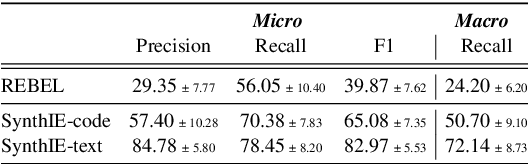
Large language models (LLMs) show great potential for synthetic data generation. This work shows that useful data can be synthetically generated even for tasks that cannot be solved directly by the LLM: we show that, for problems with structured outputs, it is possible to prompt an LLM to perform the task in the opposite direction, to generate plausible text for the target structure. Leveraging the asymmetry in task difficulty makes it possible to produce large-scale, high-quality data for complex tasks. We demonstrate the effectiveness of this approach on closed information extraction, where collecting ground-truth data is challenging, and no satisfactory dataset exists to date. We synthetically generate a dataset of 1.8M data points, demonstrate its superior quality compared to existing datasets in a human evaluation and use it to finetune small models (220M and 770M parameters). The models we introduce, SynthIE, outperform existing baselines of comparable size with a substantial gap of 57 and 79 absolute points in micro and macro F1, respectively. Code, data, and models are available at https://github.com/epfl-dlab/SynthIE.
Content-aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers
Jun 03, 2023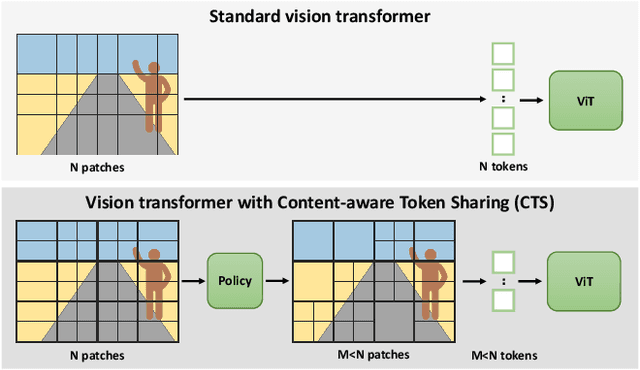
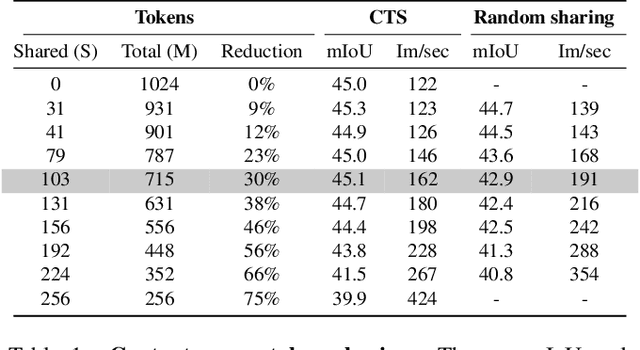
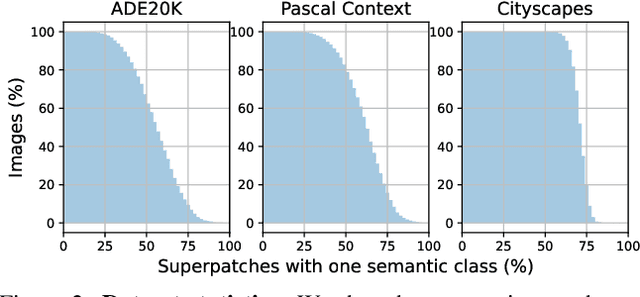
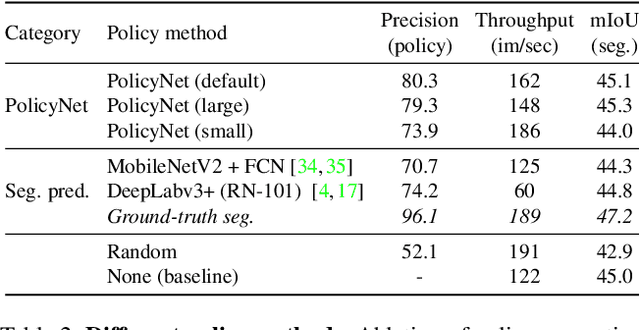
This paper introduces Content-aware Token Sharing (CTS), a token reduction approach that improves the computational efficiency of semantic segmentation networks that use Vision Transformers (ViTs). Existing works have proposed token reduction approaches to improve the efficiency of ViT-based image classification networks, but these methods are not directly applicable to semantic segmentation, which we address in this work. We observe that, for semantic segmentation, multiple image patches can share a token if they contain the same semantic class, as they contain redundant information. Our approach leverages this by employing an efficient, class-agnostic policy network that predicts if image patches contain the same semantic class, and lets them share a token if they do. With experiments, we explore the critical design choices of CTS and show its effectiveness on the ADE20K, Pascal Context and Cityscapes datasets, various ViT backbones, and different segmentation decoders. With Content-aware Token Sharing, we are able to reduce the number of processed tokens by up to 44%, without diminishing the segmentation quality.
Unsupervised Low Light Image Enhancement Using SNR-Aware Swin Transformer
Jun 03, 2023
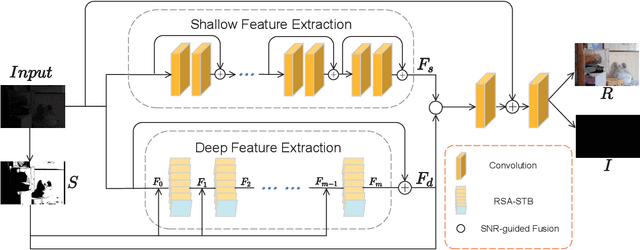
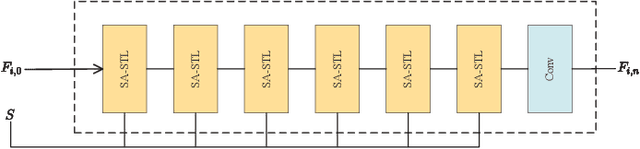
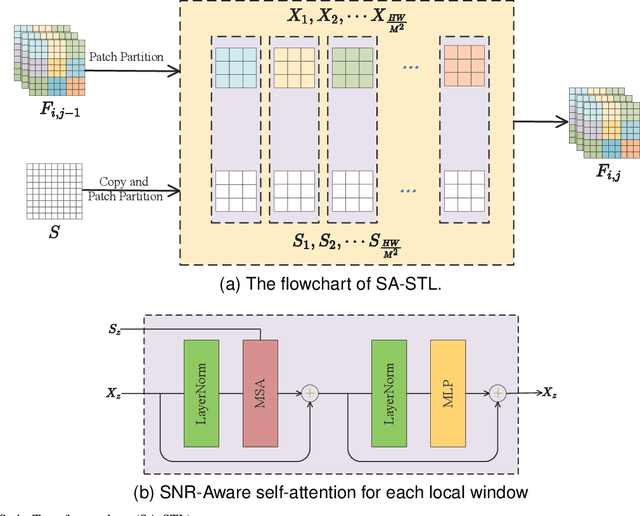
Image captured under low-light conditions presents unpleasing artifacts, which debilitate the performance of feature extraction for many upstream visual tasks. Low-light image enhancement aims at improving brightness and contrast, and further reducing noise that corrupts the visual quality. Recently, many image restoration methods based on Swin Transformer have been proposed and achieve impressive performance. However, On one hand, trivially employing Swin Transformer for low-light image enhancement would expose some artifacts, including over-exposure, brightness imbalance and noise corruption, etc. On the other hand, it is impractical to capture image pairs of low-light images and corresponding ground-truth, i.e. well-exposed image in same visual scene. In this paper, we propose a dual-branch network based on Swin Transformer, guided by a signal-to-noise ratio prior map which provides the spatial-varying information for low-light image enhancement. Moreover, we leverage unsupervised learning to construct the optimization objective based on Retinex model, to guide the training of proposed network. Experimental results demonstrate that the proposed model is competitive with the baseline models.