 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Do we become wiser with time? On causal equivalence with tiered background knowledge
Jun 02, 2023
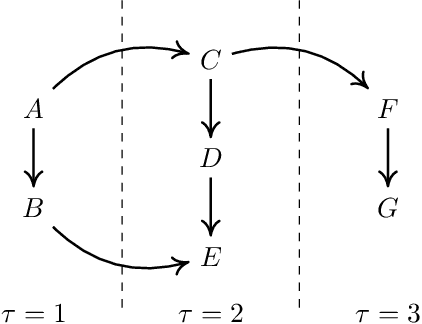
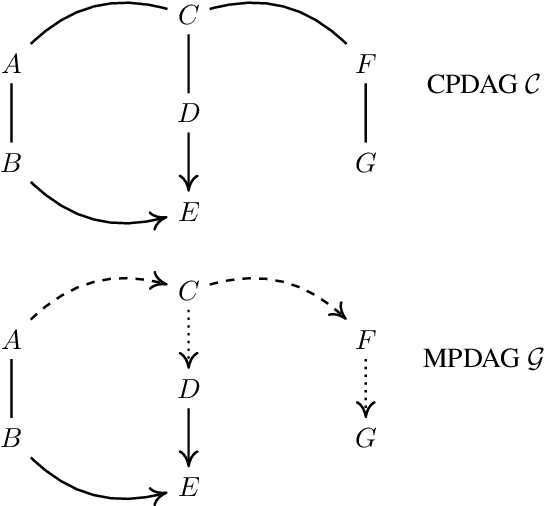
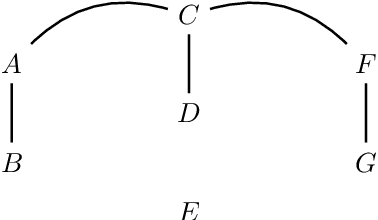
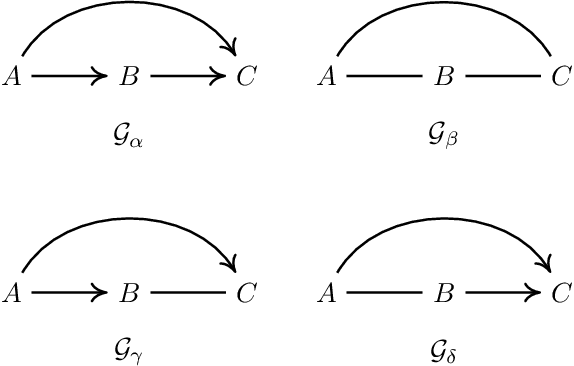
Equivalence classes of DAGs (represented by CPDAGs) may be too large to provide useful causal information. Here, we address incorporating tiered background knowledge yielding restricted equivalence classes represented by 'tiered MPDAGs'. Tiered knowledge leads to considerable gains in informativeness and computational efficiency: We show that construction of tiered MPDAGs only requires application of Meek's 1st rule, and that tiered MPDAGs (unlike general MPDAGs) are chain graphs with chordal components. This entails simplifications e.g. of determining valid adjustment sets for causal effect estimation. Further, we characterise when one tiered ordering is more informative than another, providing insights into useful aspects of background knowledge.
Towards Argument-Aware Abstractive Summarization of Long Legal Opinions with Summary Reranking
Jun 01, 2023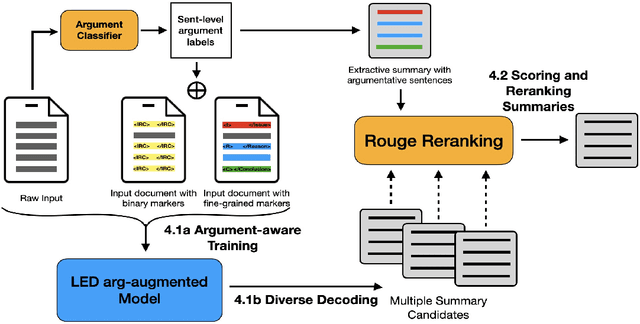
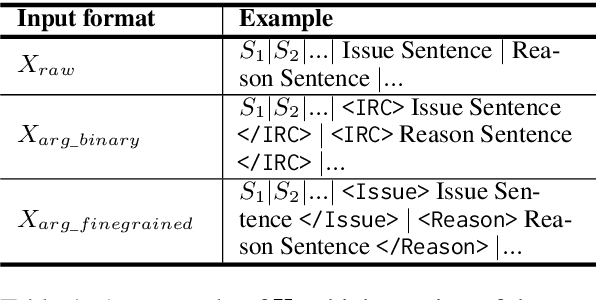
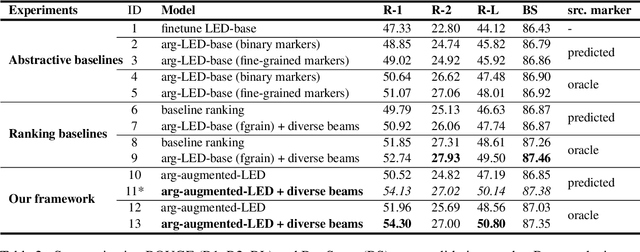
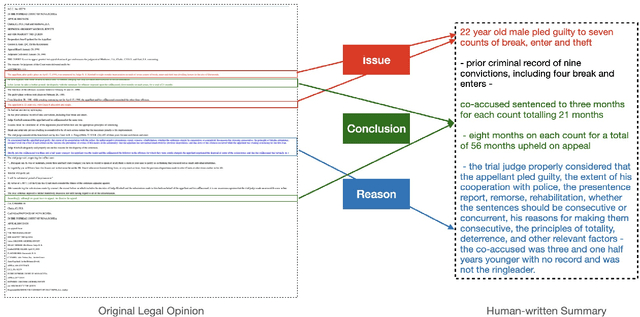
We propose a simple approach for the abstractive summarization of long legal opinions that considers the argument structure of the document. Legal opinions often contain complex and nuanced argumentation, making it challenging to generate a concise summary that accurately captures the main points of the legal opinion. Our approach involves using argument role information to generate multiple candidate summaries, then reranking these candidates based on alignment with the document's argument structure. We demonstrate the effectiveness of our approach on a dataset of long legal opinions and show that it outperforms several strong baselines.
MultiEarth 2023 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Jun 07, 2023

The Multimodal Learning for Earth and Environment Workshop (MultiEarth 2023) is the second annual CVPR workshop aimed at the monitoring and analysis of the health of Earth ecosystems by leveraging the vast amount of remote sensing data that is continuously being collected. The primary objective of this workshop is to bring together the Earth and environmental science communities as well as the multimodal representation learning communities to explore new ways of harnessing technological advancements in support of environmental monitoring. The MultiEarth Workshop also seeks to provide a common benchmark for processing multimodal remote sensing information by organizing public challenges focused on monitoring the Amazon rainforest. These challenges include estimating deforestation, detecting forest fires, translating synthetic aperture radar (SAR) images to the visible domain, and projecting environmental trends. This paper presents the challenge guidelines, datasets, and evaluation metrics. Our challenge website is available at https://sites.google.com/view/rainforest-challenge/multiearth-2023.
Differentiable Earth Mover's Distance for Data Compression at the High-Luminosity LHC
Jun 07, 2023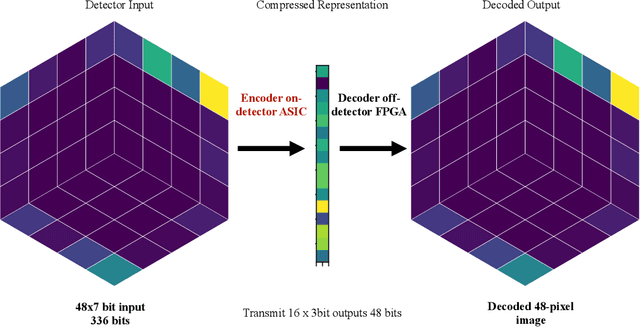
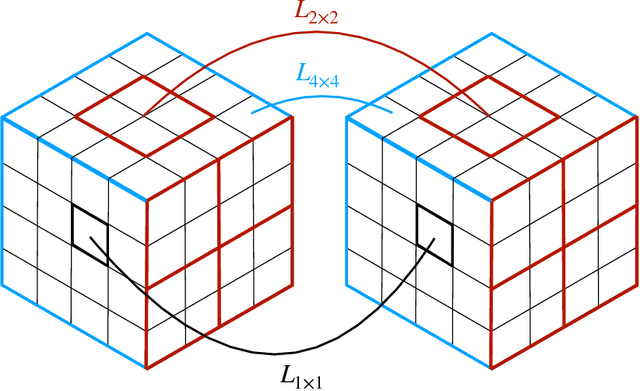
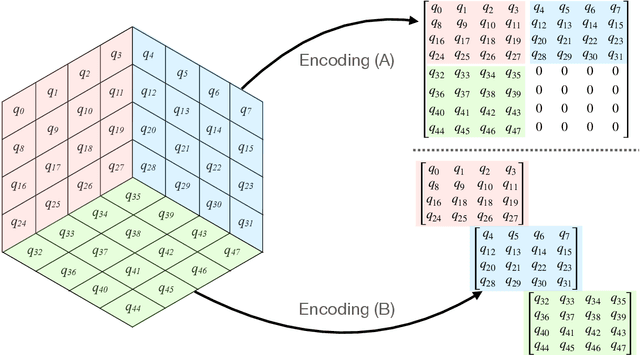
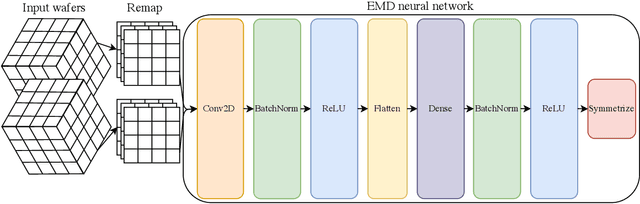
The Earth mover's distance (EMD) is a useful metric for image recognition and classification, but its usual implementations are not differentiable or too slow to be used as a loss function for training other algorithms via gradient descent. In this paper, we train a convolutional neural network (CNN) to learn a differentiable, fast approximation of the EMD and demonstrate that it can be used as a substitute for computing-intensive EMD implementations. We apply this differentiable approximation in the training of an autoencoder-inspired neural network (encoder NN) for data compression at the high-luminosity LHC at CERN. The goal of this encoder NN is to compress the data while preserving the information related to the distribution of energy deposits in particle detectors. We demonstrate that the performance of our encoder NN trained using the differentiable EMD CNN surpasses that of training with loss functions based on mean squared error.
TFDet: Target-aware Fusion for RGB-T Pedestrian Detection
May 26, 2023
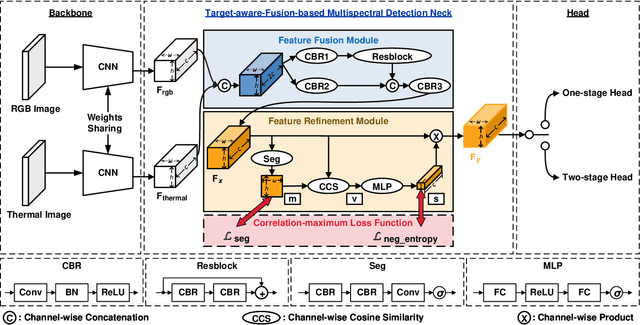
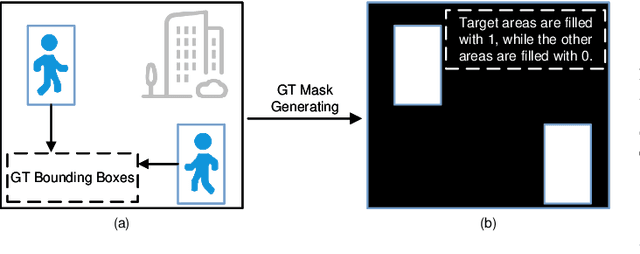
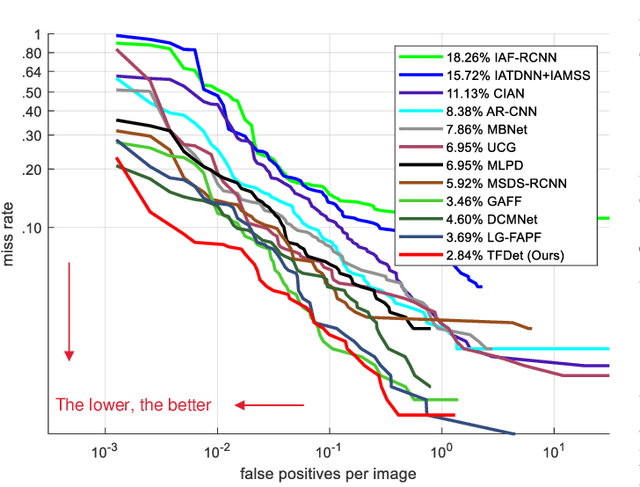
Pedestrian detection is a critical task in computer vision because of its role in ensuring traffic safety. However, existing methods that rely solely on RGB images suffer from performance degradation under low-light conditions due to the lack of useful information. To address this issue, recent multispectral detection approaches combine thermal images to provide complementary information. Nevertheless, these approaches have limitations such as the noisy fused feature maps and the loss of informative features. In this paper, we propose a novel target-aware fusion strategy for multispectral pedestrian detection, named TFDet. Unlike existing methods, TFDet enhances features by supervising the fusion process with a correlation-maximum loss function. Our fusion strategy highlights the pedestrian-related features while suppressing the unrelated ones. TFDet achieves state-of-the-art performances on both KAIST and LLVIP benchmarks, with a speed comparable to the previous state-of-the-art counterpart. Importantly, TFDet performs remarkably well under low-light conditions, which is a significant advancement for road safety.
A Multi-Scale Attentive Transformer for Multi-Instrument Symbolic Music Generation
May 26, 2023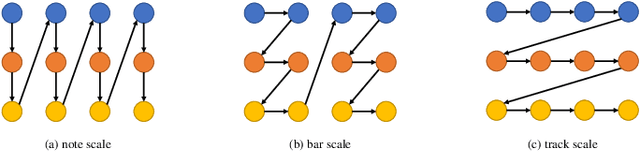
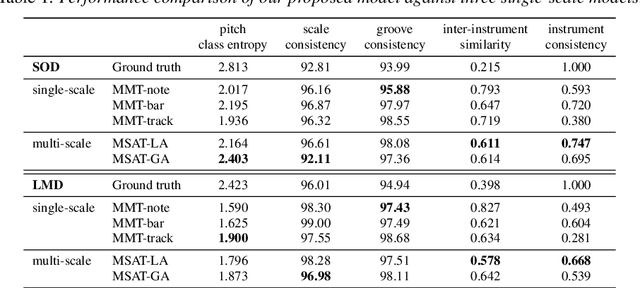
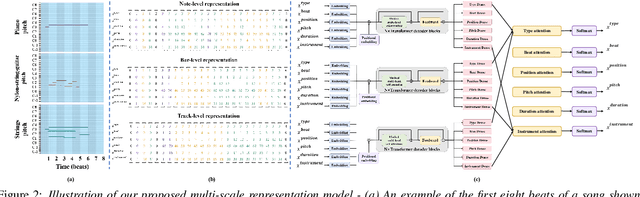
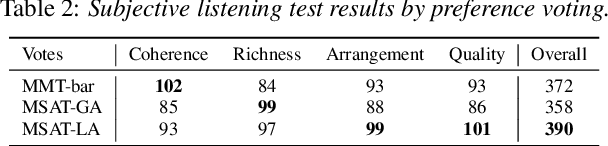
Recently, multi-instrument music generation has become a hot topic. Different from single-instrument generation, multi-instrument generation needs to consider inter-track harmony besides intra-track coherence. This is usually achieved by composing note segments from different instruments into a signal sequence. This composition could be on different scales, such as note, bar, or track. Most existing work focuses on a particular scale, leading to a shortage in modeling music with diverse temporal and track dependencies. This paper proposes a multi-scale attentive Transformer model to improve the quality of multi-instrument generation. We first employ multiple Transformer decoders to learn multi-instrument representations of different scales and then design an attentive mechanism to fuse the multi-scale information. Experiments conducted on SOD and LMD datasets show that our model improves both quantitative and qualitative performance compared to models based on single-scale information. The source code and some generated samples can be found at https://github.com/HaRry-qaq/MSAT.
Towards Cognitive Bots: Architectural Research Challenges
May 26, 2023Software bots operating in multiple virtual digital platforms must understand the platforms' affordances and behave like human users. Platform affordances or features differ from one application platform to another or through a life cycle, requiring such bots to be adaptable. Moreover, bots in such platforms could cooperate with humans or other software agents for work or to learn specific behavior patterns. However, present-day bots, particularly chatbots, other than language processing and prediction, are far from reaching a human user's behavior level within complex business information systems. They lack the cognitive capabilities to sense and act in such virtual environments, rendering their development a challenge to artificial general intelligence research. In this study, we problematize and investigate assumptions in conceptualizing software bot architecture by directing attention to significant architectural research challenges in developing cognitive bots endowed with complex behavior for operation on information systems. As an outlook, we propose alternate architectural assumptions to consider in future bot design and bot development frameworks.
Understanding the Role of Feedback in Online Learning with Switching Costs
Jun 16, 2023
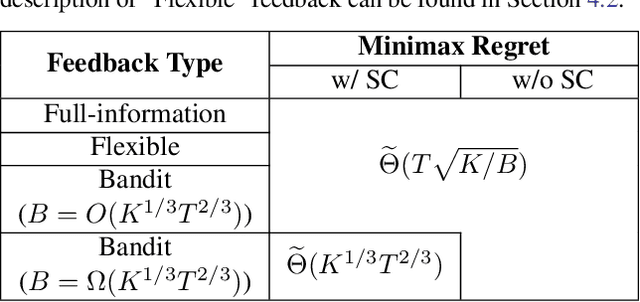
In this paper, we study the role of feedback in online learning with switching costs. It has been shown that the minimax regret is $\widetilde{\Theta}(T^{2/3})$ under bandit feedback and improves to $\widetilde{\Theta}(\sqrt{T})$ under full-information feedback, where $T$ is the length of the time horizon. However, it remains largely unknown how the amount and type of feedback generally impact regret. To this end, we first consider the setting of bandit learning with extra observations; that is, in addition to the typical bandit feedback, the learner can freely make a total of $B_{\mathrm{ex}}$ extra observations. We fully characterize the minimax regret in this setting, which exhibits an interesting phase-transition phenomenon: when $B_{\mathrm{ex}} = O(T^{2/3})$, the regret remains $\widetilde{\Theta}(T^{2/3})$, but when $B_{\mathrm{ex}} = \Omega(T^{2/3})$, it becomes $\widetilde{\Theta}(T/\sqrt{B_{\mathrm{ex}}})$, which improves as the budget $B_{\mathrm{ex}}$ increases. To design algorithms that can achieve the minimax regret, it is instructive to consider a more general setting where the learner has a budget of $B$ total observations. We fully characterize the minimax regret in this setting as well and show that it is $\widetilde{\Theta}(T/\sqrt{B})$, which scales smoothly with the total budget $B$. Furthermore, we propose a generic algorithmic framework, which enables us to design different learning algorithms that can achieve matching upper bounds for both settings based on the amount and type of feedback. One interesting finding is that while bandit feedback can still guarantee optimal regret when the budget is relatively limited, it no longer suffices to achieve optimal regret when the budget is relatively large.
S$^{3}$: Increasing GPU Utilization during Generative Inference for Higher Throughput
Jun 09, 2023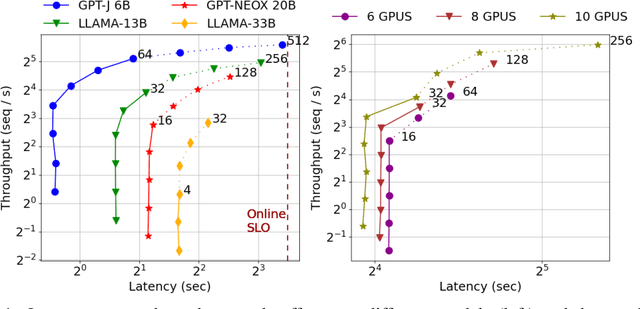
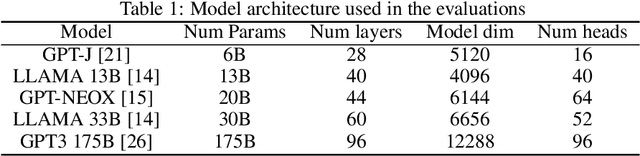
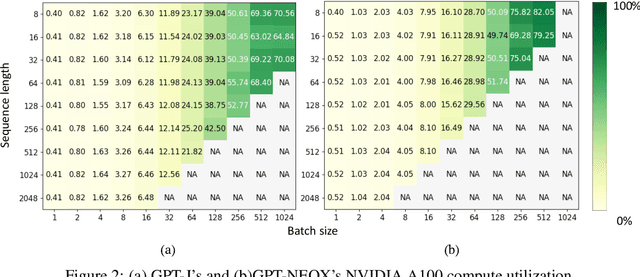
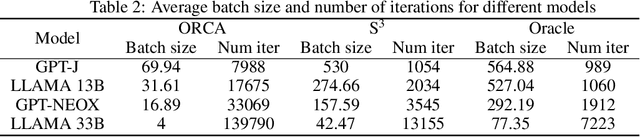
Generating texts with a large language model (LLM) consumes massive amounts of memory. Apart from the already-large model parameters, the key/value (KV) cache that holds information about previous tokens in a sequence can grow to be even larger than the model itself. This problem is exacerbated in one of the current LLM serving frameworks which reserves the maximum sequence length of memory for the KV cache to guarantee generating a complete sequence as they do not know the output sequence length. This restricts us to use a smaller batch size leading to lower GPU utilization and above all, lower throughput. We argue that designing a system with a priori knowledge of the output sequence can mitigate this problem. To this end, we propose S$^{3}$, which predicts the output sequence length, schedules generation queries based on the prediction to increase device resource utilization and throughput, and handle mispredictions. Our proposed method achieves 6.49$\times$ throughput over those systems that assume the worst case for the output sequence length.
Response Time Improves Choice Prediction and Function Estimation for Gaussian Process Models of Perception and Preferences
Jun 09, 2023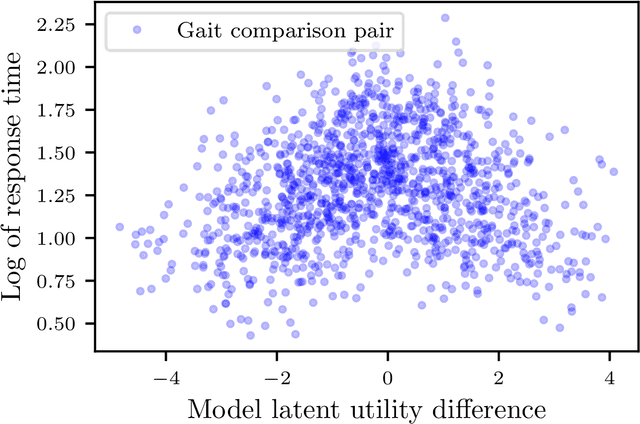
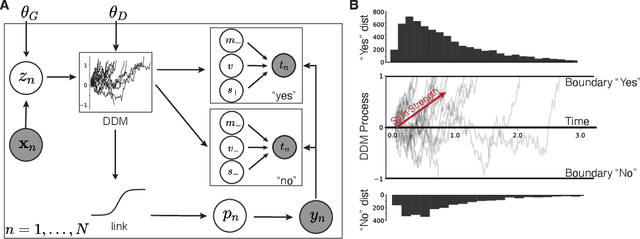
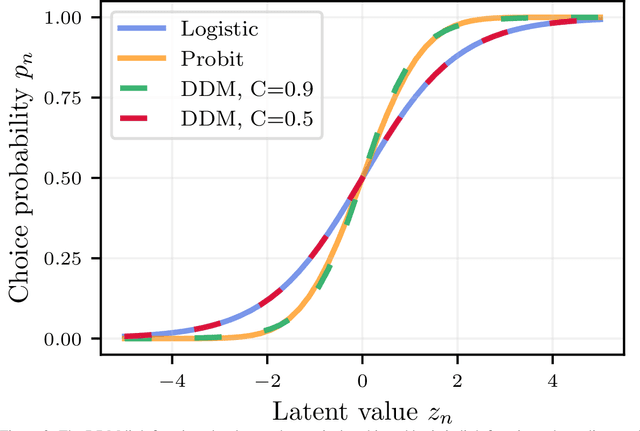
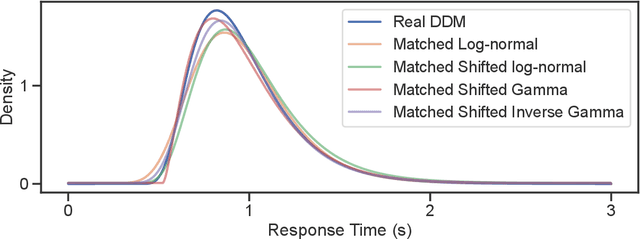
Models for human choice prediction in preference learning and psychophysics often consider only binary response data, requiring many samples to accurately learn preferences or perceptual detection thresholds. The response time (RT) to make each choice captures additional information about the decision process, however existing models incorporating RTs for choice prediction do so in fully parametric settings or over discrete stimulus sets. This is in part because the de-facto standard model for choice RTs, the diffusion decision model (DDM), does not admit tractable, differentiable inference. The DDM thus cannot be easily integrated with flexible models for continuous, multivariate function approximation, particularly Gaussian process (GP) models. We propose a novel differentiable approximation to the DDM likelihood using a family of known, skewed three-parameter distributions. We then use this new likelihood to incorporate RTs into GP models for binary choices. Our RT-choice GPs enable both better latent value estimation and held-out choice prediction relative to baselines, which we demonstrate on three real-world multivariate datasets covering both human psychophysics and preference learning applications.