 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Intelligent SDWN Routing Algorithm Based on Network Situational Awareness and Deep Reinforcement Learning
May 12, 2023
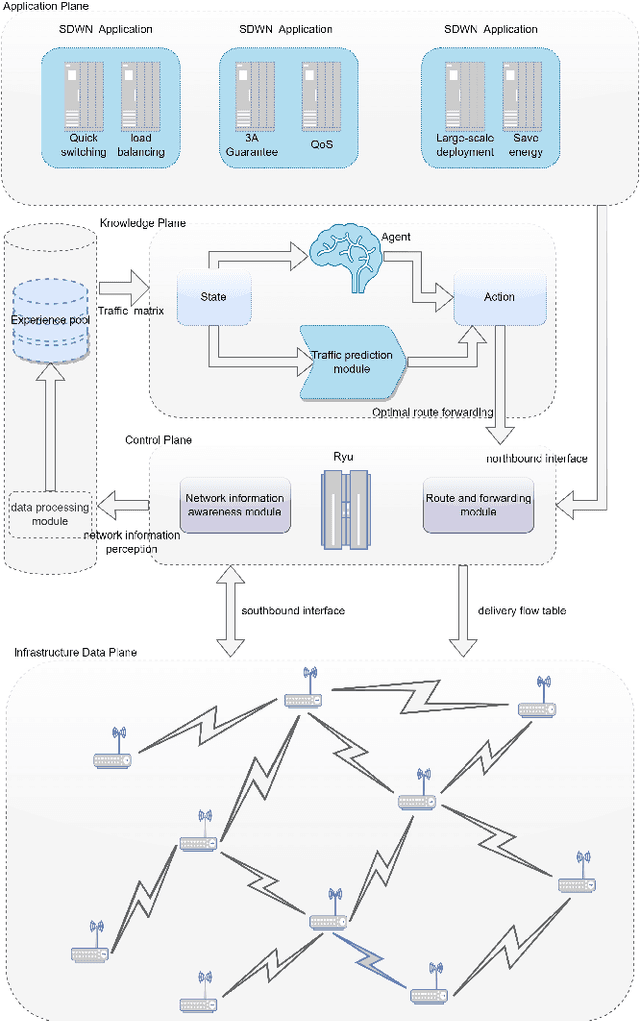
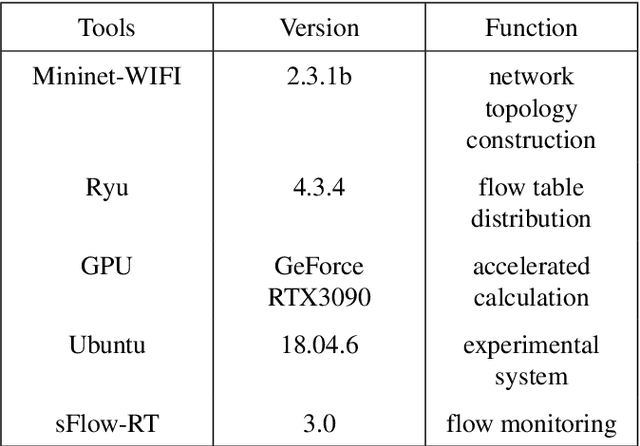
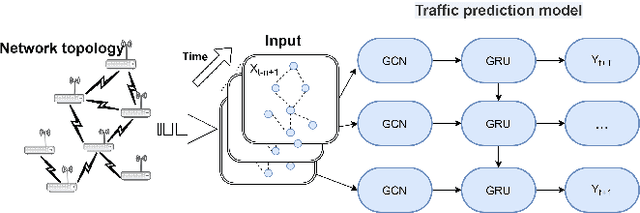
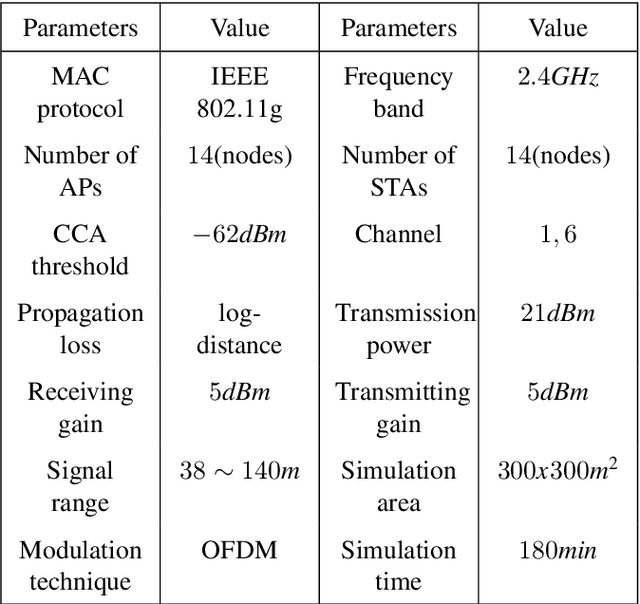
Due to the highly dynamic changes in wireless network topologies, efficiently obtaining network status information and flexibly forwarding data to improve communication quality of service are important challenges. This article introduces an intelligent routing algorithm (DRL-PPONSA) based on proximal policy optimization deep reinforcement learning with network situational awareness under a software-defined wireless networking architecture. First, a specific data plane is designed for network topology construction and data forwarding. The control plane collects network traffic information, sends flow tables, and uses a GCN-GRU prediction mechanism to perceive future traffic change trends to achieve network situational awareness. Second, a DRL-based data forwarding mechanism is designed in the knowledge plane. The predicted network traffic matrix and topology information matrix are treated as the environment for DRL agents, while next-hop adjacent nodes are treated as executable actions. Accordingly, action selection strategies are designed for different network conditions to achieve more intelligent, flexible, and efficient routing control. The reward function is designed using network link information and various reward and penalty mechanisms. Additionally, importance sampling and gradient clipping techniques are employed during gradient updating to enhance convergence speed and stability. Experimental results show that DRL-PPONSA outperforms traditional routing methods in network throughput, delay, packet loss rate, and wireless node distance. Compared to value-function-based Dueling DQN routing, the convergence speed is significantly improved, and the convergence effect is more stable. Simultaneously, its consumption of hardware storage space is reduced, and efficient routing decisions can be made in real-time using the current network state information.
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023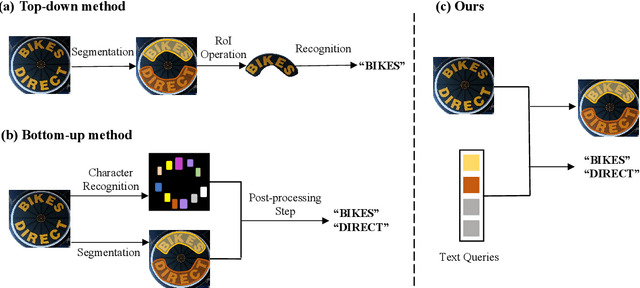
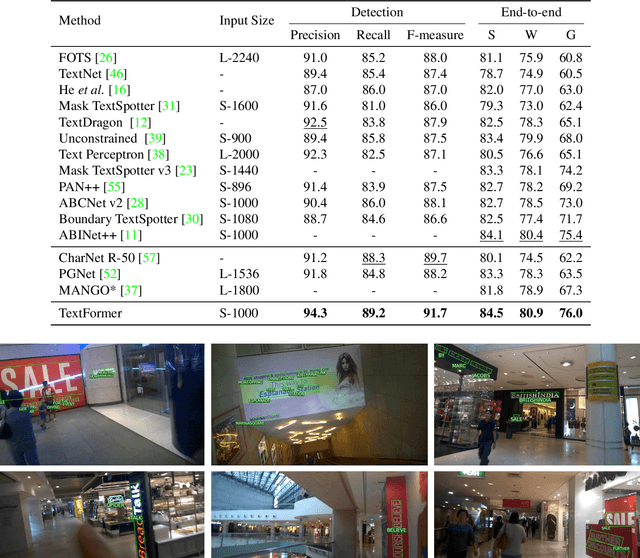

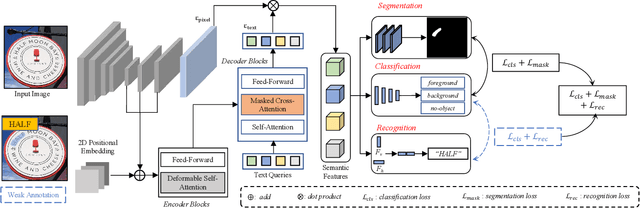
End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
How does over-squashing affect the power of GNNs?
Jun 06, 2023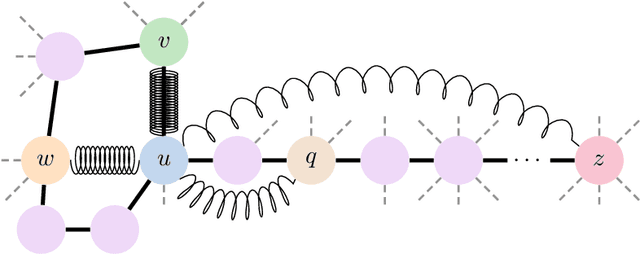

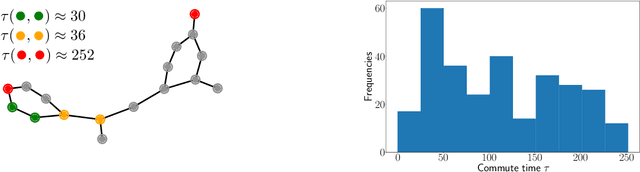
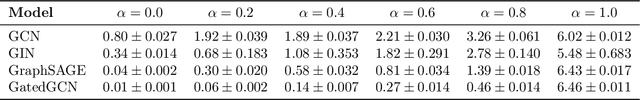
Graph Neural Networks (GNNs) are the state-of-the-art model for machine learning on graph-structured data. The most popular class of GNNs operate by exchanging information between adjacent nodes, and are known as Message Passing Neural Networks (MPNNs). Given their widespread use, understanding the expressive power of MPNNs is a key question. However, existing results typically consider settings with uninformative node features. In this paper, we provide a rigorous analysis to determine which function classes of node features can be learned by an MPNN of a given capacity. We do so by measuring the level of pairwise interactions between nodes that MPNNs allow for. This measure provides a novel quantitative characterization of the so-called over-squashing effect, which is observed to occur when a large volume of messages is aggregated into fixed-size vectors. Using our measure, we prove that, to guarantee sufficient communication between pairs of nodes, the capacity of the MPNN must be large enough, depending on properties of the input graph structure, such as commute times. For many relevant scenarios, our analysis results in impossibility statements in practice, showing that over-squashing hinders the expressive power of MPNNs. We validate our theoretical findings through extensive controlled experiments and ablation studies.
Schema First! Learn Versatile Knowledge Graph Embeddings by Capturing Semantics with MASCHInE
Jun 06, 2023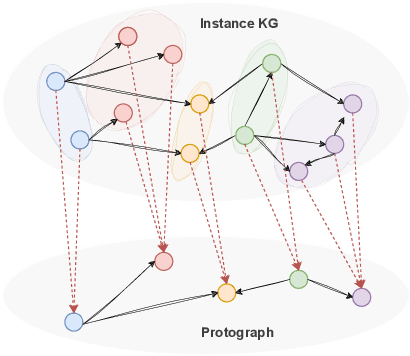
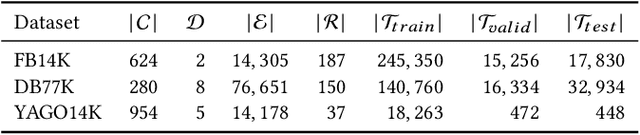
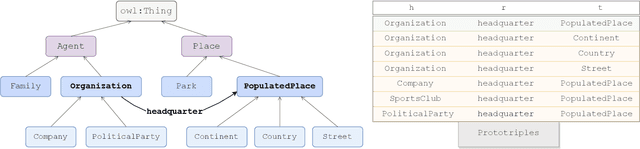
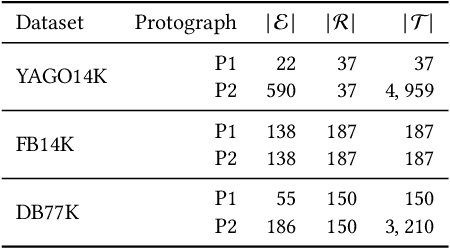
Knowledge graph embedding models (KGEMs) have gained considerable traction in recent years. These models learn a vector representation of knowledge graph entities and relations, a.k.a. knowledge graph embeddings (KGEs). Learning versatile KGEs is desirable as it makes them useful for a broad range of tasks. However, KGEMs are usually trained for a specific task, which makes their embeddings task-dependent. In parallel, the widespread assumption that KGEMs actually create a semantic representation of the underlying entities and relations (e.g., project similar entities closer than dissimilar ones) has been challenged. In this work, we design heuristics for generating protographs -- small, modified versions of a KG that leverage schema-based information. The learnt protograph-based embeddings are meant to encapsulate the semantics of a KG, and can be leveraged in learning KGEs that, in turn, also better capture semantics. Extensive experiments on various evaluation benchmarks demonstrate the soundness of this approach, which we call Modular and Agnostic SCHema-based Integration of protograph Embeddings (MASCHInE). In particular, MASCHInE helps produce more versatile KGEs that yield substantially better performance for entity clustering and node classification tasks. For link prediction, using MASCHInE has little impact on rank-based performance but increases the number of semantically valid predictions.
Human-Object Interaction Prediction in Videos through Gaze Following
Jun 06, 2023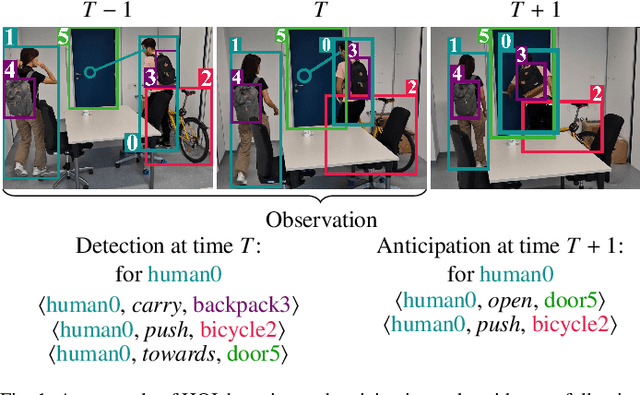
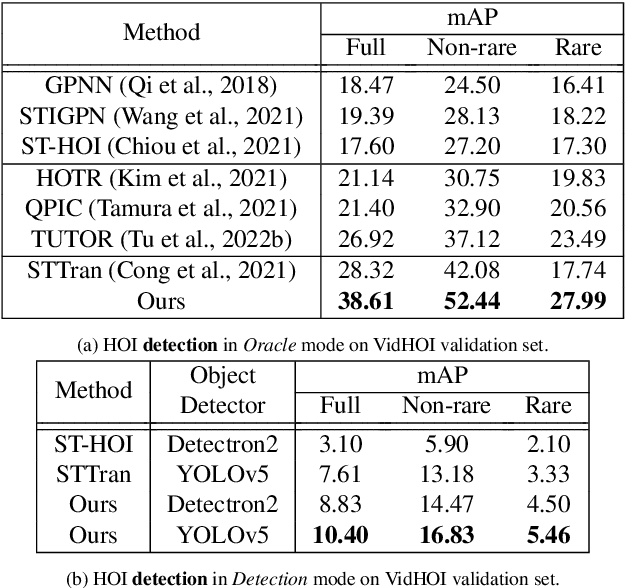
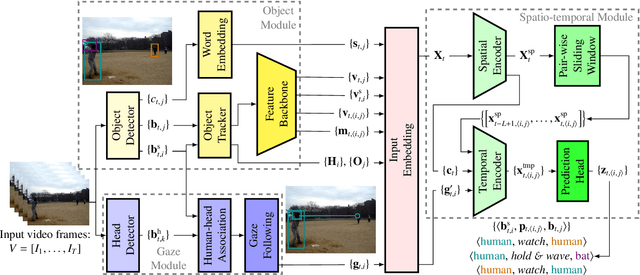
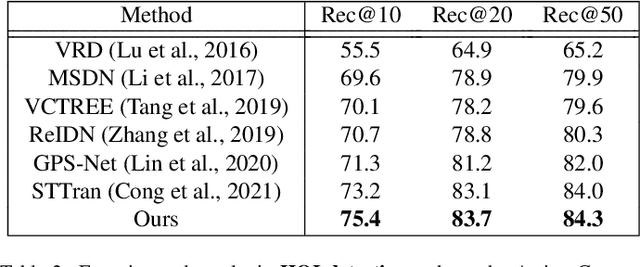
Understanding the human-object interactions (HOIs) from a video is essential to fully comprehend a visual scene. This line of research has been addressed by detecting HOIs from images and lately from videos. However, the video-based HOI anticipation task in the third-person view remains understudied. In this paper, we design a framework to detect current HOIs and anticipate future HOIs in videos. We propose to leverage human gaze information since people often fixate on an object before interacting with it. These gaze features together with the scene contexts and the visual appearances of human-object pairs are fused through a spatio-temporal transformer. To evaluate the model in the HOI anticipation task in a multi-person scenario, we propose a set of person-wise multi-label metrics. Our model is trained and validated on the VidHOI dataset, which contains videos capturing daily life and is currently the largest video HOI dataset. Experimental results in the HOI detection task show that our approach improves the baseline by a great margin of 36.3% relatively. Moreover, we conduct an extensive ablation study to demonstrate the effectiveness of our modifications and extensions to the spatio-temporal transformer. Our code is publicly available on https://github.com/nizhf/hoi-prediction-gaze-transformer.
Can large language models democratize access to dual-use biotechnology?
Jun 06, 2023Large language models (LLMs) such as those embedded in 'chatbots' are accelerating and democratizing research by providing comprehensible information and expertise from many different fields. However, these models may also confer easy access to dual-use technologies capable of inflicting great harm. To evaluate this risk, the 'Safeguarding the Future' course at MIT tasked non-scientist students with investigating whether LLM chatbots could be prompted to assist non-experts in causing a pandemic. In one hour, the chatbots suggested four potential pandemic pathogens, explained how they can be generated from synthetic DNA using reverse genetics, supplied the names of DNA synthesis companies unlikely to screen orders, identified detailed protocols and how to troubleshoot them, and recommended that anyone lacking the skills to perform reverse genetics engage a core facility or contract research organization. Collectively, these results suggest that LLMs will make pandemic-class agents widely accessible as soon as they are credibly identified, even to people with little or no laboratory training. Promising nonproliferation measures include pre-release evaluations of LLMs by third parties, curating training datasets to remove harmful concepts, and verifiably screening all DNA generated by synthesis providers or used by contract research organizations and robotic cloud laboratories to engineer organisms or viruses.
Designing explainable artificial intelligence with active inference: A framework for transparent introspection and decision-making
Jun 06, 2023
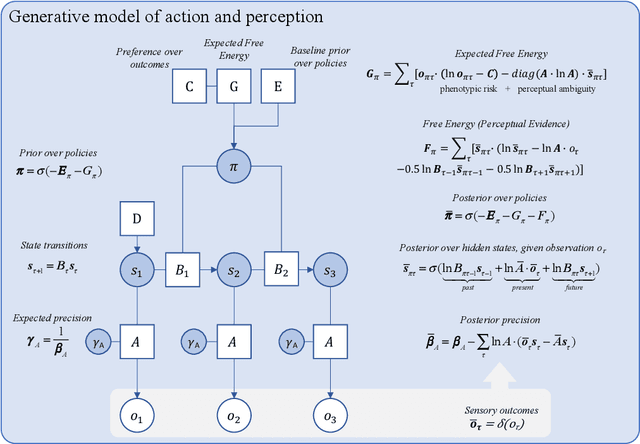
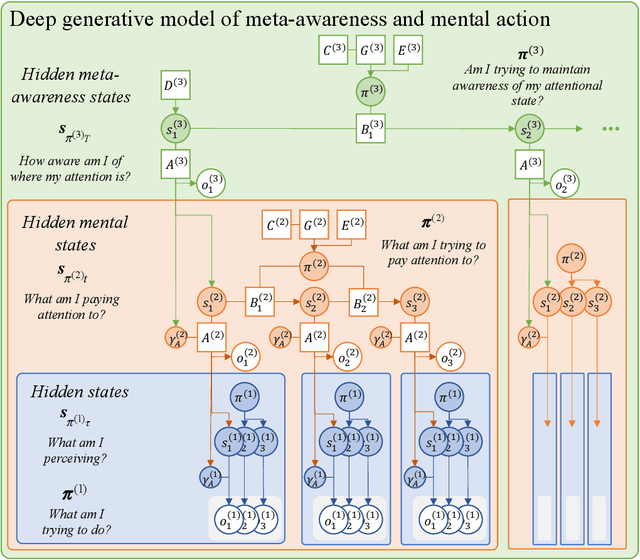
This paper investigates the prospect of developing human-interpretable, explainable artificial intelligence (AI) systems based on active inference and the free energy principle. We first provide a brief overview of active inference, and in particular, of how it applies to the modeling of decision-making, introspection, as well as the generation of overt and covert actions. We then discuss how active inference can be leveraged to design explainable AI systems, namely, by allowing us to model core features of ``introspective'' processes and by generating useful, human-interpretable models of the processes involved in decision-making. We propose an architecture for explainable AI systems using active inference. This architecture foregrounds the role of an explicit hierarchical generative model, the operation of which enables the AI system to track and explain the factors that contribute to its own decisions, and whose structure is designed to be interpretable and auditable by human users. We outline how this architecture can integrate diverse sources of information to make informed decisions in an auditable manner, mimicking or reproducing aspects of human-like consciousness and introspection. Finally, we discuss the implications of our findings for future research in AI, and the potential ethical considerations of developing AI systems with (the appearance of) introspective capabilities.
MCD64A1 Burnt Area Dataset Assessment using Sentinel-2 and Landsat-8 on Google Earth Engine: A Case Study in Rompin, Pahang in Malaysia
Jun 06, 2023
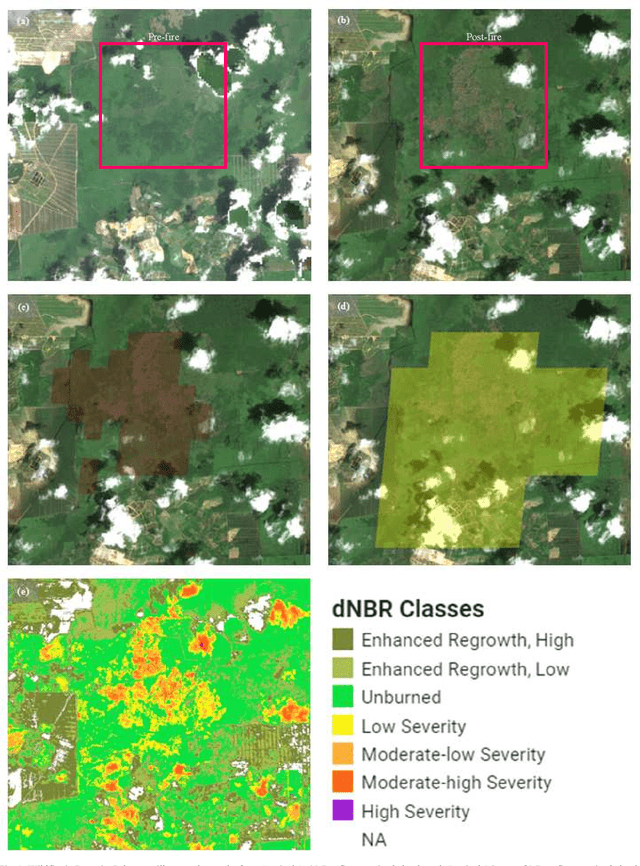
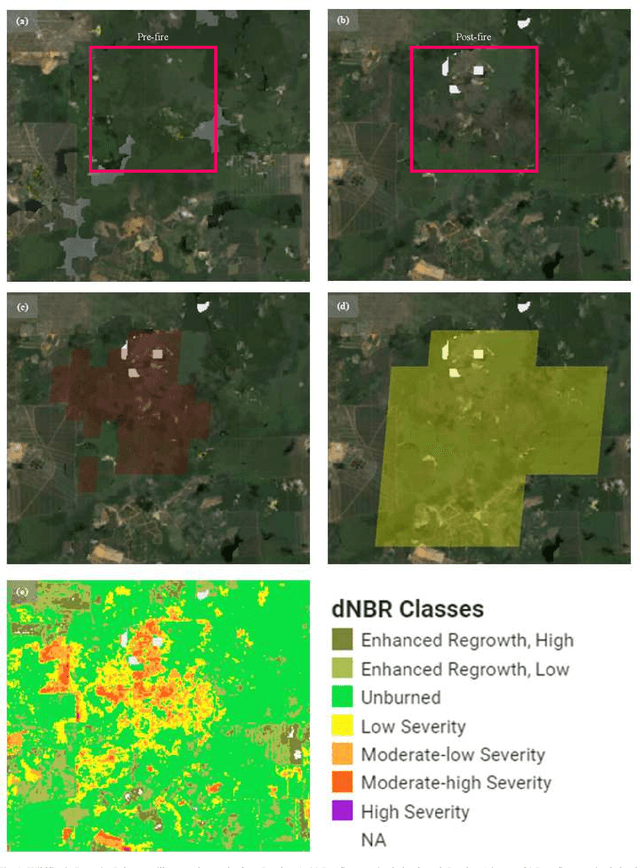
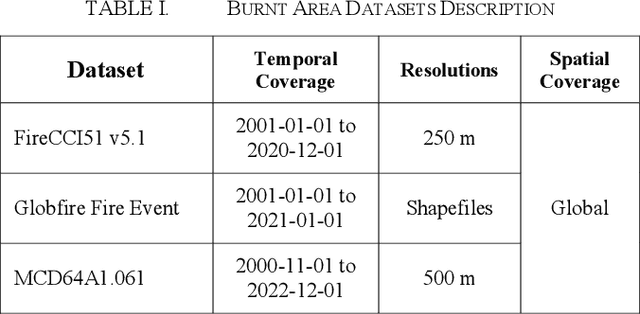
This research paper intends to explore the suitability of adopting the MCD64A1 product to detect burnt areas using Google Earth Engine (GEE) in Peninsular Malaysia. The primary aim of this study is to find out if the MCD64A1 is adequate to identify the small-scale fire in Peninsular Malaysia. To evaluate the MCD64A1, a fire that was instigated in Rompin, a district of Pahang on March 2021 has been chosen as the case study in this work. Although several other burnt area datasets had also been made available in GEE, only MCD64A1 is selected due to its temporal availability. In the absence of validation information associated with the fire from the Malaysian government, public news sources are utilized to retrieve details related to the fire in Rompin. Additionally, the MCD64A1 is also validated with the burnt area observed from the true color imagery produced from the surface reflectance of Sentinel-2 and Landsat-8. From the burnt area assessment, we scrutinize that the MCD64A1 product is practical to be exploited to discover the historical fire in Peninsular Malaysia. However, additional case studies involving other locations in Peninsular Malaysia are advocated to be carried out to substantiate the claims discussed in this work.
Hybrid Graph: A Unified Graph Representation with Datasets and Benchmarks for Complex Graphs
Jun 08, 2023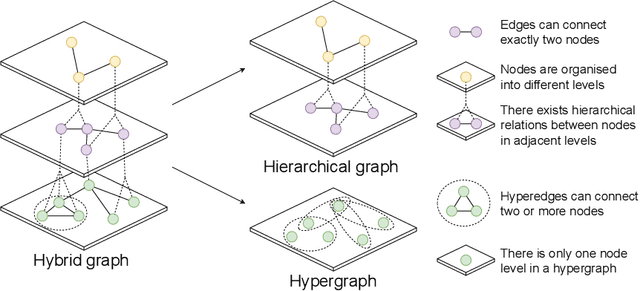
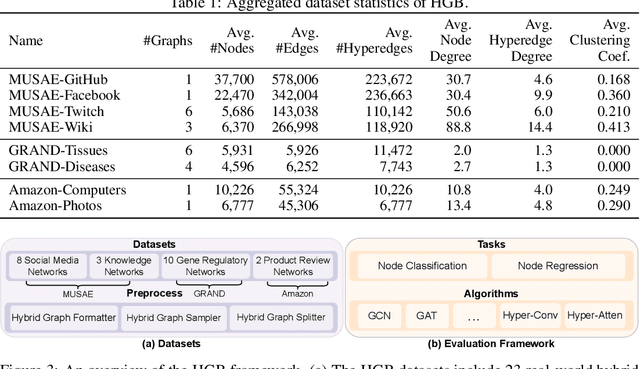
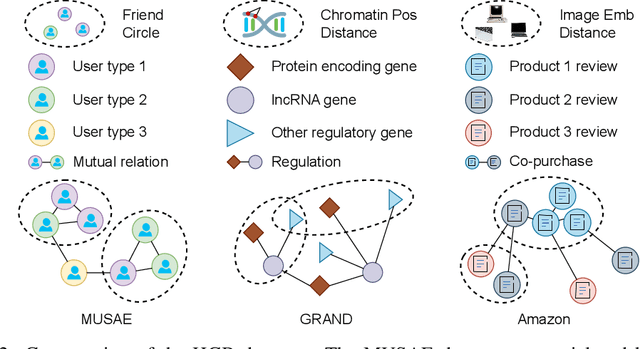
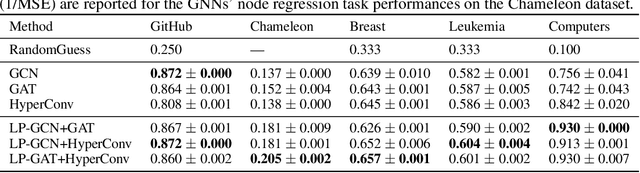
Graphs are widely used to encapsulate a variety of data formats, but real-world networks often involve complex node relations beyond only being pairwise. While hypergraphs and hierarchical graphs have been developed and employed to account for the complex node relations, they cannot fully represent these complexities in practice. Additionally, though many Graph Neural Networks (GNNs) have been proposed for representation learning on higher-order graphs, they are usually only evaluated on simple graph datasets. Therefore, there is a need for a unified modelling of higher-order graphs, and a collection of comprehensive datasets with an accessible evaluation framework to fully understand the performance of these algorithms on complex graphs. In this paper, we introduce the concept of hybrid graphs, a unified definition for higher-order graphs, and present the Hybrid Graph Benchmark (HGB). HGB contains 23 real-world hybrid graph datasets across various domains such as biology, social media, and e-commerce. Furthermore, we provide an extensible evaluation framework and a supporting codebase to facilitate the training and evaluation of GNNs on HGB. Our empirical study of existing GNNs on HGB reveals various research opportunities and gaps, including (1) evaluating the actual performance improvement of hypergraph GNNs over simple graph GNNs; (2) comparing the impact of different sampling strategies on hybrid graph learning methods; and (3) exploring ways to integrate simple graph and hypergraph information. We make our source code and full datasets publicly available at https://zehui127.github.io/hybrid-graph-benchmark/.
A Dynamic Feature Interaction Framework for Multi-task Visual Perception
Jun 08, 2023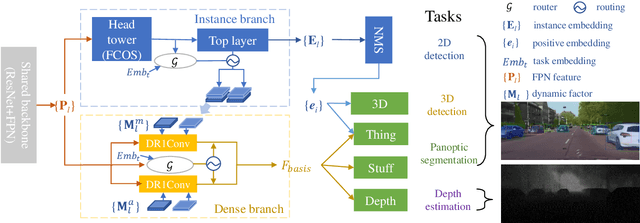
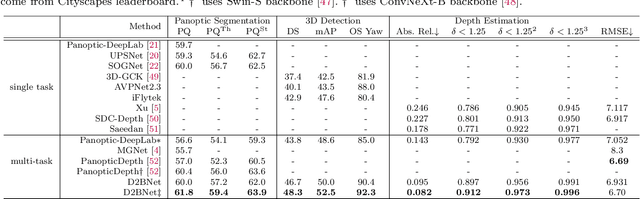
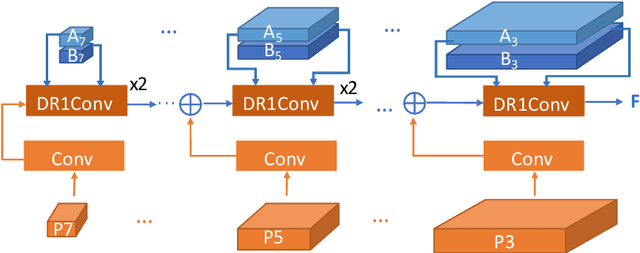
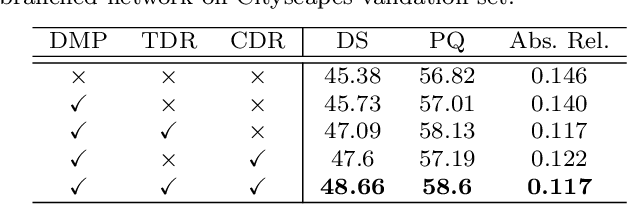
Multi-task visual perception has a wide range of applications in scene understanding such as autonomous driving. In this work, we devise an efficient unified framework to solve multiple common perception tasks, including instance segmentation, semantic segmentation, monocular 3D detection, and depth estimation. Simply sharing the same visual feature representations for these tasks impairs the performance of tasks, while independent task-specific feature extractors lead to parameter redundancy and latency. Thus, we design two feature-merge branches to learn feature basis, which can be useful to, and thus shared by, multiple perception tasks. Then, each task takes the corresponding feature basis as the input of the prediction task head to fulfill a specific task. In particular, one feature merge branch is designed for instance-level recognition the other for dense predictions. To enhance inter-branch communication, the instance branch passes pixel-wise spatial information of each instance to the dense branch using efficient dynamic convolution weighting. Moreover, a simple but effective dynamic routing mechanism is proposed to isolate task-specific features and leverage common properties among tasks. Our proposed framework, termed D2BNet, demonstrates a unique approach to parameter-efficient predictions for multi-task perception. In addition, as tasks benefit from co-training with each other, our solution achieves on par results on partially labeled settings on nuScenes and outperforms previous works for 3D detection and depth estimation on the Cityscapes dataset with full supervision.