 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ReFACT: Updating Text-to-Image Models by Editing the Text Encoder
Jun 01, 2023

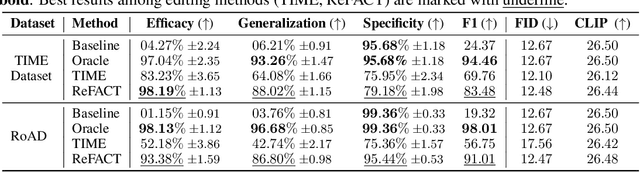
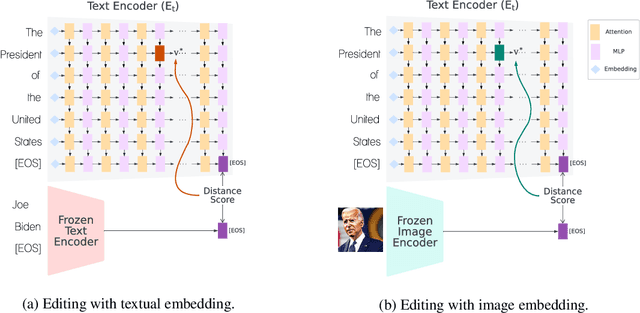
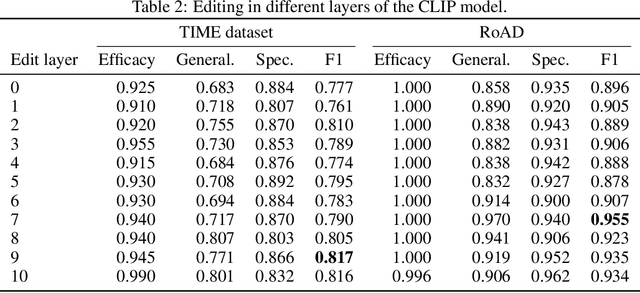
Text-to-image models are trained on extensive amounts of data, leading them to implicitly encode factual knowledge within their parameters. While some facts are useful, others may be incorrect or become outdated (e.g., the current President of the United States). We introduce ReFACT, a novel approach for editing factual knowledge in text-to-image generative models. ReFACT updates the weights of a specific layer in the text encoder, only modifying a tiny portion of the model's parameters, and leaving the rest of the model unaffected. We empirically evaluate ReFACT on an existing benchmark, alongside RoAD, a newly curated dataset. ReFACT achieves superior performance in terms of generalization to related concepts while preserving unrelated concepts. Furthermore, ReFACT maintains image generation quality, making it a valuable tool for updating and correcting factual information in text-to-image models.
Emotion Detection from EEG using Transfer Learning
Jun 09, 2023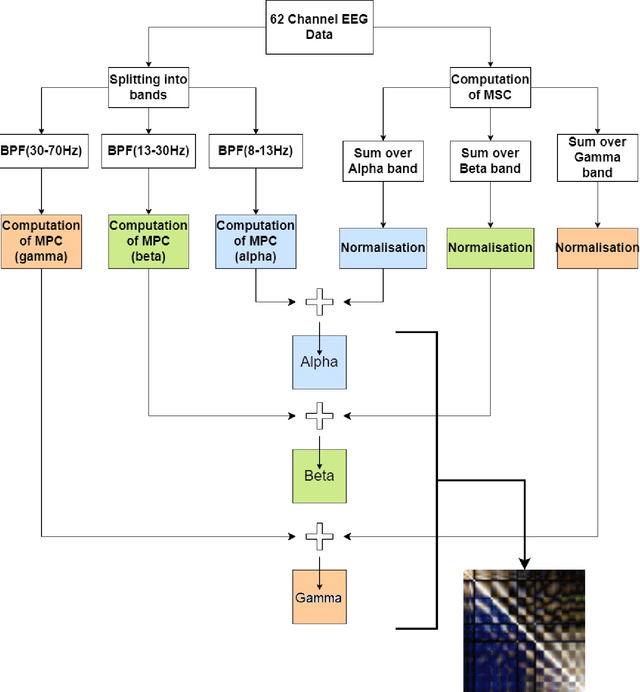
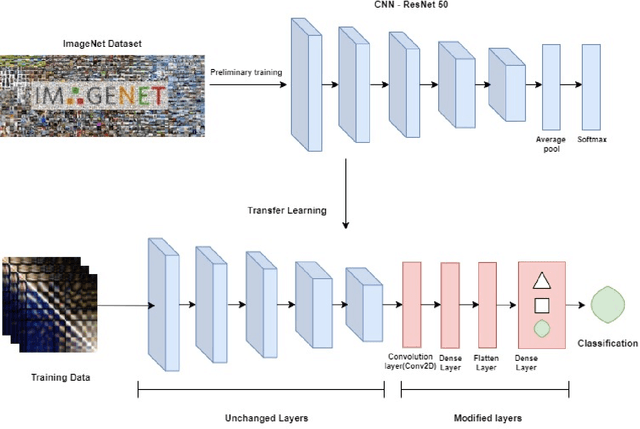
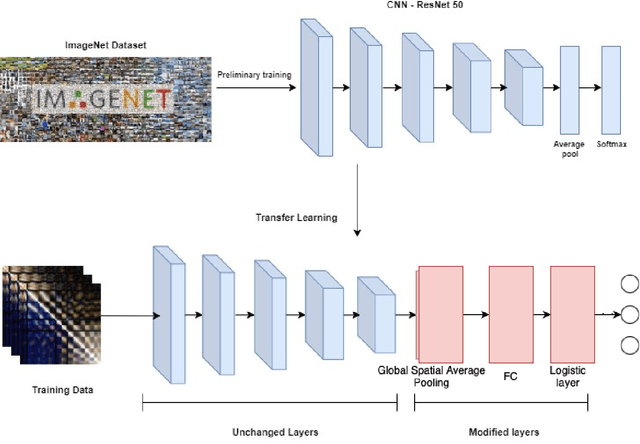
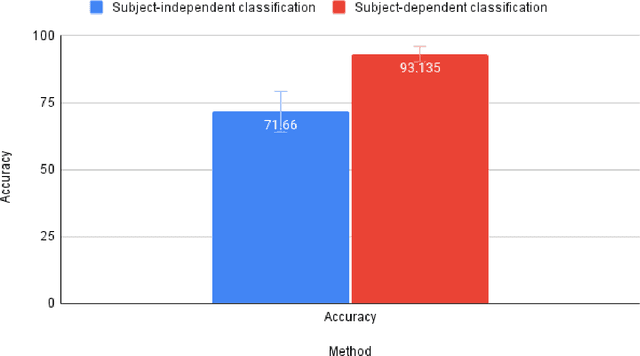
The detection of emotions using an Electroencephalogram (EEG) is a crucial area in brain-computer interfaces and has valuable applications in fields such as rehabilitation and medicine. In this study, we employed transfer learning to overcome the challenge of limited data availability in EEG-based emotion detection. The base model used in this study was Resnet50. Additionally, we employed a novel feature combination in EEG-based emotion detection. The input to the model was in the form of an image matrix, which comprised Mean Phase Coherence (MPC) and Magnitude Squared Coherence (MSC) in the upper-triangular and lower-triangular matrices, respectively. We further improved the technique by incorporating features obtained from the Differential Entropy (DE) into the diagonal, which previously held little to no useful information for classifying emotions. The dataset used in this study, SEED EEG (62 channel EEG), comprises three classes (Positive, Neutral, and Negative). We calculated both subject-independent and subject-dependent accuracy. The subject-dependent accuracy was obtained using a 10-fold cross-validation method and was 93.1%, while the subject-independent classification was performed by employing the leave-one-subject-out (LOSO) strategy. The accuracy obtained in subject-independent classification was 71.6%. Both of these accuracies are at least twice better than the chance accuracy of classifying 3 classes. The study found the use of MSC and MPC in EEG-based emotion detection promising for emotion classification. The future scope of this work includes the use of data augmentation techniques, enhanced classifiers, and better features for emotion classification.
An F-ratio-Based Method for Estimating the Number of Active Sources in MEG
Jun 09, 2023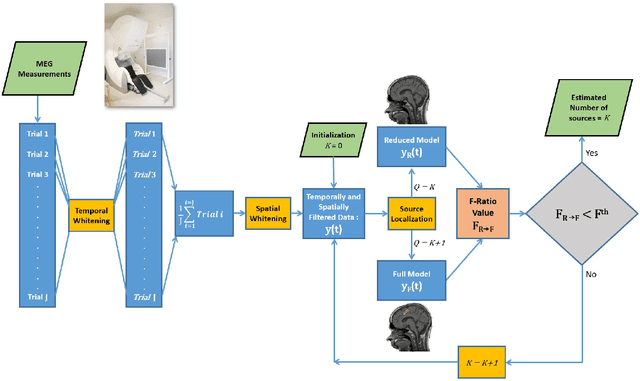
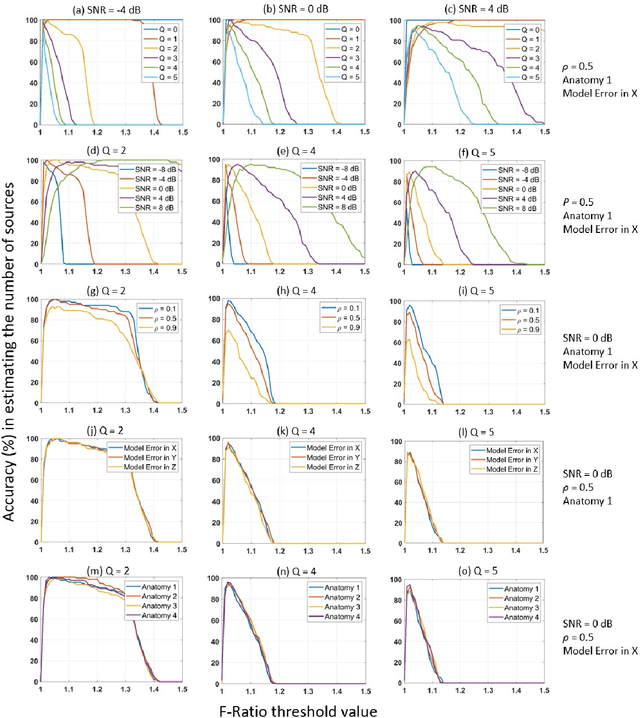
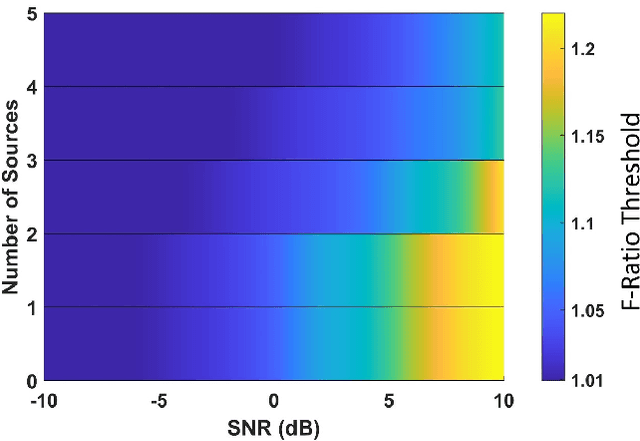
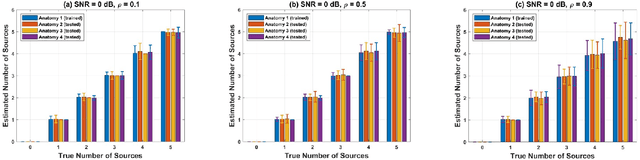
Magnetoencephalography (MEG) is a powerful technique for studying the human brain function. However, accurately estimating the number of sources that contribute to the MEG recordings remains a challenging problem due to the low signal-to-noise ratio (SNR), the presence of correlated sources, inaccuracies in head modeling, and variations in individual anatomy. To address these issues, our study introduces a robust method for accurately estimating the number of active sources in the brain based on the F-ratio statistical approach, which allows for a comparison between a full model with a higher number of sources and a reduced model with fewer sources. Using this approach, we developed a formal statistical procedure that sequentially increases the number of sources in the multiple dipole localization problem until all sources are found. Our results revealed that the selection of thresholds plays a critical role in determining the method`s overall performance, and appropriate thresholds needed to be adjusted for the number of sources and SNR levels, while they remained largely invariant to different inter-source correlations, modeling inaccuracies, and different cortical anatomies. By identifying optimal thresholds and validating our F-ratio-based method in simulated, real phantom, and human MEG data, we demonstrated the superiority of our F-ratio-based method over existing state-of-the-art statistical approaches, such as the Akaike Information Criterion (AIC) and Minimum Description Length (MDL). Overall, when tuned for optimal selection of thresholds, our method offers researchers a precise tool to estimate the true number of active brain sources and accurately model brain function.
A Macro-Micro Approach to Reconstructing Vehicle Trajectories on Multi-Lane Freeways with Lane Changing
Jun 09, 2023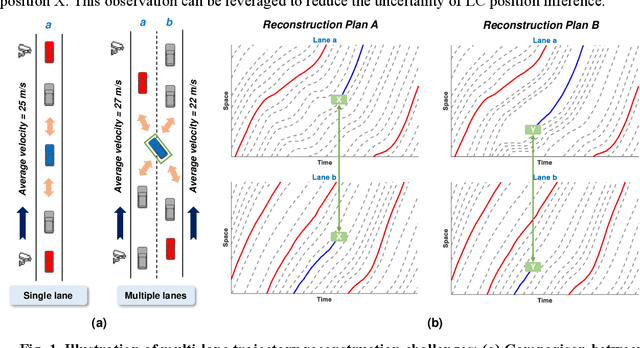

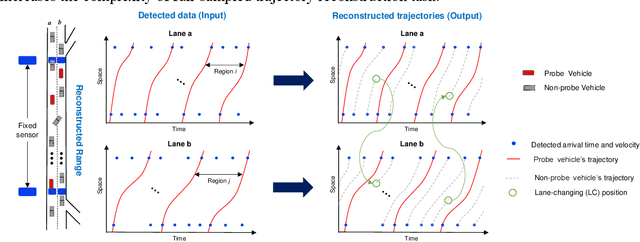
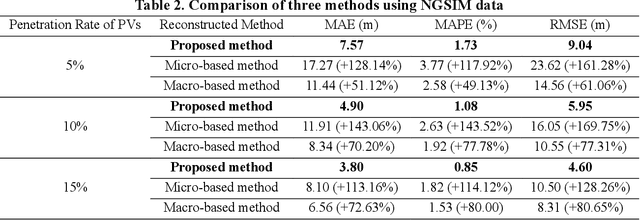
Vehicle trajectories can offer the most precise and detailed depiction of traffic flow and serve as a critical component in traffic management and control applications. Various technologies have been applied to reconstruct vehicle trajectories from sparse fixed and mobile detection data. However, existing methods predominantly concentrate on single-lane scenarios and neglect lane-changing (LC) behaviors that occur across multiple lanes, which limit their applicability in practical traffic systems. To address this research gap, we propose a macro-micro approach for reconstructing complete vehicle trajectories on multi-lane freeways, wherein the macro traffic state information and micro driving models are integrated to overcome the restrictions imposed by lane boundary. Particularly, the macroscopic velocity contour maps are established for each lane to regulate the movement of vehicle platoons, meanwhile the velocity difference between adjacent lanes provide valuable criteria for guiding LC behaviors. Simultaneously, the car-following models are extended from micro perspective to supply lane-based candidate trajectories and define the plausible range for LC positions. Later, a two-stage trajectory fusion algorithm is proposed to jointly infer both the car-following and LC behaviors, in which the optimal LC positions is identified and candidate trajectories are adjusted according to their weights. The proposed framework was evaluated using NGSIM dataset, and the results indicated a remarkable enhancement in both the accuracy and smoothness of reconstructed trajectories, with performance indicators reduced by over 30% compared to two representative reconstruction methods. Furthermore, the reconstruction process effectively reproduced LC behaviors across contiguous lanes, adding to the framework's comprehensiveness and realism.
Improving Toponym Resolution with Better Candidate Generation, Transformer-based Reranking, and Two-Stage Resolution
May 18, 2023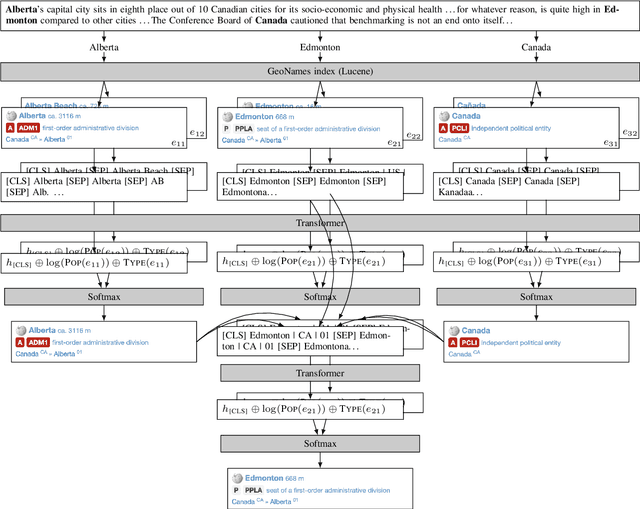
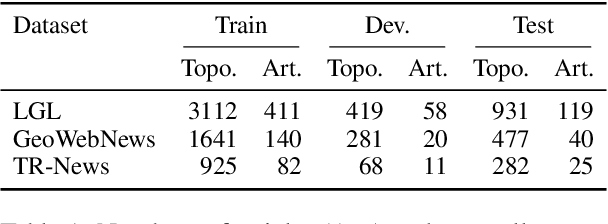
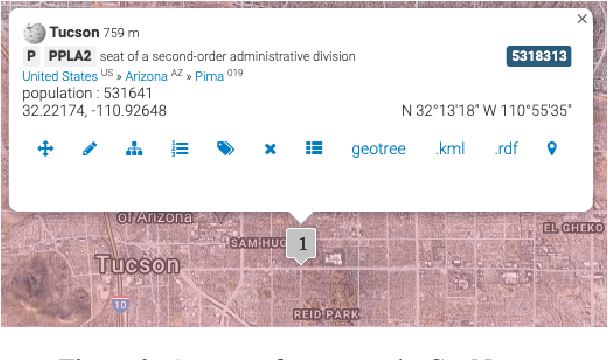
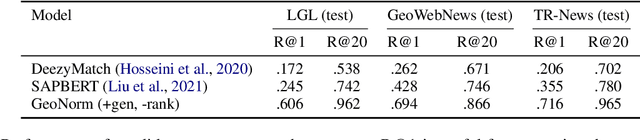
Geocoding is the task of converting location mentions in text into structured data that encodes the geospatial semantics. We propose a new architecture for geocoding, GeoNorm. GeoNorm first uses information retrieval techniques to generate a list of candidate entries from the geospatial ontology. Then it reranks the candidate entries using a transformer-based neural network that incorporates information from the ontology such as the entry's population. This generate-and-rerank process is applied twice: first to resolve the less ambiguous countries, states, and counties, and second to resolve the remaining location mentions, using the identified countries, states, and counties as context. Our proposed toponym resolution framework achieves state-of-the-art performance on multiple datasets. Code and models are available at \url{https://github.com/clulab/geonorm}.
OpenPI2.0: An Improved Dataset for Entity Tracking in Texts
May 24, 2023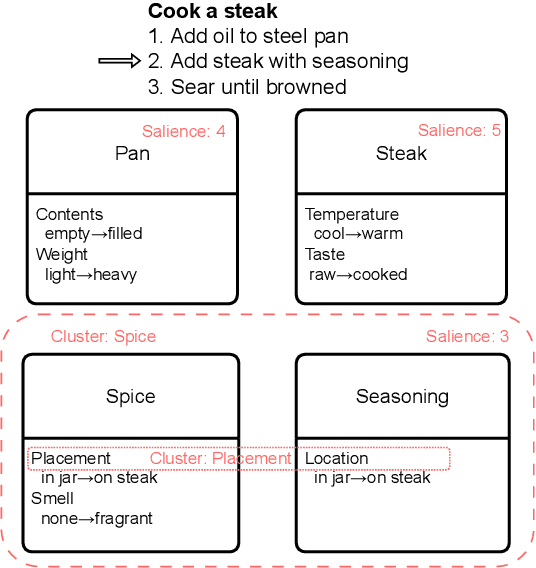

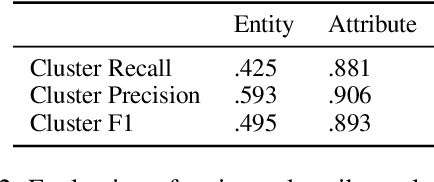
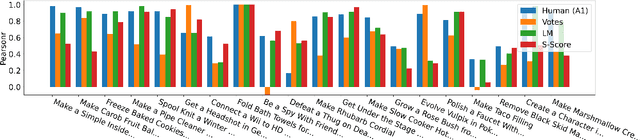
Representing texts as information about entities has long been deemed effective in event reasoning. We propose OpenPI2.0, an improved dataset for tracking entity states in procedural texts. OpenPI2.0 features not only canonicalized entities that facilitate evaluation, but also salience annotations including both manual labels and automatic predictions. Regarding entity salience, we provide a survey on annotation subjectivity, modeling feasibility, and downstream applications in tasks such as question answering and classical planning.
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023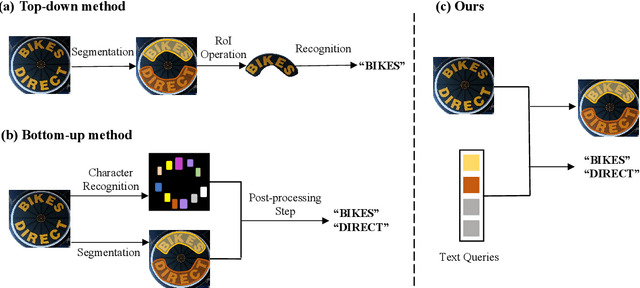
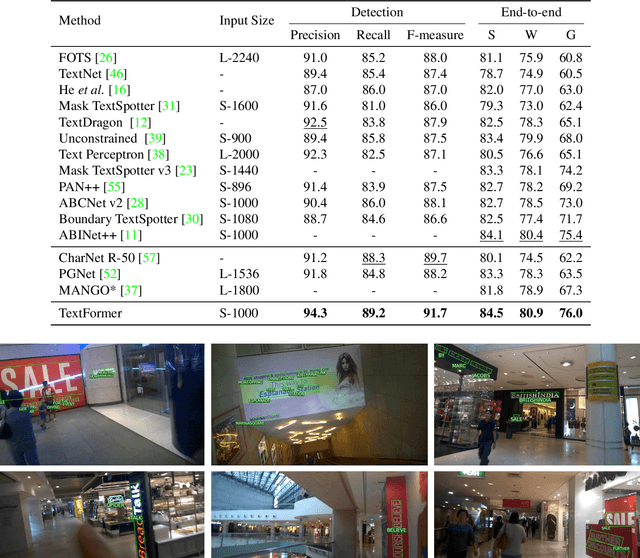

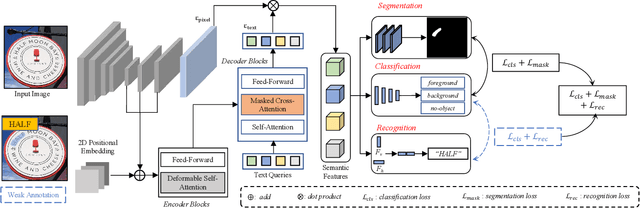
End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
How does over-squashing affect the power of GNNs?
Jun 06, 2023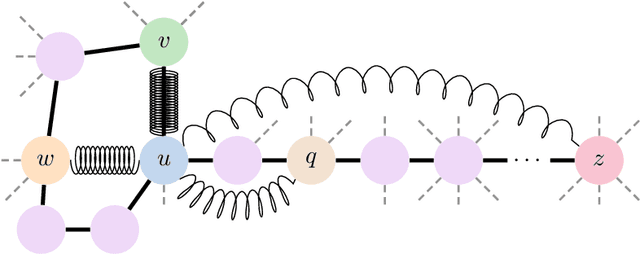

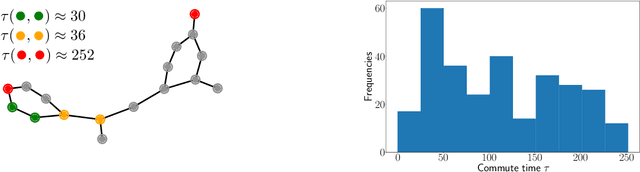
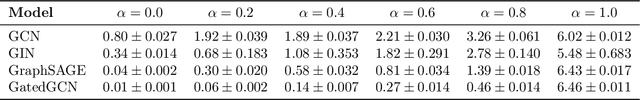
Graph Neural Networks (GNNs) are the state-of-the-art model for machine learning on graph-structured data. The most popular class of GNNs operate by exchanging information between adjacent nodes, and are known as Message Passing Neural Networks (MPNNs). Given their widespread use, understanding the expressive power of MPNNs is a key question. However, existing results typically consider settings with uninformative node features. In this paper, we provide a rigorous analysis to determine which function classes of node features can be learned by an MPNN of a given capacity. We do so by measuring the level of pairwise interactions between nodes that MPNNs allow for. This measure provides a novel quantitative characterization of the so-called over-squashing effect, which is observed to occur when a large volume of messages is aggregated into fixed-size vectors. Using our measure, we prove that, to guarantee sufficient communication between pairs of nodes, the capacity of the MPNN must be large enough, depending on properties of the input graph structure, such as commute times. For many relevant scenarios, our analysis results in impossibility statements in practice, showing that over-squashing hinders the expressive power of MPNNs. We validate our theoretical findings through extensive controlled experiments and ablation studies.
Schema First! Learn Versatile Knowledge Graph Embeddings by Capturing Semantics with MASCHInE
Jun 06, 2023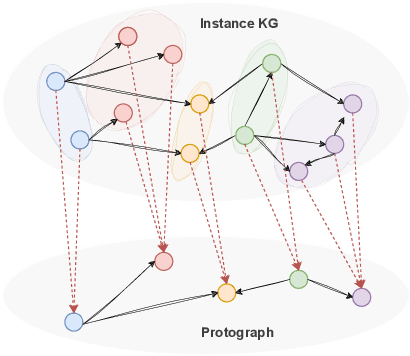
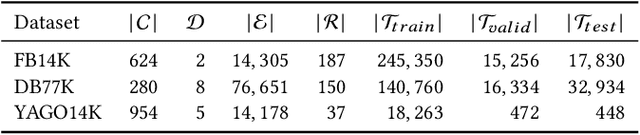
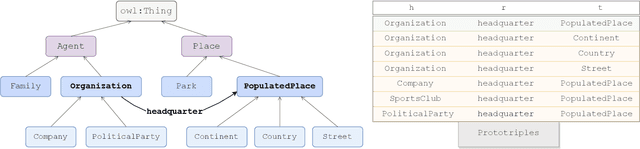
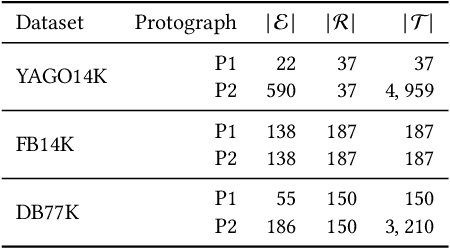
Knowledge graph embedding models (KGEMs) have gained considerable traction in recent years. These models learn a vector representation of knowledge graph entities and relations, a.k.a. knowledge graph embeddings (KGEs). Learning versatile KGEs is desirable as it makes them useful for a broad range of tasks. However, KGEMs are usually trained for a specific task, which makes their embeddings task-dependent. In parallel, the widespread assumption that KGEMs actually create a semantic representation of the underlying entities and relations (e.g., project similar entities closer than dissimilar ones) has been challenged. In this work, we design heuristics for generating protographs -- small, modified versions of a KG that leverage schema-based information. The learnt protograph-based embeddings are meant to encapsulate the semantics of a KG, and can be leveraged in learning KGEs that, in turn, also better capture semantics. Extensive experiments on various evaluation benchmarks demonstrate the soundness of this approach, which we call Modular and Agnostic SCHema-based Integration of protograph Embeddings (MASCHInE). In particular, MASCHInE helps produce more versatile KGEs that yield substantially better performance for entity clustering and node classification tasks. For link prediction, using MASCHInE has little impact on rank-based performance but increases the number of semantically valid predictions.
Human-Object Interaction Prediction in Videos through Gaze Following
Jun 06, 2023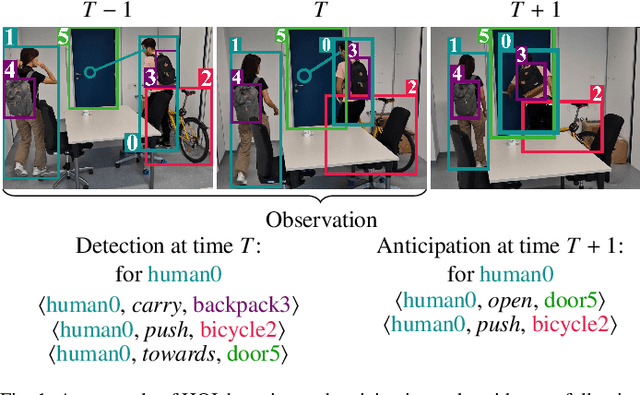
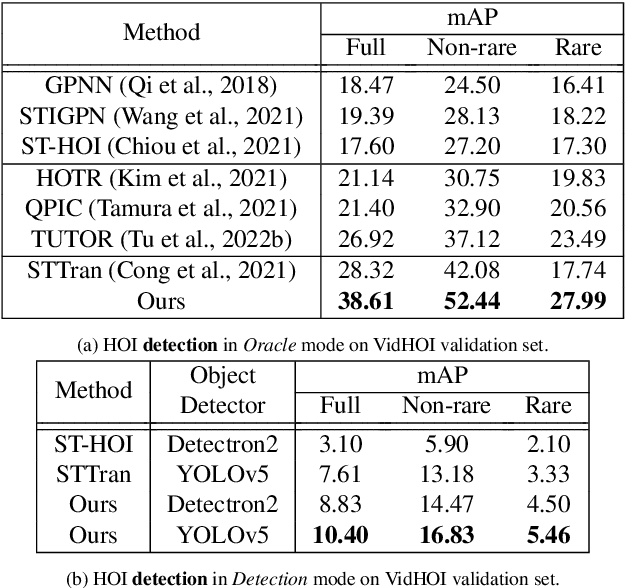
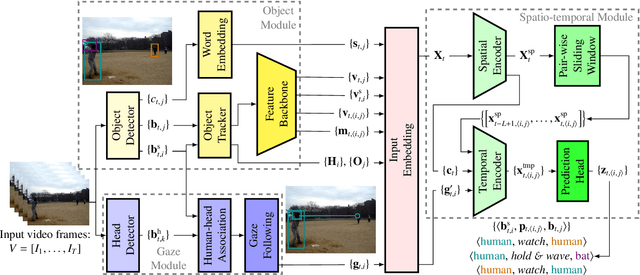
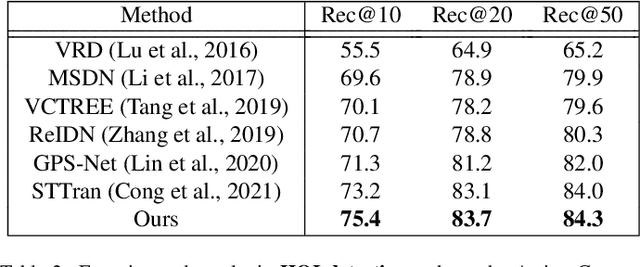
Understanding the human-object interactions (HOIs) from a video is essential to fully comprehend a visual scene. This line of research has been addressed by detecting HOIs from images and lately from videos. However, the video-based HOI anticipation task in the third-person view remains understudied. In this paper, we design a framework to detect current HOIs and anticipate future HOIs in videos. We propose to leverage human gaze information since people often fixate on an object before interacting with it. These gaze features together with the scene contexts and the visual appearances of human-object pairs are fused through a spatio-temporal transformer. To evaluate the model in the HOI anticipation task in a multi-person scenario, we propose a set of person-wise multi-label metrics. Our model is trained and validated on the VidHOI dataset, which contains videos capturing daily life and is currently the largest video HOI dataset. Experimental results in the HOI detection task show that our approach improves the baseline by a great margin of 36.3% relatively. Moreover, we conduct an extensive ablation study to demonstrate the effectiveness of our modifications and extensions to the spatio-temporal transformer. Our code is publicly available on https://github.com/nizhf/hoi-prediction-gaze-transformer.