 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Vision Transformer for Human Pose Estimation via Patch Selection
Jun 07, 2023
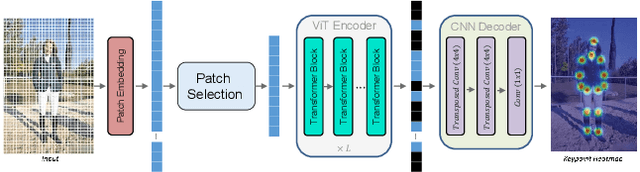
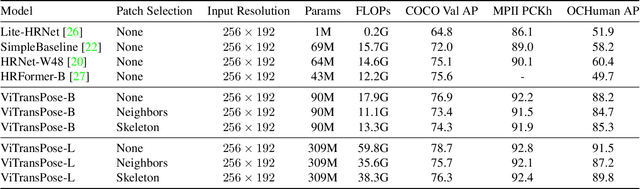
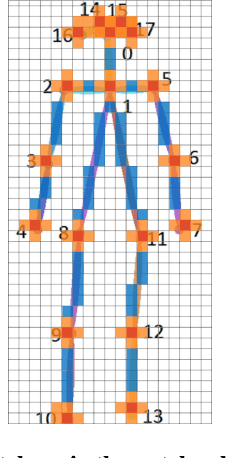
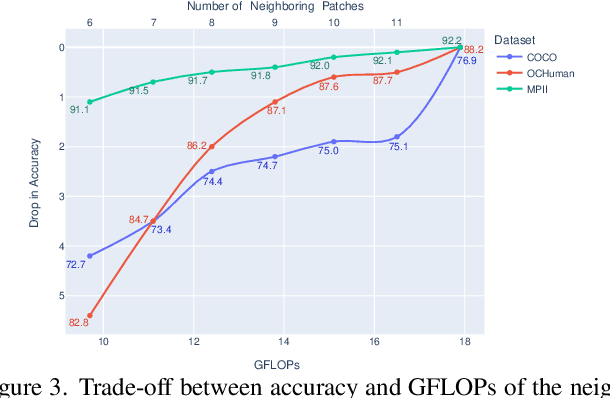
While Convolutional Neural Networks (CNNs) have been widely successful in 2D human pose estimation, Vision Transformers (ViTs) have emerged as a promising alternative to CNNs, boosting state-of-the-art performance. However, the quadratic computational complexity of ViTs has limited their applicability for processing high-resolution images and long videos. To address this challenge, we propose a simple method for reducing ViT's computational complexity based on selecting and processing a small number of most informative patches while disregarding others. We leverage a lightweight pose estimation network to guide the patch selection process, ensuring that the selected patches contain the most important information. Our experimental results on three widely used 2D pose estimation benchmarks, namely COCO, MPII and OCHuman, demonstrate the effectiveness of our proposed methods in significantly improving speed and reducing computational complexity with a slight drop in performance.
Meta-SAGE: Scale Meta-Learning Scheduled Adaptation with Guided Exploration for Mitigating Scale Shift on Combinatorial Optimization
Jun 07, 2023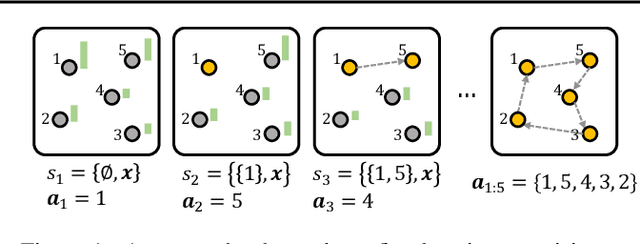
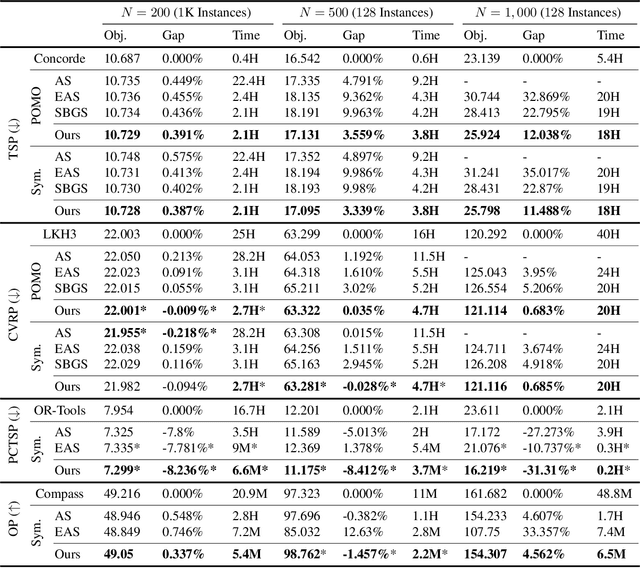
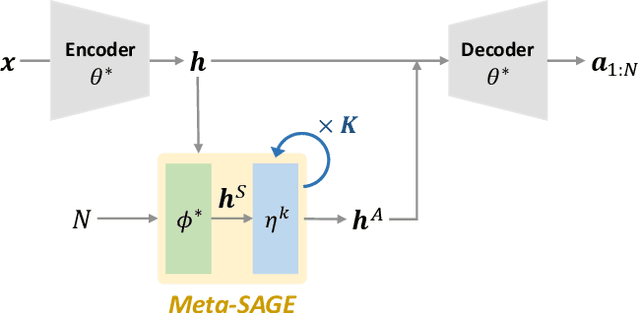
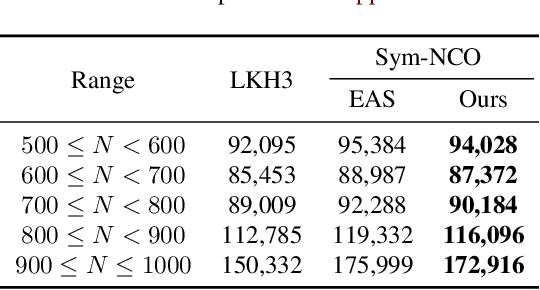
This paper proposes Meta-SAGE, a novel approach for improving the scalability of deep reinforcement learning models for combinatorial optimization (CO) tasks. Our method adapts pre-trained models to larger-scale problems in test time by suggesting two components: a scale meta-learner (SML) and scheduled adaptation with guided exploration (SAGE). First, SML transforms the context embedding for subsequent adaptation of SAGE based on scale information. Then, SAGE adjusts the model parameters dedicated to the context embedding for a specific instance. SAGE introduces locality bias, which encourages selecting nearby locations to determine the next location. The locality bias gradually decays as the model is adapted to the target instance. Results show that Meta-SAGE outperforms previous adaptation methods and significantly improves scalability in representative CO tasks. Our source code is available at https://github.com/kaist-silab/meta-sage
Improving Expressivity of GNNs with Subgraph-specific Factor Embedded Normalization
Jun 11, 2023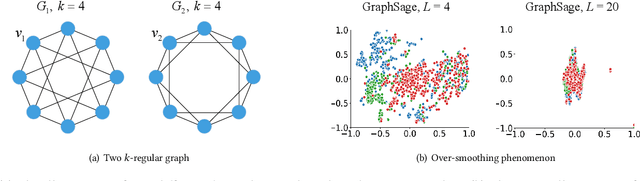
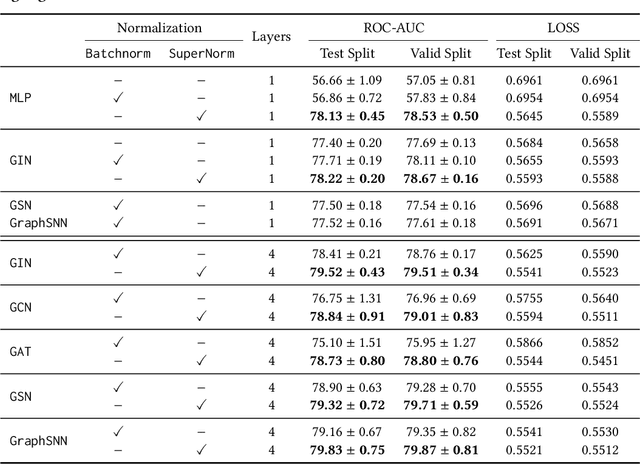
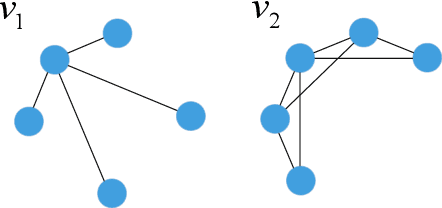
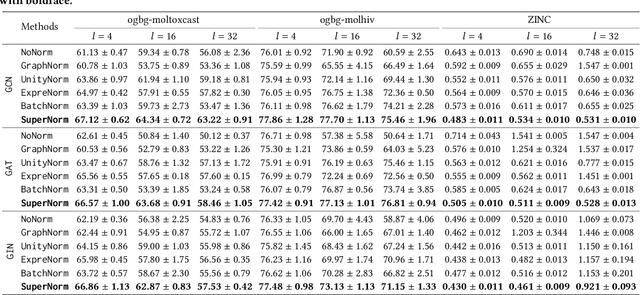
Graph Neural Networks (GNNs) have emerged as a powerful category of learning architecture for handling graph-structured data. However, existing GNNs typically ignore crucial structural characteristics in node-induced subgraphs, which thus limits their expressiveness for various downstream tasks. In this paper, we strive to strengthen the representative capabilities of GNNs by devising a dedicated plug-and-play normalization scheme, termed as SUbgraph-sPEcific FactoR Embedded Normalization (SuperNorm), that explicitly considers the intra-connection information within each node-induced subgraph. To this end, we embed the subgraph-specific factor at the beginning and the end of the standard BatchNorm, as well as incorporate graph instance-specific statistics for improved distinguishable capabilities. In the meantime, we provide theoretical analysis to support that, with the elaborated SuperNorm, an arbitrary GNN is at least as powerful as the 1-WL test in distinguishing non-isomorphism graphs. Furthermore, the proposed SuperNorm scheme is also demonstrated to alleviate the over-smoothing phenomenon. Experimental results related to predictions of graph, node, and link properties on the eight popular datasets demonstrate the effectiveness of the proposed method. The code is available at https://github.com/chenchkx/SuperNorm.
UAV Trajectory and Multi-User Beamforming Optimization for Clustered Users Against Passive Eavesdropping Attacks With Unknown CSI
Jun 11, 2023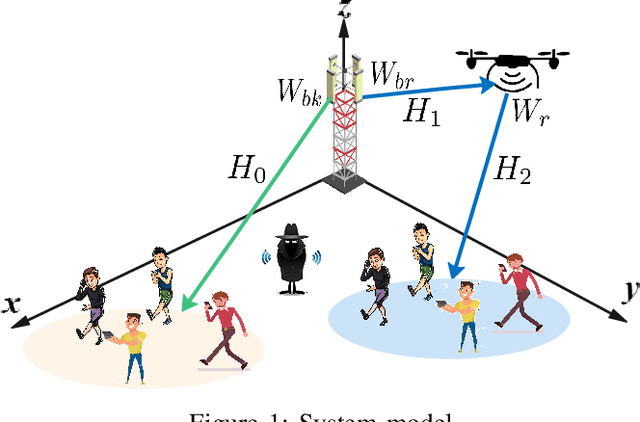
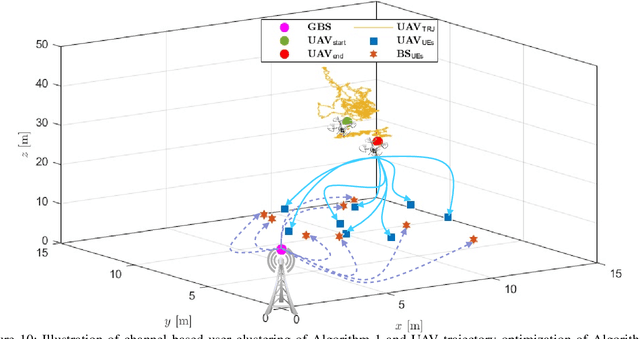
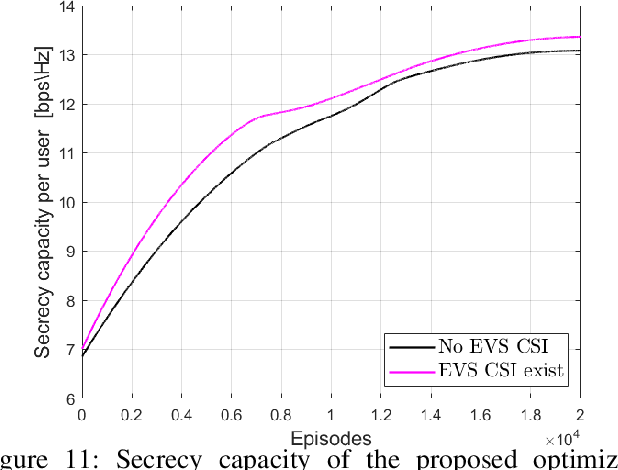
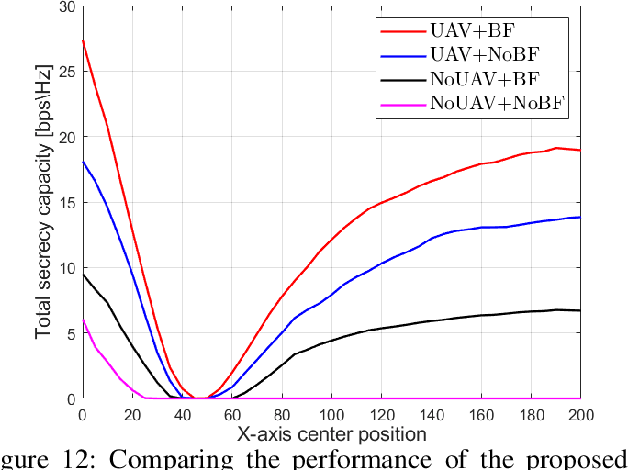
This paper tackles the fundamental passive eavesdropping problem in modern wireless communications in which the location and the channel state information (CSI) of the attackers are unknown. In this regard, we propose deploying an unmanned aerial vehicle (UAV) that serves as a mobile aerial relay (AR) to help ground base station (GBS) support a subset of vulnerable users. More precisely, our solution (1) clusters the single-antenna users in two groups to be either served by the GBS directly or via the AR, (2) employs optimal multi-user beamforming to the directly served users, and (3) optimizes the AR's 3D position, its multi-user beamforming matrix and transmit powers by combining closed-form solutions with machine learning techniques. Specifically, we design a plain beamforming and power optimization combined with a deep reinforcement learning (DRL) algorithm for an AR to optimize its trajectory for the security maximization of the served users. Numerical results show that the multi-user multiple input, single output (MU-MISO) system split between a GBS and an AR with optimized transmission parameters without knowledge of the eavesdropping channels achieves high secrecy capacities that scale well with increasing the number of users.
Weakly Supervised Visual Question Answer Generation
Jun 11, 2023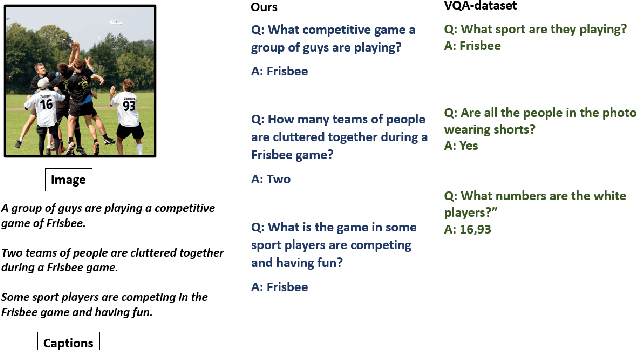
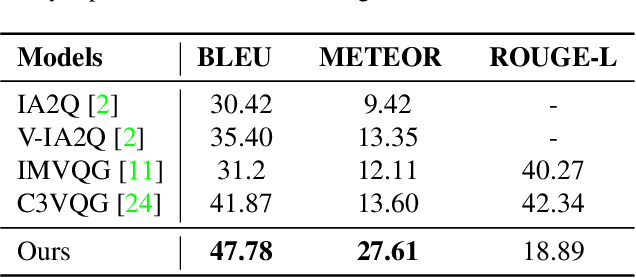
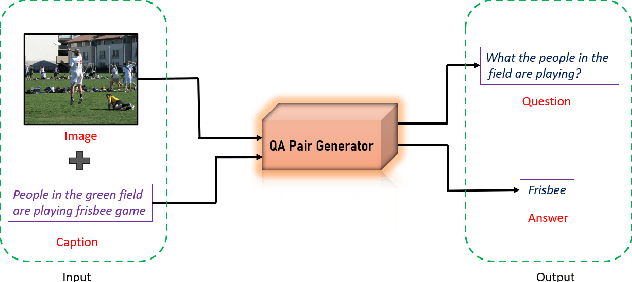

Growing interest in conversational agents promote twoway human-computer communications involving asking and answering visual questions have become an active area of research in AI. Thus, generation of visual questionanswer pair(s) becomes an important and challenging task. To address this issue, we propose a weakly-supervised visual question answer generation method that generates a relevant question-answer pairs for a given input image and associated caption. Most of the prior works are supervised and depend on the annotated question-answer datasets. In our work, we present a weakly supervised method that synthetically generates question-answer pairs procedurally from visual information and captions. The proposed method initially extracts list of answer words, then does nearest question generation that uses the caption and answer word to generate synthetic question. Next, the relevant question generator converts the nearest question to relevant language question by dependency parsing and in-order tree traversal, finally, fine-tune a ViLBERT model with the question-answer pair(s) generated at end. We perform an exhaustive experimental analysis on VQA dataset and see that our model significantly outperform SOTA methods on BLEU scores. We also show the results wrt baseline models and ablation study.
Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment
Jun 15, 2023
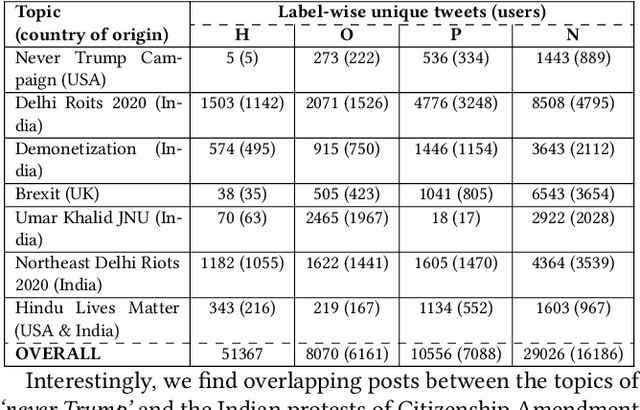
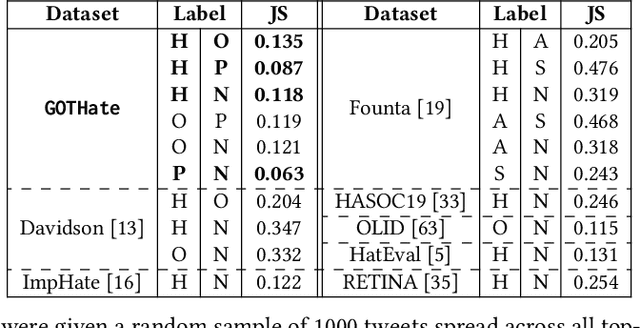
Social media is awash with hateful content, much of which is often veiled with linguistic and topical diversity. The benchmark datasets used for hate speech detection do not account for such divagation as they are predominantly compiled using hate lexicons. However, capturing hate signals becomes challenging in neutrally-seeded malicious content. Thus, designing models and datasets that mimic the real-world variability of hate warrants further investigation. To this end, we present GOTHate, a large-scale code-mixed crowdsourced dataset of around 51k posts for hate speech detection from Twitter. GOTHate is neutrally seeded, encompassing different languages and topics. We conduct detailed comparisons of GOTHate with the existing hate speech datasets, highlighting its novelty. We benchmark it with 10 recent baselines. Our extensive empirical and benchmarking experiments suggest that GOTHate is hard to classify in a text-only setup. Thus, we investigate how adding endogenous signals enhances the hate speech detection task. We augment GOTHate with the user's timeline information and ego network, bringing the overall data source closer to the real-world setup for understanding hateful content. Our proposed solution HEN-mBERT is a modular, multilingual, mixture-of-experts model that enriches the linguistic subspace with latent endogenous signals from history, topology, and exemplars. HEN-mBERT transcends the best baseline by 2.5% and 5% in overall macro-F1 and hate class F1, respectively. Inspired by our experiments, in partnership with Wipro AI, we are developing a semi-automated pipeline to detect hateful content as a part of their mission to tackle online harm.
Real-Time Network-Level Traffic Signal Control: An Explicit Multiagent Coordination Method
Jun 15, 2023
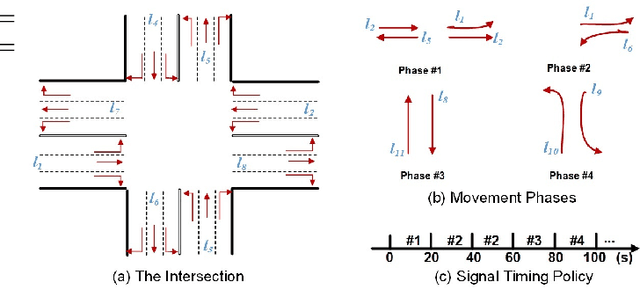

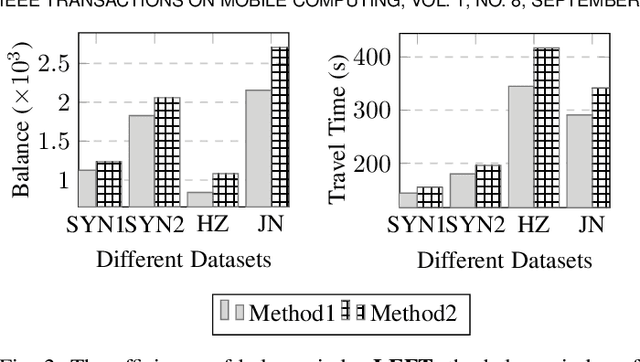
Efficient traffic signal control (TSC) has been one of the most useful ways for reducing urban road congestion. Key to the challenge of TSC includes 1) the essential of real-time signal decision, 2) the complexity in traffic dynamics, and 3) the network-level coordination. Recent efforts that applied reinforcement learning (RL) methods can query policies by mapping the traffic state to the signal decision in real-time, however, is inadequate for unexpected traffic flows. By observing real traffic information, online planning methods can compute the signal decisions in a responsive manner. We propose an explicit multiagent coordination (EMC)-based online planning methods that can satisfy adaptive, real-time and network-level TSC. By multiagent, we model each intersection as an autonomous agent, and the coordination efficiency is modeled by a cost (i.e., congestion index) function between neighbor intersections. By network-level coordination, each agent exchanges messages with respect to cost function with its neighbors in a fully decentralized manner. By real-time, the message passing procedure can interrupt at any time when the real time limit is reached and agents select the optimal signal decisions according to the current message. Moreover, we prove our EMC method can guarantee network stability by borrowing ideas from transportation domain. Finally, we test our EMC method in both synthetic and real road network datasets. Experimental results are encouraging: compared to RL and conventional transportation baselines, our EMC method performs reasonably well in terms of adapting to real-time traffic dynamics, minimizing vehicle travel time and scalability to city-scale road networks.
A Group Symmetric Stochastic Differential Equation Model for Molecule Multi-modal Pretraining
May 28, 2023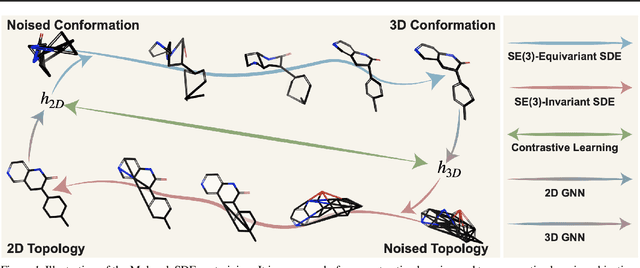

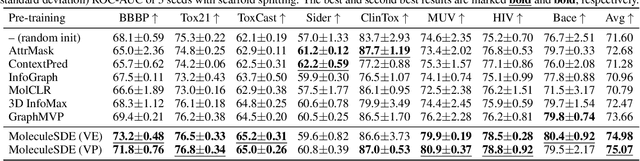
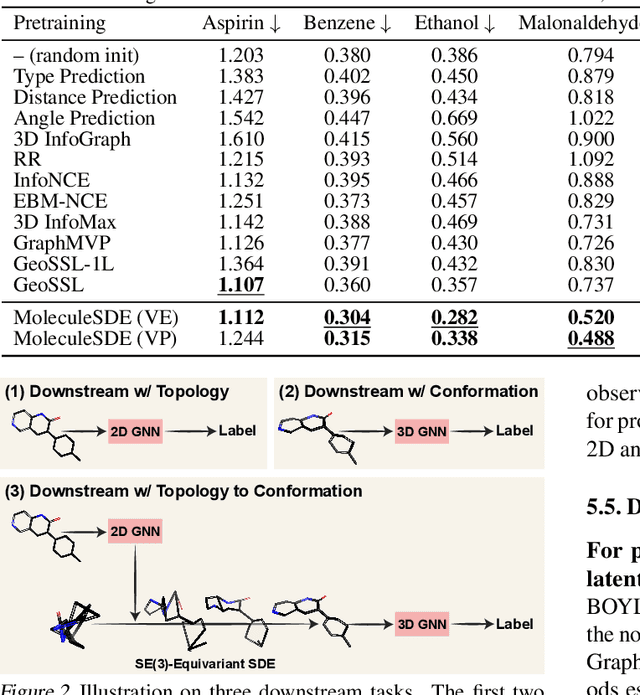
Molecule pretraining has quickly become the go-to schema to boost the performance of AI-based drug discovery. Naturally, molecules can be represented as 2D topological graphs or 3D geometric point clouds. Although most existing pertaining methods focus on merely the single modality, recent research has shown that maximizing the mutual information (MI) between such two modalities enhances the molecule representation ability. Meanwhile, existing molecule multi-modal pretraining approaches approximate MI based on the representation space encoded from the topology and geometry, thus resulting in the loss of critical structural information of molecules. To address this issue, we propose MoleculeSDE. MoleculeSDE leverages group symmetric (e.g., SE(3)-equivariant and reflection-antisymmetric) stochastic differential equation models to generate the 3D geometries from 2D topologies, and vice versa, directly in the input space. It not only obtains tighter MI bound but also enables prosperous downstream tasks than the previous work. By comparing with 17 pretraining baselines, we empirically verify that MoleculeSDE can learn an expressive representation with state-of-the-art performance on 26 out of 32 downstream tasks.
Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
Jun 12, 2023
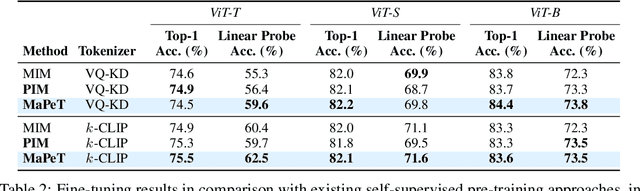
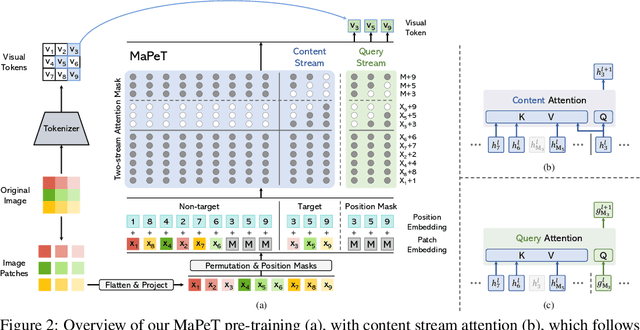
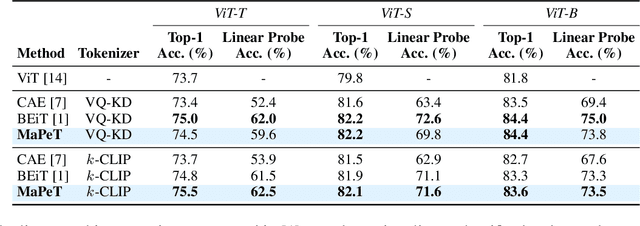
The use of self-supervised pre-training has emerged as a promising approach to enhance the performance of visual tasks such as image classification. In this context, recent approaches have employed the Masked Image Modeling paradigm, which pre-trains a backbone by reconstructing visual tokens associated with randomly masked image patches. This masking approach, however, introduces noise into the input data during pre-training, leading to discrepancies that can impair performance during the fine-tuning phase. Furthermore, input masking neglects the dependencies between corrupted patches, increasing the inconsistencies observed in downstream fine-tuning tasks. To overcome these issues, we propose a new self-supervised pre-training approach, named Masked and Permuted Vision Transformer (MaPeT), that employs autoregressive and permuted predictions to capture intra-patch dependencies. In addition, MaPeT employs auxiliary positional information to reduce the disparity between the pre-training and fine-tuning phases. In our experiments, we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers, including our proposed $k$-CLIP which directly employs discretized CLIP features. Our results demonstrate that MaPeT achieves competitive performance on ImageNet, compared to baselines and competitors under the same model setting. Source code and trained models are publicly available at: https://github.com/aimagelab/MaPeT.
Retrieval-Enhanced Contrastive Vision-Text Models
Jun 12, 2023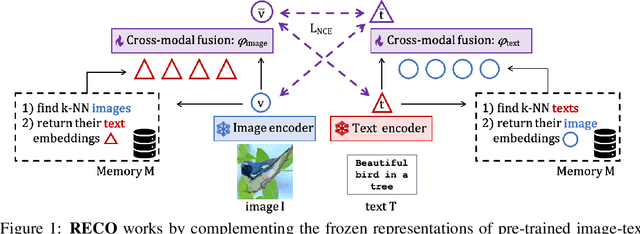
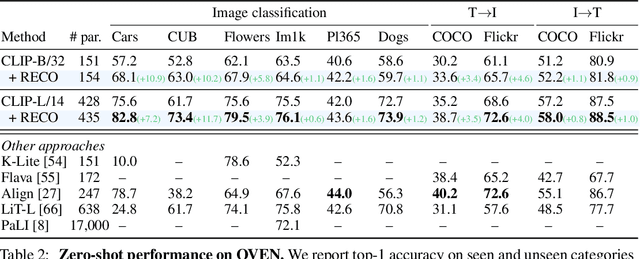
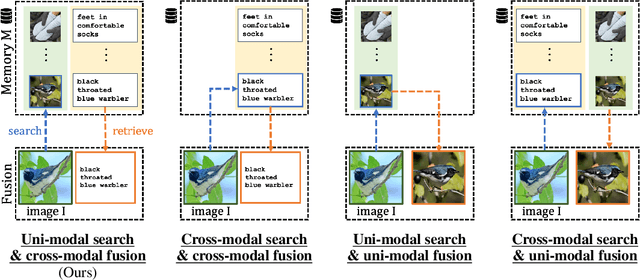
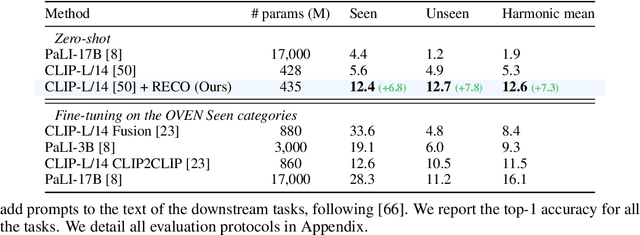
Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.