 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-Grained Action Detection with RGB and Pose Information using Two Stream Convolutional Networks
Feb 06, 2023
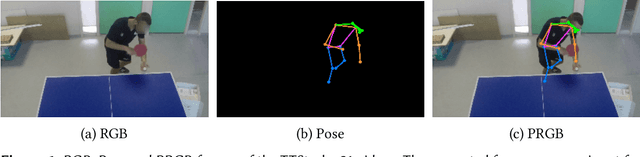
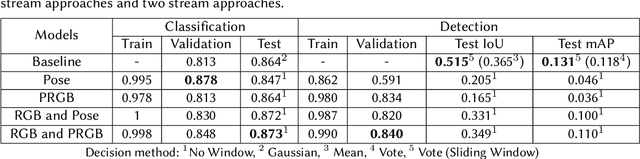
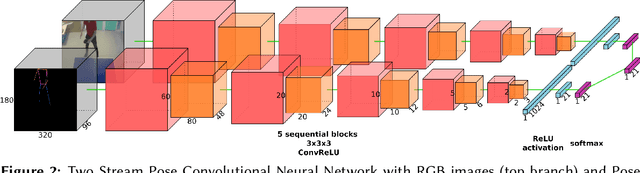
As participants of the MediaEval 2022 Sport Task, we propose a two-stream network approach for the classification and detection of table tennis strokes. Each stream is a succession of 3D Convolutional Neural Network (CNN) blocks using attention mechanisms. Each stream processes different 4D inputs. Our method utilizes raw RGB data and pose information computed from MMPose toolbox. The pose information is treated as an image by applying the pose either on a black background or on the original RGB frame it has been computed from. Best performance is obtained by feeding raw RGB data to one stream, Pose + RGB (PRGB) information to the other stream and applying late fusion on the features. The approaches were evaluated on the provided TTStroke-21 data sets. We can report an improvement in stroke classification, reaching 87.3% of accuracy, while the detection does not outperform the baseline but still reaches an IoU of 0.349 and mAP of 0.110.
Detecting Errors in Numerical Data via any Regression Model
Jun 03, 2023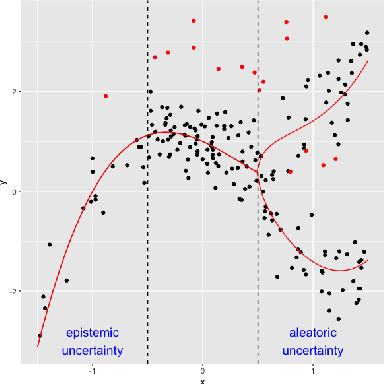
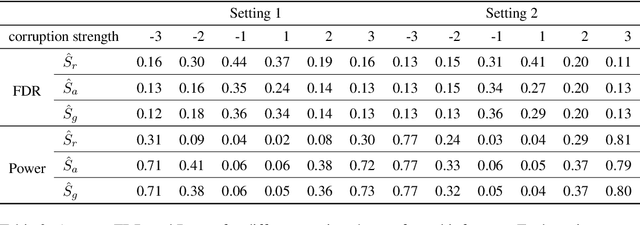
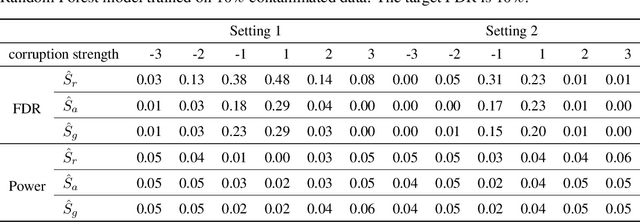
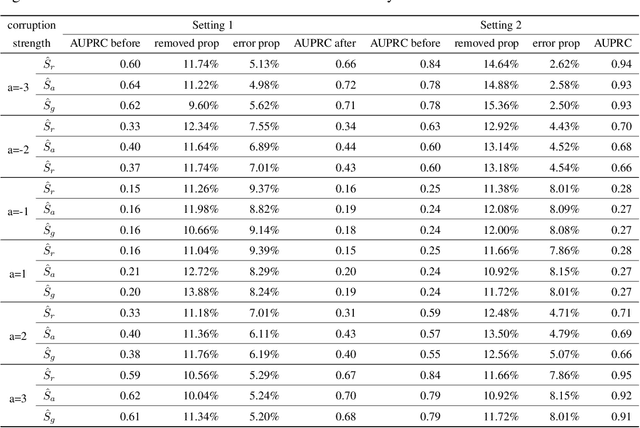
Noise plagues many numerical datasets, where the recorded values in the data may fail to match the true underlying values due to reasons including: erroneous sensors, data entry/processing mistakes, or imperfect human estimates. Here we consider estimating which data values are incorrect along a numerical column. We present a model-agnostic approach that can utilize any regressor (i.e. statistical or machine learning model) which was fit to predict values in this column based on the other variables in the dataset. By accounting for various uncertainties, our approach distinguishes between genuine anomalies and natural data fluctuations, conditioned on the available information in the dataset. We establish theoretical guarantees for our method and show that other approaches like conformal inference struggle to detect errors. We also contribute a new error detection benchmark involving 5 regression datasets with real-world numerical errors (for which the true values are also known). In this benchmark and additional simulation studies, our method identifies incorrect values with better precision/recall than other approaches.
Utilizing ChatGPT to Enhance Clinical Trial Enrollment
Jun 03, 2023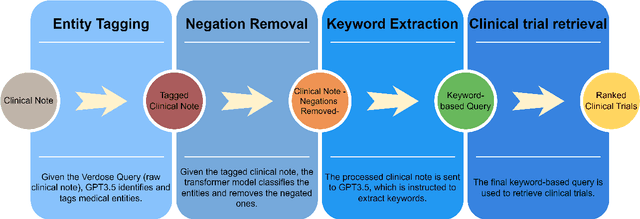
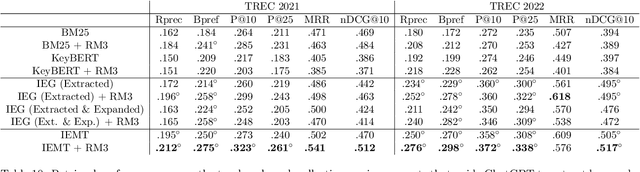
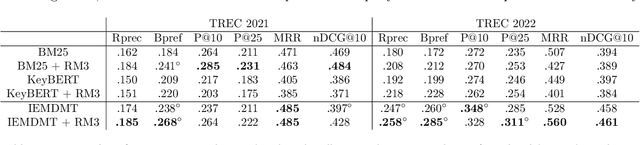
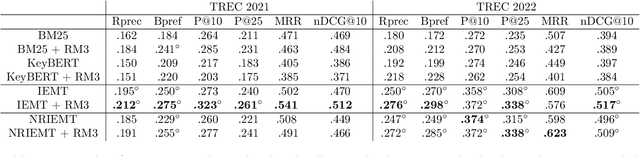
Clinical trials are a critical component of evaluating the effectiveness of new medical interventions and driving advancements in medical research. Therefore, timely enrollment of patients is crucial to prevent delays or premature termination of trials. In this context, Electronic Health Records (EHRs) have emerged as a valuable tool for identifying and enrolling eligible participants. In this study, we propose an automated approach that leverages ChatGPT, a large language model, to extract patient-related information from unstructured clinical notes and generate search queries for retrieving potentially eligible clinical trials. Our empirical evaluation, conducted on two benchmark retrieval collections, shows improved retrieval performance compared to existing approaches when several general-purposed and task-specific prompts are used. Notably, ChatGPT-generated queries also outperform human-generated queries in terms of retrieval performance. These findings highlight the potential use of ChatGPT to enhance clinical trial enrollment while ensuring the quality of medical service and minimizing direct risks to patients.
Can Directed Graph Neural Networks be Adversarially Robust?
Jun 03, 2023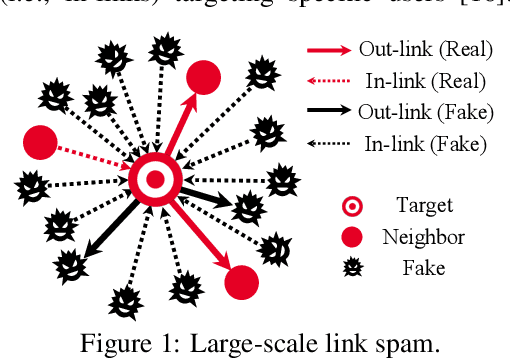
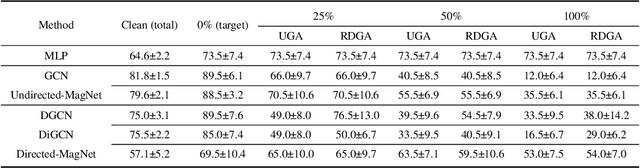
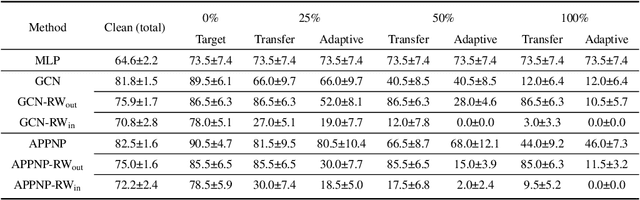
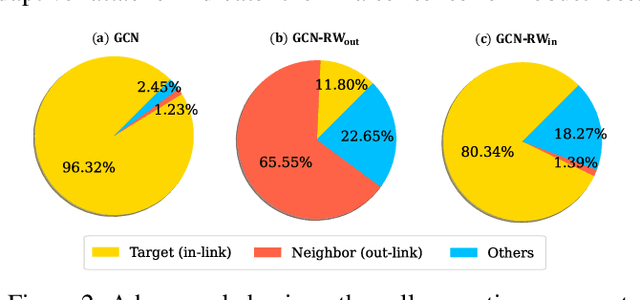
The existing research on robust Graph Neural Networks (GNNs) fails to acknowledge the significance of directed graphs in providing rich information about networks' inherent structure. This work presents the first investigation into the robustness of GNNs in the context of directed graphs, aiming to harness the profound trust implications offered by directed graphs to bolster the robustness and resilience of GNNs. Our study reveals that existing directed GNNs are not adversarially robust. In pursuit of our goal, we introduce a new and realistic directed graph attack setting and propose an innovative, universal, and efficient message-passing framework as a plug-in layer to significantly enhance the robustness of GNNs. Combined with existing defense strategies, this framework achieves outstanding clean accuracy and state-of-the-art robust performance, offering superior defense against both transfer and adaptive attacks. The findings in this study reveal a novel and promising direction for this crucial research area. The code will be made publicly available upon the acceptance of this work.
Multi-Objective Genetic Algorithm for Multi-View Feature Selection
May 26, 2023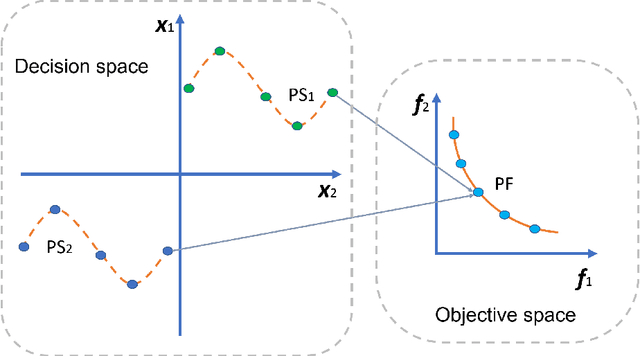

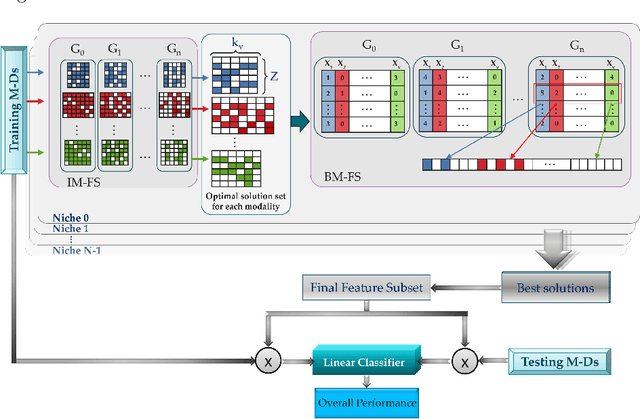

Multi-view datasets offer diverse forms of data that can enhance prediction models by providing complementary information. However, the use of multi-view data leads to an increase in high-dimensional data, which poses significant challenges for the prediction models that can lead to poor generalization. Therefore, relevant feature selection from multi-view datasets is important as it not only addresses the poor generalization but also enhances the interpretability of the models. Despite the success of traditional feature selection methods, they have limitations in leveraging intrinsic information across modalities, lacking generalizability, and being tailored to specific classification tasks. We propose a novel genetic algorithm strategy to overcome these limitations of traditional feature selection methods for multi-view data. Our proposed approach, called the multi-view multi-objective feature selection genetic algorithm (MMFS-GA), simultaneously selects the optimal subset of features within a view and between views under a unified framework. The MMFS-GA framework demonstrates superior performance and interpretability for feature selection on multi-view datasets in both binary and multiclass classification tasks. The results of our evaluations on three benchmark datasets, including synthetic and real data, show improvement over the best baseline methods. This work provides a promising solution for multi-view feature selection and opens up new possibilities for further research in multi-view datasets.
Semantic segmentation of sparse irregular point clouds for leaf/wood discrimination
May 26, 2023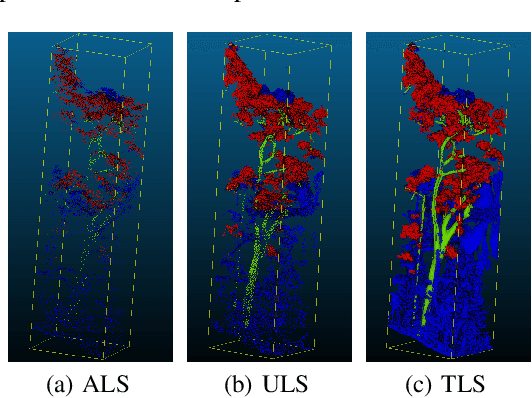
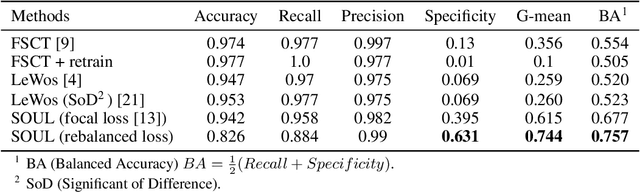
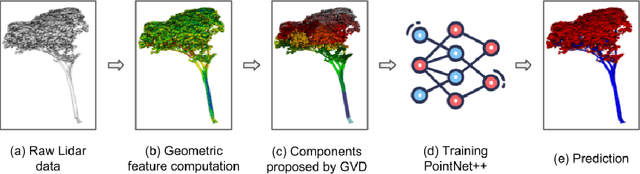

LiDAR (Light Detection and Ranging) has become an essential part of the remote sensing toolbox used for biosphere monitoring. In particular, LiDAR provides the opportunity to map forest leaf area with unprecedented accuracy, while leaf area has remained an important source of uncertainty affecting models of gas exchanges between the vegetation and the atmosphere. Unmanned Aerial Vehicles (UAV) are easy to mobilize and therefore allow frequent revisits to track the response of vegetation to climate change. However, miniature sensors embarked on UAVs usually provide point clouds of limited density, which are further affected by a strong decrease in density from top to bottom of the canopy due to progressively stronger occlusion. In such a context, discriminating leaf points from wood points presents a significant challenge due in particular to strong class imbalance and spatially irregular sampling intensity. Here we introduce a neural network model based on the Pointnet ++ architecture which makes use of point geometry only (excluding any spectral information). To cope with local data sparsity, we propose an innovative sampling scheme which strives to preserve local important geometric information. We also propose a loss function adapted to the severe class imbalance. We show that our model outperforms state-of-the-art alternatives on UAV point clouds. We discuss future possible improvements, particularly regarding much denser point clouds acquired from below the canopy.
Graph Exploration Matters: Improving both individual-level and system-level diversity in WeChat Feed Recommender
May 29, 2023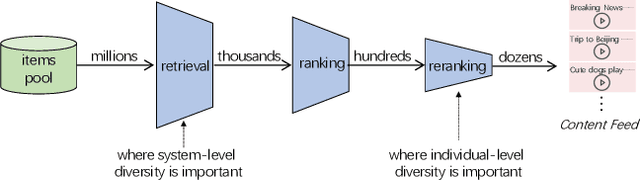

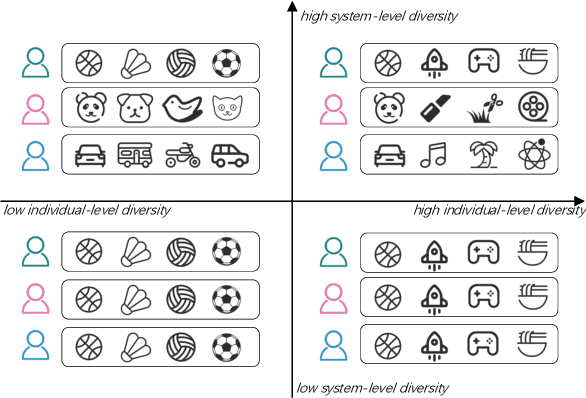
There are roughly three stages in real industrial recommendation systems, candidates generation (retrieval), ranking and reranking. Individual-level diversity and system-level diversity are both important for industrial recommender systems. The former focus on each single user's experience, while the latter focus on the difference among users. Graph-based retrieval strategies are inevitably hijacked by heavy users and popular items, leading to the convergence of candidates for users and the lack of system-level diversity. Meanwhile, in the reranking phase, Determinantal Point Process (DPP) is deployed to increase individual-level diverisity. Heavily relying on the semantic information of items, DPP suffers from clickbait and inaccurate attributes. Besides, most studies only focus on one of the two levels of diversity, and ignore the mutual influence among different stages in real recommender systems. We argue that individual-level diversity and system-level diversity should be viewed as an integrated problem, and we provide an efficient and deployable solution for web-scale recommenders. Generally, we propose to employ the retrieval graph information in diversity-based reranking, by which to weaken the hidden similarity of items exposed to users, and consequently gain more graph explorations to improve the system-level diveristy. Besides, we argue that users' propensity for diversity changes over time in content feed recommendation. Therefore, with the explored graph, we also propose to capture the user's real-time personalized propensity to the diversity. We implement and deploy the combined system in WeChat App's Top Stories used by hundreds of millions of users. Offline simulations and online A/B tests show our solution can effectively improve both user engagement and system revenue.
Active Collaborative Localization in Heterogeneous Robot Teams
May 29, 2023



Accurate and robust state estimation is critical for autonomous navigation of robot teams. This task is especially challenging for large groups of size, weight, and power (SWAP) constrained aerial robots operating in perceptually-degraded GPS-denied environments. We can, however, actively increase the amount of perceptual information available to such robots by augmenting them with a small number of more expensive, but less resource-constrained, agents. Specifically, the latter can serve as sources of perceptual information themselves. In this paper, we study the problem of optimally positioning (and potentially navigating) a small number of more capable agents to enhance the perceptual environment for their lightweight,inexpensive, teammates that only need to rely on cameras and IMUs. We propose a numerically robust, computationally efficient approach to solve this problem via nonlinear optimization. Our method outperforms the standard approach based on the greedy algorithm, while matching the accuracy of a heuristic evolutionary scheme for global optimization at a fraction of its running time. Ultimately, we validate our solution in both photorealistic simulations and real-world experiments. In these experiments, we use lidar-based autonomous ground vehicles as the more capable agents, and vision-based aerial robots as their SWAP-constrained teammates. Our method is able to reduce drift in visual-inertial odometry by as much as 90%, and it outperforms random positioning of lidar-equipped agents by a significant margin. Furthermore, our method can be generalized to different types of robot teams with heterogeneous perception capabilities. It has a wide range of applications, such as surveying and mapping challenging dynamic environments, and enabling resilience to large-scale perturbations that can be caused by earthquakes or storms.
An empirical study on speech restoration guided by self supervised speech representation
May 30, 2023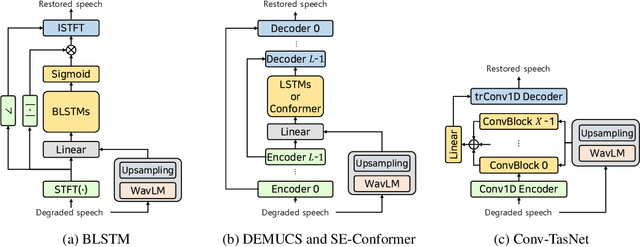
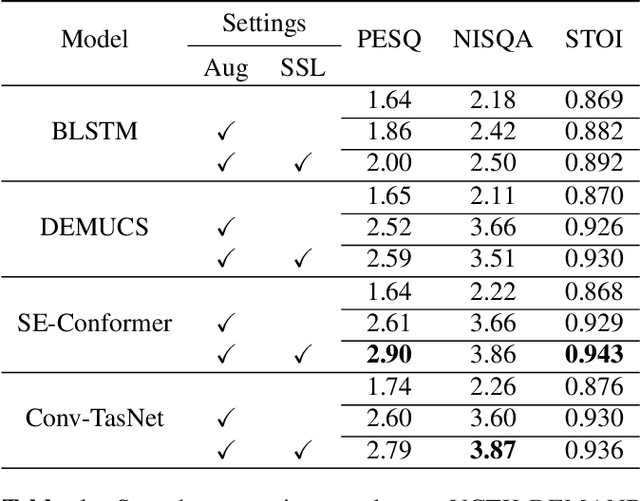
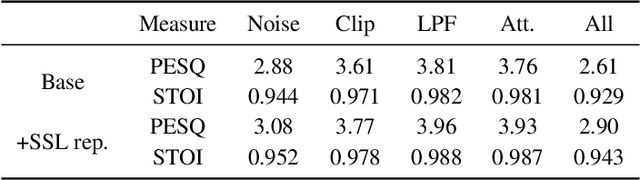
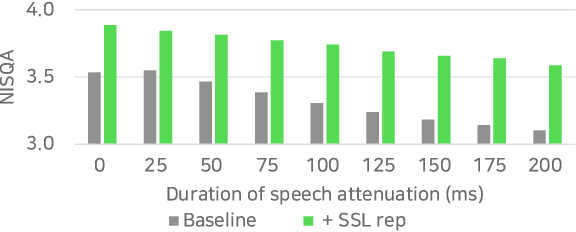
Enhancing speech quality is an indispensable yet difficult task as it is often complicated by a range of degradation factors. In addition to additive noise, reverberation, clipping, and speech attenuation can all adversely affect speech quality. Speech restoration aims to recover speech components from these distortions. This paper focuses on exploring the impact of self-supervised speech representation learning on the speech restoration task. Specifically, we employ speech representation in various speech restoration networks and evaluate their performance under complicated distortion scenarios. Our experiments demonstrate that the contextual information provided by the self-supervised speech representation can enhance speech restoration performance in various distortion scenarios, while also increasing robustness against the duration of speech attenuation and mismatched test conditions.
Towards Consistent Video Editing with Text-to-Image Diffusion Models
May 27, 2023
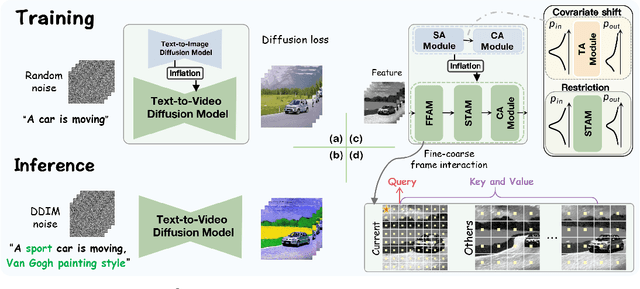


Existing works have advanced Text-to-Image (TTI) diffusion models for video editing in a one-shot learning manner. Despite their low requirements of data and computation, these methods might produce results of unsatisfied consistency with text prompt as well as temporal sequence, limiting their applications in the real world. In this paper, we propose to address the above issues with a novel EI$^2$ model towards \textbf{E}nhancing v\textbf{I}deo \textbf{E}diting cons\textbf{I}stency of TTI-based frameworks. Specifically, we analyze and find that the inconsistent problem is caused by newly added modules into TTI models for learning temporal information. These modules lead to covariate shift in the feature space, which harms the editing capability. Thus, we design EI$^2$ to tackle the above drawbacks with two classical modules: Shift-restricted Temporal Attention Module (STAM) and Fine-coarse Frame Attention Module (FFAM). First, through theoretical analysis, we demonstrate that covariate shift is highly related to Layer Normalization, thus STAM employs a \textit{Instance Centering} layer replacing it to preserve the distribution of temporal features. In addition, {STAM} employs an attention layer with normalized mapping to transform temporal features while constraining the variance shift. As the second part, we incorporate {STAM} with a novel {FFAM}, which efficiently leverages fine-coarse spatial information of overall frames to further enhance temporal consistency. Extensive experiments demonstrate the superiority of the proposed EI$^2$ model for text-driven video editing.