 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visualizing Information Bottleneck through Variational Inference
Dec 24, 2022
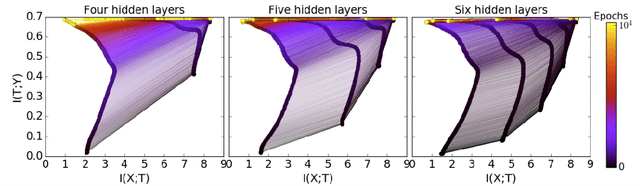

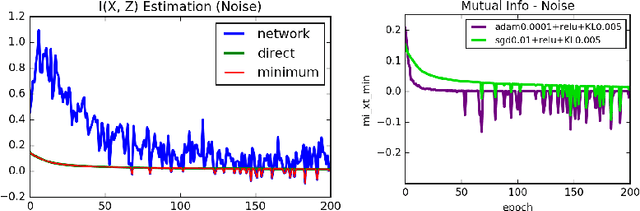
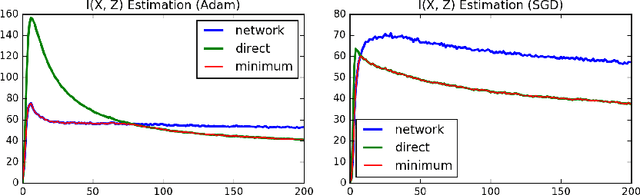
The Information Bottleneck theory provides a theoretical and computational framework for finding approximate minimum sufficient statistics. Analysis of the Stochastic Gradient Descent (SGD) training of a neural network on a toy problem has shown the existence of two phases, fitting and compression. In this work, we analyze the SGD training process of a Deep Neural Network on MNIST classification and confirm the existence of two phases of SGD training. We also propose a setup for estimating the mutual information for a Deep Neural Network through Variational Inference.
Calculating and Visualizing Counterfactual Feature Importance Values
Jun 10, 2023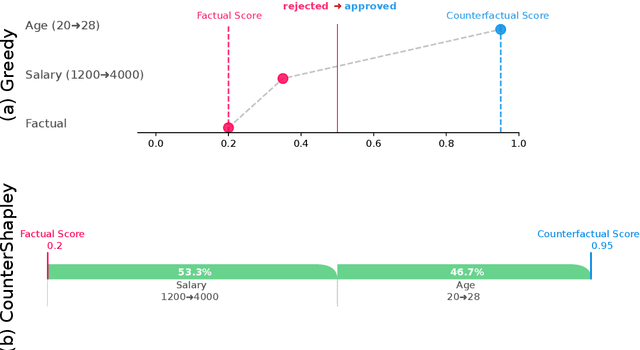

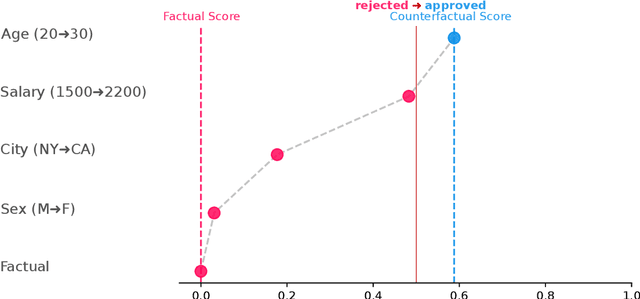

Despite the success of complex machine learning algorithms, mostly justified by an outstanding performance in prediction tasks, their inherent opaque nature still represents a challenge to their responsible application. Counterfactual explanations surged as one potential solution to explain individual decision results. However, two major drawbacks directly impact their usability: (1) the isonomic view of feature changes, in which it is not possible to observe \textit{how much} each modified feature influences the prediction, and (2) the lack of graphical resources to visualize the counterfactual explanation. We introduce Counterfactual Feature (change) Importance (CFI) values as a solution: a way of assigning an importance value to each feature change in a given counterfactual explanation. To calculate these values, we propose two potential CFI methods. One is simple, fast, and has a greedy nature. The other, coined CounterShapley, provides a way to calculate Shapley values between the factual-counterfactual pair. Using these importance values, we additionally introduce three chart types to visualize the counterfactual explanations: (a) the Greedy chart, which shows a greedy sequential path for prediction score increase up to predicted class change, (b) the CounterShapley chart, depicting its respective score in a simple and one-dimensional chart, and finally (c) the Constellation chart, which shows all possible combinations of feature changes, and their impact on the model's prediction score. For each of our proposed CFI methods and visualization schemes, we show how they can provide more information on counterfactual explanations. Finally, an open-source implementation is offered, compatible with any counterfactual explanation generator algorithm. Code repository at: https://github.com/ADMAntwerp/CounterPlots
An Architecture for Deploying Reinforcement Learning in Industrial Environments
Jun 02, 2023Industry 4.0 is driven by demands like shorter time-to-market, mass customization of products, and batch size one production. Reinforcement Learning (RL), a machine learning paradigm shown to possess a great potential in improving and surpassing human level performance in numerous complex tasks, allows coping with the mentioned demands. In this paper, we present an OPC UA based Operational Technology (OT)-aware RL architecture, which extends the standard RL setting, combining it with the setting of digital twins. Moreover, we define an OPC UA information model allowing for a generalized plug-and-play like approach for exchanging the RL agent used. In conclusion, we demonstrate and evaluate the architecture, by creating a proof of concept. By means of solving a toy example, we show that this architecture can be used to determine the optimal policy using a real control system.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in Computer Aided Systems Theory - EUROCAST 2022 and is available online at https://doi.org/10.1007/978-3-031-25312-6_67
DistilXLSR: A Light Weight Cross-Lingual Speech Representation Model
Jun 02, 2023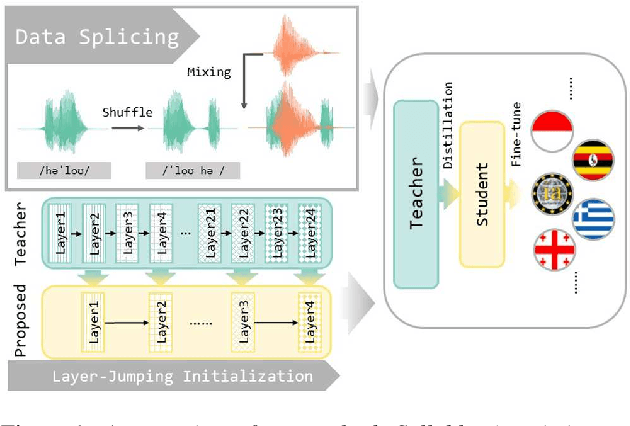
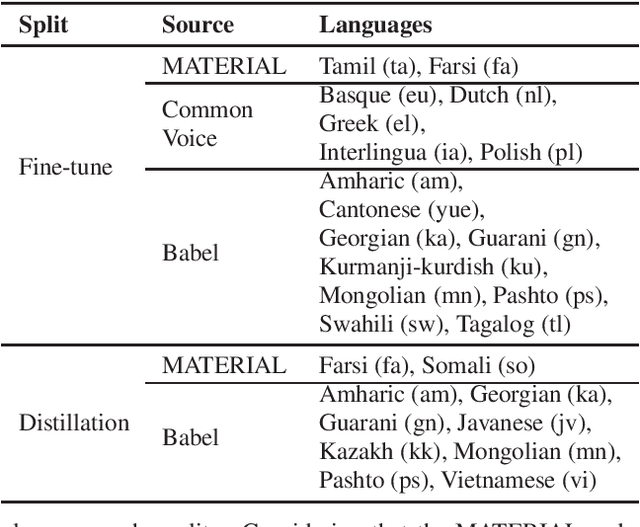
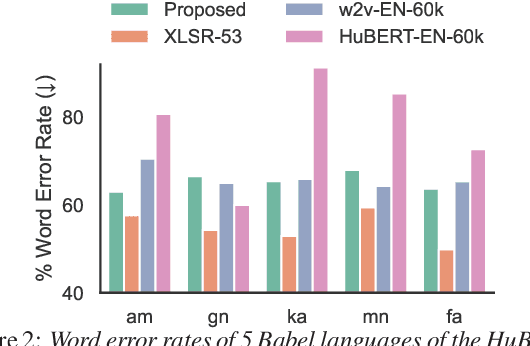
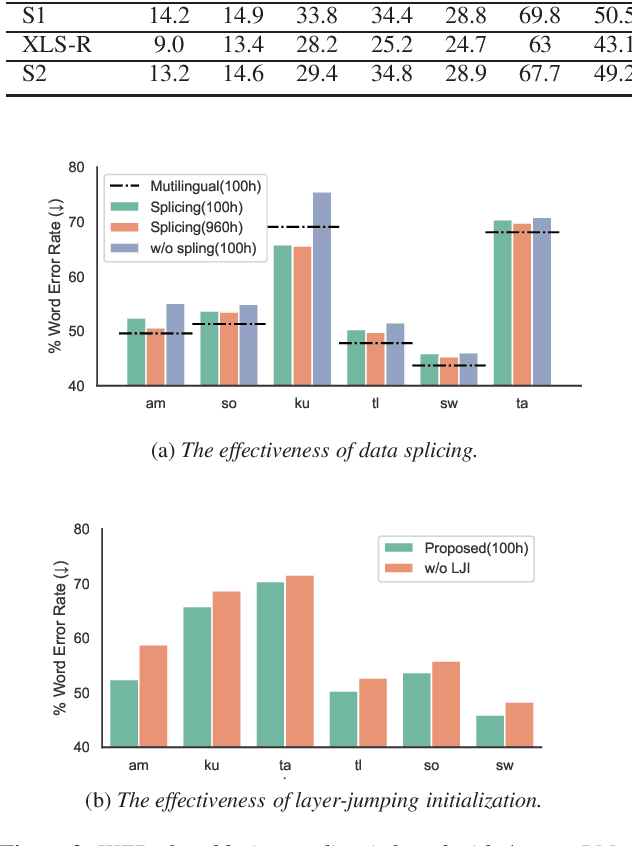
Multilingual self-supervised speech representation models have greatly enhanced the speech recognition performance for low-resource languages, and the compression of these huge models has also become a crucial prerequisite for their industrial application. In this paper, we propose DistilXLSR, a distilled cross-lingual speech representation model. By randomly shuffling the phonemes of existing speech, we reduce the linguistic information and distill cross-lingual models using only English data. We also design a layer-jumping initialization method to fully leverage the teacher's pre-trained weights. Experiments on 2 kinds of teacher models and 15 low-resource languages show that our method can reduce the parameters by 50% while maintaining cross-lingual representation ability. Our method is proven to be generalizable to various languages/teacher models and has the potential to improve the cross-lingual performance of the English pre-trained models.
Enhance Temporal Relations in Audio Captioning with Sound Event Detection
Jun 02, 2023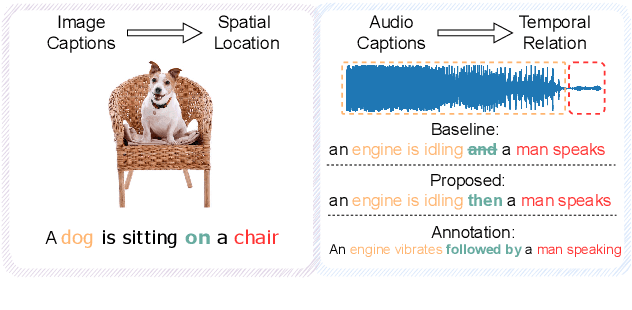

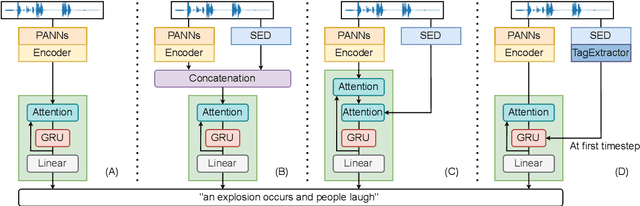
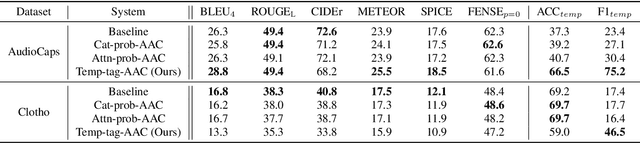
Automated audio captioning aims at generating natural language descriptions for given audio clips, not only detecting and classifying sounds, but also summarizing the relationships between audio events. Recent research advances in audio captioning have introduced additional guidance to improve the accuracy of audio events in generated sentences. However, temporal relations between audio events have received little attention while revealing complex relations is a key component in summarizing audio content. Therefore, this paper aims to better capture temporal relationships in caption generation with sound event detection (SED), a task that locates events' timestamps. We investigate the best approach to integrate temporal information in a captioning model and propose a temporal tag system to transform the timestamps into comprehensible relations. Results evaluated by the proposed temporal metrics suggest that great improvement is achieved in terms of temporal relation generation.
Meta-Learning in Spiking Neural Networks with Reward-Modulated STDP
Jun 07, 2023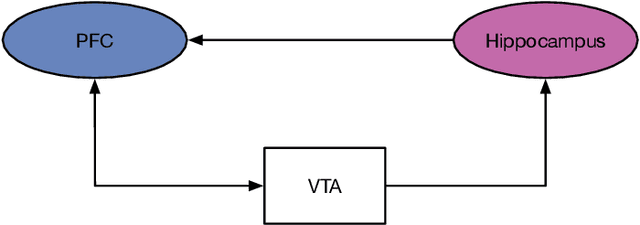
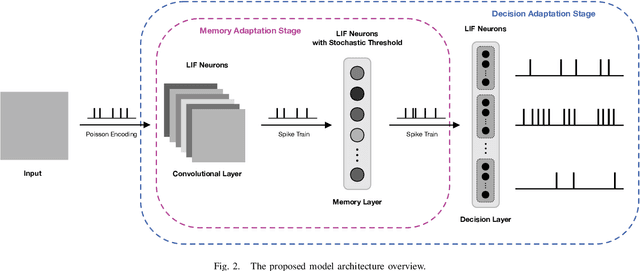


The human brain constantly learns and rapidly adapts to new situations by integrating acquired knowledge and experiences into memory. Developing this capability in machine learning models is considered an important goal of AI research since deep neural networks perform poorly when there is limited data or when they need to adapt quickly to new unseen tasks. Meta-learning models are proposed to facilitate quick learning in low-data regimes by employing absorbed information from the past. Although some models have recently been introduced that reached high-performance levels, they are not biologically plausible. We have proposed a bio-plausible meta-learning model inspired by the hippocampus and the prefrontal cortex using spiking neural networks with a reward-based learning system. Our proposed model includes a memory designed to prevent catastrophic forgetting, a phenomenon that occurs when meta-learning models forget what they have learned as soon as the new task begins. Also, our new model can easily be applied to spike-based neuromorphic devices and enables fast learning in neuromorphic hardware. The final analysis will discuss the implications and predictions of the model for solving few-shot classification tasks. In solving these tasks, our model has demonstrated the ability to compete with the existing state-of-the-art meta-learning techniques.
Understanding Place Identity with Generative AI
Jun 07, 2023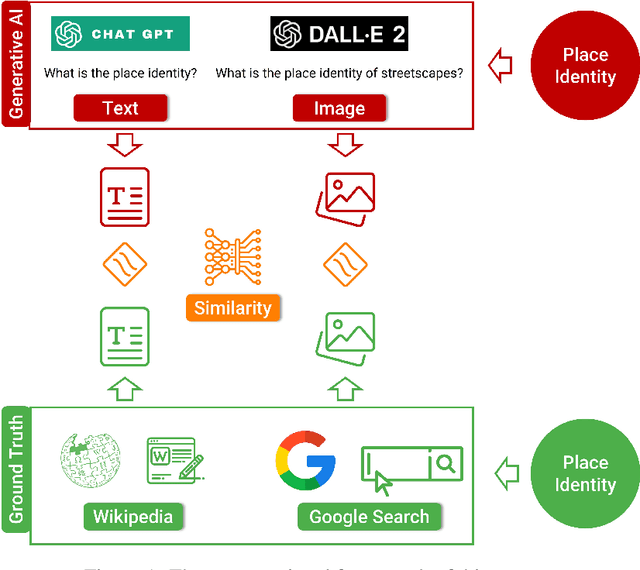
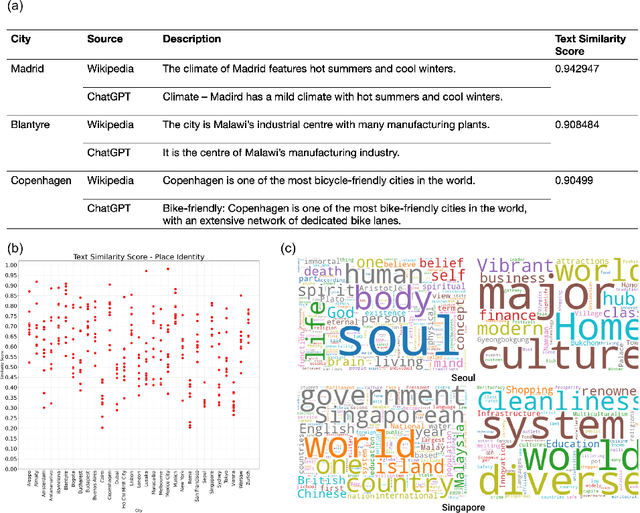
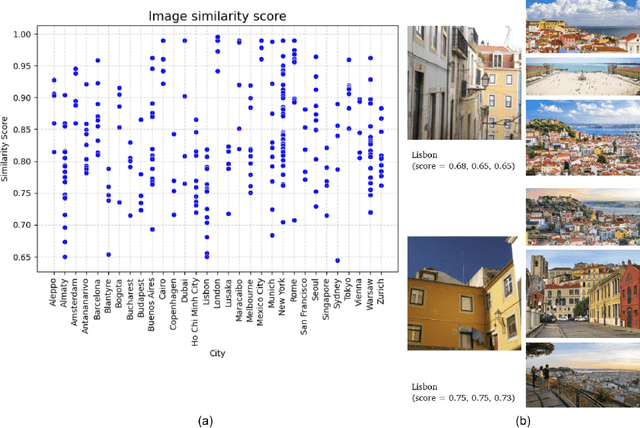
Researchers are constantly leveraging new forms of data with the goal of understanding how people perceive the built environment and build the collective place identity of cities. Latest advancements in generative artificial intelligence (AI) models have enabled the production of realistic representations learned from vast amounts of data. In this study, we aim to test the potential of generative AI as the source of textual and visual information in capturing the place identity of cities assessed by filtered descriptions and images. We asked questions on the place identity of a set of 31 global cities to two generative AI models, ChatGPT and DALL-E2. Since generative AI has raised ethical concerns regarding its trustworthiness, we performed cross-validation to examine whether the results show similar patterns to real urban settings. In particular, we compared the outputs with Wikipedia data for text and images searched from Google for image. Our results indicate that generative AI models have the potential to capture the collective image of cities that can make them distinguishable. This study is among the first attempts to explore the capabilities of generative AI in understanding human perceptions of the built environment. It contributes to urban design literature by discussing future research opportunities and potential limitations.
Enabling tabular deep learning when $d \gg n$ with an auxiliary knowledge graph
Jun 07, 2023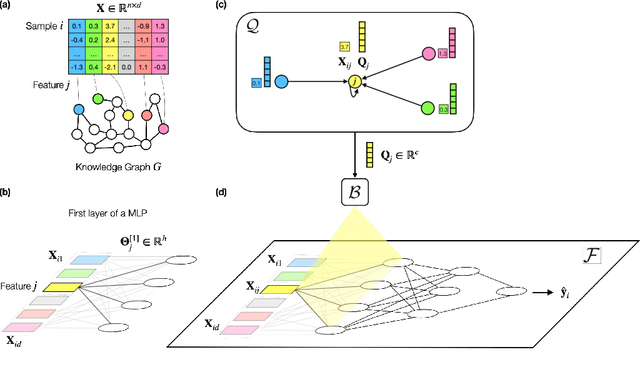

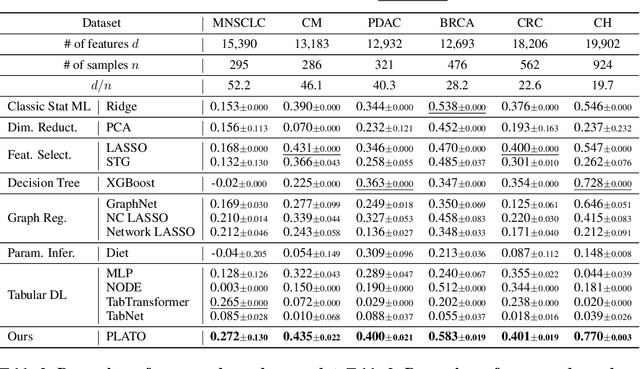
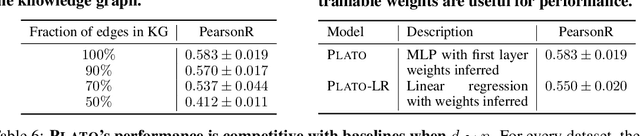
Machine learning models exhibit strong performance on datasets with abundant labeled samples. However, for tabular datasets with extremely high $d$-dimensional features but limited $n$ samples (i.e. $d \gg n$), machine learning models struggle to achieve strong performance due to the risk of overfitting. Here, our key insight is that there is often abundant, auxiliary domain information describing input features which can be structured as a heterogeneous knowledge graph (KG). We propose PLATO, a method that achieves strong performance on tabular data with $d \gg n$ by using an auxiliary KG describing input features to regularize a multilayer perceptron (MLP). In PLATO, each input feature corresponds to a node in the auxiliary KG. In the MLP's first layer, each input feature also corresponds to a weight vector. PLATO is based on the inductive bias that two input features corresponding to similar nodes in the auxiliary KG should have similar weight vectors in the MLP's first layer. PLATO captures this inductive bias by inferring the weight vector for each input feature from its corresponding node in the KG via a trainable message-passing function. Across 6 $d \gg n$ datasets, PLATO outperforms 13 state-of-the-art baselines by up to 10.19%.
Multiscale Flow for Robust and Optimal Cosmological Analysis
Jun 07, 2023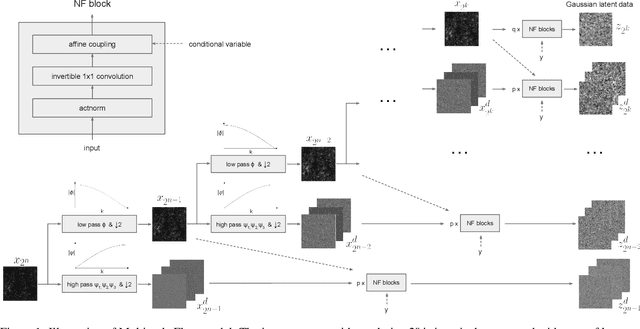

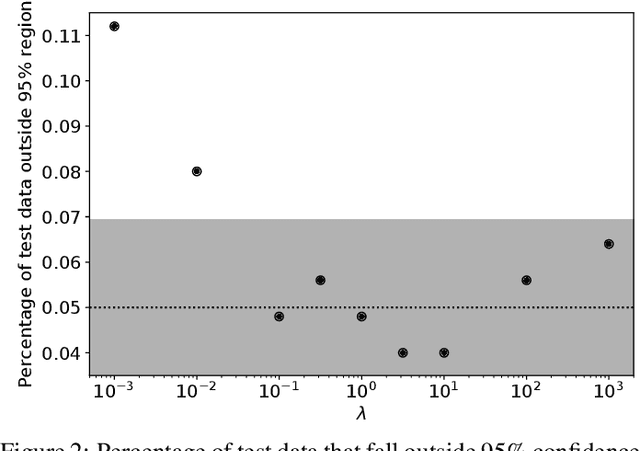
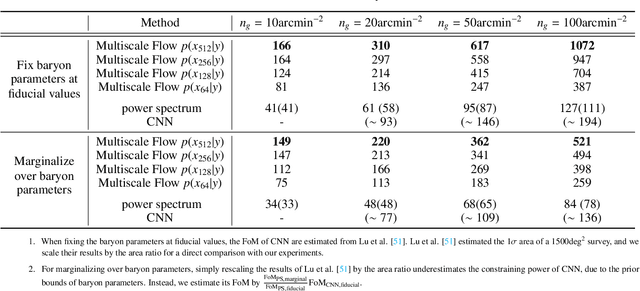
We propose Multiscale Flow, a generative Normalizing Flow that creates samples and models the field-level likelihood of two-dimensional cosmological data such as weak lensing. Multiscale Flow uses hierarchical decomposition of cosmological fields via a wavelet basis, and then models different wavelet components separately as Normalizing Flows. The log-likelihood of the original cosmological field can be recovered by summing over the log-likelihood of each wavelet term. This decomposition allows us to separate the information from different scales and identify distribution shifts in the data such as unknown scale-dependent systematics. The resulting likelihood analysis can not only identify these types of systematics, but can also be made optimal, in the sense that the Multiscale Flow can learn the full likelihood at the field without any dimensionality reduction. We apply Multiscale Flow to weak lensing mock datasets for cosmological inference, and show that it significantly outperforms traditional summary statistics such as power spectrum and peak counts, as well as novel Machine Learning based summary statistics such as scattering transform and convolutional neural networks. We further show that Multiscale Flow is able to identify distribution shifts not in the training data such as baryonic effects. Finally, we demonstrate that Multiscale Flow can be used to generate realistic samples of weak lensing data.
Towards Decentralized Heterogeneous Multi-Robot SLAM and Target Tracking
Jun 07, 2023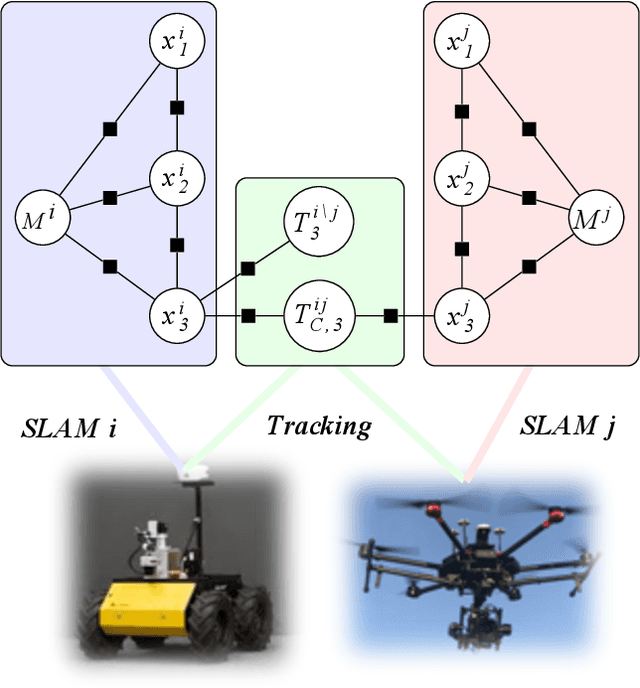
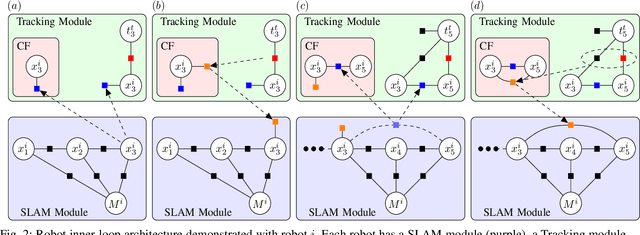
In many robotics problems, there is a significant gain in collaborative information sharing between multiple robots, for exploration, search and rescue, tracking multiple targets, or mapping large environments. One of the key implicit assumptions when solving cooperative multi-robot problems is that all robots use the same (homogeneous) underlying algorithm. However, in practice, we want to allow collaboration between robots possessing different capabilities and that therefore must rely on heterogeneous algorithms. We present a system architecture and the supporting theory, to enable collaboration in a decentralized network of robots, where each robot relies on different estimation algorithms. To develop our approach, we focus on multi-robot simultaneous localization and mapping (SLAM) with multi-target tracking. Our theoretical framework builds on our idea of exploiting the conditional independence structure inherent to many robotics applications to separate between each robot's local inference (estimation) tasks and fuse only relevant parts of their non-equal, but overlapping probability density function (pdfs). We present a new decentralized graph-based approach to the multi-robot SLAM and tracking problem. We leverage factor graphs to split between different parts of the problem for efficient data sharing between robots in the network while enabling robots to use different local sparse landmark/dense/metric-semantic SLAM algorithms.