 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Neural Networks in Video Human Action Recognition: A Review
May 25, 2023

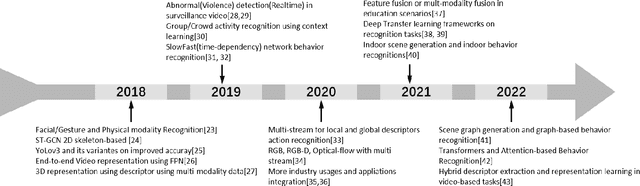
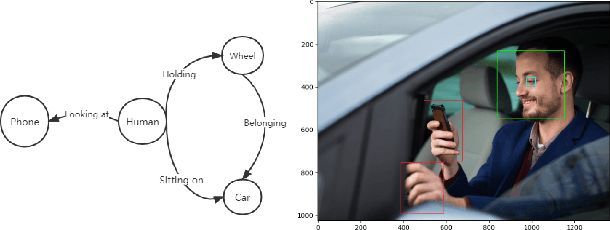

Currently, video behavior recognition is one of the most foundational tasks of computer vision. The 2D neural networks of deep learning are built for recognizing pixel-level information such as images with RGB, RGB-D, or optical flow formats, with the current increasingly wide usage of surveillance video and more tasks related to human action recognition. There are increasing tasks requiring temporal information for frames dependency analysis. The researchers have widely studied video-based recognition rather than image-based(pixel-based) only to extract more informative elements from geometry tasks. Our current related research addresses multiple novel proposed research works and compares their advantages and disadvantages between the derived deep learning frameworks rather than machine learning frameworks. The comparison happened between existing frameworks and datasets, which are video format data only. Due to the specific properties of human actions and the increasingly wide usage of deep neural networks, we collected all research works within the last three years between 2020 to 2022. In our article, the performance of deep neural networks surpassed most of the techniques in the feature learning and extraction tasks, especially video action recognition.
Codebook Configuration for 1-bit RIS-aided Systems Based on Implicit Neural Representations
Jun 01, 2023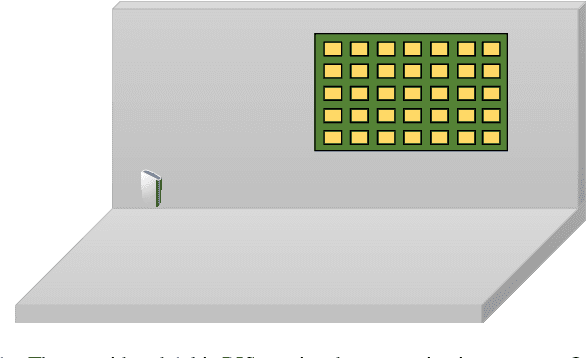
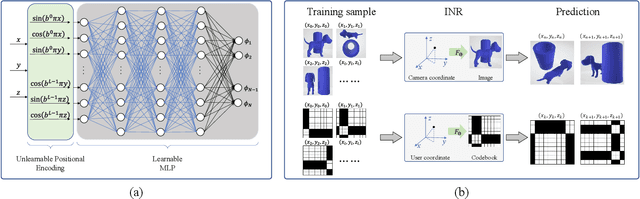
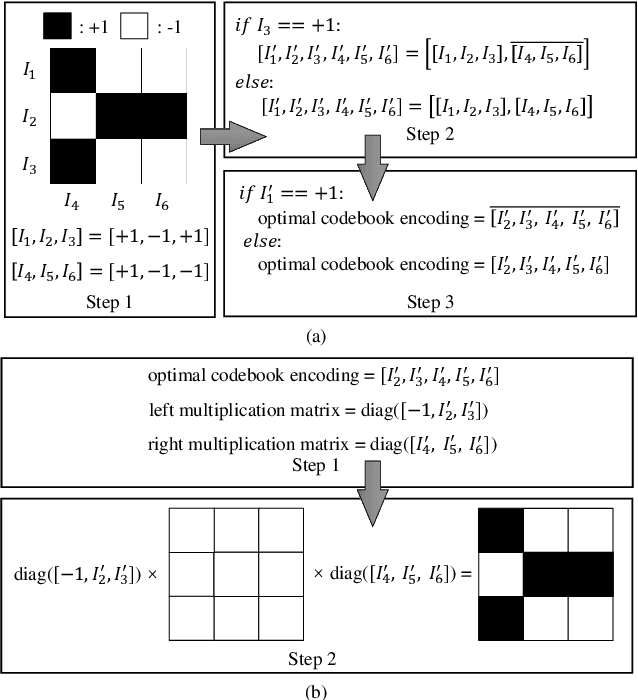
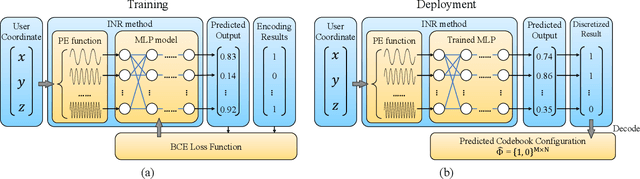
Reconfigurable intelligent surfaces (RISs) have become one of the key technologies in 6G wireless communications. By configuring the reflection beamforming codebooks, RIS focuses signals on target receivers. In this paper, we investigate the codebook configuration for 1-bit RIS-aided systems. We propose a novel learning-based method built upon the advanced methodology of implicit neural representations. The proposed model learns a continuous and differentiable coordinate-to-codebook representation from samplings. Our method only requires the information of the user's coordinate and avoids the assumption of channel models. Moreover, we propose an encoding-decoding strategy to reduce the dimension of codebooks, and thus improve the learning efficiency of the proposed method. Experimental results on simulation and measured data demonstrated the remarkable advantages of the proposed method.
MindBigData 2023 MNIST-8B The 8 billion datapoints Multimodal Dataset of Brain Signals
Jun 01, 2023MindBigData 2023 MNIST-8B is the largest, to date (June 1st 2023), brain signals open dataset created for Machine Learning, based on EEG signals from a single subject captured using a custom 128 channels device, replicating the full 70,000 digits from Yaan LeCun et all MNIST dataset. The brain signals were captured while the subject was watching the pixels of the original digits one by one on a screen and listening at the same time to the spoken number 0 to 9 from the real label. The data, collection procedures, hardware and software created are described in detail, background extra information and other related datasets can be found at our previous paper MindBigData 2022: A Large Dataset of Brain Signals.
Federated Graph Learning for Low Probability of Detection in Wireless Ad-Hoc Networks
Jun 01, 2023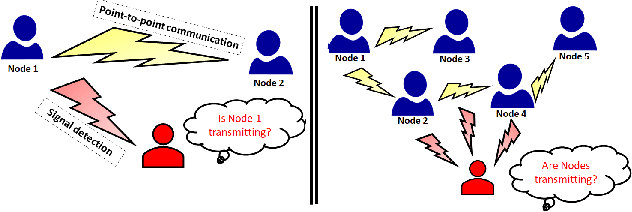
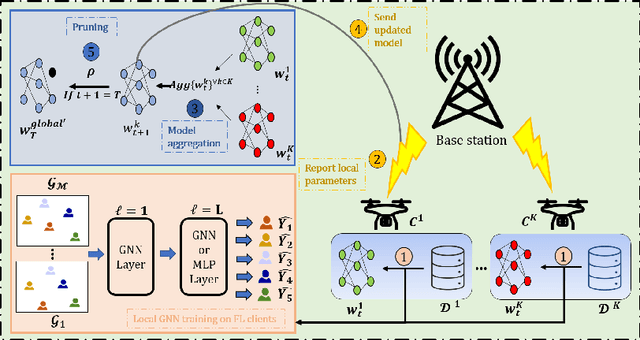
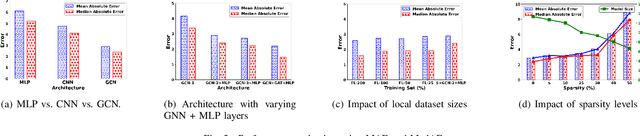
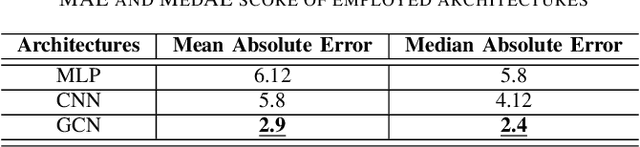
Low probability of detection (LPD) has recently emerged as a means to enhance the privacy and security of wireless networks. Unlike existing wireless security techniques, LPD measures aim to conceal the entire existence of wireless communication instead of safeguarding the information transmitted from users. Motivated by LPD communication, in this paper, we study a privacy-preserving and distributed framework based on graph neural networks to minimise the detectability of a wireless ad-hoc network as a whole and predict an optimal communication region for each node in the wireless network, allowing them to communicate while remaining undetected from external actors. We also demonstrate the effectiveness of the proposed method in terms of two performance measures, i.e., mean absolute error and median absolute error.
Modeling Cross-Cultural Pragmatic Inference with Codenames Duet
Jun 04, 2023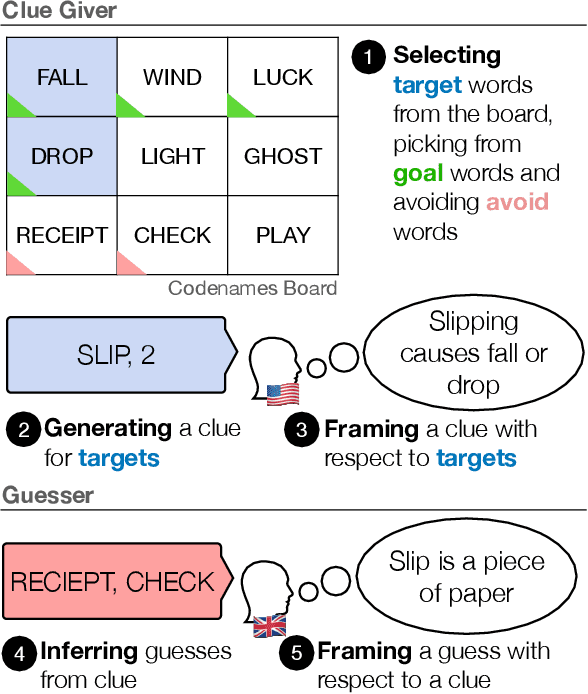
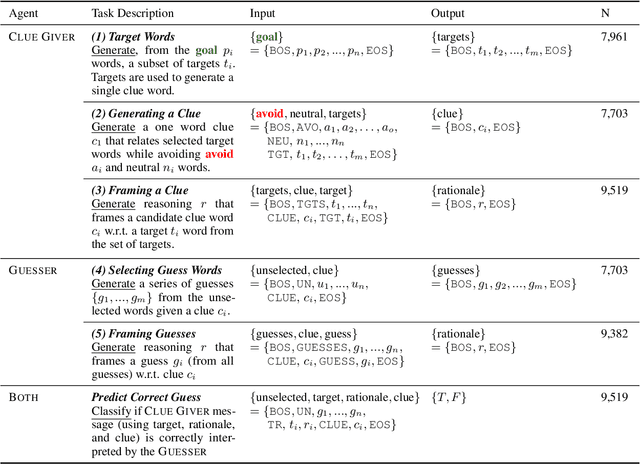
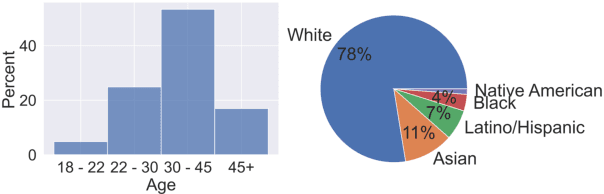
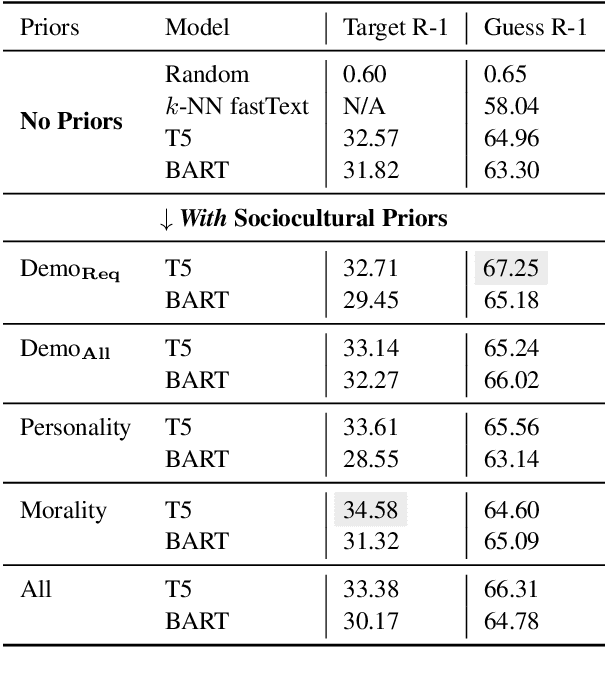
Pragmatic reference enables efficient interpersonal communication. Prior work uses simple reference games to test models of pragmatic reasoning, often with unidentified speakers and listeners. In practice, however, speakers' sociocultural background shapes their pragmatic assumptions. For example, readers of this paper assume NLP refers to "Natural Language Processing," and not "Neuro-linguistic Programming." This work introduces the Cultural Codes dataset, which operationalizes sociocultural pragmatic inference in a simple word reference game. Cultural Codes is based on the multi-turn collaborative two-player game, Codenames Duet. Our dataset consists of 794 games with 7,703 turns, distributed across 153 unique players. Alongside gameplay, we collect information about players' personalities, values, and demographics. Utilizing theories of communication and pragmatics, we predict each player's actions via joint modeling of their sociocultural priors and the game context. Our experiments show that accounting for background characteristics significantly improves model performance for tasks related to both clue giving and guessing, indicating that sociocultural priors play a vital role in gameplay decisions.
Commitment with Signaling under Double-sided Information Asymmetry
Dec 22, 2022
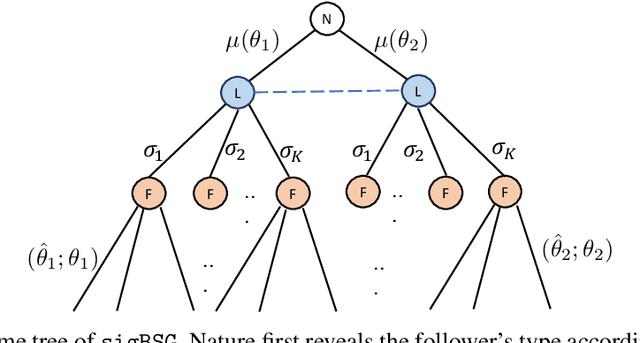
Information asymmetry in games enables players with the information advantage to manipulate others' beliefs by strategically revealing information to other players. This work considers a double-sided information asymmetry in a Bayesian Stackelberg game, where the leader's realized action, sampled from the mixed strategy commitment, is hidden from the follower. In contrast, the follower holds private information about his payoff. Given asymmetric information on both sides, an important question arises: \emph{Does the leader's information advantage outweigh the follower's?} We answer this question affirmatively in this work, where we demonstrate that by adequately designing a signaling device that reveals partial information regarding the leader's realized action to the follower, the leader can achieve a higher expected utility than that without signaling. Moreover, unlike previous works on the Bayesian Stackelberg game where mathematical programming tools are utilized, we interpret the leader's commitment as a probability measure over the belief space. Such a probabilistic language greatly simplifies the analysis and allows an indirect signaling scheme, leading to a geometric characterization of the equilibrium under the proposed game model.
DiffuSIA: A Spiral Interaction Architecture for Encoder-Decoder Text Diffusion
May 19, 2023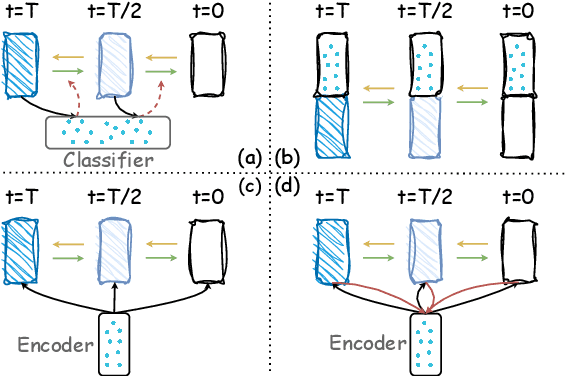
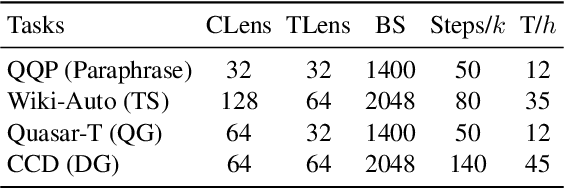
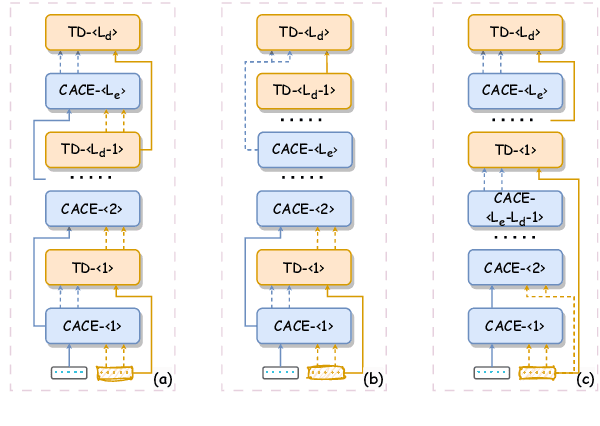
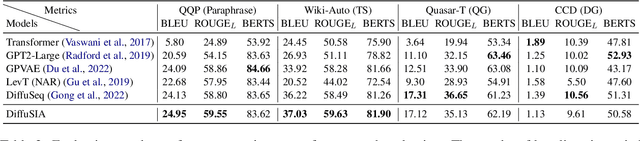
Diffusion models have emerged as the new state-of-the-art family of deep generative models, and their promising potentials for text generation have recently attracted increasing attention. Existing studies mostly adopt a single encoder architecture with partially noising processes for conditional text generation, but its degree of flexibility for conditional modeling is limited. In fact, the encoder-decoder architecture is naturally more flexible for its detachable encoder and decoder modules, which is extensible to multilingual and multimodal generation tasks for conditions and target texts. However, the encoding process of conditional texts lacks the understanding of target texts. To this end, a spiral interaction architecture for encoder-decoder text diffusion (DiffuSIA) is proposed. Concretely, the conditional information from encoder is designed to be captured by the diffusion decoder, while the target information from decoder is designed to be captured by the conditional encoder. These two types of information flow run through multilayer interaction spirally for deep fusion and understanding. DiffuSIA is evaluated on four text generation tasks, including paraphrase, text simplification, question generation, and open-domain dialogue generation. Experimental results show that DiffuSIA achieves competitive performance among previous methods on all four tasks, demonstrating the effectiveness and generalization ability of the proposed method.
DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions
May 26, 2023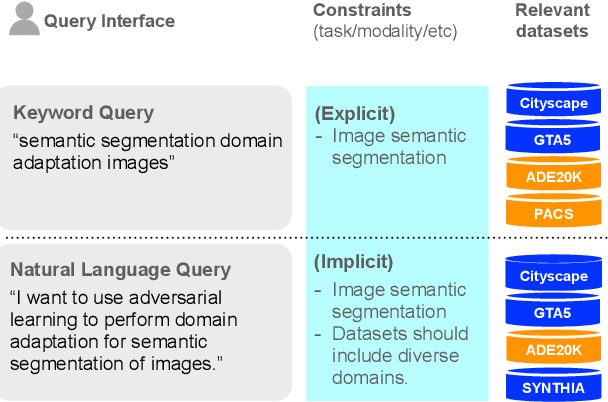
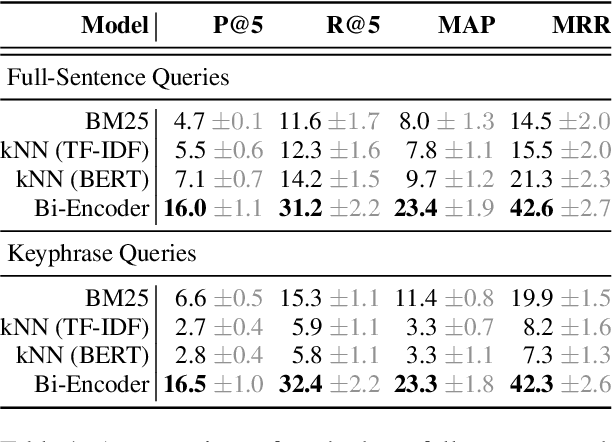
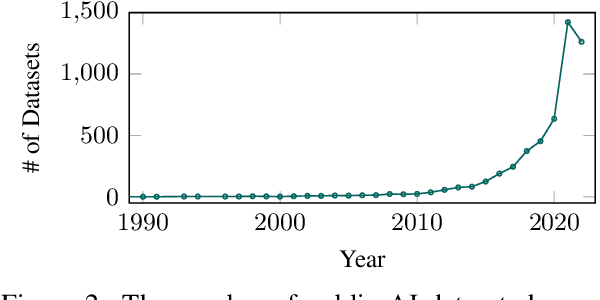
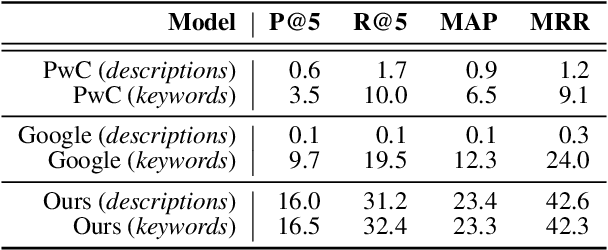
Modern machine learning relies on datasets to develop and validate research ideas. Given the growth of publicly available data, finding the right dataset to use is increasingly difficult. Any research question imposes explicit and implicit constraints on how well a given dataset will enable researchers to answer this question, such as dataset size, modality, and domain. We introduce a new task of recommending relevant datasets given a short natural language description of a research idea, to help people find relevant datasets for their needs. Dataset recommendation poses unique challenges as an information retrieval problem; datasets are hard to directly index for search and there are no corpora readily available for this task. To operationalize this task, we build the DataFinder Dataset which consists of a larger automatically-constructed training set (17.5K queries) and a smaller expert-annotated evaluation set (392 queries). Using this data, we compare various information retrieval algorithms on our test set and present the first-ever published system for text-based dataset recommendation using machine learning techniques. This system, trained on the DataFinder Dataset, finds more relevant search results than existing third-party dataset search engines. To encourage progress on dataset recommendation, we release our dataset and models to the public.
CyPhERS: A Cyber-Physical Event Reasoning System providing real-time situational awareness for attack and fault response
May 26, 2023
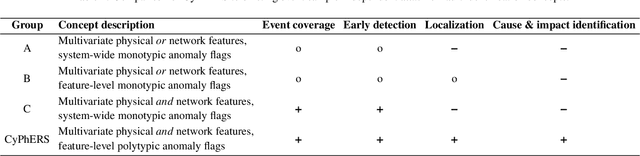
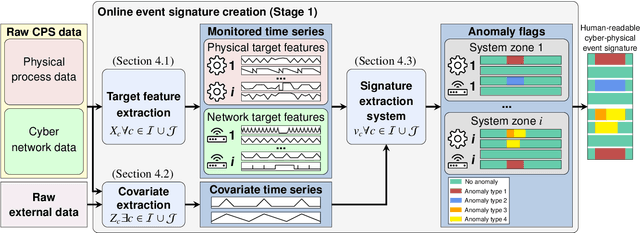

Cyber-physical systems (CPSs) constitute the backbone of critical infrastructures such as power grids or water distribution networks. Operating failures in these systems can cause serious risks for society. To avoid or minimize downtime, operators require real-time awareness about critical incidents. However, online event identification in CPSs is challenged by the complex interdependency of numerous physical and digital components, requiring to take cyber attacks and physical failures equally into account. The online event identification problem is further complicated through the lack of historical observations of critical but rare events, and the continuous evolution of cyber attack strategies. This work introduces and demonstrates CyPhERS, a Cyber-Physical Event Reasoning System. CyPhERS provides real-time information pertaining the occurrence, location, physical impact, and root cause of potentially critical events in CPSs, without the need for historical event observations. Key novelty of CyPhERS is the capability to generate informative and interpretable event signatures of known and unknown types of both cyber attacks and physical failures. The concept is evaluated and benchmarked on a demonstration case that comprises a multitude of attack and fault events targeting various components of a CPS. The results demonstrate that the event signatures provide relevant and inferable information on both known and unknown event types.
On the Choice of Perception Loss Function for Learned Video Compression
May 30, 2023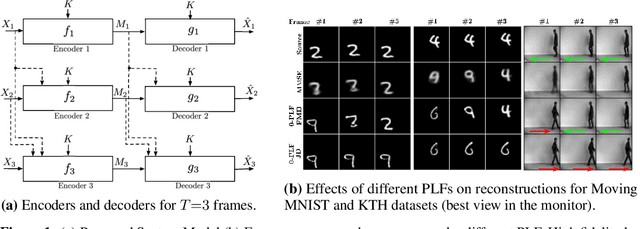
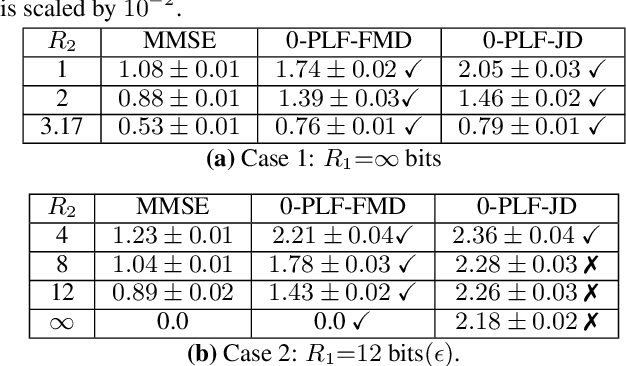
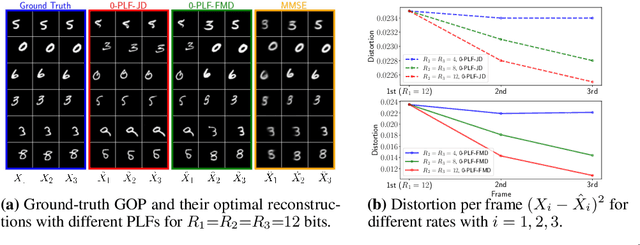

We study causal, low-latency, sequential video compression when the output is subjected to both a mean squared-error (MSE) distortion loss as well as a perception loss to target realism. Motivated by prior approaches, we consider two different perception loss functions (PLFs). The first, PLF-JD, considers the joint distribution (JD) of all the video frames up to the current one, while the second metric, PLF-FMD, considers the framewise marginal distributions (FMD) between the source and reconstruction. Using information theoretic analysis and deep-learning based experiments, we demonstrate that the choice of PLF can have a significant effect on the reconstruction, especially at low-bit rates. In particular, while the reconstruction based on PLF-JD can better preserve the temporal correlation across frames, it also imposes a significant penalty in distortion compared to PLF-FMD and further makes it more difficult to recover from errors made in the earlier output frames. Although the choice of PLF decisively affects reconstruction quality, we also demonstrate that it may not be essential to commit to a particular PLF during encoding and the choice of PLF can be delegated to the decoder. In particular, encoded representations generated by training a system to minimize the MSE (without requiring either PLF) can be {\em near universal} and can generate close to optimal reconstructions for either choice of PLF at the decoder. We validate our results using (one-shot) information-theoretic analysis, detailed study of the rate-distortion-perception tradeoff of the Gauss-Markov source model as well as deep-learning based experiments on moving MNIST and KTH datasets.