 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoviePuzzle: Visual Narrative Reasoning through Multimodal Order Learning
Jun 14, 2023


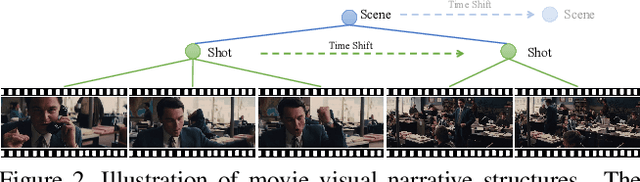
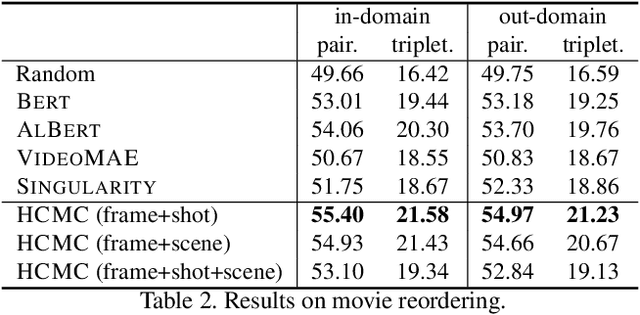
We introduce MoviePuzzle, a novel challenge that targets visual narrative reasoning and holistic movie understanding. Despite the notable progress that has been witnessed in the realm of video understanding, most prior works fail to present tasks and models to address holistic video understanding and the innate visual narrative structures existing in long-form videos. To tackle this quandary, we put forth MoviePuzzle task that amplifies the temporal feature learning and structure learning of video models by reshuffling the shot, frame, and clip layers of movie segments in the presence of video-dialogue information. We start by establishing a carefully refined dataset based on MovieNet by dissecting movies into hierarchical layers and randomly permuting the orders. Besides benchmarking the MoviePuzzle with prior arts on movie understanding, we devise a Hierarchical Contrastive Movie Clustering (HCMC) model that considers the underlying structure and visual semantic orders for movie reordering. Specifically, through a pairwise and contrastive learning approach, we train models to predict the correct order of each layer. This equips them with the knack for deciphering the visual narrative structure of movies and handling the disorder lurking in video data. Experiments show that our approach outperforms existing state-of-the-art methods on the \MoviePuzzle benchmark, underscoring its efficacy.
Decentralized Learning Dynamics in the Gossip Model
Jun 14, 2023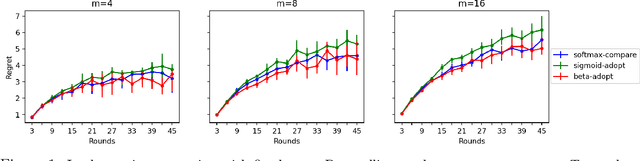
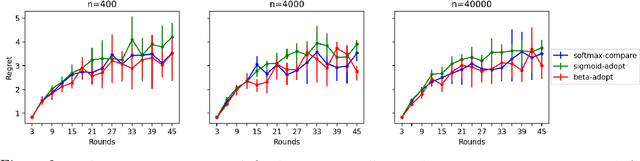
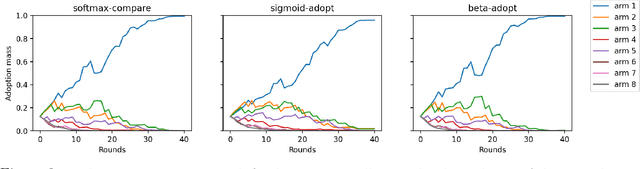
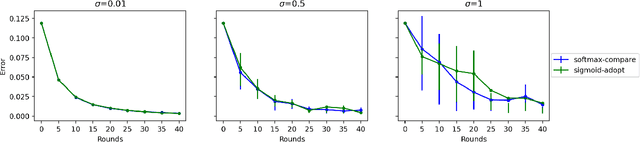
We study a distributed multi-armed bandit setting among a population of $n$ memory-constrained nodes in the gossip model: at each round, every node locally adopts one of $m$ arms, observes a reward drawn from the arm's (adversarially chosen) distribution, and then communicates with a randomly sampled neighbor, exchanging information to determine its policy in the next round. We introduce and analyze several families of dynamics for this task that are decentralized: each node's decision is entirely local and depends only on its most recently obtained reward and that of the neighbor it sampled. We show a connection between the global evolution of these decentralized dynamics with a certain class of "zero-sum" multiplicative weight update algorithms, and we develop a general framework for analyzing the population-level regret of these natural protocols. Using this framework, we derive sublinear regret bounds under a wide range of parameter regimes (i.e., the size of the population and number of arms) for both the stationary reward setting (where the mean of each arm's distribution is fixed over time) and the adversarial reward setting (where means can vary over time). Further, we show that these protocols can approximately optimize convex functions over the simplex when the reward distributions are generated from a stochastic gradient oracle.
CLIPXPlore: Coupled CLIP and Shape Spaces for 3D Shape Exploration
Jun 14, 2023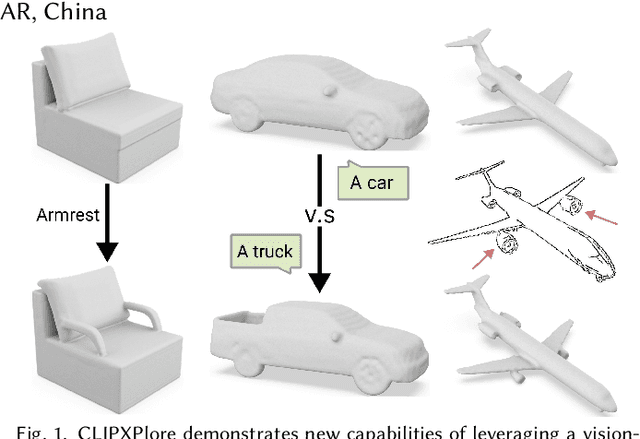
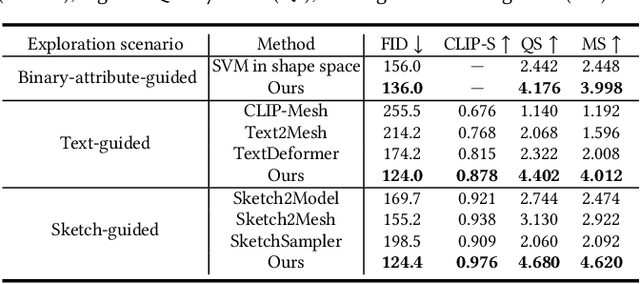
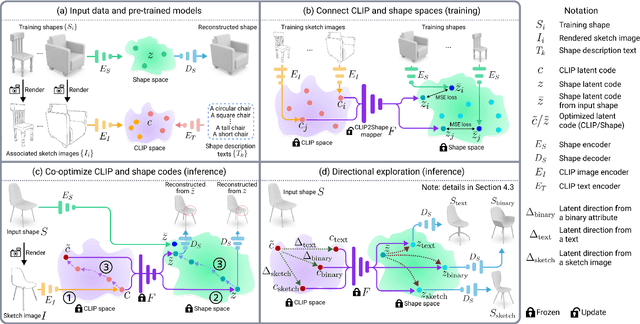

This paper presents CLIPXPlore, a new framework that leverages a vision-language model to guide the exploration of the 3D shape space. Many recent methods have been developed to encode 3D shapes into a learned latent shape space to enable generative design and modeling. Yet, existing methods lack effective exploration mechanisms, despite the rich information. To this end, we propose to leverage CLIP, a powerful pre-trained vision-language model, to aid the shape-space exploration. Our idea is threefold. First, we couple the CLIP and shape spaces by generating paired CLIP and shape codes through sketch images and training a mapper network to connect the two spaces. Second, to explore the space around a given shape, we formulate a co-optimization strategy to search for the CLIP code that better matches the geometry of the shape. Third, we design three exploration modes, binary-attribute-guided, text-guided, and sketch-guided, to locate suitable exploration trajectories in shape space and induce meaningful changes to the shape. We perform a series of experiments to quantitatively and visually compare CLIPXPlore with different baselines in each of the three exploration modes, showing that CLIPXPlore can produce many meaningful exploration results that cannot be achieved by the existing solutions.
Explore In-Context Learning for 3D Point Cloud Understanding
Jun 14, 2023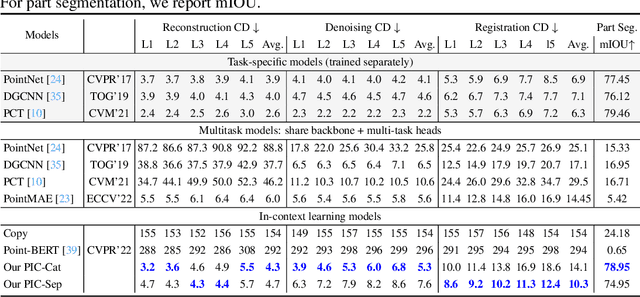
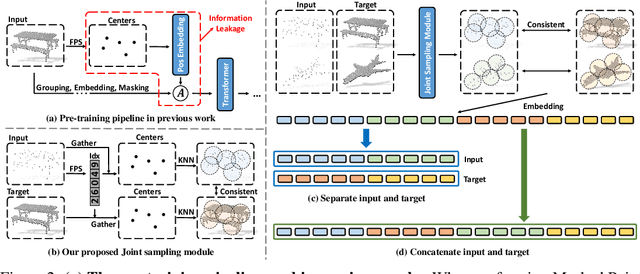
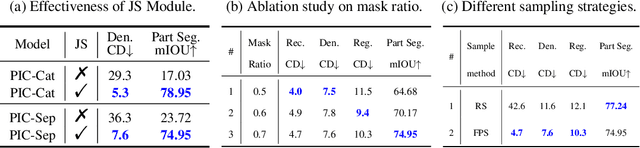
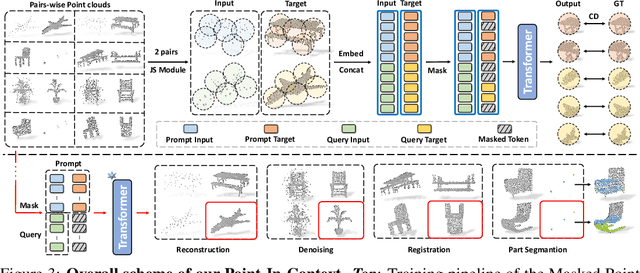
With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks. Meanwhile, in-context learning is still largely unexplored in the 3D point cloud domain. Although masked modeling has been successfully applied for in-context learning in 2D vision, directly extending it to 3D point clouds remains a formidable challenge. In the case of point clouds, the tokens themselves are the point cloud positions (coordinates) that are masked during inference. Moreover, position embedding in previous works may inadvertently introduce information leakage. To address these challenges, we introduce a novel framework, named Point-In-Context, designed especially for in-context learning in 3D point clouds, where both inputs and outputs are modeled as coordinates for each task. Additionally, we propose the Joint Sampling module, carefully designed to work in tandem with the general point sampling operator, effectively resolving the aforementioned technical issues. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks. Furthermore, with a more effective prompt selection strategy, our framework surpasses the results of individually trained models.
Revealing the impact of social circumstances on the selection of cancer therapy through natural language processing of social work notes
Jun 16, 2023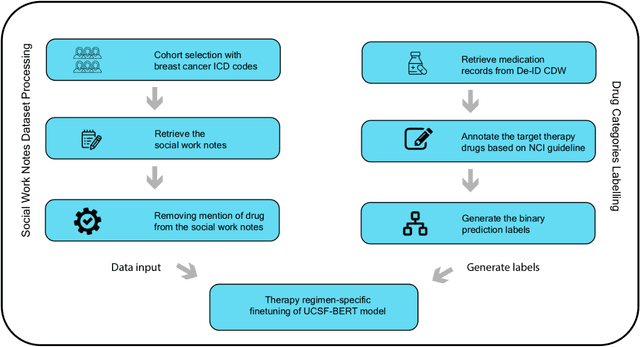
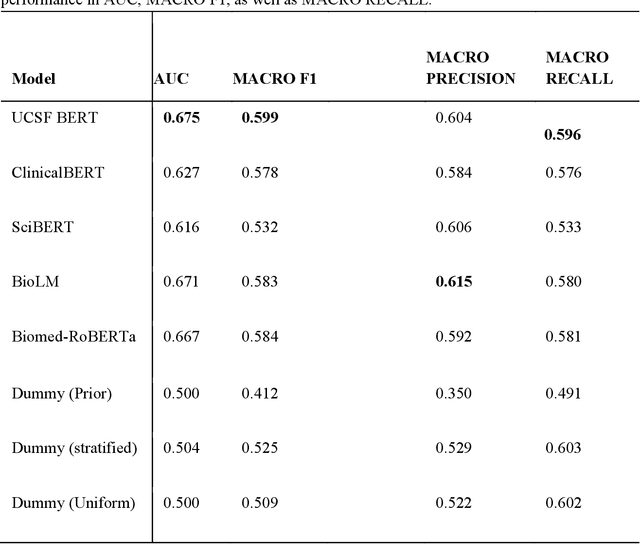
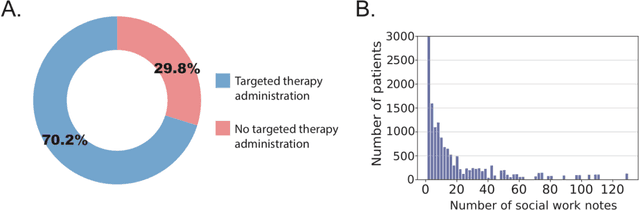
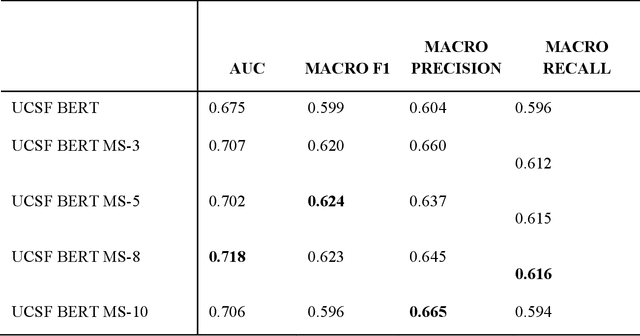
We aimed to investigate the impact of social circumstances on cancer therapy selection using natural language processing to derive insights from social worker documentation. We developed and employed a Bidirectional Encoder Representations from Transformers (BERT) based approach, using a hierarchical multi-step BERT model (BERT-MS) to predict the prescription of targeted cancer therapy to patients based solely on documentation by clinical social workers. Our corpus included free-text clinical social work notes, combined with medication prescription information, for all patients treated for breast cancer. We conducted a feature importance analysis to pinpoint the specific social circumstances that impact cancer therapy selection. Using only social work notes, we consistently predicted the administration of targeted therapies, suggesting systematic differences in treatment selection exist due to non-clinical factors. The UCSF-BERT model, pretrained on clinical text at UCSF, outperformed other publicly available language models with an AUROC of 0.675 and a Macro F1 score of 0.599. The UCSF BERT-MS model, capable of leveraging multiple pieces of notes, surpassed the UCSF-BERT model in both AUROC and Macro-F1. Our feature importance analysis identified several clinically intuitive social determinants of health (SDOH) that potentially contribute to disparities in treatment. Our findings indicate that significant disparities exist among breast cancer patients receiving different types of therapies based on social determinants of health. Social work reports play a crucial role in understanding these disparities in clinical decision-making.
Towards Better Orthogonality Regularization with Disentangled Norm in Training Deep CNNs
Jun 16, 2023
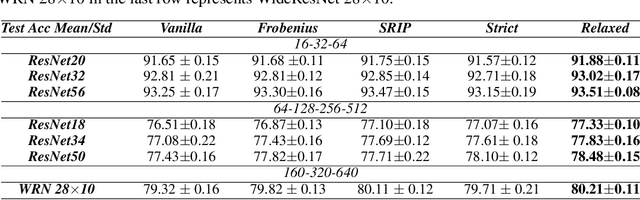
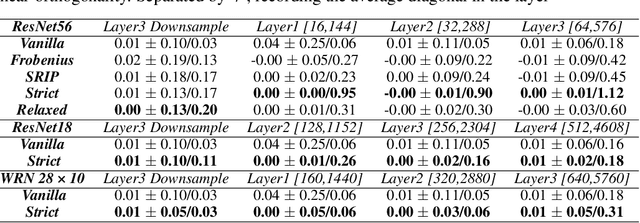
Orthogonality regularization has been developed to prevent deep CNNs from training instability and feature redundancy. Among existing proposals, kernel orthogonality regularization enforces orthogonality by minimizing the residual between the Gram matrix formed by convolutional filters and the orthogonality matrix. We propose a novel measure for achieving better orthogonality among filters, which disentangles diagonal and correlation information from the residual. The model equipped with the measure under the principle of imposing strict orthogonality between filters surpasses previous regularization methods in near-orthogonality. Moreover, we observe the benefits of improved strict filter orthogonality in relatively shallow models, but as model depth increases, the performance gains in models employing strict kernel orthogonality decrease sharply. Furthermore, based on the observation of the potential conflict between strict kernel orthogonality and growing model capacity, we propose a relaxation theory on kernel orthogonality regularization. The relaxed kernel orthogonality achieves enhanced performance on models with increased capacity, shedding light on the burden of strict kernel orthogonality on deep model performance. We conduct extensive experiments with our kernel orthogonality regularization toolkit on ResNet and WideResNet in CIFAR-10 and CIFAR-100. We observe state-of-the-art gains in model performance from the toolkit, which includes both strict orthogonality and relaxed orthogonality regularization, and obtain more robust models with expressive features. These experiments demonstrate the efficacy of our toolkit and subtly provide insights into the often overlooked challenges posed by strict orthogonality, addressing the burden of strict orthogonality on capacity-rich models.
Automatic Deduction Path Learning via Reinforcement Learning with Environmental Correction
Jun 16, 2023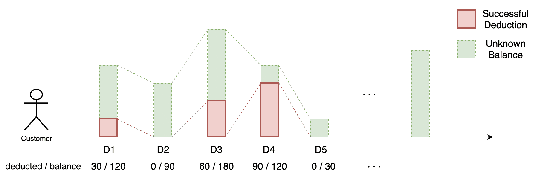

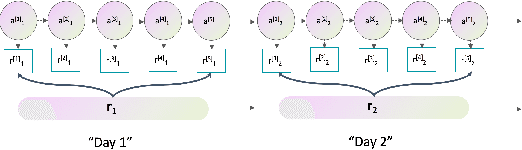

Automatic bill payment is an important part of business operations in fintech companies. The practice of deduction was mainly based on the total amount or heuristic search by dividing the bill into smaller parts to deduct as much as possible. This article proposes an end-to-end approach of automatically learning the optimal deduction paths (deduction amount in order), which reduces the cost of manual path design and maximizes the amount of successful deduction. Specifically, in view of the large search space of the paths and the extreme sparsity of historical successful deduction records, we propose a deep hierarchical reinforcement learning approach which abstracts the action into a two-level hierarchical space: an upper agent that determines the number of steps of deductions each day and a lower agent that decides the amount of deduction at each step. In such a way, the action space is structured via prior knowledge and the exploration space is reduced. Moreover, the inherited information incompleteness of the business makes the environment just partially observable. To be precise, the deducted amounts indicate merely the lower bounds of the available account balance. To this end, we formulate the problem as a partially observable Markov decision problem (POMDP) and employ an environment correction algorithm based on the characteristics of the business. In the world's largest electronic payment business, we have verified the effectiveness of this scheme offline and deployed it online to serve millions of users.
Memory-Constrained Algorithms for Convex Optimization via Recursive Cutting-Planes
Jun 16, 2023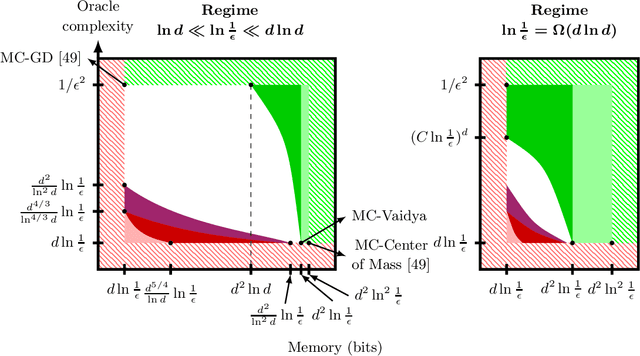
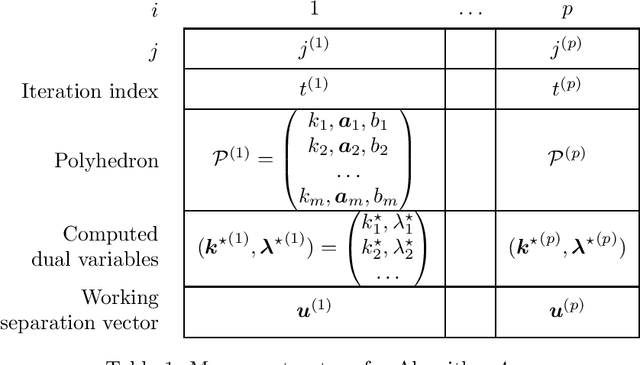

We propose a family of recursive cutting-plane algorithms to solve feasibility problems with constrained memory, which can also be used for first-order convex optimization. Precisely, in order to find a point within a ball of radius $\epsilon$ with a separation oracle in dimension $d$ -- or to minimize $1$-Lipschitz convex functions to accuracy $\epsilon$ over the unit ball -- our algorithms use $\mathcal O(\frac{d^2}{p}\ln \frac{1}{\epsilon})$ bits of memory, and make $\mathcal O((C\frac{d}{p}\ln \frac{1}{\epsilon})^p)$ oracle calls, for some universal constant $C \geq 1$. The family is parametrized by $p\in[d]$ and provides an oracle-complexity/memory trade-off in the sub-polynomial regime $\ln\frac{1}{\epsilon}\gg\ln d$. While several works gave lower-bound trade-offs (impossibility results) -- we explicit here their dependence with $\ln\frac{1}{\epsilon}$, showing that these also hold in any sub-polynomial regime -- to the best of our knowledge this is the first class of algorithms that provides a positive trade-off between gradient descent and cutting-plane methods in any regime with $\epsilon\leq 1/\sqrt d$. The algorithms divide the $d$ variables into $p$ blocks and optimize over blocks sequentially, with approximate separation vectors constructed using a variant of Vaidya's method. In the regime $\epsilon \leq d^{-\Omega(d)}$, our algorithm with $p=d$ achieves the information-theoretic optimal memory usage and improves the oracle-complexity of gradient descent.
Enabling BIM-Driven Robotic Construction Workflows with Closed-Loop Digital Twins
Jun 16, 2023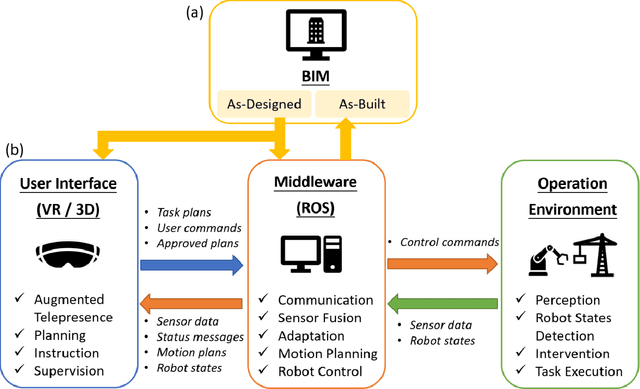
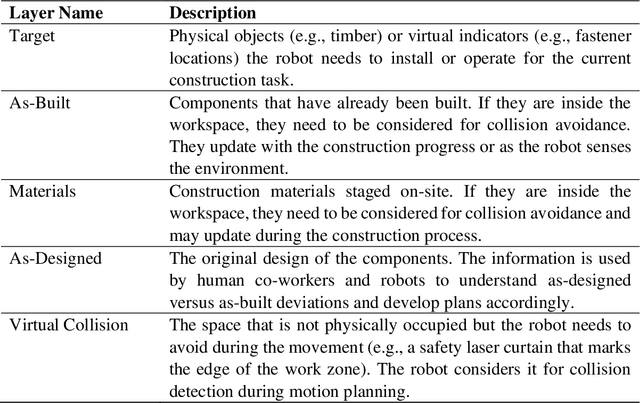
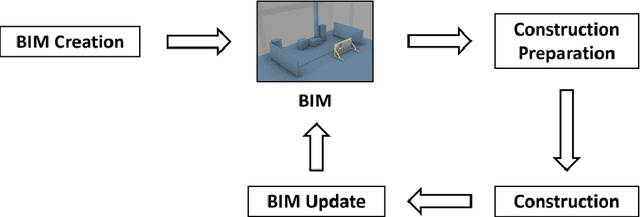

Robots can greatly alleviate physical demands on construction workers while enhancing both the productivity and safety of construction projects. Leveraging a Building Information Model (BIM) offers a natural and promising approach to drive a robotic construction workflow. However, because of uncertainties inherent on construction sites, such as discrepancies between the designed and as-built workpieces, robots cannot solely rely on the BIM to guide field construction work. Human workers are adept at improvising alternative plans with their creativity and experience and thus can assist robots in overcoming uncertainties and performing construction work successfully. This research introduces an interactive closed-loop digital twin system that integrates a BIM into human-robot collaborative construction workflows. The robot is primarily driven by the BIM, but it adaptively adjusts its plan based on actual site conditions while the human co-worker supervises the process. If necessary, the human co-worker intervenes in the robot's plan by changing the task sequence or target position, requesting a new motion plan, or modifying the construction component(s)/material(s) to help the robot navigate uncertainties. To investigate the physical deployment of the system, a drywall installation case study is conducted with an industrial robotic arm in a laboratory. In addition, a block pick-and-place experiment is carried out to evaluate system performance. Integrating the flexibility of human workers and the autonomy and accuracy afforded by the BIM, the system significantly increases the robustness of construction robots in the performance of field construction work.
PEACE: Cross-Platform Hate Speech Detection- A Causality-guided Framework
Jun 15, 2023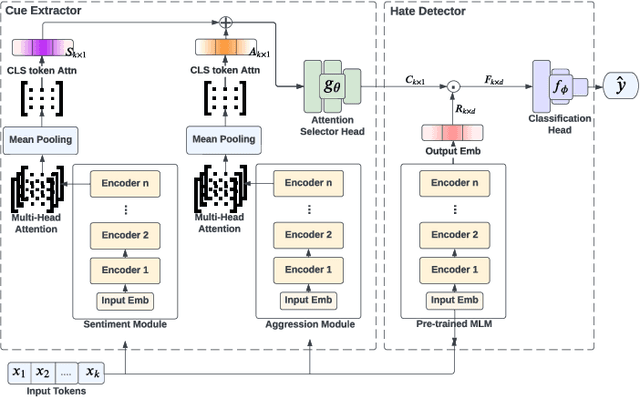
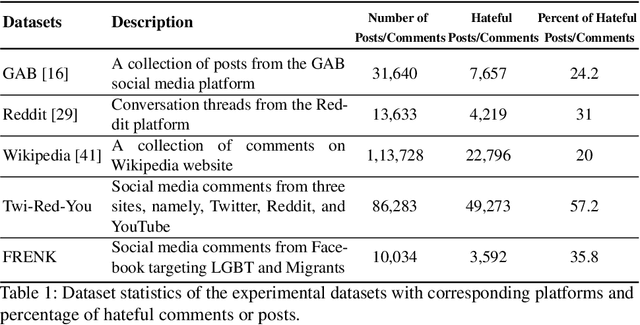
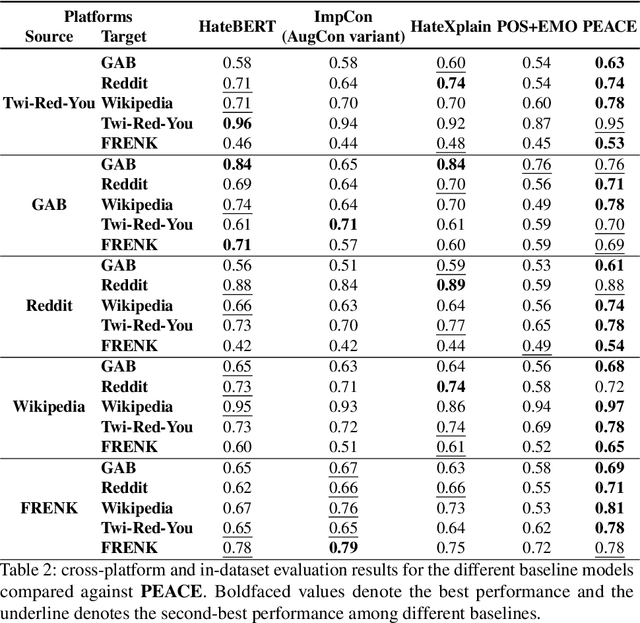
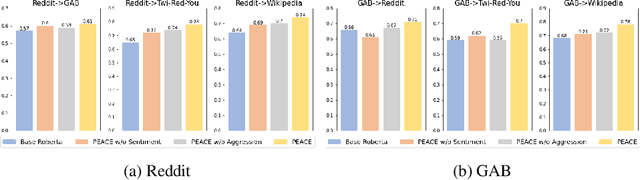
Hate speech detection refers to the task of detecting hateful content that aims at denigrating an individual or a group based on their religion, gender, sexual orientation, or other characteristics. Due to the different policies of the platforms, different groups of people express hate in different ways. Furthermore, due to the lack of labeled data in some platforms it becomes challenging to build hate speech detection models. To this end, we revisit if we can learn a generalizable hate speech detection model for the cross platform setting, where we train the model on the data from one (source) platform and generalize the model across multiple (target) platforms. Existing generalization models rely on linguistic cues or auxiliary information, making them biased towards certain tags or certain kinds of words (e.g., abusive words) on the source platform and thus not applicable to the target platforms. Inspired by social and psychological theories, we endeavor to explore if there exist inherent causal cues that can be leveraged to learn generalizable representations for detecting hate speech across these distribution shifts. To this end, we propose a causality-guided framework, PEACE, that identifies and leverages two intrinsic causal cues omnipresent in hateful content: the overall sentiment and the aggression in the text. We conduct extensive experiments across multiple platforms (representing the distribution shift) showing if causal cues can help cross-platform generalization.