 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Images in Language Space: Exploring the Suitability of Large Language Models for Vision & Language Tasks
May 23, 2023
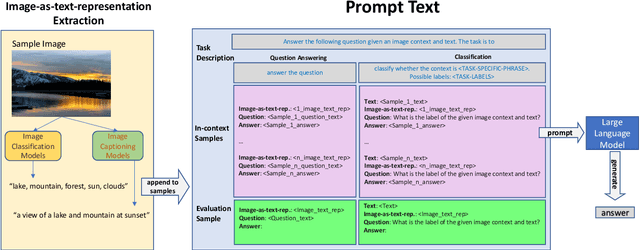
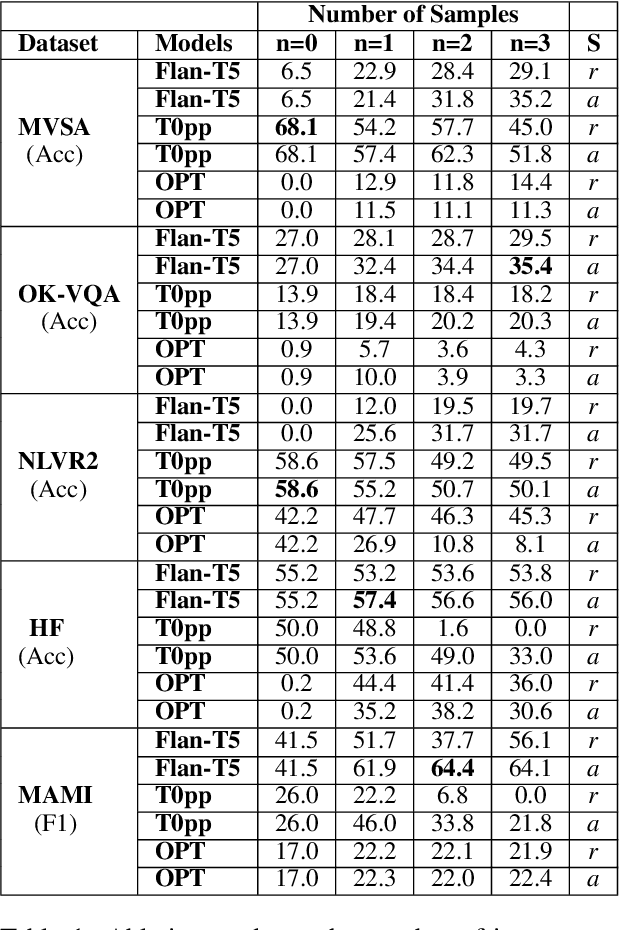
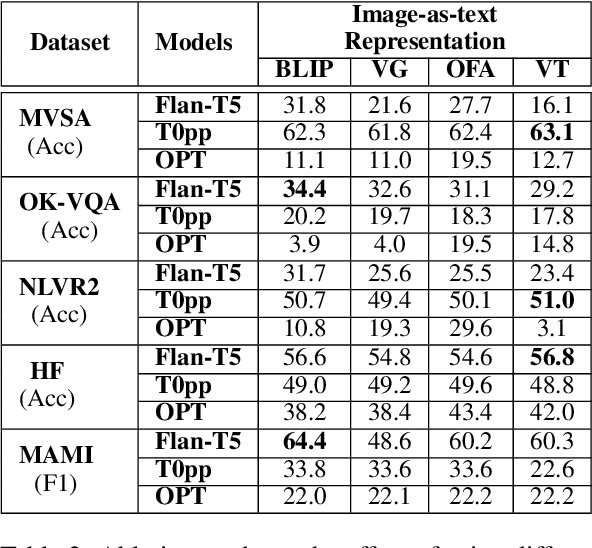
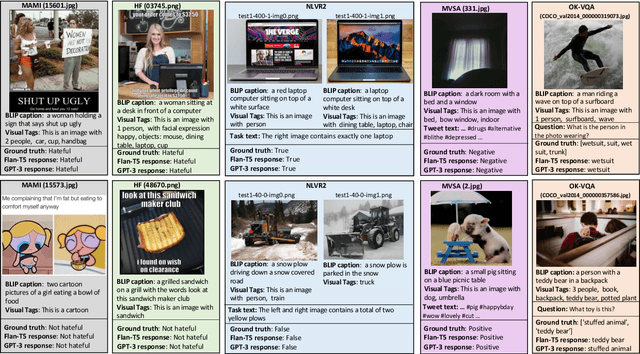
Large language models have demonstrated robust performance on various language tasks using zero-shot or few-shot learning paradigms. While being actively researched, multimodal models that can additionally handle images as input have yet to catch up in size and generality with language-only models. In this work, we ask whether language-only models can be utilised for tasks that require visual input -- but also, as we argue, often require a strong reasoning component. Similar to some recent related work, we make visual information accessible to the language model using separate verbalisation models. Specifically, we investigate the performance of open-source, open-access language models against GPT-3 on five vision-language tasks when given textually-encoded visual information. Our results suggest that language models are effective for solving vision-language tasks even with limited samples. This approach also enhances the interpretability of a model's output by providing a means of tracing the output back through the verbalised image content.
BEDRF: Bidirectional Edge Diffraction Response Function for Interactive Sound Propagation
Jun 03, 2023
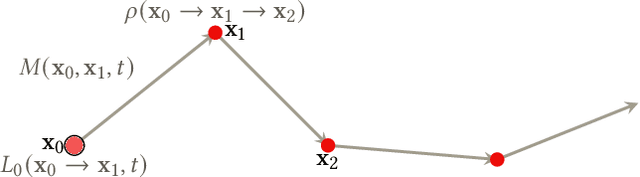
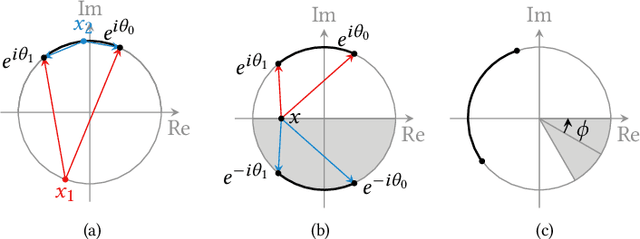
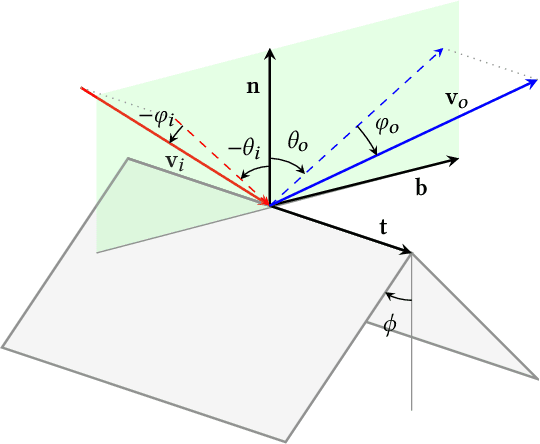
We introduce bidirectional edge diffraction response function (BEDRF), a new approach to model wave diffraction around edges with path tracing. The diffraction part of the wave is expressed as an integration on path space, and the wave-edge interaction is expressed using only the localized information around points on the edge similar to a bidirectional scattering distribution function (BSDF) for visual rendering. For an infinite single wedge, our model generates the same result as the analytic solution. Our approach can be easily integrated into interactive geometric sound propagation algorithms that use path tracing to compute specular and diffuse reflections. Our resulting propagation algorithm can approximate complex wave propagation phenomena involving high-order diffraction, and is able to handle dynamic, deformable objects and moving sources and listeners. We highlight the performance of our approach in different scenarios to generate smooth auralization.
DataAI-6G: A System Parameters Configurable Channel Dataset for AI-6G Research
Jun 03, 2023
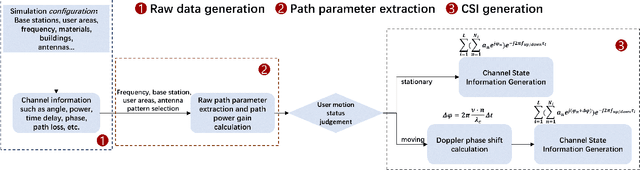
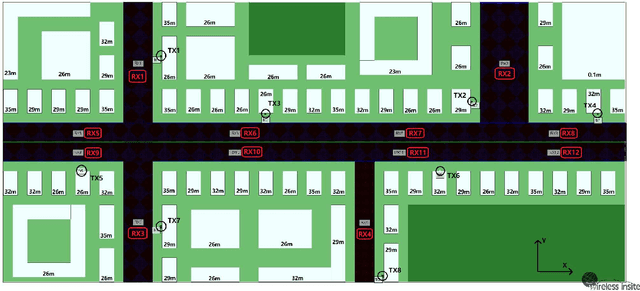
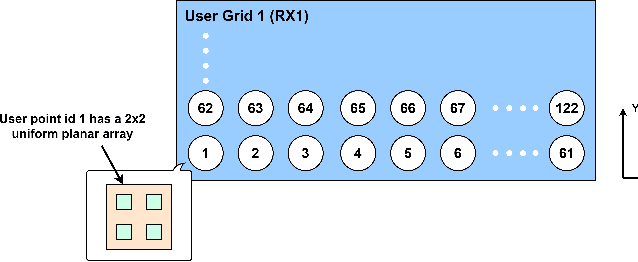
With the acceleration of the commercialization of fifth generation (5G) mobile communication technology and the research for 6G communication systems, the communication system has the characteristics of high frequency, multi-band, high speed movement of users and large antenna array. These bring many difficulties to obtain accurate channel state information (CSI), which makes the performance of traditional communication methods be greatly restricted. Therefore, there has been a lot of interest in using artificial intelligence (AI) instead of traditional methods to improve performance. A common and accurate dataset is essential for the research of AI communication. However, the common datasets nowadays still lack some important features, such as mobile features, spatial non-stationary features etc. To address these issues, we give a dataset for future 6G communication. In this dataset, we address these issues with specific simulation methods and accompanying code processing.
Privacy in Speech Technology
May 09, 2023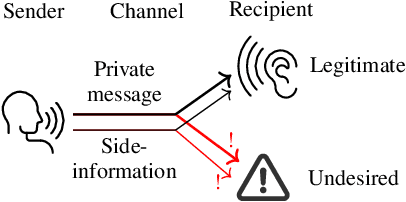
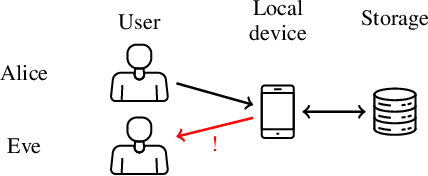
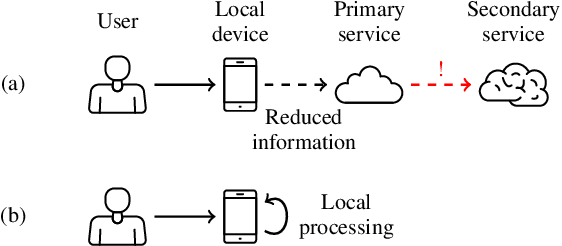
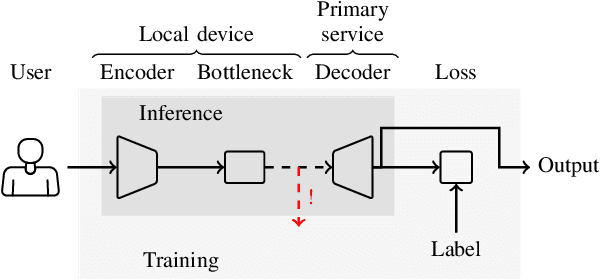
Speech technology for communication, accessing information and services has rapidly improved in quality. It is convenient and appealing because speech is the primary mode of communication for humans. Such technology however also presents proven threats to privacy. Speech is a tool for communication and it will thus inherently contain private information. Importantly, it however also contains a wealth of side information, such as information related to health, emotions, affiliations, and relationships, all of which are private. Exposing such private information can lead to serious threats such as price gouging, harassment, extortion, and stalking. This paper is a tutorial on privacy issues related to speech technology, modeling their threats, approaches for protecting users' privacy, measuring the performance of privacy-protecting methods, perception of privacy as well as societal and legal consequences. In addition to a tutorial overview, it also presents lines for further development where improvements are most urgently needed.
RETA-LLM: A Retrieval-Augmented Large Language Model Toolkit
Jun 08, 2023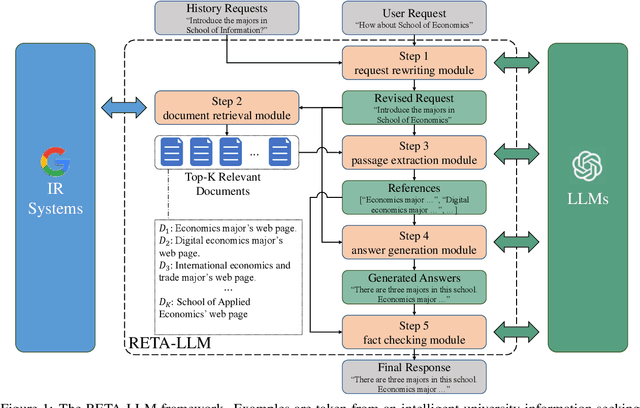
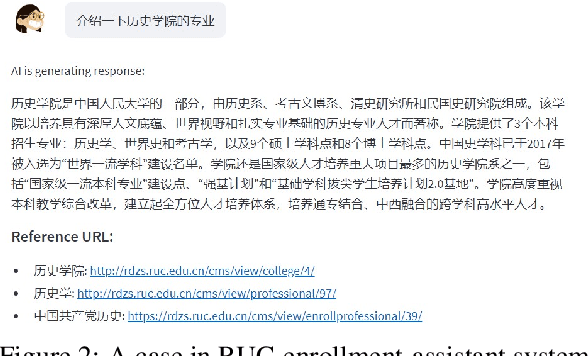
Although Large Language Models (LLMs) have demonstrated extraordinary capabilities in many domains, they still have a tendency to hallucinate and generate fictitious responses to user requests. This problem can be alleviated by augmenting LLMs with information retrieval (IR) systems (also known as retrieval-augmented LLMs). Applying this strategy, LLMs can generate more factual texts in response to user input according to the relevant content retrieved by IR systems from external corpora as references. In addition, by incorporating external knowledge, retrieval-augmented LLMs can answer in-domain questions that cannot be answered by solely relying on the world knowledge stored in parameters. To support research in this area and facilitate the development of retrieval-augmented LLM systems, we develop RETA-LLM, a {RET}reival-{A}ugmented LLM toolkit. In RETA-LLM, we create a complete pipeline to help researchers and users build their customized in-domain LLM-based systems. Compared with previous retrieval-augmented LLM systems, RETA-LLM provides more plug-and-play modules to support better interaction between IR systems and LLMs, including {request rewriting, document retrieval, passage extraction, answer generation, and fact checking} modules. Our toolkit is publicly available at https://github.com/RUC-GSAI/YuLan-IR/tree/main/RETA-LLM.
CTRL: Connect Tabular and Language Model for CTR Prediction
Jun 08, 2023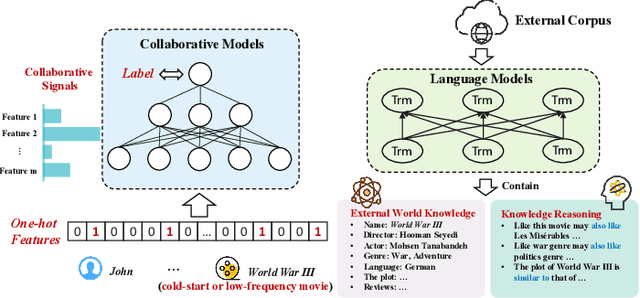

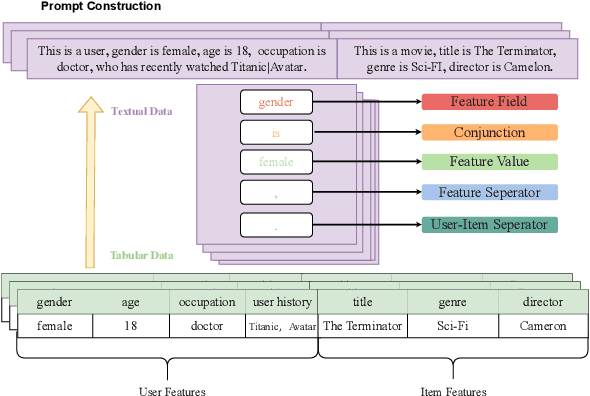
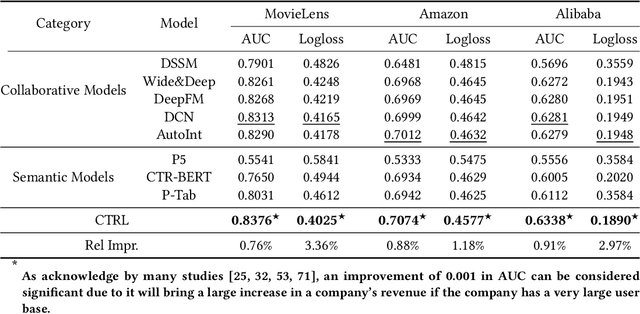
Traditional click-through rate (CTR) prediction models convert the tabular data into one-hot vectors and leverage the collaborative relations among features for inferring user's preference over items. This modeling paradigm discards the essential semantic information. Though some recent works like P5 and M6-Rec have explored the potential of using Pre-trained Language Models (PLMs) to extract semantic signals for CTR prediction, they are computationally expensive and suffer from low efficiency. Besides, the beneficial collaborative relations are not considered, hindering the recommendation performance. To solve these problems, in this paper, we propose a novel framework \textbf{CTRL}, which is industrial friendly and model-agnostic with high training and inference efficiency. Specifically, the original tabular data is first converted into textual data. Both tabular data and converted textual data are regarded as two different modalities and are separately fed into the collaborative CTR model and pre-trained language model. A cross-modal knowledge alignment procedure is performed to fine-grained align and integrate the collaborative and semantic signals, and the lightweight collaborative model can be deployed online for efficient serving after fine-tuned with supervised signals. Experimental results on three public datasets show that CTRL outperforms the SOTA CTR models significantly. Moreover, we further verify its effectiveness on a large-scale industrial recommender system.
Multi-Modal Classifiers for Open-Vocabulary Object Detection
Jun 08, 2023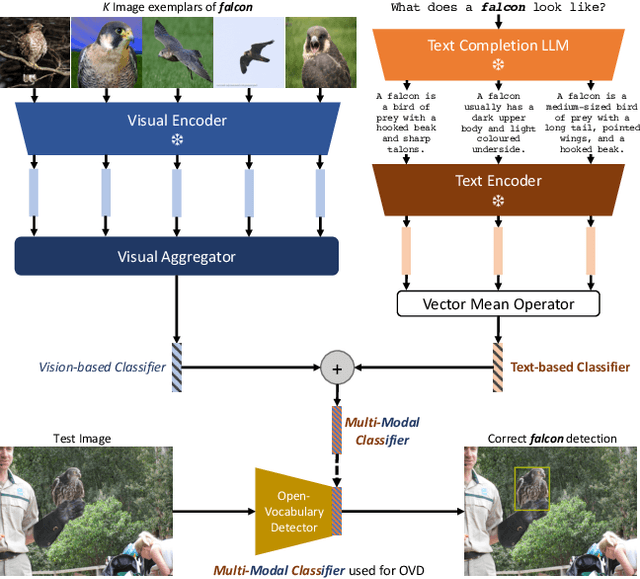
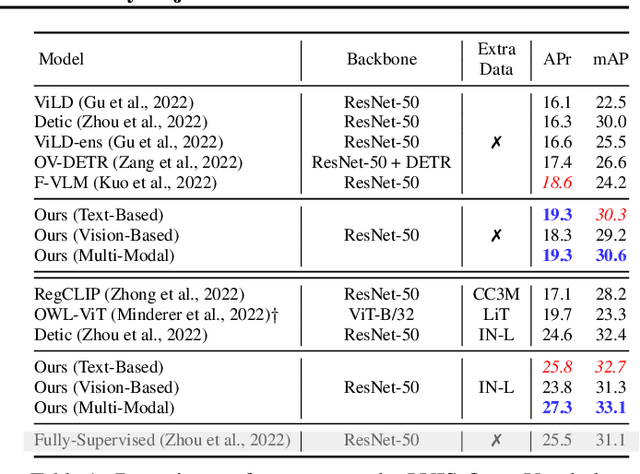
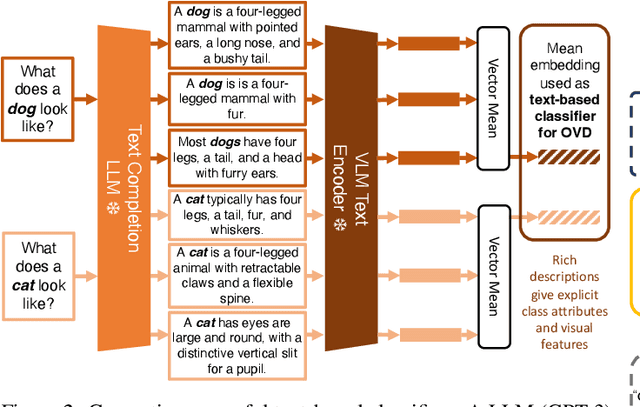
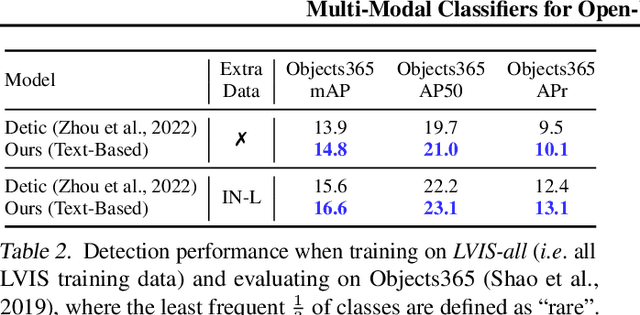
The goal of this paper is open-vocabulary object detection (OVOD) $\unicode{x2013}$ building a model that can detect objects beyond the set of categories seen at training, thus enabling the user to specify categories of interest at inference without the need for model retraining. We adopt a standard two-stage object detector architecture, and explore three ways for specifying novel categories: via language descriptions, via image exemplars, or via a combination of the two. We make three contributions: first, we prompt a large language model (LLM) to generate informative language descriptions for object classes, and construct powerful text-based classifiers; second, we employ a visual aggregator on image exemplars that can ingest any number of images as input, forming vision-based classifiers; and third, we provide a simple method to fuse information from language descriptions and image exemplars, yielding a multi-modal classifier. When evaluating on the challenging LVIS open-vocabulary benchmark we demonstrate that: (i) our text-based classifiers outperform all previous OVOD works; (ii) our vision-based classifiers perform as well as text-based classifiers in prior work; (iii) using multi-modal classifiers perform better than either modality alone; and finally, (iv) our text-based and multi-modal classifiers yield better performance than a fully-supervised detector.
MIMIC-IT: Multi-Modal In-Context Instruction Tuning
Jun 08, 2023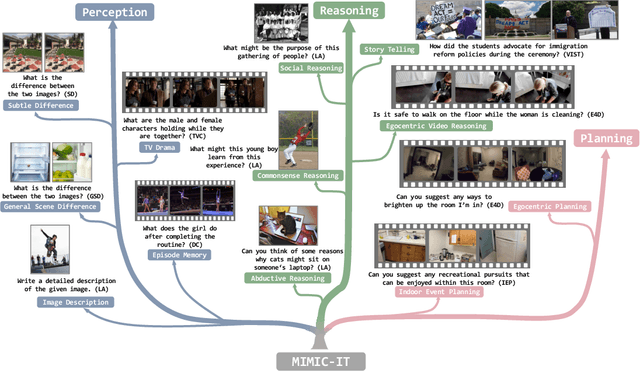
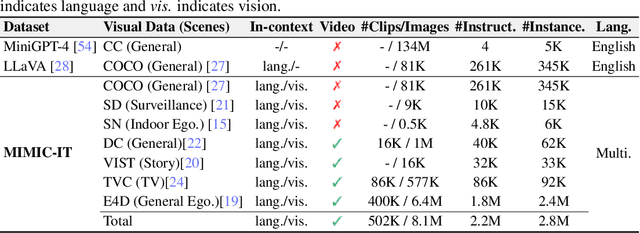

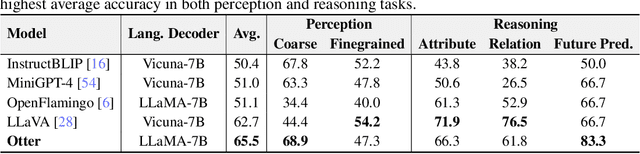
High-quality instructions and responses are essential for the zero-shot performance of large language models on interactive natural language tasks. For interactive vision-language tasks involving intricate visual scenes, a large quantity of diverse and creative instruction-response pairs should be imperative to tune vision-language models (VLMs). Nevertheless, the current availability of vision-language instruction-response pairs in terms of quantity, diversity, and creativity remains limited, posing challenges to the generalization of interactive VLMs. Here we present MultI-Modal In-Context Instruction Tuning (MIMIC-IT), a dataset comprising 2.8 million multimodal instruction-response pairs, with 2.2 million unique instructions derived from images and videos. Each pair is accompanied by multi-modal in-context information, forming conversational contexts aimed at empowering VLMs in perception, reasoning, and planning. The instruction-response collection process, dubbed as Syphus, is scaled using an automatic annotation pipeline that combines human expertise with GPT's capabilities. Using the MIMIC-IT dataset, we train a large VLM named Otter. Based on extensive evaluations conducted on vision-language benchmarks, it has been observed that Otter demonstrates remarkable proficiency in multi-modal perception, reasoning, and in-context learning. Human evaluation reveals it effectively aligns with the user's intentions. We release the MIMIC-IT dataset, instruction-response collection pipeline, benchmarks, and the Otter model.
Neuro-Symbolic Approaches for Context-Aware Human Activity Recognition
Jun 08, 2023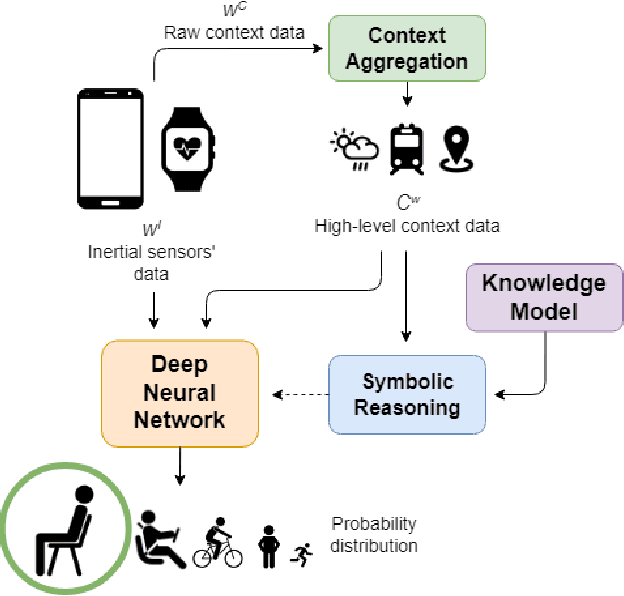
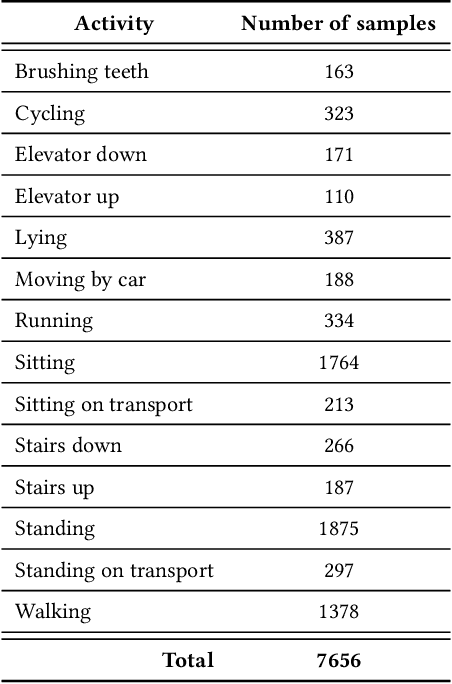
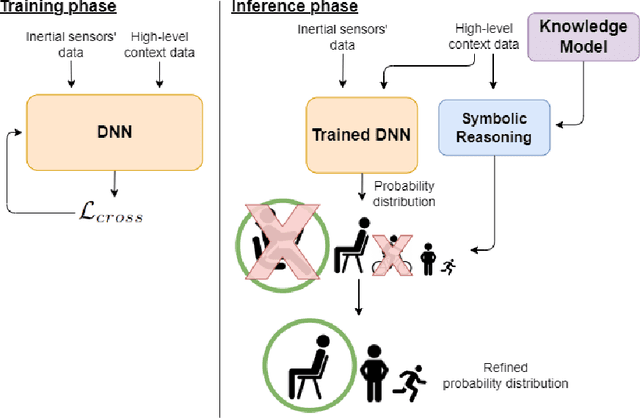
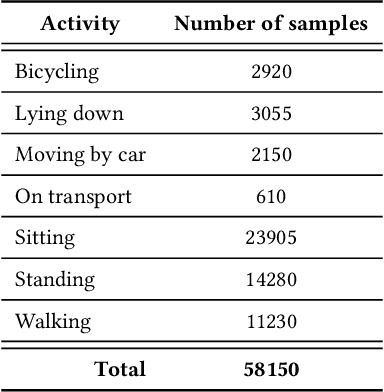
Deep Learning models are a standard solution for sensor-based Human Activity Recognition (HAR), but their deployment is often limited by labeled data scarcity and models' opacity. Neuro-Symbolic AI (NeSy) provides an interesting research direction to mitigate these issues by infusing knowledge about context information into HAR deep learning classifiers. However, existing NeSy methods for context-aware HAR require computationally expensive symbolic reasoners during classification, making them less suitable for deployment on resource-constrained devices (e.g., mobile devices). Additionally, NeSy approaches for context-aware HAR have never been evaluated on in-the-wild datasets, and their generalization capabilities in real-world scenarios are questionable. In this work, we propose a novel approach based on a semantic loss function that infuses knowledge constraints in the HAR model during the training phase, avoiding symbolic reasoning during classification. Our results on scripted and in-the-wild datasets show the impact of different semantic loss functions in outperforming a purely data-driven model. We also compare our solution with existing NeSy methods and analyze each approach's strengths and weaknesses. Our semantic loss remains the only NeSy solution that can be deployed as a single DNN without the need for symbolic reasoning modules, reaching recognition rates close (and better in some cases) to existing approaches.
TopoMask: Instance-Mask-Based Formulation for the Road Topology Problem via Transformer-Based Architecture
Jun 08, 2023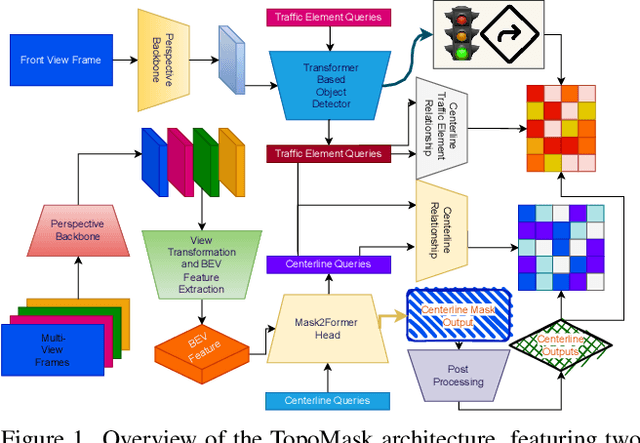



Driving scene understanding task involves detecting static elements such as lanes, traffic signs, and traffic lights, and their relationships with each other. To facilitate the development of comprehensive scene understanding solutions using multiple camera views, a new dataset called Road Genome (OpenLane-V2) has been released. This dataset allows for the exploration of complex road connections and situations where lane markings may be absent. Instead of using traditional lane markings, the lanes in this dataset are represented by centerlines, which offer a more suitable representation of lanes and their connections. In this study, we have introduced a new approach called TopoMask for predicting centerlines in road topology. Unlike existing approaches in the literature that rely on keypoints or parametric methods, TopoMask utilizes an instance-mask based formulation with a transformer-based architecture and, in order to enrich the mask instances with flow information, a direction label representation is proposed. TopoMask have ranked 4th in the OpenLane-V2 Score (OLS) and ranked 2nd in the F1 score of centerline prediction in OpenLane Topology Challenge 2023. In comparison to the current state-of-the-art method, TopoNet, the proposed method has achieved similar performance in Frechet-based lane detection and outperformed TopoNet in Chamfer-based lane detection without utilizing its scene graph neural network.