 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Assessing the Effectiveness of GPT-3 in Detecting False Political Statements: A Case Study on the LIAR Dataset
Jun 14, 2023
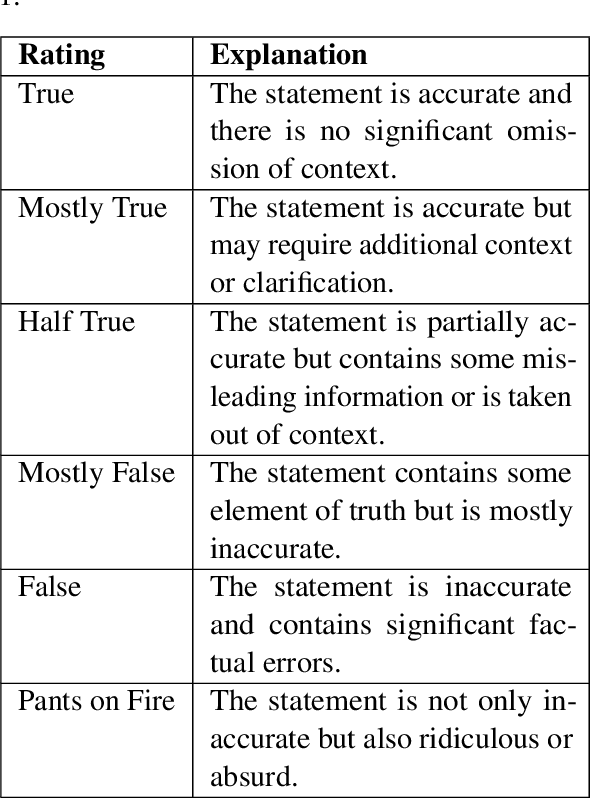
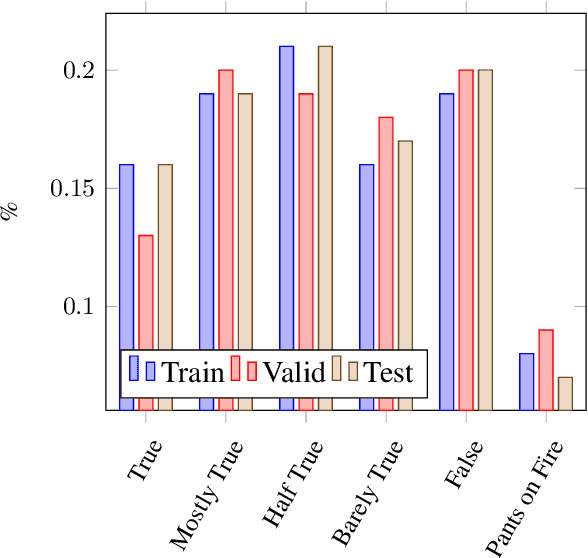


The detection of political fake statements is crucial for maintaining information integrity and preventing the spread of misinformation in society. Historically, state-of-the-art machine learning models employed various methods for detecting deceptive statements. These methods include the use of metadata (W. Wang et al., 2018), n-grams analysis (Singh et al., 2021), and linguistic (Wu et al., 2022) and stylometric (Islam et al., 2020) features. Recent advancements in large language models, such as GPT-3 (Brown et al., 2020) have achieved state-of-the-art performance on a wide range of tasks. In this study, we conducted experiments with GPT-3 on the LIAR dataset (W. Wang et al., 2018) and achieved higher accuracy than state-of-the-art models without using any additional meta or linguistic features. Additionally, we experimented with zero-shot learning using a carefully designed prompt and achieved near state-of-the-art performance. An advantage of this approach is that the model provided evidence for its decision, which adds transparency to the model's decision-making and offers a chance for users to verify the validity of the evidence provided.
On the Role of Morphological Information for Contextual Lemmatization
Feb 01, 2023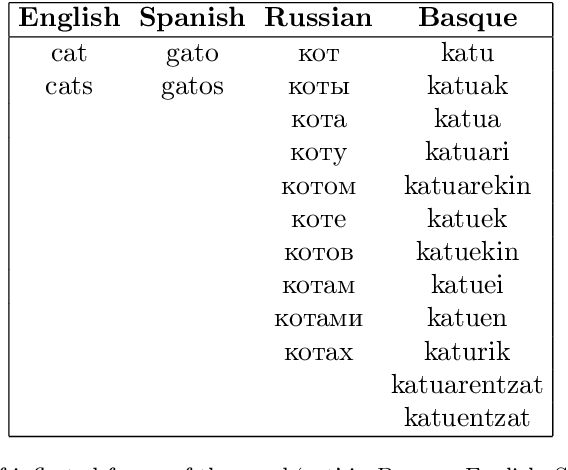

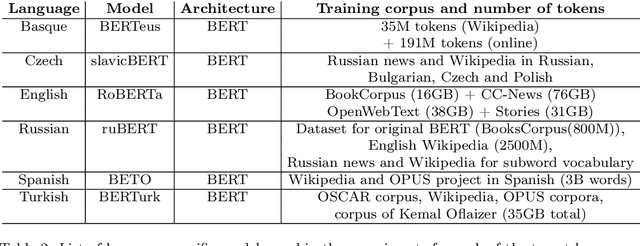
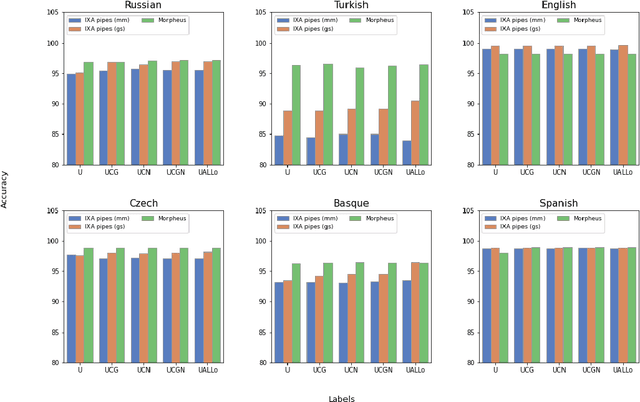
Lemmatization is a Natural Language Processing (NLP) task which consists of producing, from a given inflected word, its canonical form or lemma. Lemmatization is one of the basic tasks that facilitate downstream NLP applications, and is of particular importance for high-inflected languages. Given that the process to obtain a lemma from an inflected word can be explained by looking at its morphosyntactic category, including fine-grained morphosyntactic information to train contextual lemmatizers has become common practice, without analyzing whether that is the optimum in terms of downstream performance. Thus, in this paper we empirically investigate the role of morphological information to develop contextual lemmatizers in six languages within a varied spectrum of morphological complexity: Basque, Turkish, Russian, Czech, Spanish and English. Furthermore, and unlike the vast majority of previous work, we also evaluate lemmatizers in out-of-domain settings, which constitutes, after all, their most common application use. The results of our study are rather surprising: (i) providing lemmatizers with fine-grained morphological features during training is not that beneficial, not even for agglutinative languages; (ii) in fact, modern contextual word representations seem to implicitly encode enough morphological information to obtain good contextual lemmatizers without seeing any explicit morphological signal; (iii) the best lemmatizers out-of-domain are those using simple UPOS tags or those trained without morphology; (iv) current evaluation practices for lemmatization are not adequate to clearly discriminate between models.
WikiChat: A Few-Shot LLM-Based Chatbot Grounded with Wikipedia
May 23, 2023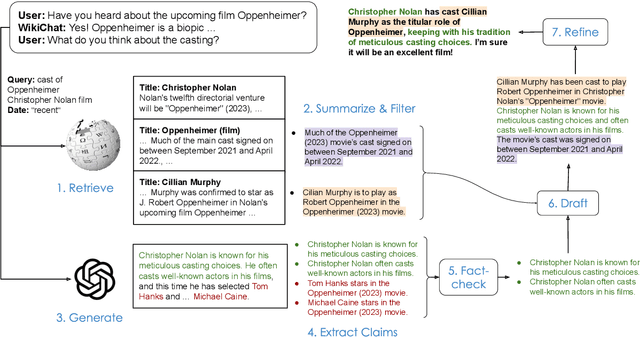
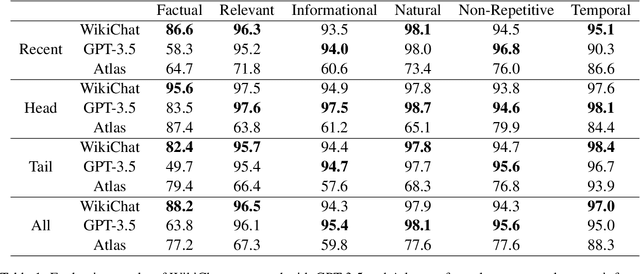


Despite recent advances in Large Language Models (LLMs), users still cannot trust the information provided in their responses. LLMs cannot speak accurately about events that occurred after their training, which are often topics of great interest to users, and, as we show in this paper, they are highly prone to hallucination when talking about less popular (tail) topics. This paper presents WikiChat, a few-shot LLM-based chatbot that is grounded with live information from Wikipedia. Through many iterations of experimentation, we have crafte a pipeline based on information retrieval that (1) uses LLMs to suggest interesting and relevant facts that are individually verified against Wikipedia, (2) retrieves additional up-to-date information, and (3) composes coherent and engaging time-aware responses. We propose a novel hybrid human-and-LLM evaluation methodology to analyze the factuality and conversationality of LLM-based chatbots. We focus on evaluating important but previously neglected issues such as conversing about recent and tail topics. We evaluate WikiChat against strong fine-tuned and LLM-based baselines across a diverse set of conversation topics. We find that WikiChat outperforms all baselines in terms of the factual accuracy of its claims, by up to 12.1%, 28.3% and 32.7% on head, recent and tail topics, while matching GPT-3.5 in terms of providing natural, relevant, non-repetitive and informational responses.
Graph Ladling: Shockingly Simple Parallel GNN Training without Intermediate Communication
Jun 18, 2023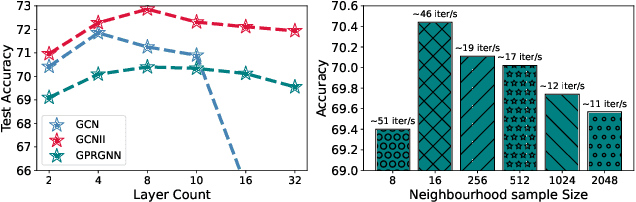

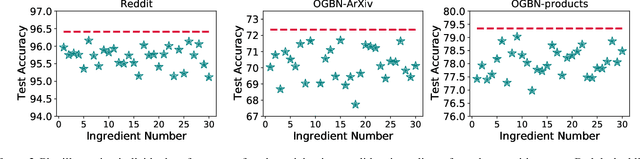
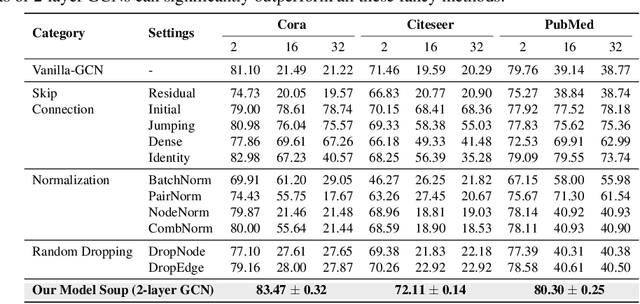
Graphs are omnipresent and GNNs are a powerful family of neural networks for learning over graphs. Despite their popularity, scaling GNNs either by deepening or widening suffers from prevalent issues of unhealthy gradients, over-smoothening, information squashing, which often lead to sub-standard performance. In this work, we are interested in exploring a principled way to scale GNNs capacity without deepening or widening, which can improve its performance across multiple small and large graphs. Motivated by the recent intriguing phenomenon of model soups, which suggest that fine-tuned weights of multiple large-language pre-trained models can be merged to a better minima, we argue to exploit the fundamentals of model soups to mitigate the aforementioned issues of memory bottleneck and trainability during GNNs scaling. More specifically, we propose not to deepen or widen current GNNs, but instead present a data-centric perspective of model soups tailored for GNNs, i.e., to build powerful GNNs by dividing giant graph data to build independently and parallelly trained multiple comparatively weaker GNNs without any intermediate communication, and combining their strength using a greedy interpolation soup procedure to achieve state-of-the-art performance. Moreover, we provide a wide variety of model soup preparation techniques by leveraging state-of-the-art graph sampling and graph partitioning approaches that can handle large graph data structures. Our extensive experiments across many real-world small and large graphs, illustrate the effectiveness of our approach and point towards a promising orthogonal direction for GNN scaling. Codes are available at: \url{https://github.com/VITA-Group/graph_ladling}.
DEYOv2: Rank Feature with Greedy Matching for End-to-End Object Detection
Jun 15, 2023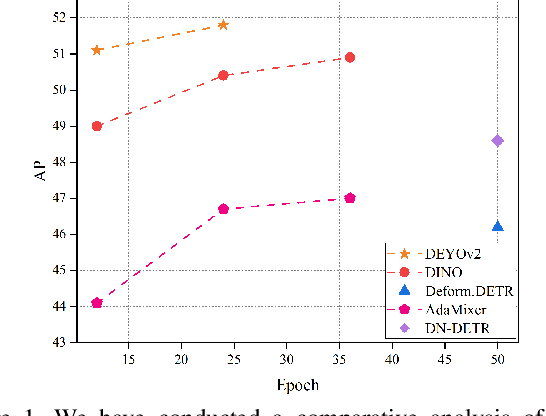
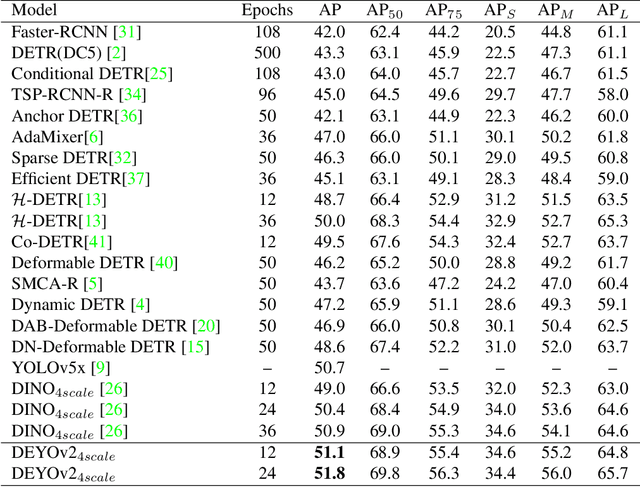
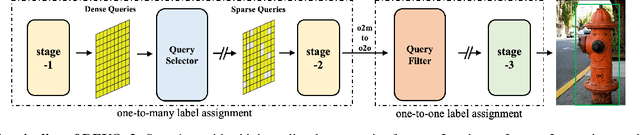
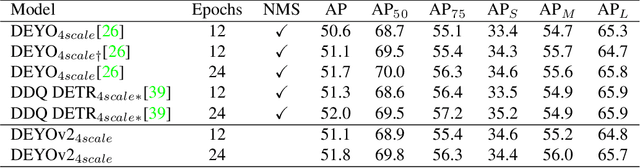
This paper presents a novel object detector called DEYOv2, an improved version of the first-generation DEYO (DETR with YOLO) model. DEYOv2, similar to its predecessor, DEYOv2 employs a progressive reasoning approach to accelerate model training and enhance performance. The study delves into the limitations of one-to-one matching in optimization and proposes solutions to effectively address the issue, such as Rank Feature and Greedy Matching. This approach enables the third stage of DEYOv2 to maximize information acquisition from the first and second stages without needing NMS, achieving end-to-end optimization. By combining dense queries, sparse queries, one-to-many matching, and one-to-one matching, DEYOv2 leverages the advantages of each method. It outperforms all existing query-based end-to-end detectors under the same settings. When using ResNet-50 as the backbone and multi-scale features on the COCO dataset, DEYOv2 achieves 51.1 AP and 51.8 AP in 12 and 24 epochs, respectively. Compared to the end-to-end model DINO, DEYOv2 provides significant performance gains of 2.1 AP and 1.4 AP in the two epoch settings. To the best of our knowledge, DEYOv2 is the first fully end-to-end object detector that combines the respective strengths of classical detectors and query-based detectors.
A9 Intersection Dataset: All You Need for Urban 3D Camera-LiDAR Roadside Perception
Jun 15, 2023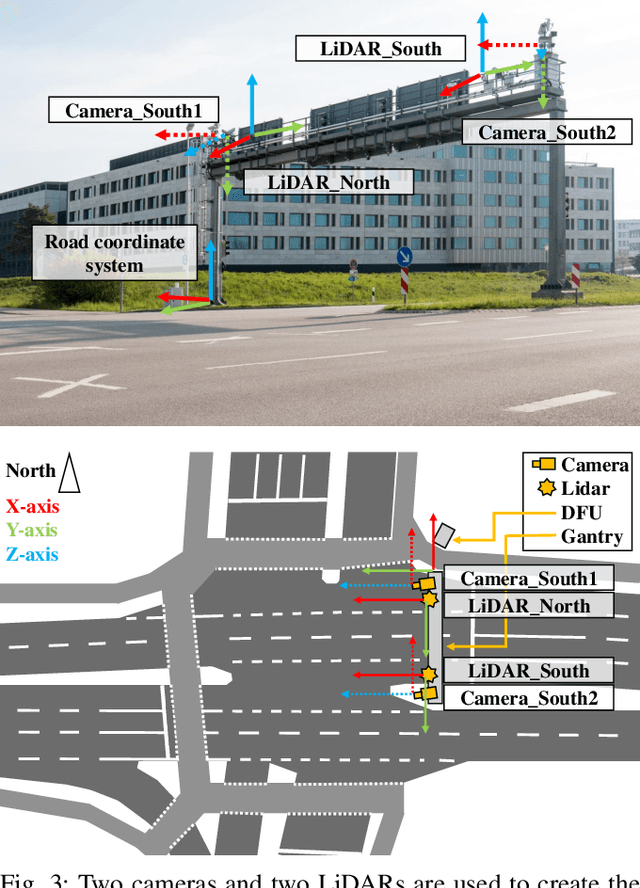
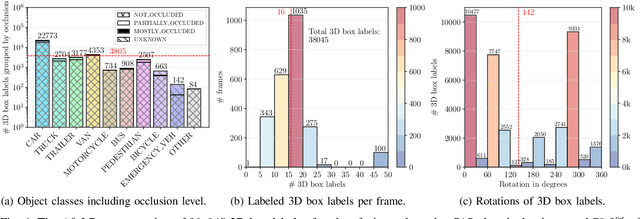
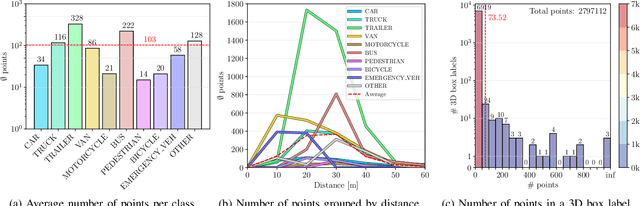
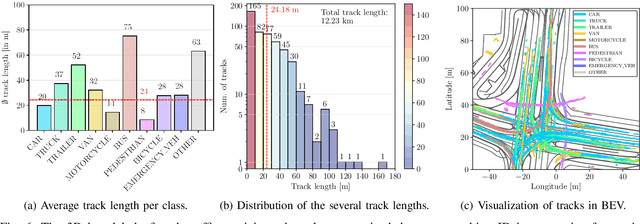
Intelligent Transportation Systems (ITS) allow a drastic expansion of the visibility range and decrease occlusions for autonomous driving. To obtain accurate detections, detailed labeled sensor data for training is required. Unfortunately, high-quality 3D labels of LiDAR point clouds from the infrastructure perspective of an intersection are still rare. Therefore, we provide the A9 Intersection Dataset, which consists of labeled LiDAR point clouds and synchronized camera images. Here, we recorded the sensor output from two roadside cameras and LiDARs mounted on intersection gantry bridges. The point clouds were labeled in 3D by experienced annotators. Furthermore, we provide calibration data between all sensors, which allow the projection of the 3D labels into the camera images and an accurate data fusion. Our dataset consists of 4.8k images and point clouds with more than 57.4k manually labeled 3D boxes. With ten object classes, it has a high diversity of road users in complex driving maneuvers, such as left and right turns, overtaking, and U-turns. In experiments, we provided multiple baselines for the perception tasks. Overall, our dataset is a valuable contribution to the scientific community to perform complex 3D camera-LiDAR roadside perception tasks. Find data, code, and more information at https://a9-dataset.com.
Retrieving-to-Answer: Zero-Shot Video Question Answering with Frozen Large Language Models
Jun 15, 2023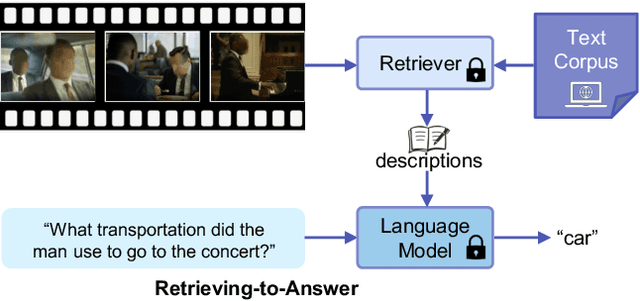
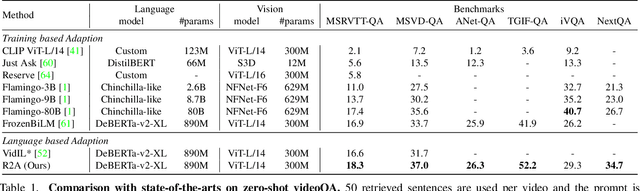
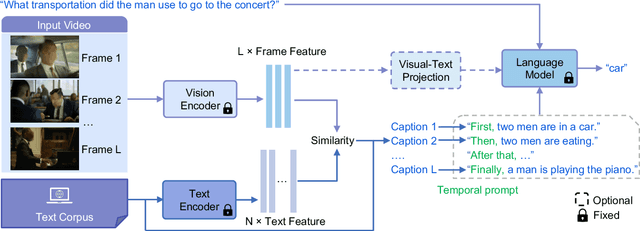

Video Question Answering (VideoQA) has been significantly advanced from the scaling of recent Large Language Models (LLMs). The key idea is to convert the visual information into the language feature space so that the capacity of LLMs can be fully exploited. Existing VideoQA methods typically take two paradigms: (1) learning cross-modal alignment, and (2) using an off-the-shelf captioning model to describe the visual data. However, the first design needs costly training on many extra multi-modal data, whilst the second is further limited by limited domain generalization. To address these limitations, a simple yet effective Retrieving-to-Answer (R2A) framework is proposed.Given an input video, R2A first retrieves a set of semantically similar texts from a generic text corpus using a pre-trained multi-modal model (e.g., CLIP). With both the question and the retrieved texts, a LLM (e.g., DeBERTa) can be directly used to yield a desired answer. Without the need for cross-modal fine-tuning, R2A allows for all the key components (e.g., LLM, retrieval model, and text corpus) to plug-and-play. Extensive experiments on several VideoQA benchmarks show that despite with 1.3B parameters and no fine-tuning, our R2A can outperform the 61 times larger Flamingo-80B model even additionally trained on nearly 2.1B multi-modal data.
MCPI: Integrating Multimodal Data for Enhanced Prediction of Compound Protein Interactions
Jun 15, 2023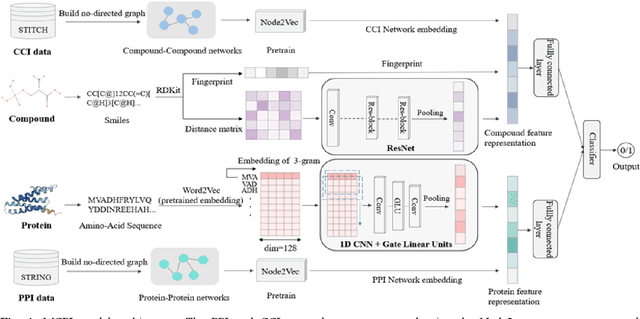
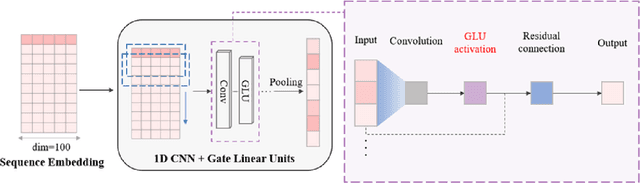
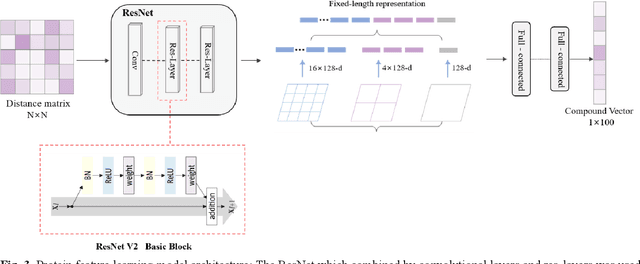
The identification of compound-protein interactions (CPI) plays a critical role in drug screening, drug repurposing, and combination therapy studies. The effectiveness of CPI prediction relies heavily on the features extracted from both compounds and target proteins. While various prediction methods employ different feature combinations, both molecular-based and network-based models encounter the common obstacle of incomplete feature representations. Thus, a promising solution to this issue is to fully integrate all relevant CPI features. This study proposed a novel model named MCPI, which is designed to improve the prediction performance of CPI by integrating multiple sources of information, including the PPI network, CCI network, and structural features of CPI. The results of the study indicate that the MCPI model outperformed other existing methods for predicting CPI on public datasets. Furthermore, the study has practical implications for drug development, as the model was applied to search for potential inhibitors among FDA-approved drugs in response to the SARS-CoV-2 pandemic. The prediction results were then validated through the literature, suggesting that the MCPI model could be a useful tool for identifying potential drug candidates. Overall, this study has the potential to advance our understanding of CPI and guide drug development efforts.
A Gromov--Wasserstein Geometric View of Spectrum-Preserving Graph Coarsening
Jun 15, 2023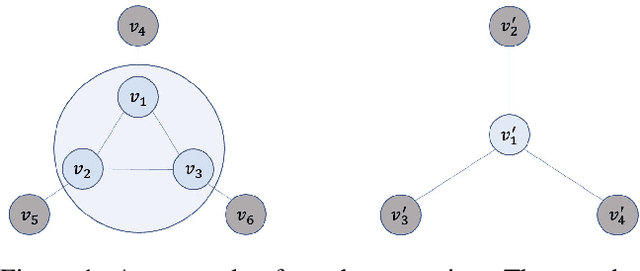
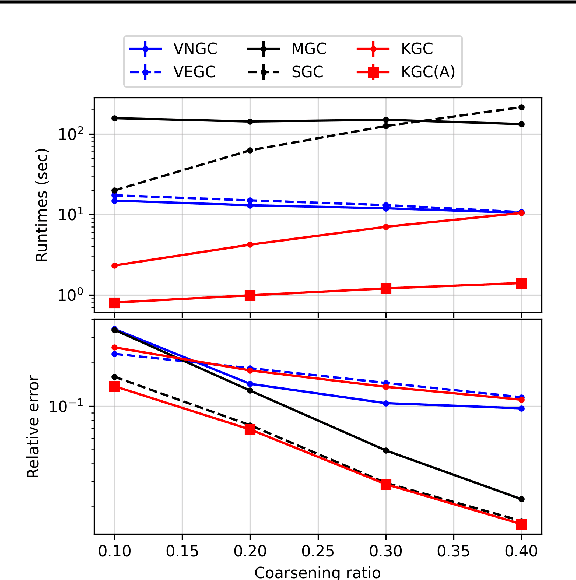
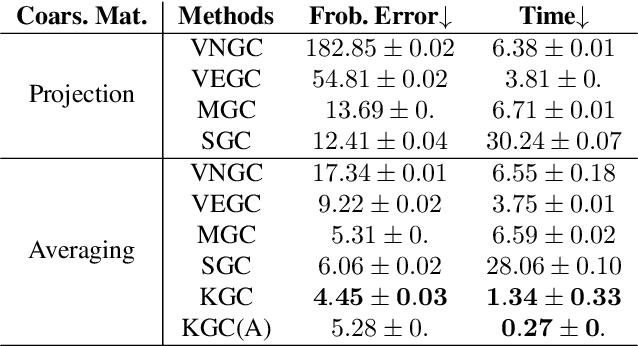
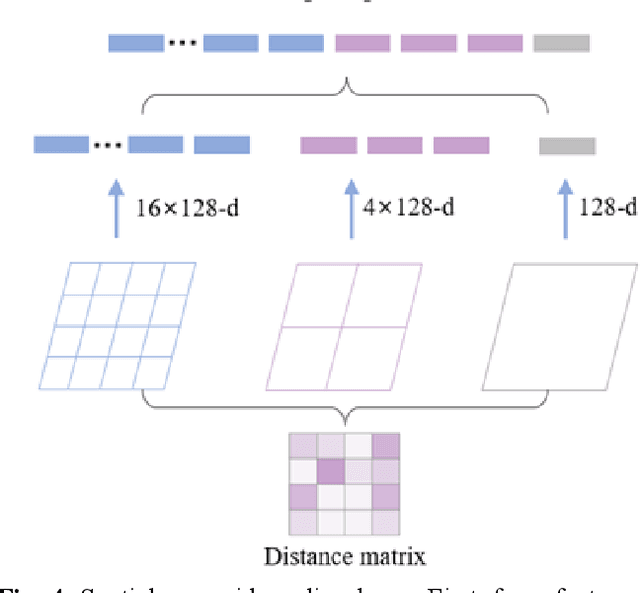
Graph coarsening is a technique for solving large-scale graph problems by working on a smaller version of the original graph, and possibly interpolating the results back to the original graph. It has a long history in scientific computing and has recently gained popularity in machine learning, particularly in methods that preserve the graph spectrum. This work studies graph coarsening from a different perspective, developing a theory for preserving graph distances and proposing a method to achieve this. The geometric approach is useful when working with a collection of graphs, such as in graph classification and regression. In this study, we consider a graph as an element on a metric space equipped with the Gromov--Wasserstein (GW) distance, and bound the difference between the distance of two graphs and their coarsened versions. Minimizing this difference can be done using the popular weighted kernel $K$-means method, which improves existing spectrum-preserving methods with the proper choice of the kernel. The study includes a set of experiments to support the theory and method, including approximating the GW distance, preserving the graph spectrum, classifying graphs using spectral information, and performing regression using graph convolutional networks. Code is available at https://github.com/ychen-stat-ml/GW-Graph-Coarsening .
Graph Extraction for Assisting Crash Simulation Data Analysis
Jun 15, 2023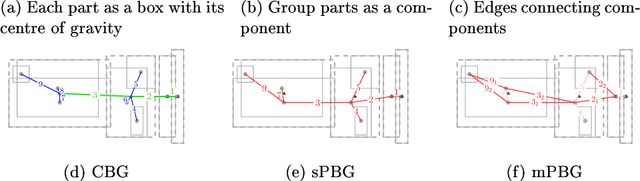
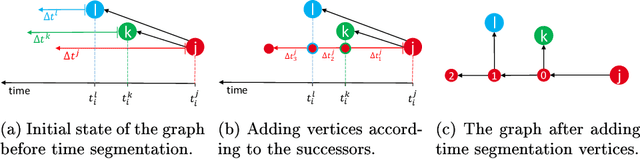
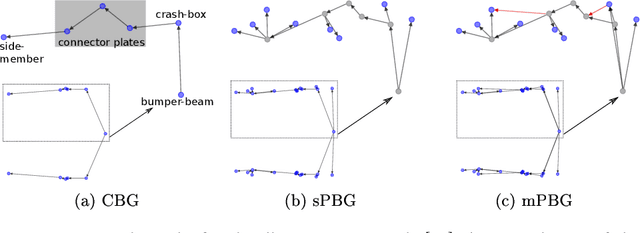

In this work, we establish a method for abstracting information from Computer Aided Engineering (CAE) into graphs. Such graph representations of CAE data can improve design guidelines and support recommendation systems by enabling the comparison of simulations, highlighting unexplored experimental designs, and correlating different designs. We focus on the load-path in crashworthiness analysis, a complex sub-discipline in vehicle design. The load-path is the sequence of parts that absorb most of the energy caused by the impact. To detect the load-path, we generate a directed weighted graph from the CAE data. The vertices represent the vehicle's parts, and the edges are an abstraction of the connectivity of the parts. The edge direction follows the temporal occurrence of the collision, where the edge weights reflect aspects of the energy absorption. We introduce and assess three methods for graph extraction and an additional method for further updating each graph with the sequences of absorption. Based on longest-path calculations, we introduce an automated detection of the load-path, which we analyse for the different graph extraction methods and weights. Finally, we show how our method for the detection of load-paths helps in the classification and labelling of CAE simulations.