 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Machine Translation for Mathematical Formulae
May 25, 2023
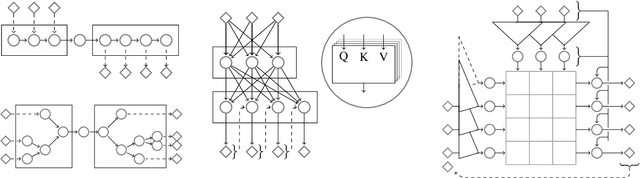



We tackle the problem of neural machine translation of mathematical formulae between ambiguous presentation languages and unambiguous content languages. Compared to neural machine translation on natural language, mathematical formulae have a much smaller vocabulary and much longer sequences of symbols, while their translation requires extreme precision to satisfy mathematical information needs. In this work, we perform the tasks of translating from LaTeX to Mathematica as well as from LaTeX to semantic LaTeX. While recurrent, recursive, and transformer networks struggle with preserving all contained information, we find that convolutional sequence-to-sequence networks achieve 95.1% and 90.7% exact matches, respectively.
Toward Fairness in Text Generation via Mutual Information Minimization based on Importance Sampling
Feb 25, 2023
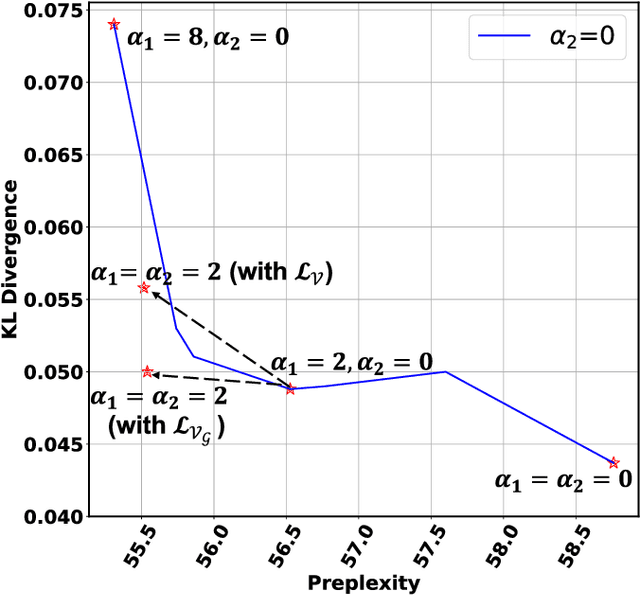
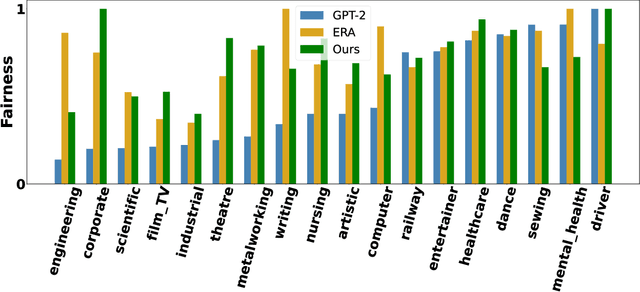
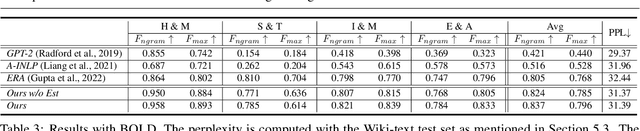
Pretrained language models (PLMs), such as GPT2, have achieved remarkable empirical performance in text generation tasks. However, pretrained on large-scale natural language corpora, the generated text from PLMs may exhibit social bias against disadvantaged demographic groups. To improve the fairness of PLMs in text generation, we propose to minimize the mutual information between the semantics in the generated text sentences and their demographic polarity, i.e., the demographic group to which the sentence is referring. In this way, the mentioning of a demographic group (e.g., male or female) is encouraged to be independent from how it is described in the generated text, thus effectively alleviating the social bias. Moreover, we propose to efficiently estimate the upper bound of the above mutual information via importance sampling, leveraging a natural language corpus. We also propose a distillation mechanism that preserves the language modeling ability of the PLMs after debiasing. Empirical results on real-world benchmarks demonstrate that the proposed method yields superior performance in term of both fairness and language modeling ability.
Construction d'un système de recommandation basé sur des contraintes via des graphes de connaissances
Jun 05, 2023


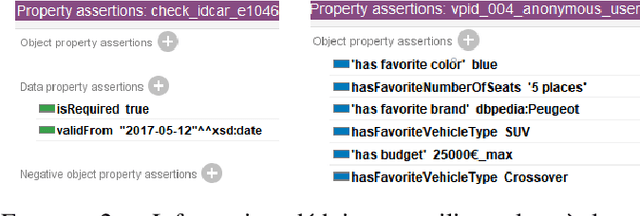
Knowledge graphs in RDF model entities and their relations using ontologies, and have gained popularity for information modeling. In recommender systems, knowledge graphs help represent more links and relationships between users and items. Constraint-based recommender systems leverage deep recommendation knowledge to identify relevant suggestions. When combined with knowledge graphs, they offer benefits in constraint sets. This paper explores a constraint-based recommender system using RDF knowledge graphs for the vehicle purchase/sale domain. Our experiments demonstrate that the proposed approach efficiently identifies recommendations based on user preferences.
On the Role of Morphological Information for Contextual Lemmatization
Feb 01, 2023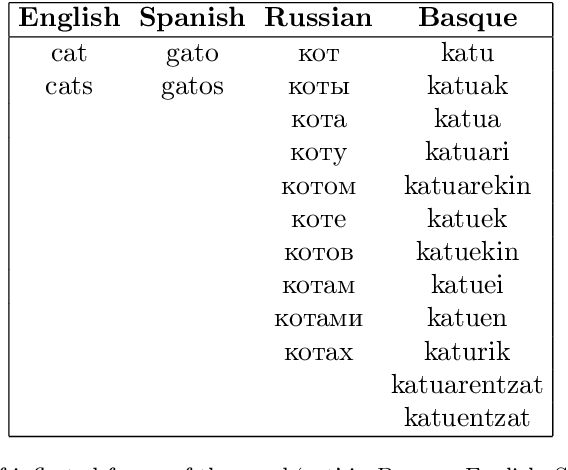

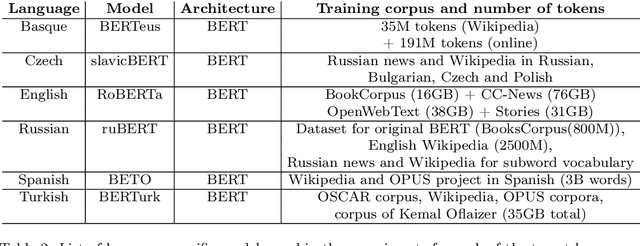
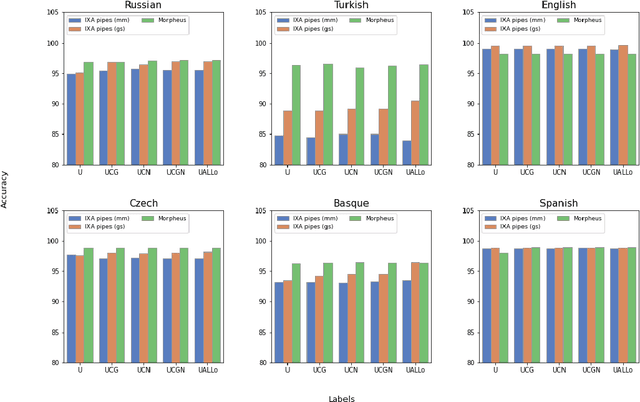
Lemmatization is a Natural Language Processing (NLP) task which consists of producing, from a given inflected word, its canonical form or lemma. Lemmatization is one of the basic tasks that facilitate downstream NLP applications, and is of particular importance for high-inflected languages. Given that the process to obtain a lemma from an inflected word can be explained by looking at its morphosyntactic category, including fine-grained morphosyntactic information to train contextual lemmatizers has become common practice, without analyzing whether that is the optimum in terms of downstream performance. Thus, in this paper we empirically investigate the role of morphological information to develop contextual lemmatizers in six languages within a varied spectrum of morphological complexity: Basque, Turkish, Russian, Czech, Spanish and English. Furthermore, and unlike the vast majority of previous work, we also evaluate lemmatizers in out-of-domain settings, which constitutes, after all, their most common application use. The results of our study are rather surprising: (i) providing lemmatizers with fine-grained morphological features during training is not that beneficial, not even for agglutinative languages; (ii) in fact, modern contextual word representations seem to implicitly encode enough morphological information to obtain good contextual lemmatizers without seeing any explicit morphological signal; (iii) the best lemmatizers out-of-domain are those using simple UPOS tags or those trained without morphology; (iv) current evaluation practices for lemmatization are not adequate to clearly discriminate between models.
Human Limits in Machine Learning: Prediction of Plant Phenotypes Using Soil Microbiome Data
Jun 19, 2023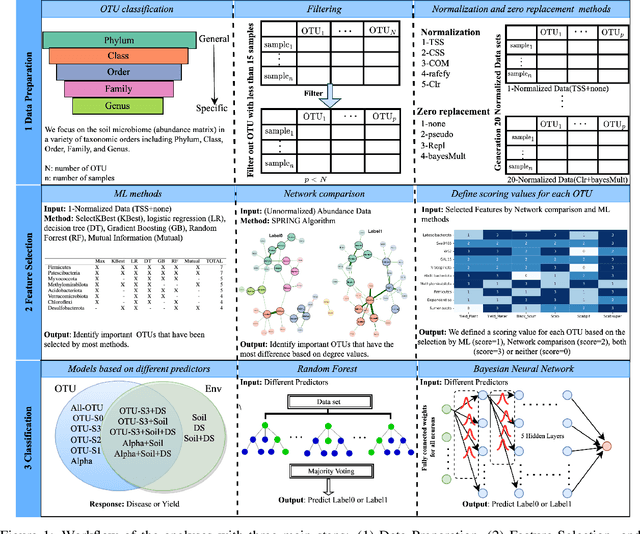

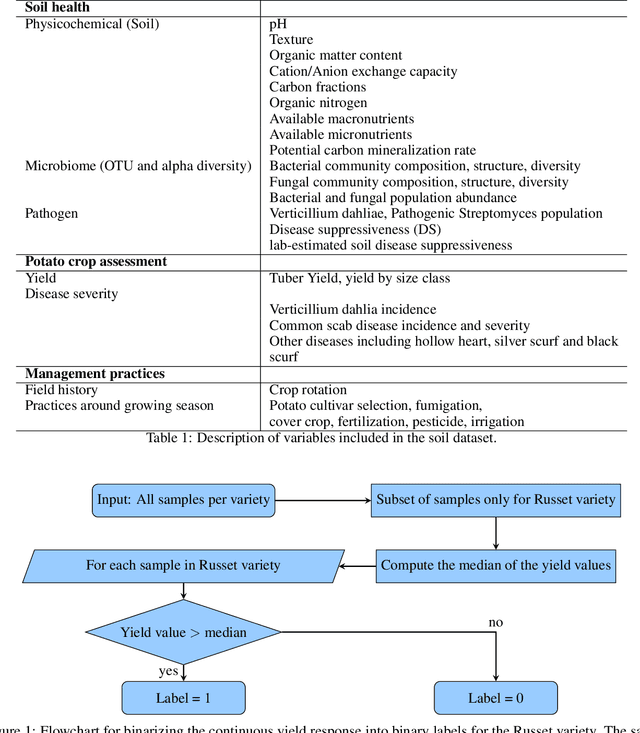
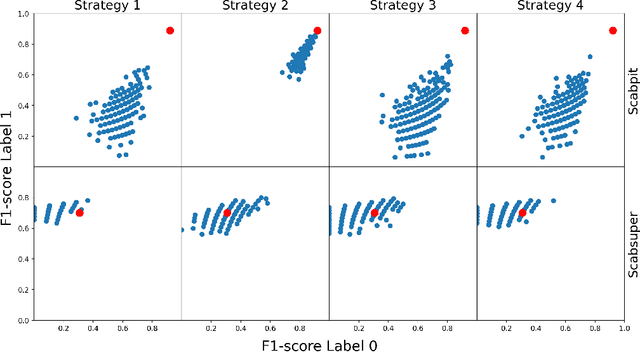
The preservation of soil health has been identified as one of the main challenges of the XXI century given its vast (and potentially threatening) ramifications in agriculture, human health and biodiversity. Here, we provide the first deep investigation of the predictive potential of machine-learning models to understand the connections between soil and biological phenotypes. Indeed, we investigate an integrative framework performing accurate machine-learning-based prediction of plant phenotypes from biological, chemical and physical properties of the soil via two models: random forest and Bayesian neural network. We show that prediction is improved, as evidenced by higher weighted F1 scores, when incorporating into the models environmental features like soil physicochemical properties and microbial population density in addition to the microbiome information. Furthermore, by exploring multiple data preprocessing strategies such as normalization, zero replacement, and data augmentation, we confirm that human decisions have a huge impact on the predictive performance. In particular, we show that the naive total sum scaling normalization that is commonly used in microbiome research is not the optimal strategy to maximize predictive power. In addition, we find that accurately defined labels are more important than normalization, taxonomic level or model characteristics. That is, if humans are unable to classify the samples and provide accurate labels, the performance of machine-learning models will be limited. Lastly, we present strategies for domain scientists via a full model selection decision tree to identify the human choices that maximize the prediction power of the models. Our work is accompanied by open source reproducible scripts (https://github.com/solislemuslab/soil-microbiome-nn) for maximum outreach among the microbiome research community.
Non-contact Sensing for Anomaly Detection in Wind Turbine Blades: A focus-SVDD with Complex-Valued Auto-Encoder Approach
Jun 19, 2023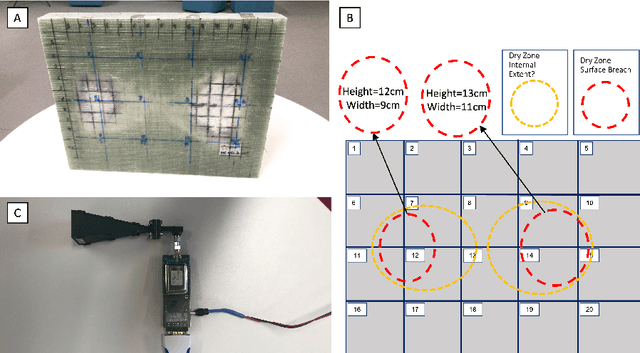


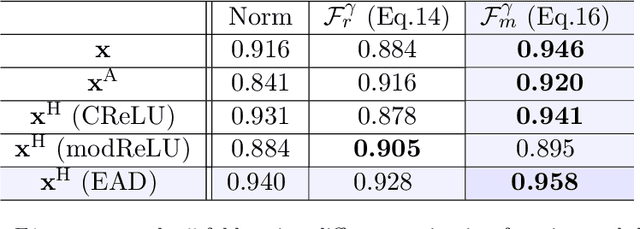
The occurrence of manufacturing defects in wind turbine blade (WTB) production can result in significant increases in operation and maintenance costs and lead to severe and disastrous consequences. Therefore, inspection during the manufacturing process is crucial to ensure consistent fabrication of composite materials. Non-contact sensing techniques, such as Frequency Modulated Continuous Wave (FMCW) radar, are becoming increasingly popular as they offer a full view of these complex structures during curing. In this paper, we enhance the quality assurance of manufacturing utilizing FMCW radar as a non-destructive sensing modality. Additionally, a novel anomaly detection pipeline is developed that offers the following advantages: (1) We use the analytic representation of the Intermediate Frequency signal of the FMCW radar as a feature to disentangle material-specific and round-trip delay information from the received wave. (2) We propose a novel anomaly detection methodology called focus Support Vector Data Description (focus-SVDD). This methodology involves defining the limit boundaries of the dataset after removing healthy data features, thereby focusing on the attributes of anomalies. (3) The proposed method employs a complex-valued autoencoder to remove healthy features and we introduces a new activation function called Exponential Amplitude Decay (EAD). EAD takes advantage of the Rayleigh distribution, which characterizes an instantaneous amplitude signal. The effectiveness of the proposed method is demonstrated through its application to collected data, where it shows superior performance compared to other state-of-the-art unsupervised anomaly detection methods. This method is expected to make a significant contribution not only to structural health monitoring but also to the field of deep complex-valued data processing and SVDD application.
WikiChat: A Few-Shot LLM-Based Chatbot Grounded with Wikipedia
May 23, 2023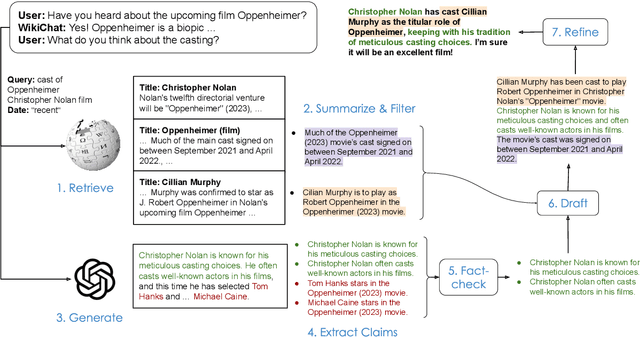
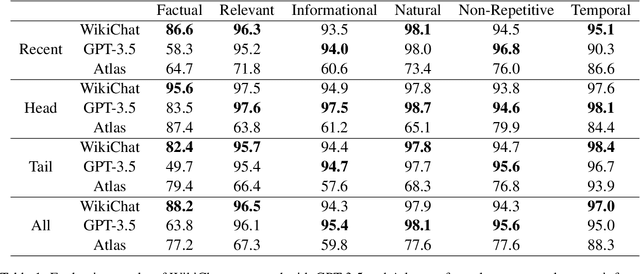


Despite recent advances in Large Language Models (LLMs), users still cannot trust the information provided in their responses. LLMs cannot speak accurately about events that occurred after their training, which are often topics of great interest to users, and, as we show in this paper, they are highly prone to hallucination when talking about less popular (tail) topics. This paper presents WikiChat, a few-shot LLM-based chatbot that is grounded with live information from Wikipedia. Through many iterations of experimentation, we have crafte a pipeline based on information retrieval that (1) uses LLMs to suggest interesting and relevant facts that are individually verified against Wikipedia, (2) retrieves additional up-to-date information, and (3) composes coherent and engaging time-aware responses. We propose a novel hybrid human-and-LLM evaluation methodology to analyze the factuality and conversationality of LLM-based chatbots. We focus on evaluating important but previously neglected issues such as conversing about recent and tail topics. We evaluate WikiChat against strong fine-tuned and LLM-based baselines across a diverse set of conversation topics. We find that WikiChat outperforms all baselines in terms of the factual accuracy of its claims, by up to 12.1%, 28.3% and 32.7% on head, recent and tail topics, while matching GPT-3.5 in terms of providing natural, relevant, non-repetitive and informational responses.
Achievable Rate Analysis of the STAR-RIS Aided NOMA Uplink in the Face of Imperfect CSI and Hardware Impairments
Jun 14, 2023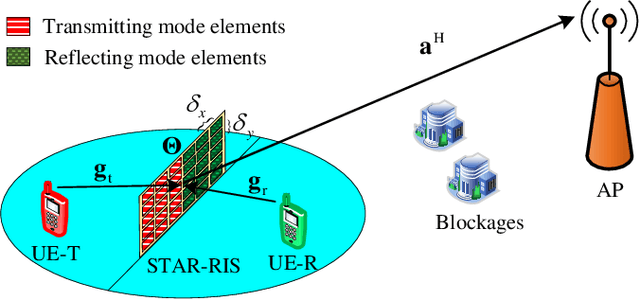
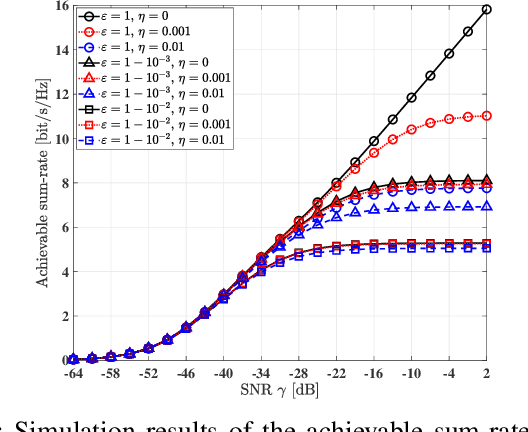

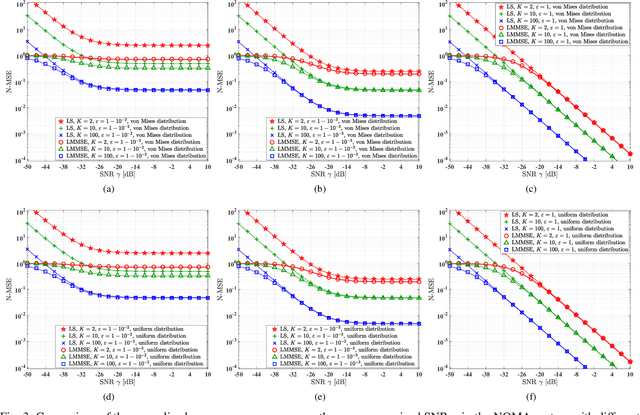
Reconfigurable intelligent surfaces (RIS) are capable of beneficially ameliorating the propagation environment by appropriately controlling the passive reflecting elements. To extend the coverage area, the concept of simultaneous transmitting and reflecting reconfigurable intelligent surfaces (STAR-RIS) has been proposed, yielding supporting 360^circ coverage user equipment (UE) located on both sides of the RIS. In this paper, we theoretically formulate the ergodic sum-rate of the STAR-RIS assisted non-orthogonal multiple access (NOMA) uplink in the face of channel estimation errors and hardware impairments (HWI). Specifically, the STAR-RIS phase shift is configured based on the statistical channel state information (CSI), followed by linear minimum mean square error (LMMSE) channel estimation of the equivalent channel spanning from the UEs to the access point (AP). Afterwards, successive interference cancellation (SIC) is employed at the AP using the estimated instantaneous CSI, and we derive the theoretical ergodic sum-rate upper bound for both perfect and imperfect SIC decoding algorithm. The theoretical analysis and the simulation results show that both the channel estimation and the ergodic sum-rate have performance floor at high transmit power region caused by transceiver hardware impairments.
Towards Interactive Image Inpainting via Sketch Refinement
Jun 14, 2023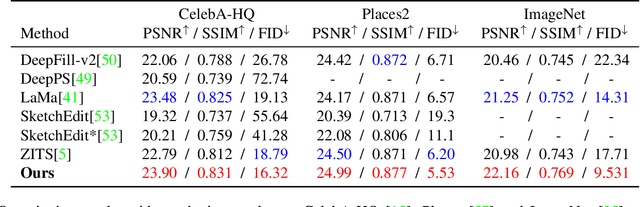
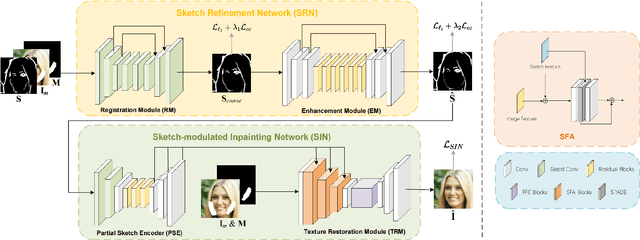
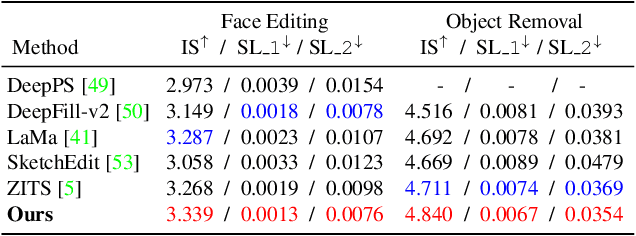

One tough problem of image inpainting is to restore complex structures in the corrupted regions. It motivates interactive image inpainting which leverages additional hints, e.g., sketches, to assist the inpainting process. Sketch is simple and intuitive to end users, but meanwhile has free forms with much randomness. Such randomness may confuse the inpainting models, and incur severe artifacts in completed images. To address this problem, we propose a two-stage image inpainting method termed SketchRefiner. In the first stage, we propose using a cross-correlation loss function to robustly calibrate and refine the user-provided sketches in a coarse-to-fine fashion. In the second stage, we learn to extract informative features from the abstracted sketches in the feature space and modulate the inpainting process. We also propose an algorithm to simulate real sketches automatically and build a test protocol with different applications. Experimental results on public datasets demonstrate that SketchRefiner effectively utilizes sketch information and eliminates the artifacts due to the free-form sketches. Our method consistently outperforms the state-of-the-art ones both qualitatively and quantitatively, meanwhile revealing great potential in real-world applications. Our code and dataset are available.
Identification of Energy Management Configuration Concepts from a Set of Pareto-optimal Solutions
Jun 14, 2023
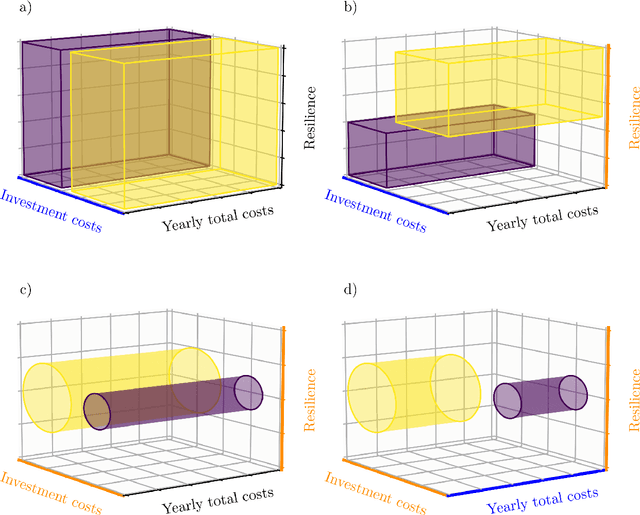

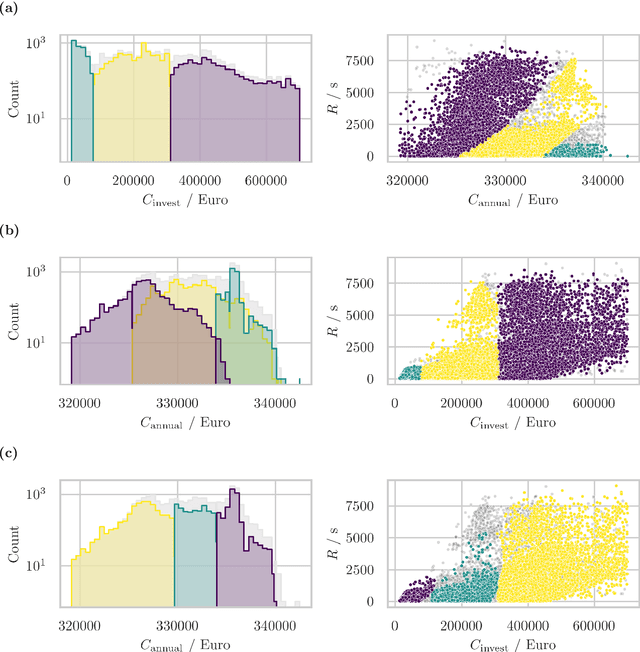
Optimizing building configurations for an efficient use of energy is increasingly receiving attention by current research and several methods have been developed to address this task. Selecting a suitable configuration based on multiple conflicting objectives, such as initial investment cost, recurring cost, robustness with respect to uncertainty of grid operation is, however, a difficult multi-criteria decision making problem. Concept identification can facilitate a decision maker by sorting configuration options into semantically meaningful groups (concepts), further introducing constraints to meet trade-off expectations for a selection of objectives. In this study, for a set of 20000 Pareto-optimal building energy management configurations, resulting from a many-objective evolutionary optimization, multiple concept identification iterations are conducted to provide a basis for making an informed investment decision. In a series of subsequent analysis steps, it is shown how the choice of description spaces, i.e., the partitioning of the features into sets for which consistent and non-overlapping concepts are required, impacts the type of information that can be extracted and that different setups of description spaces illuminate several different aspects of the configuration data - an important aspect that has not been addressed in previous work.