 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LoCoOp: Few-Shot Out-of-Distribution Detection via Prompt Learning
Jun 10, 2023
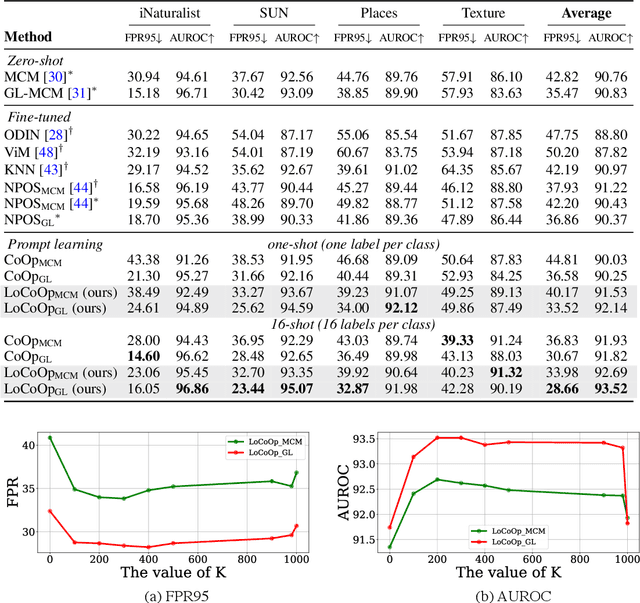
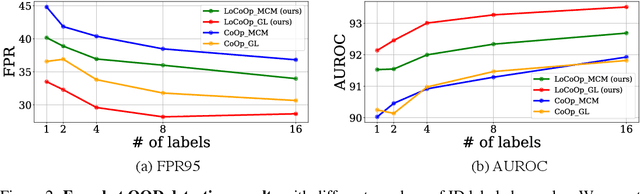

We present a novel vision-language prompt learning approach for few-shot out-of-distribution (OOD) detection. Few-shot OOD detection aims to detect OOD images from classes that are unseen during training using only a few labeled in-distribution (ID) images. While prompt learning methods such as CoOp have shown effectiveness and efficiency in few-shot ID classification, they still face limitations in OOD detection due to the potential presence of ID-irrelevant information in text embeddings. To address this issue, we introduce a new approach called Local regularized Context Optimization (LoCoOp), which performs OOD regularization that utilizes the portions of CLIP local features as OOD features during training. CLIP's local features have a lot of ID-irrelevant nuisances (e.g., backgrounds), and by learning to push them away from the ID class text embeddings, we can remove the nuisances in the ID class text embeddings and enhance the separation between ID and OOD. Experiments on the large-scale ImageNet OOD detection benchmarks demonstrate the superiority of our LoCoOp over zero-shot, fully supervised detection methods and prompt learning methods. Notably, even in a one-shot setting -- just one label per class, LoCoOp outperforms existing zero-shot and fully supervised detection methods. The code will be available via https://github.com/AtsuMiyai/LoCoOp.
Manipulating Visually-aware Federated Recommender Systems and Its Countermeasures
May 14, 2023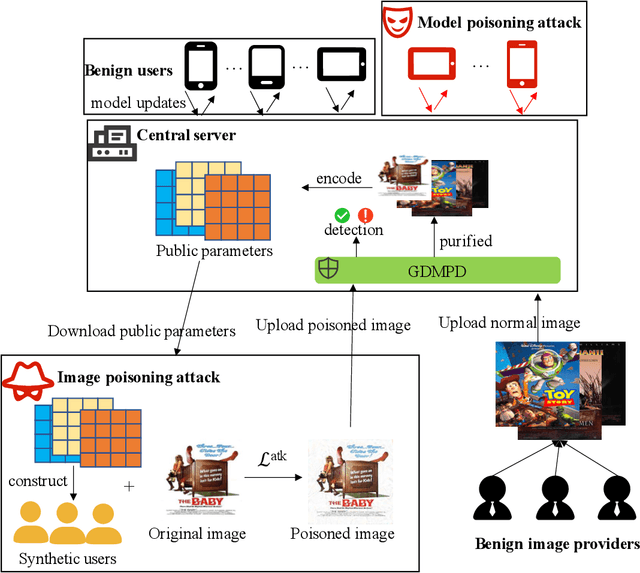

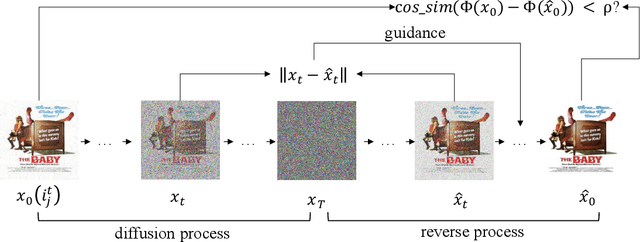

Federated recommender systems (FedRecs) have been widely explored recently due to their ability to protect user data privacy. In FedRecs, a central server collaboratively learns recommendation models by sharing model public parameters with clients, thereby offering a privacy-preserving solution. Unfortunately, the exposure of model parameters leaves a backdoor for adversaries to manipulate FedRecs. Existing works about FedRec security already reveal that items can easily be promoted by malicious users via model poisoning attacks, but all of them mainly focus on FedRecs with only collaborative information (i.e., user-item interactions). We argue that these attacks are effective because of the data sparsity of collaborative signals. In practice, auxiliary information, such as products' visual descriptions, is used to alleviate collaborative filtering data's sparsity. Therefore, when incorporating visual information in FedRecs, all existing model poisoning attacks' effectiveness becomes questionable. In this paper, we conduct extensive experiments to verify that incorporating visual information can beat existing state-of-the-art attacks in reasonable settings. However, since visual information is usually provided by external sources, simply including it will create new security problems. Specifically, we propose a new kind of poisoning attack for visually-aware FedRecs, namely image poisoning attacks, where adversaries can gradually modify the uploaded image to manipulate item ranks during FedRecs' training process. Furthermore, we reveal that the potential collaboration between image poisoning attacks and model poisoning attacks will make visually-aware FedRecs more vulnerable to being manipulated. To safely use visual information, we employ a diffusion model in visually-aware FedRecs to purify each uploaded image and detect the adversarial images.
Friendly Neighbors: Contextualized Sequence-to-Sequence Link Prediction
May 22, 2023
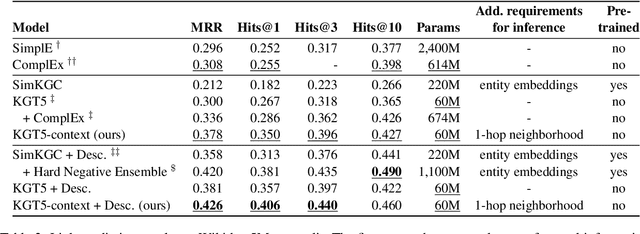
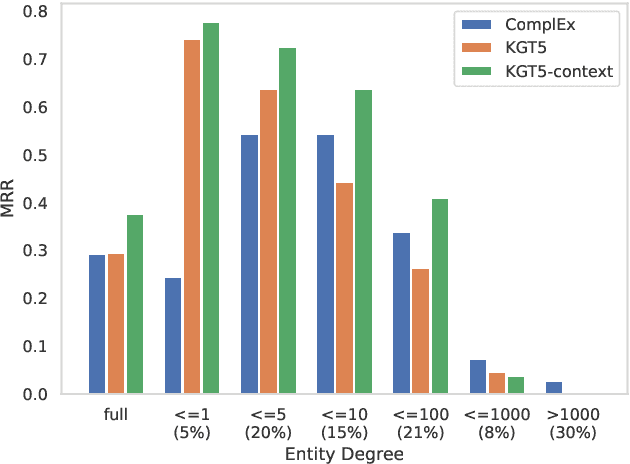
We propose KGT5-context, a simple sequence-to-sequence model for link prediction (LP) in knowledge graphs (KG). Our work expands on KGT5, a recent LP model that exploits textual features of the KG, has small model size, and is scalable. To reach good predictive performance, however, KGT5 relies on an ensemble with a knowledge graph embedding model, which itself is excessively large and costly to use. In this short paper, we show empirically that adding contextual information - i.e., information about the direct neighborhood of a query vertex - alleviates the need for a separate KGE model to obtain good performance. The resulting KGT5-context model obtains state-of-the-art performance in our experimental study, while at the same time reducing model size significantly.
Temporal Knowledge Graph Forecasting Without Knowledge Using In-Context Learning
May 17, 2023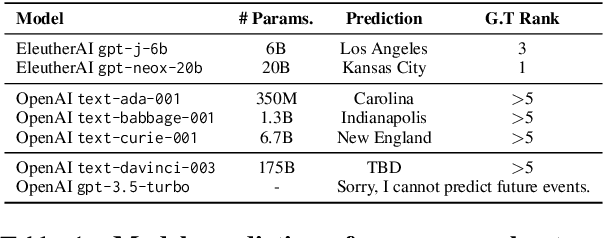
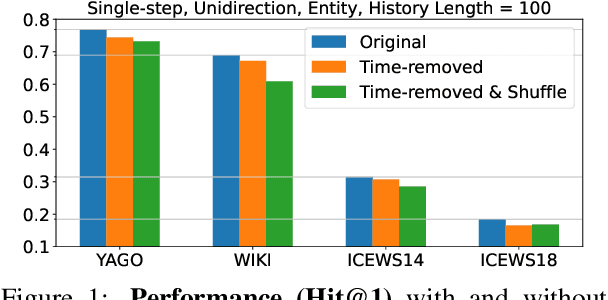
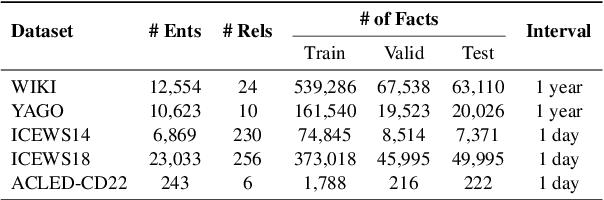
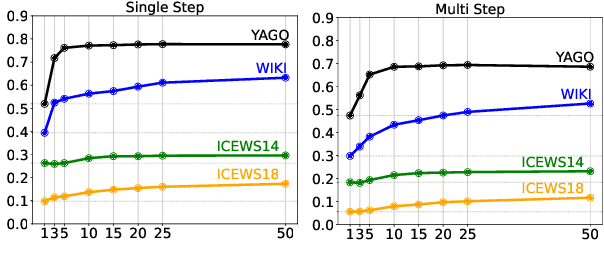
Temporal knowledge graph (TKG) forecasting benchmarks challenge models to predict future facts using knowledge of past facts. In this paper, we apply large language models (LLMs) to these benchmarks using in-context learning (ICL). We investigate whether and to what extent LLMs can be used for TKG forecasting, especially without any fine-tuning or explicit modules for capturing structural and temporal information. For our experiments, we present a framework that converts relevant historical facts into prompts and generates ranked predictions using token probabilities. Surprisingly, we observe that LLMs, out-of-the-box, perform on par with state-of-the-art TKG models carefully designed and trained for TKG forecasting. Our extensive evaluation presents performances across several models and datasets with different characteristics, compares alternative heuristics for preparing contextual information, and contrasts to prominent TKG methods and simple frequency and recency baselines. We also discover that using numerical indices instead of entity/relation names, i.e., hiding semantic information, does not significantly affect the performance ($\pm$0.4\% Hit@1). This shows that prior semantic knowledge is unnecessary; instead, LLMs can leverage the existing patterns in the context to achieve such performance. Our analysis also reveals that ICL enables LLMs to learn irregular patterns from the historical context, going beyond simple predictions based on common or recent information.
Reinforcement Learning with Simple Sequence Priors
May 26, 2023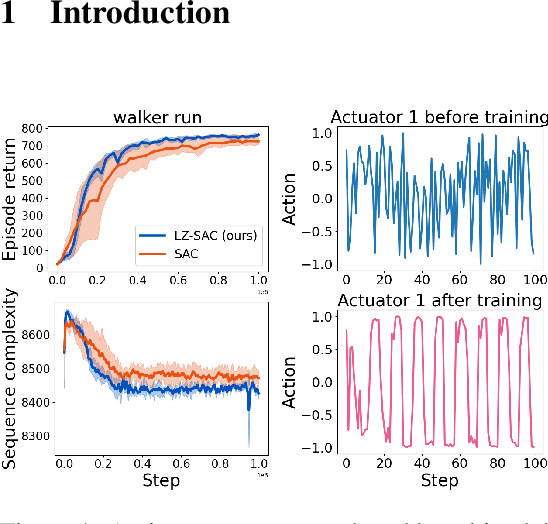

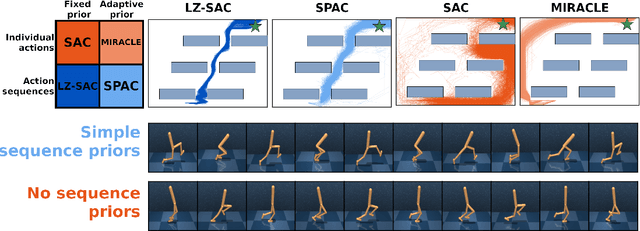

Everything else being equal, simpler models should be preferred over more complex ones. In reinforcement learning (RL), simplicity is typically quantified on an action-by-action basis -- but this timescale ignores temporal regularities, like repetitions, often present in sequential strategies. We therefore propose an RL algorithm that learns to solve tasks with sequences of actions that are compressible. We explore two possible sources of simple action sequences: Sequences that can be learned by autoregressive models, and sequences that are compressible with off-the-shelf data compression algorithms. Distilling these preferences into sequence priors, we derive a novel information-theoretic objective that incentivizes agents to learn policies that maximize rewards while conforming to these priors. We show that the resulting RL algorithm leads to faster learning, and attains higher returns than state-of-the-art model-free approaches in a series of continuous control tasks from the DeepMind Control Suite. These priors also produce a powerful information-regularized agent that is robust to noisy observations and can perform open-loop control.
Shielded Representations: Protecting Sensitive Attributes Through Iterative Gradient-Based Projection
May 17, 2023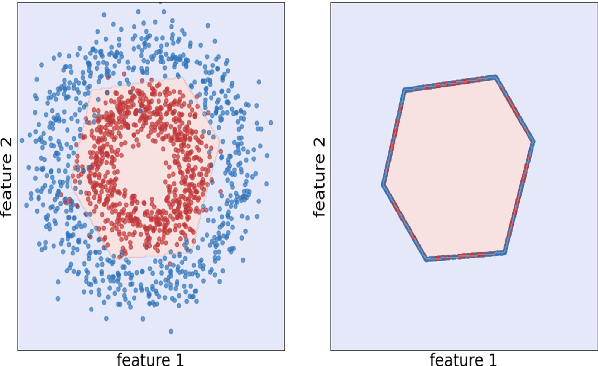
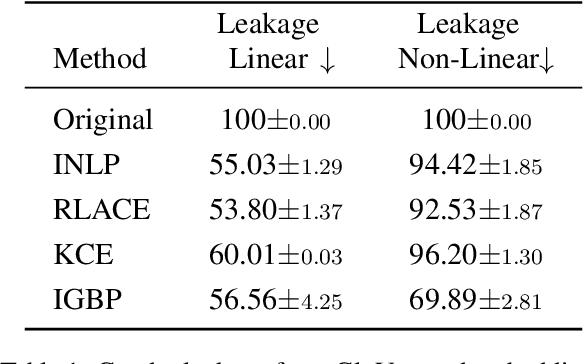
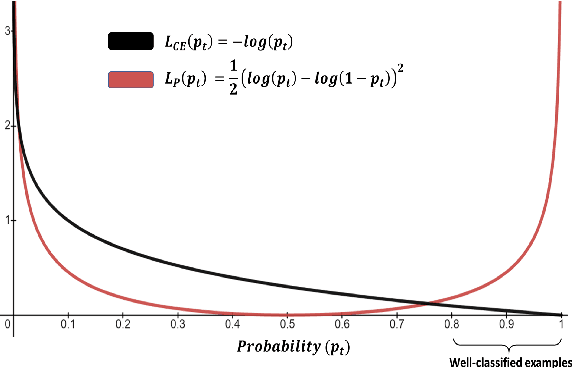

Natural language processing models tend to learn and encode social biases present in the data. One popular approach for addressing such biases is to eliminate encoded information from the model's representations. However, current methods are restricted to removing only linearly encoded information. In this work, we propose Iterative Gradient-Based Projection (IGBP), a novel method for removing non-linear encoded concepts from neural representations. Our method consists of iteratively training neural classifiers to predict a particular attribute we seek to eliminate, followed by a projection of the representation on a hypersurface, such that the classifiers become oblivious to the target attribute. We evaluate the effectiveness of our method on the task of removing gender and race information as sensitive attributes. Our results demonstrate that IGBP is effective in mitigating bias through intrinsic and extrinsic evaluations, with minimal impact on downstream task accuracy.
Identifying Informational Sources in News Articles
May 24, 2023
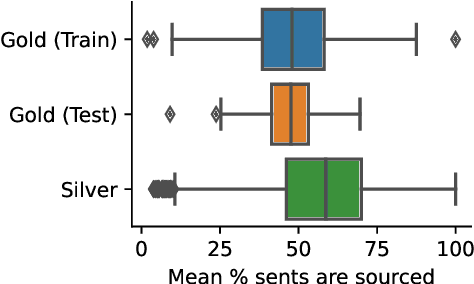

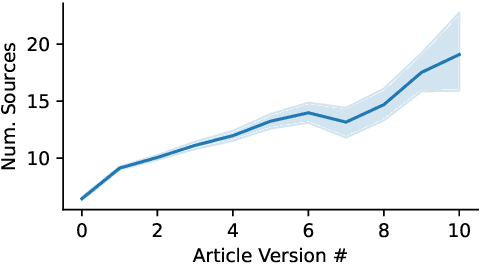
News articles are driven by the informational sources journalists use in reporting. Modeling when, how and why sources get used together in stories can help us better understand the information we consume and even help journalists with the task of producing it. In this work, we take steps toward this goal by constructing the largest and widest-ranging annotated dataset, to date, of informational sources used in news writing. We show that our dataset can be used to train high-performing models for information detection and source attribution. We further introduce a novel task, source prediction, to study the compositionality of sources in news articles. We show good performance on this task, which we argue is an important proof for narrative science exploring the internal structure of news articles and aiding in planning-based language generation, and an important step towards a source-recommendation system to aid journalists.
Optimal Control of Logically Constrained Partially Observable and Multi-Agent Markov Decision Processes
May 24, 2023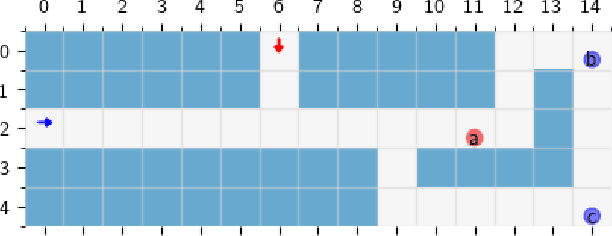
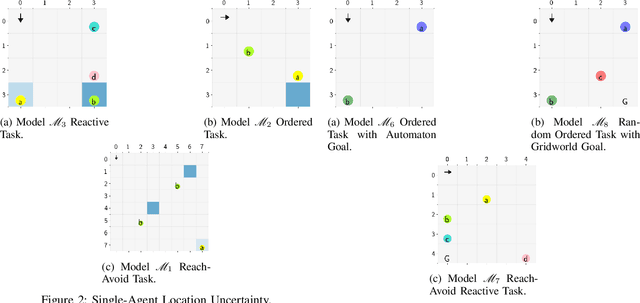
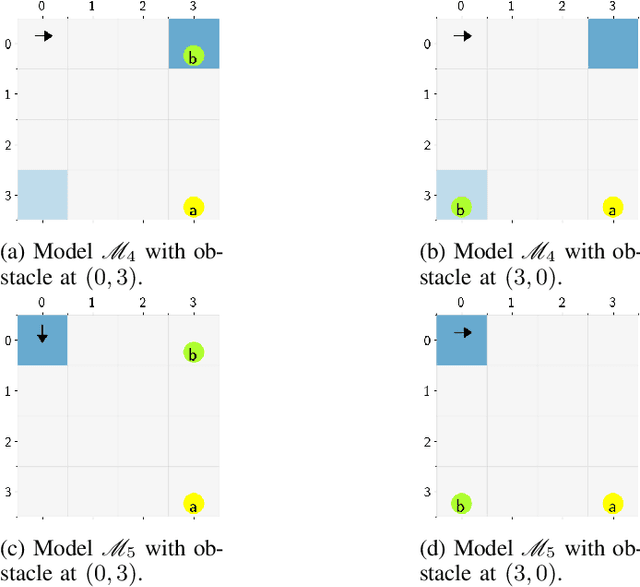

Autonomous systems often have logical constraints arising, for example, from safety, operational, or regulatory requirements. Such constraints can be expressed using temporal logic specifications. The system state is often partially observable. Moreover, it could encompass a team of multiple agents with a common objective but disparate information structures and constraints. In this paper, we first introduce an optimal control theory for partially observable Markov decision processes (POMDPs) with finite linear temporal logic constraints. We provide a structured methodology for synthesizing policies that maximize a cumulative reward while ensuring that the probability of satisfying a temporal logic constraint is sufficiently high. Our approach comes with guarantees on approximate reward optimality and constraint satisfaction. We then build on this approach to design an optimal control framework for logically constrained multi-agent settings with information asymmetry. We illustrate the effectiveness of our approach by implementing it on several case studies.
Towards Fine-Grained Information: Identifying the Type and Location of Translation Errors
Feb 17, 2023
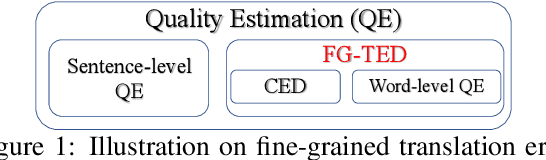
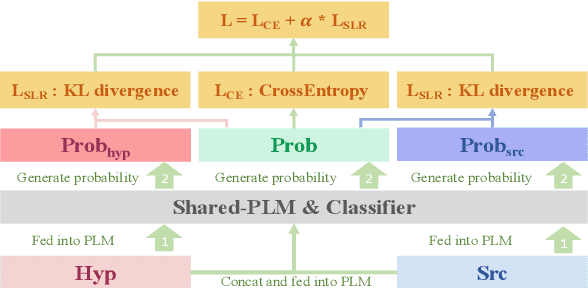
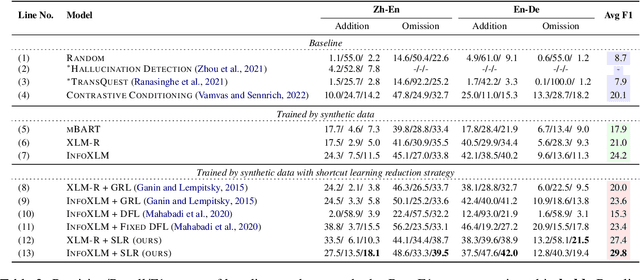
Fine-grained information on translation errors is helpful for the translation evaluation community. Existing approaches can not synchronously consider error position and type, failing to integrate the error information of both. In this paper, we propose Fine-Grained Translation Error Detection (FG-TED) task, aiming at identifying both the position and the type of translation errors on given source-hypothesis sentence pairs. Besides, we build an FG-TED model to predict the \textbf{addition} and \textbf{omission} errors -- two typical translation accuracy errors. First, we use a word-level classification paradigm to form our model and use the shortcut learning reduction to relieve the influence of monolingual features. Besides, we construct synthetic datasets for model training, and relieve the disagreement of data labeling in authoritative datasets, making the experimental benchmark concordant. Experiments show that our model can identify both error type and position concurrently, and gives state-of-the-art results on the restored dataset. Our model also delivers more reliable predictions on low-resource and transfer scenarios than existing baselines. The related datasets and the source code will be released in the future.
A Comprehensive Survey on Deep Learning for Relation Extraction: Recent Advances and New Frontiers
Jun 06, 2023
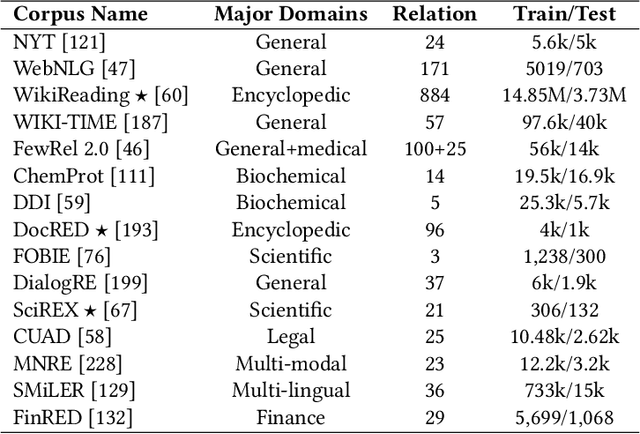
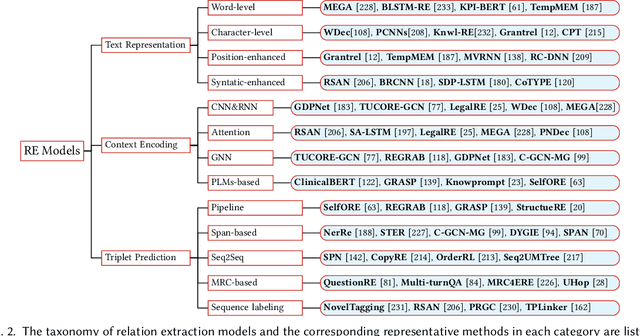
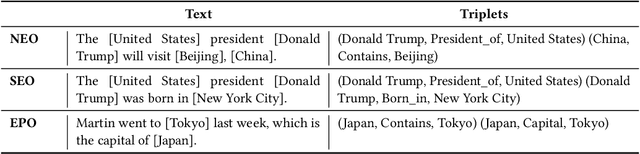
Relation extraction (RE) involves identifying the relations between entities from unstructured texts. RE serves as the foundation for many natural language processing (NLP) applications, such as knowledge graph completion, question answering, and information retrieval. In recent years, deep neural networks have dominated the field of RE and made noticeable progress. Subsequently, the large pre-trained language models (PLMs) have taken the state-of-the-art of RE to a new level. This survey provides a comprehensive review of existing deep learning techniques for RE. First, we introduce RE resources, including RE datasets and evaluation metrics. Second, we propose a new taxonomy to categorize existing works from three perspectives (text representation, context encoding, and triplet prediction). Third, we discuss several important challenges faced by RE and summarize potential techniques to tackle these challenges. Finally, we outline some promising future directions and prospects in this field. This survey is expected to facilitate researchers' collaborative efforts to tackle the challenges of real-life RE systems.