 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Proximal Symmetric Non-negative Latent Factor Analysis: A Novel Approach to Highly-Accurate Representation of Undirected Weighted Networks
Jun 06, 2023
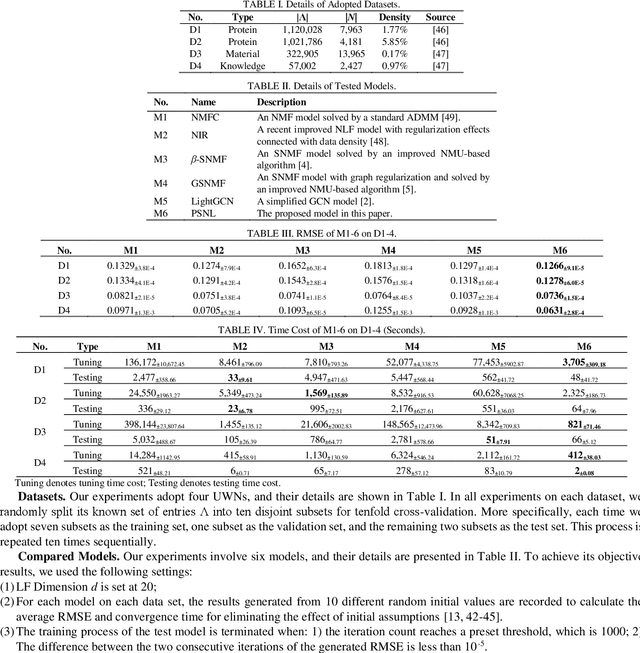
An Undirected Weighted Network (UWN) is commonly found in big data-related applications. Note that such a network's information connected with its nodes, and edges can be expressed as a Symmetric, High-Dimensional and Incomplete (SHDI) matrix. However, existing models fail in either modeling its intrinsic symmetry or low-data density, resulting in low model scalability or representation learning ability. For addressing this issue, a Proximal Symmetric Nonnegative Latent-factor-analysis (PSNL) model is proposed. It incorporates a proximal term into symmetry-aware and data density-oriented objective function for high representation accuracy. Then an adaptive Alternating Direction Method of Multipliers (ADMM)-based learning scheme is implemented through a Tree-structured of Parzen Estimators (TPE) method for high computational efficiency. Empirical studies on four UWNs demonstrate that PSNL achieves higher accuracy gain than state-of-the-art models, as well as highly competitive computational efficiency.
From Data to Action: Exploring AI and IoT-driven Solutions for Smarter Cities
Jun 06, 2023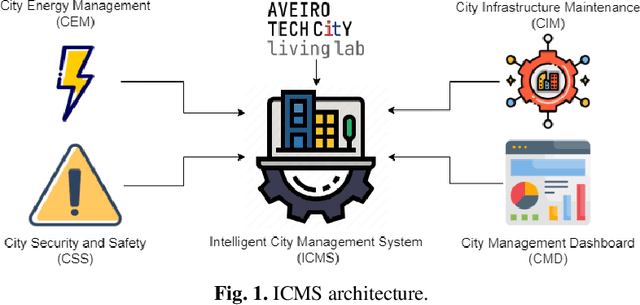
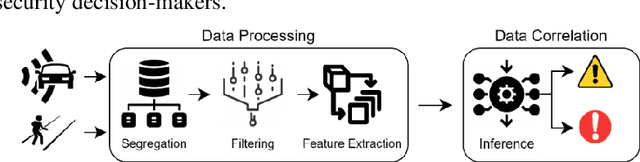
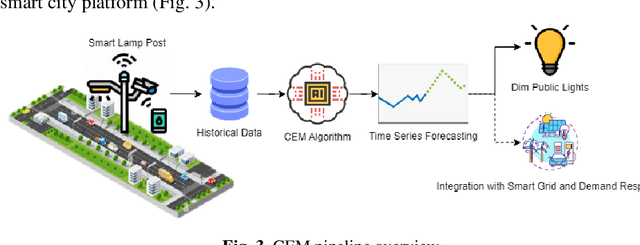
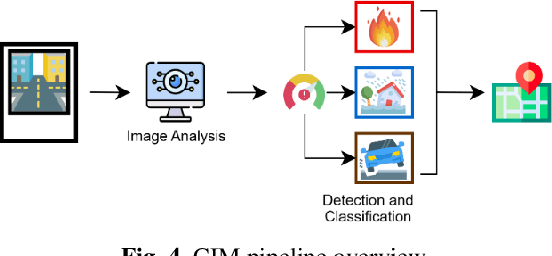
The emergence of smart cities demands harnessing advanced technologies like the Internet of Things (IoT) and Artificial Intelligence (AI) and promises to unlock cities' potential to become more sustainable, efficient, and ultimately livable for their inhabitants. This work introduces an intelligent city management system that provides a data-driven approach to three use cases: (i) analyze traffic information to reduce the risk of traffic collisions and improve driver and pedestrian safety, (ii) identify when and where energy consumption can be reduced to improve cost savings, and (iii) detect maintenance issues like potholes in the city's roads and sidewalks, as well as the beginning of hazards like floods and fires. A case study in Aveiro City demonstrates the system's effectiveness in generating actionable insights that enhance security, energy efficiency, and sustainability, while highlighting the potential of AI and IoT-driven solutions for smart city development.
Normalization-Equivariant Neural Networks with Application to Image Denoising
Jun 08, 2023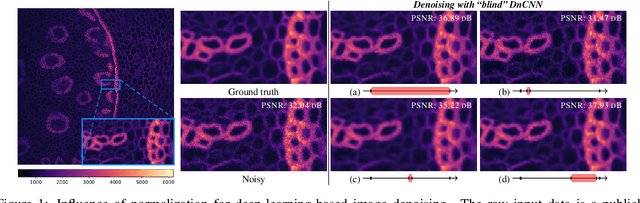

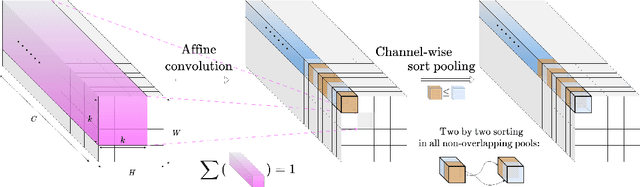
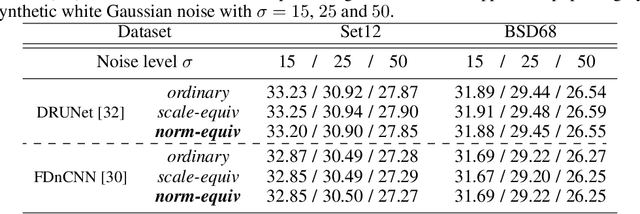
In many information processing systems, it may be desirable to ensure that any change of the input, whether by shifting or scaling, results in a corresponding change in the system response. While deep neural networks are gradually replacing all traditional automatic processing methods, they surprisingly do not guarantee such normalization-equivariance (scale + shift) property, which can be detrimental in many applications. To address this issue, we propose a methodology for adapting existing neural networks so that normalization-equivariance holds by design. Our main claim is that not only ordinary convolutional layers, but also all activation functions, including the ReLU (rectified linear unit), which are applied element-wise to the pre-activated neurons, should be completely removed from neural networks and replaced by better conditioned alternatives. To this end, we introduce affine-constrained convolutions and channel-wise sort pooling layers as surrogates and show that these two architectural modifications do preserve normalization-equivariance without loss of performance. Experimental results in image denoising show that normalization-equivariant neural networks, in addition to their better conditioning, also provide much better generalization across noise levels.
Differential Privacy for Class-based Data: A Practical Gaussian Mechanism
Jun 08, 2023
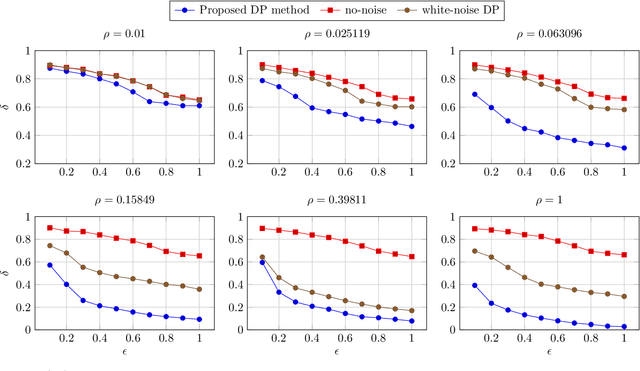
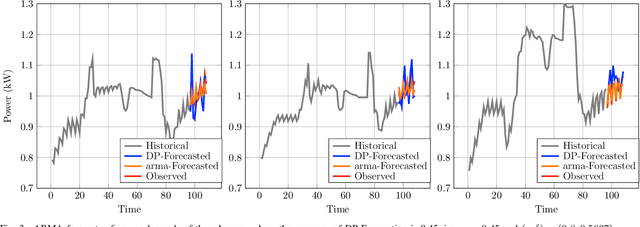
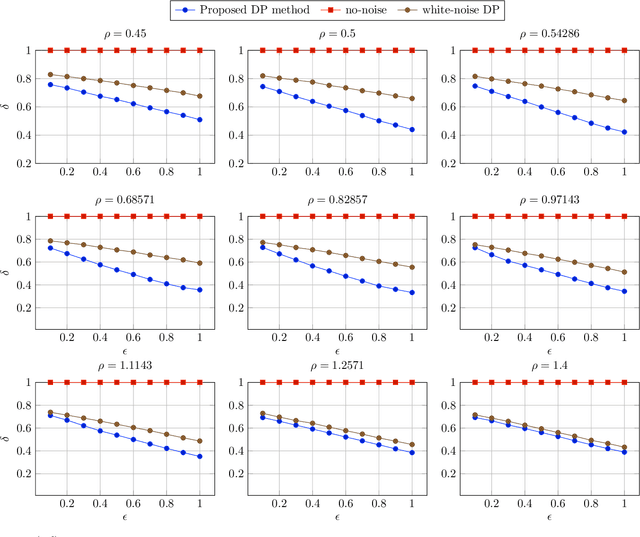
In this paper, we present a notion of differential privacy (DP) for data that comes from different classes. Here, the class-membership is private information that needs to be protected. The proposed method is an output perturbation mechanism that adds noise to the release of query response such that the analyst is unable to infer the underlying class-label. The proposed DP method is capable of not only protecting the privacy of class-based data but also meets quality metrics of accuracy and is computationally efficient and practical. We illustrate the efficacy of the proposed method empirically while outperforming the baseline additive Gaussian noise mechanism. We also examine a real-world application and apply the proposed DP method to the autoregression and moving average (ARMA) forecasting method, protecting the privacy of the underlying data source. Case studies on the real-world advanced metering infrastructure (AMI) measurements of household power consumption validate the excellent performance of the proposed DP method while also satisfying the accuracy of forecasted power consumption measurements.
On Search Strategies for Document-Level Neural Machine Translation
Jun 08, 2023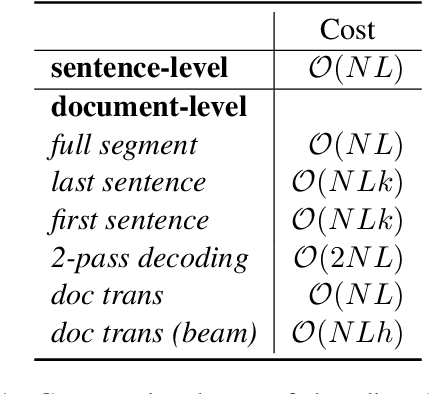
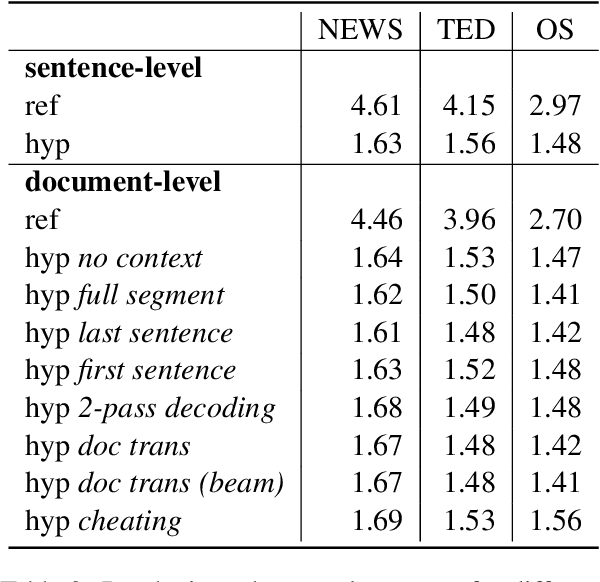
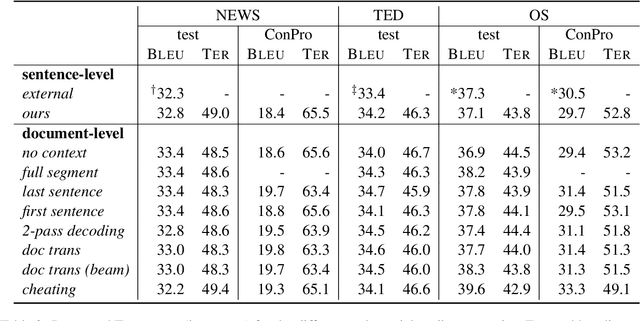
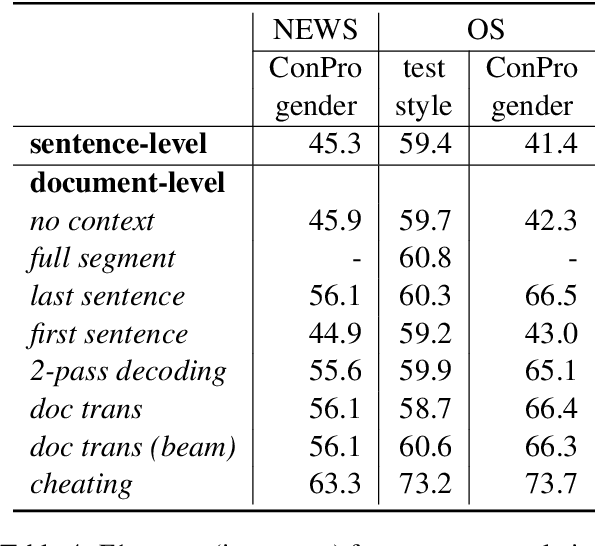
Compared to sentence-level systems, document-level neural machine translation (NMT) models produce a more consistent output across a document and are able to better resolve ambiguities within the input. There are many works on document-level NMT, mostly focusing on modifying the model architecture or training strategy to better accommodate the additional context-input. On the other hand, in most works, the question on how to perform search with the trained model is scarcely discussed, sometimes not mentioned at all. In this work, we aim to answer the question how to best utilize a context-aware translation model in decoding. We start with the most popular document-level NMT approach and compare different decoding schemes, some from the literature and others proposed by us. In the comparison, we are using both, standard automatic metrics, as well as specific linguistic phenomena on three standard document-level translation benchmarks. We find that most commonly used decoding strategies perform similar to each other and that higher quality context information has the potential to further improve the translation.
Data Augmentation for Seizure Prediction with Generative Diffusion Model
Jun 14, 2023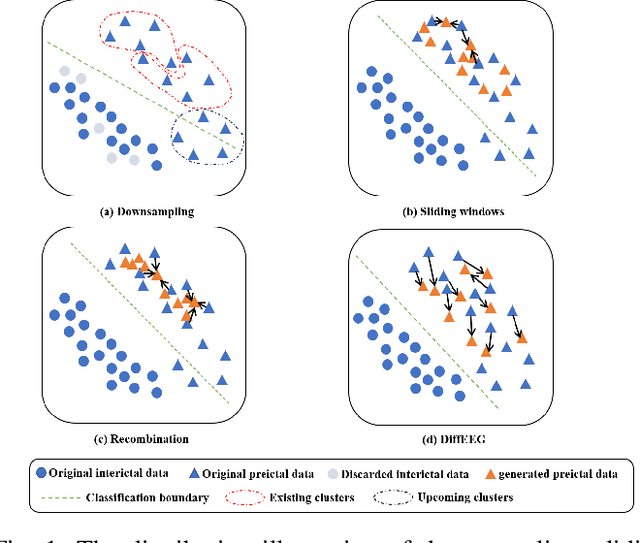
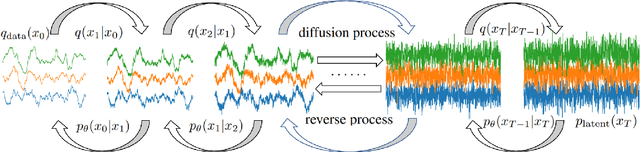
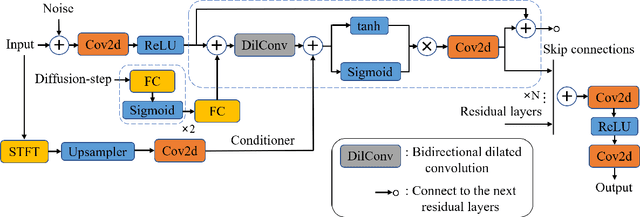
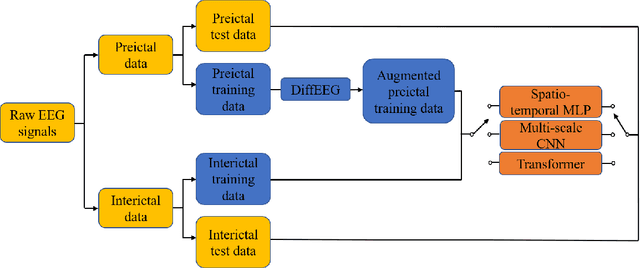
Objective: Seizure prediction is of great importance to improve the life of patients. The focal point is to distinguish preictal states from interictal ones. With the development of machine learning, seizure prediction methods have achieved significant progress. However, the severe imbalance problem between preictal and interictal data still poses a great challenge, restricting the performance of classifiers. Data augmentation is an intuitive way to solve this problem. Existing data augmentation methods generate samples by overlapping or recombining data. The distribution of generated samples is limited by original data, because such transformations cannot fully explore the feature space and offer new information. As the epileptic EEG representation varies among seizures, these generated samples cannot provide enough diversity to achieve high performance on a new seizure. As a consequence, we propose a novel data augmentation method with diffusion model called DiffEEG. Methods: Diffusion models are a class of generative models that consist of two processes. Specifically, in the diffusion process, the model adds noise to the input EEG sample step by step and converts the noisy sample into output random noise, exploring the distribution of data by minimizing the loss between the output and the noise added. In the denoised process, the model samples the synthetic data by removing the noise gradually, diffusing the data distribution to outward areas and narrowing the distance between different clusters. Results: We compared DiffEEG with existing methods, and integrated them into three representative classifiers. The experiments indicate that DiffEEG could further improve the performance and shows superiority to existing methods. Conclusion: This paper proposes a novel and effective method to solve the imbalanced problem and demonstrates the effectiveness and generality of our method.
A Surrogate Model Framework for Explainable Autonomous Behaviour
May 31, 2023
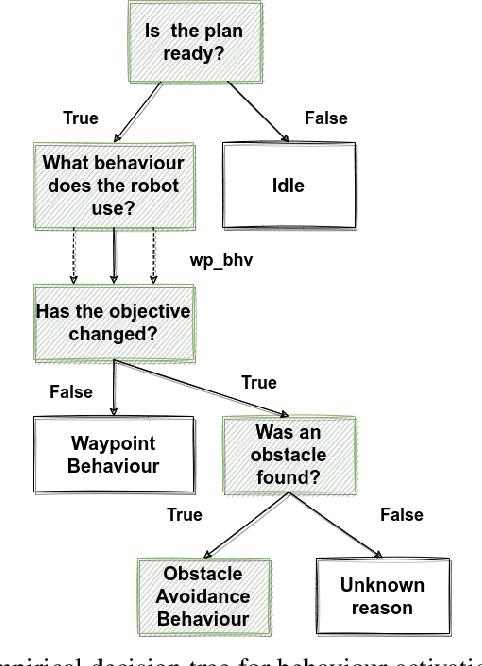
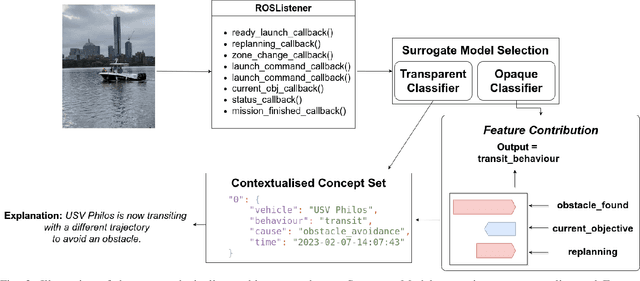
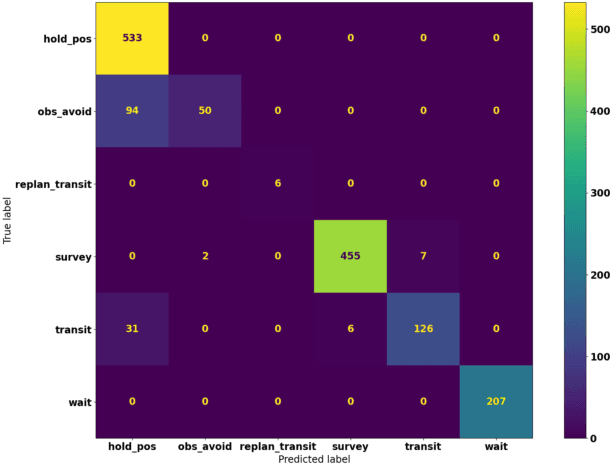
Adoption and deployment of robotic and autonomous systems in industry are currently hindered by the lack of transparency, required for safety and accountability. Methods for providing explanations are needed that are agnostic to the underlying autonomous system and easily updated. Furthermore, different stakeholders with varying levels of expertise, will require different levels of information. In this work, we use surrogate models to provide transparency as to the underlying policies for behaviour activation. We show that these surrogate models can effectively break down autonomous agents' behaviour into explainable components for use in natural language explanations.
Towards Fine-Grained Information: Identifying the Type and Location of Translation Errors
Feb 17, 2023
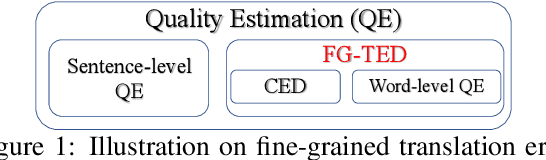
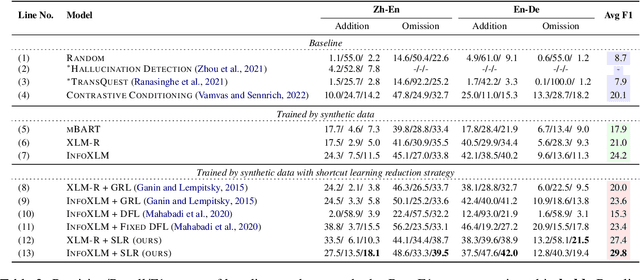
Fine-grained information on translation errors is helpful for the translation evaluation community. Existing approaches can not synchronously consider error position and type, failing to integrate the error information of both. In this paper, we propose Fine-Grained Translation Error Detection (FG-TED) task, aiming at identifying both the position and the type of translation errors on given source-hypothesis sentence pairs. Besides, we build an FG-TED model to predict the \textbf{addition} and \textbf{omission} errors -- two typical translation accuracy errors. First, we use a word-level classification paradigm to form our model and use the shortcut learning reduction to relieve the influence of monolingual features. Besides, we construct synthetic datasets for model training, and relieve the disagreement of data labeling in authoritative datasets, making the experimental benchmark concordant. Experiments show that our model can identify both error type and position concurrently, and gives state-of-the-art results on the restored dataset. Our model also delivers more reliable predictions on low-resource and transfer scenarios than existing baselines. The related datasets and the source code will be released in the future.
Spike timing reshapes robustness against attacks in spiking neural networks
Jun 09, 2023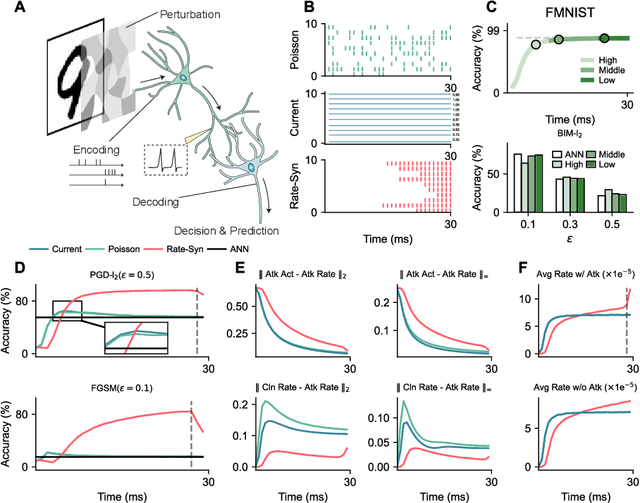
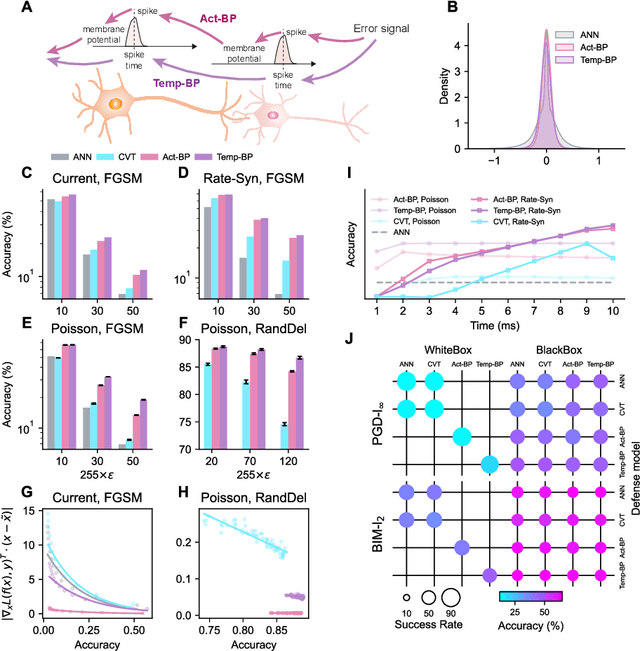
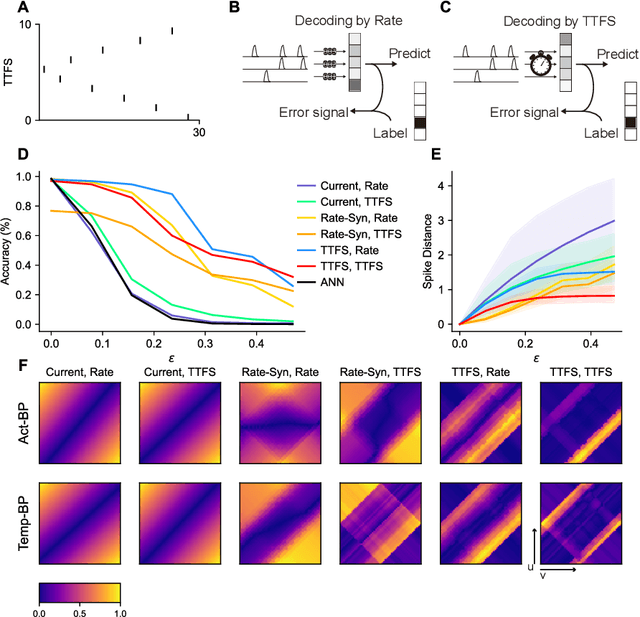
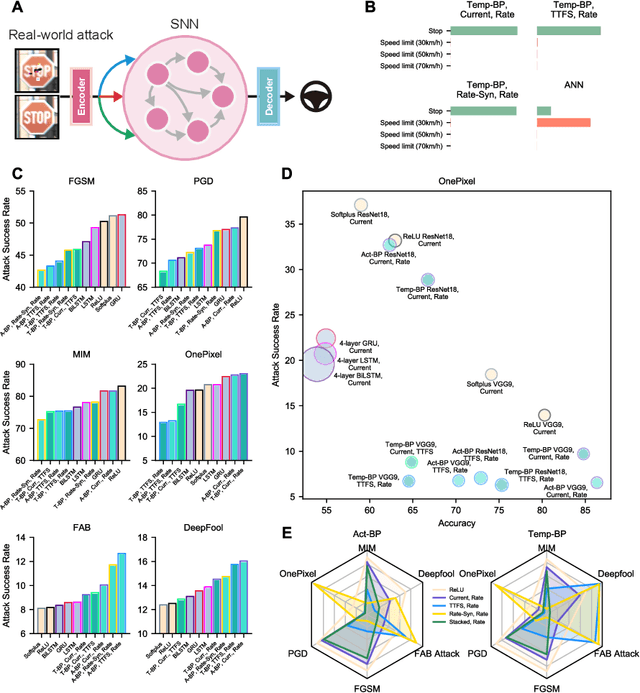
The success of deep learning in the past decade is partially shrouded in the shadow of adversarial attacks. In contrast, the brain is far more robust at complex cognitive tasks. Utilizing the advantage that neurons in the brain communicate via spikes, spiking neural networks (SNNs) are emerging as a new type of neural network model, boosting the frontier of theoretical investigation and empirical application of artificial neural networks and deep learning. Neuroscience research proposes that the precise timing of neural spikes plays an important role in the information coding and sensory processing of the biological brain. However, the role of spike timing in SNNs is less considered and far from understood. Here we systematically explored the timing mechanism of spike coding in SNNs, focusing on the robustness of the system against various types of attacks. We found that SNNs can achieve higher robustness improvement using the coding principle of precise spike timing in neural encoding and decoding, facilitated by different learning rules. Our results suggest that the utility of spike timing coding in SNNs could improve the robustness against attacks, providing a new approach to reliable coding principles for developing next-generation brain-inspired deep learning.
Communication-Efficient Zeroth-Order Distributed Online Optimization: Algorithm, Theory, and Applications
Jun 09, 2023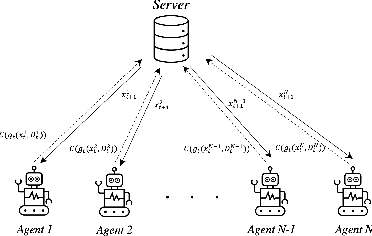
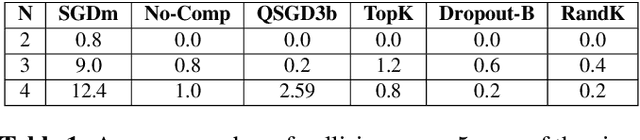
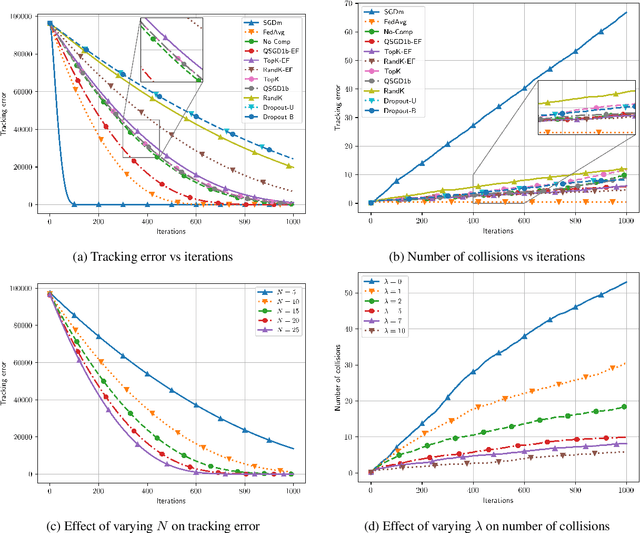
This paper focuses on a multi-agent zeroth-order online optimization problem in a federated learning setting for target tracking. The agents only sense their current distances to their targets and aim to maintain a minimum safe distance from each other to prevent collisions. The coordination among the agents and dissemination of collision-prevention information is managed by a central server using the federated learning paradigm. The proposed formulation leads to an instance of distributed online nonconvex optimization problem that is solved via a group of communication-constrained agents. To deal with the communication limitations of the agents, an error feedback-based compression scheme is utilized for agent-to-server communication. The proposed algorithm is analyzed theoretically for the general class of distributed online nonconvex optimization problems. We provide non-asymptotic convergence rates that show the dominant term is independent of the characteristics of the compression scheme. Our theoretical results feature a new approach that employs significantly more relaxed assumptions in comparison to standard literature. The performance of the proposed solution is further analyzed numerically in terms of tracking errors and collisions between agents in two relevant applications.