 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Dynamic Quantization for Diffusion Models
Jun 04, 2023
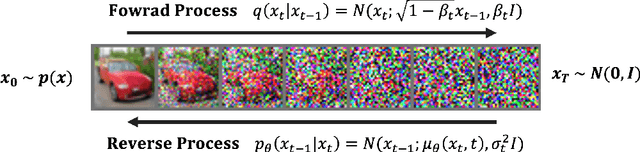
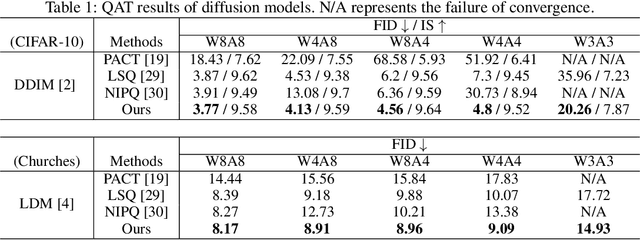
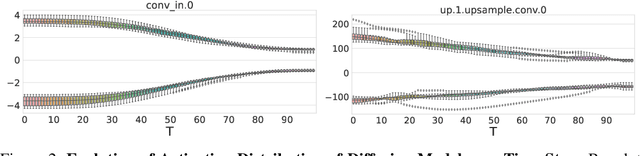
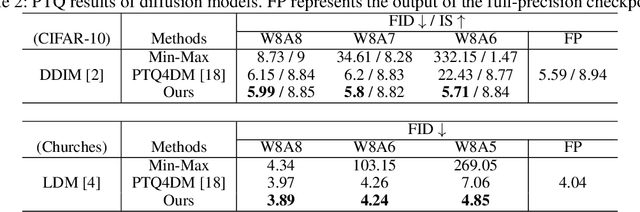
The diffusion model has gained popularity in vision applications due to its remarkable generative performance and versatility. However, high storage and computation demands, resulting from the model size and iterative generation, hinder its use on mobile devices. Existing quantization techniques struggle to maintain performance even in 8-bit precision due to the diffusion model's unique property of temporal variation in activation. We introduce a novel quantization method that dynamically adjusts the quantization interval based on time step information, significantly improving output quality. Unlike conventional dynamic quantization techniques, our approach has no computational overhead during inference and is compatible with both post-training quantization (PTQ) and quantization-aware training (QAT). Our extensive experiments demonstrate substantial improvements in output quality with the quantized diffusion model across various datasets.
Generating High-Quality Emotion Arcs For Low-Resource Languages Using Emotion Lexicons
Jun 03, 2023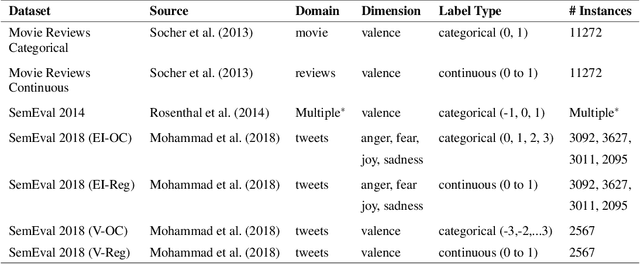
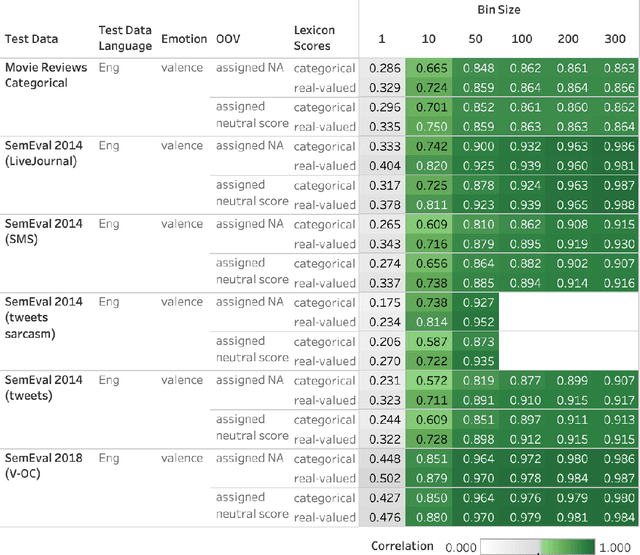

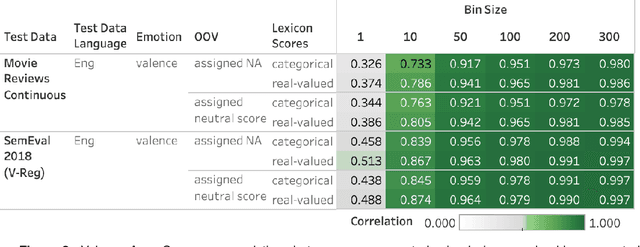
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs in English (where the emotion resources are available) and no work on generating or evaluating emotion arcs for low-resource languages. Work on generating emotion arcs in low-resource languages such as those indigenous to Africa, the Americas, and Australia is stymied by the lack of emotion-labeled resources and large language models for those languages. Work on evaluating emotion arcs (for any language) is scarce because of the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. By running experiments on 42 diverse datasets in 9 languages, we show that despite being markedly poor at instance level emotion classification, LexO methods are highly accurate at generating emotion arcs when aggregating information from hundreds of instances. (Predicted arcs have correlations ranging from 0.94 to 0.99 with the gold arcs for various emotions.) We also show that for languages with no emotion lexicons, automatic translations of English emotion lexicons can be used to generate high-quality emotion arcs -- correlations above 0.9 with the gold emotion arcs in all six indigenous African languages explored. This opens up avenues for work on emotions in numerous languages from around the world; crucial not only for commerce, public policy, and health research in service of speakers of those languages, but also to draw meaningful conclusions in emotion-pertinent research using information from around the world (thereby avoiding a western-centric bias in research).
IoT Localization and Optimized Topology Extraction Using Eigenvector Synchronization
May 28, 2023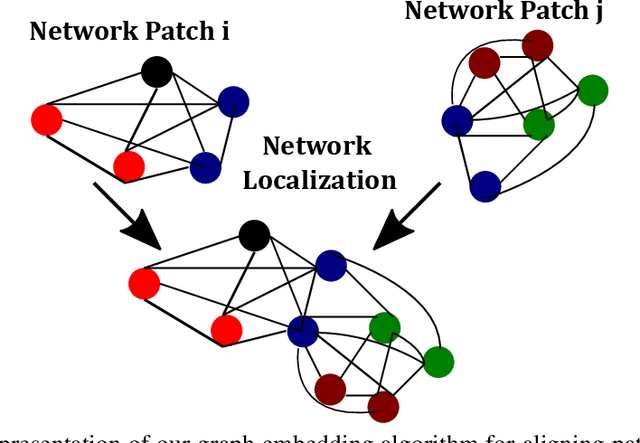
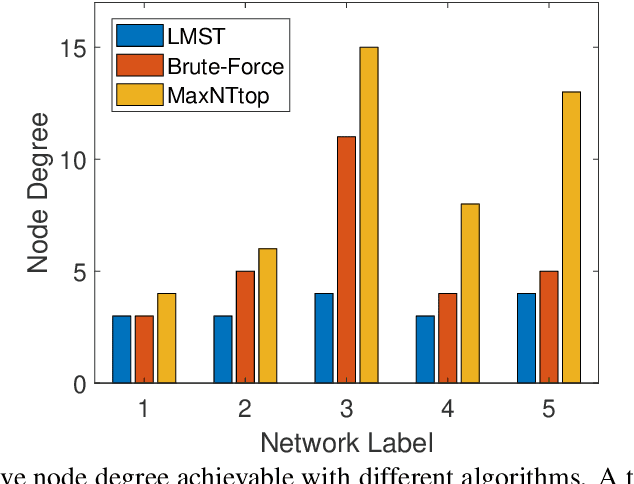
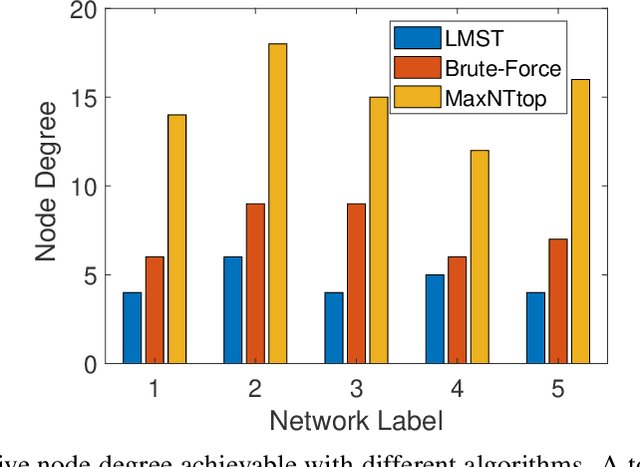
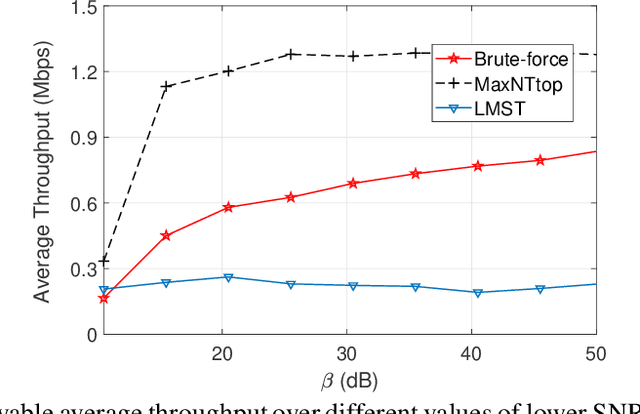
Internet-of-Things (IoT) devices are low size, weight and power (SWaP), low complexity and include sensors, meters, wearables and trackers. Transmitting information with high signal power is exacting on device battery life, therefore an efficient link and network configuration is absolutely crucial to avoid signal power enhancement in interference-rich environment and resorting to battery-life extending strategies. Efficient network configuration can also ensure fulfilment of network performance metrics like throughput, coding rate and spectral efficiency. We formulate a novel approach of first localizing the IoT nodes and then extracting the network topology for information exchange between the nodes (devices, gateway and sinks), such that overall network throughput is maximized. The nodes are localized using noisy measurements of a subset of Euclidean distances between two nodes. Realizable subsets of neighboring devices agree with their own position within the entire network graph through eigenvector synchronization. Using communication global graph-model-based technique, network topology is constructed in terms of transmit power allocation with the aim of maximizing spatial usage and overall network throughput. This topology extraction problem is solved using the concept of linear programming.
Enhance Reasoning Ability of Visual-Language Models via Large Language Models
May 22, 2023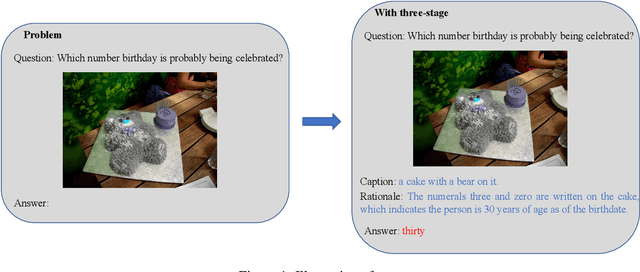


Pre-trained visual language models (VLM) have shown excellent performance in image caption tasks. However, it sometimes shows insufficient reasoning ability. In contrast, large language models (LLMs) emerge with powerful reasoning capabilities. Therefore, we propose a method called TReE, which transfers the reasoning ability of a large language model to a visual language model in zero-shot scenarios. TReE contains three stages: observation, thinking, and re-thinking. Observation stage indicates that VLM obtains the overall information of the relative image. Thinking stage combines the image information and task description as the prompt of the LLM, inference with the rationals. Re-Thinking stage learns from rationale and then inference the final result through VLM.
Pre-trained Language Model with Prompts for Temporal Knowledge Graph Completion
May 13, 2023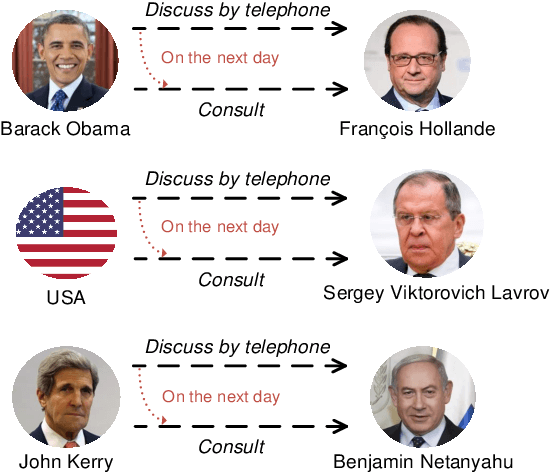
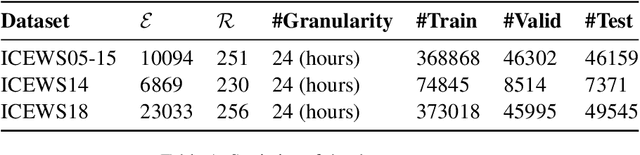
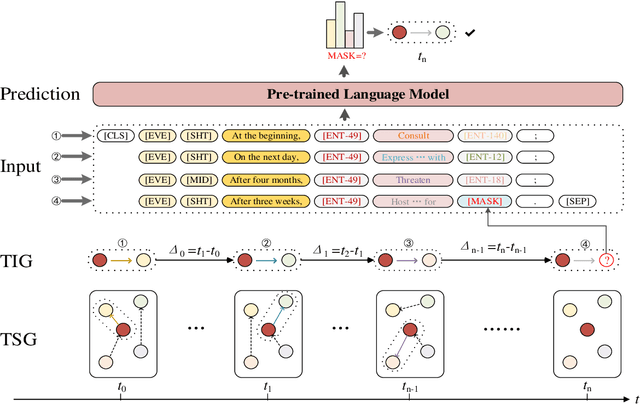

Temporal Knowledge graph completion (TKGC) is a crucial task that involves reasoning at known timestamps to complete the missing part of facts and has attracted more and more attention in recent years. Most existing methods focus on learning representations based on graph neural networks while inaccurately extracting information from timestamps and insufficiently utilizing the implied information in relations. To address these problems, we propose a novel TKGC model, namely Pre-trained Language Model with Prompts for TKGC (PPT). We convert a series of sampled quadruples into pre-trained language model inputs and convert intervals between timestamps into different prompts to make coherent sentences with implicit semantic information. We train our model with a masking strategy to convert TKGC task into a masked token prediction task, which can leverage the semantic information in pre-trained language models. Experiments on three benchmark datasets and extensive analysis demonstrate that our model has great competitiveness compared to other models with four metrics. Our model can effectively incorporate information from temporal knowledge graphs into the language models.
A Minimum Assumption Approach to MEG Sensor Array Design
Jun 15, 2023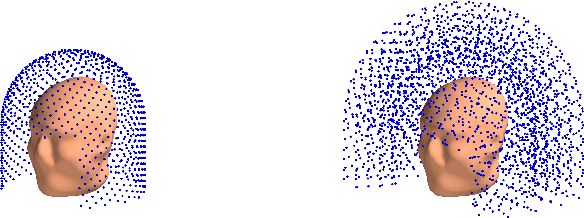
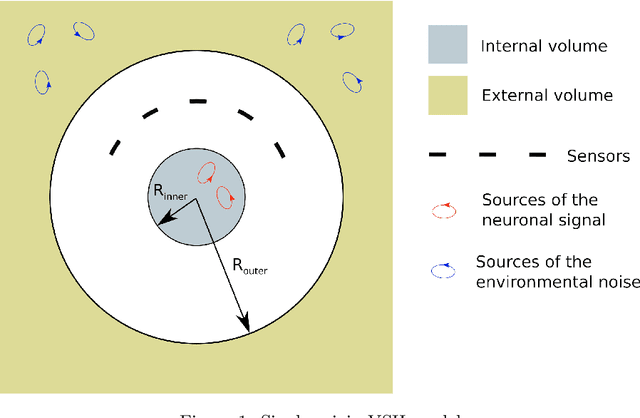
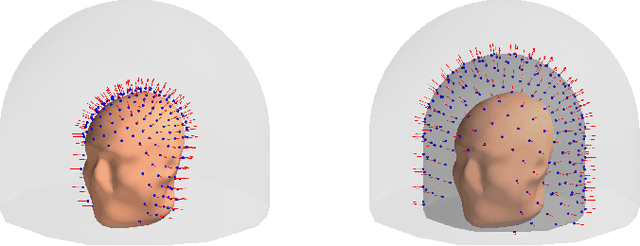
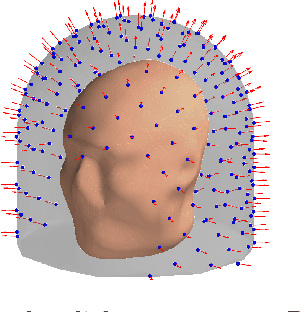
Objective: Our objective is to formulate the problem of the Magnetoencephalographic (MEG) sensor array design as a well-posed engineering problem of accurately measuring the neuronal magnetic fields. This is in contrast to the traditional approach that formulates the sensor array design problem in terms of neurobiological interpretability the sensor array measurements. Approach: We use the Vector Spherical Harmonics (VSH) formalism to define a figure-of-merit for an MEG sensor array. We start with an observation that, under certain reasonable assumptions, any array of $m$ perfectly noiseless sensors will attain exactly the same performance, regardless of the sensors' locations and orientations (with the exception of a negligible set of singularly bad sensor configurations). We proceed to the conclusion that under the aforementioned assumptions, the only difference between different array configurations is the effect of (sensor) noise on their performance. We then propose a figure-of-merit that quantifies, with a single number, how much the sensor array in question amplifies the sensor noise. Main results: We derive a formula for intuitively meaningful, yet mathematically rigorous figure-of-merit that summarizes how desirable a particular sensor array design is. We demonstrate that this figure-of-merit is well-behaved enough to be used as a cost function for a general-purpose nonlinear optimization methods such as simulated annealing. We also show that sensor array configurations obtained by such optimizations exhibit properties that are typically expected of high-quality MEG sensor arrays, e.g. high channel information capacity. Significance: Our work paves the way toward designing better MEG sensor arrays by isolating the engineering problem of measuring the neuromagnetic fields out of the bigger problem of studying brain function through neuromagnetic measurements.
Auditing for Human Expertise
Jun 02, 2023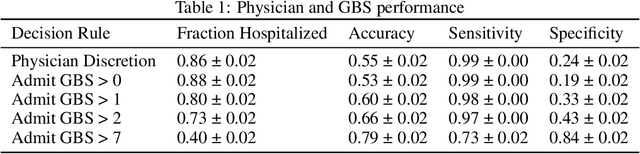
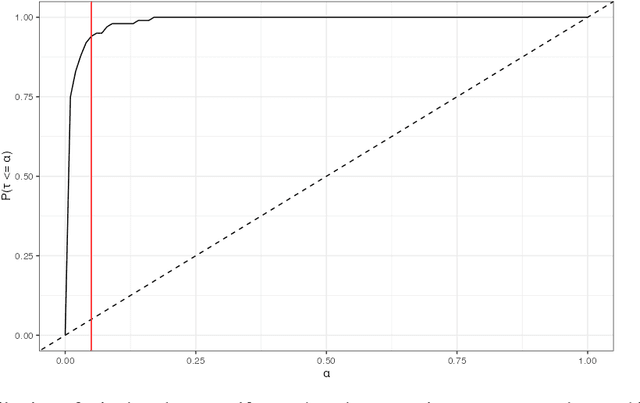

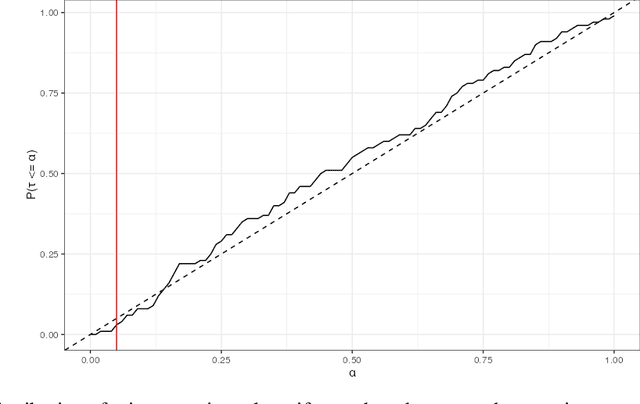
High-stakes prediction tasks (e.g., patient diagnosis) are often handled by trained human experts. A common source of concern about automation in these settings is that experts may exercise intuition that is difficult to model and/or have access to information (e.g., conversations with a patient) that is simply unavailable to a would-be algorithm. This raises a natural question whether human experts add value which could not be captured by an algorithmic predictor. We develop a statistical framework under which we can pose this question as a natural hypothesis test. Indeed, as our framework highlights, detecting human expertise is more subtle than simply comparing the accuracy of expert predictions to those made by a particular learning algorithm. Instead, we propose a simple procedure which tests whether expert predictions are statistically independent from the outcomes of interest after conditioning on the available inputs (`features'). A rejection of our test thus suggests that human experts may add value to any algorithm trained on the available data, and has direct implications for whether human-AI `complementarity' is achievable in a given prediction task. We highlight the utility of our procedure using admissions data collected from the emergency department of a large academic hospital system, where we show that physicians' admit/discharge decisions for patients with acute gastrointestinal bleeding (AGIB) appear to be incorporating information not captured in a standard algorithmic screening tool. This is despite the fact that the screening tool is arguably more accurate than physicians' discretionary decisions, highlighting that -- even absent normative concerns about accountability or interpretability -- accuracy is insufficient to justify algorithmic automation.
Atomic and Subgraph-aware Bilateral Aggregation for Molecular Representation Learning
May 22, 2023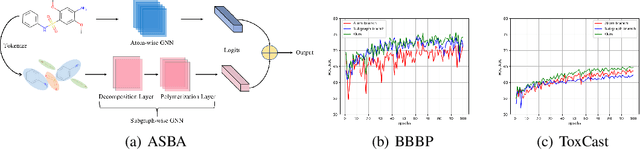

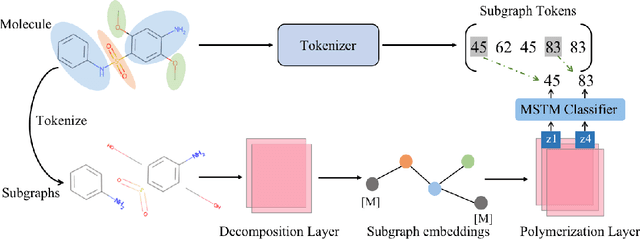
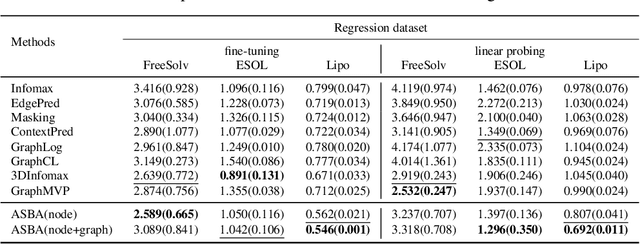
Molecular representation learning is a crucial task in predicting molecular properties. Molecules are often modeled as graphs where atoms and chemical bonds are represented as nodes and edges, respectively, and Graph Neural Networks (GNNs) have been commonly utilized to predict atom-related properties, such as reactivity and solubility. However, functional groups (subgraphs) are closely related to some chemical properties of molecules, such as efficacy, and metabolic properties, which cannot be solely determined by individual atoms. In this paper, we introduce a new model for molecular representation learning called the Atomic and Subgraph-aware Bilateral Aggregation (ASBA), which addresses the limitations of previous atom-wise and subgraph-wise models by incorporating both types of information. ASBA consists of two branches, one for atom-wise information and the other for subgraph-wise information. Considering existing atom-wise GNNs cannot properly extract invariant subgraph features, we propose a decomposition-polymerization GNN architecture for the subgraph-wise branch. Furthermore, we propose cooperative node-level and graph-level self-supervised learning strategies for ASBA to improve its generalization. Our method offers a more comprehensive way to learn representations for molecular property prediction and has broad potential in drug and material discovery applications. Extensive experiments have demonstrated the effectiveness of our method.
Web scraping: a promising tool for geographic data acquisition
May 31, 2023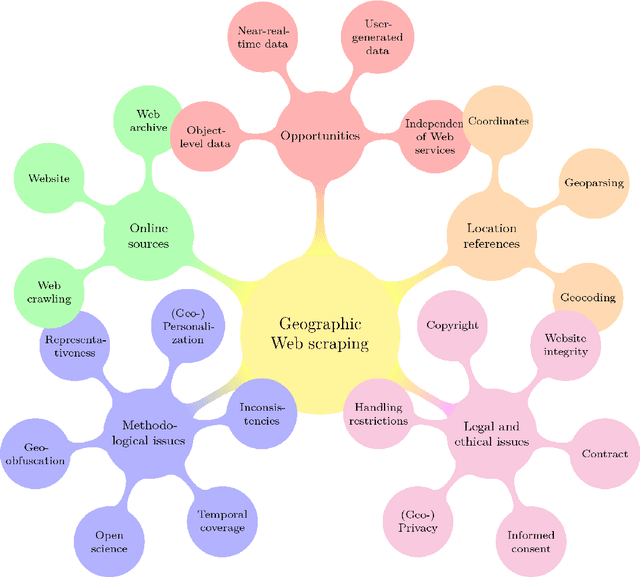
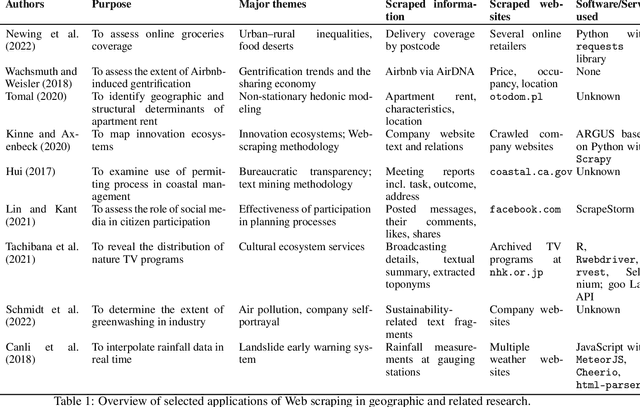
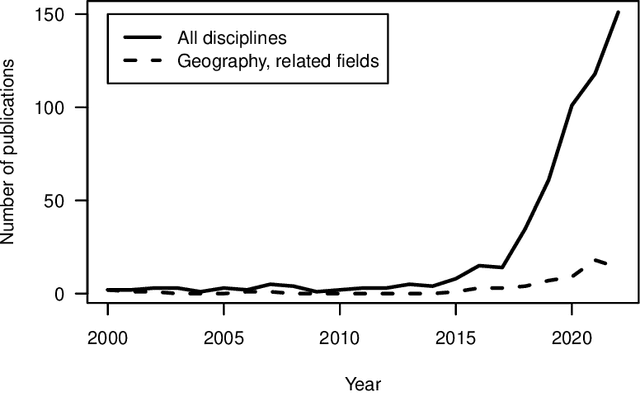
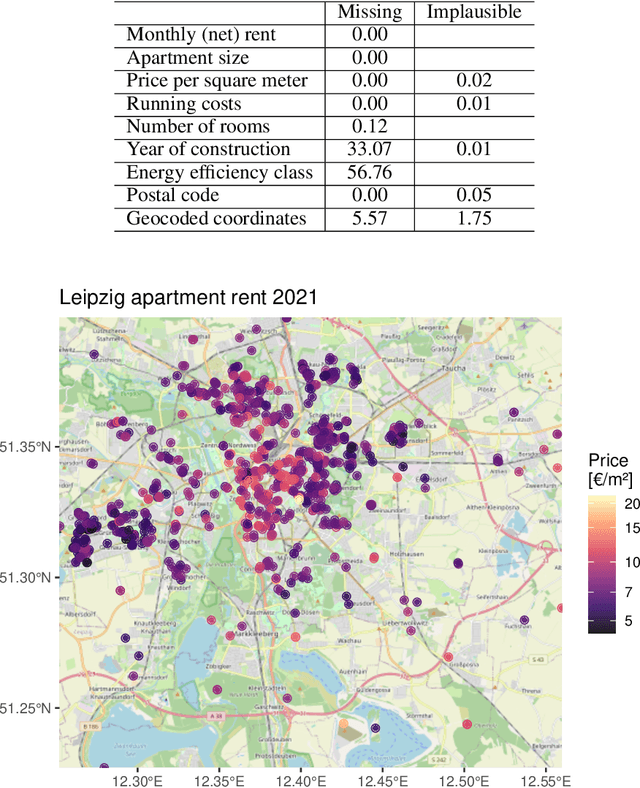
With much of our lives taking place online, researchers are increasingly turning to information from the World Wide Web to gain insights into geographic patterns and processes. Web scraping as an online data acquisition technique allows us to gather intelligence especially on social and economic actions for which the Web serves as a platform. Specific opportunities relate to near-real-time access to object-level geolocated data, which can be captured in a cost-effective way. The studied geographic phenomena include, but are not limited to, the rental market and associated processes such as gentrification, entrepreneurial ecosystems, or spatial planning processes. Since the information retrieved from the Web is not made available for that purpose, Web scraping faces several unique challenges, several of which relate to location. Ethical and legal issues mainly relate to intellectual property rights, informed consent and (geo-) privacy, and website integrity and contract. These issues also effect the practice of open science. In addition, there are technical and statistical challenges that relate to dependability and incompleteness, data inconsistencies and bias, as well as the limited historical coverage. Geospatial analyses furthermore usually require the automated extraction and subsequent resolution of toponyms or addresses (geoparsing, geocoding). A study on apartment rent in Leipzig, Germany is used to illustrate the use of Web scraping and its challenges. We conclude that geographic researchers should embrace Web scraping as a powerful and affordable digital fieldwork tool while paying special attention to its legal, ethical, and methodological challenges.
People and Places of Historical Europe: Bootstrapping Annotation Pipeline and a New Corpus of Named Entities in Late Medieval Texts
Jun 06, 2023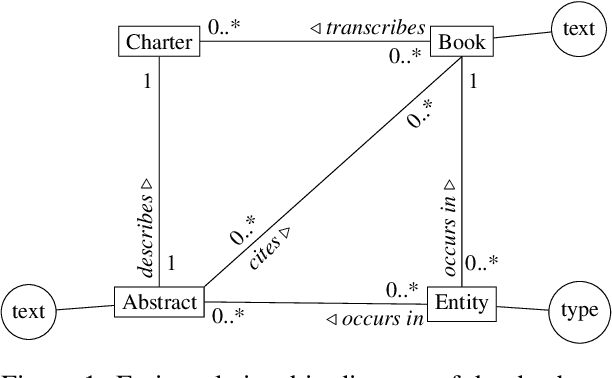
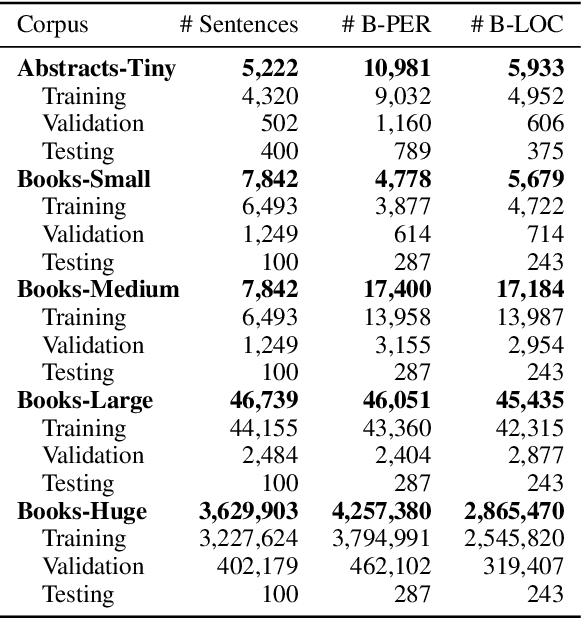
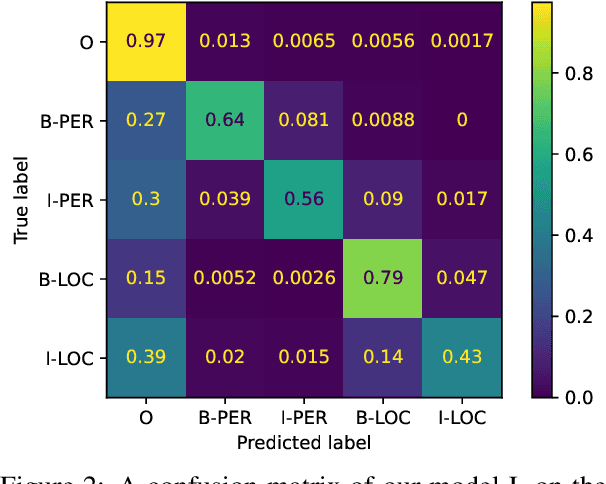
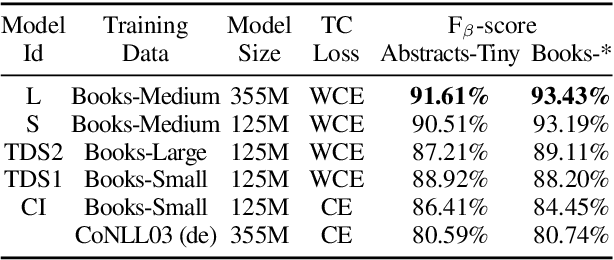
Although pre-trained named entity recognition (NER) models are highly accurate on modern corpora, they underperform on historical texts due to differences in language OCR errors. In this work, we develop a new NER corpus of 3.6M sentences from late medieval charters written mainly in Czech, Latin, and German. We show that we can start with a list of known historical figures and locations and an unannotated corpus of historical texts, and use information retrieval techniques to automatically bootstrap a NER-annotated corpus. Using our corpus, we train a NER model that achieves entity-level Precision of 72.81-93.98% with 58.14-81.77% Recall on a manually-annotated test dataset. Furthermore, we show that using a weighted loss function helps to combat class imbalance in token classification tasks. To make it easy for others to reproduce and build upon our work, we publicly release our corpus, models, and experimental code.