 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution
Jun 02, 2023
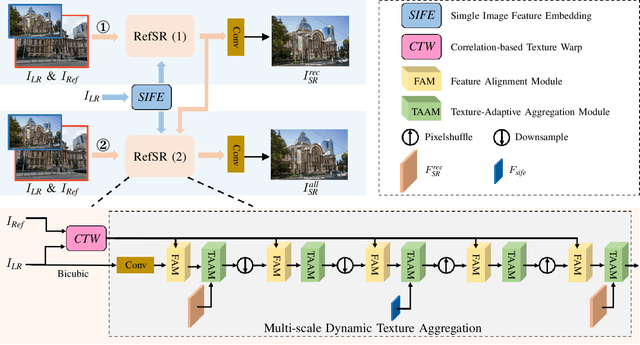
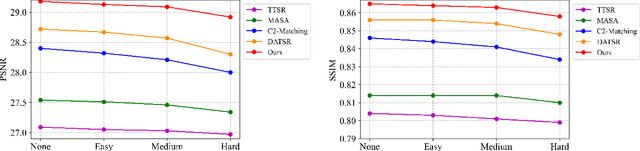

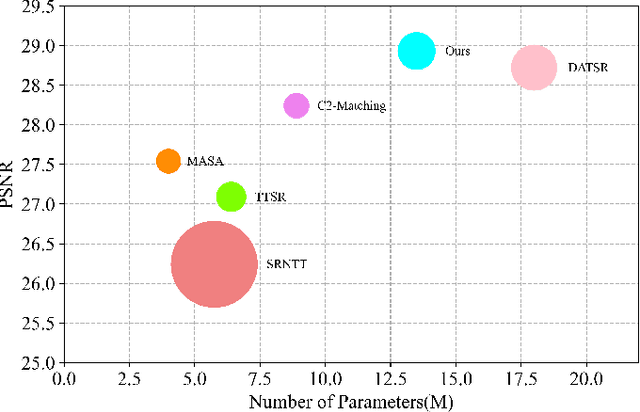
Reference-based super-resolution (RefSR) has gained considerable success in the field of super-resolution with the addition of high-resolution reference images to reconstruct low-resolution (LR) inputs with more high-frequency details, thereby overcoming some limitations of single image super-resolution (SISR). Previous research in the field of RefSR has mostly focused on two crucial aspects. The first is accurate correspondence matching between the LR and the reference (Ref) image. The second is the effective transfer and aggregation of similar texture information from the Ref images. Nonetheless, an important detail of perceptual loss and adversarial loss has been underestimated, which has a certain adverse effect on texture transfer and reconstruction. In this study, we propose a feature reuse framework that guides the step-by-step texture reconstruction process through different stages, reducing the negative impacts of perceptual and adversarial loss. The feature reuse framework can be used for any RefSR model, and several RefSR approaches have improved their performance after being retrained using our framework. Additionally, we introduce a single image feature embedding module and a texture-adaptive aggregation module. The single image feature embedding module assists in reconstructing the features of the LR inputs itself and effectively lowers the possibility of including irrelevant textures. The texture-adaptive aggregation module dynamically perceives and aggregates texture information between the LR inputs and the Ref images using dynamic filters. This enhances the utilization of the reference texture while reducing reference misuse. The source code is available at https://github.com/Yi-Yang355/FRFSR.
Analyzing Credit Risk Model Problems through NLP-Based Clustering and Machine Learning: Insights from Validation Reports
Jun 02, 2023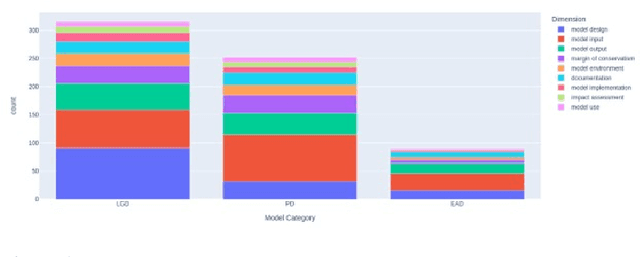
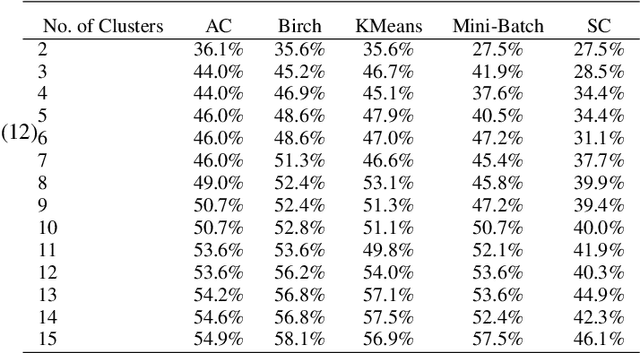
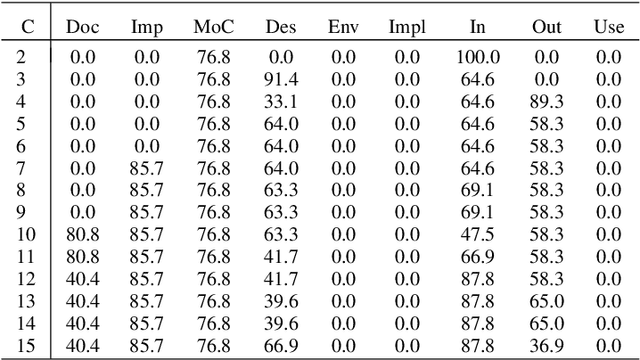
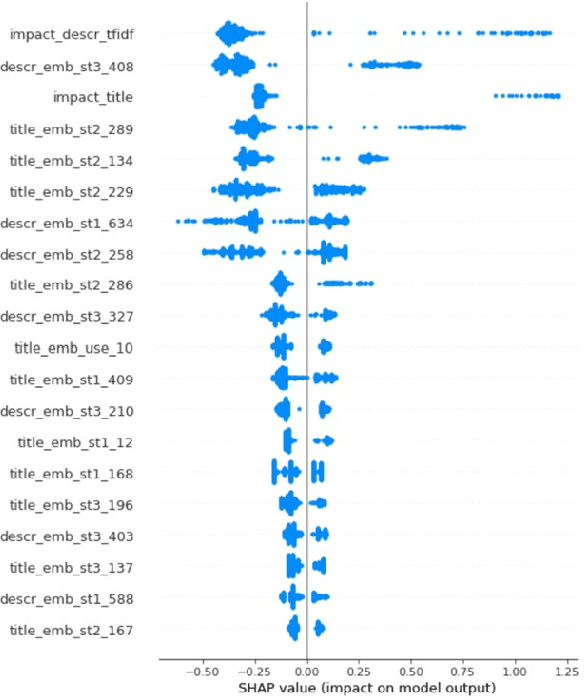
This paper explores the use of clustering methods and machine learning algorithms, including Natural Language Processing (NLP), to identify and classify problems identified in credit risk models through textual information contained in validation reports. Using a unique dataset of 657 findings raised by validation teams in a large international banking group between January 2019 and December 2022. The findings are classified into nine validation dimensions and assigned a severity level by validators using their expert knowledge. The authors use embedding generation for the findings' titles and observations using four different pre-trained models, including "module\_url" from TensorFlow Hub and three models from the SentenceTransformer library, namely "all-mpnet-base-v2", "all-MiniLM-L6-v2", and "paraphrase-mpnet-base-v2". The paper uses and compares various clustering methods in grouping findings with similar characteristics, enabling the identification of common problems within each validation dimension and severity. The results of the study show that clustering is an effective approach for identifying and classifying credit risk model problems with accuracy higher than 60\%. The authors also employ machine learning algorithms, including logistic regression and XGBoost, to predict the validation dimension and its severity, achieving an accuracy of 80\% for XGBoost algorithm. Furthermore, the study identifies the top 10 words that predict a validation dimension and severity. Overall, this paper makes a contribution by demonstrating the usefulness of clustering and machine learning for analyzing textual information in validation reports, and providing insights into the types of problems encountered in the development and validation of credit risk models.
Bi-VLGM : Bi-Level Class-Severity-Aware Vision-Language Graph Matching for Text Guided Medical Image Segmentation
May 20, 2023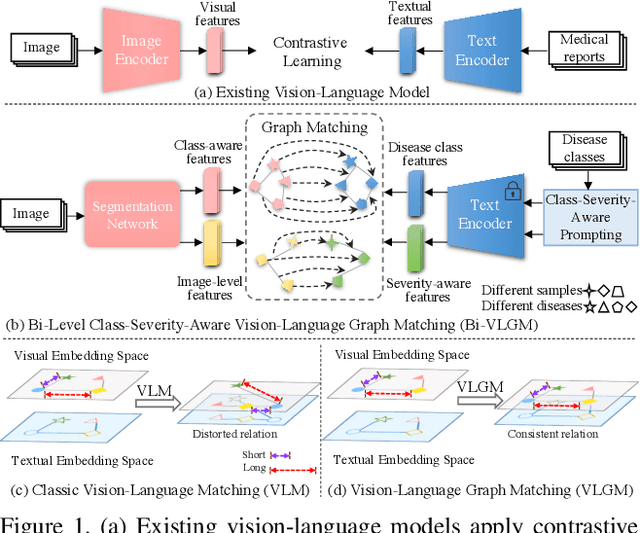

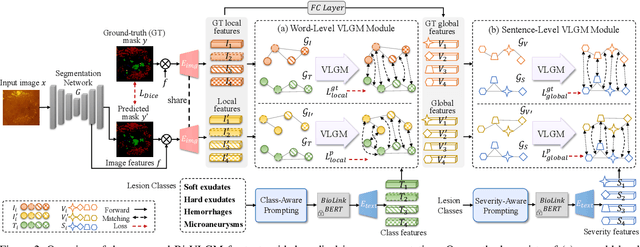
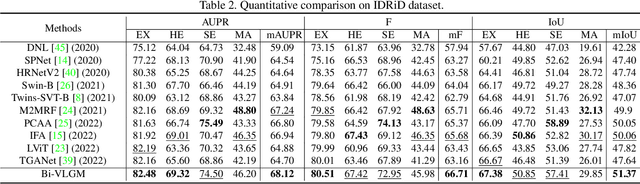
Medical reports with substantial information can be naturally complementary to medical images for computer vision tasks, and the modality gap between vision and language can be solved by vision-language matching (VLM). However, current vision-language models distort the intra-model relation and mainly include class information in prompt learning that is insufficient for segmentation task. In this paper, we introduce a Bi-level class-severity-aware Vision-Language Graph Matching (Bi-VLGM) for text guided medical image segmentation, composed of a word-level VLGM module and a sentence-level VLGM module, to exploit the class-severity-aware relation among visual-textual features. In word-level VLGM, to mitigate the distorted intra-modal relation during VLM, we reformulate VLM as graph matching problem and introduce a vision-language graph matching (VLGM) to exploit the high-order relation among visual-textual features. Then, we perform VLGM between the local features for each class region and class-aware prompts to bridge their gap. In sentence-level VLGM, to provide disease severity information for segmentation task, we introduce a severity-aware prompting to quantify the severity level of retinal lesion, and perform VLGM between the global features and the severity-aware prompts. By exploiting the relation between the local (global) and class (severity) features, the segmentation model can selectively learn the class-aware and severity-aware information to promote performance. Extensive experiments prove the effectiveness of our method and its superiority to existing methods. Source code is to be released.
Understanding the Role of Feedback in Online Learning with Switching Costs
Jun 16, 2023
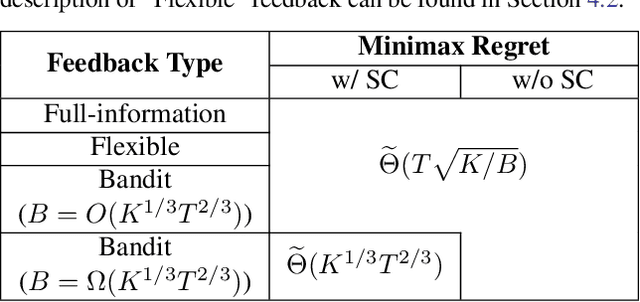
In this paper, we study the role of feedback in online learning with switching costs. It has been shown that the minimax regret is $\widetilde{\Theta}(T^{2/3})$ under bandit feedback and improves to $\widetilde{\Theta}(\sqrt{T})$ under full-information feedback, where $T$ is the length of the time horizon. However, it remains largely unknown how the amount and type of feedback generally impact regret. To this end, we first consider the setting of bandit learning with extra observations; that is, in addition to the typical bandit feedback, the learner can freely make a total of $B_{\mathrm{ex}}$ extra observations. We fully characterize the minimax regret in this setting, which exhibits an interesting phase-transition phenomenon: when $B_{\mathrm{ex}} = O(T^{2/3})$, the regret remains $\widetilde{\Theta}(T^{2/3})$, but when $B_{\mathrm{ex}} = \Omega(T^{2/3})$, it becomes $\widetilde{\Theta}(T/\sqrt{B_{\mathrm{ex}}})$, which improves as the budget $B_{\mathrm{ex}}$ increases. To design algorithms that can achieve the minimax regret, it is instructive to consider a more general setting where the learner has a budget of $B$ total observations. We fully characterize the minimax regret in this setting as well and show that it is $\widetilde{\Theta}(T/\sqrt{B})$, which scales smoothly with the total budget $B$. Furthermore, we propose a generic algorithmic framework, which enables us to design different learning algorithms that can achieve matching upper bounds for both settings based on the amount and type of feedback. One interesting finding is that while bandit feedback can still guarantee optimal regret when the budget is relatively limited, it no longer suffices to achieve optimal regret when the budget is relatively large.
MultiEarth 2023 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Jun 07, 2023
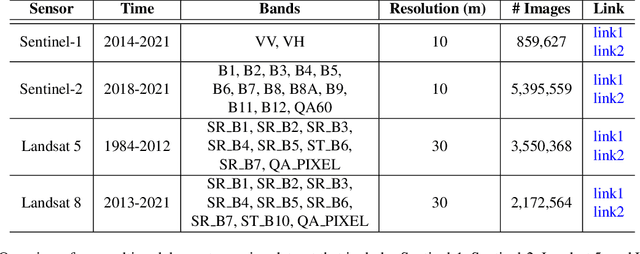

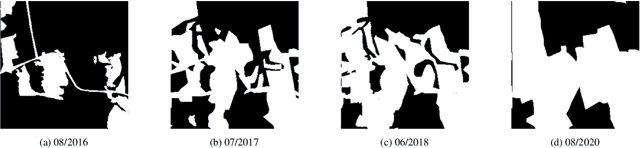
The Multimodal Learning for Earth and Environment Workshop (MultiEarth 2023) is the second annual CVPR workshop aimed at the monitoring and analysis of the health of Earth ecosystems by leveraging the vast amount of remote sensing data that is continuously being collected. The primary objective of this workshop is to bring together the Earth and environmental science communities as well as the multimodal representation learning communities to explore new ways of harnessing technological advancements in support of environmental monitoring. The MultiEarth Workshop also seeks to provide a common benchmark for processing multimodal remote sensing information by organizing public challenges focused on monitoring the Amazon rainforest. These challenges include estimating deforestation, detecting forest fires, translating synthetic aperture radar (SAR) images to the visible domain, and projecting environmental trends. This paper presents the challenge guidelines, datasets, and evaluation metrics. Our challenge website is available at https://sites.google.com/view/rainforest-challenge/multiearth-2023.
Differentiable Earth Mover's Distance for Data Compression at the High-Luminosity LHC
Jun 07, 2023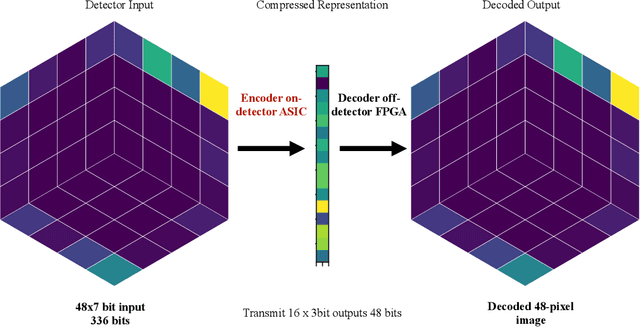
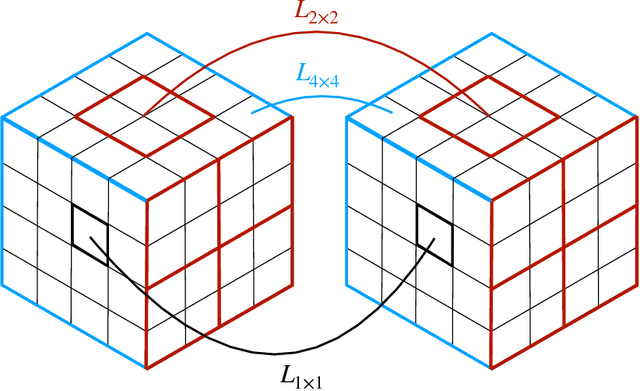
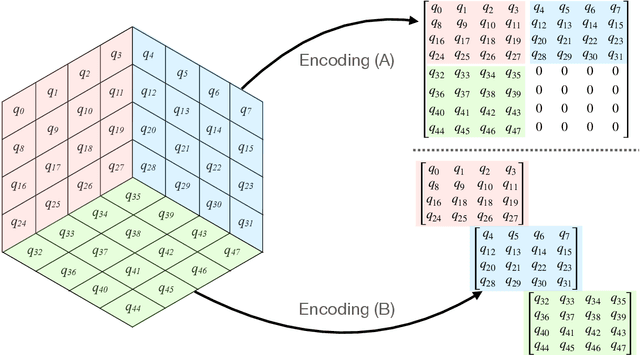
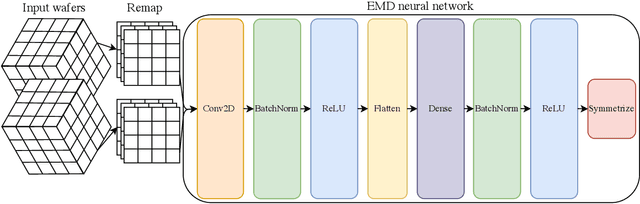
The Earth mover's distance (EMD) is a useful metric for image recognition and classification, but its usual implementations are not differentiable or too slow to be used as a loss function for training other algorithms via gradient descent. In this paper, we train a convolutional neural network (CNN) to learn a differentiable, fast approximation of the EMD and demonstrate that it can be used as a substitute for computing-intensive EMD implementations. We apply this differentiable approximation in the training of an autoencoder-inspired neural network (encoder NN) for data compression at the high-luminosity LHC at CERN. The goal of this encoder NN is to compress the data while preserving the information related to the distribution of energy deposits in particle detectors. We demonstrate that the performance of our encoder NN trained using the differentiable EMD CNN surpasses that of training with loss functions based on mean squared error.
Do we become wiser with time? On causal equivalence with tiered background knowledge
Jun 02, 2023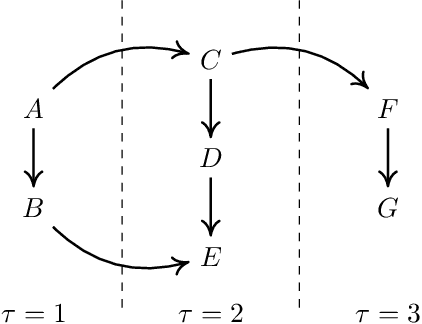
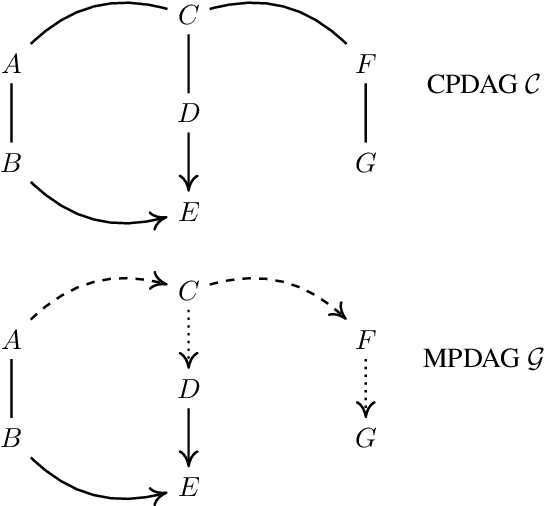
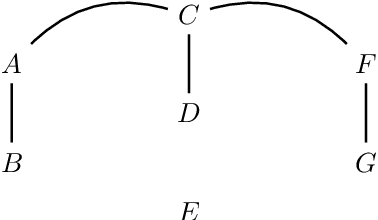
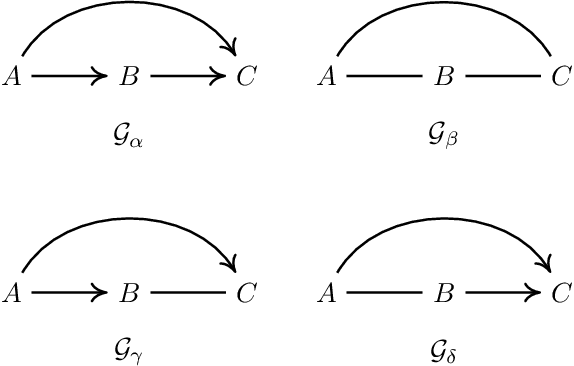
Equivalence classes of DAGs (represented by CPDAGs) may be too large to provide useful causal information. Here, we address incorporating tiered background knowledge yielding restricted equivalence classes represented by 'tiered MPDAGs'. Tiered knowledge leads to considerable gains in informativeness and computational efficiency: We show that construction of tiered MPDAGs only requires application of Meek's 1st rule, and that tiered MPDAGs (unlike general MPDAGs) are chain graphs with chordal components. This entails simplifications e.g. of determining valid adjustment sets for causal effect estimation. Further, we characterise when one tiered ordering is more informative than another, providing insights into useful aspects of background knowledge.
Towards Argument-Aware Abstractive Summarization of Long Legal Opinions with Summary Reranking
Jun 01, 2023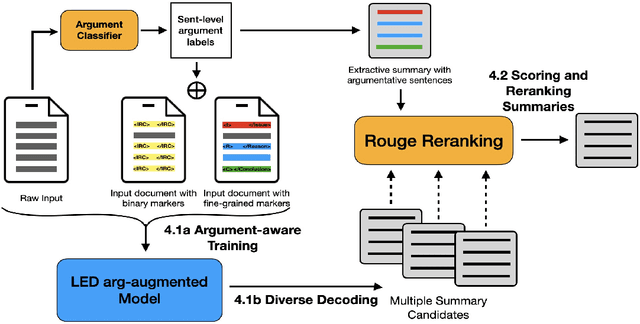
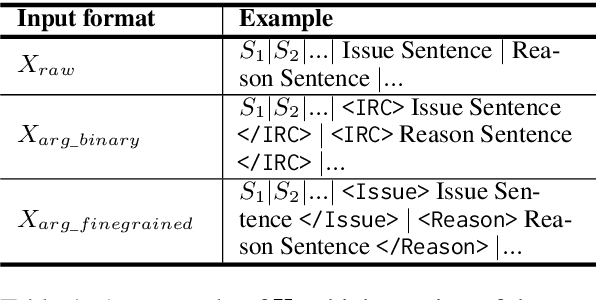
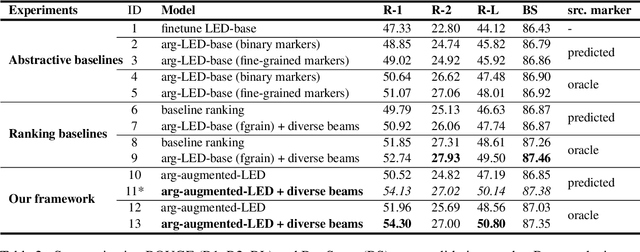
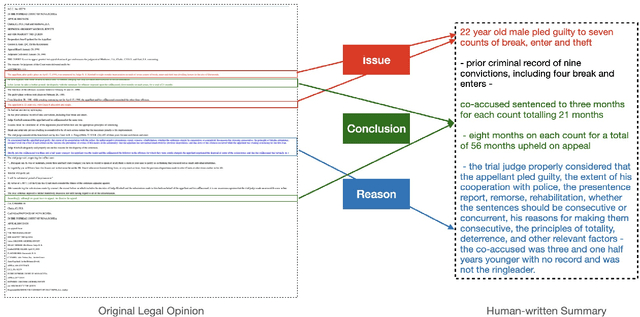
We propose a simple approach for the abstractive summarization of long legal opinions that considers the argument structure of the document. Legal opinions often contain complex and nuanced argumentation, making it challenging to generate a concise summary that accurately captures the main points of the legal opinion. Our approach involves using argument role information to generate multiple candidate summaries, then reranking these candidates based on alignment with the document's argument structure. We demonstrate the effectiveness of our approach on a dataset of long legal opinions and show that it outperforms several strong baselines.
SRRM: Semantic Region Relation Model for Indoor Scene Recognition
May 15, 2023
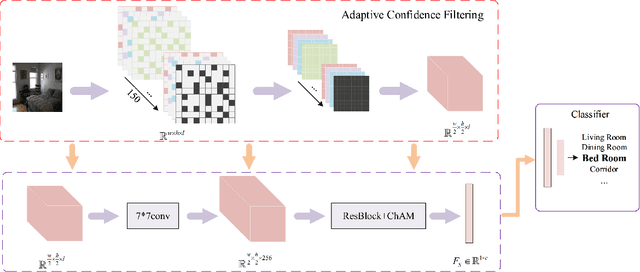
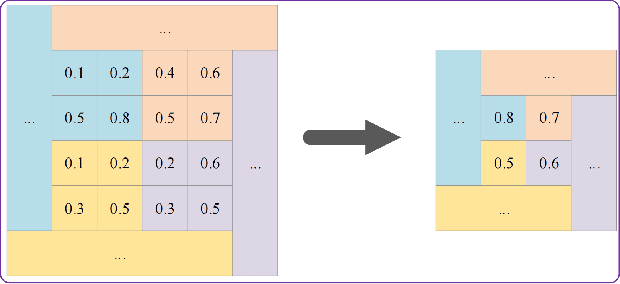
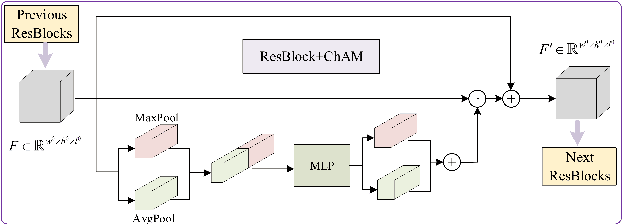
Despite the remarkable success of convolutional neural networks in various computer vision tasks, recognizing indoor scenes still presents a significant challenge due to their complex composition. Consequently, effectively leveraging semantic information in the scene has been a key issue in advancing indoor scene recognition. Unfortunately, the accuracy of semantic segmentation has limited the effectiveness of existing approaches for leveraging semantic information. As a result, many of these approaches remain at the stage of auxiliary labeling or co-occurrence statistics, with few exploring the contextual relationships between the semantic elements directly within the scene. In this paper, we propose the Semantic Region Relationship Model (SRRM), which starts directly from the semantic information inside the scene. Specifically, SRRM adopts an adaptive and efficient approach to mitigate the negative impact of semantic ambiguity and then models the semantic region relationship to perform scene recognition. Additionally, to more comprehensively exploit the information contained in the scene, we combine the proposed SRRM with the PlacesCNN module to create the Combined Semantic Region Relation Model (CSRRM), and propose a novel information combining approach to effectively explore the complementary contents between them. CSRRM significantly outperforms the SOTA methods on the MIT Indoor 67, reduced Places365 dataset, and SUN RGB-D without retraining. The code is available at: https://github.com/ChuanxinSong/SRRM
S$^{3}$: Increasing GPU Utilization during Generative Inference for Higher Throughput
Jun 09, 2023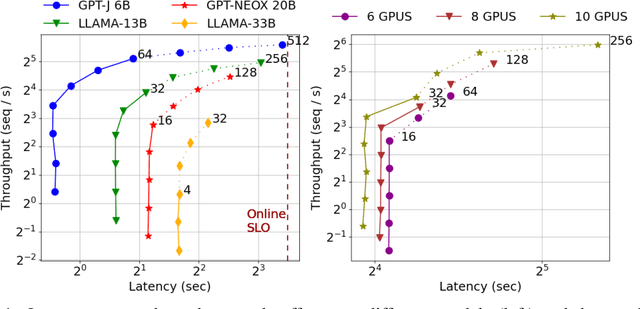
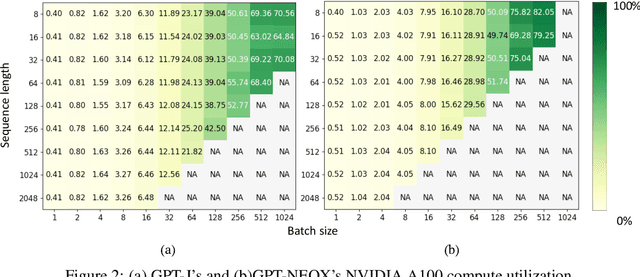
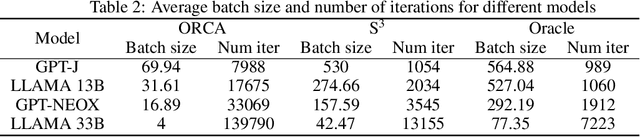
Generating texts with a large language model (LLM) consumes massive amounts of memory. Apart from the already-large model parameters, the key/value (KV) cache that holds information about previous tokens in a sequence can grow to be even larger than the model itself. This problem is exacerbated in one of the current LLM serving frameworks which reserves the maximum sequence length of memory for the KV cache to guarantee generating a complete sequence as they do not know the output sequence length. This restricts us to use a smaller batch size leading to lower GPU utilization and above all, lower throughput. We argue that designing a system with a priori knowledge of the output sequence can mitigate this problem. To this end, we propose S$^{3}$, which predicts the output sequence length, schedules generation queries based on the prediction to increase device resource utilization and throughput, and handle mispredictions. Our proposed method achieves 6.49$\times$ throughput over those systems that assume the worst case for the output sequence length.