 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
May 22, 2023
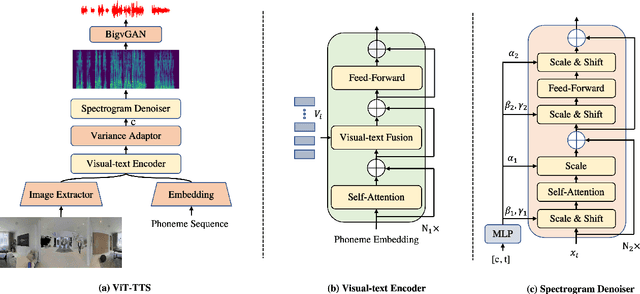
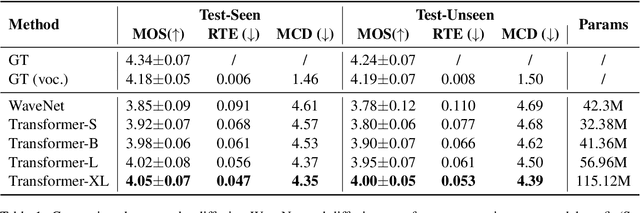
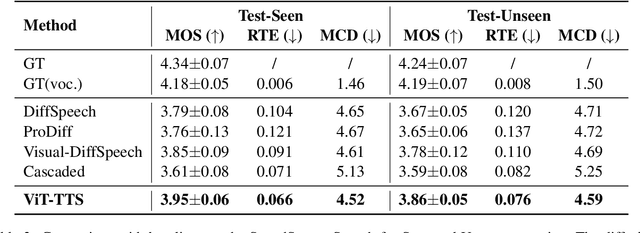
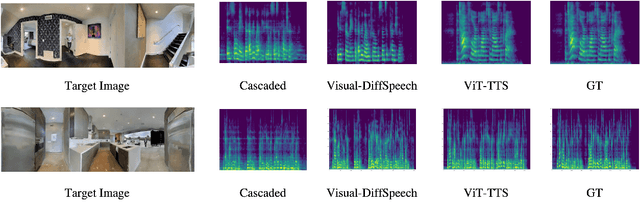
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~\footnote{Audio samples are available at \url{https://ViT-TTS.github.io/.}}
Spatiotemporal Attention-based Semantic Compression for Real-time Video Recognition
May 22, 2023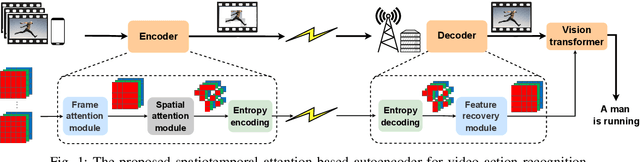

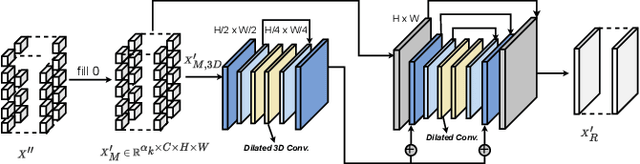
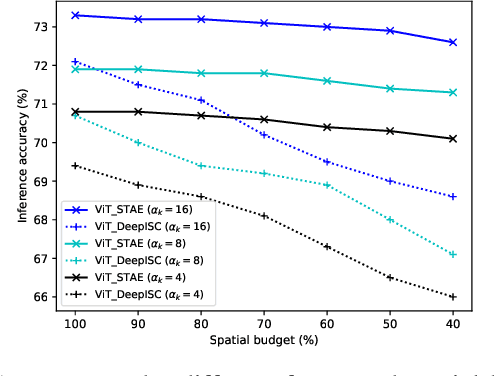
This paper studies the computational offloading of video action recognition in edge computing. To achieve effective semantic information extraction and compression, following semantic communication we propose a novel spatiotemporal attention-based autoencoder (STAE) architecture, including a frame attention module and a spatial attention module, to evaluate the importance of frames and pixels in each frame. Additionally, we use entropy encoding to remove statistical redundancy in the compressed data to further reduce communication overhead. At the receiver, we develop a lightweight decoder that leverages a 3D-2D CNN combined architecture to reconstruct missing information by simultaneously learning temporal and spatial information from the received data to improve accuracy. To fasten convergence, we use a step-by-step approach to train the resulting STAE-based vision transformer (ViT_STAE) models. Experimental results show that ViT_STAE can compress the video dataset HMDB51 by 104x with only 5% accuracy loss, outperforming the state-of-the-art baseline DeepISC. The proposed ViT_STAE achieves faster inference and higher accuracy than the DeepISC-based ViT model under time-varying wireless channel, which highlights the effectiveness of STAE in guaranteeing higher accuracy under time constraints.
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection
May 22, 2023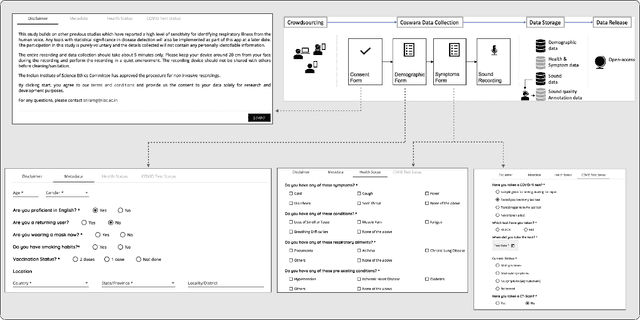
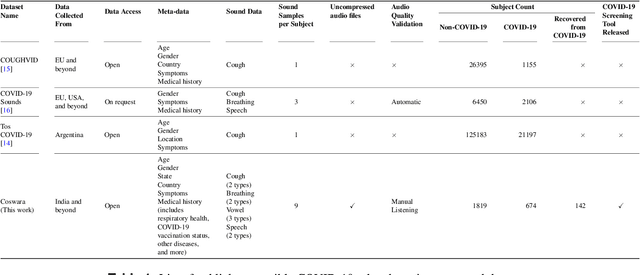
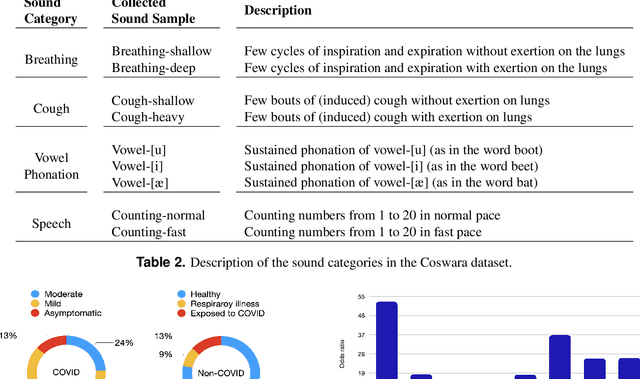
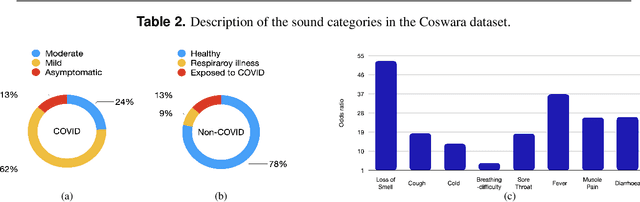
This paper presents the Coswara dataset, a dataset containing diverse set of respiratory sounds and rich meta-data, recorded between April-2020 and February-2022 from 2635 individuals (1819 SARS-CoV-2 negative, 674 positive, and 142 recovered subjects). The respiratory sounds contained nine sound categories associated with variants of breathing, cough and speech. The rich metadata contained demographic information associated with age, gender and geographic location, as well as the health information relating to the symptoms, pre-existing respiratory ailments, comorbidity and SARS-CoV-2 test status. Our study is the first of its kind to manually annotate the audio quality of the entire dataset (amounting to 65~hours) through manual listening. The paper summarizes the data collection procedure, demographic, symptoms and audio data information. A COVID-19 classifier based on bi-directional long short-term (BLSTM) architecture, is trained and evaluated on the different population sub-groups contained in the dataset to understand the bias/fairness of the model. This enabled the analysis of the impact of gender, geographic location, date of recording, and language proficiency on the COVID-19 detection performance.
Meta-Learning Online Adaptation of Language Models
May 24, 2023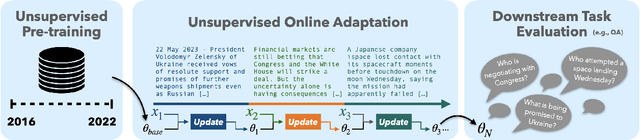


Large language models encode surprisingly broad knowledge about the world into their parameters. However, the knowledge in static language models can fall out of date, limiting the model's effective "shelf life." While online fine-tuning can reduce this degradation, we find that fine-tuning on a stream of documents using standard optimizers such as Adam leads to a disappointingly low level of information uptake. We hypothesize that online fine-tuning does not sufficiently 'attend' to important information. That is, the gradient signal from important tokens representing factual information is drowned out by the gradient from inherently noisy tokens, suggesting a dynamic, context-aware learning rate may be beneficial. To test this hypothesis, we meta-train a small, autoregressive model to reweight the language modeling loss for each token during online fine-tuning, with the objective of maximizing the out-of-date base language model's ability to answer questions about a document after a single weighted gradient step. We call this approach Context-aware Meta-learned Loss Scaling (CaMeLS). Across three different distributions of documents, our experiments find that fine-tuning on streams of thousands of documents with CaMeLS substantially improves knowledge retention compared to standard online fine-tuning. Finally, we find that the meta-learned weights are general, and that a single reweighting model can be used to enhance the online adaptation of many LMs.
Collaborative Recommendation Model Based on Multi-modal Multi-view Attention Network: Movie and literature cases
May 24, 2023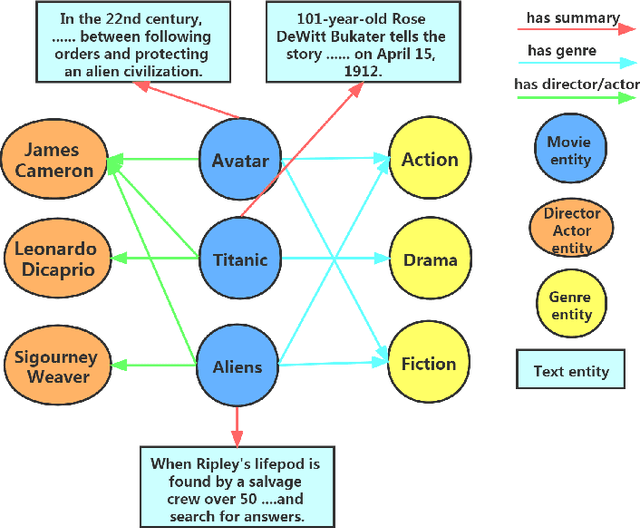

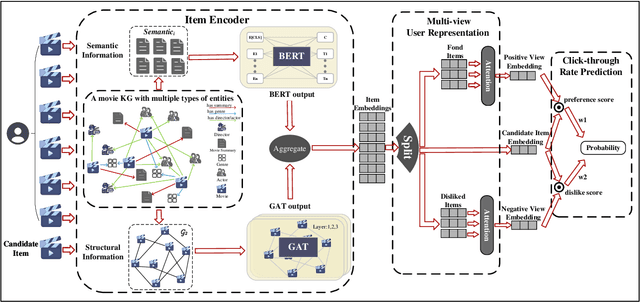
The existing collaborative recommendation models that use multi-modal information emphasize the representation of users' preferences but easily ignore the representation of users' dislikes. Nevertheless, modelling users' dislikes facilitates comprehensively characterizing user profiles. Thus, the representation of users' dislikes should be integrated into the user modelling when we construct a collaborative recommendation model. In this paper, we propose a novel Collaborative Recommendation Model based on Multi-modal multi-view Attention Network (CRMMAN), in which the users are represented from both preference and dislike views. Specifically, the users' historical interactions are divided into positive and negative interactions, used to model the user's preference and dislike views, respectively. Furthermore, the semantic and structural information extracted from the scene is employed to enrich the item representation. We validate CRMMAN by designing contrast experiments based on two benchmark MovieLens-1M and Book-Crossing datasets. Movielens-1m has about a million ratings, and Book-Crossing has about 300,000 ratings. Compared with the state-of-the-art knowledge-graph-based and multi-modal recommendation methods, the AUC, NDCG@5 and NDCG@10 are improved by 2.08%, 2.20% and 2.26% on average of two datasets. We also conduct controlled experiments to explore the effects of multi-modal information and multi-view mechanism. The experimental results show that both of them enhance the model's performance.
S$^{3}$: Increasing GPU Utilization during Generative Inference for Higher Throughput
Jun 09, 2023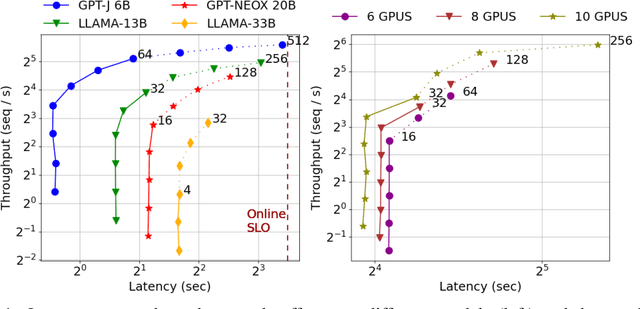
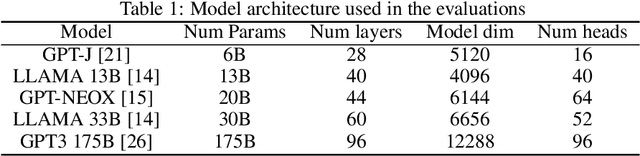
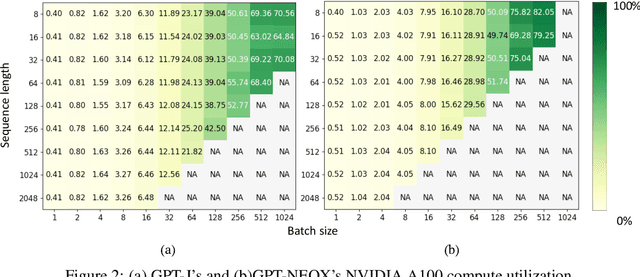
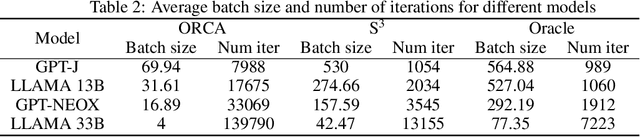
Generating texts with a large language model (LLM) consumes massive amounts of memory. Apart from the already-large model parameters, the key/value (KV) cache that holds information about previous tokens in a sequence can grow to be even larger than the model itself. This problem is exacerbated in one of the current LLM serving frameworks which reserves the maximum sequence length of memory for the KV cache to guarantee generating a complete sequence as they do not know the output sequence length. This restricts us to use a smaller batch size leading to lower GPU utilization and above all, lower throughput. We argue that designing a system with a priori knowledge of the output sequence can mitigate this problem. To this end, we propose S$^{3}$, which predicts the output sequence length, schedules generation queries based on the prediction to increase device resource utilization and throughput, and handle mispredictions. Our proposed method achieves 6.49$\times$ throughput over those systems that assume the worst case for the output sequence length.
Response Time Improves Choice Prediction and Function Estimation for Gaussian Process Models of Perception and Preferences
Jun 09, 2023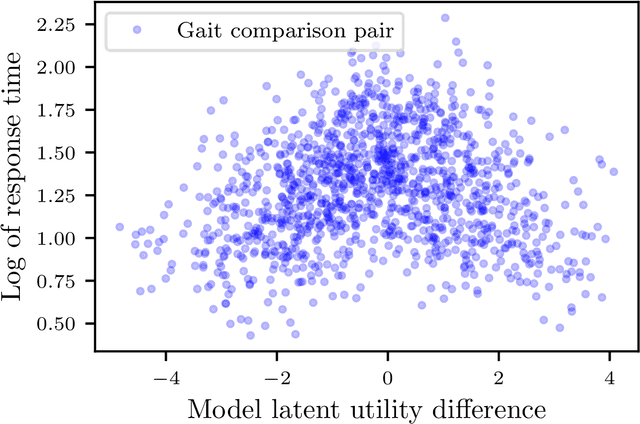
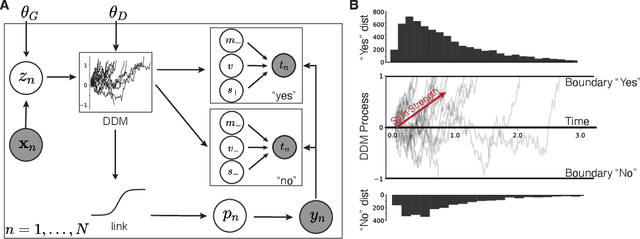
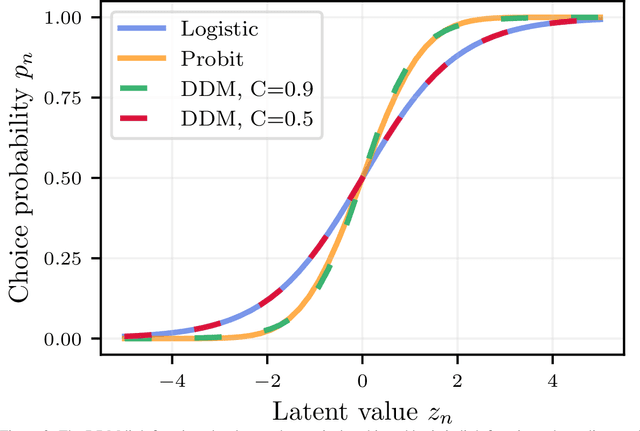
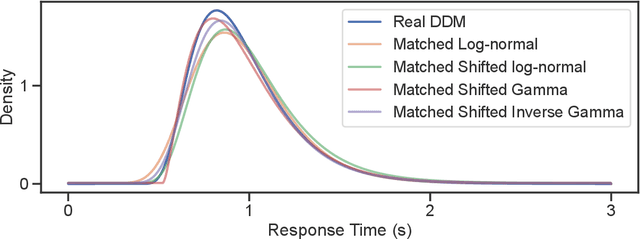
Models for human choice prediction in preference learning and psychophysics often consider only binary response data, requiring many samples to accurately learn preferences or perceptual detection thresholds. The response time (RT) to make each choice captures additional information about the decision process, however existing models incorporating RTs for choice prediction do so in fully parametric settings or over discrete stimulus sets. This is in part because the de-facto standard model for choice RTs, the diffusion decision model (DDM), does not admit tractable, differentiable inference. The DDM thus cannot be easily integrated with flexible models for continuous, multivariate function approximation, particularly Gaussian process (GP) models. We propose a novel differentiable approximation to the DDM likelihood using a family of known, skewed three-parameter distributions. We then use this new likelihood to incorporate RTs into GP models for binary choices. Our RT-choice GPs enable both better latent value estimation and held-out choice prediction relative to baselines, which we demonstrate on three real-world multivariate datasets covering both human psychophysics and preference learning applications.
Quantifying the Knowledge in GNNs for Reliable Distillation into MLPs
Jun 09, 2023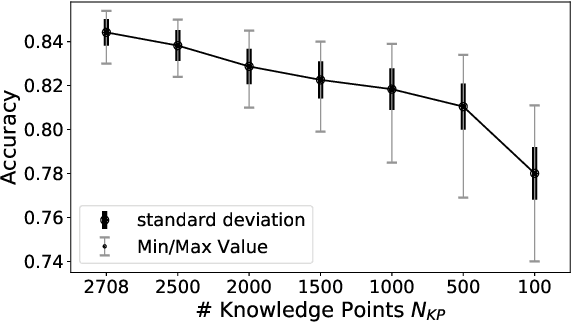
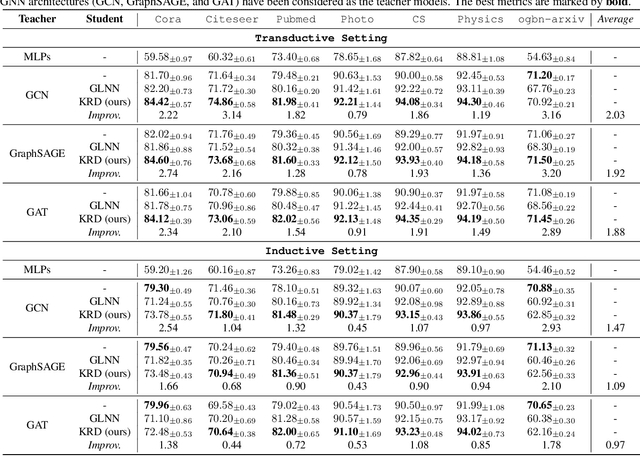
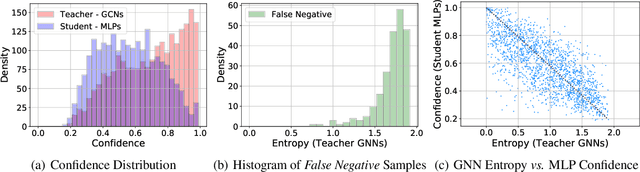
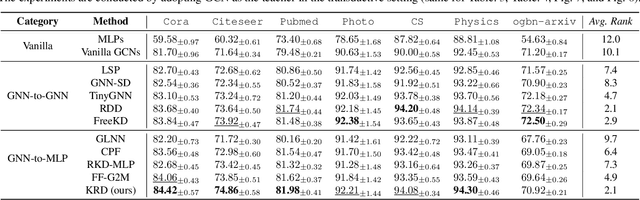
To bridge the gaps between topology-aware Graph Neural Networks (GNNs) and inference-efficient Multi-Layer Perceptron (MLPs), GLNN proposes to distill knowledge from a well-trained teacher GNN into a student MLP. Despite their great progress, comparatively little work has been done to explore the reliability of different knowledge points (nodes) in GNNs, especially their roles played during distillation. In this paper, we first quantify the knowledge reliability in GNN by measuring the invariance of their information entropy to noise perturbations, from which we observe that different knowledge points (1) show different distillation speeds (temporally); (2) are differentially distributed in the graph (spatially). To achieve reliable distillation, we propose an effective approach, namely Knowledge-inspired Reliable Distillation (KRD), that models the probability of each node being an informative and reliable knowledge point, based on which we sample a set of additional reliable knowledge points as supervision for training student MLPs. Extensive experiments show that KRD improves over the vanilla MLPs by 12.62% and outperforms its corresponding teacher GNNs by 2.16% averaged over 7 datasets and 3 GNN architectures.
MultiEarth 2023 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Jun 07, 2023
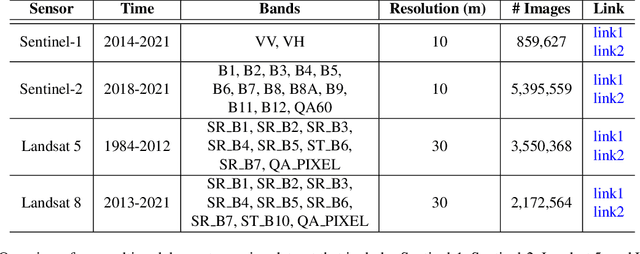

The Multimodal Learning for Earth and Environment Workshop (MultiEarth 2023) is the second annual CVPR workshop aimed at the monitoring and analysis of the health of Earth ecosystems by leveraging the vast amount of remote sensing data that is continuously being collected. The primary objective of this workshop is to bring together the Earth and environmental science communities as well as the multimodal representation learning communities to explore new ways of harnessing technological advancements in support of environmental monitoring. The MultiEarth Workshop also seeks to provide a common benchmark for processing multimodal remote sensing information by organizing public challenges focused on monitoring the Amazon rainforest. These challenges include estimating deforestation, detecting forest fires, translating synthetic aperture radar (SAR) images to the visible domain, and projecting environmental trends. This paper presents the challenge guidelines, datasets, and evaluation metrics. Our challenge website is available at https://sites.google.com/view/rainforest-challenge/multiearth-2023.
Differentiable Earth Mover's Distance for Data Compression at the High-Luminosity LHC
Jun 07, 2023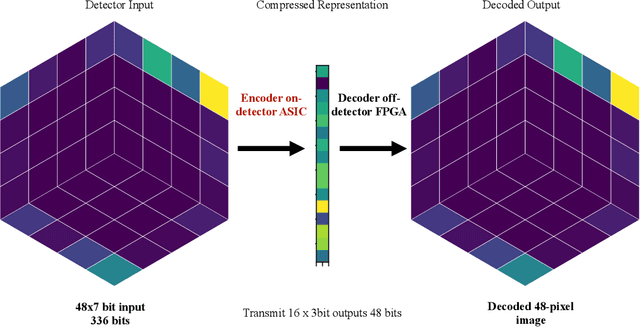
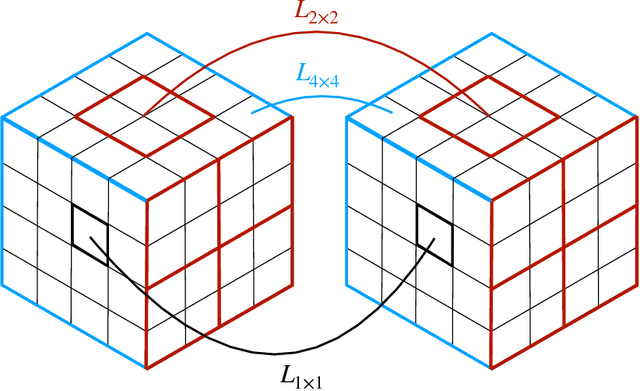
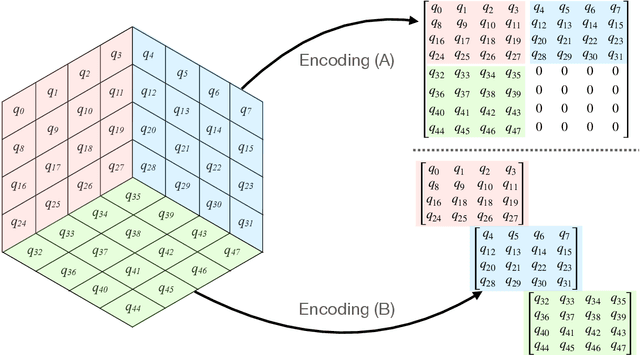
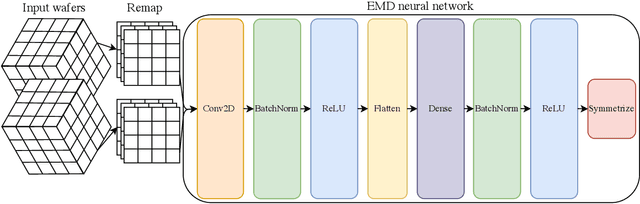
The Earth mover's distance (EMD) is a useful metric for image recognition and classification, but its usual implementations are not differentiable or too slow to be used as a loss function for training other algorithms via gradient descent. In this paper, we train a convolutional neural network (CNN) to learn a differentiable, fast approximation of the EMD and demonstrate that it can be used as a substitute for computing-intensive EMD implementations. We apply this differentiable approximation in the training of an autoencoder-inspired neural network (encoder NN) for data compression at the high-luminosity LHC at CERN. The goal of this encoder NN is to compress the data while preserving the information related to the distribution of energy deposits in particle detectors. We demonstrate that the performance of our encoder NN trained using the differentiable EMD CNN surpasses that of training with loss functions based on mean squared error.