 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Assessing Phrase Break of ESL Speech with Pre-trained Language Models and Large Language Models
Jun 08, 2023


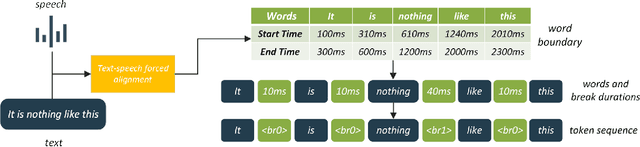
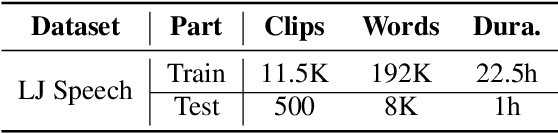
This work introduces approaches to assessing phrase breaks in ESL learners' speech using pre-trained language models (PLMs) and large language models (LLMs). There are two tasks: overall assessment of phrase break for a speech clip and fine-grained assessment of every possible phrase break position. To leverage NLP models, speech input is first force-aligned with texts, and then pre-processed into a token sequence, including words and phrase break information. To utilize PLMs, we propose a pre-training and fine-tuning pipeline with the processed tokens. This process includes pre-training with a replaced break token detection module and fine-tuning with text classification and sequence labeling. To employ LLMs, we design prompts for ChatGPT. The experiments show that with the PLMs, the dependence on labeled training data has been greatly reduced, and the performance has improved. Meanwhile, we verify that ChatGPT, a renowned LLM, has potential for further advancement in this area.
Speech-to-Text Adapter and Speech-to-Entity Retriever Augmented LLMs for Speech Understanding
Jun 08, 2023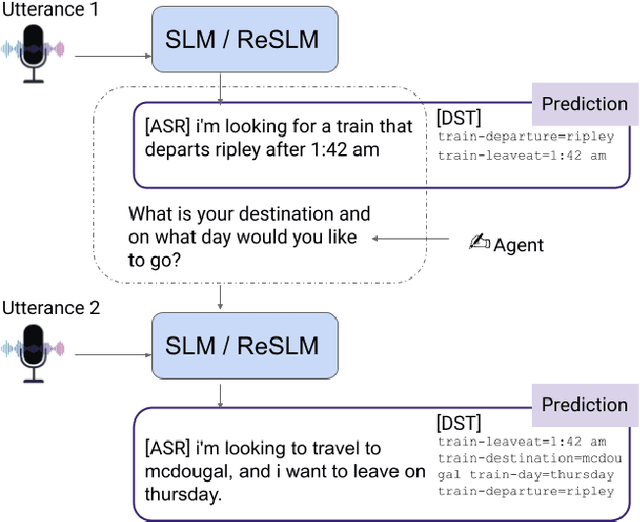
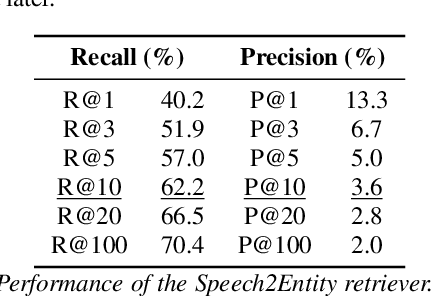
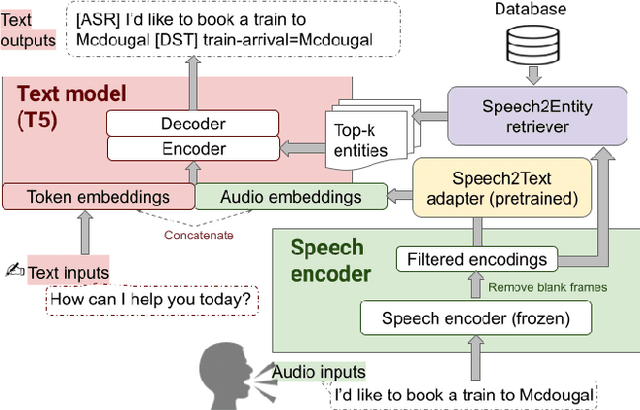
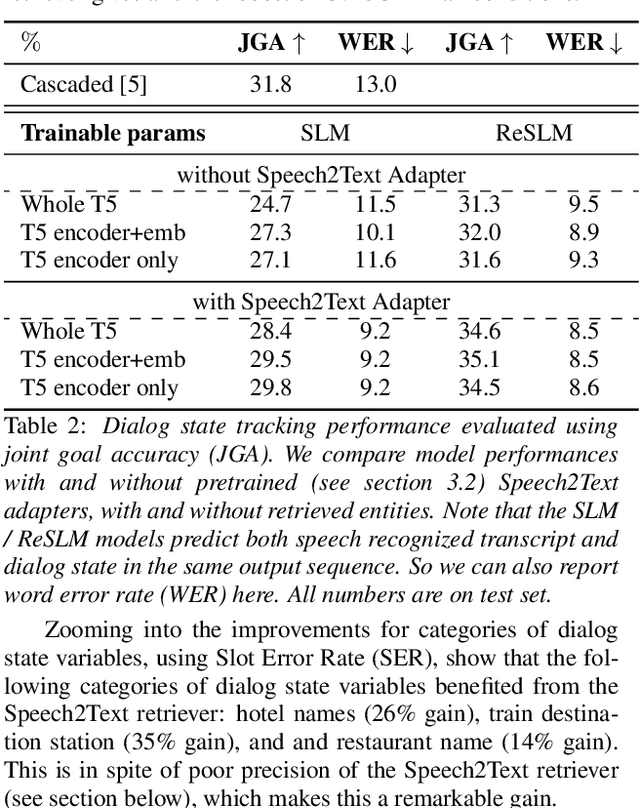
Large Language Models (LLMs) have been applied in the speech domain, often incurring a performance drop due to misaligned between speech and language representations. To bridge this gap, we propose a joint speech and language model (SLM) using a Speech2Text adapter, which maps speech into text token embedding space without speech information loss. Additionally, using a CTC-based blank-filtering, we can reduce the speech sequence length to that of text. In speech MultiWoz dataset (DSTC11 challenge), SLM largely improves the dialog state tracking (DST) performance (24.7% to 28.4% accuracy). Further to address errors on rare entities, we augment SLM with a Speech2Entity retriever, which uses speech to retrieve relevant entities, and then adds them to the original SLM input as a prefix. With this retrieval-augmented SLM (ReSLM), the DST performance jumps to 34.6% accuracy. Moreover, augmenting the ASR task with the dialog understanding task improves the ASR performance from 9.4% to 8.5% WER.
Intelligent Energy Management with IoT Framework in Smart Cities Using Intelligent Analysis: An Application of Machine Learning Methods for Complex Networks and Systems
Jun 08, 2023
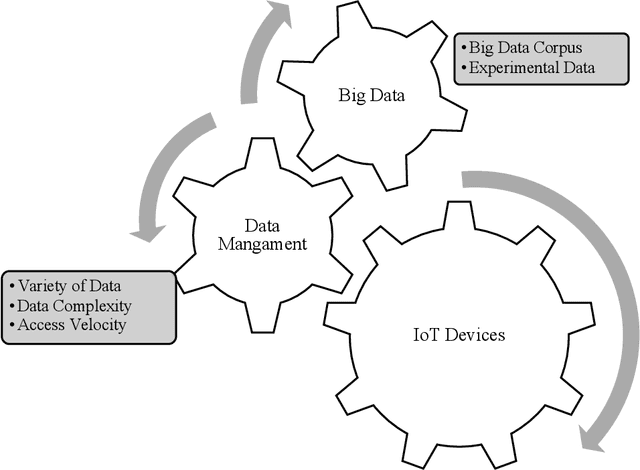
Smart buildings are increasingly using Internet of Things (IoT)-based wireless sensing systems to reduce their energy consumption and environmental impact. As a result of their compact size and ability to sense, measure, and compute all electrical properties, Internet of Things devices have become increasingly important in our society. A major contribution of this study is the development of a comprehensive IoT-based framework for smart city energy management, incorporating multiple components of IoT architecture and framework. An IoT framework for intelligent energy management applications that employ intelligent analysis is an essential system component that collects and stores information. Additionally, it serves as a platform for the development of applications by other companies. Furthermore, we have studied intelligent energy management solutions based on intelligent mechanisms. The depletion of energy resources and the increase in energy demand have led to an increase in energy consumption and building maintenance. The data collected is used to monitor, control, and enhance the efficiency of the system.
Early Rumor Detection Using Neural Hawkes Process with a New Benchmark Dataset
Jun 05, 2023
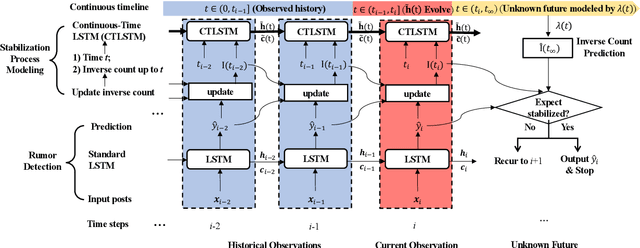
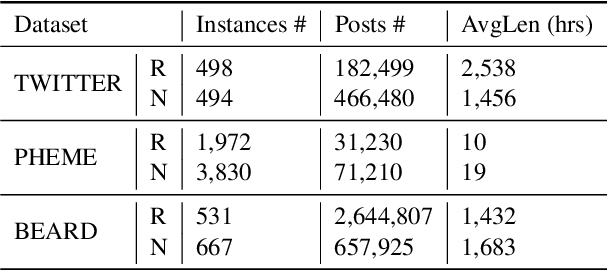

Little attention has been paid on \underline{EA}rly \underline{R}umor \underline{D}etection (EARD), and EARD performance was evaluated inappropriately on a few datasets where the actual early-stage information is largely missing. To reverse such situation, we construct BEARD, a new \underline{B}enchmark dataset for \underline{EARD}, based on claims from fact-checking websites by trying to gather as many early relevant posts as possible. We also propose HEARD, a novel model based on neural \underline{H}awkes process for \underline{EARD}, which can guide a generic rumor detection model to make timely, accurate and stable predictions. Experiments show that HEARD achieves effective EARD performance on two commonly used general rumor detection datasets and our BEARD dataset.
Understanding the Role of Feedback in Online Learning with Switching Costs
Jun 16, 2023
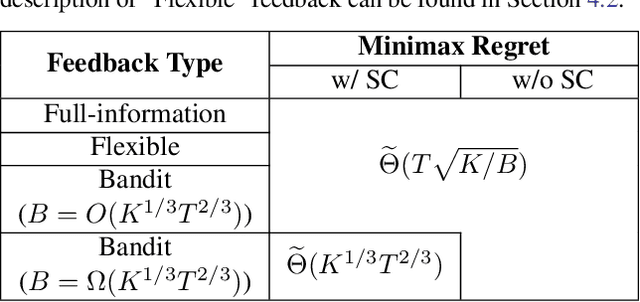
In this paper, we study the role of feedback in online learning with switching costs. It has been shown that the minimax regret is $\widetilde{\Theta}(T^{2/3})$ under bandit feedback and improves to $\widetilde{\Theta}(\sqrt{T})$ under full-information feedback, where $T$ is the length of the time horizon. However, it remains largely unknown how the amount and type of feedback generally impact regret. To this end, we first consider the setting of bandit learning with extra observations; that is, in addition to the typical bandit feedback, the learner can freely make a total of $B_{\mathrm{ex}}$ extra observations. We fully characterize the minimax regret in this setting, which exhibits an interesting phase-transition phenomenon: when $B_{\mathrm{ex}} = O(T^{2/3})$, the regret remains $\widetilde{\Theta}(T^{2/3})$, but when $B_{\mathrm{ex}} = \Omega(T^{2/3})$, it becomes $\widetilde{\Theta}(T/\sqrt{B_{\mathrm{ex}}})$, which improves as the budget $B_{\mathrm{ex}}$ increases. To design algorithms that can achieve the minimax regret, it is instructive to consider a more general setting where the learner has a budget of $B$ total observations. We fully characterize the minimax regret in this setting as well and show that it is $\widetilde{\Theta}(T/\sqrt{B})$, which scales smoothly with the total budget $B$. Furthermore, we propose a generic algorithmic framework, which enables us to design different learning algorithms that can achieve matching upper bounds for both settings based on the amount and type of feedback. One interesting finding is that while bandit feedback can still guarantee optimal regret when the budget is relatively limited, it no longer suffices to achieve optimal regret when the budget is relatively large.
VCVW-3D: A Virtual Construction Vehicles and Workers Dataset with 3D Annotations
May 29, 2023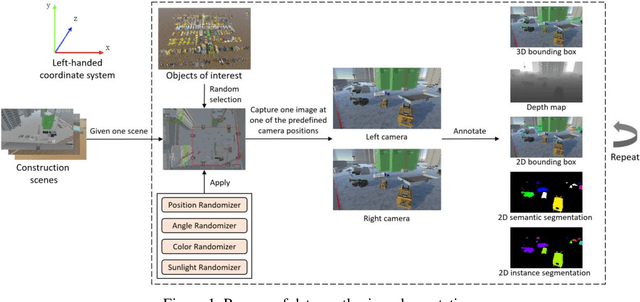
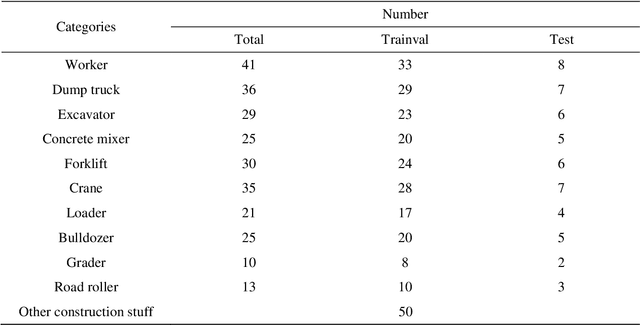


Currently, object detection applications in construction are almost based on pure 2D data (both image and annotation are 2D-based), resulting in the developed artificial intelligence (AI) applications only applicable to some scenarios that only require 2D information. However, most advanced applications usually require AI agents to perceive 3D spatial information, which limits the further development of the current computer vision (CV) in construction. The lack of 3D annotated datasets for construction object detection worsens the situation. Therefore, this study creates and releases a virtual dataset with 3D annotations named VCVW-3D, which covers 15 construction scenes and involves ten categories of construction vehicles and workers. The VCVW-3D dataset is characterized by multi-scene, multi-category, multi-randomness, multi-viewpoint, multi-annotation, and binocular vision. Several typical 2D and monocular 3D object detection models are then trained and evaluated on the VCVW-3D dataset to provide a benchmark for subsequent research. The VCVW-3D is expected to bring considerable economic benefits and practical significance by reducing the costs of data construction, prototype development, and exploration of space-awareness applications, thus promoting the development of CV in construction, especially those of 3D applications.
Privileged Knowledge Distillation for Sim-to-Real Policy Generalization
May 29, 2023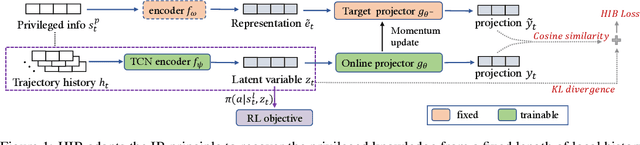
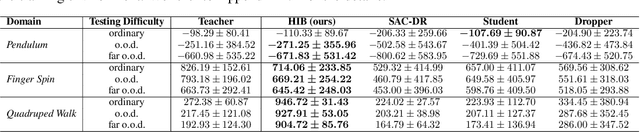


Reinforcement Learning (RL) has recently achieved remarkable success in robotic control. However, most RL methods operate in simulated environments where privileged knowledge (e.g., dynamics, surroundings, terrains) is readily available. Conversely, in real-world scenarios, robot agents usually rely solely on local states (e.g., proprioceptive feedback of robot joints) to select actions, leading to a significant sim-to-real gap. Existing methods address this gap by either gradually reducing the reliance on privileged knowledge or performing a two-stage policy imitation. However, we argue that these methods are limited in their ability to fully leverage the privileged knowledge, resulting in suboptimal performance. In this paper, we propose a novel single-stage privileged knowledge distillation method called the Historical Information Bottleneck (HIB) to narrow the sim-to-real gap. In particular, HIB learns a privileged knowledge representation from historical trajectories by capturing the underlying changeable dynamic information. Theoretical analysis shows that the learned privileged knowledge representation helps reduce the value discrepancy between the oracle and learned policies. Empirical experiments on both simulated and real-world tasks demonstrate that HIB yields improved generalizability compared to previous methods.
Dark web activity classification using deep learning
May 30, 2023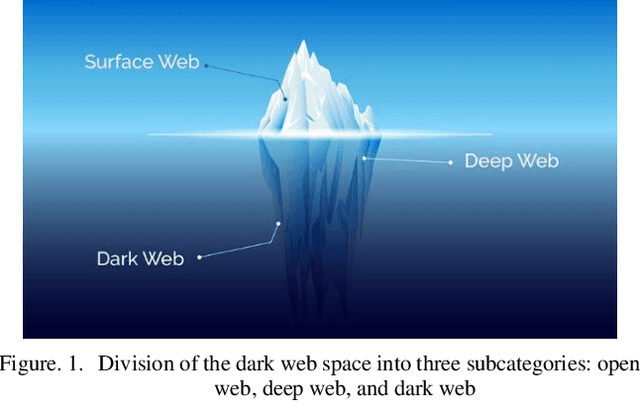
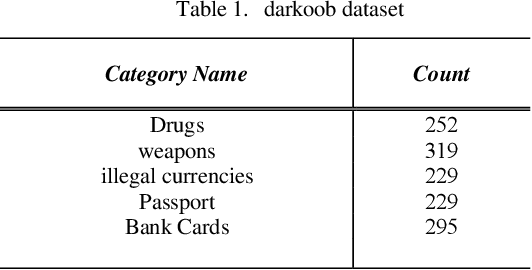


The present article highlights the pressing need for identifying and controlling illicit activities on the dark web. While only 4% of the information available on the internet is accessible through regular search engines, the deep web contains a plethora of information, including personal data and online accounts, that is not indexed by search engines. The dark web, which constitutes a subset of the deep web, is a notorious breeding ground for various illegal activities, such as drug trafficking, weapon sales, and money laundering. Against this backdrop, the authors propose a novel search engine that leverages deep learning to identify and extract relevant images related to illicit activities on the dark web. Specifically, the system can detect the titles of illegal activities on the dark web and retrieve pertinent images from websites with a .onion extension. The authors have collected a comprehensive dataset named darkoob and the proposed method achieves an accuracy of 94% on the test dataset. Overall, the proposed search engine represents a significant step forward in identifying and controlling illicit activities on the dark web. By contributing to internet and community security, this technology has the potential to mitigate a wide range of social, economic, and political challenges arising from illegal activities on the dark web.
A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution
Jun 02, 2023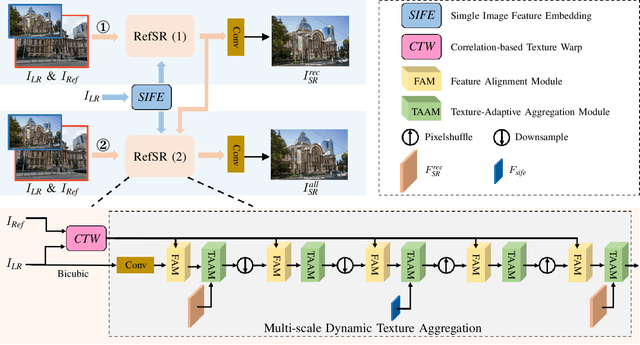
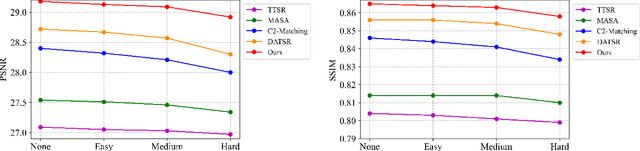

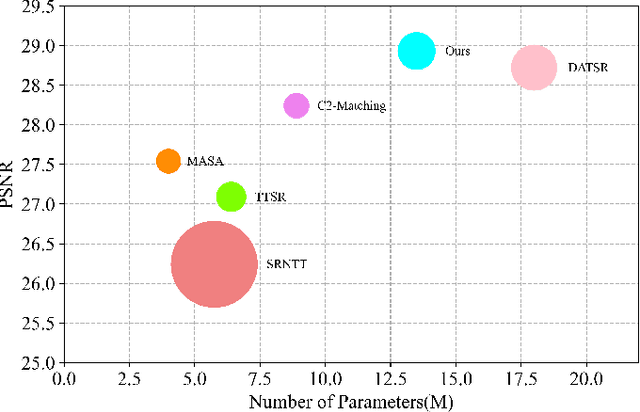
Reference-based super-resolution (RefSR) has gained considerable success in the field of super-resolution with the addition of high-resolution reference images to reconstruct low-resolution (LR) inputs with more high-frequency details, thereby overcoming some limitations of single image super-resolution (SISR). Previous research in the field of RefSR has mostly focused on two crucial aspects. The first is accurate correspondence matching between the LR and the reference (Ref) image. The second is the effective transfer and aggregation of similar texture information from the Ref images. Nonetheless, an important detail of perceptual loss and adversarial loss has been underestimated, which has a certain adverse effect on texture transfer and reconstruction. In this study, we propose a feature reuse framework that guides the step-by-step texture reconstruction process through different stages, reducing the negative impacts of perceptual and adversarial loss. The feature reuse framework can be used for any RefSR model, and several RefSR approaches have improved their performance after being retrained using our framework. Additionally, we introduce a single image feature embedding module and a texture-adaptive aggregation module. The single image feature embedding module assists in reconstructing the features of the LR inputs itself and effectively lowers the possibility of including irrelevant textures. The texture-adaptive aggregation module dynamically perceives and aggregates texture information between the LR inputs and the Ref images using dynamic filters. This enhances the utilization of the reference texture while reducing reference misuse. The source code is available at https://github.com/Yi-Yang355/FRFSR.
Analyzing Credit Risk Model Problems through NLP-Based Clustering and Machine Learning: Insights from Validation Reports
Jun 02, 2023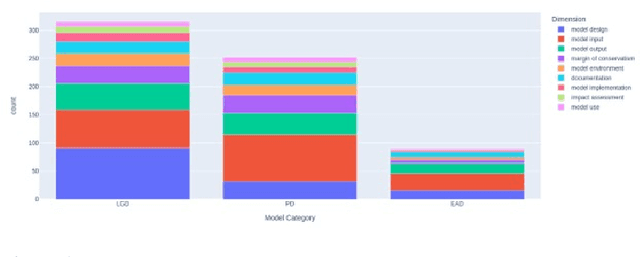
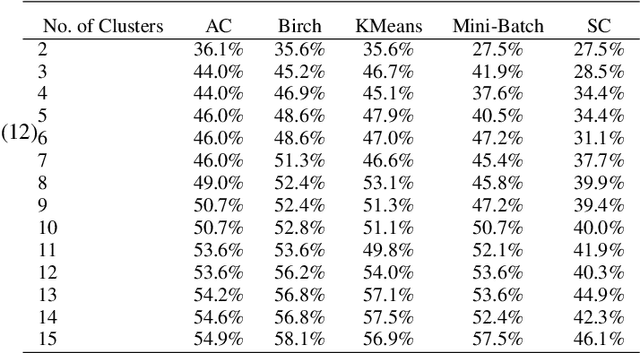
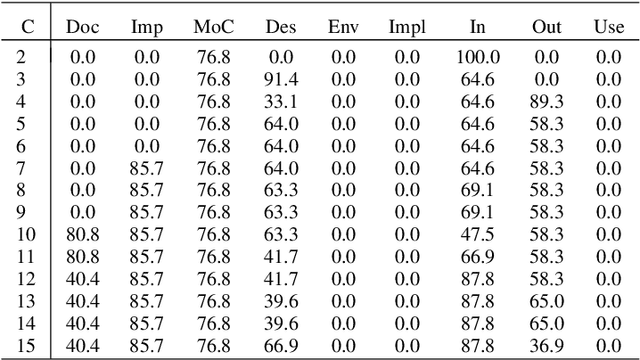
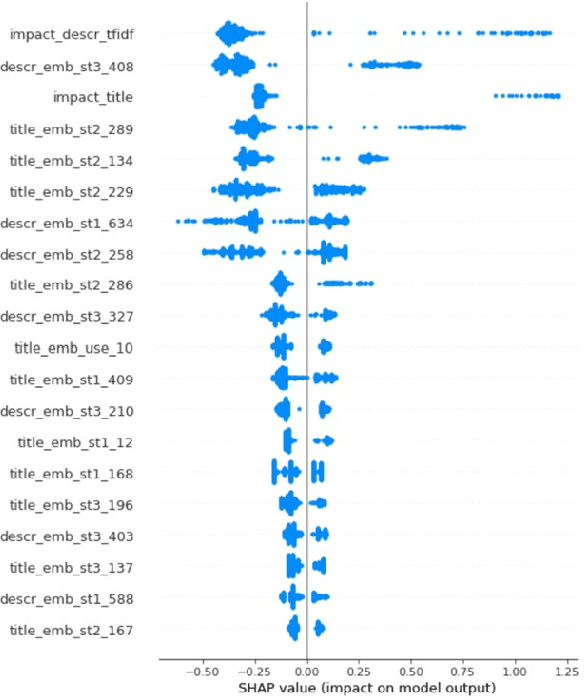
This paper explores the use of clustering methods and machine learning algorithms, including Natural Language Processing (NLP), to identify and classify problems identified in credit risk models through textual information contained in validation reports. Using a unique dataset of 657 findings raised by validation teams in a large international banking group between January 2019 and December 2022. The findings are classified into nine validation dimensions and assigned a severity level by validators using their expert knowledge. The authors use embedding generation for the findings' titles and observations using four different pre-trained models, including "module\_url" from TensorFlow Hub and three models from the SentenceTransformer library, namely "all-mpnet-base-v2", "all-MiniLM-L6-v2", and "paraphrase-mpnet-base-v2". The paper uses and compares various clustering methods in grouping findings with similar characteristics, enabling the identification of common problems within each validation dimension and severity. The results of the study show that clustering is an effective approach for identifying and classifying credit risk model problems with accuracy higher than 60\%. The authors also employ machine learning algorithms, including logistic regression and XGBoost, to predict the validation dimension and its severity, achieving an accuracy of 80\% for XGBoost algorithm. Furthermore, the study identifies the top 10 words that predict a validation dimension and severity. Overall, this paper makes a contribution by demonstrating the usefulness of clustering and machine learning for analyzing textual information in validation reports, and providing insights into the types of problems encountered in the development and validation of credit risk models.