 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Differentially Private Over-the-Air Federated Learning Over MIMO Fading Channels
Jun 19, 2023
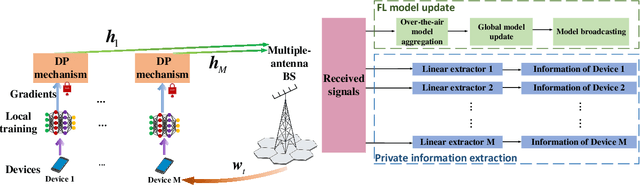
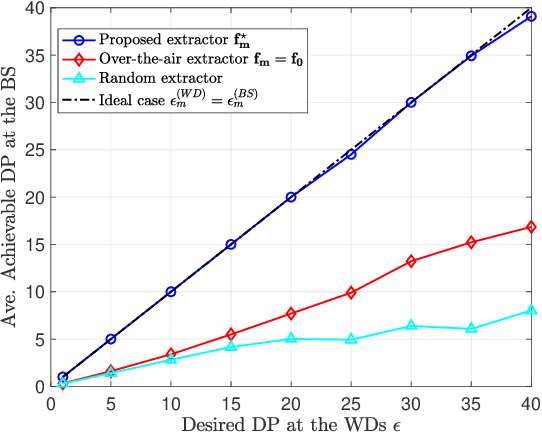
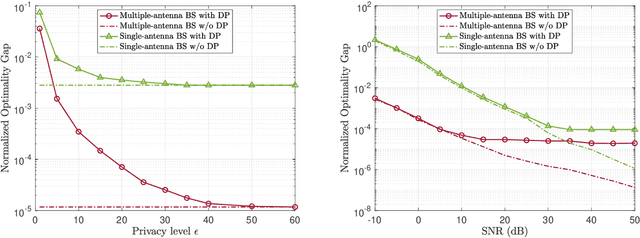
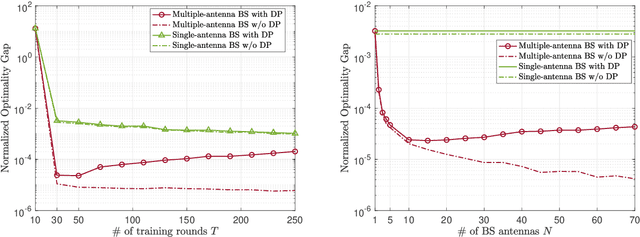
Federated learning (FL) enables edge devices to collaboratively train machine learning models, with model communication replacing direct data uploading. While over-the-air model aggregation improves communication efficiency, uploading models to an edge server over wireless networks can pose privacy risks. Differential privacy (DP) is a widely used quantitative technique to measure statistical data privacy in FL. Previous research has focused on over-the-air FL with a single-antenna server, leveraging communication noise to enhance user-level DP. This approach achieves the so-called "free DP" by controlling transmit power rather than introducing additional DP-preserving mechanisms at devices, such as adding artificial noise. In this paper, we study differentially private over-the-air FL over a multiple-input multiple-output (MIMO) fading channel. We show that FL model communication with a multiple-antenna server amplifies privacy leakage as the multiple-antenna server employs separate receive combining for model aggregation and information inference. Consequently, relying solely on communication noise, as done in the multiple-input single-output system, cannot meet high privacy requirements, and a device-side privacy-preserving mechanism is necessary for optimal DP design. We analyze the learning convergence and privacy loss of the studied FL system and propose a transceiver design algorithm based on alternating optimization. Numerical results demonstrate that the proposed method achieves a better privacy-learning trade-off compared to prior work.
Simplifying and Empowering Transformers for Large-Graph Representations
Jun 19, 2023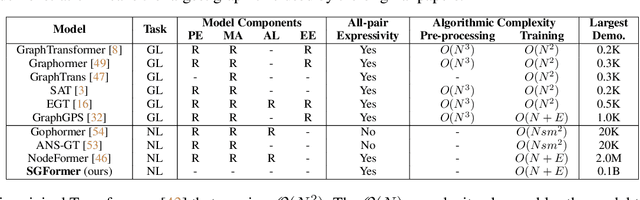
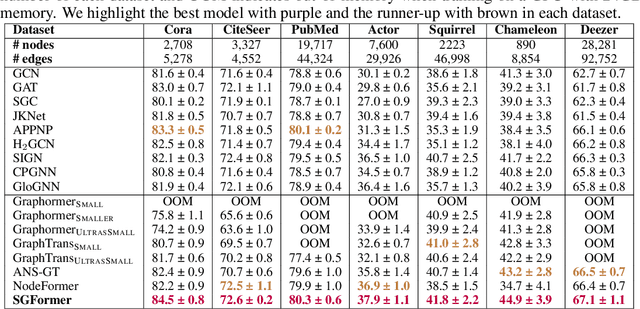
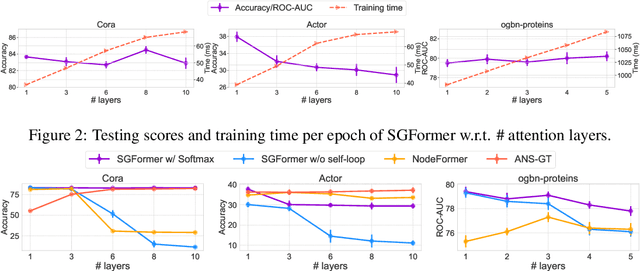
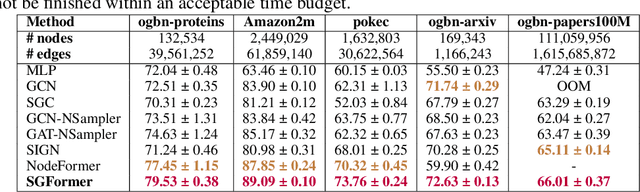
Learning representations on large-sized graphs is a long-standing challenge due to the inter-dependence nature involved in massive data points. Transformers, as an emerging class of foundation encoders for graph-structured data, have shown promising performance on small graphs due to its global attention capable of capturing all-pair influence beyond neighboring nodes. Even so, existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated models by stacking deep multi-head attentions. In this paper, we critically demonstrate that even using a one-layer attention can bring up surprisingly competitive performance across node property prediction benchmarks where node numbers range from thousand-level to billion-level. This encourages us to rethink the design philosophy for Transformers on large graphs, where the global attention is a computation overhead hindering the scalability. We frame the proposed scheme as Simplified Graph Transformers (SGFormer), which is empowered by a simple attention model that can efficiently propagate information among arbitrary nodes in one layer. SGFormer requires none of positional encodings, feature/graph pre-processing or augmented loss. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M and yields up to 141x inference acceleration over SOTA Transformers on medium-sized graphs. Beyond current results, we believe the proposed methodology alone enlightens a new technical path of independent interest for building Transformers on large graphs.
SegT: A Novel Separated Edge-guidance Transformer Network for Polyp Segmentation
Jun 19, 2023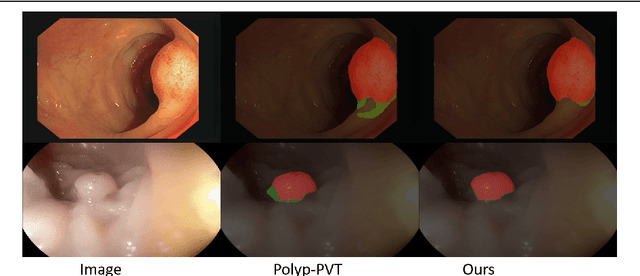
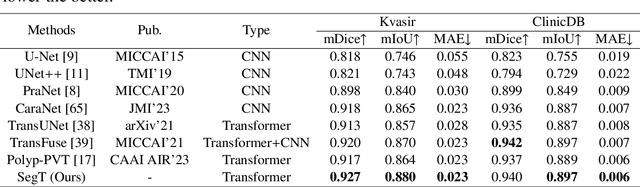
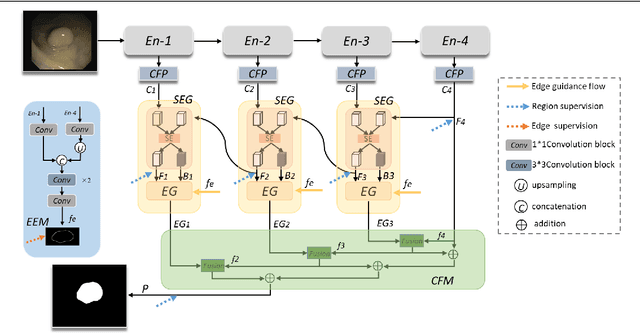
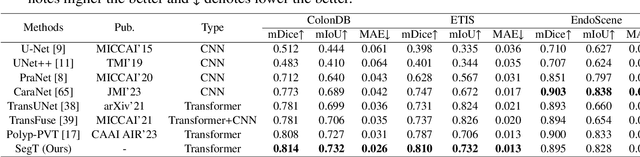
Accurate segmentation of colonoscopic polyps is considered a fundamental step in medical image analysis and surgical interventions. Many recent studies have made improvements based on the encoder-decoder framework, which can effectively segment diverse polyps. Such improvements mainly aim to enhance local features by using global features and applying attention methods. However, relying only on the global information of the final encoder block can result in losing local regional features in the intermediate layer. In addition, determining the edges between benign regions and polyps could be a challenging task. To address the aforementioned issues, we propose a novel separated edge-guidance transformer (SegT) network that aims to build an effective polyp segmentation model. A transformer encoder that learns a more robust representation than existing CNN-based approaches was specifically applied. To determine the precise segmentation of polyps, we utilize a separated edge-guidance module consisting of separator and edge-guidance blocks. The separator block is a two-stream operator to highlight edges between the background and foreground, whereas the edge-guidance block lies behind both streams to strengthen the understanding of the edge. Lastly, an innovative cascade fusion module was used and fused the refined multi-level features. To evaluate the effectiveness of SegT, we conducted experiments with five challenging public datasets, and the proposed model achieved state-of-the-art performance.
Practical and General Backdoor Attacks against Vertical Federated Learning
Jun 19, 2023Federated learning (FL), which aims to facilitate data collaboration across multiple organizations without exposing data privacy, encounters potential security risks. One serious threat is backdoor attacks, where an attacker injects a specific trigger into the training dataset to manipulate the model's prediction. Most existing FL backdoor attacks are based on horizontal federated learning (HFL), where the data owned by different parties have the same features. However, compared to HFL, backdoor attacks on vertical federated learning (VFL), where each party only holds a disjoint subset of features and the labels are only owned by one party, are rarely studied. The main challenge of this attack is to allow an attacker without access to the data labels, to perform an effective attack. To this end, we propose BadVFL, a novel and practical approach to inject backdoor triggers into victim models without label information. BadVFL mainly consists of two key steps. First, to address the challenge of attackers having no knowledge of labels, we introduce a SDD module that can trace data categories based on gradients. Second, we propose a SDP module that can improve the attack's effectiveness by enhancing the decision dependency between the trigger and attack target. Extensive experiments show that BadVFL supports diverse datasets and models, and achieves over 93% attack success rate with only 1% poisoning rate.
Learning-based sound speed reconstruction and aberration correction in linear-array photoacoustic/ultrasound imaging
Jun 19, 2023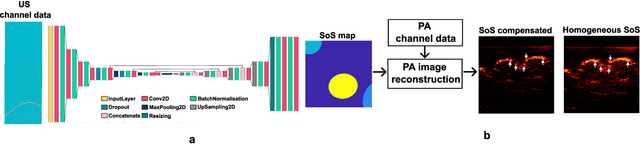
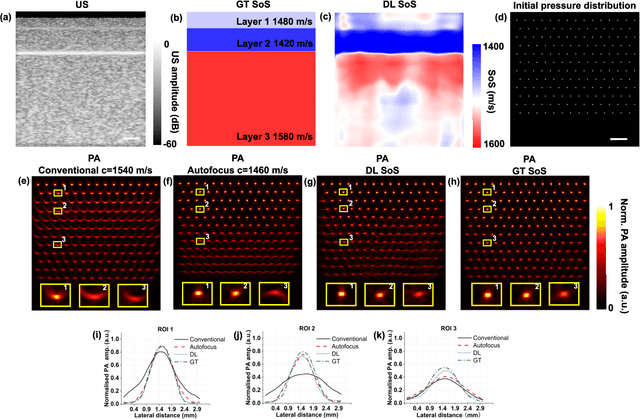
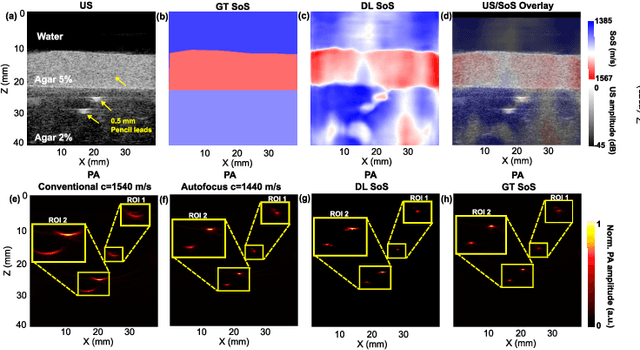
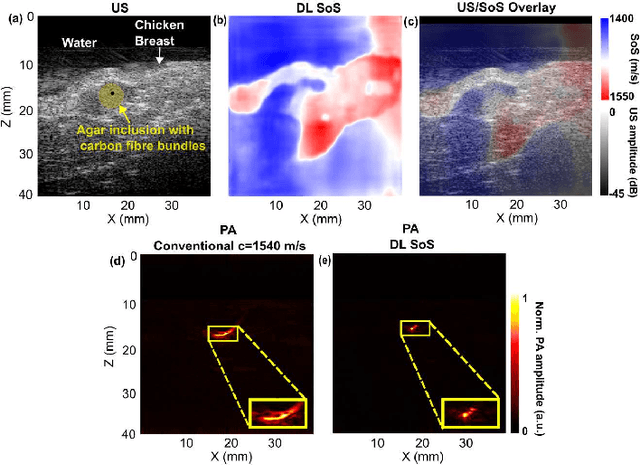
Photoacoustic (PA) image reconstruction involves acoustic inversion that necessitates the specification of the speed of sound (SoS) within the medium of propagation. Due to the lack of information on the spatial distribution of the SoS within heterogeneous soft tissue, a homogeneous SoS distribution (such as 1540 m/s) is typically assumed in PA image reconstruction, similar to that of ultrasound (US) imaging. Failure to compensate the SoS variations leads to aberration artefacts, deteriorating the image quality. In this work, we developed a deep learning framework for SoS reconstruction and subsequent aberration correction in a dual-modal PA/US imaging system sharing a clinical US probe. As the PA and US data were inherently co-registered, the reconstructed SoS distribution from US channel data using deep neural networks was utilised for accurate PA image reconstruction. On a numerical and a tissue-mimicking phantom, this framework was able to significantly suppress US aberration artefacts, with the structural similarity index measure (SSIM) of up to 0.8109 and 0.8128 as compared to the conventional approach (0.6096 and 0.5985, respectively). The networks, trained only on simulated US data, also demonstrated a good generalisation ability on data from ex vivo tissues and the wrist and fingers of healthy human volunteers, and thus could be valuable in various in vivo applications to enhance PA image reconstruction.
Image encryption for Offshore wind power based on 2D-LCLM and Zhou Yi Eight Trigrams
Jun 02, 2023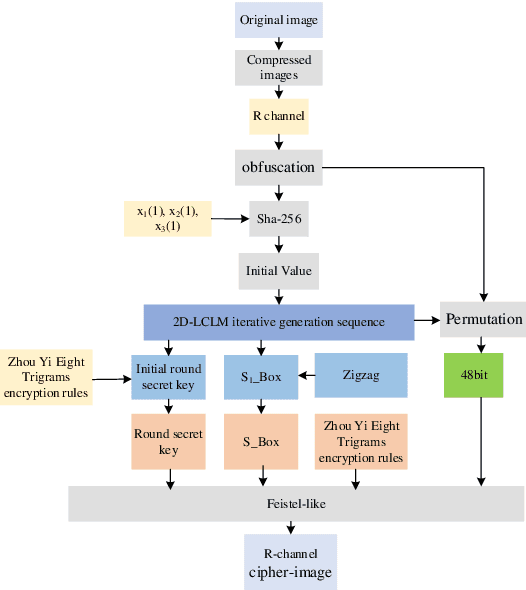
Offshore wind power is an important part of the new power system, due to the complex and changing situation at ocean, its normal operation and maintenance cannot be done without information such as images, therefore, it is especially important to transmit the correct image in the process of information transmission. In this paper, we propose a new encryption algorithm for offshore wind power based on two-dimensional lagged complex logistic mapping (2D-LCLM) and Zhou Yi Eight Trigrams. Firstly, the initial value of the 2D-LCLM is constructed by the Sha-256 to associate the 2D-LCLM with the plaintext. Secondly, a new encryption rule is proposed from the Zhou Yi Eight Trigrams to obfuscate the pixel values and generate the round key. Then, 2D-LCLM is combined with the Zigzag to form an S-box. Finally, the simulation experiment of the algorithm is accomplished. The experimental results demonstrate that the algorithm can resistant common attacks and has prefect encryption performance.
Deep Representation Learning of Tissue Metabolome and Computed Tomography Images Annotates Non-invasive Classification and Prognosis Prediction of NSCLC
May 26, 2023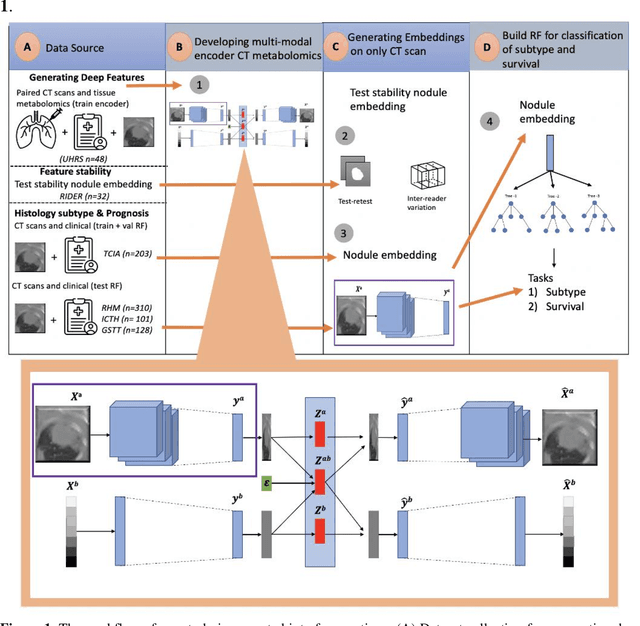

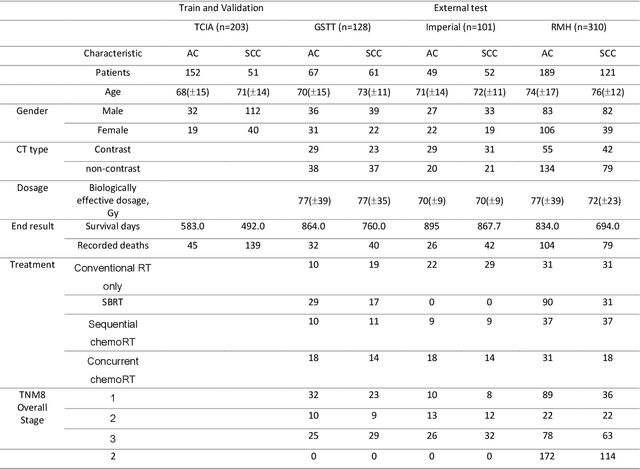
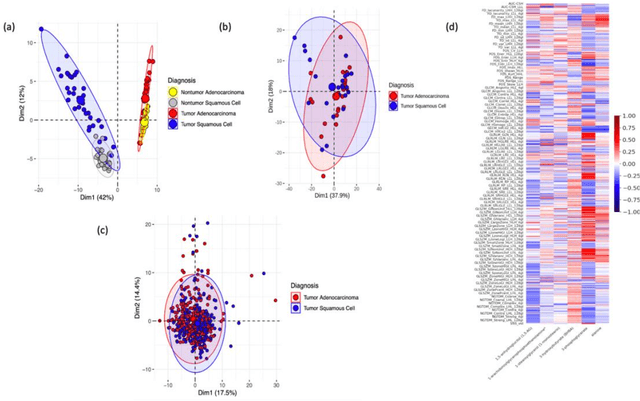
The rich chemical information from tissue metabolomics provides a powerful means to elaborate tissue physiology or tumor characteristics at cellular and tumor microenvironment levels. However, the process of obtaining such information requires invasive biopsies, is costly, and can delay clinical patient management. Conversely, computed tomography (CT) is a clinical standard of care but does not intuitively harbor histological or prognostic information. Furthermore, the ability to embed metabolome information into CT to subsequently use the learned representation for classification or prognosis has yet to be described. This study develops a deep learning-based framework -- tissue-metabolomic-radiomic-CT (TMR-CT) by combining 48 paired CT images and tumor/normal tissue metabolite intensities to generate ten image embeddings to infer metabolite-derived representation from CT alone. In clinical NSCLC settings, we ascertain whether TMR-CT achieves state-of-the-art results in solving histology classification/prognosis tasks in an unseen international CT dataset of 742 patients. TMR-CT non-invasively determines histological classes - adenocarcinoma/ squamous cell carcinoma with an F1-score=0.78 and further asserts patients' prognosis with a c-index=0.72, surpassing the performance of radiomics models and clinical features. Additionally, our work shows the potential to generate informative biology-inspired CT-led features to explore connections between hard-to-obtain tissue metabolic profiles and routine lesion-derived image data.
Quality of Service Based Radar Resource Management for Navigation and Positioning
Jun 12, 2023

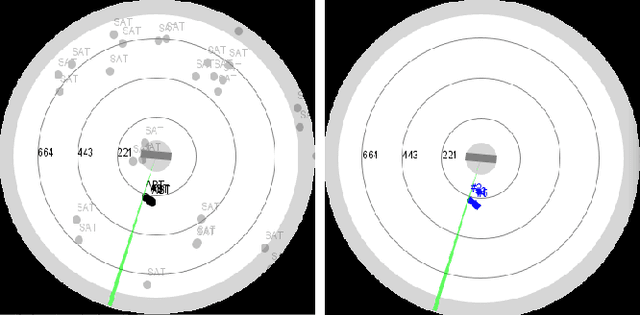
In hostile environments, GNSS is a potentially unreliable solution for self-localization and navigation. Many systems only use an IMU as a backup system, resulting in integration errors which can dramatically increase during mission execution. We suggest using a fighter radar to illuminate satellites with known trajectories to enhance the self-localization information. This technique is time-consuming and resource-demanding but necessary as other tasks depend on the self-localization accuracy. Therefore an adaption of classical resource management frameworks is required. We propose a quality of service based resource manager with capabilities to account for inter-task dependencies to optimize the self-localization update strategy. Our results show that this leads to adaptive navigation update strategies, mastering the trade-off between self-localization and the requirements of other tasks.
* 8 pages, 9 figures
Zero-Shot Information Extraction via Chatting with ChatGPT
Feb 20, 2023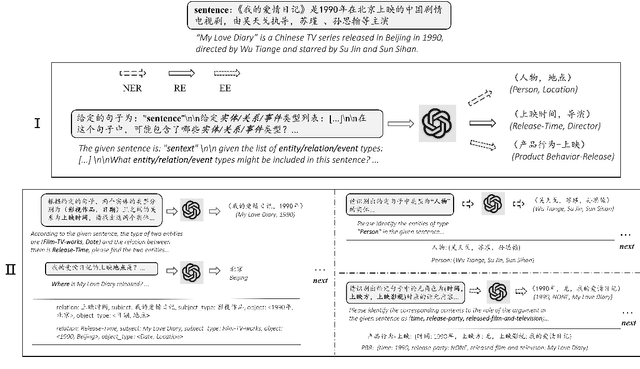
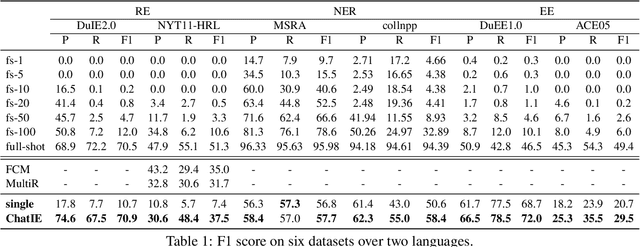


Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. It is challenging due to involving little human intervention. Challenging but worthwhile, zero-shot IE reduces the time and effort that data labeling takes. Recent efforts on large language models (LLMs, e.g., GPT-3, ChatGPT) show promising performance on zero-shot settings, thus inspiring us to explore prompt-based methods. In this work, we ask whether strong IE models can be constructed by directly prompting LLMs. Specifically, we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE). With the power of ChatGPT, we extensively evaluate our framework on three IE tasks: entity-relation triple extract, named entity recognition, and event extraction. Empirical results on six datasets across two languages show that ChatIE achieves impressive performance and even surpasses some full-shot models on several datasets (e.g., NYT11-HRL). We believe that our work could shed light on building IE models with limited resources.
Optimising Human-Machine Collaboration for Efficient High-Precision Information Extraction from Text Documents
Feb 18, 2023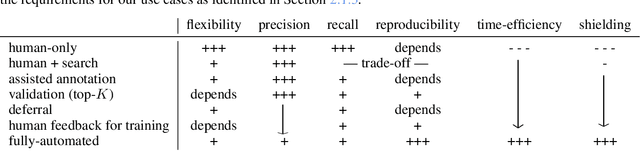
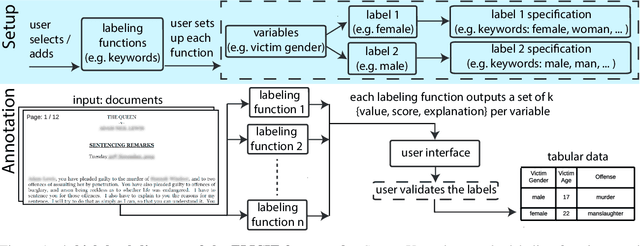
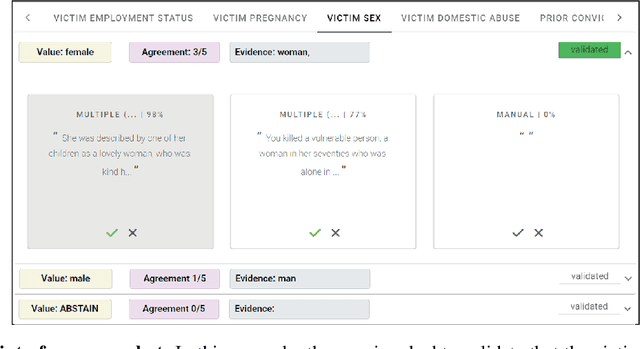
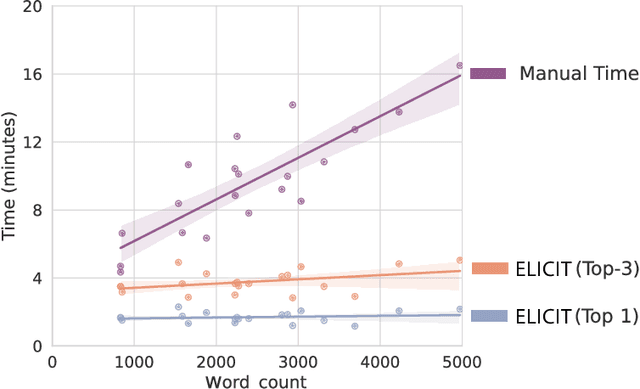
While humans can extract information from unstructured text with high precision and recall, this is often too time-consuming to be practical. Automated approaches, on the other hand, produce nearly-immediate results, but may not be reliable enough for high-stakes applications where precision is essential. In this work, we consider the benefits and drawbacks of various human-only, human-machine, and machine-only information extraction approaches. We argue for the utility of a human-in-the-loop approach in applications where high precision is required, but purely manual extraction is infeasible. We present a framework and an accompanying tool for information extraction using weak-supervision labelling with human validation. We demonstrate our approach on three criminal justice datasets. We find that the combination of computer speed and human understanding yields precision comparable to manual annotation while requiring only a fraction of time, and significantly outperforms fully automated baselines in terms of precision.