 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fuzzy Rough Choquet Distances for Classification
Mar 18, 2024

This paper introduces a novel Choquet distance using fuzzy rough set based measures. The proposed distance measure combines the attribute information received from fuzzy rough set theory with the flexibility of the Choquet integral. This approach is designed to adeptly capture non-linear relationships within the data, acknowledging the interplay of the conditional attributes towards the decision attribute and resulting in a more flexible and accurate distance. We explore its application in the context of machine learning, with a specific emphasis on distance-based classification approaches (e.g. k-nearest neighbours). The paper examines two fuzzy rough set based measures that are based on the positive region. Moreover, we explore two procedures for monotonizing the measures derived from fuzzy rough set theory, making them suitable for use with the Choquet integral, and investigate their differences.
Fair Distributed Cooperative Bandit Learning on Networks for Intelligent Internet of Things Systems (Technical Report)
Mar 18, 2024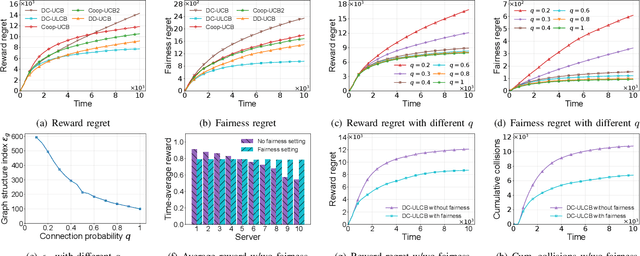
In intelligent Internet of Things (IoT) systems, edge servers within a network exchange information with their neighbors and collect data from sensors to complete delivered tasks. In this paper, we propose a multiplayer multi-armed bandit model for intelligent IoT systems to facilitate data collection and incorporate fairness considerations. In our model, we establish an effective communication protocol that helps servers cooperate with their neighbors. Then we design a distributed cooperative bandit algorithm, DC-ULCB, enabling servers to collaboratively select sensors to maximize data rates while maintaining fairness in their choices. We conduct an analysis of the reward regret and fairness regret of DC-ULCB, and prove that both regrets have logarithmic instance-dependent upper bounds. Additionally, through extensive simulations, we validate that DC-ULCB outperforms existing algorithms in maximizing reward and ensuring fairness.
Enhancing Information Maximization with Distance-Aware Contrastive Learning for Source-Free Cross-Domain Few-Shot Learning
Mar 04, 2024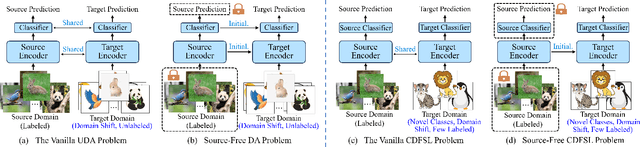
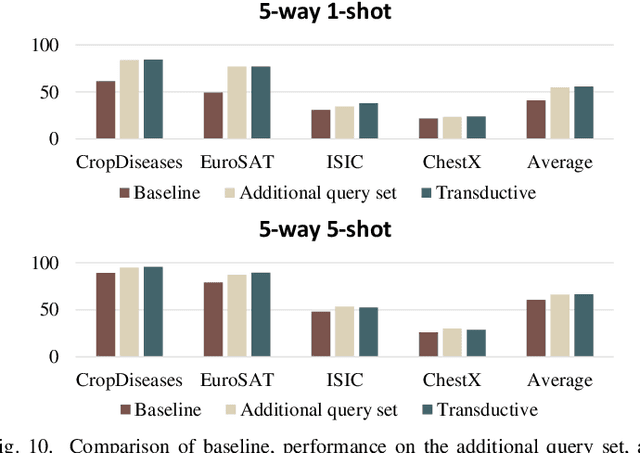
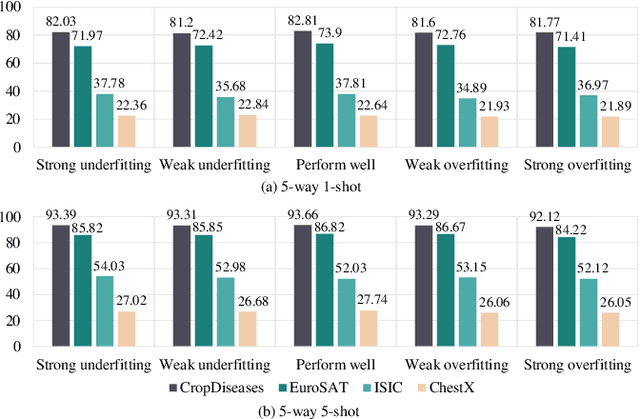
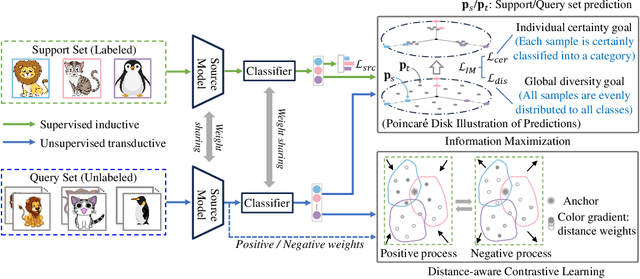
Existing Cross-Domain Few-Shot Learning (CDFSL) methods require access to source domain data to train a model in the pre-training phase. However, due to increasing concerns about data privacy and the desire to reduce data transmission and training costs, it is necessary to develop a CDFSL solution without accessing source data. For this reason, this paper explores a Source-Free CDFSL (SF-CDFSL) problem, in which CDFSL is addressed through the use of existing pretrained models instead of training a model with source data, avoiding accessing source data. This paper proposes an Enhanced Information Maximization with Distance-Aware Contrastive Learning (IM-DCL) method to address these challenges. Firstly, we introduce the transductive mechanism for learning the query set. Secondly, information maximization (IM) is explored to map target samples into both individual certainty and global diversity predictions, helping the source model better fit the target data distribution. However, IM fails to learn the decision boundary of the target task. This motivates us to introduce a novel approach called Distance-Aware Contrastive Learning (DCL), in which we consider the entire feature set as both positive and negative sets, akin to Schrodinger's concept of a dual state. Instead of a rigid separation between positive and negative sets, we employ a weighted distance calculation among features to establish a soft classification of the positive and negative sets for the entire feature set. Furthermore, we address issues related to IM by incorporating contrastive constraints between object features and their corresponding positive and negative sets. Evaluations of the 4 datasets in the BSCD-FSL benchmark indicate that the proposed IM-DCL, without accessing the source domain, demonstrates superiority over existing methods, especially in the distant domain task.
FutureDepth: Learning to Predict the Future Improves Video Depth Estimation
Mar 19, 2024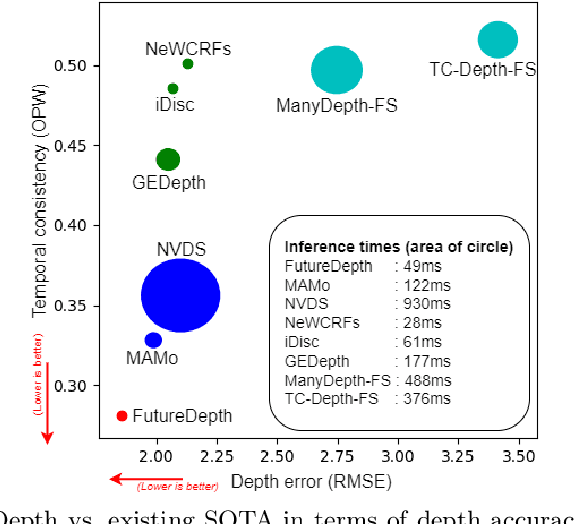
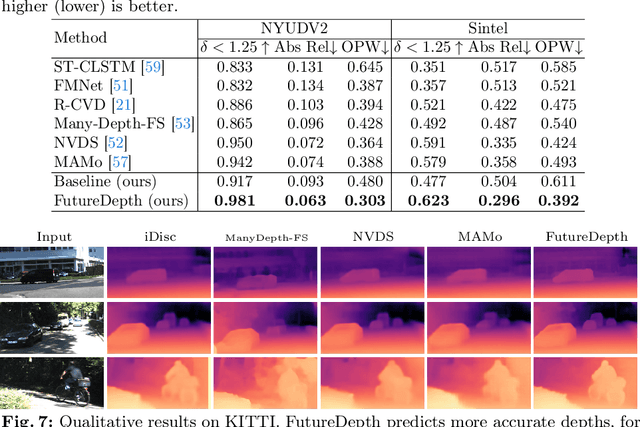
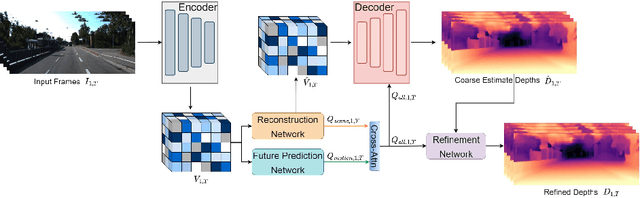
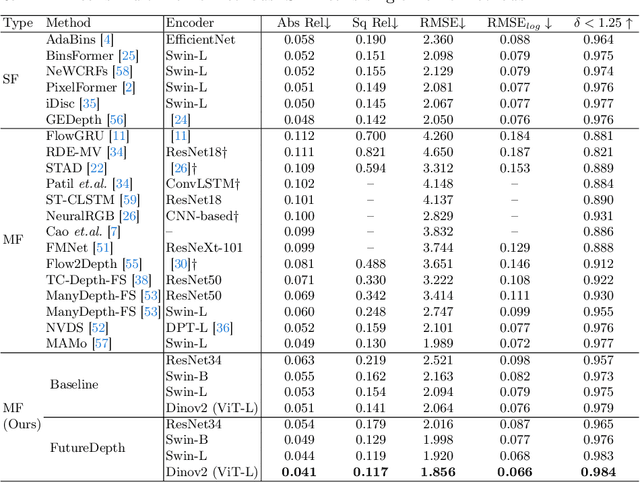
In this paper, we propose a novel video depth estimation approach, FutureDepth, which enables the model to implicitly leverage multi-frame and motion cues to improve depth estimation by making it learn to predict the future at training. More specifically, we propose a future prediction network, F-Net, which takes the features of multiple consecutive frames and is trained to predict multi-frame features one time step ahead iteratively. In this way, F-Net learns the underlying motion and correspondence information, and we incorporate its features into the depth decoding process. Additionally, to enrich the learning of multiframe correspondence cues, we further leverage a reconstruction network, R-Net, which is trained via adaptively masked auto-encoding of multiframe feature volumes. At inference time, both F-Net and R-Net are used to produce queries to work with the depth decoder, as well as a final refinement network. Through extensive experiments on several benchmarks, i.e., NYUDv2, KITTI, DDAD, and Sintel, which cover indoor, driving, and open-domain scenarios, we show that FutureDepth significantly improves upon baseline models, outperforms existing video depth estimation methods, and sets new state-of-the-art (SOTA) accuracy. Furthermore, FutureDepth is more efficient than existing SOTA video depth estimation models and has similar latencies when comparing to monocular models
Supporting Energy Policy Research with Large Language Models
Mar 19, 2024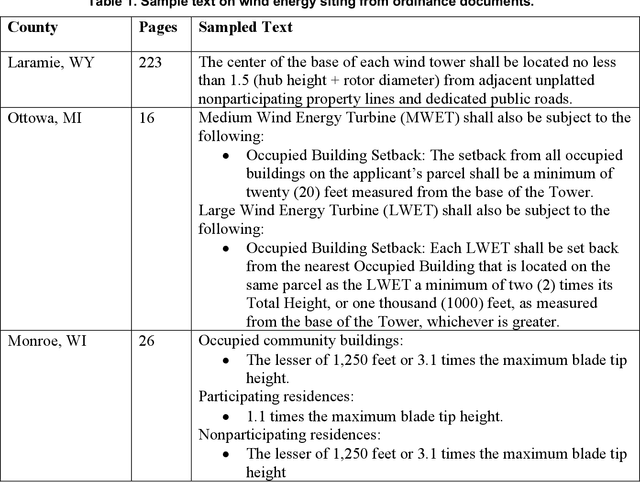

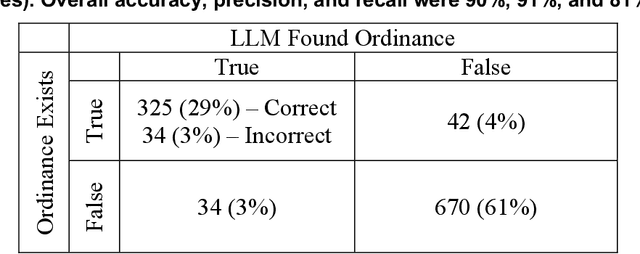
The recent growth in renewable energy development in the United States has been accompanied by a simultaneous surge in renewable energy siting ordinances. These zoning laws play a critical role in dictating the placement of wind and solar resources that are critical for achieving low-carbon energy futures. In this context, efficient access to and management of siting ordinance data becomes imperative. The National Renewable Energy Laboratory (NREL) recently introduced a public wind and solar siting database to fill this need. This paper presents a method for harnessing Large Language Models (LLMs) to automate the extraction of these siting ordinances from legal documents, enabling this database to maintain accurate up-to-date information in the rapidly changing energy policy landscape. A novel contribution of this research is the integration of a decision tree framework with LLMs. Our results show that this approach is 85 to 90% accurate with outputs that can be used directly in downstream quantitative modeling. We discuss opportunities to use this work to support similar large-scale policy research in the energy sector. By unlocking new efficiencies in the extraction and analysis of legal documents using LLMs, this study enables a path forward for automated large-scale energy policy research.
CLASSLA-web: Comparable Web Corpora of South Slavic Languages Enriched with Linguistic and Genre Annotation
Mar 19, 2024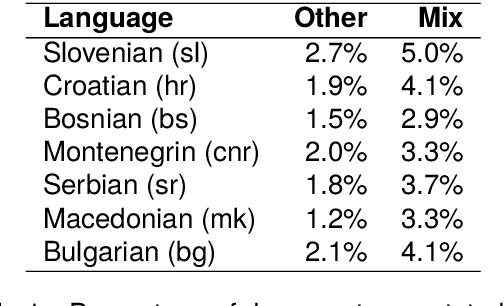
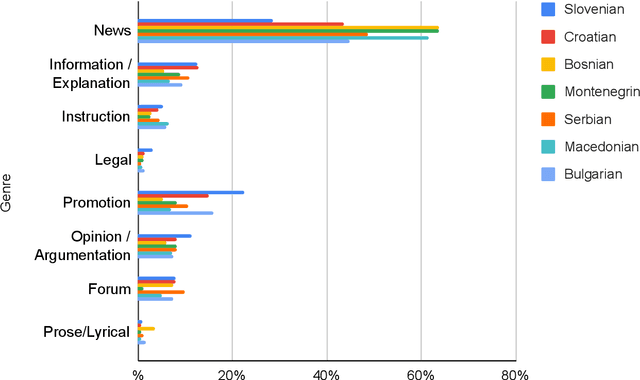
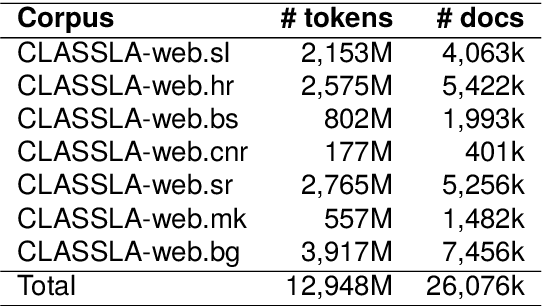
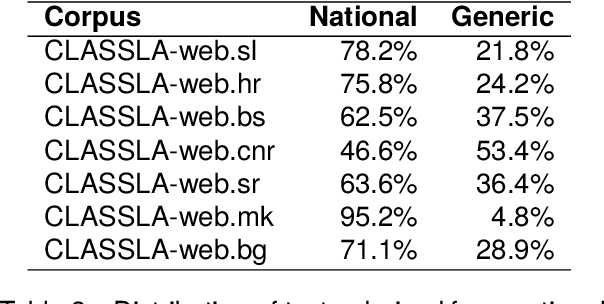
This paper presents a collection of highly comparable web corpora of Slovenian, Croatian, Bosnian, Montenegrin, Serbian, Macedonian, and Bulgarian, covering thereby the whole spectrum of official languages in the South Slavic language space. The collection of these corpora comprises a total of 13 billion tokens of texts from 26 million documents. The comparability of the corpora is ensured by a comparable crawling setup and the usage of identical crawling and post-processing technology. All the corpora were linguistically annotated with the state-of-the-art CLASSLA-Stanza linguistic processing pipeline, and enriched with document-level genre information via the Transformer-based multilingual X-GENRE classifier, which further enhances comparability at the level of linguistic annotation and metadata enrichment. The genre-focused analysis of the resulting corpora shows a rather consistent distribution of genres throughout the seven corpora, with variations in the most prominent genre categories being well-explained by the economic strength of each language community. A comparison of the distribution of genre categories across the corpora indicates that web corpora from less developed countries primarily consist of news articles. Conversely, web corpora from economically more developed countries exhibit a smaller proportion of news content, with a greater presence of promotional and opinionated texts.
Dr3: Ask Large Language Models Not to Give Off-Topic Answers in Open Domain Multi-Hop Question Answering
Mar 19, 2024
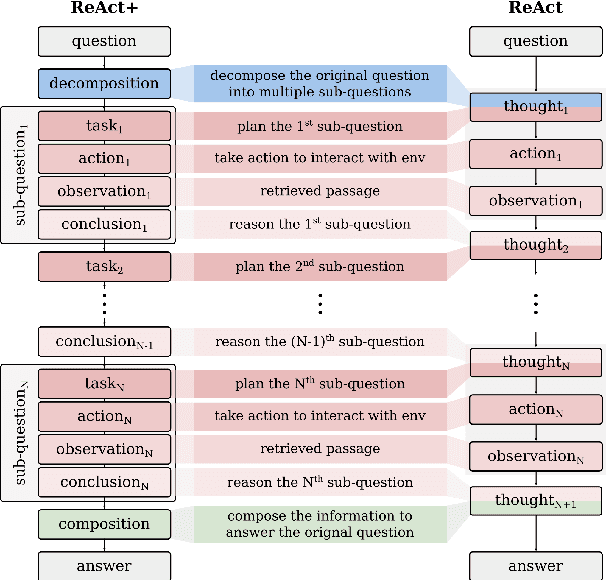
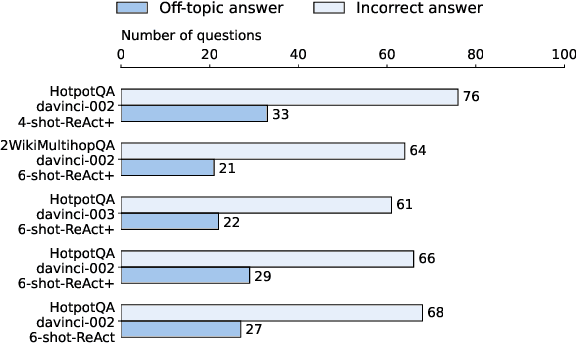
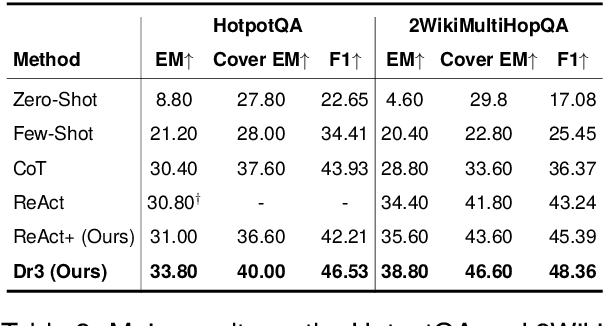
Open Domain Multi-Hop Question Answering (ODMHQA) plays a crucial role in Natural Language Processing (NLP) by aiming to answer complex questions through multi-step reasoning over retrieved information from external knowledge sources. Recently, Large Language Models (LLMs) have demonstrated remarkable performance in solving ODMHQA owing to their capabilities including planning, reasoning, and utilizing tools. However, LLMs may generate off-topic answers when attempting to solve ODMHQA, namely the generated answers are irrelevant to the original questions. This issue of off-topic answers accounts for approximately one-third of incorrect answers, yet remains underexplored despite its significance. To alleviate this issue, we propose the Discriminate->Re-Compose->Re- Solve->Re-Decompose (Dr3) mechanism. Specifically, the Discriminator leverages the intrinsic capabilities of LLMs to judge whether the generated answers are off-topic. In cases where an off-topic answer is detected, the Corrector performs step-wise revisions along the reversed reasoning chain (Re-Compose->Re-Solve->Re-Decompose) until the final answer becomes on-topic. Experimental results on the HotpotQA and 2WikiMultiHopQA datasets demonstrate that our Dr3 mechanism considerably reduces the occurrence of off-topic answers in ODMHQA by nearly 13%, improving the performance in Exact Match (EM) by nearly 3% compared to the baseline method without the Dr3 mechanism.
Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
Mar 19, 2024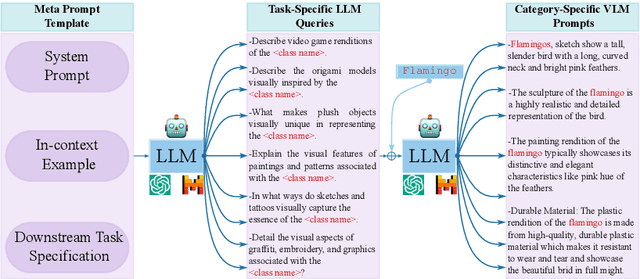
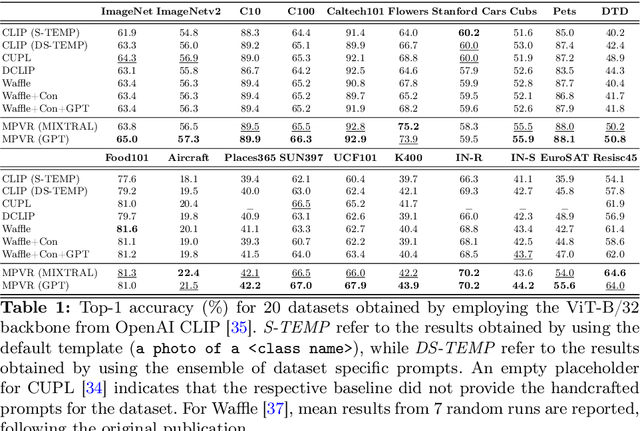
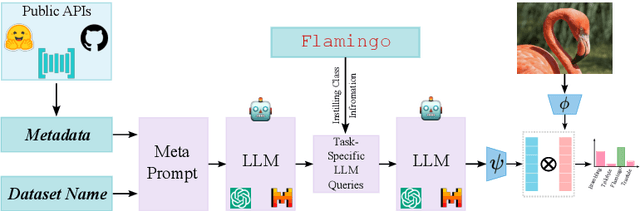
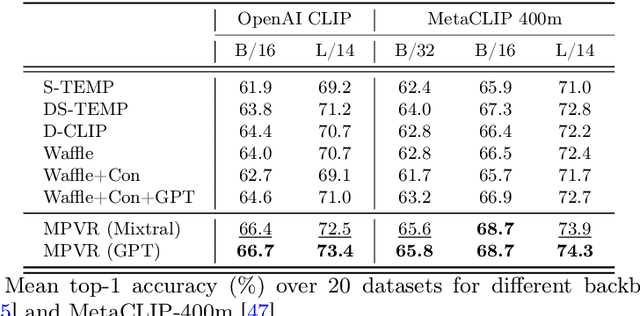
Prompt ensembling of Large Language Model (LLM) generated category-specific prompts has emerged as an effective method to enhance zero-shot recognition ability of Vision-Language Models (VLMs). To obtain these category-specific prompts, the present methods rely on hand-crafting the prompts to the LLMs for generating VLM prompts for the downstream tasks. However, this requires manually composing these task-specific prompts and still, they might not cover the diverse set of visual concepts and task-specific styles associated with the categories of interest. To effectively take humans out of the loop and completely automate the prompt generation process for zero-shot recognition, we propose Meta-Prompting for Visual Recognition (MPVR). Taking as input only minimal information about the target task, in the form of its short natural language description, and a list of associated class labels, MPVR automatically produces a diverse set of category-specific prompts resulting in a strong zero-shot classifier. MPVR generalizes effectively across various popular zero-shot image recognition benchmarks belonging to widely different domains when tested with multiple LLMs and VLMs. For example, MPVR obtains a zero-shot recognition improvement over CLIP by up to 19.8% and 18.2% (5.0% and 4.5% on average over 20 datasets) leveraging GPT and Mixtral LLMs, respectively
Texture Edge detection by Patch consensus (TEP)
Mar 16, 2024
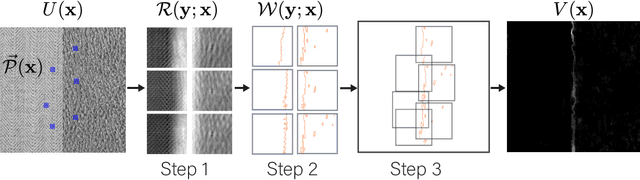

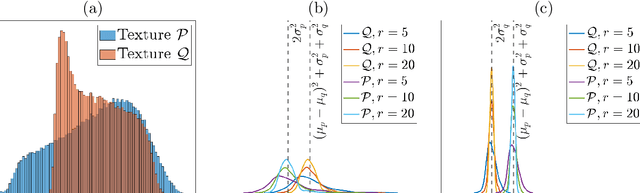
We propose Texture Edge detection using Patch consensus (TEP) which is a training-free method to detect the boundary of texture. We propose a new simple way to identify the texture edge location, using the consensus of segmented local patch information. While on the boundary, even using local patch information, the distinction between textures are typically not clear, but using neighbor consensus give a clear idea of the boundary. We utilize local patch, and its response against neighboring regions, to emphasize the similarities and the differences across different textures. The step of segmentation of response further emphasizes the edge location, and the neighborhood voting gives consensus and stabilize the edge detection. We analyze texture as a stationary process to give insight into the patch width parameter verses the quality of edge detection. We derive the necessary condition for textures to be distinguished, and analyze the patch width with respect to the scale of textures. Various experiments are presented to validate the proposed model.
Task-Aware Low-Rank Adaptation of Segment Anything Model
Mar 16, 2024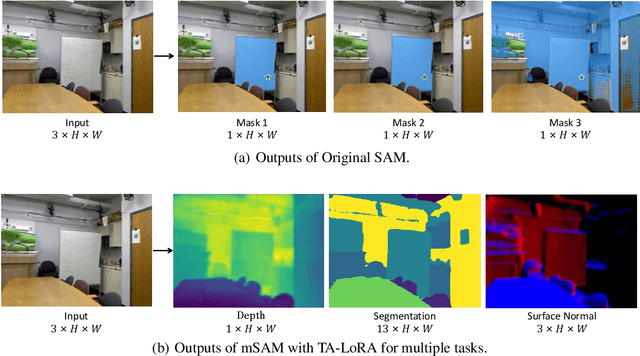
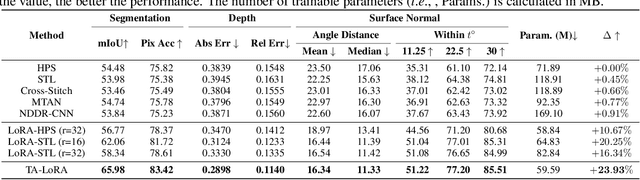
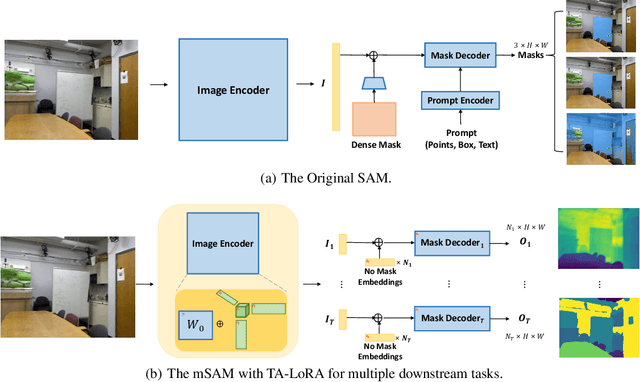
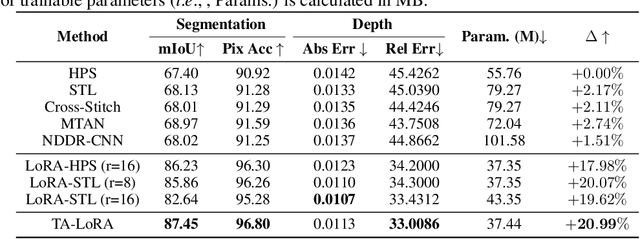
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has been proven to be a powerful foundation model for image segmentation tasks, which is an important task in computer vision. However, the transfer of its rich semantic information to multiple different downstream tasks remains unexplored. In this paper, we propose the Task-Aware Low-Rank Adaptation (TA-LoRA) method, which enables SAM to work as a foundation model for multi-task learning. Specifically, TA-LoRA injects an update parameter tensor into each layer of the encoder in SAM and leverages a low-rank tensor decomposition method to incorporate both task-shared and task-specific information. Furthermore, we introduce modified SAM (mSAM) for multi-task learning where we remove the prompt encoder of SAM and use task-specific no mask embeddings and mask decoder for each task. Extensive experiments conducted on benchmark datasets substantiate the efficacy of TA-LoRA in enhancing the performance of mSAM across multiple downstream tasks.