 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Segmentation on VSPW Dataset through Contrastive Loss and Multi-dataset Training Approach
Jun 06, 2023

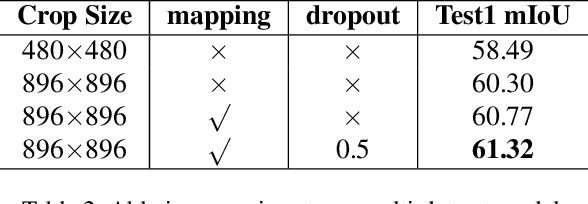
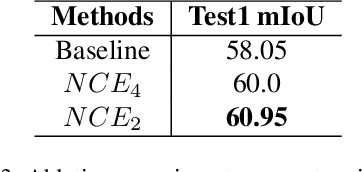
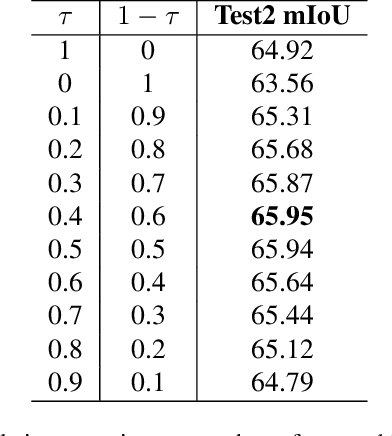
Video scene parsing incorporates temporal information, which can enhance the consistency and accuracy of predictions compared to image scene parsing. The added temporal dimension enables a more comprehensive understanding of the scene, leading to more reliable results. This paper presents the winning solution of the CVPR2023 workshop for video semantic segmentation, focusing on enhancing Spatial-Temporal correlations with contrastive loss. We also explore the influence of multi-dataset training by utilizing a label-mapping technique. And the final result is aggregating the output of the above two models. Our approach achieves 65.95% mIoU performance on the VSPW dataset, ranked 1st place on the VSPW challenge at CVPR 2023.
An information-theoretic learning model based on importance sampling
Feb 23, 2023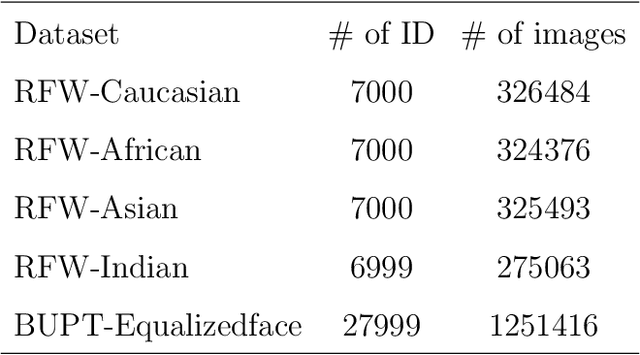

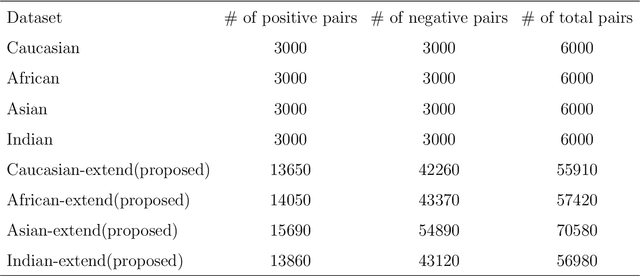
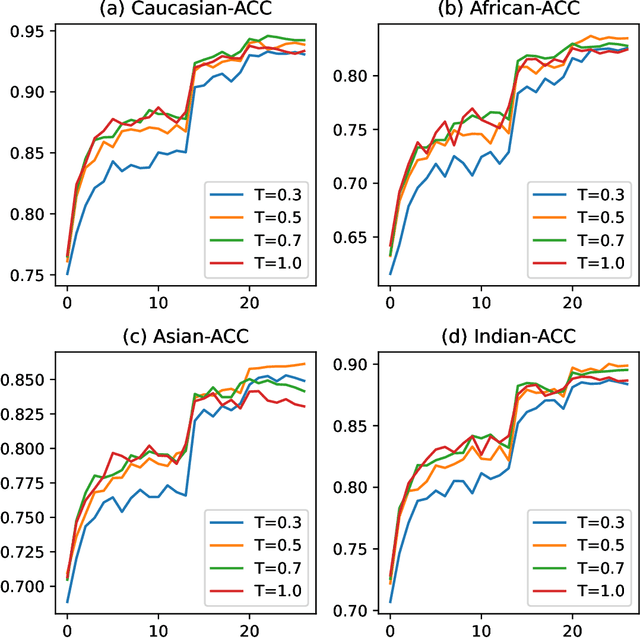
A crucial assumption underlying the most current theory of machine learning is that the training distribution is identical to the test distribution. However, this assumption may not hold in some real-world applications. In this paper, we develop a learning model based on principles of information theory by minimizing the worst-case loss at prescribed levels of uncertainty. We reformulate the empirical estimation of the risk functional and the distribution deviation constraint based on the importance sampling method. The objective of the proposed approach is to minimize the loss under maximum degradation and hence the resulting problem is a minimax problem which can be converted to an unconstrained minimum problem using the Lagrange method with the Lagrange multiplier $T$. We reveal that the minimization of the objective function under logarithmic transformation is equivalent to the minimization of the p-norm loss with $p=\frac{1}{T}$. We applied the proposed model to the face verification task on Racial Faces in the Wild datasets and showed that the proposed model performs better under large distribution deviations.
Correlated Time Series Self-Supervised Representation Learning via Spatiotemporal Bootstrapping
Jun 12, 2023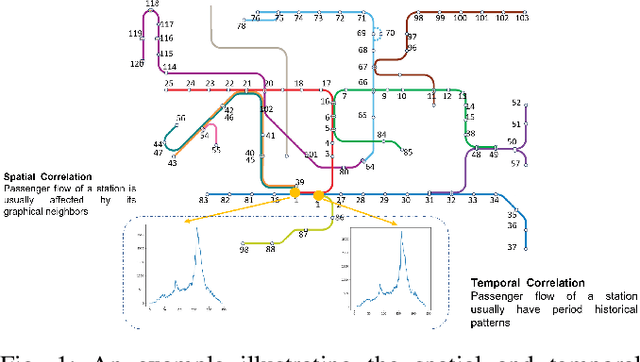
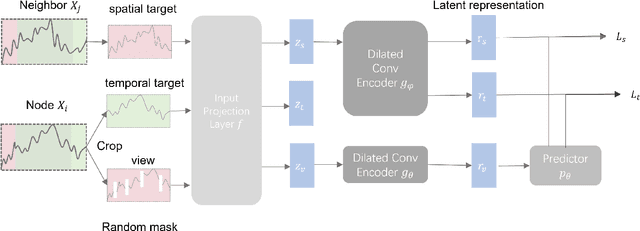
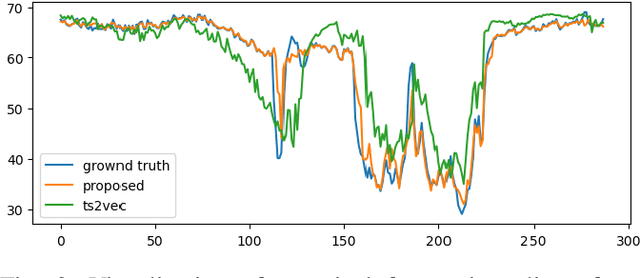
Correlated time series analysis plays an important role in many real-world industries. Learning an efficient representation of this large-scale data for further downstream tasks is necessary but challenging. In this paper, we propose a time-step-level representation learning framework for individual instances via bootstrapped spatiotemporal representation prediction. We evaluated the effectiveness and flexibility of our representation learning framework on correlated time series forecasting and cold-start transferring the forecasting model to new instances with limited data. A linear regression model trained on top of the learned representations demonstrates our model performs best in most cases. Especially compared to representation learning models, we reduce the RMSE, MAE, and MAPE by 37%, 49%, and 48% on the PeMS-BAY dataset, respectively. Furthermore, in real-world metro passenger flow data, our framework demonstrates the ability to transfer to infer future information of new cold-start instances, with gains of 15%, 19%, and 18%. The source code will be released under the GitHub https://github.com/bonaldli/Spatiotemporal-TS-Representation-Learning
Feature Fusion from Head to Tail: an Extreme Augmenting Strategy for Long-Tailed Visual Recognition
Jun 12, 2023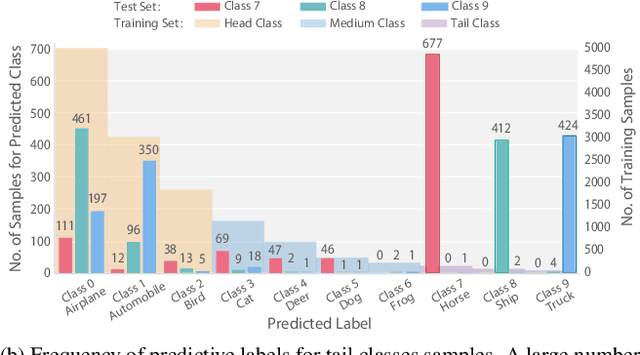
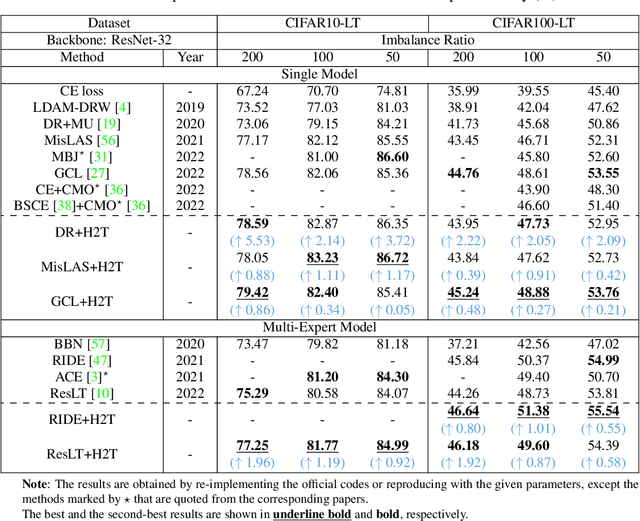
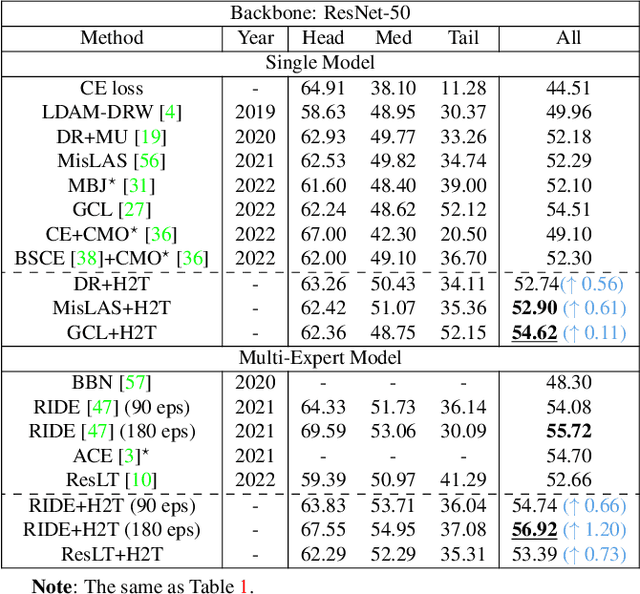
The imbalanced distribution of long-tailed data poses a challenge for deep neural networks, as models tend to prioritize correctly classifying head classes over others so that perform poorly on tail classes. The lack of semantics for tail classes is one of the key factors contributing to their low recognition accuracy. To rectify this issue, we propose to augment tail classes by borrowing the diverse semantic information from head classes, referred to as head-to-tail fusion (H2T). We randomly replace a portion of the feature maps of the tail class with those of the head class. The fused feature map can effectively enhance the diversity of tail classes by incorporating features from head classes that are relevant to them. The proposed method is easy to implement due to its additive fusion module, making it highly compatible with existing long-tail recognition methods for further performance boosting. Extensive experiments on various long-tailed benchmarks demonstrate the effectiveness of the proposed H2T. The source code is temporarily available at https://github.com/Keke921/H2T.
"Are you telling me to put glasses on the dog?'' Content-Grounded Annotation of Instruction Clarification Requests in the CoDraw Dataset
Jun 04, 2023
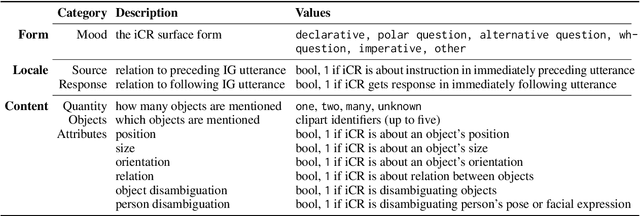
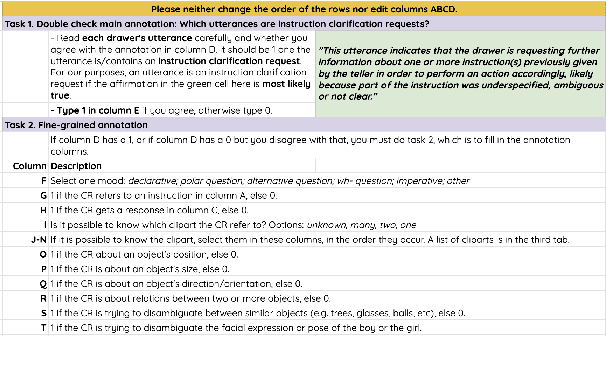

Instruction Clarification Requests are a mechanism to solve communication problems, which is very functional in instruction-following interactions. Recent work has argued that the CoDraw dataset is a valuable source of naturally occurring iCRs. Beyond identifying when iCRs should be made, dialogue models should also be able to generate them with suitable form and content. In this work, we introduce CoDraw-iCR (v2), which extends the existing iCR identifiers fine-grained information grounded in the underlying dialogue game items and possible actions. Our annotation can serve to model and evaluate repair capabilities of dialogue agents.
Basis Pursuit Denoising via Recurrent Neural Network Applied to Super-resolving SAR Tomography
May 23, 2023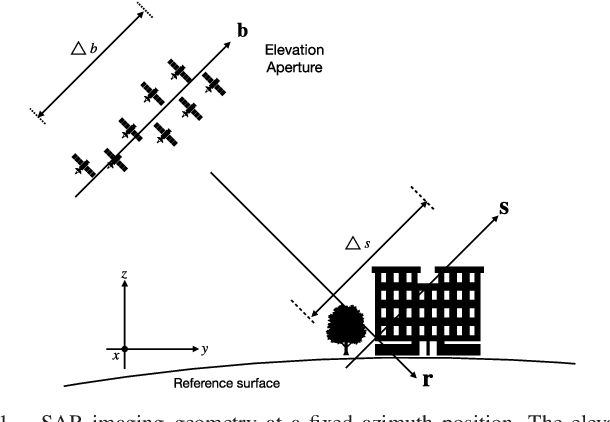
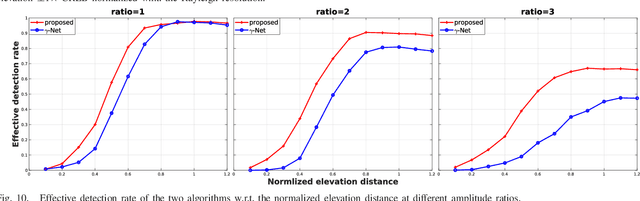
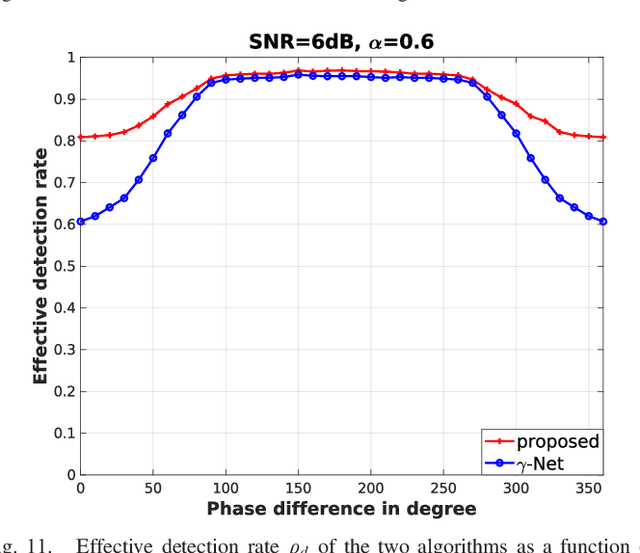

Finding sparse solutions of underdetermined linear systems commonly requires the solving of L1 regularized least squares minimization problem, which is also known as the basis pursuit denoising (BPDN). They are computationally expensive since they cannot be solved analytically. An emerging technique known as deep unrolling provided a good combination of the descriptive ability of neural networks, explainable, and computational efficiency for BPDN. Many unrolled neural networks for BPDN, e.g. learned iterative shrinkage thresholding algorithm and its variants, employ shrinkage functions to prune elements with small magnitude. Through experiments on synthetic aperture radar tomography (TomoSAR), we discover the shrinkage step leads to unavoidable information loss in the dynamics of networks and degrades the performance of the model. We propose a recurrent neural network (RNN) with novel sparse minimal gated units (SMGUs) to solve the information loss issue. The proposed RNN architecture with SMGUs benefits from incorporating historical information into optimization, and thus effectively preserves full information in the final output. Taking TomoSAR inversion as an example, extensive simulations demonstrated that the proposed RNN outperforms the state-of-the-art deep learning-based algorithm in terms of super-resolution power as well as generalization ability. It achieved a 10% to 20% higher double scatterers detection rate and is less sensitive to phase and amplitude ratio differences between scatterers. Test on real TerraSAR-X spotlight images also shows a high-quality 3-D reconstruction of the test site.
Efficient Communication via Self-supervised Information Aggregation for Online and Offline Multi-agent Reinforcement Learning
Feb 19, 2023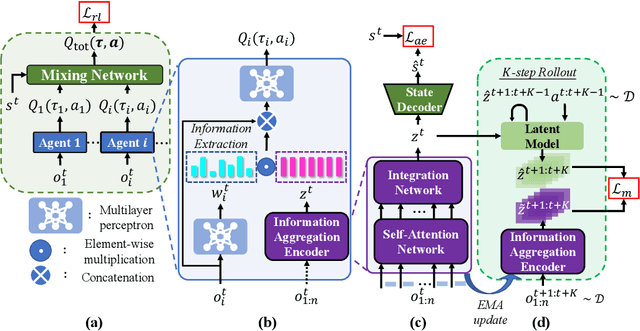
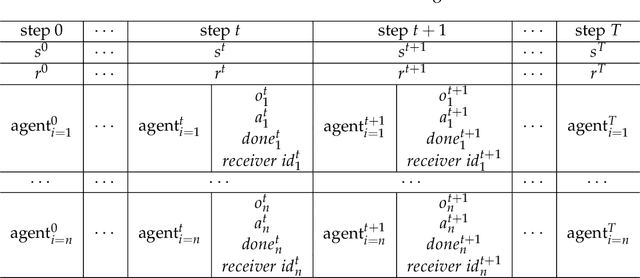
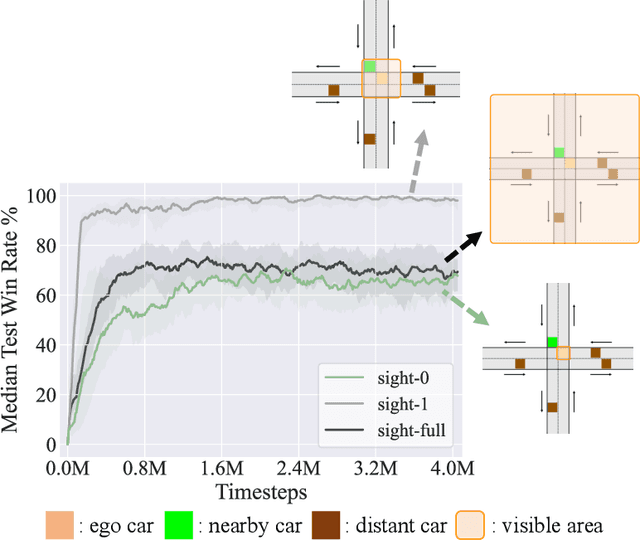
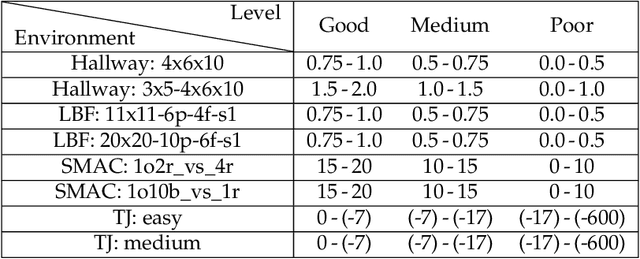
Utilizing messages from teammates can improve coordination in cooperative Multi-agent Reinforcement Learning (MARL). Previous works typically combine raw messages of teammates with local information as inputs for policy. However, neglecting message aggregation poses significant inefficiency for policy learning. Motivated by recent advances in representation learning, we argue that efficient message aggregation is essential for good coordination in cooperative MARL. In this paper, we propose Multi-Agent communication via Self-supervised Information Aggregation (MASIA), where agents can aggregate the received messages into compact representations with high relevance to augment the local policy. Specifically, we design a permutation invariant message encoder to generate common information-aggregated representation from messages and optimize it via reconstructing and shooting future information in a self-supervised manner. Hence, each agent would utilize the most relevant parts of the aggregated representation for decision-making by a novel message extraction mechanism. Furthermore, considering the potential of offline learning for real-world applications, we build offline benchmarks for multi-agent communication, which is the first as we know. Empirical results demonstrate the superiority of our method in both online and offline settings. We also release the built offline benchmarks in this paper as a testbed for communication ability validation to facilitate further future research.
UAV Trajectory and Multi-User Beamforming Optimization for Clustered Users Against Passive Eavesdropping Attacks With Unknown CSI
Jun 13, 2023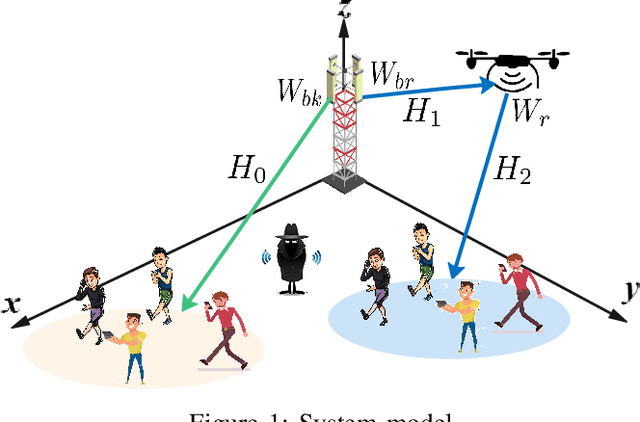
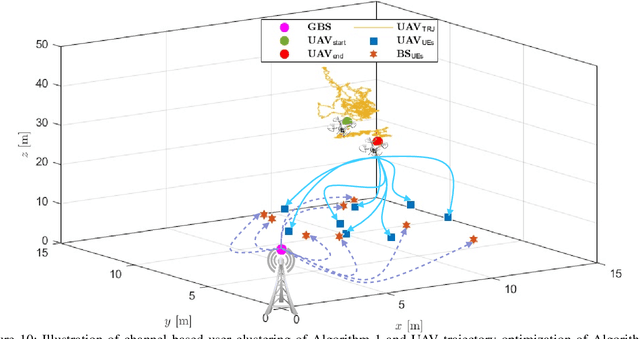
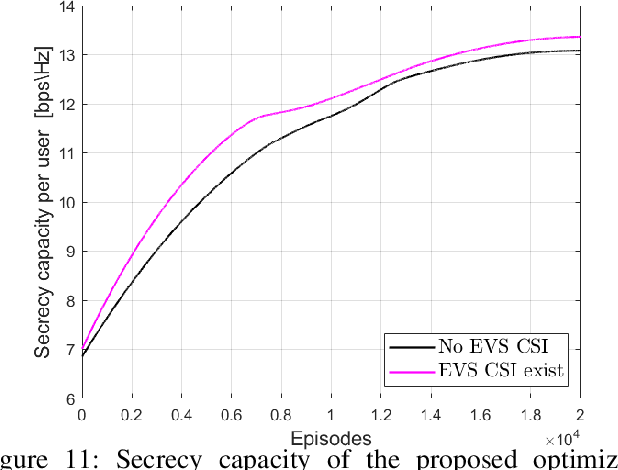
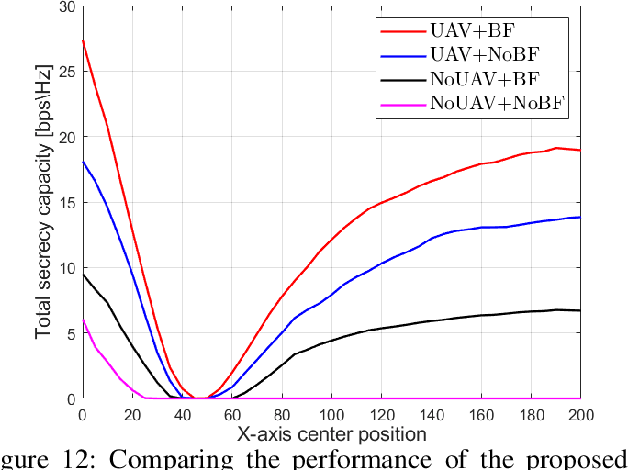
This paper tackles the fundamental passive eavesdropping problem in modern wireless communications in which the location and the channel state information (CSI) of the attackers are unknown. In this regard, we propose deploying an unmanned aerial vehicle (UAV) that serves as a mobile aerial relay (AR) to help ground base station (GBS) support a subset of vulnerable users. More precisely, our solution (1) clusters the single-antenna users in two groups to be either served by the GBS directly or via the AR, (2) employs optimal multi-user beamforming to the directly served users, and (3) optimizes the AR's 3D position, its multi-user beamforming matrix and transmit powers by combining closed-form solutions with machine learning techniques. Specifically, we design a plain beamforming and power optimization combined with a deep reinforcement learning (DRL) algorithm for an AR to optimize its trajectory for the security maximization of the served users. Numerical results show that the multi-user multiple input, single output (MU-MISO) system split between a GBS and an AR with optimized transmission parameters without knowledge of the eavesdropping channels achieves high secrecy capacities that scale well with increasing the number of users.
BPKD: Boundary Privileged Knowledge Distillation For Semantic Segmentation
Jun 13, 2023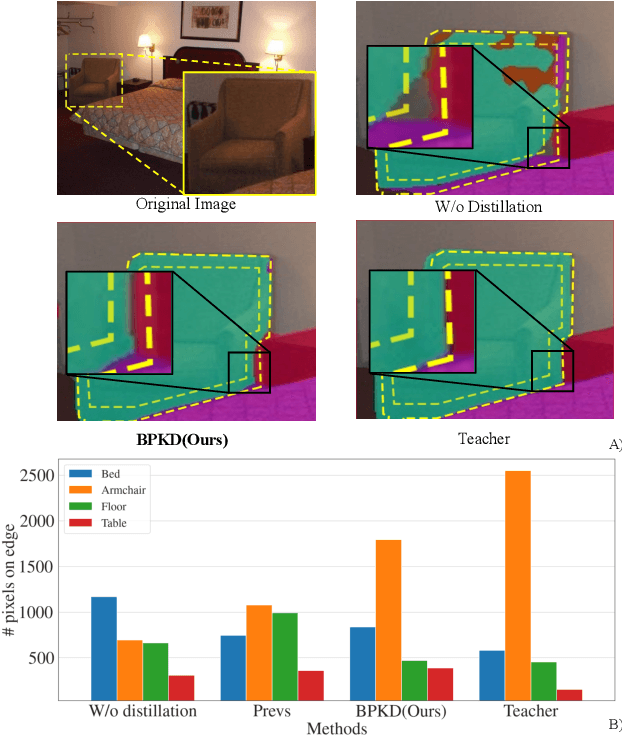
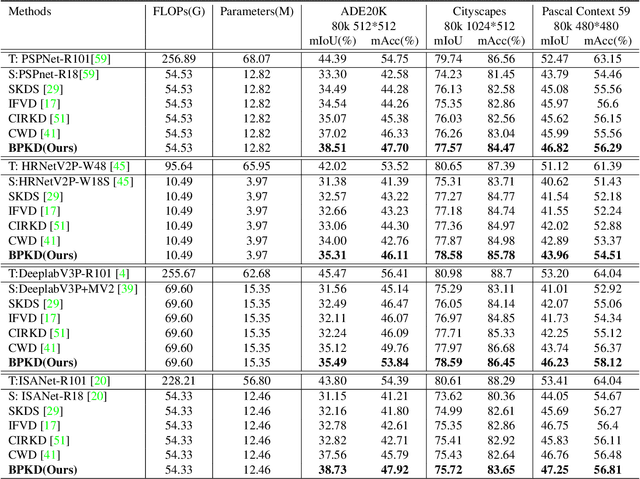
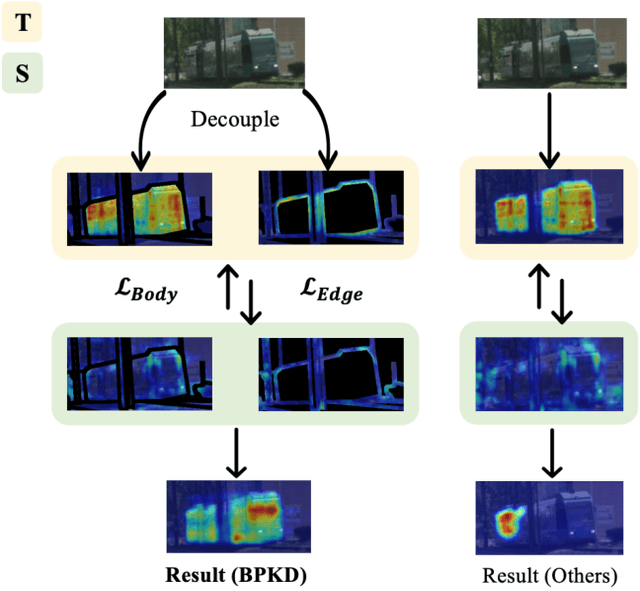
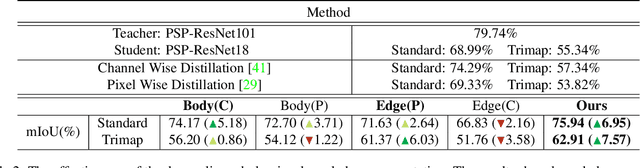
Current approaches for knowledge distillation in semantic segmentation tend to adopt a holistic approach that treats all spatial locations equally. However, for dense prediction tasks, it is crucial to consider the knowledge representation for different spatial locations in a different manner. Furthermore, edge regions between adjacent categories are highly uncertain due to context information leakage, which is particularly pronounced for compact networks. To address this challenge, this paper proposes a novel approach called boundary-privileged knowledge distillation (BPKD). BPKD distills the knowledge of the teacher model's body and edges separately from the compact student model. Specifically, we employ two distinct loss functions: 1) Edge Loss, which aims to distinguish between ambiguous classes at the pixel level in edge regions. 2) Body Loss, which utilizes shape constraints and selectively attends to the inner-semantic regions. Our experiments demonstrate that the proposed BPKD method provides extensive refinements and aggregation for edge and body regions. Additionally, the method achieves state-of-the-art distillation performance for semantic segmentation on three popular benchmark datasets, highlighting its effectiveness and generalization ability. BPKD shows consistent improvements over various lightweight semantic segmentation structures. The code is available at \url{https://github.com/AkideLiu/BPKD}.
Automated 3D Pre-Training for Molecular Property Prediction
Jun 13, 2023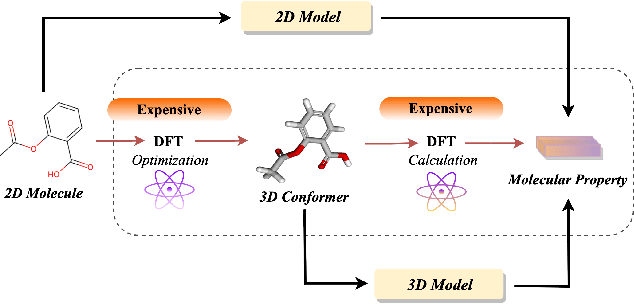
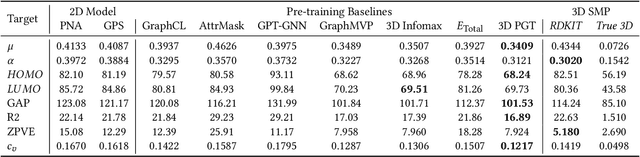
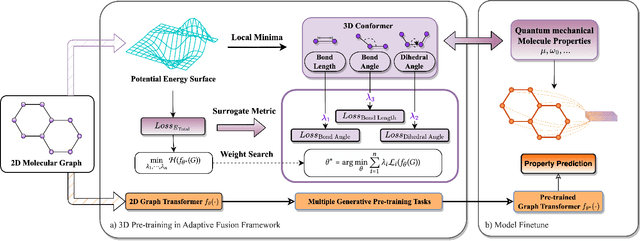
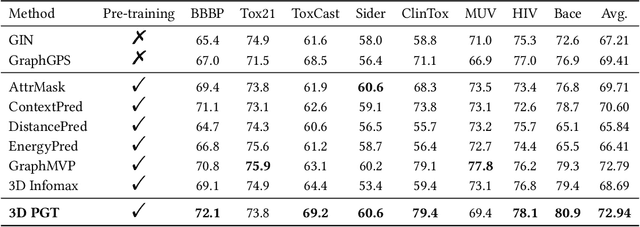
Molecular property prediction is an important problem in drug discovery and materials science. As geometric structures have been demonstrated necessary for molecular property prediction, 3D information has been combined with various graph learning methods to boost prediction performance. However, obtaining the geometric structure of molecules is not feasible in many real-world applications due to the high computational cost. In this work, we propose a novel 3D pre-training framework (dubbed 3D PGT), which pre-trains a model on 3D molecular graphs, and then fine-tunes it on molecular graphs without 3D structures. Based on fact that bond length, bond angle, and dihedral angle are three basic geometric descriptors corresponding to a complete molecular 3D conformer, we first develop a multi-task generative pre-train framework based on these three attributes. Next, to automatically fuse these three generative tasks, we design a surrogate metric using the \textit{total energy} to search for weight distribution of the three pretext task since total energy corresponding to the quality of 3D conformer.Extensive experiments on 2D molecular graphs are conducted to demonstrate the accuracy, efficiency and generalization ability of the proposed 3D PGT compared to various pre-training baselines.